MySQL -- 字符串索引
场景
建表
1 | CREATE TABLE SUser( |
查询
1 | SELECT id,name,email FROM SUser WHERE email='[email protected]'; |
创建索引
1 | ALTER TABLE SUser ADD INDEX index1(email); |
index1
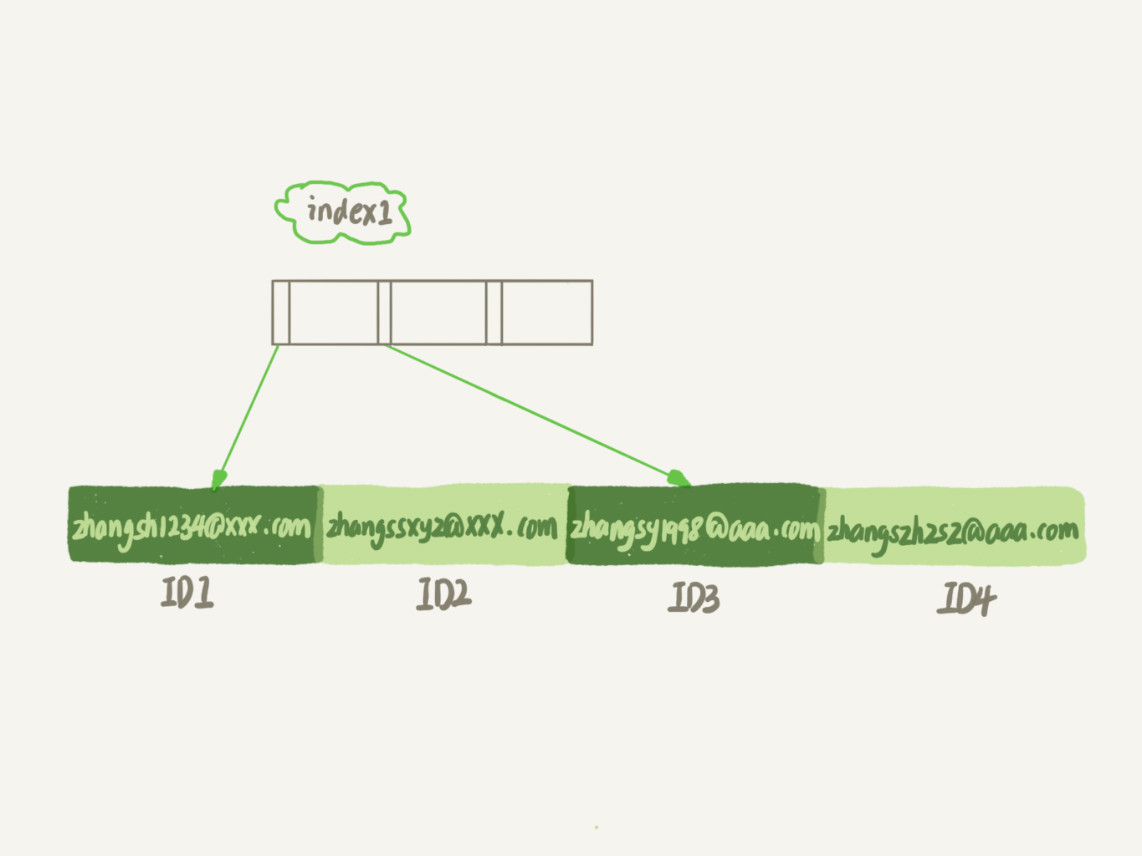
- 索引长度:整个字符串
- 从index1索引树找到第一个满足索引值为zhangssxyz@xxx.com的记录,取得主键为ID2
- 到聚簇索引上查找值为ID2的行,判断email的值是否正确(Server层行为),将该行记录加入结果集
- 获取index1上的下一条记录,发现不满足email=zhangssxyz@xxx.com,循环结束
- 整个过程,只需要回表1次,系统认为只扫描了1行
index2
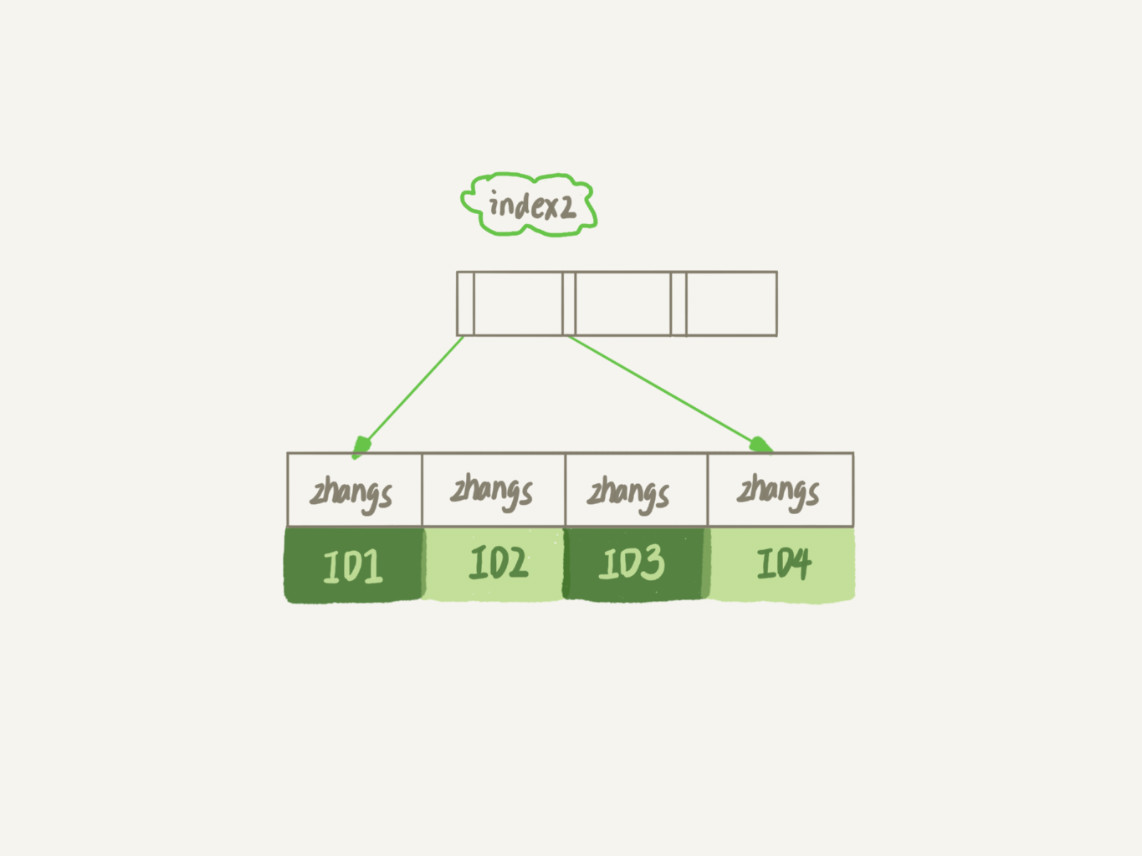
- 索引长度:_前6个字节_
- 索引占用的空间更小,增加额外的记录扫描次数,(且不支持覆盖索引,见后面)
- 从index2索引树找到第一个满足索引值为
zhangs的记录,取得主键为ID1- 到聚簇索引上查找值为ID1的行,email!=zhangssxyz@xxx.com(Server层行为),记录丢弃
- 获取index2上的下一条记录,发现仍然是
zhangs,取得主键为ID2- 到聚簇索引上查找值为ID2的行,email==zhangssxyz@xxx.com,加入结果集
- 重复上面的步骤,直到index2上取得的值不为
zhangs为止 - 整个过程,需要回表4次,系统认为扫描了4行
- 假设index2为
email(7),满足前缀zhangss只有一个,只需要回表一次- 使用前缀索引,如果能定义好长度,即能节省空间,又不会增加太多的查询成本
前缀索引的长度
原则:区分度。使用前缀索引一般都会损失区分度,预设一个可接受的损失比例,在该损失比例内,寻找最短前缀长度
1 | SELECT |
前缀索引与覆盖索引
1 | SELECT id,email FROM SUser WHERE email='[email protected]'; |
- 如果使用index1,可以利用覆盖索引,不需要回表
- 如果使用index2,就必须回表,获得整行记录后再去判断email字段的值
- 即使index2为
email(18)(包含了所有信息),还是需要回表 - 因为系统不确定前缀索引的定义是否截断了完整信息
- 因此,前缀索引是用不上覆盖索引对查询性能的优化
- 即使index2为
其他手段
