
MySQL -- JOIN优化
表初始化
1 | CREATE TABLE t1(id INT PRIMARY KEY, a INT, b INT, INDEX(a)); |
Multi-Range Read
MRR的目的:尽量使用顺序读盘
回表
1 | SELECT * FROM t1 WHERE a>=1 AND a<=100; |
如果随着a递增的顺序进行查询的话,id的值会变成随机的,就会出现随机访问,性能相对较差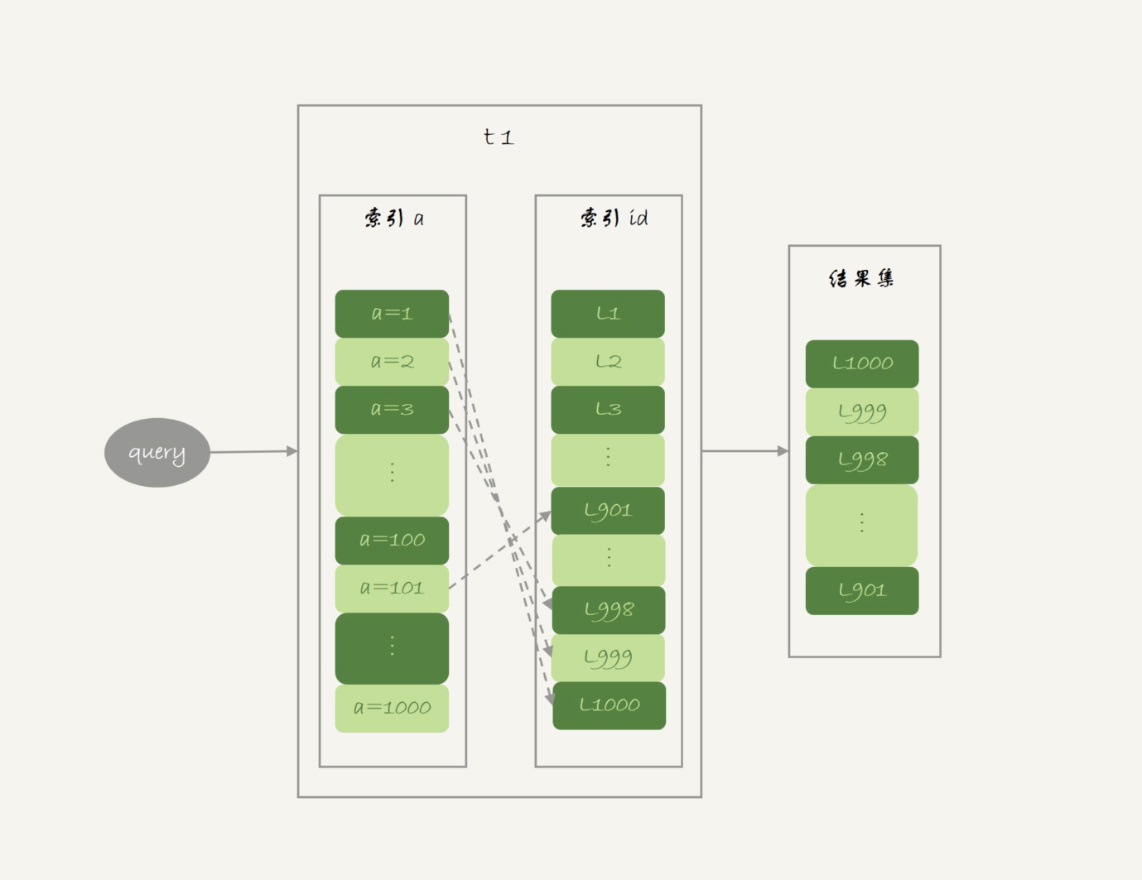
MRR
- 根据索引a,定位到满足条件的记录,将id的值放入
read_rnd_buffer中 - 将
read_rnd_buffer中的id进行递增排序 - 排序后的id值,依次到主键索引中查找
- 如果
read_rnd_buffer满,先执行完第2步和第3步,然后清空read_rnd_buffer,继续遍历索引a
1 | -- 默认值为256KB |
执行流程

