
MySQL -- order by
市民信息
1 | CREATE TABLE `t` ( |
查询语句
1 | SELECT city,name,age FROM t WHERE city='杭州' ORDER BY name LIMIT 1000; |
存储过程
1 | DELIMITER ;; |
全字段排序
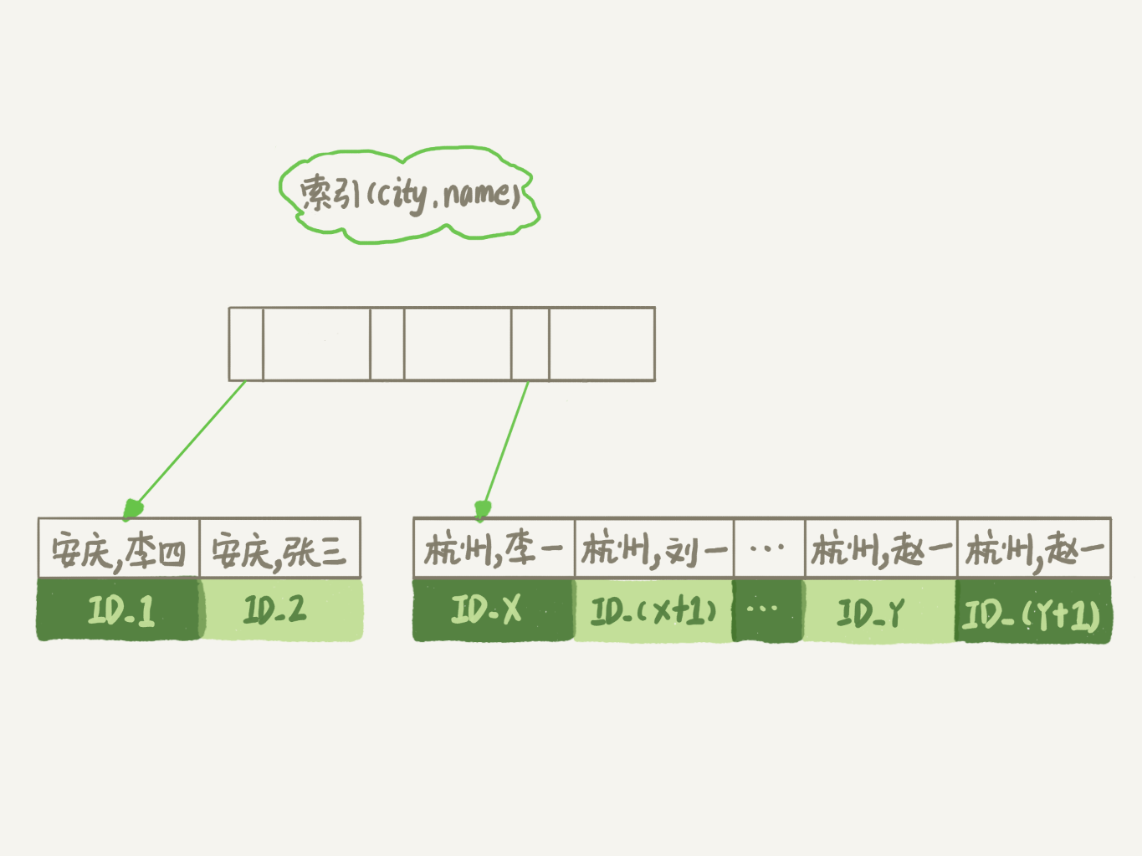
city索引树
满足city=’杭州’的行,主键为ID_X ~ ID_(X+N)
sort buffer
1 | mysql> EXPLAIN SELECT city,name,age FROM t FORCE INDEX(city) WHERE city='杭州' ORDER BY name LIMIT 1000\G; |
rows=4000:EXPLAIN是不考虑LIMIT的,代表匹配条件的总行数Using index condition:表示使用了索引下推Using filesort:表示需要排序,MySQL会为每个线程分配一块内存用于排序,即sort buffer
1 | -- 1048576 Bytes = 1 MB |
执行过程

