
MySQL -- 普通索引与唯一索引
场景
- 维护一个市民系统,有一个字段为身份证号
- 业务代码能保证不会写入两个重复的身份证号(如果业务无法保证,可以依赖数据库的唯一索引来进行约束)
- 常用SQL查询语句:
SELECT name FROM CUser WHERE id_card = 'XXX' - 建立索引
- 身份证号比较大,不建议设置为主键
- 从性能角度出发,选择普通索引还是唯一索引?
假设字段k上的值都不重复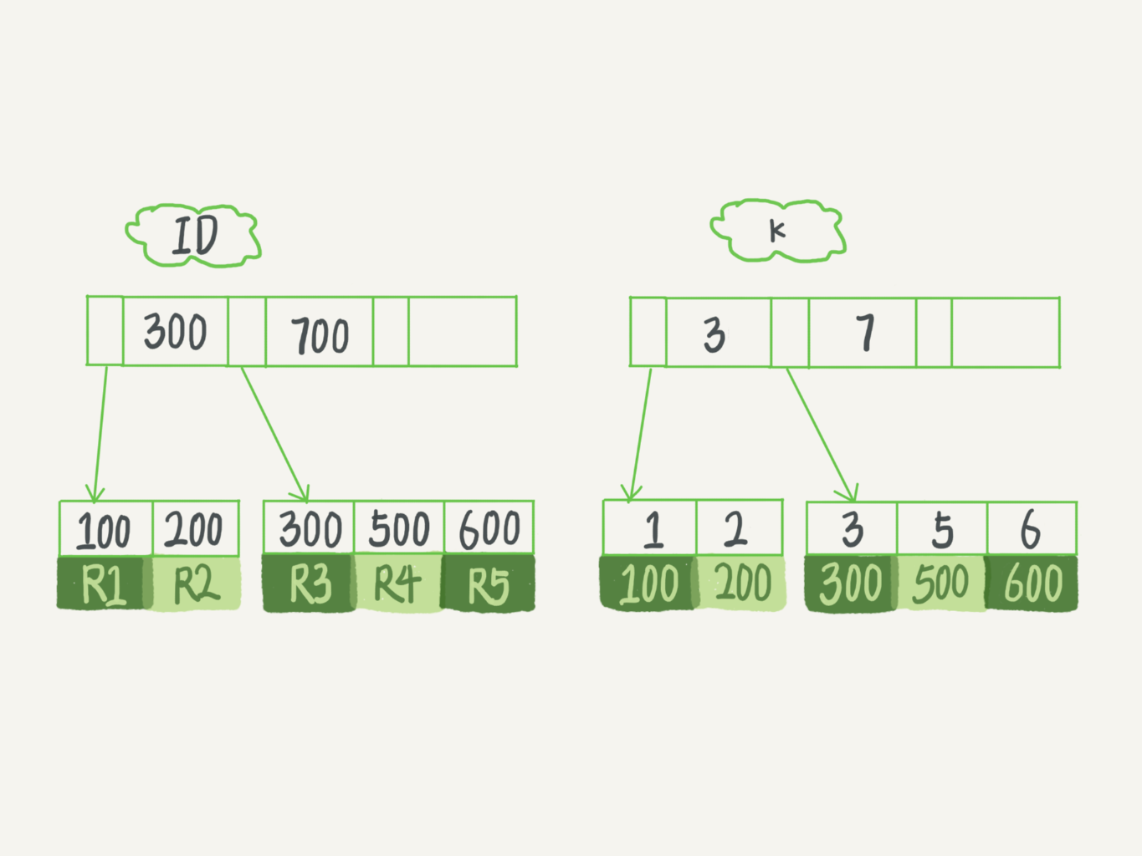
查询过程
- 查询语句:
SELECT id FROM T WHERE k=5 - 查询过程
- 通过B+树从树根开始,按层搜索到叶子节点,即上图中右下角的数据页
- 在数据页内部通过二分法来定位具体的记录
- 针对普通索引
- 查找满足条件的第一个记录
(5,500),然后查找下一个记录,直到找到第一个不满足k=5的记录
- 查找满足条件的第一个记录
- 针对唯一索引
- 由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续查找
性能差异
- 性能差异:微乎其微
- InnoDB的数据是按照数据页为单位进行读写的,默认为16KB
- 当需要读取一条记录时,并不是将这个记录本身从磁盘读出来,而是以数据页为单位进行读取的
- 当找到k=5的记录时,它所在的数据页都已经在内存里了
- 对于普通索引而言,只需要多一次指针寻找和多一次计算 – CPU消耗很低
- 如果k=5这个记录恰好是所在数据页的最后一个记录,那么如果要取下一个记录,就需要读取下一个数据页
- 概率很低:对于整型字段索引,一个数据页(16KB,compact格式)可以存放大概745个值
change buffer
- 当需要更新一个数据页时,如果数据页在内存中就直接更新
- 如果这个数据页不在内存中,在不影响数据一致性的前提下
- InnoDB会将这些更新操作缓存在change buffer
- 不需要从磁盘读入这个数据页(随机读)
- 在下次查询需要访问这个数据页的时候,将数据页读入内存
- 然后执行change buffer中与这个数据页有关的操作(merge)
- change buffer是可以持久化的数据,在内存中有拷贝,也会被写入到磁盘上
- 将更新操作先记录在channge buffer,减少随机读磁盘,提升语句的执行速度
