Kafka -- 消费者
基本概念
消费者 + 消费者群组
- 消费者从属于消费者群组
- 一个消费者群组里的消费者订阅的是同一个主题,每个消费者接收主题的部分分区的消息
消费者横向扩展
1个消费者

- 主题T1有4个分区,然后创建消费者C1,C1是消费者群组G1里唯一的消费者,C1订阅T1
- 消费者C1将接收主题T1的全部4个分区的消息
2个消费者
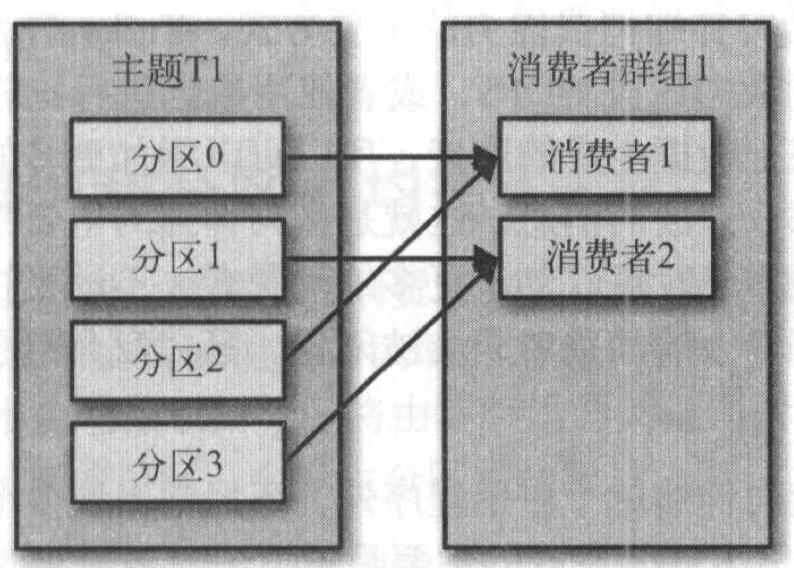
- 如果群组G1新增一个消费者C2,那么每个消费者将分别从两个分区接收消息
- 假设C1接收分区0和分区2的消息,C2接收分区1和分区3的消息
4个消费者
 如果群组G1有4个消费者,那么每个消费者可以分配到一个分区
如果群组G1有4个消费者,那么每个消费者可以分配到一个分区
5个消费者
 如果群组G1有5个消费者,_**消费者数量超过主题的分区数量**_,那么有1个消费者就会被**闲置**,不会接收到任何消息
如果群组G1有5个消费者,_**消费者数量超过主题的分区数量**_,那么有1个消费者就会被**闲置**,不会接收到任何消息
总结
- 往群组里增加消费者是横向伸缩消费能力的主要方式
- 消费者经常会做一些高延迟的操作,比如把数据写到数据库或HDFS,或者使用数据进行比较耗时的计算
- 有必要为主题创建大量的分区,在负载增长时可以加入更多的消费者,减少消息堆积
- 不要让消费者的数量超过主题分区的数量,多余的消费者只会被闲置
消费者群组横向扩展
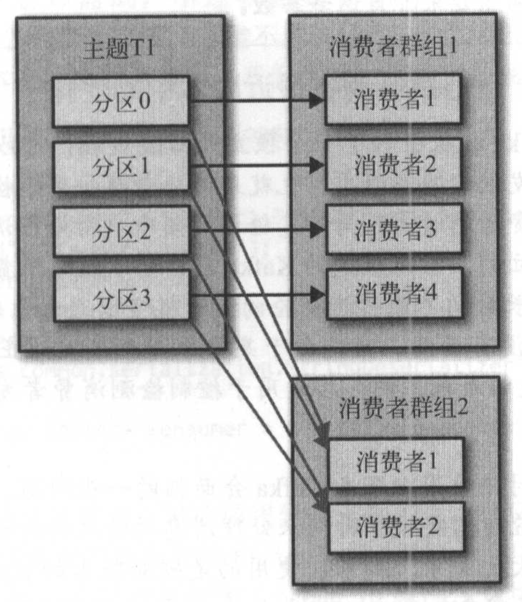
- Kafka设计的主要目标之一,就是要让Kafka主题里的数据能够满足企业各种应用场景(不同的消费者群组)的需求
- 在这些场景里,每个应用程序可以获取到所有的消息,而不只是其中的一部分
- 只要保证每个应用程序有自己的消费者群组,就可以让它们获取到主题所有的消息
- 不同于传统的消息系统,_横向伸缩Kafka消费者和消费者群组并不会对性能造成负面影响_
消费者群组 + 分区再均衡
分区再均衡
- 分区再均衡:_分区的所有权从一个消费者转移到另一个消费者_
- 分区再均衡非常重要,它为消费者群组带来了高可用性和伸缩性(可以放心地添加或移除消费者)
- 在分区再均衡期间,_消费者无法读取消息_,造成整个群组在一小段时间内不可用
- 当分区被重新分配给另一个消费者时,消费者当前的读取状态会丢失
- 它有可能需要去刷新缓存,在它重新恢复状态之前会拖慢应用程序
心跳
- 消费者通过向被指派为群组协调器的Broker发送心跳
- 目的
- 维持它们_和群组的从属关系_
- 维持它们_对分区的所有权关系_
- 不同的群组可以有不同的协调器
- 目的
- 只要消费者以正常的时间间隔发送心跳,就被认为是活跃的,说明它还在读取分区里的消息
- 消费者发送心跳的时机
- 轮询消息(为了获取消息)
- 提交偏移量
- 如果消费者停止发送心跳的时间足够长,会话就会过期,群组协调器认为它已经死亡,就会触发一次再均衡
- 如果一个消费者发生崩溃,并停止读取消息,群组协调器会等待几秒钟,确认它死亡了才会触发再均衡
- 在这几秒的时间内,死掉的消费者不会读取分区里的消息
- 在清理消费者时,消费者会通知群组协调器它将要离开群组,群组协调器会立即触发一次再均衡,尽量降低处理停顿
分配分区
- 当消费者要加入消费者群组时,它会向群组协调器发送一个
JoinGroup的请求,第一个加入群组的消费者将成为群主 - 群主(消费者)从群组协调器(Broker)那里获得成员列表(消费者)
