
Kafka -- 生产者
生产者概述
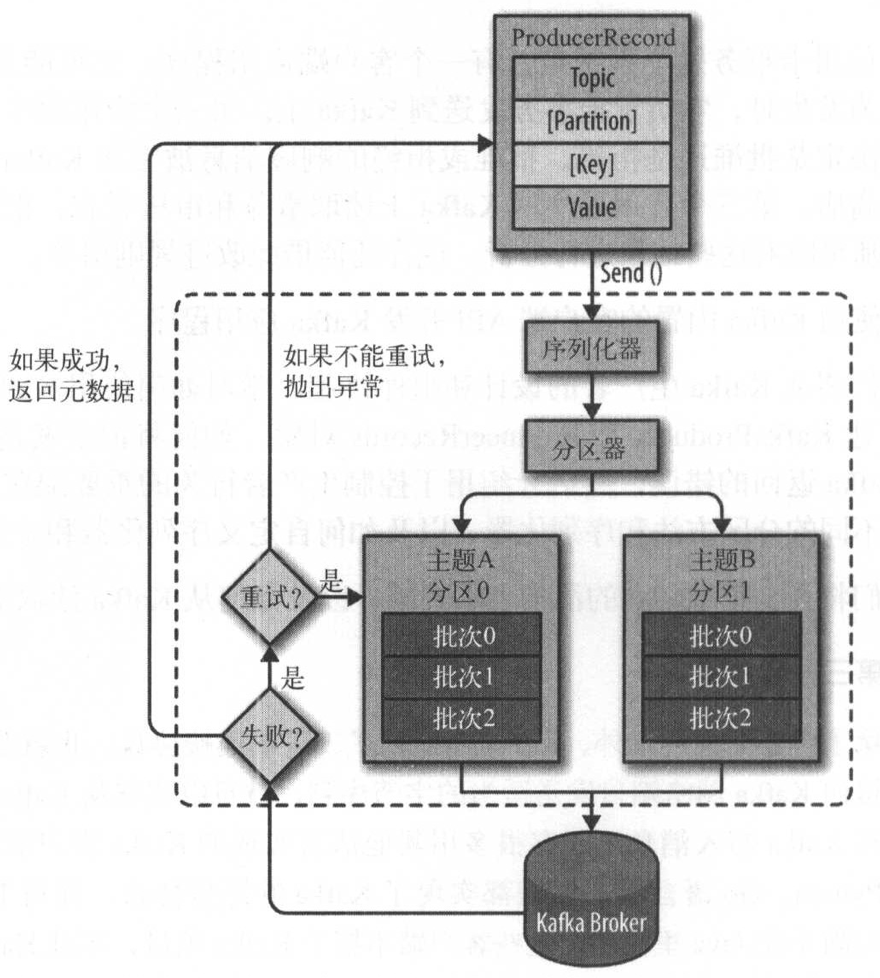
- 创建一个
ProducerRecord对象,ProducerRecord对象包含Topic和Value,还可以指定Key或Partition - 在发送
ProducerRecord对象时,生产者先将Key和Partition序列化成字节数组,以便于在网络上传输 - 字节数组被传给分区器
- 如果在
ProducerRecord对象里指定了Partition- 那么分区器就不会做任何事情,直接返回指定的分区
- 如果没有指定分区,那么分区器会根据
ProducerRecord对象的Key来选择一个Partition - 选择好分区后,生产者就知道该往哪个主题和分区发送这条记录
- 如果在
- 这条记录会被添加到一个记录批次里,一个批次内的所有消息都会被发送到相同的Topic和Partition上
- 有一个单独的线程负责把这些记录批次发送到相应的Broker
- 服务器在收到这些消息时会返回一个响应
- 如果消息成功写入Kafka,就会返回一个
RecordMetaData对象- 包含了Topic和Partition信息,以及记录在分区里的偏移量
- 如果写入失败,就会返回一个错误
- 生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败,就会返回错误信息
- 如果消息成功写入Kafka,就会返回一个
创建生产者
必选属性
bootstrap.servers
- Broker的地址清单,host:port
- 清单里不需要包含所有的Broker地址,生产者会从给定的Broker里找到其它Broker的信息
- 建议最少两个,一旦其中一个宕机,生产者仍然能够连接到集群上
key.serializer
- Broker希望接收到的消息的Key和Value都是字节数组
- 生产者接口允许使用参数化类型,因此可以把Java对象作为Key和Value发送给Broker
key.serializer必须是org.apache.kafka.common.serialization.Serializer的实现类- 生产者会通过
key.serializer把Key对象序列化为_字节数组_ - Kafka默认提供
ByteArraySerializerStringSerializerIntegerSerializer
value.serializer
- 与
key.serializer类似,value.serializer指定的类会把Value序列化成字节数组 - 如果Key和Value都是字符串,可以使用与
key.serializer一样的序列化器 - 如果Key是整数类型,而Value是字符串,那么需要使用不同的序列化器
Java代码
1 | Properties properties = new Properties(); |
发送消息
发送方式
发送并忘记
- 生产者把消息发送给服务器,但并不关心是否正常到达
- Kafka是高可用的,而且生产者会自动尝试重发
- 但会丢失一些消息
同步发送
1 | // Key对象和Value对象的类型必须与生产者对象的序列化器相匹配 |
发送错误
- 可重试错误(可以通过重发消息来解决的错误)
- 连接错误,可以通过再次建立连接来解决
KafkaProducer可以被配置成自动重连- 如果在多次重试后扔无法解决问题,应用程序会收到一个重试异常
- No Leader 错误,可以通过重新为分区选举领导来解决
- 连接错误,可以通过再次建立连接来解决
- 无法通过重试解决的错误,例如消息太大,
KafkaProducer不会进行任何重试,直接抛出异常
异步发送
1 | ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, KEY, VALUE); |
生产者配置
acks
acks:必须有多少个分区副本收到消息,生产者才会认为消息写入是成功的- ack=0:生产者不会等待任何来自服务器的响应。