- 初始化
sort buffer,确定放入三个字段:**city、name、age** - 从city索引树找到第一个满足city=’杭州’的主键ID,即ID_X
- 然后拿着ID_X回表取出整行,将
city、name、age这三个字段的值都存入sort buffer - 回到city索引树取下一条记录,重复上述动作,直至city的值不满足条件为止,即ID_Y
- 对
sort buffer中的数据按照name字段进行排序- 排序过程可能使用内部排序(内存,首选,快速排序/堆排序),也可能使用外部排序(磁盘,次选,归并排序)
- 这取决于排序所需要的内存是否小于
sort_buffer_size(默认1 MB)
- 按照排序结果取前1000行返回给客户端
观察指标
1 | -- 打开慢查询日志 |
外部排序
慢查询日志
1 | # Time: 2019-02-10T07:19:38.347053Z |
OPTIMIZER_TRACE
1 | "filesort_summary": { |
In optimizer trace output,
num_tmp_filesdid not actually indicate number of files.
It has been renamed tonum_initial_chunks_spilled_to_diskand indicates the number of chunks before any merging has occurred.
num_initial_chunks_spilled_to_disk=9,说明采用了外部排序,使用了磁盘临时文件peak_memory_used > memory_available:sort buffer空间不足- 如果
sort_buffer_size越小,num_initial_chunks_spilled_to_disk的值就越大 - 如果
sort_buffer_size足够大,那么num_initial_chunks_spilled_to_disk=0,采用内部排序 num_examined_rows=4000:参与排序的行数sort_mode含有的packed_additional_fields:排序过程中对字符串做了紧凑处理- 字段name为
VARCHAR(16),在排序过程中还是按照实际长度来分配空间
- 字段name为
扫描行数
整个执行过程中总共扫描了4000行(如果internal_tmp_disk_storage_engine=InnoDB,返回4001)
1 | mysql> SELECT @b-@a; |
内部排序
慢查询日志
Query_time为0.007517,为采用外部排序的59%
1 | # Time: 2019-02-10T07:36:36.442679Z |
OPTIMIZER_TRACE
1 | "filesort_information": [ |
num_initial_chunks_spilled_to_disk=0,说明采用了内部排序(堆排序),排序直接在sort buffer中完成peak_memory_used < memory_available:sort buffer空间充足num_examined_rows=4000:参与排序的行数filesort_priority_queue_optimization:采用优先级队列优化(堆排序)
扫描行数
1 | mysql> SELECT @b-@a; |
性能
- 全字段排序:对原表数据读一遍(覆盖索引的情况除外),其余操作都在
sort buffer和临时文件中进行 - 如果查询要返回的字段很多,那么
sort buffer中能同时放下的行就会变得很少 - 这时会分成很多个临时文件,排序性能就会很差
- 解决方案:采用_rowid排序_
- 单行的长度不超过
max_length_for_sort_data:全字段排序 - 单行的长度超过
max_length_for_sort_data:rowid排序
- 单行的长度不超过
1 | mysql> SHOW VARIABLES LIKE '%max_length_for_sort_data%'; |
rowid排序
city、name和age三个字段的总长度最少为36,执行SET max_length_for_sort_data=16;
执行过程

- 初始化
sort buffer,确定放入两个字段:**name(需要排序的字段)、id(索引组织表,主键)** - 从city索引树找到第一个满足city=’杭州’的主键ID,即ID_X
- 然后拿着ID_X回表取出整行,将
name和ID这两个字段的值存入sort buffer - 回到city索引树取下一条记录,重复上述动作,直至city的值不满足条件为止,即ID_Y
- 对
sort buffer中的数据按照name字段进行排序(当然也有可能仍然是外部排序) - 遍历排序结果,取出前1000行,并按照主键id的值回表取出
city,name和age三个字段返回给客户端- 其实,结果集只是一个逻辑概念,MySQL服务端在sort buffer排序完成后,不会再耗费内存来存储回表取回的内容
- 实际上,MySQL服务端从排序后的
sort buffer中依次取出id,回表取回内容后,直接返回给客户端
观察指标
1 | -- 采用外部排序 + rowid排序 |
慢查询日志
1 | # Time: 2019-02-10T08:23:59.068672Z |
OPTIMIZER_TRACE
1 | "filesort_information": [ |
num_initial_chunks_spilled_to_disk,9->6,说明外部排序所需要的临时文件变少了sort_mode含有的rowid:采用rowid排序num_examined_rows=4000:参与排序的行数
扫描行数
扫描的行数变成了5000行(多出了1000行是回表操作)
1 | mysql> SELECT @b-@a; |
全字段排序 vs rowid排序
- MySQL只有在担心由于sort buffer太小而影响排序效率的时候,才会考虑使用rowid排序,rowid排序的优缺点如下
- 优点:排序过程中,一次排序可以排序更多的行
- 缺点:增加回表次数,与LIMIT N成正相关
- MySQL如果认为
sort buffer足够大,会优先选择全字段排序- 把需要的所有字段都放到
sort buffer,排序完成后直接从内存返回查询结果,无需回表 - 体现了MySQL的一个设计思路
- 尽量使用内存,减少磁盘访问
- 把需要的所有字段都放到
- MySQL排序是一个比较成本较高的操作,进一步的优化方案:联合索引、覆盖索引
- 目的:移除
Using filesort
- 目的:移除
优化方案
联合索引
1 | ALTER TABLE t ADD INDEX city_user(city, name); |
city_user索引树
explain
1 | mysql> EXPLAIN SELECT city,name,age FROM t FORCE INDEX(city_user) WHERE city='杭州' ORDER BY name LIMIT 1000\G; |
Extra里面已经移除了Using filesort,说明MySQL不需要排序操作了- 联合索引
city_user本身就是有序的,因此无需将4000行都扫描一遍,只需要扫描满足条件的前1000条记录即可 Using index condition:表示使用了索引下推
执行过程