- 列表中包含了最近发送过心跳的消费者,它们被认为是活跃的
- 群主负责给每个成员(消费者)分配分区
- 实现
PartitionAssignor接口的类来决定哪些分区应该被分配给哪个消费者
- 群主(消费者)分配分区完毕后,把分区的分配情况发送给群组协调器(Broker)
- 群组协调器(Broker)再把这些信息发送给所有的消费者
- 每个消费者只能看到自己的分配信息,只有群主知道消费者群组里所有消费者的分配信息
- 这个过程会在每次再均衡时重复发生
创建消费者
1 | Properties properties = new Properties(); |
订阅主题
1 | // 订阅主题 |
轮询
- 消息轮询是消费者API的核心,通过一个简单的轮询向服务器请求数据
- 一旦消费者订阅了主题,轮询就会处理所有的细节
- 群组协调、分区再均衡、发送心跳、获取数据
- 线程安全
- 在同一个群组里,无法让一个线程运行多个消费者,也无法让多个线程安全地共享一个消费者
- 按照规则,_一个消费者使用一个线程_
1 | try { |
消费者的配置
fetch.min.bytes
- 该参数指定了消费者单个数据请求的最小字节数,默认值为
1 - Broker在收到消费者的数据请求时
- 如果可用的数据量小于
fetch.min.bytes指定的大小,那么它会等到有足够的可用数据时才会返回给消费者 - 这样可以降低消费者和Broker的工作负载,因为在主题不是很活跃的时候,就不需要来回处理消息
- 如果可用的数据量小于
fetch.max.wait.ms
- 如果
fetch.max.wait.ms(默认值为500)被设为100ms,并且fetch.min.bytes被设为1MB - 那么Kafka在收到消费者的请求后,要么返回1MB数据,要么在100ms后返回所有可用的数据,看哪个条件先得到满足
max.partition.fetch.bytes
- 该参数指定了服务器从每个分区里返回给消费者的最大字节数,默认1MB
Consumer.poll()方法从每个分区里返回的数据不能超过max.partition.fetch.bytes- 如果单次
poll()返回的数据太多,消费者需要更多时间来处理- 可能无法及时地进行下一次轮询(发送心跳)来避免会话过期,触发再平衡
- 减少
max.partition.fetch.bytes的值 - 或者延长会话过期时间
- 如果主题有20个分区和5个消费者,那么每个消费者需要至少4MB的可用内存来接收记录
- 在为消费者分配内存时,可以适当地多分配些
- 因为如果消费者群组里有消费者发生崩溃,剩下的消费者需要处理更多的分区
max.partition.fetch.bytes必须比message.max.bytes(Broker能够接收到最大消息的字节数)大- 否着消费者可能无法读取这些大消息,导致消费者一直挂起重试
session.timeout.ms + heartbeat.interval.ms
session.timeout.ms指定了消费者在被认为死亡之前可以与服务器断开连接的时间,默认值为10000- 如果消费者没有在
session.timeout.ms指定的时间内发送心跳给在群组协调器(Broker) - 就会被认为已经死亡,群组协调器就会触发再均衡
- 如果消费者没有在
heartbeat.interval.ms指定了poll()方法向群组协调器发送心跳的频率,默认值为3000- 而
session.timeout.ms指定了消费者可以多久不发心跳