场景:前缀的区分度非常差,例如居民身份证(前6位是地址码)
倒序存储
1 | SELECT field_list FROM t WHERE id_card = REVERSE('input_id_card_string'); |
增加hash字段
1 | ALTER TABLE t ADD id_card_crc INT UNSIGNED, ADD INDEX(id_card_crc); |
- 每次插入新纪录的时候,都需要使用
CRC32()函数得到校验码 - 由于校验码可能会冲突,因此查询语句的条件需要加上id_card(精确匹配)
- 索引的长度变为了4个字节,比直接用身份证作为索引所占用的空间小很多
异同点
- 都不支持范围查询,只支持等值查询
- 空间占用
- 倒序存储:N个字节的索引
- 增加hash字段:字段+索引
- CPU
- 倒序存储:每次读写都需要额外调用一次
REVERSE函数,开销比CRC32函数略小 - 增加hash字段:每次读写都需要额外调用一次
CRC32函数
- 倒序存储:每次读写都需要额外调用一次
- 查询效率
- 增加hash字段方式的查询性能会更加稳定一些
- CRC32虽然会有一定的冲突概率,但概率非常低,可以认为平均扫描行数接近1
- 倒序存储一般会用到前缀索引,这会增加扫描行数(无法利用覆盖索引,必须回表)
- 增加hash字段方式的查询性能会更加稳定一些
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-02-24
MySQL -- 主从复制的可靠性与可用性
Master-Master 主从切换 同步延时 主库A执行完成一个事务,写入binlog,记为T1 然后传给从库B,从库B接收该binlog,记为T2 从库B执行完成这个事务,记为T3 同步延时:T3-T1 同一个事务,在从库执行完成的时间和主库执行完成的时间之间的差值 SHOW SLAVE STATUS中的Seconds_Behind_Master Seconds_Behind_Master 计算方法 每个事务的binlog里面都有一个时间字段,用于记录该binlog在主库上的写入时间 从库取出当前正在执行的事务的时间字段的值,计算它与当前系统时间点差值,得到Seconds_Behind_Master 即T3-T1 如果主库与从库的时间不一致,Seconds_Behind_Master会不会有误差? 一般不会 在从库连接到主库时,会通过SELECT UNIX_TIMESTAMP()获取当前主库的系统时间 如果从库发现当前主库的系统时间与自己的不一致,在计算Seconds_Behind_Master会自动扣除这部分差值 但建立连接后,主库或从库又修改了系统时间,依然会不准确 ...

