
MySQL -- 主从复制的可靠性与可用性
Master-Master 主从切换
同步延时
- 主库A执行完成一个事务,写入binlog,记为
T1 - 然后传给从库B,从库B接收该binlog,记为
T2 - 从库B执行完成这个事务,记为
T3 - 同步延时:
T3-T1- 同一个事务,在从库执行完成的时间和主库执行完成的时间之间的差值
SHOW SLAVE STATUS中的Seconds_Behind_Master
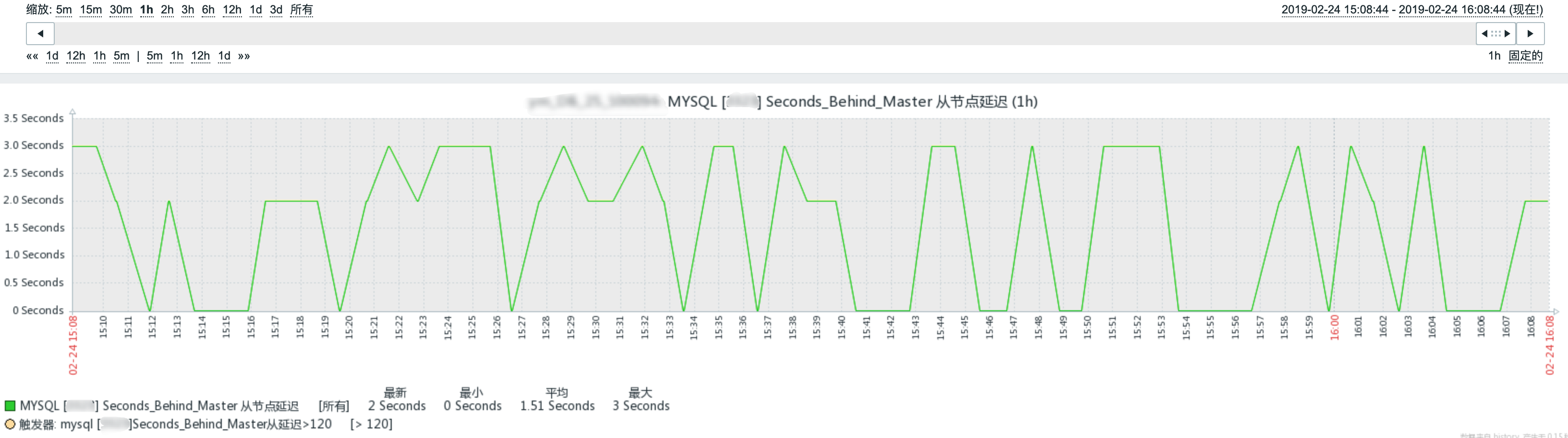
Seconds_Behind_Master
- 计算方法
- 每个事务的
binlog里面都有一个时间字段,用于记录该binlog在主库上的写入时间 - 从库取出当前正在执行的事务的时间字段的值,计算它与当前系统时间点差值,得到
Seconds_Behind_Master - 即
T3-T1
- 每个事务的
- 如果主库与从库的时间不一致,
Seconds_Behind_Master会不会有误差?- 一般不会
- 在从库连接到主库时,会通过
SELECT UNIX_TIMESTAMP()获取当前主库的系统时间 - 如果从库发现当前主库的系统时间与自己的不一致,在计算
Seconds_Behind_Master会自动扣除这部分差值 - 但建立连接后,主库或从库又修改了系统时间,依然会不准确
- 在网络正常的情况下,
T2-T1通常会非常小,此时同步延时的主要来源是**T3-T2**- 从库消费
relaylog的速度跟不上主库生成binlog的速度
- 从库消费
延时来源
- 从库所在机器的性能要弱于主库所在的机器
- 更新请求对于IPOS的压力,在主库和从库上是无差别的
- 非对称部署:20个主库放在4个机器上,但所有从库放在一个机器上
