
MySQL -- 主从复制的可靠性与可用性
Master-Master 主从切换
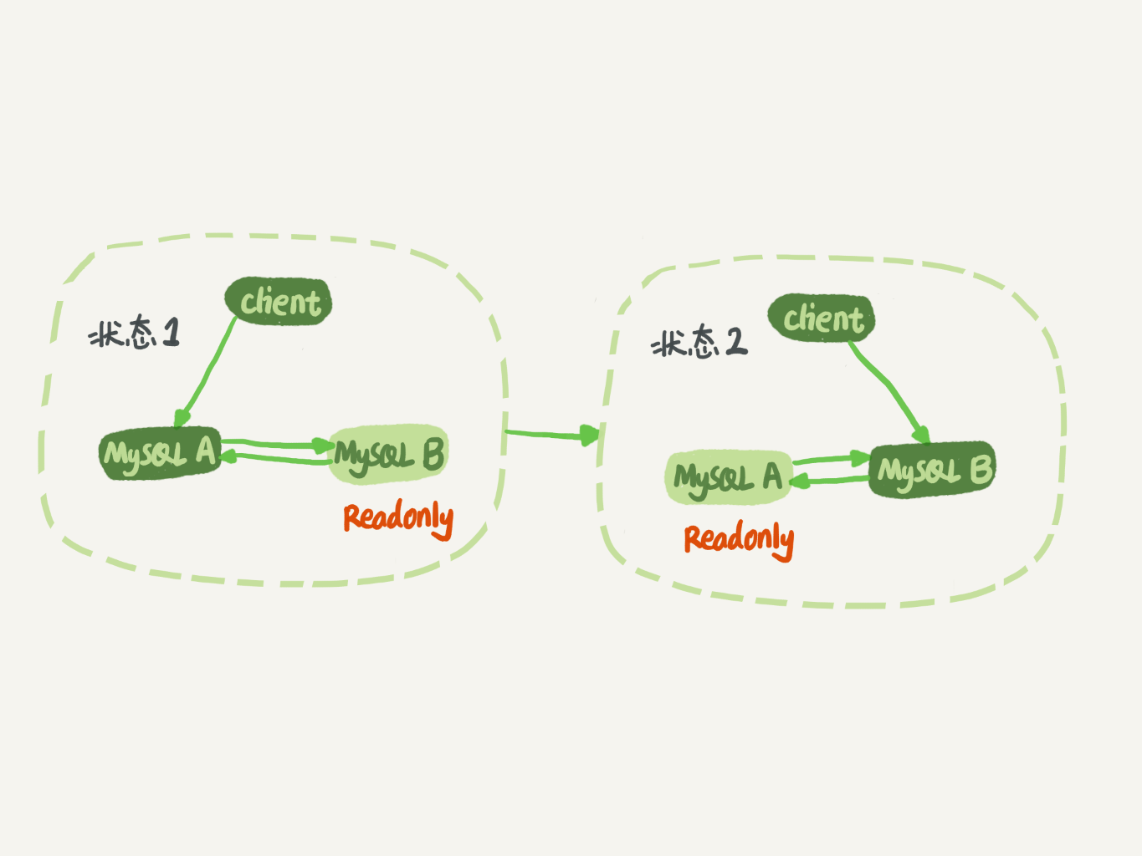
同步延时
- 主库A执行完成一个事务,写入binlog,记为
T1 - 然后传给从库B,从库B接收该binlog,记为
T2 - 从库B执行完成这个事务,记为
T3 - 同步延时:
T3-T1- 同一个事务,在从库执行完成的时间和主库执行完成的时间之间的差值
SHOW SLAVE STATUS中的Seconds_Behind_Master
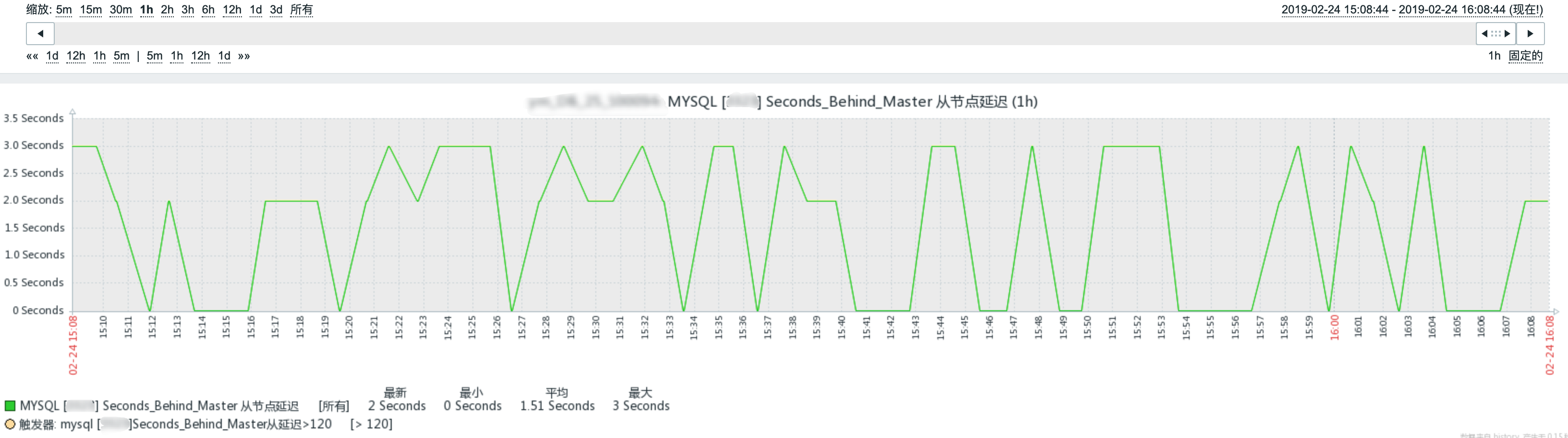
Seconds_Behind_Master
- 计算方法
- 每个事务的
binlog里面都有一个时间字段,用于记录该binlog在主库上的写入时间 - 从库取出当前正在执行的事务的时间字段的值,计算它与当前系统时间点差值,得到
Seconds_Behind_Master - 即
T3-T1
- 每个事务的
- 如果主库与从库的时间不一致,
Seconds_Behind_Master会不会有误差?- 一般不会
- 在从库连接到主库时,会通过
SELECT UNIX_TIMESTAMP()获取当前主库的系统时间 - 如果从库发现当前主库的系统时间与自己的不一致,在计算
Seconds_Behind_Master会自动扣除这部分差值 - 但建立连接后,主库或从库又修改了系统时间,依然会不准确
- 在网络正常的情况下,
T2-T1通常会非常小,此时同步延时的主要来源是**T3-T2**- 从库消费
relaylog的速度跟不上主库生成binlog的速度
- 从库消费
延时来源
- 从库所在机器的性能要弱于主库所在的机器
- 更新请求对于IPOS的压力,在主库和从库上是无差别的
- 非对称部署:20个主库放在4个机器上,但所有从库放在一个机器上
- 主从之间可能会随时切换,现在一般都会采用相同规格的机器+对称部署
