
MySQL -- RR隔离与RC隔离
视图
- 虚拟表 – 本文不关心
- 在调用的时候执行查询语句并生成执行结果
- SQL语句:
CREATE VIEW
- InnoDB在实现MVCC时用到的一致性读视图(consistent read view)
- 用于支持RC和RR隔离级别的实现
- 没有对应的物理结构
- 主要作用:在事务执行期间,事务能看到怎样的数据
快照
- 在RR隔离级别下,事务在启动的时候保存了一个快照,快照是基于整库的
- 在InnoDB,每个事务都有一个唯一的事务ID(transaction id)
- 在事务开始的时候向InnoDB的事务系统申请的,按申请的顺序严格递增
- 每行数据都有多个版本,每次事务更新数据的时候,都会生成一个新的数据版本
- 事务会把自己的transaction id赋值给这个数据版本的事务ID,记为
row trx_id- 每个数据版本都有对应的row trx_id
- 同时也要逻辑保留旧的数据版本,通过新的数据版本和
undolog可以计算出旧的数据版本
- 事务会把自己的transaction id赋值给这个数据版本的事务ID,记为
多版本

- 虚线框是同一行记录的4个版本
- 当前最新版本为V4,k=22,是被
transaction id为25的事务所更新的,因此它的row trx_id为25 - 虚线箭头就是
undolog,而V1、V2和V3并不是物理真实存在的- 每次需要的时候根据当前最新版本与
undolog计算出来的 - 例如当需要V2时,就通过V4依次执行U3和U2算出来的
- 每次需要的时候根据当前最新版本与
创建快照
- RR的定义:在事务启动时,能够看到所有已经提交的事务结果
- 在该事务后续的执行过程中,其他事务的更新对该事务是不可见的
- 在事务启动时,事务只认可在该事务启动之前提交的数据版本
- 在实现上,InnoDB会为每个事务构造一个视图数组,用来保存在这个事务启动的瞬间,所有处于活跃状态的事务ID
- 活跃的定义:启动了但尚未提交
- 低水位与高水位
- 低水位:视图数组里面最小的事务ID
- 高水位:当前系统中已经创建过最大事务ID+1,一般就是当前事务的
transaction id
- 当前事务的一致性读视图的组成部分:视图数组和高水位
- 获取事务的视图数组和高水位在事务系统的锁保护下进行,可以认为是原子操作,期间不能创建事务
- InnoDB利用了数据的Multi-Version的特性,实现快照的秒级创建
- 快照 = 一致性读视图 = 视图数组+高水位
事务启动
BEGIN/START TRANSACTION:事务并未立马启动,在执行到后续的第一个一致性读语句,事务才真正开始START TRANSACTION WITH CONSISTENT SNAPSHOT;:事务立马启动
样例分析
表初始化
1 | # 建表 |
样例1
事务执行流程
事务ABC的执行流程(autocommit=1)
| 事务A | 事务B | 事务C |
|---|---|---|
| START TRANSACTION WITH CONSISTENT SNAPSHOT; | ||
| START TRANSACTION WITH CONSISTENT SNAPSHOT; | ||
| UPDATE t SET k=k+1 WHERE id=1; | ||
| UPDATE t SET k=k+1 WHERE id=1; | ||
| SELECT k FROM t WHERE id=1; | ||
| SELECT k FROM t WHERE id=1; | ||
| COMMIT; | ||
| COMMIT; |
事务A的查询
假设
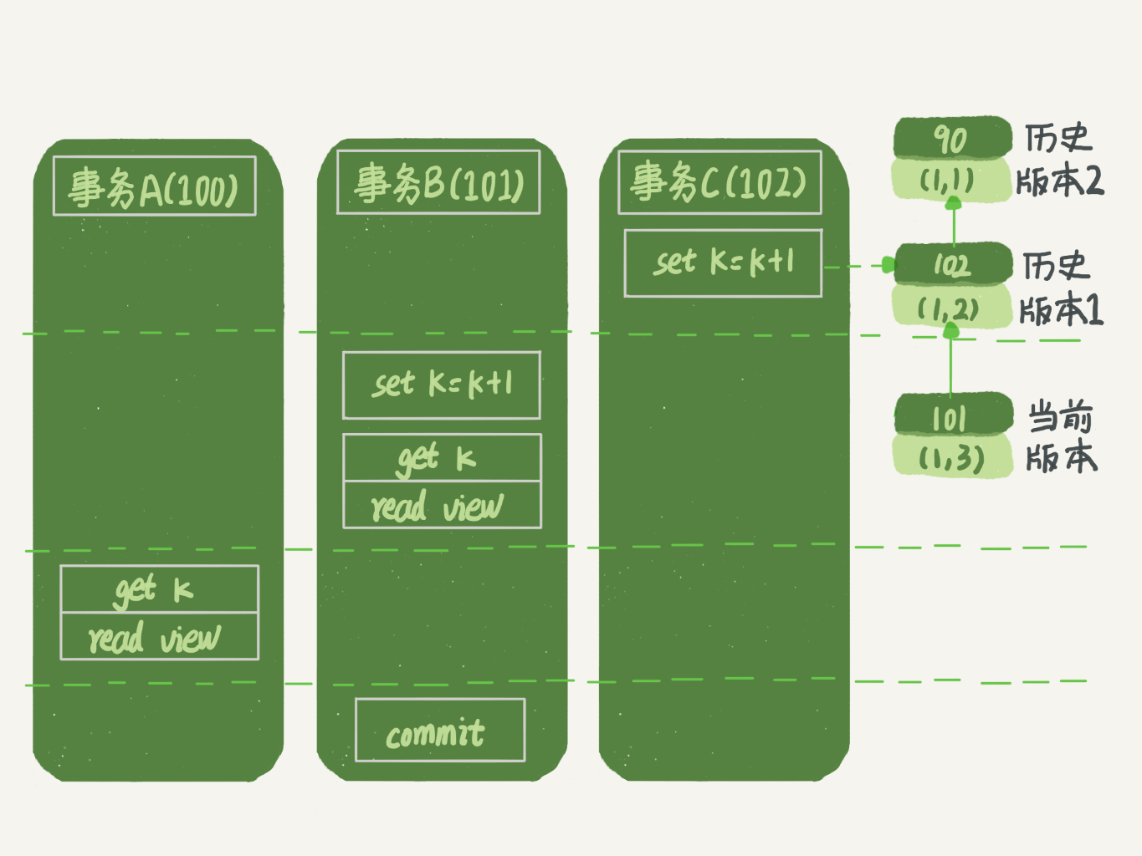
- 事务A开始前,系统里只有一个活跃事务ID是99
- 事务ABC的事务ID分别是100,101和102,且当前系统只有这4个事务
- 事务ABC开始前,
(1,1)这一行数据的row trx_id是90 - 视图数组
- 事务A:
[99,100] - 事务B:
[99,100,101] - 事务C:
[99,100,101,102]
- 事务A:
- 低水位与高水位
- 事务A:
99和100 - 事务B:
99和101 - 事务C:
99和102
- 事务A:
查询逻辑