- 主从之间可能会随时切换,现在一般都会采用相同规格的机器+对称部署
- 从库压力大
- 常见场景:管理后台的查询语句
- 从库上的查询耗费大量的CPU资源和IO资源,影响了同步速度,造成了同步延时
- 解决方案
- 一主多从,分担读压力,一般都会采用
- 通过
binlog输出到外部系统,例如Hadoop
- 大事务
- 主库上必须等待事务执行完成后才会写入
binlog,再传给从库 - 常见场景1:一次性删除太多数据(如归档的历史数据)
- 解决方案:控制每个事务删除的数据量,分多次删除
- 常见场景2:大表DDL
- 解决方案:
gh-ost
- 解决方案:
- 主库上必须等待事务执行完成后才会写入
- 从库的并行复制能力(后续展开)
切换策略
可靠性优先
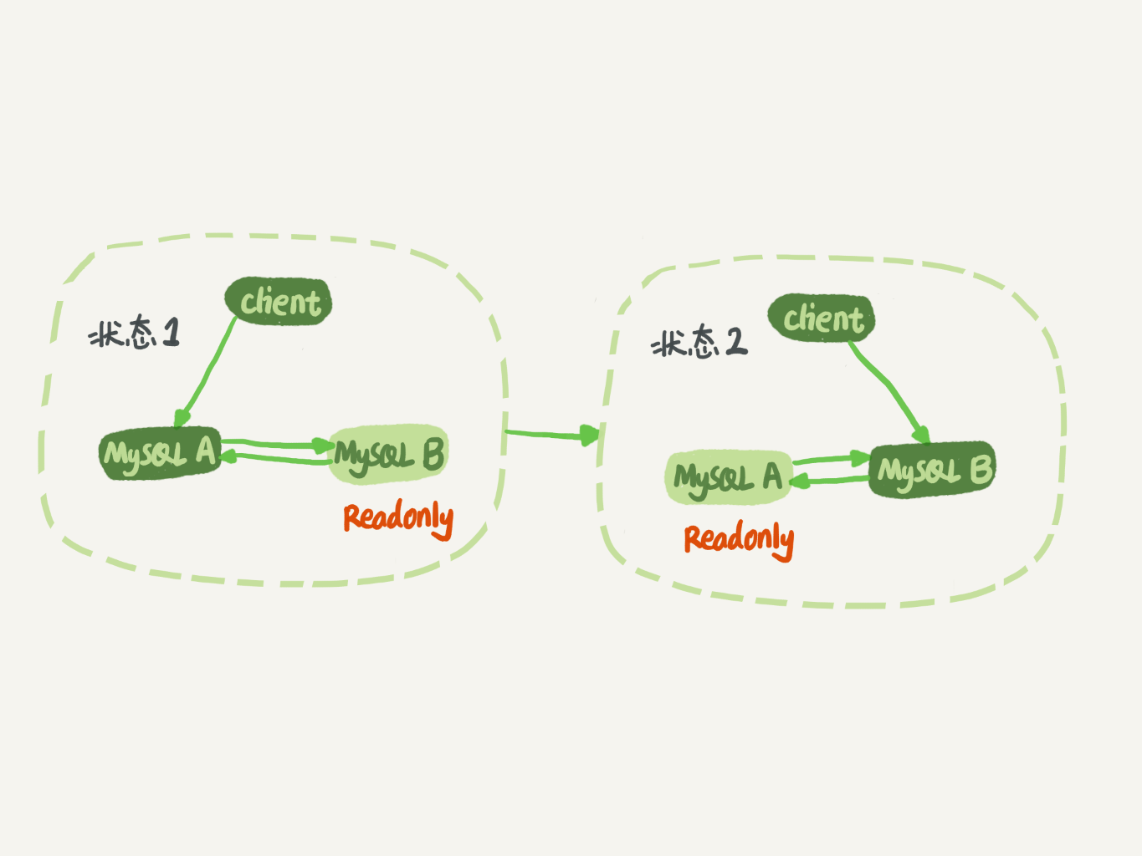
切换过程一般由专门的HA系统完成,存在不可用时间(主库A和从库B都处于只读状态)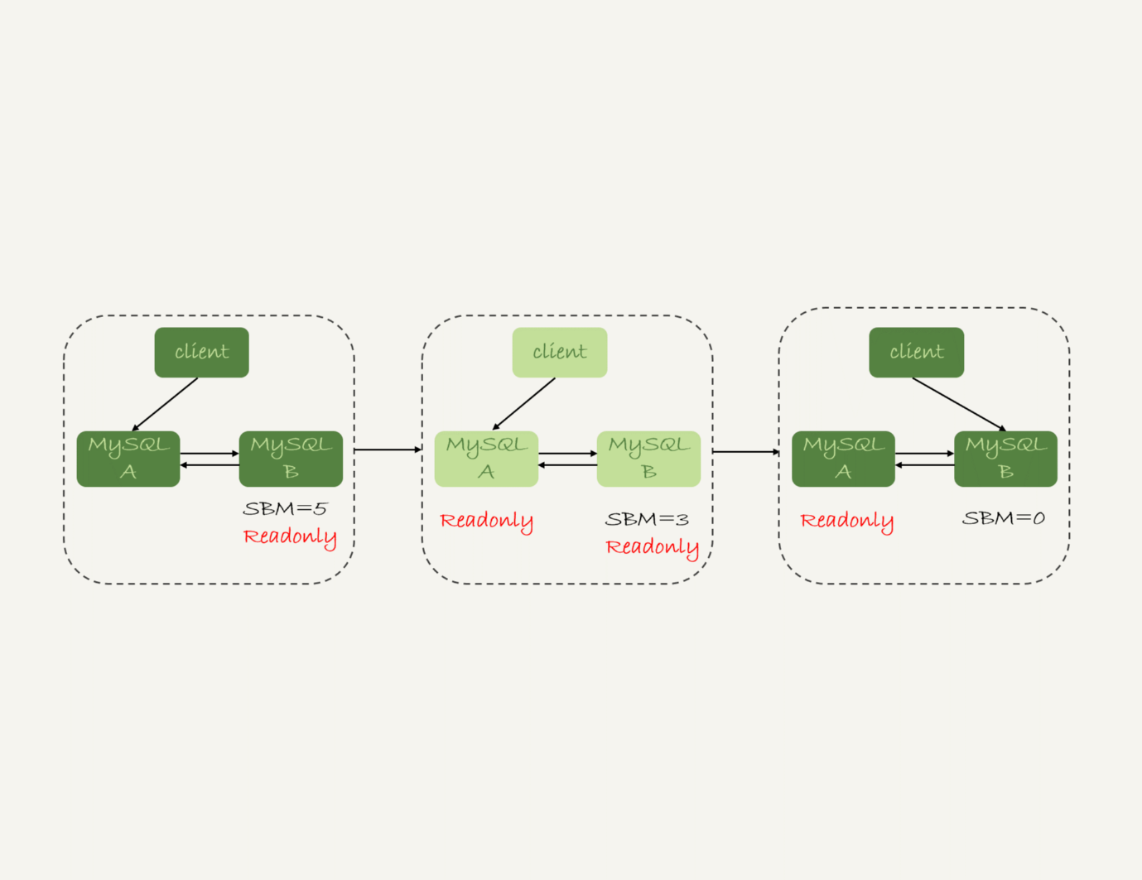
- 判断从库B的
Seconds_Behind_Master值,当小于某个值(例如5)才继续下一步 - 把主库A改为只读状态(
readonly=true) - 等待从库B的
Seconds_Behind_Master值降为0 - 把从库B改为可读写状态(
readonly=false) - 把业务请求切换至从库B
可用性优先
不等主从同步完成,直接把业务请求切换至从库B,并且让从库B可读写,这样几乎不存在不可用时间,但可能会数据不一致
表初始化
1 | CREATE TABLE `t` ( |
插入数据
1 | INSERT INTO t (c) VALUES (4); |
MIXED