- 如果当中出现问题,导致服务器没有收到消息,那么生产者无从得知,会造成消息丢失
- 由于生产者不需要等待服务器的响应
- 所以可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量
- acks=1(默认值):只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应
- 如果消息无法到达Leader节点(例如Leader节点崩溃,新的Leader节点还没有被选举出来)
- 生产者就会收到一个错误响应,为了避免数据丢失,生产者会重发消息
- 如果一个没有收到消息的节点成为新Leader,消息还是会丢失
- 此时的吞吐量主要取决于使用的是同步发送还是异步发送
- 吞吐量还受到发送中消息数量的限制,例如生产者在收到服务器响应之前可以发送多少个消息
- 如果消息无法到达Leader节点(例如Leader节点崩溃,新的Leader节点还没有被选举出来)
- acks=all:只有当所有参与复制的节点全部都收到消息时,生产者才会收到一个来自服务器的成功响应
- 这种模式是最安全的
- 可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群依然可以运行
- 延时比acks=1更高,因为要等待不止一个服务器节点接收消息
- 这种模式是最安全的
buffer.memory
- 该参数用来设置生产者内缓冲区的大小,生产者用缓冲区来缓冲要发送到服务器端的消息,默认为
32MB - 如果应用程序发送消息的速度超过了发送到服务器端速度,会导致生产者空间不足
- 这个时候,
send()方法调用要么被阻塞,要么抛出异常,取决于block.on.buffer.full
compression.type
- 默认情况下为
none,消息在发送时是不会被压缩的 - 该参数可以设置为
snappy、gzip或者lz4snappy压缩算法由Google发明- 占用较少的CPU,却能提供较好的性能和相当可观的压缩比
- 适用于关注性能和网络带宽的场景
gzip压缩算法- 占用较多的CPU,但会提供更高的压缩比
- 适用于网络带宽比较有限的场景
- 压缩消息可以降低网络传输开销和存储开销,而这往往是向
Broker发送消息的瓶颈
retries
- 生产者从服务器收到的错误有可能是临时性错误(如分区找不到Leader)
- 在这种情况下,
retries参数决定了生产者可以重发消息的次数- 默认情况下,生产者会在每次重试之间等待100ms,控制参数为
retry.backoff.ms - 可以先测试一下恢复一个崩溃节点需要多少时间,假设为
T- 让生产者总的重试时间比
T长,否着生产者会_过早地放弃重试_
- 让生产者总的重试时间比
- 默认情况下,生产者会在每次重试之间等待100ms,控制参数为
- 有些错误不是临时性错误,没办法通过重试来解决(例如消息太大)
- 一般情况下,因为生产者会自动进行重试,所以没必要在代码逻辑处理那些可重试的错误
- 只需要处理那些不可重试的错误或者重试次数超过上限的情况
batch.size
- 当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里,默认值为
16KB- 该参数指定了一个批次可以使用多内存大小,单位为_字节_
- 当批次被填满,批次里的所有消息会被发送出去
- 生产者不一定会等到批次被填满才发送,半满设置只有一个消息的批次也有可能被发送
- 如果
batch.size设置很大,也不会造成延迟,只是会占用更多的内存 - 如果
batch.size设置很小,生产者需要频繁地发送消息,会增加一些额外的开销
linger.ms
- 该参数指定了生产者在发送批次之前等待更多消息加入批次的时间,默认值为0
KafkaProducer会在批次填满或者linger.ms达到上限时把批次发出去- 默认情况下,只要有可用的线程,生产者就会把消息发出去,就算批次里只有一个消息
- 设置
linger.ms,会增加延迟,但也会提高吞吐量- 一次性发送更多的消息,平摊到单个消息的开销就变小了
client.id