- 另外数据页读入内存需要占用buffer pool,使用channge buffer能避免占用内存,提高内存利用率
- change buffer用到是buffer pool里的内存,不能无限增大,控制参数
innodb_change_buffer_max_size
1 | # 默认25,最大50 |
merge
- merge:将change buffer中的操作应用到原数据页
- merge的执行过程
- 从磁盘读入数据页到内存(老版本的数据页)
- 从change buffer里找出这个数据页的change buffer记录(可能多个)
- 然后依次执行,得到新版本的数据页
- 写入redolog,包含内容:数据页的表更+change buffer的变更
- merge执行完后,内存中的数据页和change buffer所对应的磁盘页都还没修改,属于脏页
- 通过其他机制,脏页会被刷新到对应的物理磁盘页
- 触发时机
- 访问这个数据页
- 系统后台线程定期merge
- 数据库正常关闭
使用条件
- 对于唯一索引来说,所有的更新操作需要先判断这个操作是否违反唯一性约束
- 唯一索引的更新无法使用change buffer,只有普通索引可以使用change buffer
- 主键也是无法使用change buffer的
- 例如要插入
(4,400),必须先判断表中是否存在k=4的记录,这个判断的前提是将数据页读入内存 - 既然数据页已经读入到了内存,直接更新内存中的数据页就好,无需再写change buffer
使用场景
- 一个数据页在merge之前,change buffer记录关于这个数据页的变更越多,收益越大
- 对于写多读少的业务,页面在写完后马上被访问的概率极低,此时change buffer的使用效果最好
- 例如账单类、日志类的系统
- 如果一个业务的更新模式为:写入之后马上会做查询
- 虽然更新操作被记录到change buffer,但之后马上查询,又会从磁盘读取数据页,触发merge过程
- 没有减少随机读,反而增加了维护change buffer的代价
更新过程
插入(4,400)
目标页在内存中
- 对于唯一索引来说,找到3~5之间的位置,判断没有冲突,插入这个值
- 对于普通索引来说,找到3~5之间的位置,插入这个值
- 性能差异:微乎其微
目标页不在内存中
- 对于唯一索引来说,需要将数据页读入内存,判断没有冲突,插入这个值