- 而
heartbeat.interval.ms必须比session.timeout.ms小,一般是session.timeout.ms的1/3- 如果把
session.timeout.ms值设置得比默认值小,可以更快地检测和恢复崩溃的节点- 不过长时间的轮询或者GC可能会导致非预期的再均衡
- 如果把
session.timeout.ms值设置得比默认值大,可以减少意外的再均衡- 不过检测节点崩溃需要更长的时间
auto.offset.reset
- 该参数指定了消费者在下列情况下该如何处理
- 读取一个没有偏移量的分区(新加入消费者,还没有该消费者的消费记录)
- 偏移量无效(消费者长时间失效,包含偏移量的记录已经过时并被删除)
- 默认值是latest:消费者从最新的记录开始读取数据
- earliest:消费者从起始位置读取分区的记录
enable.auto.commit + auto.commit.interval.ms
enable.auto.commit指定了消费者是否自动提交偏移量,默认值是true- 可能出现重复数据和数据丢失
auto.commit.interval.ms指定提交的频率,默认值为5000
partition.assignment.strategy
- 分区会被分配给消费群组里的消费者的策略
Range:把主题的若干连续的分区分配给消费者,默认值RoundRobin:把主题的所有分区逐个分配给消费者
client.id
- 任意字符串,Broker用它来标识从客户端发过来的消息
- 通常被用在日志、度量指标和配额里
max.poll.records
- 该参数用于控制单次调用
poll()方法能够返回的消息数量,默认值为500
receive.buffer.bytes + send.buffer.bytes
- 设置socket在读写数据时用到的TCP缓冲区
- 如果为**-1,就使用操作系统的默认值**
receive.buffer.bytes的默认值为32KBsend.buffer.bytes的默认值为128KB
- 如果生产者或消费者与Broker处于不同的数据中心内,可以适当增大这些值
提交 + 偏移量
- 每次调用
poll()方法,总是返回由生产者写入Kafka但还没有被消费者读取过的记录 - Kakfa不像其它JMS队列那样,_Kafka不需要得到消费者的确认_
- 消费者可以使用Kafka来追踪消息在分区里的位置(偏移量)
- 把更新分区当前位置的操作叫作提交
- 消费者往一个叫作
__consumer_offsets的特殊主题发送消息,消息里包含_每个分区的偏移量_ - 如果消费者发生崩溃或者有新的消费者加入群组,就会触发再均衡
- 完成再均衡之后,每个消费者可能分配到新的分区
- 为了能继续之前的工作,消费者需要读取每个分区最后一次提交的偏移量,然后从偏移量指定的位置继续处理
- 消费者往一个叫作
- 偏移量不相同
- 如果提交的偏移量 小于 客户端处理的最后一个消息的偏移量
- 那么处于两个偏移量之间的消息就会被_重复处理_
- 如果提交的偏移量 大于 客户端处理的最后一个消息的偏移量
- 那么处于两个偏移量之间的消息就会_丢失_
- 如果提交的偏移量 小于 客户端处理的最后一个消息的偏移量
自动提交
- 自动提交是基于时间间隔
- 如果
enable.auto.commit为true,那么每过auto.commit.interval.ms(默认5s)- 消费者就会自动把从
poll()方法接收到的最大偏移量提交上去,_不论客户端是否真的处理完_