- 第一个有效更新是事务C,采用当前读,读取当前最新版本
(1,1),改成(1,2)- 此时最新版本的
row trx_id为102,90那个版本成为历史版本 - 由于autocommit=1,事务C在执行完更新后会立马释放id=1的行锁
- 此时最新版本的
- 第二个有效更新是事务B,采用当前读,读取当前最新版本
(1,2),改成(1,3)- 此时最新版本的
row trx_id为101,102那个版本成为历史版本
- 此时最新版本的
- 事务A查询时,由于事务B还未提交,当前最新版本为
(1,3),对事务A是不可见的,否则就了脏读了,读取过程如下- 事务A的视图数组为
[99,100],读数据都是从当前最新版本开始读 - 首先找到当前最新版本
(1,3),判断row trx_id为101,比事务A的视图数组的高水位(100)大,不可见 - 接着寻找上一历史版本,判断
row trx_id为102,同样比事务A的视图数组的高水位(100)大,不可见 - 再往前寻找,找到版本
(1,1),判断row trx_id为90,比事务A的视图数组的低水位(99)小,可见 - 所以事务A的查询结果为1
- 事务A的视图数组为
- 一致性读:事务A不论在什么时候查询,看到的数据都是一致的,哪怕同一行数据同时会被其他事务更新
时间视角
- 一个数据版本,对于一个事务视图来说,除了该事务本身的更新总是可见以外,还有下面3种情况
- 如果版本对应的事务未提交,不可见
- 如果版本对应的事务已提交,但是是在视图创建之后提交的,不可见
- 如果版本对应的事务已提交,并且是在视图创建之前提交的,可见
- 归纳:_一个事务只承认自身更新的数据版本以及视图创建之前已经提交的数据版本_
- 应用规则进行分析
- 事务A的一致性读视图是在事务A启动时生成的,在事务A查询时
- 此时
(1,3)的数据版本尚未提交,不可见 - 此时
(1,2)的数据版本虽然提交了,但是是在事务A的一致性读视图创建之后提交的,不可见 - 此时
(1,1)的数据版本是在事务A的一致性读视图创建之前提交的,可见
更新逻辑