- 从city_user索引树找到第一个满足city=’杭州’的主键ID,即ID_X
- 然后拿着ID_X回表取出整行,取
city、name和age三个字段的值,作为结果集的一部分直接返回给客户端 - 继续取city_user索引树的下一条记录,重复上述步骤,直到查到1000条记录或者不满足city=’杭州’时结束循环
- 这个过程不需要排序(当然也不需要外部排序用到的临时文件)
观察指标
慢查询日志
Rows_examined为1000,Query_time为上面全字段排序(内部排序)的情况耗时的49%
1 | 278 # Time: 2019-02-10T09:00:28.956622Z |
扫描行数
1 | mysql> SELECT @b-@a; |
覆盖索引
覆盖索引:索引上的信息足够满足查询需求,无需再回表,但维护索引是有代价的,需要权衡
1 | ALTER TABLE t ADD INDEX city_user_age(city, name, age); |
explain
Using index:表示使用覆盖索引
1 | mysql> EXPLAIN SELECT city,name,age FROM t FORCE INDEX(city_user_age) WHERE city='杭州' ORDER BY name LIMIT 1000\G; |
执行过程

- 从city_user_age索引树找到第一个满足city=’杭州’的记录
- 直接取出
city、name和age这三个字段的值,作为结果集的一部分直接返回给客户端
- 直接取出
- 继续取city_user_age索引树的下一条记录,重复上述步骤,直到查到1000条记录或者不满足city=’杭州’时结束循环
观察指标
慢查询日志
Rows_examined同样为1000,Query_time为上面使用联合索引city_user耗时的49%
1 | # Time: 2019-02-10T09:16:20.911513Z |
扫描行数
1 | mysql> SELECT @b-@a; |
in语句优化
假设已有联合索引city_user(city,name),查询语句如下
1 | SELECT * FROM t WHERE city IN ('杭州','苏州') ORDER BY name LIMIT 100; |
单个city内部,name是递增的,但在匹配多个city时,name就不能保证是递增的,因此这个SQL语句需要排序
explain
依然有Using filesort
1 | mysql> EXPLAIN SELECT * FROM t FORCE INDEX(city_user) WHERE city IN ('杭州','苏州') ORDER BY name LIMIT 100\G |
解决方案
- 拆分语句,包装在同一个事务
SELECT * FROM t WHERE city='杭州' ORDER BY name LIMIT 100;:不需要排序,客户端用一个内存数组A保存结果SELECT * FROM t WHERE city='苏州' ORDER BY name LIMIT 100;:不需要排序,客户端用一个内存数组B保存结果- 内存数组A和内存数组B均为有序数组,可以采用内存中的归并排序
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-02-12
MySQL -- 索引上的函数
结论先行如果对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器会决定放弃走树搜索功能 条件字段函数操作交易日志表123456789CREATE TABLE `tradelog` ( `id` INT(11) NOT NULL, `tradeid` VARCHAR(32) DEFAULT NULL, `operator` INT(11) DEFAULT NULL, `t_modified` DATETIME DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `tradeid` (`tradeid`), KEY `t_modified` (`t_modified`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 123456789101112131415-- 94608000 = 3 * 365 * 24 * 3600-- t_modified : 2016-01-01 00:00:00 ~ 2019-01-01 00:00:00DELIMITER ;;CREATE ...

2017-05-13
InnoDB -- B+Tree索引
本文主要介绍InnoDB存储引擎的B+Tree索引 B+Tree数据结构 所有叶子节点出现在同一层 叶子节点包含关键字信息 叶子节点本身构成单向有序链表 叶子节点内部的记录也构成单向有序链表 索引节点不包含关键字信息,这样能容纳更多的索引信息,B+Tree的高度很低,查找效率很高 关于B+Tree的更多内容请查看维基百科 MyISAM与InnoDBMyISAM 索引文件与数据文件是**分离**的 MyISAM的索引文件采用B+Tree索引 叶子节点data域记录的是**数据存放的地址** 主索引(唯一)与辅助索引(可重复)在结构上没有任何区别 InnoDB 数据文件本身是按照B+Tree组织的索引结构(主索引:Primary Index或聚集索引:Clustered Index),而叶子节点data域记录的是**完整的数据信息** InnoDB**必须有主键**,如果没有显式定义主键或非NULL的唯一索引,InnoDB会自动生成6 Bytes的ROWID作为主键 辅助索引(Secondary Index)也是按B+Tree组织,叶子节点data域记录的是**主键值**,因此主键不宜定...