任意字符串,服务器会用它来识别消息的来源,还可以用在日志和配额指标里
max.in.flight.requests.per.connection
- 该参数指定了生产者在收到服务器响应之前可以发送多少消息,默认值为5
- 值越高,会占用越多的内存,不过也会提升吞吐量
- 如果设为1,可以保证消息是按照发送的顺序写入服务器,即使发生重试
timeout.ms、request.timeout.ms、metadata.fetch.timeout.ms
timeout.ms:指定了Broker等待同步副本返回消息确认的时间,默认值为30000- 与
acks的配置相匹配,如果在指定时间内没有收到同步副本的确认,那么Broker就会返回一个错误
- 与
request.timeout.ms:指定了生产者在发送数据时等待服务器返回响应的时间,默认值为10000metadata.fetch.timeout.ms:指定了生产者在获取元数据时等待服务器返回响应的时间,默认值为60000- 如果等待响应超时,那么生产者要么重试发送数据,要么返回一个错误(抛出异常或者执行回调)
max.block.ms
- 该参数指定了在调用
send()方法或使用partitionsFor()方法获取元数据时,生产者阻塞的时间,默认值为60000 - 当生产者的发送缓冲区已满,或者没有可用的元数据时,上面两个方法会阻塞
- 在阻塞时间达到
max.block.ms时,生产者就会抛出超时异常
max.request.size
- 该参数用于控制生产者发送单个请求的大小,默认值
1MB- 可以指能发送的单个消息的最大值(因为一个请求最少有一个消息)
- 也可以指单个请求里所有消息(一个批次,多个消息)的总大小
Broker对单个可接收消息的最大值也有自己的限制(message.max.bytes,默认值为1000012)- 所以两边的配置最好可以匹配,避免生产者发送的消息被
Broker拒绝
- 所以两边的配置最好可以匹配,避免生产者发送的消息被
receive.buffer.bytes、send.buffer.bytes
- 这两个参数分别指定了TCP Socket接收和发送数据包的缓冲区大小
- 如果都被设为**-1,就使用操作系统的默认值**
receive.buffer.bytes的默认值为32KBsend.buffer.bytes的默认值为128KB
- 如果生产者或消费者与Broker处于不同的数据中心,那么可以适当增大这些值
序列化器
自定义序列化
- 如果发送到Kafka的对象不是简单的字符串或整型,那么可以使用序列化框架来创建消息记录
- 例如通用的序列化框架(推荐):
Avro、Thrift、ProtoBuf - 也可以使用自定义序列化器,但不推荐
- 例如通用的序列化框架(推荐):
1 | // 复杂对象 |
1 | // 序列化器 |
1 | public class CustomSerializerTest { |
Avro
Apache Avro是一种与编程语言无关的序列化格式Avro数据通过与语言无关的schema来定义schema通过JSON来描述,数据被序列化成二进制文件或JSON文件,一般会使用二进制文件Avro在读写文件时需要用到schema,schema一般是内嵌在数据文件里
- 重要特性
- 当负责写消息的应用程序使用新的schema,负责读消息的应用程序可以继续处理消息而无需做任何改动
- 特别适用于Kafka这样的消息系统
分区
- Kafka的消息是一个键值对,
ProducerRecord对象可以只包含Topic和Value,Key可以设置为null - Key的作用
- 作为_消息的附加信息_
- 用来_决定消息被写到主题的哪一个分区_
- 拥有相同Key的消息会被写入到同一个分区
- 如果Key为null,并且使用了默认的分区器,那么记录会被随机(轮询算法)地发送到主题内的各个可用分区上
- 如果Key不为null,并且使用了默认的分区器,那么Kafka会对
Key进行散列,然后根据散列值把消息映射到特定的分区上- 使用的是Kafka内部的散列算法,即使升级Java版本,散列值也不会发生变化
