
MySQL -- 内部临时表
UNION
UNION语义:取两个子查询结果的并集,重复的行只保留一行
表初始化
1 | CREATE TABLE t1(id INT PRIMARY KEY, a INT, b INT, INDEX(a)); |
执行语句
1 | (SELECT 1000 AS f) UNION (SELECT id FROM t1 ORDER BY id DESC LIMIT 2); |
- 第二行的
Key=PRIMARY,说明第二个子查询用到了索引id - 第三行的Extra字段为
Using temporary- 表示在对子查询的结果做
UNION RESULT的时候,使用了临时表
- 表示在对子查询的结果做
UNION RESULT
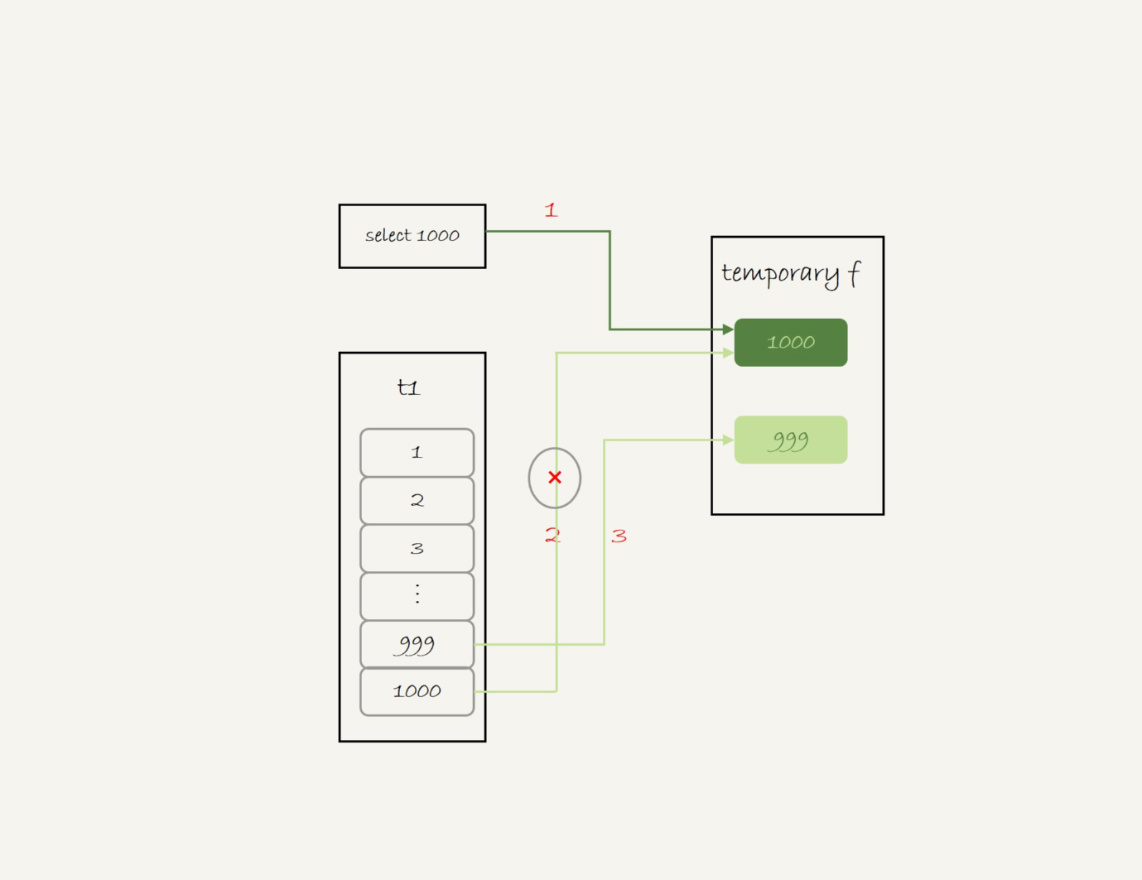
- 创建一个内存临时表,这个内存临时表只有一个整型字段f,并且f为主键
- 执行第一个子查询,得到1000,并存入内存临时表中
- 执行第二个子查询
- 拿到第一行id=1000,试图插入到内存临时表,但由于1000这个值已经存在于内存临时表
- 违反唯一性约束,插入失败,继续执行
- 拿到第二行id=999,插入内存临时表成功
- 拿到第一行id=1000,试图插入到内存临时表,但由于1000这个值已经存在于内存临时表
- 从内存临时表中按行取出数据,返回结果,并删除内存临时表,结果中包含id=1000和id=999两行
- 内存临时表起到了暂存数据的作用,还用到了内存临时表主键id的唯一性约束,实现UNION的语义
UNION ALL
UNION ALL没有去重的语义,一次执行子查询,得到的结果直接发给客户端,不需要内存临时表
1 | mysql> EXPLAIN (SELECT 1000 AS f) UNION ALL (SELECT id FROM t1 ORDER BY id DESC LIMIT 2); |