- 主库A执行完
INSERT c=4,得到(4,4),然后开始执行主从切换 - 主从之间有5S的同步延迟,从库B会先执行
INSERT c=5,得到(4,5),并且会把这个binlog发给主库A - 从库B执行主库A传过来的
INSERT c=4,得到(5,4) - 主库A执行从库B传过来的
INSERT c=5,得到(5,5) - 此时主库A和从库B会有两行不一致的数据
ROW

- 采用
ROW格式的binlog时,会记录新插入行的所有字段的值,所以最后只会有一行数据不一致 - 主库A和从库B的同步线程都会报错并停止:
duplicate key error
小结
- 使用
ROW格式的binlog,数据不一致的问题更容易发现,采用MIXED或STATEMENT格式的binlog,数据可能悄悄地不一致 - 主从切换采用可用性优先策略,可能会导致数据不一致,大多数情况下,优先选择可靠性优先策略
- 在满足数据可靠性的前提下,MySQL的可用性依赖于同步延时的大小(同步延时越小,可用性越高)
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-03-14
MySQL -- Memory引擎
数据组织表初始化1234CREATE TABLE t1 (id INT PRIMARY KEY, c INT) ENGINE=Memory;CREATE TABLE t2 (id INT PRIMARY KEY, c INT) ENGINE=InnoDB;INSERT INTO t1 VALUES (1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);INSERT INTO t2 VALUES (1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0); 执行语句123456789101112131415161718192021222324252627282930313233-- 0在最后mysql> SELECT * FROM t1;+----+------+| id | c |+----+------+| 1 | 1 || 2 | 2 || 3 | 3 || 4 | 4 || 5 | 5 || 6 | 6 ||...

