MySQL -- redolog + binlog
更新语句
1 | mysql> CREATE TABLE T (id INT PRIMARY KEY, c INT); |
执行过程
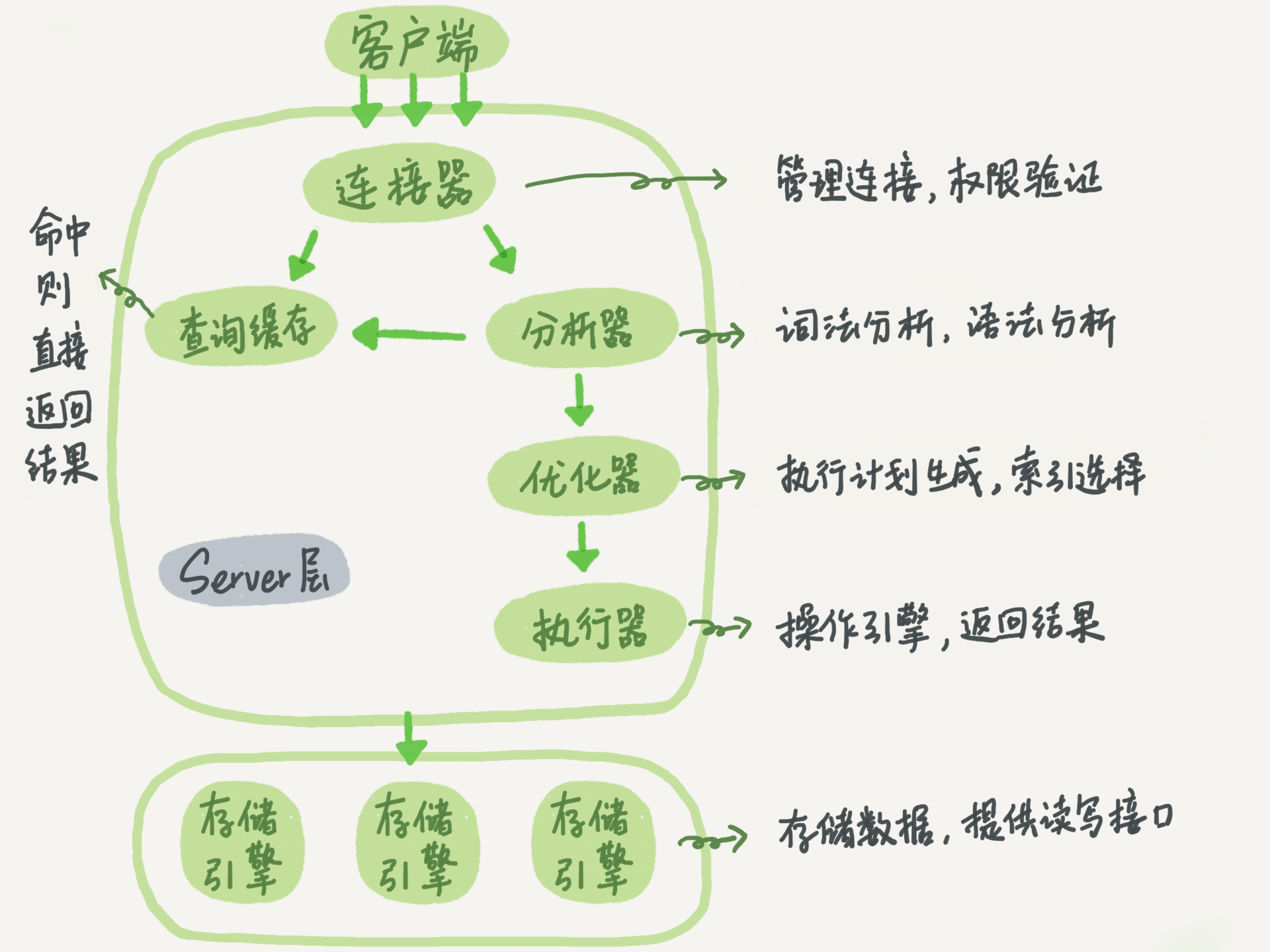
- 通过连接器,客户端与MySQL建立连接
- update语句会把T表上的所有查询缓存清空
- 分析器会通过词法分析和语法分析识别这是一条更新语句
- 优化器会决定使用id这个索引(聚簇索引)
- 执行器负责具体执行,找到匹配的一行,然后更新
- 更新过程中还会涉及redolog(重做日志)和binlog(归档日志)的操作
redolog – InnoDB
- 如果每次更新操作都需要直接写入磁盘(在磁盘中找到相关的记录并更新),整个过程的IO成本和查找成本都很高
- 针对这种情况,MySQL采用的是WAL技术(Write-Ahead Logging):_先写日志,再写磁盘_
- 当有一条记录需要更新的时候,InnoDB会先把记录写到redolog(redolog buffer),并更新内存(buffer pool)
- InnoDB会在适当的时候(例如系统空闲),将这个操作记录到磁盘里面(刷脏页)
- InnoDB的redolog是固定大小的,如果每个日志文件大小为1GB,4个日志文件为一组
- redolog的总大小为4GB,_循环写_
- write pos是当前记录的位置,一边写一边后移,写到3号文件末尾后就回到0号文件开头
- redolog是顺序写,数据文件是随机写
- checkpoint是当前要擦除的位置,擦除记录前需要先把对应的数据落盘(更新内存页,等待刷脏页)
- write pos到checkpoint之间的部分可以用来记录新的操作
- 如果write pos赶上了checkpoint,说明redolog已满,不能再执行新的更新操作,需要先推进checkpoint
- 只要write pos未赶上checkpoint,就可以执行新的更新操作
- checkpoint到write pos之间的部分等待落盘(先更新内存页,然后等待刷脏页)
- 如果checkpoint赶上了write pos,说明redolog已空
- 有了redolog之后,InnoDB能保证数据库即使发生异常重启,之前提交的记录都不会丢失,达到crash-safe
- 如果redolog太小,会导致很快被写满,然后就不得不强行刷redolog,这样WAL机制的能力就无法发挥出来
- 如果磁盘能达到几TB,那么可以将redolog设置4个一组,每个日志文件大小为1GB

1 | # innodb_log_file_size -> 单个redolog文件的大小 |
1 | # 这里的written是指写到磁盘缓存 |
innodb_flush_log_at_trx_commit
数据落盘
- redolog并没有记录数据页的完整记录,只是记录数据页的变更,因此redolog本身并没有直接更新磁盘页的能力
- MySQL实例正常运行,在内存中的数据页被修改后,跟磁盘上的数据页不一致,称为脏页
- 最终的数据落盘,指的是把内存中的数据页覆盖磁盘上的数据页,这个过程与redolog无关
- 在崩溃恢复的场景,InnoDB如果判断是下面的
2.a场景- 就会读取磁盘上对应的数据页到内存中,然后应用redolog,更新内存页
- 更新完成后,这个内存页就变成了脏页,等待被刷到磁盘上
redolog buffer
1 | BEGIN; |
- redolog buffer用于存放redolog
- 执行完第一个