GROUP BY
内存充足
1 | -- 16777216 Bytes = 16 MB |
执行语句
1 | -- MySQL 5.6上执行 |
Using index:表示使用了覆盖索引,选择了索引a,不需要回表Using temporary:表示使用了临时表Using filesort:表示需要排序
执行过程
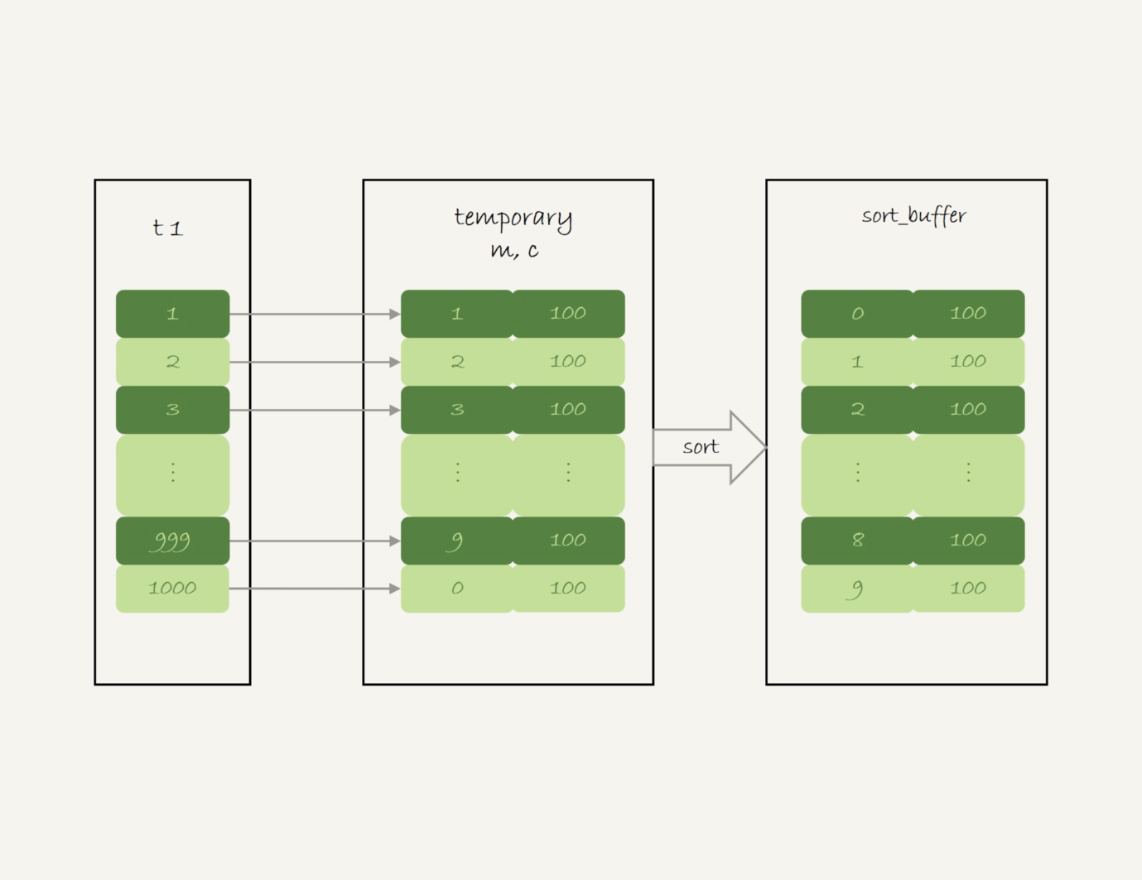
- 创建内存临时表,表里有两个字段m和c,m为主键
- 扫描t1的索引a,依次取出叶子节点上的id值,计算id%10,记为x
- 如果内存临时表中没有主键为x的行,插入一行记录
(x,1) - 如果内存临时表中有主键为x的行,将x这一行的c值加1
- 如果内存临时表中没有主键为x的行,插入一行记录
- 遍历完成后,再根据字段m做排序,得到结果集返回给客户端
排序过程
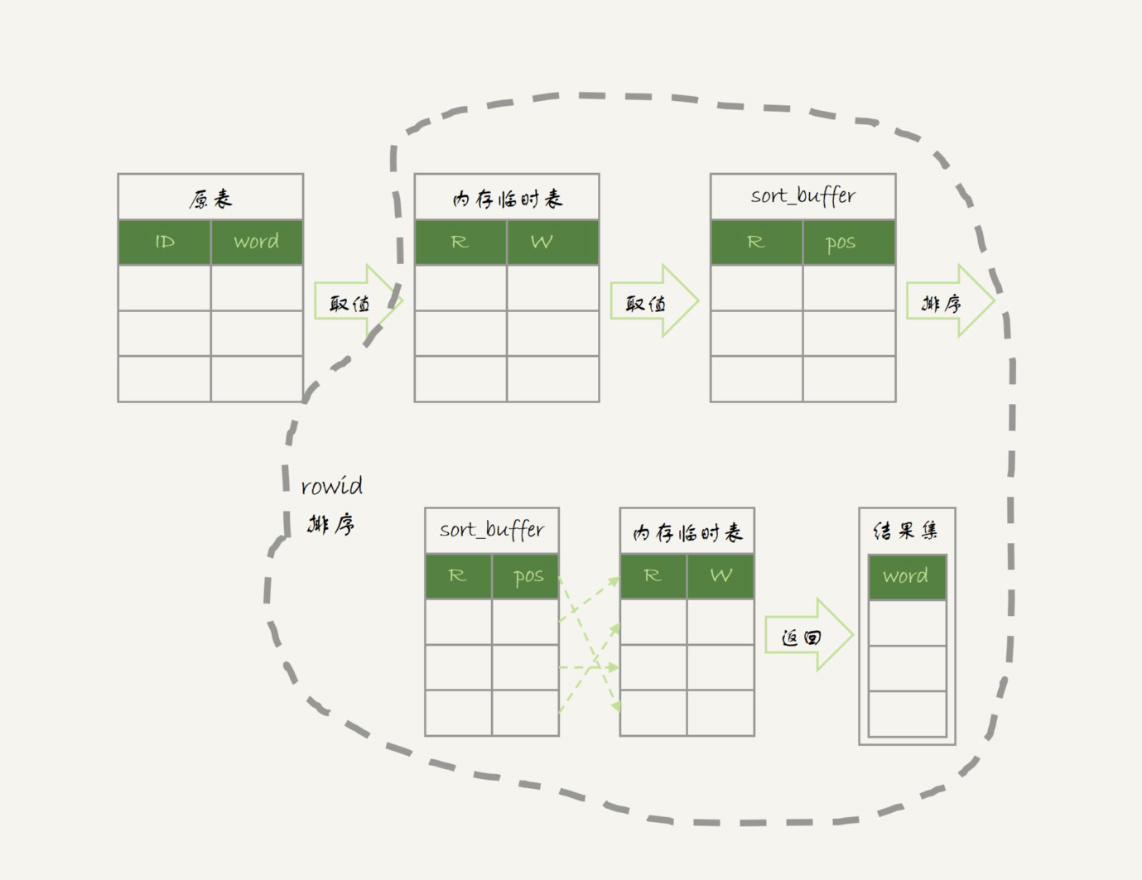
ORDER BY NULL
1 | -- 跳过最后的排序阶段,直接从临时表中取回数据 |
内存不足
1 | SET tmp_table_size=1024; |
执行语句
1 | -- 内存临时表的上限为1024 Bytes,但内存临时表不能完全放下100行数据,内存临时表会转成磁盘临时表,默认采用InnoDB引擎 |
优化方案
优化索引
- 不论使用内存临时表还是磁盘临时表,
GROUP BY都需要构造一个带唯一索引的表,_执行代价较高_ - 需要临时表的原因:每一行的
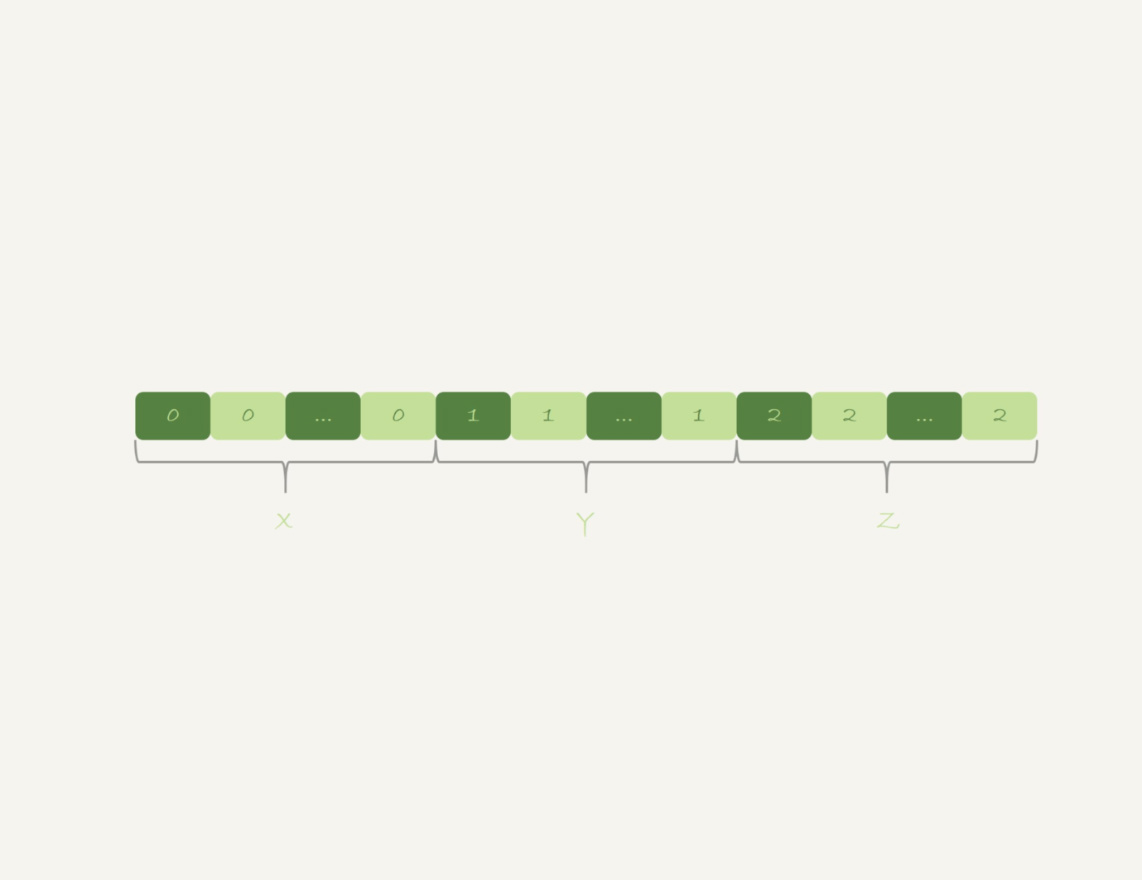
id%100是无序的,因此需要临时表,来记录并统计结果 - 如果可以确保输入的数据是有序的,那么计算
GROUP BY时,只需要从左到右顺序扫描,依次累加即可- 当碰到第一个1的时候,已经累积了X个0,结果集里的第一行为
(0,X) - 当碰到第一个2的时候,已经累积了Y个1,结果集里的第一行为