- 从库压力大
- 常见场景:管理后台的查询语句
- 从库上的查询耗费大量的CPU资源和IO资源,影响了同步速度,造成了同步延时
- 解决方案
- 一主多从,分担读压力,一般都会采用
- 通过
binlog输出到外部系统,例如Hadoop
- 大事务
- 主库上必须等待事务执行完成后才会写入
binlog,再传给从库 - 常见场景1:一次性删除太多数据(如归档的历史数据)
- 解决方案:控制每个事务删除的数据量,分多次删除
- 常见场景2:大表DDL
- 解决方案:
gh-ost
- 解决方案:
- 主库上必须等待事务执行完成后才会写入
- 从库的并行复制能力(后续展开)
切换策略
可靠性优先
切换过程一般由专门的HA系统完成,存在不可用时间(主库A和从库B都处于只读状态)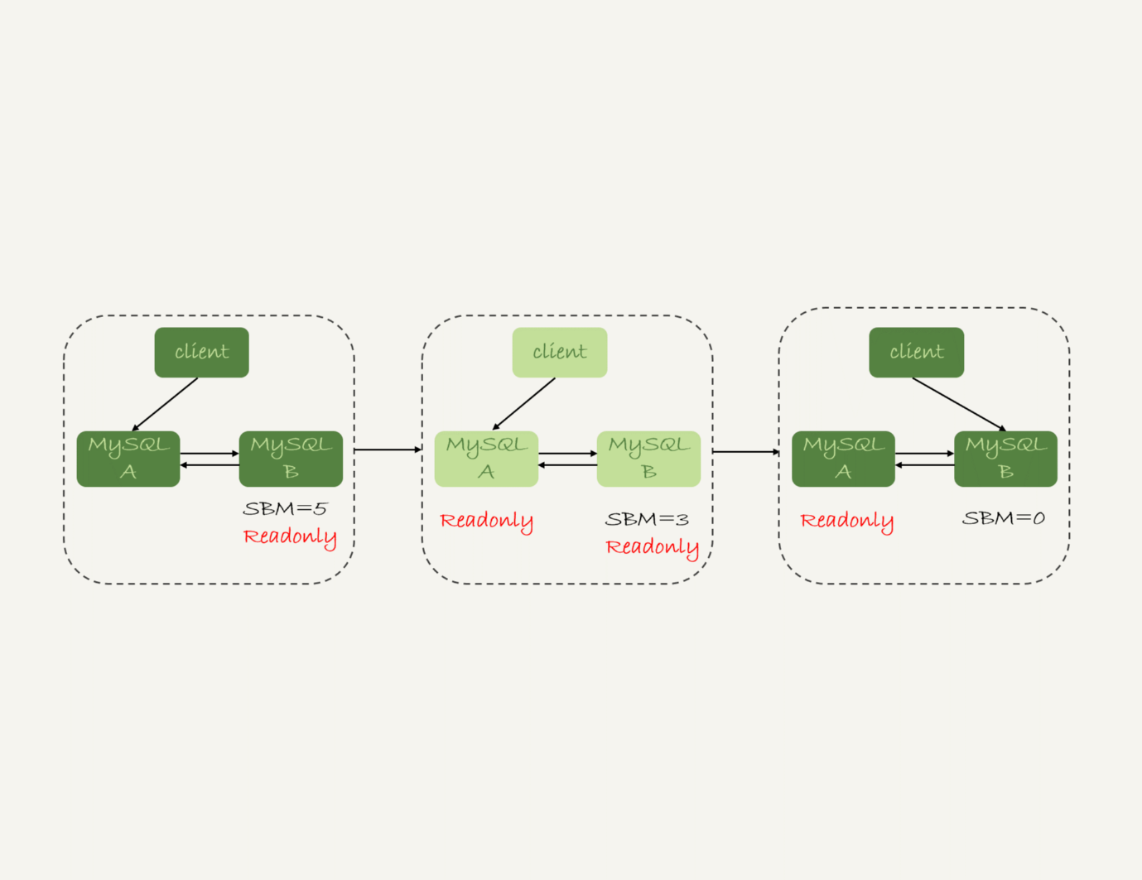
- 判断从库B的
Seconds_Behind_Master值,当小于某个值(例如5)才继续下一步 - 把主库A改为只读状态(
readonly=true) - 等待从库B的
Seconds_Behind_Master值降为0 - 把从库B改为可读写状态(
readonly=false) - 把业务请求切换至从库B
可用性优先
不等主从同步完成,直接把业务请求切换至从库B,并且让从库B可读写,这样几乎不存在不可用时间,但可能会数据不一致
表初始化
1 | CREATE TABLE `t` ( |
插入数据
1 | INSERT INTO t (c) VALUES (4); |
MIXED

- 主库A执行完
INSERT c=4,得到(4,4),然后开始执行主从切换 - 主从之间有5S的同步延迟,从库B会先执行
INSERT c=5,得到(4,5),并且会把这个binlog发给主库A - 从库B执行主库A传过来的
INSERT c=4,得到(5,4) - 主库A执行从库B传过来的
INSERT c=5,得到(5,5) - 此时主库A和从库B会有两行不一致的数据