INSERT后,内存中(buffer pool)的数据页被修改了,另外redolog buffer也写入了日志 COMMIT:真正把日志写到redolog(ib_logfileX)- 自动开启事务的SQL语句隐式包含上述过程
binlog – Server
- redolog是InnoDB特有的日志,binlog属于Server层日志
- 有两份日志的历史原因
- 一开始并没有InnoDB,采用的是MyISAM,但MyISAM没有crash-safe的能力,binlog日志只能用于归档
- InnoDB是以插件的形式引入MySQL的,为了实现crash-safe,InnoDB采用了redolog的方案
- binlog一开始的设计就是不支持崩溃恢复(原库)的,如果不考虑搭建从库等操作,binlog是可以关闭的(sql_log_bin)
- redolog vs binlog
- redolog是InnoDB特有的,binlog是MySQL的Server层实现的,所有层都可以使用
- redolog是物理日志,记录某个数据页上做了什么修改
- binlog是逻辑日志,记录某个语句的原始逻辑
- 逻辑日志:提供给别的引擎用,是大家都能理解的逻辑,例如搭建从库
- 物理日志:只能内部使用,其他引擎无法共享内部的物理格式
- redolog是循环写,空间固定,不能持久保存,没有归档功能
- binlog是追加写,空间不受限制,有归档功能
- redolog主要用于crash-safe,原库恢复
- binlog主要用于恢复成临时库(从库)
- 崩溃恢复的过程不写binlog(可能需要读binlog,如果binlog有打开,一般都会打开)
- 用binlog恢复实例(从库),需要写redolog
- redolog支持事务的持久性,undolog支持事务的隔离性
- redolog对应用开发来说是透明的
- binlog有两种模式
- statement格式:SQL语句
- row格式:行内容(记两条,更新前和更新后),推荐
- 日志一样的可以用于重放
1 | mysql> SHOW VARIABLES LIKE '%sql_log_bin%'; |
update 内部流程
浅色框在InnoDB内部执行,深色框在执行器中执行
- 执行器先通过InnoDB获取id=2这一行,id是主键,InnoDB可以通过聚簇索引找到这一行
- 如果id=2这一行所在的数据页本来就在内存(InnoDB Buffer Pool)中,直接返回给执行器
- 否则先从磁盘读入内存,然后再返回
- 执行器拿到InnoDB返回的行数据,进行**+1**操作,得到新的一行数据,再调用InnoDB的引擎接口写入这行数据
- InnoDB首先将这行新数据更新到内存(InnoDB Buffer Pool)中,同时将这个更新操作记录到redolog(物理记录)
- 更新到内存中,在事务提交后,后续的查询就可以直接在内存中读取该数据页,但此时的数据可能还没有真正落盘
- 但在事务提交前,其他事务是无法看到这个内存修改的
- 而在事务提交后,说明已经成功写入了redolog,可崩溃恢复,不会丢数据,因此可以直接读内存的数据
- 刚更新的内存是不会删除的,除非内存不够用,在数据从内存删除之前,系统会保证它们已经落盘
- 此时redolog处于prepare状态(prepare标签),然后告诉执行器执行完成,随时可以提交事务
- 对其他事务来说,刚刚修改的内存是不可见的
- 更新到内存中,在事务提交后,后续的查询就可以直接在内存中读取该数据页,但此时的数据可能还没有真正落盘
- 执行器生成这个操作的binlog(逻辑记录)并写入磁盘
- binlog写成功事务就算成功,可以提交事务