(1,Y) - 整个过程不需要临时表,也不需要排序
- 当碰到第一个1的时候,已经累积了X个0,结果集里的第一行为
1 | -- MySQL 5.7上执行 |
直接排序
- 一个
GROUP BY语句需要放到临时表的数据量特别大,还是按照先放在内存临时表,再退化成磁盘临时表 - 可以直接用磁盘临时表的形式,在
GROUP BY语句中SQL_BIG_RESULT(告诉优化器涉及的数据量很大) - 磁盘临时表原本采用B+树存储,存储效率还不如数组,优化器看到
SQL_BIG_RESULT,会直接用数组存储- 即放弃使用临时表,_直接进入排序阶段_
执行过程
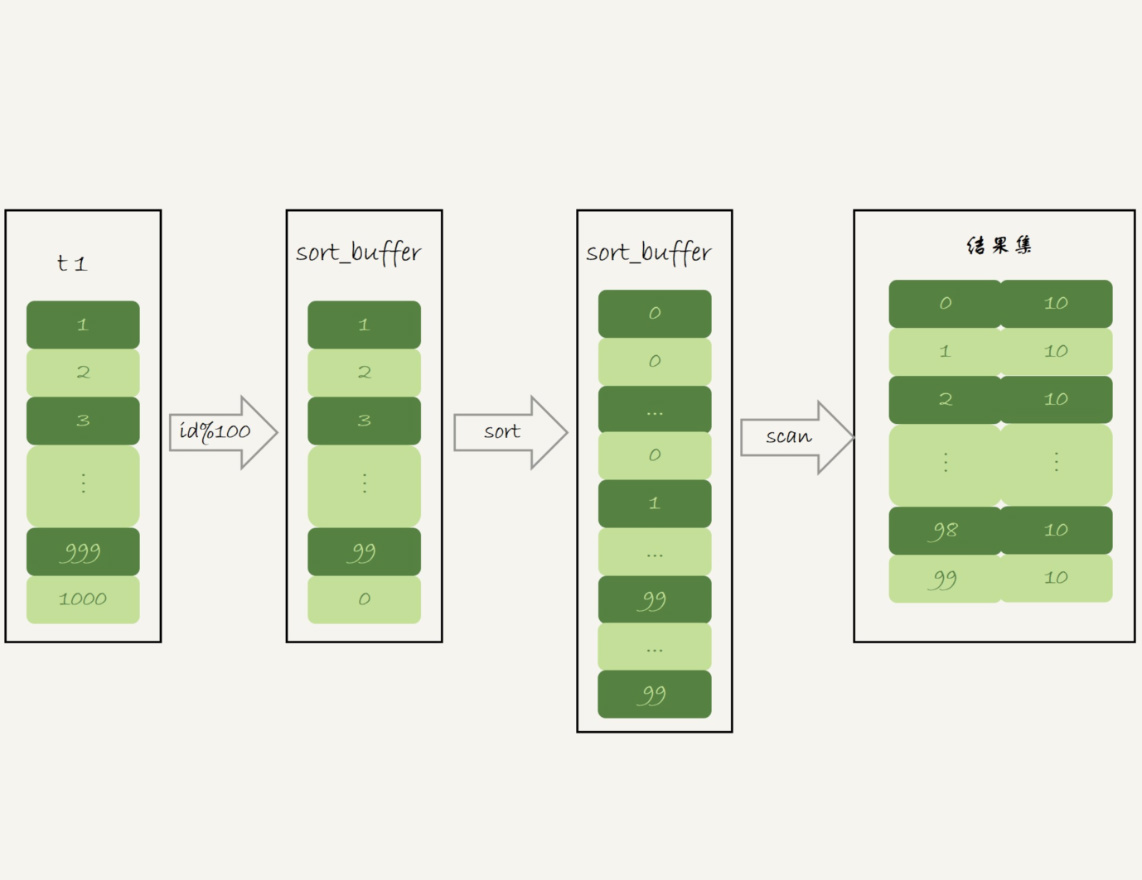
1 | -- 没有再使用临时表,而是直接使用了排序算法 |
- 初始化
sort_buffer,确定放入一个整型字段,记为m - 扫描t1的索引a,依次取出里面的id值,将id%100的值放入
sort_buffer - 扫描完成后,对
sort_buffer的字段m做排序(sort_buffer内存不够时,会利用磁盘临时文件辅助排序) - 排序完成后,得到一个有序数组,遍历有序数组,得到每个值出现的次数(类似上面优化索引的方式)
对比DISTINCT
1 | -- 标准SQL,SELECT部分添加一个聚合函数COUNT(*) |
- 标准SQL:按照字段a分组,计算每组a出现的次数
- 非标准SQL:没有了
COUNT(*),不再需要执行计算总数的逻辑- 按照字段a分组,相同的a的值只返回一行,与
DISTINCT语义一致
- 按照字段a分组,相同的a的值只返回一行,与
- 如果不需要执行聚合函数,
DISTINCT和GROUP BY的语义、执行流程和执行性能是相同的- 创建一个临时表,临时表有一个字段a,并且在这个字段a上创建一个唯一索引
- 遍历表t,依次取出数据插入临时表中
- 如果发现唯一键冲突,就跳过