- 同一个Key总是被映射到同一个分区上
- 因此在映射时,会使用主题的所有分区,如果写入数据的分区是不可用的,那么就会发生错误
- 只有不改变分区数量的情况下,Key与分区之间的映射才能保持不变
- 如果使用
Key来映射分区,最好在创建主题的时候就把分区规划好,并且永远不要增加新分区
- 如果使用
- 可以自定义分区器
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-09-16
Kafka -- 重平衡
触发重平衡 组成员数量发生变化 – 最常见 订阅主题数量发生变化 订阅主题的分区数发生变化 通知 重平衡过程是通过消费者的心跳线程通知到其它消费者实例的 Kafka Java消费者需要定期地发送心跳请求到Broker端的协调者,表明它还活着 在Kafka 0.10.1.0之前,发送心跳请求是在消费者主线程完成的,即调用poll方法的那个线程 弊端 消息处理逻辑是也在主线程完成的 一旦消息处理消耗了很长时间,心跳请求将无法及时发送给协调者,导致协调者误以为消费者已死 从Kafka 0.10.1.0开始,社区引入了单独的心跳线程 重平衡的通知机制是通过心跳线程来完成的 当协调者决定开启新一轮重平衡后,会将REBALANCE_IN_PROGRESS封装进心跳请求的响应中 当消费者实例发现心跳响应中包含REBALANCE_IN_PROGRESS,就知道重平衡要开始了,这是重平衡的通知机制 heartbeat.interval.ms的真正作用是控制重平衡通知的频率 消费者组状态机 状态 描述 Empty 组内没有任何成员,但消费者组可能存在已提交的位移数据,而且这些位移尚未过期 ...

2019-08-26
Kafka -- 位移主题
ZooKeeper 老版本Consumer的位移管理依托于Apache ZooKeeper,自动或手动地将位移数据提交到ZK中保存 当Consumer重启后,能自动从ZK中读取位移数据,从而在上次消费截止的地方继续消费 这种设计使得Kafka Broker不需要保存位移数据,减少了Broker端需要持有的状态空间,有利于实现高伸缩性 但ZK并不适用于高频的写操作 位移主题 将Consumer的位移数据作为普通的Kafka消息,提交到__consumer_offsets(保存Consumer的位移信息) 提交过程需要实现高持久性,并需要支持高频的写操作 位移主题是普通的Kafka主题,同时也是一个内部主题,交由Kafka管理即可 位移主题的消息格式由Kafka定义,用户不能修改 因此不能随意向位移主题写消息,一旦写入的消息不能满足格式,那Kafka内部无法成功解析,会造成Broker崩溃 Kafka Consumer有API来提交位移(即向位移主题写消息) 消息格式 常用格式:Key-Value Key为消息键值,Value为消息体,在Kafka中都是字节数组 Key <Group ...

2019-09-03
Kafka -- 提交位移
消费位移 Consumer的消费位移,记录了Consumer要消费的下一条消息的位移 假设一个分区中有10条消息,位移分别为0到9 某个Consumer消费了5条消息,实际消费了位移0到4的5条消息,此时Consumer的位移为5,指向下一条消息的位移 Consumer需要向Kafka汇报自己的位移数据,这个汇报过程就是提交位移 Consumer能够同时消费多个分区的数据,所以位移的提交实际上是在分区粒度上进行的 Consumer需要为分配给它的每个分区提交各自的位移数据 提交位移主要是为了表征Consumer的消费进度 当Consumer发生故障重启后,能够从Kafka中读取之前提交的位移值,然后从相应的位移处继续消费 位移提交的语义 如果提交了位移X,那么Kafka会认为位移值小于X的消息都已经被成功消费了 灵活 位移提交非常灵活,可以提交任何位移值,但要承担相应的后果 假设Consumer消费了位移为0~9的10条消息 如果提交的位移为20,位移位于10~19的消息可能会丢失 如果提交的位移为5,位移位于5~9的消息可能会被重复消费 位移提交的语义保障由应用程序保证,Ka...