2019-02-22
MySQL -- 主从复制的基本原理
主从切换 在状态1,客户端的读写都是直接访问节点A,节点B是节点A的从库 只是将节点A的更新都同步过来,在节点B本地执行,保持一致 在状态1,虽然节点B没有被直接访问,但依然建议设置成readonly模式 运营类的查询语句会在从库上执行,设置成readonly模式能够防止一些误操作 防止切换逻辑有Bug,例如出现双写,造成主从不一致 可以通过readonly状态来判断节点的角色 在状态1,节点B设置为readonly模式,同样能与节点A保持同步更新 readonly设置对超级权限用户是无效的,而节点B中用于同步更新的线程,就拥有超级权限 主从同步在节点A执行update语句,然后同步到节点B 从库B与主库A之间维持一个长连接,主库A内部有一个专门用于服务于从库B长连接的线程 在从库B上执行CHANGE MASTER命令,设置主库A的信息 IP、PORT、USER、PASSWORD 从哪个位置(文件名 + 日志偏移量)开始请求binlog 在从库B上执行START SLAVE命令,这时从库B会启动两个线程:io_thread + sql_thread io_thread:负责...

2019-01-28
MySQL -- RR隔离与RC隔离
视图 虚拟表 – 本文不关心 在调用的时候执行查询语句并生成执行结果 SQL语句:CREATE VIEW InnoDB在实现MVCC时用到的一致性读视图(consistent read view) 用于支持RC和RR隔离级别的实现 没有对应的物理结构 主要作用:在事务执行期间,事务能看到怎样的数据 快照 在RR隔离级别下,事务在启动的时候保存了一个快照,快照是基于整库的 在InnoDB,每个事务都有一个唯一的事务ID(transaction id) 在事务开始的时候向InnoDB的事务系统申请的,按申请的顺序严格递增 每行数据都有多个版本,每次事务更新数据的时候,都会生成一个新的数据版本 事务会把自己的transaction id赋值给这个数据版本的事务ID,记为row trx_id 每个数据版本都有对应的row trx_id 同时也要逻辑保留旧的数据版本,通过新的数据版本和undolog可以计算出旧的数据版本 多版本 虚线框是同一行记录的4个版本 当前最新版本为V4,k=22,是被transaction id为25的事务所更新的,因此它的row trx_id为...

2017-05-19
InnoDB -- Next-Key Lock
本文主要介绍InnoDB存储引擎的Next-Key Lock MVCC InnoDB支持MVCC,与之MVCC相对的是LBCC MVCC中读操作分两类:Snapshot Read(不加锁)和Current Read(加锁) MVCC的好处:**Snapshot Read不加锁**,并发性能好,适用于常规的JavaWeb项目(OLTP应用) 隔离级别InnoDB支持4种事务隔离级别(Isolation Level) 隔离级别 描述 READ UNCOMMITTED (RUC) 可以读取到其他事务中尚未提交的内容,生产环境中不会使用 READ COMMITTED (RC) 可以读取到其他事务中已经提交的内容,Current Read会加锁,存在幻读现象,Oracle和SQL Server的默认事务隔离级别为RC REPEATABLE READ (RR) 保证事务的隔离性,Current Read会加锁,同时会加Gap Lock,不存在幻读现象,InnoDB的默认事务隔离级别为RR SERIALIZABLE MVCC退化为LBCC,不区分Snapshot Read和Curre...
2019-03-02
MySQL -- 读写分离
读写分离架构客户端直连 Proxy 对比 客户端直连 少了一层Proxy转发,查询性能稍微好一点 整体架构简单,排查问题方便 需要了解后端部署细节,在出现主从切换、库迁移时,客户端有感知,需要调整数据库连接信息 一般伴随着一个负责管理后端的组件,例如ZooKeeper Proxy – 发展趋势 对客户端友好,客户端不需要关注后端细节,但后端维护成本较高 Proxy也需要高可用架构,带Proxy的整体架构相对复杂 过期读由于主从延迟,主库上执行完一个更新事务后,立马在从库上执行查询,有可能读到刚刚的事务更新之前的状态 解决方案强制走主库 将查询请求做分类 必须要拿到最新结果的请求,强制将其发送到主库上 可以读到旧数据的请求,将其发到从库上 如果完全不能接受过期读,例如金融类业务,相当于放弃读写分离,所有的读写压力都在主库上 SLEEP 主库更新后,读从库之前先SLEEP一下,类似于SELECT SLEEP(1) 基于的假设:大多数主从延时在1秒内 卖家发布商品后,用Ajax直接把客户端输入的内容作为“新的商品”显示在页面上,而非真正的做数据库查询 等卖家再次刷新页面,其...