- 磁盘随机读,成本很高
- 对于普通索引来说,将更新操作记录在change buffer即可
- 减少了磁盘随机读,性能提升明显
索引选择
- 普通索引与唯一索引,在查询性能上并没有太大差异,主要考虑的是更新性能,推荐选择普通索引
- 建议关闭change buffer的场景
- 如果所有的更新后面,都伴随着对这个记录的查询
- 控制参数
innodb_change_buffering
1 | mysql> SHOW VARIABLES LIKE '%innodb_change_buffering%'; |
change buffer + redolog
更新过程
当前k树的状态:找到对应的位置后,k1所在的数据页Page 1在内存中,k2所在的数据页Page 2不在内存中
1 | INSERT INTO t(id,k) VALUES (id1,k1),(id2,k2); |
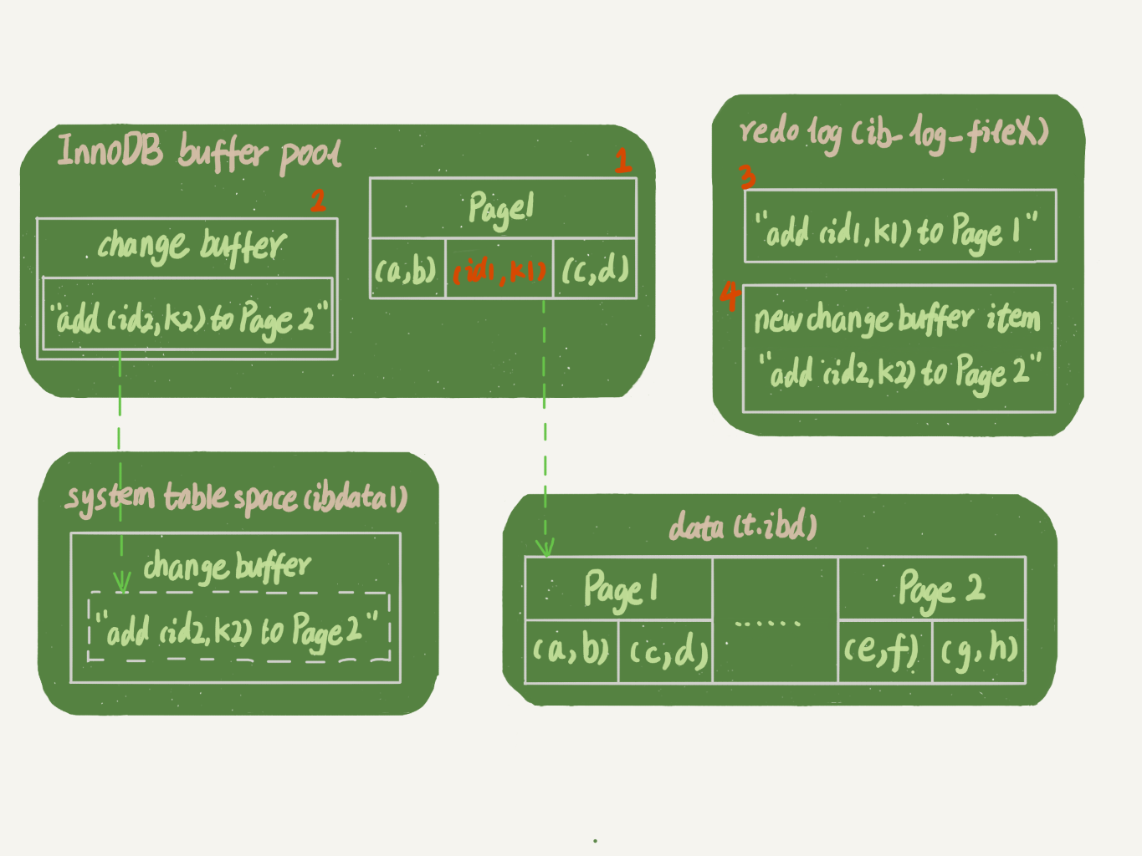
1 | # 内存:buffer pool |
- Page 1在内存中,直接更新内存
- Page 2不在内存中,在changer buffer中记录:
add (id2,k2) to Page 2 - 上述两个动作计入redolog(磁盘顺序写)
- 至此事务完成,执行更新语句的成本很低
- 写两次内存+一次磁盘
- 由于在事务提交时,会把change buffer的操作记录也记录到redolog
- 因此可以在崩溃恢复时,恢复change buffer
- 虚线为后台操作,不影响更新操作的响应时间
读过程
假设:读语句发生在更新语句后不久,内存中的数据都还在,与系统表空间(ibdata1)和redolog(ib_logfileX)无关
1 | SELECT * FROM t WHERE k IN (k1,k2); |
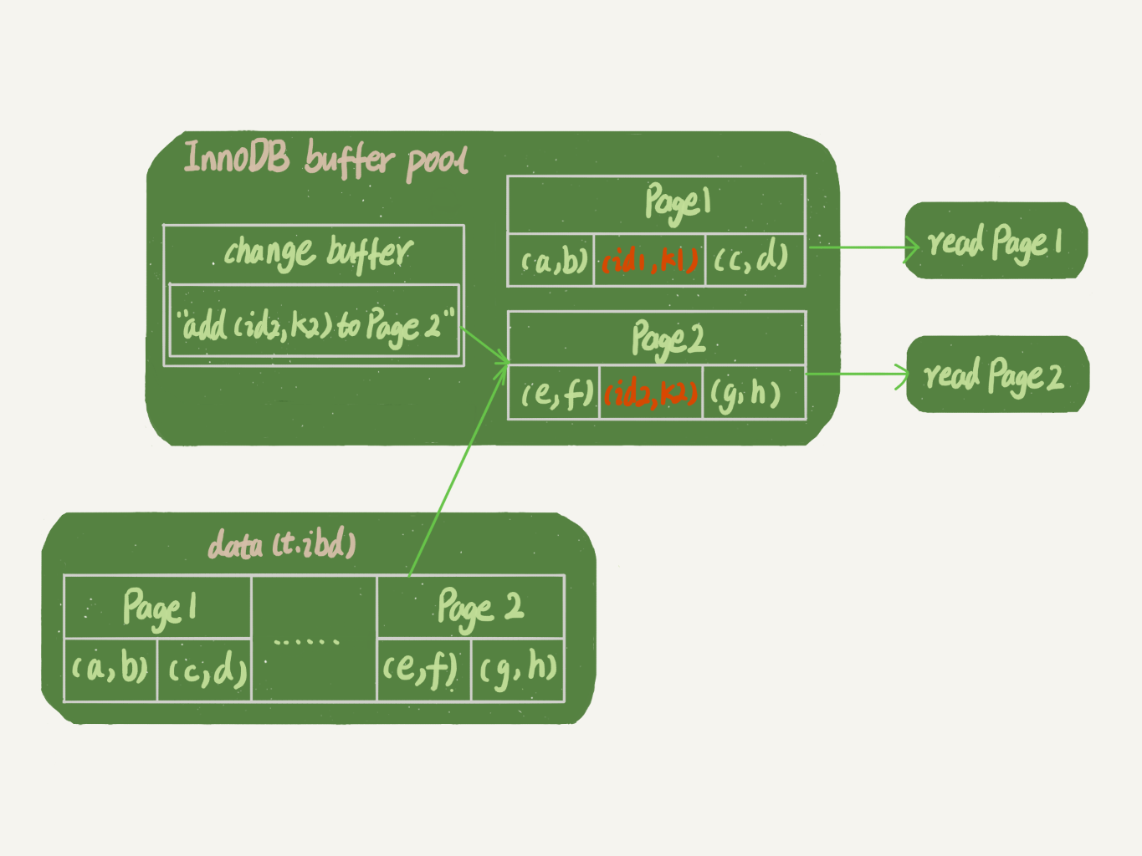
- 读Page 1,直接从内存返回(此时Page 1有可能还是脏页,并未真正落盘)
- 读Page 2,通过磁盘随机读将数据页读入内存,然后应用change buffer里面的操作日志(merge)
- 生成一个正确的版本并返回
提升更新性能
- redolog:节省随机写磁盘的IO消耗(顺序写)
- change buffer:节省随机读磁盘的IO消耗