2019-03-26
Kafka -- 内部原理
群组成员关系 Kakfa使用ZooKeeper来维护集群成员的信息 每个Broker都有一个唯一的ID,这个ID可以在配置文件里面指定,也可以自动生成 在Broker启动的时候,通过创建临时节点把自己的ID注册到ZooKeeper Kakfa组件订阅ZooKeeper的/brokers/ids路径,当有Broker加入集群或者退出集群时,Kafka组件能获得通知 如果要启动另一个具有相同ID的Broker,会得到一个错误,这个Broker会尝试进行注册,但会失败 在Broker停机,出现网络分区或者长时间垃圾回收停顿时,Broker会从ZooKeeper上_断开连接_ 此时,Broker在启动时创建的临时节点会从ZooKeeper上自动移除(ZooKeeper特性) 订阅Broker列表的Kafka组件会被告知该Broker已经被移除 在关闭Broker时,它对应的临时节点也会消失,不过它的ID会继续存在于其他数据结构中 例如,主题的副本列表里可能会包含这些ID 在完全关闭了一个Broker之后,如果使用相同的ID启动另一个全新的Broker 该Broker会立即加入集群,并拥有与旧Broker...

2019-08-22
Kafka -- 消费者组
消费者组 消费者组(Consumer Group)是Kafka提供的可扩展且具有容错性的消费者机制 一个消费者组内可以有多个消费者或消费者实例(进程/线程),它们共享一个Group ID(字符串) 组内的所有消费者协调在一起来消费订阅主题的所有分区 每个分区只能由同一个消费者组内的一个Consumer实例来消费,Consumer实例对分区有所有权 消息引擎模型 两种模型:点对点模型(消息队列)、发布订阅模型 点对点模型(传统的消息队列模型) 缺陷/特性:消息一旦被消费、就会从队列中被删除,而且只能被下游的一个Consumer消费 伸缩性很差,下游的多个Consumer需要抢占共享消息队列中的消息 发布订阅模型 缺陷:伸缩性不高,每个订阅者都必须订阅主题的所有分区(全量订阅) Consumer Group 当Consumer Group订阅了多个主题之后 组内的每个Consumer实例不要求一定要订阅主题的所有分区,只会消费部分分区的消息 Consumer Group之间彼此独立,互不影响,它们能够订阅相同主题而互不干涉 Kafka使用Consumer Group...
2019-03-31
Kafka -- 可靠性
可靠性保证 可靠性保证:确保系统在各种不同的环境下能够发生一致的行为 Kafka的保证 保证_分区消息的顺序_ 如果使用同一个生产者往同一个分区写入消息,而且消息B在消息A之后写入 那么Kafka可以保证消息B的偏移量比消息A的偏移量大,而且消费者会先读取消息A再读取消息B 只有当消息被写入分区的所有同步副本时(文件系统缓存),它才被认为是已提交 生产者可以选择接收不同类型的确认,控制参数acks 只要还有一个副本是活跃的,那么已提交的消息就不会丢失 消费者只能读取已经提交的消息 复制 Kafka可靠性保证的核心:_复制机制_ + 分区的多副本架构 把消息写入多个副本,可以使Kafka在发生崩溃时仍能保证消息的持久性 Kafka的主题被分成多个分区,分区是基本的数据块,分区存储在单个磁盘上 Kafka可以保证分区里的事件总是有序的,分区可以在线(可用),也可以离线(不可用) 每个分区可以有多个副本,其中一个副本是首领副本 所有的事件都直接发送给首领副本,或者直接从首领副本读取事件 其他副本只需要与首领副本保持同步,并及时复制最新的事件即可 当首领副本不可用时,其中一个同步副本将成为新的...