ROW

- 采用
ROW格式的binlog时,会记录新插入行的所有字段的值,所以最后只会有一行数据不一致 - 主库A和从库B的同步线程都会报错并停止:
duplicate key error
小结
- 使用
ROW格式的binlog,数据不一致的问题更容易发现,采用MIXED或STATEMENT格式的binlog,数据可能悄悄地不一致 - 主从切换采用可用性优先策略,可能会导致数据不一致,大多数情况下,优先选择可靠性优先策略
- 在满足数据可靠性的前提下,MySQL的可用性依赖于同步延时的大小(同步延时越小,可用性越高)
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2017-05-13
InnoDB -- B+Tree索引
本文主要介绍InnoDB存储引擎的B+Tree索引 B+Tree数据结构 所有叶子节点出现在同一层 叶子节点包含关键字信息 叶子节点本身构成单向有序链表 叶子节点内部的记录也构成单向有序链表 索引节点不包含关键字信息,这样能容纳更多的索引信息,B+Tree的高度很低,查找效率很高 关于B+Tree的更多内容请查看维基百科 MyISAM与InnoDBMyISAM 索引文件与数据文件是**分离**的 MyISAM的索引文件采用B+Tree索引 叶子节点data域记录的是**数据存放的地址** 主索引(唯一)与辅助索引(可重复)在结构上没有任何区别 InnoDB 数据文件本身是按照B+Tree组织的索引结构(主索引:Primary Index或聚集索引:Clustered Index),而叶子节点data域记录的是**完整的数据信息** InnoDB**必须有主键**,如果没有显式定义主键或非NULL的唯一索引,InnoDB会自动生成6 Bytes的ROWID作为主键 辅助索引(Secondary Index)也是按B+Tree组织,叶子节点data域记录的是**主键值**,因此主键不宜定...