- 消费者就会自动把从
- 自动提交也是在轮询里进行,消费者每次轮询时会检查是否该提交偏移量
- 如果是,那就会提交
poll()返回的最大偏移量
- 如果是,那就会提交
问题
- 消息重复处理
- 假设时刻
T自动提交,在时刻T+3发生了再均衡,还没到时刻T+5- 客户端已经处理的部分消息没有被提交
- 再均衡之后,消费者还是会从最后一次提交的偏移量位置(时刻
T)开始读取消息,消息会被重复处理
- 假设时刻
- 消息丢失
- 假设时刻
T自动提交,执行poll()拉回100条消息,在时刻T+5会再次提交 - 但在时刻
T+5,客户端只处理完了90条消息,在自动提交完成之后的那一刻该客户端崩溃,消息丢失
- 假设时刻
- 每次调用轮询方法都会把上一次调用
poll()返回的最大偏移量提交上去,_并不关心哪些消息已经被处理过了_- 所以在再次调用轮询之前最好确保所有应该处理的消息都已经处理完毕
同步提交
enable.auto.commit=false,让应用程序决定何时提交偏移量- 使用
commitAsync()提交偏移量最简单也最可靠- 提交由
poll()方法返回的最大偏移量,提交成功后立马返回,如果提交失败就会抛出异常
- 提交由
- 如果发生再均衡,消息会被_重复处理_
1 | consumer.subscribe(Collections.singletonList(TOPIC)); |
异步提交
- 同步提交,在Broker对提交请求作出响应之前,应用程序会一直阻塞,_限制应用程序的吞吐量_
- 可以通过降低提交频率来提升吞吐量,但如果发生再均衡,会增加重复消息的数量
- 在成功提交或碰到无法恢复的错误之前,
commitSync()会一直重试,但是commitAsync()不会- 不进行重试的原因:_在它收到服务器响应的时候,可能有一个更大的偏移量已经提交成功_
commitAsync()支持回调,在Broker作出响应时会执行回调(通常用于记录提交错误或生成度量指标)- 如果用回调来进行重试,一定要注意_提交的顺序_
- 使用一个单调递增的序列号来维护异步提交的顺序
- 在每次提交偏移量之后或者在回调里提交偏移量时递增序列号
- 在进行重试前,先检查回调的序列号和即将提交的偏移量是否相等
- 如果相等,说明没有新的提交,那么可以安全地进行重试
- 如果回调序列号比较大,说明有一个新的提交已经发送出去了,应该停止重试
1 | consumer.subscribe(Collections.singletonList(TOPIC)); |
组合提交(同步+异步)
- 一般情况下,偶尔出现的提交失败,不进行重试不会有太大问题
- 如果这是发生在关闭消费者或者再均衡前的最后一次提交,那么就要_确保能够提交成功_
1 | consumer.subscribe(Collections.singletonList(TOPIC)); |
提交特定的偏移量
- 提交偏移量的频率和处理消息批次的频率是一样的
commitSync()和commitAsync(),只会提交最后一个偏移,而此时该批次里的部分消息可能还没处理- 如果需要提交特定的偏移量,需要跟踪所有分区的偏移量
1 | consumer.subscribe(Collections.singletonList(TOPIC)); |
再均衡监听器
- 消费者在退出消费者群组和进行分区再均衡之前,会做一些清理工作
- 在消费者失去对一个分区的所有权之前提交最后一个已处理记录的偏移量