- 哪怕崩溃恢复,也会恢复binlog写成功的事务(此时对应的redolog处于prepare状态)
- binlog如果没写成功就回滚,回滚会写redolog,打上rollback标签,binlog则会直接丢弃
- 如果binlog不丢弃,则会传播到从库
- binlog写成功事务就算成功,可以提交事务
- 执行器调用InnoDB的提交事务接口,InnoDB把刚刚写入的redolog改成commit状态,更新完成
- redolog打上了commit标签
- commit表示两个日志都生效了
- commit完成后才会返回客户端
1 | # 0 -> Disables synchronization of the binary log to disk by the MySQL server |
1 | # 归纳 |
redolog的两阶段提交
- 目的:为了让redolog和binlog的逻辑一致
- 脑洞:假设不采用两阶段提交
- 有两种顺序:redolog->binlog,或者binlog->redolog
- 此时可以认为redolog和binlog完全独立
- 崩溃恢复完全依赖于redolog(原库),恢复临时库完全依赖于binlog
- 按照上面的两种顺序,都会导致redolog和binlog逻辑上的不一致
- 假设原库crash后执行原库恢复+执行临时库恢复,恢复出来的数据是不一致的(主从不一致)
- 恢复清醒:两阶段提交(假设是双1的配置)
- redolog prepare + binlog成功,提交事务,崩溃恢复后也会继续提交事务(redolog commit),逻辑一致
- redolog prepare + binlog失败,回滚事务,崩溃恢复后也会继续回滚事务(redolog rollback),逻辑一致
- 一个事务的binlog是有固定格式的
- redolog与binlog是通过事务id(XID)进行关联的
- 此时binglog中没有对应的记录,事务记录是不完整的
- 崩溃恢复后是会从checkpoint开始往后主动刷数据
- 采用非双1的配置,在极端环境下会出现redolog与binlog不一致的情况
- 优先保证redolog,先原库崩溃恢复,再处理从库(原库可以在崩溃恢复后,重新做一次全量备份,重建从库)
redolog->binlog
- 反证:事务的持久性问题
- 对InnoDB而言,redolog有commit标签,代表这个事务不能再回滚
- 假若后续的binlog写失败了,此时数据与binlog是不一致的,主从也不一致
只有binlog
binlog是逻辑日志,没有记录数据页的更新细节,_没有能力恢复数据页_
只有redolog
- 如果仅从崩溃恢复的角度来说,binlog是可以关掉的
- 因为崩溃恢复是redolog的功能
- 此时没有两阶段提交,但系统依然是crash-safe的
- 但线上一般都会打开binlog,binlog有着redolog无法替代的功能
- 首先是归档功能,redolog是循环写,起不到归档的作用
- binlog复制:MySQL高可用的基础
- 主从复制
- 异构系统(如数据分析系统)会消费MySQL的binlog来更新自己的数据
崩溃恢复
判断逻辑
- 如果redolog里面的事务是完整的,即已经有了commit标签,那么直接提交
- 如果redolog里面的事务只有prepare标签,则需要判断事务对应的binlog是否存在并完整
- a. 如果是,则提交事务
- b. 如果否,则回滚事务
redolog与binlog关联
- redolog和binlog有一个共同的数据字段:XID