- 否则插入成功
- 遍历完成后,将临时表作为结果集返回给客户端
小结
- 用到内部临时表的场景
- 如果语句执行过程中可以一边读数据,一边得到结果,是不需要额外内存的
- 否则需要额外内存来保存中间结果
join_buffer是无序数组,sort_buffer是有序数组,临时表是二维表结构- 如果执行逻辑需要用到二维表特性,就会优先考虑使用临时表
- 如果对
GROUP BY语句的结果没有明确的排序要求,加上ORDER BY NULL(MySQL 5.6) - 尽量让
GROUP BY过程用上索引,确认EXPLAIN结果没有Using temporary和Using filesort - 如果
GROUP BY需要统计的数据量不大,尽量使用内存临时表(可以适当调大tmp_table_size) - 如果数据量实在太大,使用
SQL_BIG_RESULT来告诉优化器直接使用排序算法(跳过临时表)
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2017-05-22
InnoDB -- 事务隔离级别
本文主要介绍InnoDB的事务隔离级别关于Next-Key Lock的内容,请参照「InnoDB备忘录 - Next-Key Lock」,这里不再赘述 脏读、不可重复读、幻读脏读在不同的事务下,当前事务可以读到其它事务中尚未提交的数据,即可以读到脏数据 不可重复读在同一个事务中,同一个查询在T1时间读取某一行,在T2时间重新读取这一行时候,这一行的数据已经发生修改,不可重复读的重点是修改(Update) 幻读在同一事务中,同一查询多次进行,由于包含插入或删除操作的其他事务提交,导致每次返回不同的结果集,幻读的重点在于插入(Insert)或者删除(Delete) 两类读操作一致性非锁定读 InnoDB通过行多版本控制的方式来读取当前执行时间数据中行的数据,如果读取的行正在执行DELETE或UPDATE操作,这时读操作不会等待行上锁的释放,而是读取行的一个快照数据 