2019-01-29
MySQL -- 普通索引与唯一索引
场景 维护一个市民系统,有一个字段为身份证号 业务代码能保证不会写入两个重复的身份证号(如果业务无法保证,可以依赖数据库的唯一索引来进行约束) 常用SQL查询语句:SELECT name FROM CUser WHERE id_card = 'XXX' 建立索引 身份证号比较大,不建议设置为主键 从性能角度出发,选择普通索引还是唯一索引? 假设字段k上的值都不重复 查询过程 查询语句:SELECT id FROM T WHERE k=5 查询过程 通过B+树从树根开始,按层搜索到叶子节点,即上图中右下角的数据页 在数据页内部通过二分法来定位具体的记录 针对普通索引 查找满足条件的第一个记录(5,500),然后查找下一个记录,直到找到第一个不满足k=5的记录 针对唯一索引 由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续查找 性能差异 性能差异:微乎其微 InnoDB的数据是按照数据页为单位进行读写的,默认为16KB 当需要读取一条记录时,并不是将这个记录本身从磁盘读出来,而是以数据页为单位进行读取的 当找到k=5的记录时,它所在的数据页都...

2019-03-15
MySQL -- 自增主键
自增不连续表初始化1234567CREATE TABLE `t` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `c` INT(11) DEFAULT NULL, `d` INT(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`)) ENGINE=InnoDB; 自增值123456789101112131415INSERT INTO t VALUES (null,1,1);-- AUTO_INCREMENT=2,表示下一次插入数据时,如果需要自动生成自增值,会生成id=2mysql> SHOW CREATE TABLE t;+-------+---------------------------------------------+| Table | Create Table |+-------+---------------------------------------------+| t | CREATE T...

2019-02-22
MySQL -- 主从复制的基本原理
主从切换 在状态1,客户端的读写都是直接访问节点A,节点B是节点A的从库 只是将节点A的更新都同步过来,在节点B本地执行,保持一致 在状态1,虽然节点B没有被直接访问,但依然建议设置成readonly模式 运营类的查询语句会在从库上执行,设置成readonly模式能够防止一些误操作 防止切换逻辑有Bug,例如出现双写,造成主从不一致 可以通过readonly状态来判断节点的角色 在状态1,节点B设置为readonly模式,同样能与节点A保持同步更新 readonly设置对超级权限用户是无效的,而节点B中用于同步更新的线程,就拥有超级权限 主从同步在节点A执行update语句,然后同步到节点B 从库B与主库A之间维持一个长连接,主库A内部有一个专门用于服务于从库B长连接的线程 在从库B上执行CHANGE MASTER命令,设置主库A的信息 IP、PORT、USER、PASSWORD 从哪个位置(文件名 + 日志偏移量)开始请求binlog 在从库B上执行START SLAVE命令,这时从库B会启动两个线程:io_thread + sql_thread io_thread:负责...

2019-02-09
MySQL -- order by
市民信息123456789CREATE TABLE `t` ( `id` INT(11) NOT NULL, `city` VARCHAR(16) NOT NULL, `name` VARCHAR(16) NOT NULL, `age` INT(11) NOT NULL, `addr` VARCHAR(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`)) ENGINE=InnoDB; 查询语句1SELECT city,name,age FROM t WHERE city='杭州' ORDER BY name LIMIT 1000; 存储过程12345678910111213DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=0; WHILE i<4000 DO INSERT INTO t VALUES (i,'杭州',concat('zhongmingmao...

2019-02-21
MySQL -- 数据可靠性
binlog的写入机制 事务在执行过程中,先把日志写到binlog cache,事务提交时,再把binlog cache写到binlog file 一个事务的binlog是不能被拆开的,不论事务多大,也要确保一次性写入 系统会给每个线程分配一块内存binlog cache,由参数binlog_cache_size控制 如果超过了binlog_cache_size,需要暂存到磁盘 事务提交时,执行器把binlog cache里面的完整事务写入到binlog file,并清空binlog cache 12345678-- 2097152 Bytes = 2 MBmysql> SHOW VARIABLES LIKE '%binlog_cache_size%';+-----------------------+----------------------+| Variable_name | Value |+-----------------------+----------------------+| binlog_cache_siz...