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-03-06
MySQL -- KILL + 客户端
KILL KILL QUERY THREAD_ID 终止这个线程中正在执行的语句 KILL [ CONNECTION ] THREAD_ID 断开这个线程的连接,如果该线程有语句在执行,先停止正在执行的语句 锁等待表初始化1234567CREATE TABLE `t` ( `id` INT(11) NOT NULL, `c` INT(11) NOT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;INSERT INTO t VALUES (1,1); 操作次序 session A session B session C BEGIN; UPDATE t SET c=c+1 WHERE id=1; UPDATE t SET c=c+2 WHERE id=1;(Blocked) SHOW PROCESSLIST; KILL QUERY 24; ERROR 1317 (70100): Query execution was interrupted 1234567...

2019-03-10
MySQL -- JOIN
表初始化123456789101112131415161718192021222324CREATE TABLE `t2` ( `id` INT(11) NOT NULL, `a` INT(11) DEFAULT NULL, `b` INT(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `a` (`a`)) ENGINE=InnoDB;DROP PROCEDURE IF EXISTS idata;DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=1; WHILE (i <= 1000) DO INSERT INTO t2 VALUES (i,i,i); SET i=i+1; END WHILE;END;;DELIMITER ;CALL idata();CREATE TABLE t1 LIKE t2;INSERT INTO t1 (SELECT * FROM t2 WHERE id<=100); Index Nested-Loo...