2019-03-15
MySQL -- 自增主键
自增不连续表初始化1234567CREATE TABLE `t` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `c` INT(11) DEFAULT NULL, `d` INT(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`)) ENGINE=InnoDB; 自增值123456789101112131415INSERT INTO t VALUES (null,1,1);-- AUTO_INCREMENT=2,表示下一次插入数据时,如果需要自动生成自增值,会生成id=2mysql> SHOW CREATE TABLE t;+-------+---------------------------------------------+| Table | Create Table |+-------+---------------------------------------------+| t | CREATE T...

2019-03-17
MySQL -- 权限
创建用户1CREATE USER 'ua'@'%' IDENTIFIED BY 'pa'; 用户名+地址才表示一个用户,ua@ip1和ua@ip2代表的是两个不同的用户 在磁盘上,往mysql.user表里插入一行,由于没有指定权限,所有表示权限的字段都是N 在内存里,往数组acl_users里插入一个acl_user对象,该对象的access字段的值为0 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950mysql> SELECT * FROM mysql.user WHERE user = 'ua'\G;*************************** 1. row *************************** Host: % User: ua Select_priv: N ...

2019-03-19
MySQL -- 自增ID耗尽
显示定义ID表定义的自增值ID达到上限后,在申请下一个ID时,得到的值保持不变 123456789101112131415161718-- (2^32-1) = 4,294,967,295-- 建议使用 BIGINT UNSIGNEDCREATE TABLE t (id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY) AUTO_INCREMENT=4294967295;INSERT INTO t VALUES (null);-- AUTO_INCREMENT没有改变mysql> SHOW CREATE TABLE t;+-------+------------------------------------------------------+| Table | Create Table |+-------+------------------------------------------------------+| t | CREATE TABLE `t` ( `id` ...

2019-02-12
MySQL -- 索引上的函数
结论先行如果对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器会决定放弃走树搜索功能 条件字段函数操作交易日志表123456789CREATE TABLE `tradelog` ( `id` INT(11) NOT NULL, `tradeid` VARCHAR(32) DEFAULT NULL, `operator` INT(11) DEFAULT NULL, `t_modified` DATETIME DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `tradeid` (`tradeid`), KEY `t_modified` (`t_modified`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 123456789101112131415-- 94608000 = 3 * 365 * 24 * 3600-- t_modified : 2016-01-01 00:00:00 ~ 2019-01-01 00:00:00DELIMITER ;;CREATE ...

2019-02-25
MySQL -- 从库并行复制
主从复制 第一个黑色箭头:客户端写入主库,第二个黑色箭头:从库上sql_thread执行relaylog,前者的并发度大于后者 在主库上,影响并发度的原因是锁,InnoDB支持行锁,对业务并发度的支持还算比较友好 如果在从库上采用单线程(MySQL 5.6之前)更新DATA的话,有可能导致从库应用relaylog不够快,造成主从延迟 多线程模型 coordinator就是原来的sql_thread,但不会再直接应用relaylog后更新DATA,只负责读取relaylog和分发事务 真正更新日志的是worker线程,数量由参数slave_parallel_workers控制 123456mysql> SHOW VARIABLES LIKE '%slave_parallel_workers%';+------------------------+-------+| Variable_name | Value |+------------------------+-------+| slave_parallel_workers | 4 |...