- 如果消费者准备了一个缓冲区用于处理偶发的事件,那么在失去分区所有权之前,需要处理在缓冲区累积下来的记录
- 关闭文件句柄,数据库连接
- 在为消费者分配新分区或者移除旧分区时,可以通过消费者API执行一些动作
- 在调用
subscribe()方法传进去一个ConsumerRebalanceListener实例 onPartitionsRevoked- 在消费者停止读取消息之后和再均衡开始之前被调用
- 如果在这里提交偏移量,下一个接管分区的消费者就知道该从哪里开始读取
onPartitionsAssigned- 在重新分配分区之后和消费者开始读取之前被调用
- 在调用
1 | Map<TopicPartition, OffsetAndMetadata> currentOffsets = Maps.newHashMap(); |
从特定偏移量开始处理记录
1 | // org.apache.kafka.clients.consumer.Consumer |
1 | private void commitDbTransaction() { |
退出
1 | // ShutdownHook运行在单独的线程里,所以退出循环最安全的方式是调用wakeup() |
反序列化器
- 对于开发者而言
- 必须明确写入主题的消息使用的是哪一种序列化器
- 并确保每个主题里只包含能够被反序列化器解析的数据
自定义序列化器
- 不推荐使用自定义序列化器和自定义反序列化器,它们把生产者和消费者耦合在一起,很脆弱,容易出错
- 推荐使用标准的消息格式,如
JSON、Thrift、Protobuf和Avro
1 | Properties props = new Properties(); |
1 |
|
独立消费者
- 场景
- 只需要一个消费者从一个主题的所有分区或者某个特定分区读取数据
- 此时不再需要消费者群组和再均衡
- 只需要把主题或者分区分配给消费者,然后开始读取消息并提交偏移量
- 这时不再需要订阅主题,取而代之的是消费者为自己分配分区
- 一个消费者可以订阅主题(并加入消费者群组),或者为自己分配分区,但这两个动作是互斥的
1 | // 向集群请求主题可用的分区,如果只读取特定分区,跳过这一步 |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-06-25
Kafka -- 分布式流处理平台
历史消息引擎系统 Kafka在刚诞生时是以消息引擎系统的面目出现在大众视野中 Kafka在0.10.0.0之前的定位:分布式、分区化且带备份功能的提交日志(Commit Log)服务 Kafka在设计之初的功能特性 提供一套API实现生产者和消费者 降低网络传输和磁盘存储开销 实现高伸缩架构 分布式流处理平台 Kafka于2011年正式进入Apache基金会孵化并于次年10月成为Apache顶级项目 Kafka社区于0.10.0.0版本正式推出流处理组件Kafka Streams,定位变成了分布式流处理平台 同等级的实时流处理平台:Apache Kafka、Apache Storm、Apache Spark、Apache Flink 目前国内对Kafka是流处理平台的认知还不普及,其核心的流处理组件Kafka Streams更是少有大厂在使用 优势端到端的正确性 Kafka更容易实现端到端的正确性(Correctness) 流处理要替代批处理需要具备两个核心优势 实现正确性(正确性是流处理能够匹敌批处理的基石) 提供能够推导时间的工具 正确性一直都是批处理的强项,而实现正确性的基石是要求...