2019-01-16
MySQL -- 事务隔离
概念 事务:保证一组数据库操作,要么全部成功,要么全部失败 在MySQL中,事务支持是在存储引擎层实现的 MyISAM不支持事务 InnoDB支持事务 隔离性与隔离级别 事务特性:ACID(Atomicity、Consistency、Isolation、Durability) 如果多个事务并发执行时,就可能会出现脏读、不可重复读、幻读(phantom read)等问题 解决方案:隔离级别 隔离级别越高,效率就会越低 SQL标准的事务隔离级别 READ-UNCOMMITTED 一个事务还未提交时,它所做的变更能被别的事务看到 READ-COMMITTED 一个事务提交之后,它所做的变更才会被其他事务看到 REPEATABLE-READ 一个事务在执行过程中所看到的数据,总是跟这个事务在启动时看到的数据是一致的 同样,在RR隔离级别下,未提交的变更对其他事务也是不可见的 SERIALIZABLE 对同一行记录,写会加写锁,读会加读锁,锁级别是行锁 当出现读写锁冲突时,后访问的事务必须等前一个事务执行完成,才能继续执行 默认隔离级别 Oracle:READ-COMMITTED...

2017-05-06
InnoDB -- 逻辑存储
本文主要介绍InnoDB存储引擎的逻辑存储结构 逻辑存储结构 Tablespace Tablespace是InnoDB存储引擎逻辑存储结构的最高层,所有数据都存放在Tablespace中 分类 System Tablespace Separate Tablespace General Tablespace System Tablespace System Tablespace即我们常见的共享表空间,变量为innodb_data_file_path,一般为ibdata1文件 里面存放着undo logs,change buffer,doublewrite buffer等信息(后续将详细介绍),在没有开启file-per-table的情况下,还会包含所有表的索引和数据信息 没有开启file-per-table时存在的问题 所有的表和索引都会在System Tablespace中,占用空间会越来越大 碎片越来越多(如truncate table时,占用的磁盘空间依旧保留在System Tablespace) 12345678910111213141516171819mysql> ...

2019-03-02
MySQL -- 读写分离
读写分离架构客户端直连 Proxy 对比 客户端直连 少了一层Proxy转发,查询性能稍微好一点 整体架构简单,排查问题方便 需要了解后端部署细节,在出现主从切换、库迁移时,客户端有感知,需要调整数据库连接信息 一般伴随着一个负责管理后端的组件,例如ZooKeeper Proxy – 发展趋势 对客户端友好,客户端不需要关注后端细节,但后端维护成本较高 Proxy也需要高可用架构,带Proxy的整体架构相对复杂 过期读由于主从延迟,主库上执行完一个更新事务后,立马在从库上执行查询,有可能读到刚刚的事务更新之前的状态 解决方案强制走主库 将查询请求做分类 必须要拿到最新结果的请求,强制将其发送到主库上 可以读到旧数据的请求,将其发到从库上 如果完全不能接受过期读,例如金融类业务,相当于放弃读写分离,所有的读写压力都在主库上 SLEEP 主库更新后,读从库之前先SLEEP一下,类似于SELECT SLEEP(1) 基于的假设:大多数主从延时在1秒内 卖家发布商品后,用Ajax直接把客户端输入的内容作为“新的商品”显示在页面上,而非真正的做数据库查询 等卖家再次刷新页面,其...

2019-03-12
MySQL -- 用户临时表
临时表 VS 内存表 内存表,指的是使用Memory引擎的表,建表语法:CREATE TABLE ... ENGINE=Memory 所有数据都保存在内存中,系统重启时被清空,但表结构还在 临时表,可以使用各种引擎 如果使用的是InnoDB或者MyISAM引擎,数据需要写到磁盘上 当然也可以使用Memory引擎 特征 session A session B CREATE TEMPORARY TABLE t(c int) ENGINE=MyISAM;(创建临时表) SHOW CREATE TABLE t;(Table ‘test.t’ doesn’t exist) CREATE TABLE t(id INT PRIMARY KEY) ENGINE=InnoDB;(创建普通表) SHOW CREATE TABLE t;(显示临时表) SHOW TABLES;(显示普通表) INSERT INTO t VALUES (1); SELECT * FROM t;(返回1) SELECT * FROM t;(Empty set) ...