EXPLAIN
1 | mysql> SET optimizer_switch='mrr_cost_based=on'; |
小结
MRR提升性能的核心:能够在索引a上做范围查询,得到足够多的主键,完成排序后再回表,体现出顺序性的优势
NLJ优化
NLJ算法
从驱动表t1,一行行地取出a的值,再到被驱动表t2去join,此时没有利用到MRR的优势
BKA优化
Batched Key Access,是MySQL 5.6引入的对Index Nested-Loop Join(NLJ)的优化
BKA优化的思路:复用join_buffer- 在
BNL算法中,利用了join_buffer来暂存驱动表的数据,但在NLJ里面并没有利用到join_buffer - 在
join_buffer中放入的数据为P1~P100,表示只会取查询所需要的字段- 如果
join_buffer放不下P1~P100,就会将这100行数据分成多段执行
- 如果
启用
1 | -- BKA算法依赖于MRR |
BNL优化
性能问题
- 使用
BNL算法,可能会对被驱动表做多次扫描,如果被驱动表是一个大的冷数据表,首先IO压力会增大 - Buffer Pool的LRU算法
- 第一次从磁盘读入内存的数据页,会先放在
old区 - 如果1s后这个数据页不再被访问,就不会被移动到LRU链表头部,对Buffer Pool的命中率影响不大
- 第一次从磁盘读入内存的数据页,会先放在
- 如果一个使用了BNL算法的Join语句,多次扫描一个冷表
- 如果冷表不大,能够完全放入old区
- 再次扫描冷表的时候,会把冷表的数据页移到LRU链表头部,不属于期望的晋升
- 如果冷表很大,_业务正常访问的数据页,可能没有机会进入young区_
- 一个正常访问的数据页,要进入young区,需要隔1S后再次被访问
- 由于Join语句在循环读磁盘和淘汰内存页,进入old区的数据页,很有可能在1S内被淘汰
- 正常业务访问的数据页也一并被冲掉,影响正常业务的内存命中率
- 如果冷表不大,能够完全放入old区
- 大表Join虽然对IO有影响,但在语句执行结束后,对IO的影响也就结束了
- 但对Buffer Pool的影响是持续性的,需要依靠后续的查询请求慢慢恢复内存命中率
- 为了减少这种影响,可以考虑适当地增大
join_buffer_size,减少对被驱动表的扫描次数
- 小结
- 可能会多次扫描被驱动表,占用磁盘IO资源
- 判断Join条件需要执行$M*N$次对比,如果是大表会占用非常多的CPU资源
- 可能会导致Buffer Pool的热数据被淘汰和正常的业务数据无法成为热数据,进而影响内存命中率
- 如果优化器选择了
BNL算法,就需要做优化- 给被驱动表Join字段加索引,把
BNL算法转换成BKA算法 - 临时表
- 给被驱动表Join字段加索引,把
不适合建索引
t2中需要参与Join的只有2000行,并且为一个低频语句,为此在t2.b上建索引是比较浪费的
1 | SELECT * FROM t1 JOIN t2 ON (t1.b=t2.b) WHERE t2.b>=1 AND t2.b<=2000; |
采用BNL
- 取出t1的所有字段,存入
join_buffer(无序数组),完全放得下 - 扫描t2,取出每一行数据跟
join_buffer中的数据进行对比- 如果不满足
t1.b=t2.b,则跳过 - 如果满足
t1.b=t2.b,_再判断是否满足其它条件_,如果满足就作为结果集的一部分返回,否则跳过
- 如果不满足
- 等值判断的次数为1000*100W=10亿,计算量很大
1 | -- 使用BNL算法 |
临时表
思路
- 把t2中满足条件的数据先放到临时表tmp_t中
- 为了让join使用
BKA算法,给临时表tmp_t的字段b加上索引 - 让表t1和tmp_t做join操作
执行过程
1 | CREATE TEMPORARY TABLE temp_t (id INT PRIMARY KEY, a INT, b INT, INDEX(b)) ENGINE=InnoDB; |
- 执行
INSERT语句构造tmp_t表并插入数据的过程中,对t2做了全表扫描,扫描行数为100W - JOIN语句先扫描t1,扫描行数为1000,在JOIN的比较过程中,做了1000次带索引的查询
Hash Join
- 如果
join_buffer维护的不是一个无序数组,而是一个哈希表,那只需要100W次哈希查找即可 - MySQL目前不支持
Hash Join,业务端可以自己实现Hash JoinSELECT * FROM t1- 取t1的全部1000行数据,在业务端存入一个hash结构(如
java.util.HashMap)
- 取t1的全部1000行数据,在业务端存入一个hash结构(如
SELECT * FROM t2 WHERE b>=1 AND b<=2000,获取t2中满足条件的2000行数据- 把这2000行数据,一行行地到hash结构去匹配,将满足匹配条件的行数据,作为结果集的一行
小结
BKA是MySQL内置支持的,_推荐使用_BNL算法效率低,建议都尽量换成BKA算法,优化的方向是给被驱动表的关联字段加上索引- 基于临时表的改进方案,对于能够提前过滤出小数据的JOIN语句来说,效果还是很明显的
- MySQL目前还不支持
Hash Join
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-01-21
MySQL -- 索引
索引模型哈希表实现上类似于java.util.HashMap,哈希表适合只有等值查询的场景 有序数组有序数组只适用于静态存储引擎(针对不会再修改的数据) 查找 等值查询:可以采用二分法,时间复杂度为O(log(N)) 范围查询:查找[ID_card_X,ID_card_Y] 首先通过二分法找到第一个大于等于ID_card_X的记录 然后向右遍历,直到找到第一个大于ID_card_Y的记录 更新在中间插入或删除一个纪录就得挪动后面的所有的记录 搜索树平衡二叉树查询的时间复杂度:O(log(N)),更新的时间复杂度:O(log(N))(维持树的平衡) N叉树 大多数的数据库存储并没有采用二叉树,原因:索引不仅仅存在于内存中,还要写到磁盘上 对于有100W节点的平衡二叉树,树高为20,即一次查询可能需要访问20个数据块 假设HDD,随机读取一个数据块需要10ms左右的寻址时间 即一次查询可能需要200ms – 慢成狗 为了让一个查询尽量少的读取磁盘,就必须让查询过程访问尽量少的数据块,因此采用N叉树 N的大小取决于数据页的大小和索引大小 在InnoDB中,以INT(4 Bytes)字段为索引,假...