- 如果在事务B执行更新之前查询一次,采用的是一致性读,查询结果也为1
- 如果事务B要执行更新操作,是不能在历史版本上更新
- 否则事务C的更新就会丢失,或者需要采取分支策略来兼容(增加复杂度)
- 因此更新数据需要先进行当前读(current read),再写入数据
- 当前读:总是读取已经提交的最新版本
- 当前读伴随着加锁(更新操作为X Lock模式的当前读)
- 如果当前事务在执行当前读时,其他事务在这之前已经执行了更新操作,但尚未提交(持有行锁),当前事务被阻塞
- 事务B的
SET k=k+1操作是在最新版(1,2)上进行的,更新后生成新的数据版本(1,3),对应的row trx_id为101 - 事务B在进行后续的查询时,发现最新的数据版本为
101,与自己的版本号一致,认可该数据版本,查询结果为3
当前读
1 | # 查询语句 |
样例2
事务执行流程
事务ABC’的执行流程
| 事务A | 事务B | 事务C’ |
|---|---|---|
| START TRANSACTION WITH CONSISTENT SNAPSHOT; | ||
| START TRANSACTION WITH CONSISTENT SNAPSHOT; | ||
| START TRANSACTION WITH CONSISTENT SNAPSHOT; | ||
| UPDATE t SET k=k+1 WHERE id=1; | ||
| UPDATE t SET k=k+1 WHERE id=1; | ||
| SELECT k FROM t WHERE id=1; | ||
| COMMIT; | ||
| SELECT k FROM t WHERE id=1; | ||
| COMMIT; | ||
| COMMIT; |

- 事务C’没有自动提交,依然持有当前最新版本版本
(1,2)上的写锁(X Lock) - 事务B执行更新语句,采用的是当前读(X Lock模式),会被阻塞,必须等事务C’释放这把写锁后,才能继续执行
样例3
1 | # 建表 |
事务执行顺序1
| session A | session B |
|---|---|
| BEGIN; | |
| SELECT * FROM T; | |
| UPDATE t SET c=c+1 | |
| UPDATE t SET c=0 WHERE id=c; | |
| SELECT * FROM T; |
事务执行顺序2
| session A | session B’ |
|---|---|
| BEGIN; | |
| SELECT * FROM T; | |
| BEGIN; | |
| SELECT * FROM T; | |
| UPDATE t SET c=c+1; | |
| COMMIT; | |
| UPDATE t SET c=0 WHERE id=c; | |
| SELECT * FROM T; |
session A视角
1 | mysql> BEGIN; |
RR与RC
RR
- RR的实现核心为一致性读(consistent read)
- 事务更新数据的时候,只能用当前读(current read)
- 如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待
- 在RR隔离级别下,只需要在事务启动时创建一致性读视图,之后事务里的其他查询都共用这个一致性读视图
- 对于RR,查询只承认事务启动前就已经提交的数据
- 表结构不支持RR,只支持当前读
- 因为表结构没有对应的行数据,也没有row trx_id
RC
- 在RC隔离级别下,每个语句执行前都会重新计算出一个新的一致性读视图
- 在RC隔离级别下,再来考虑样例1,事务A与事务B的查询语句的结果
START TRANSACTION WITH CONSISTENT SNAPSHOT的原意:创建一个持续整个事务的一致性视图- 在RC隔离级别下,一致性读视图会被重新计算,等同于普通的
START TRANSACTION
- 在RC隔离级别下,一致性读视图会被重新计算,等同于普通的
- 事务A的查询语句的一致性读视图是在执行这个语句时才创建的
- 数据版本
(1,3)未提交,不可见 - 数据版本
(1,2)提交了,并且在事务A当前的一致性读视图创建之前提交的,可见 - 因此事务A的查询结果为2
- 数据版本
- 事务B的查询结果为3
- 对于RC,查询只承认语句启动前就已经提交的数据
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-02-25
MySQL -- 从库并行复制
主从复制 第一个黑色箭头:客户端写入主库,第二个黑色箭头:从库上sql_thread执行relaylog,前者的并发度大于后者 在主库上,影响并发度的原因是锁,InnoDB支持行锁,对业务并发度的支持还算比较友好 如果在从库上采用单线程(MySQL 5.6之前)更新DATA的话,有可能导致从库应用relaylog不够快,造成主从延迟 多线程模型 coordinator就是原来的sql_thread,但不会再直接应用relaylog后更新DATA,只负责读取relaylog和分发事务 真正更新日志的是worker线程,数量由参数slave_parallel_workers控制 123456mysql> SHOW VARIABLES LIKE '%slave_parallel_workers%';+------------------------+-------+| Variable_name | Value |+------------------------+-------+| slave_parallel_workers | 4 |...