- 崩溃恢复时,会按顺序扫描redolog
- 如果碰到既有prepare标签又有commit标签的redolog,就直接提交
- 如果碰到只有prepare标签但没有commit标签的redolog,就拿着对应的XID去binlog找对应的事务
- 后续需要校验事务对应的binlog的完整性
binlog的完整性
- binlog格式
- statement格式,最后会有
COMMMIT; - row格式,最后会有一个
XID Event
- statement格式,最后会有
- 从MySQL 5.6.2开始,引入了binlog-checksum,用于验证binlog内容的正确性
- binlog可能由于磁盘原因,在日志中间出错,MySQL可以通过校验checksum来发现
异常重启
时刻A
- 对应上面
2.b的情况 - redolog还未提交,binlog还未写,在崩溃恢复时,事务会回滚
- 由于binlog还没写,也不会传到备库
时刻B
- 对应上面的
2.a的情况,崩溃恢复过程中事务会被提交 - 此时binlog已经写入了,之后会被从库或临时库使用
- 因此主库也需要提交这个事务,保证主从一致
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-03-12
MySQL -- 用户临时表
临时表 VS 内存表 内存表,指的是使用Memory引擎的表,建表语法:CREATE TABLE ... ENGINE=Memory 所有数据都保存在内存中,系统重启时被清空,但表结构还在 临时表,可以使用各种引擎 如果使用的是InnoDB或者MyISAM引擎,数据需要写到磁盘上 当然也可以使用Memory引擎 特征 session A session B CREATE TEMPORARY TABLE t(c int) ENGINE=MyISAM;(创建临时表) SHOW CREATE TABLE t;(Table ‘test.t’ doesn’t exist) CREATE TABLE t(id INT PRIMARY KEY) ENGINE=InnoDB;(创建普通表) SHOW CREATE TABLE t;(显示临时表) SHOW TABLES;(显示普通表) INSERT INTO t VALUES (1); SELECT * FROM t;(返回1) SELECT * FROM t;(Empty set) ...

2019-01-16
MySQL -- 事务隔离
概念 事务:保证一组数据库操作,要么全部成功,要么全部失败 在MySQL中,事务支持是在存储引擎层实现的 MyISAM不支持事务 InnoDB支持事务 隔离性与隔离级别 事务特性:ACID(Atomicity、Consistency、Isolation、Durability) 如果多个事务并发执行时,就可能会出现脏读、不可重复读、幻读(phantom read)等问题 解决方案:隔离级别 隔离级别越高,效率就会越低 SQL标准的事务隔离级别 READ-UNCOMMITTED 一个事务还未提交时,它所做的变更能被别的事务看到 READ-COMMITTED 一个事务提交之后,它所做的变更才会被其他事务看到 REPEATABLE-READ 一个事务在执行过程中所看到的数据,总是跟这个事务在启动时看到的数据是一致的 同样,在RR隔离级别下,未提交的变更对其他事务也是不可见的 SERIALIZABLE 对同一行记录,写会加写锁,读会加读锁,锁级别是行锁 当出现读写锁冲突时,后访问的事务必须等前一个事务执行完成,才能继续执行 默认隔离级别 Oracle:READ-COMMITTED...