2019-02-07
MySQL -- 无过滤条件的count
count(*)实现 MyISAM:将表的总行数存放在磁盘上,针对无过滤条件的查询可以直接返回 如果有过滤条件的count(*),MyISAM也不能很快返回 InnoDB:从存储引擎一行行地读出数据,然后累加计数 由于MVCC,在同一时刻,InnoDB应该返回多少行是不确定 样例假设表t有10000条记录 session A session B session C BEGIN; SELECT COUNT(*) FROM t;(返回10000) INSERT INTO t;(插入一行) BEGIN; INSERT INTO t(插入一行); SELECT COUNT(*) FROM t;(返回10000) SELECT COUNT(*) FROM t;(返回10002) SELECT COUNT(*) FROM T;(返回10001) 最后时刻三个会话同时查询t的总行数,拿到的结果却是不同的 InnoDB默认事务隔离级别是RR,通过MVCC实现 每个事务都需要判断每一行记录是否对自己可见 优化 InnoDB是索引组织表 聚簇索引...

2019-03-14
MySQL -- Memory引擎
数据组织表初始化1234CREATE TABLE t1 (id INT PRIMARY KEY, c INT) ENGINE=Memory;CREATE TABLE t2 (id INT PRIMARY KEY, c INT) ENGINE=InnoDB;INSERT INTO t1 VALUES (1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);INSERT INTO t2 VALUES (1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0); 执行语句123456789101112131415161718192021222324252627282930313233-- 0在最后mysql> SELECT * FROM t1;+----+------+| id | c |+----+------+| 1 | 1 || 2 | 2 || 3 | 3 || 4 | 4 || 5 | 5 || 6 | 6 ||...

2019-02-13
MySQL -- 问题排查
表初始化12345678910111213141516171819CREATE TABLE `t` ( `id` INT(11) NOT NULL, `c` INT(11) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=1; WHILE (i<=100000) DO INSERT INTO t VALUES (i,i); SET i=i+1; END WHILE;END;;DELIMITER ;CALL idata(); 查询长时间等待大概率是表t被锁住了,通过SHOW PROCESSLIST;查看语句处于什么状态 1SELECT * FROM t WHERE id=1; 等MDL执行时序 session A session B LOCK TABLE t WRITE; SELECT * FROM t WHERE id=1...
2019-03-17
MySQL -- 权限
创建用户1CREATE USER 'ua'@'%' IDENTIFIED BY 'pa'; 用户名+地址才表示一个用户,ua@ip1和ua@ip2代表的是两个不同的用户 在磁盘上,往mysql.user表里插入一行,由于没有指定权限,所有表示权限的字段都是N 在内存里,往数组acl_users里插入一个acl_user对象,该对象的access字段的值为0 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950mysql> SELECT * FROM mysql.user WHERE user = 'ua'\G;*************************** 1. row *************************** Host: % User: ua Select_priv: N ...

2019-02-09
MySQL -- order by
市民信息123456789CREATE TABLE `t` ( `id` INT(11) NOT NULL, `city` VARCHAR(16) NOT NULL, `name` VARCHAR(16) NOT NULL, `age` INT(11) NOT NULL, `addr` VARCHAR(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`)) ENGINE=InnoDB; 查询语句1SELECT city,name,age FROM t WHERE city='杭州' ORDER BY name LIMIT 1000; 存储过程12345678910111213DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=0; WHILE i<4000 DO INSERT INTO t VALUES (i,'杭州',concat('zhongmingmao...