2019-03-15
MySQL -- 自增主键
自增不连续表初始化1234567CREATE TABLE `t` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `c` INT(11) DEFAULT NULL, `d` INT(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`)) ENGINE=InnoDB; 自增值123456789101112131415INSERT INTO t VALUES (null,1,1);-- AUTO_INCREMENT=2,表示下一次插入数据时,如果需要自动生成自增值,会生成id=2mysql> SHOW CREATE TABLE t;+-------+---------------------------------------------+| Table | Create Table |+-------+---------------------------------------------+| t | CREATE T...

2019-03-02
MySQL -- 读写分离
读写分离架构客户端直连 Proxy 对比 客户端直连 少了一层Proxy转发,查询性能稍微好一点 整体架构简单,排查问题方便 需要了解后端部署细节,在出现主从切换、库迁移时,客户端有感知,需要调整数据库连接信息 一般伴随着一个负责管理后端的组件,例如ZooKeeper Proxy – 发展趋势 对客户端友好,客户端不需要关注后端细节,但后端维护成本较高 Proxy也需要高可用架构,带Proxy的整体架构相对复杂 过期读由于主从延迟,主库上执行完一个更新事务后,立马在从库上执行查询,有可能读到刚刚的事务更新之前的状态 解决方案强制走主库 将查询请求做分类 必须要拿到最新结果的请求,强制将其发送到主库上 可以读到旧数据的请求,将其发到从库上 如果完全不能接受过期读,例如金融类业务,相当于放弃读写分离,所有的读写压力都在主库上 SLEEP 主库更新后,读从库之前先SLEEP一下,类似于SELECT SLEEP(1) 基于的假设:大多数主从延时在1秒内 卖家发布商品后,用Ajax直接把客户端输入的内容作为“新的商品”显示在页面上,而非真正的做数据库查询 等卖家再次刷新页面,其...

2019-01-31
MySQL -- flush
脏页 + 干净页 脏页:内存数据页与磁盘数据页内容不一致 干净页:内存数据页与磁盘数据页内容一致 flush:将内存中的脏页写入磁盘 flush – 刷脏页;purge – 清undolog;merge – 应用change buffer flush过程 触发flushredolog写满 当InnoDB的redolog写满,系统会停止所有的更新操作,推进checkpoint 把checkpoint从CP推进到CP’,需要将两点之间的日志(绿色),所对应的所有脏页都flush到磁盘上 然后write pos到CP’之间(红色+绿色)可以再写入redolog 性能影响InnoDB应该尽量避免,此时所有更新都会被堵住,更新数(写性能)跌为0 内存不足 当需要新的内存页,而内存不够用时,就需要淘汰一些内存数据页(LRU) 如果淘汰的是脏页,就需要先将脏页flush到磁盘 该过程不会动redolog,因为redolog在重放的时候 如果一个数据页已经flush过,会识别出来并跳过 性能影响 这种情况是常态,InnoDB使用buffer pool管理内存 buffer pool中内存页有3种状...

2019-03-11
MySQL -- JOIN优化
表初始化1234567891011121314151617181920212223CREATE TABLE t1(id INT PRIMARY KEY, a INT, b INT, INDEX(a));CREATE TABLE t2 LIKE t1;DROP PROCEDURE idata;DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=1; WHILE (i <= 1000) DO INSERT INTO t1 VALUES (i,1001-i,i); SET i=i+1; END WHILE; SET i=1; WHILE (i <= 1000000) DO INSERT INTO t2 VALUES (i,i,i); SET i=i+1; END WHILE;END;;DELIMITER ;CALL idata(); Multi-Range ReadMRR的目的:尽量使用顺序读盘 回表1SELECT * F...

2017-05-06
InnoDB -- 逻辑存储
本文主要介绍InnoDB存储引擎的逻辑存储结构 逻辑存储结构 Tablespace Tablespace是InnoDB存储引擎逻辑存储结构的最高层,所有数据都存放在Tablespace中 分类 System Tablespace Separate Tablespace General Tablespace System Tablespace System Tablespace即我们常见的共享表空间,变量为innodb_data_file_path,一般为ibdata1文件 里面存放着undo logs,change buffer,doublewrite buffer等信息(后续将详细介绍),在没有开启file-per-table的情况下,还会包含所有表的索引和数据信息 没有开启file-per-table时存在的问题 所有的表和索引都会在System Tablespace中,占用空间会越来越大 碎片越来越多(如truncate table时,占用的磁盘空间依旧保留在System Tablespace) 12345678910111213141516171819mysql> ...