2019-03-16
MySQL -- 拷贝表
初始化123456789101112131415161718192021CREATE DATABASE db1;USE db1;CREATE TABLE t(id INT PRIMARY KEY, a INT, b INT, INDEX(a)) ENGINE=InnoDB;DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=1; WHILE (i <= 1000) DO INSERT INTO t VALUES (i,i,i); SET i=i+1; END WHILE;END;;DELIMITER ;CALL idata();CREATE DATABASE db2;CREATE TABLE db2.t LIKE db1.t;-- 目标:把db1.t里面a>900的数据导出来,插入到db2.t mysqldump12345$ mysqldump -uroot --add-locks=0 --no-create-info --single-transaction ...

2019-02-10
MySQL -- order by rand
单词表目的:随机选择3个单词 12345678910111213141516171819CREATE TABLE `words` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `word` VARCHAR(64) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;DELIMITER ;;CREATE PROCEDURE wdata()BEGIN DECLARE i INT; SET i=0; WHILE i<10000 DO INSERT INTO words(word) VALUES (CONCAT(CHAR(97+(i DIV 1000)), CHAR(97+(i % 1000 DIV 100)), CHAR(97+(i % 100 DIV 10)), CHAR(97+(i % 10)))); SET i=i+1; END WHILE;END;;DELIMITER ;CALL wdata(); 查询语句1SELECT word FROM words ORD...

2019-02-22
MySQL -- 主从复制的基本原理
主从切换 在状态1,客户端的读写都是直接访问节点A,节点B是节点A的从库 只是将节点A的更新都同步过来,在节点B本地执行,保持一致 在状态1,虽然节点B没有被直接访问,但依然建议设置成readonly模式 运营类的查询语句会在从库上执行,设置成readonly模式能够防止一些误操作 防止切换逻辑有Bug,例如出现双写,造成主从不一致 可以通过readonly状态来判断节点的角色 在状态1,节点B设置为readonly模式,同样能与节点A保持同步更新 readonly设置对超级权限用户是无效的,而节点B中用于同步更新的线程,就拥有超级权限 主从同步在节点A执行update语句,然后同步到节点B 从库B与主库A之间维持一个长连接,主库A内部有一个专门用于服务于从库B长连接的线程 在从库B上执行CHANGE MASTER命令,设置主库A的信息 IP、PORT、USER、PASSWORD 从哪个位置(文件名 + 日志偏移量)开始请求binlog 在从库B上执行START SLAVE命令,这时从库B会启动两个线程:io_thread + sql_thread io_thread:负责...

2019-01-31
MySQL -- 字符串索引
场景建表12345CREATE TABLE SUser( id BIGINT UNSIGNED PRIMARY KEY, name VARCHAR(64), email VARCHAR(64)) ENGINE=InnoDB; 查询1SELECT id,name,email FROM SUser WHERE email='[email protected]'; 创建索引12ALTER TABLE SUser ADD INDEX index1(email);ALTER TABLE SUser ADD INDEX index2(email(6)); index1 索引长度:整个字符串 从index1索引树找到第一个满足索引值为zhangssxyz@xxx.com的记录,取得主键为ID2 到聚簇索引上查找值为ID2的行,判断email的值是否正确(Server层行为),将该行记录加入结果集...
2019-03-16
MySQL -- INSERT语句的锁
INSERT…SELECT表初始化1234567891011121314CREATE TABLE `t` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `c` INT(11) DEFAULT NULL, `d` INT(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`)) ENGINE=InnoDB;INSERT INTO t VALUES (null,1,1);INSERT INTO t VALUES (null,2,2);INSERT INTO t VALUES (null,3,3);INSERT INTO t VALUES (null,4,4);CREATE TABLE t2 LIKE t; 操作序列 时刻 session A session B T1 BEGIN; T2 INSERT INTO t2(c,d) SELECT c,d FROM t; T3 INSERT INTO t VALUES (-1,-1,-1);(Blocked) 1234567--...