2019-03-26
Kafka -- Docker + Schema Registry
Avro Avro的数据文件里包含了整个Schema 如果每条Kafka记录都嵌入了Schema,会让记录的大小成倍地增加 在读取记录时,仍然需要读到整个Schema,所以需要先找到Schema 可以采用通用的结构模式并使用Schema注册表的方案 开源的Schema注册表实现:Confluent Schema Registry Confluent Schema Registry 把所有写入数据需要用到的Schema保存在注册表里,然后在_记录里引用Schema ID_ 负责读数据的应用程序使用Schema ID从注册表拉取Schema来反序列化记录 序列化器和反序列化器分别负责处理Schema的注册和拉取 Confluent Schema Registry1234567891011121314151617181920# Start Zookeeper and expose port 2181 for use by the host machine$ docker run -d --name zookeeper -p 2181:2181 confluent/zookeeper# Star...

2019-09-28
Kafka -- KafkaAdminClient
背景 命令行脚本只能运行在控制台上,在应用程序、运维框架或者监控平台中集成它们,会非常困难 很多命令行脚本都是通过连接ZK来提供服务的,这会存在潜在的问题,即绕过Kafka的安全设置 运行这些命令行脚本需要使用Kafka内部的类实现,也就是Kafka服务端的代码 社区是希望用户使用Kafka客户端代码,通过现有的请求机制来运维管理集群 基于上述原因,社区于0.11版本正式推出Java客户端版的KafkaAdminClient 功能 主题管理 主题的创建、删除、查询 权限管理 具体权限的配置和删除 配置参数管理 Kafka各种资源(Broker、主题、用户、Client-Id等)的参数设置、查询 副本日志管理 副本底层日志路径的变更和详情查询 分区管理 创建额外的主题分区 消息删除 删除指定位移之前的分区消息 Delegation Token管理 Delegation Token的创建、更新、过期、查询 消费者组管理 消费者组的查询、位移查询和删除 Preferred领导者选举 推选指定主题分区的Preferred Broker为领导者 工作原理 Kaf...

2019-09-23
Kafka -- 主题管理
日常管理创建主题1$ kafka-topics --bootstrap-server localhost:9092 --create --topic t1 --partitions 1 --replication-factor 1 从Kafka 2.2版本开始,推荐使用--bootstrap-server代替--zookeeper(标记为已过期) 原因 使用--zookeeper会绕过Kafka的安全体系,不受认证体系的约束 使用--bootstrap-server与集群交互是未来的趋势 查询主题列表12345$ kafka-topics --bootstrap-server localhost:9092 --list__consumer_offsets_schemast1transaction 查询单个主题1234567$ kafka-topics --bootstrap-server localhost:9092 --describe --topic __consumer_offsetsTopic:__consumer_offsets PartitionCount:50 Repl...
2018-10-16
Kafka -- Avro + Kafka Native API
Schema123456789101112131415{ "namespace": "me.zhongmingmao.avro", "type": "record", "name": "Stock", "fields": [ {"name": "stockCode", "type": "string"}, {"name": "stockName", "type": "string"}, {"name": "tradeTime", "type": "long"}, {&qu...

2019-09-20
Kafka -- 高水位 + Leader Epoch
高水位水位的定义 经典教科书 在时刻T,任意创建时间(Event Time)为T',且T'<=T的所有事件都已经到达,那么T就被定义为水位 《Streaming System》 水位是一个单调增加且表征最早未完成工作的时间戳 上图中标注为Completed的蓝色部分代表已经完成的工作,标注为In-Flight的红色部分代表正在进行中的工作 两者的边界就是水位线 在Kafka中,水位不是时间戳,而是与位置信息绑定的,即用消息位移来表征水位 Kafka中也有低水位(Low Watermark),是与Kafka删除消息相关联的概念 高水位的作用 两个作用 定义消息可见性,即用来标识分区下的哪些消息可以被消费者消费的 帮助Kafka完成副本同步 上图是某个分区Leader副本的高水位图,在分区高水位以下的消息被认为是已提交消息,反之为未提交消息 消费者只能消费已提交消息,即位移小于8的所有消息 暂不讨论Kafka事务,Kafka的事务机制会影响消费者所能看到的消息的范围,不只是简单依赖高水位来判断 而是依靠LSO(Log Stable Offset)的位移...