2019-03-11
MySQL -- JOIN优化
表初始化1234567891011121314151617181920212223CREATE TABLE t1(id INT PRIMARY KEY, a INT, b INT, INDEX(a));CREATE TABLE t2 LIKE t1;DROP PROCEDURE idata;DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=1; WHILE (i <= 1000) DO INSERT INTO t1 VALUES (i,1001-i,i); SET i=i+1; END WHILE; SET i=1; WHILE (i <= 1000000) DO INSERT INTO t2 VALUES (i,i,i); SET i=i+1; END WHILE;END;;DELIMITER ;CALL idata(); Multi-Range ReadMRR的目的:尽量使用顺序读盘 回表1SELECT * F...

2019-03-08
MySQL -- 全表扫描
Server层12-- db1.t有200GBmysql -h$host -P$port -u$user -p$pwd -e "select * from db1.t" > $target_file 查询数据 InnoDB的数据是保存在主键索引上,全表扫描实际上是直接扫描表t的主键索引 获取一行,写到net_buffer中,默认为16K,控制参数为net_buffer_length 重复获取行,直到写满net_buffer,然后调用网络接口发出去 如果发送成功,就清空net_buffer,然后继续取下一行并写入net_buffer 如果发送函数返回EAGAIN或者WSAEWOULDBLOCK,表示本地网络栈socket send buffer写满 此时,进入等待,直到网络栈重新可写,再继续发送 一个查询在发送数据的过程中,占用MySQL内部的内存最大为net_buffer_length,因此不会达到200G socket send buffer也不可能达到200G,如果socket send buffer被写满,就会暂停读取数据 1234567-- 16384...

2019-01-25
MySQL -- 锁
全局锁 全局锁:对整个数据库实例加锁 加全局读锁:FLUSH TABLES WITH READ LOCK,阻塞其他线程的下列语句 数据更新语句(增删改) 数据定义语句(建表、修改表结构) 更新类事务的提交语句 主动解锁:UNLOCK TABLES 典型使用场景:全库逻辑备份 把整库每个表都SELECT出来,然后存成文本 缺点 如果在主库上执行逻辑备份,备份期间不能执行更新操作,导致业务停摆 如果在备库上执行逻辑备份,备份期间从库不能执行由主库同步过来的binlog,导致主从延时 备份加全局锁的必要性 保证全局视图是逻辑一致的 mysqldump --single-transaction 导数据之前启动一个事务,确保拿到_一致性视图_ 由于MVCC的支持,在这个过程中是可以正常更新数据的 需要存储引擎支持_RR的事务隔离级别_ MyISAM不支持事务,如果备份过程中有更新,总是能取到最新的数据,破坏了备份的一致性 因此MyISAM只能依赖于FLUSH TABLES WITH READ LOCK,不能使用--single-transaction 针对全库逻辑备份的场景,--si...

2019-02-22
MySQL -- 主从复制的基本原理
主从切换 在状态1,客户端的读写都是直接访问节点A,节点B是节点A的从库 只是将节点A的更新都同步过来,在节点B本地执行,保持一致 在状态1,虽然节点B没有被直接访问,但依然建议设置成readonly模式 运营类的查询语句会在从库上执行,设置成readonly模式能够防止一些误操作 防止切换逻辑有Bug,例如出现双写,造成主从不一致 可以通过readonly状态来判断节点的角色 在状态1,节点B设置为readonly模式,同样能与节点A保持同步更新 readonly设置对超级权限用户是无效的,而节点B中用于同步更新的线程,就拥有超级权限 主从同步在节点A执行update语句,然后同步到节点B 从库B与主库A之间维持一个长连接,主库A内部有一个专门用于服务于从库B长连接的线程 在从库B上执行CHANGE MASTER命令,设置主库A的信息 IP、PORT、USER、PASSWORD 从哪个位置(文件名 + 日志偏移量)开始请求binlog 在从库B上执行START SLAVE命令,这时从库B会启动两个线程:io_thread + sql_thread io_thread:负责...