非锁定读机制极大地提高了数据库的并发性,这是InnoDB默认的读取方式 READ COMMITED和REPEATABLE READ支持一致性非锁定读:在READ COMMITED下,总是读取被锁定行的最新的快照数据,在REPEATABLE...

2019-03-14
MySQL -- Memory引擎
数据组织表初始化1234CREATE TABLE t1 (id INT PRIMARY KEY, c INT) ENGINE=Memory;CREATE TABLE t2 (id INT PRIMARY KEY, c INT) ENGINE=InnoDB;INSERT INTO t1 VALUES (1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);INSERT INTO t2 VALUES (1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0); 执行语句123456789101112131415161718192021222324252627282930313233-- 0在最后mysql> SELECT * FROM t1;+----+------+| id | c |+----+------+| 1 | 1 || 2 | 2 || 3 | 3 || 4 | 4 || 5 | 5 || 6 | 6 ||...
2019-01-31
MySQL -- 字符串索引
场景建表12345CREATE TABLE SUser( id BIGINT UNSIGNED PRIMARY KEY, name VARCHAR(64), email VARCHAR(64)) ENGINE=InnoDB; 查询1SELECT id,name,email FROM SUser WHERE email='[email protected]'; 创建索引12ALTER TABLE SUser ADD INDEX index1(email);ALTER TABLE SUser ADD INDEX index2(email(6)); index1 索引长度:整个字符串 从index1索引树找到第一个满足索引值为zhangssxyz@xxx.com的记录,取得主键为ID2 到聚簇索引上查找值为ID2的行,判断email的值是否正确(Server层行为),将该行记录加入结果集...

2019-03-04
MySQL -- 数据恢复
DELETE 使用DELETE语句误删除了数据行,可以使用Flashback通过闪回把数据恢复 Flashback恢复数据的原理:修改binlog的内容,然后拿到原库重放 前提:binlog_format=ROW和binlog_row_image=FULL 针对单个事务 对于INSERT语句,将Write_rows event改成Delete_rows event 对于DELETE语句,将Delete_rows event改成Write_rows event 对于UPDATE语句,binlog里面记录了数据行修改前和修改后的值,对调两行的位置即可 针对多个事务 误操作 (A)DELETE (B)INSERT (C)UPDTAE Flashback (REVERSE C)UPDATE (REVERSE B)DELETE (REVERSE A)INSERT 不推荐直接在主库上执行上述操作,避免造成二次破坏 比较安全的做法是先恢复出一个备份或找一个从库作为临时库 在临时库上执行上述操作,然后再将确认过的临时库的数据,恢复到主库 预防措施 sql_safe_updates=ON,下列情况...

2019-01-31
MySQL -- flush
脏页 + 干净页 脏页:内存数据页与磁盘数据页内容不一致 干净页:内存数据页与磁盘数据页内容一致 flush:将内存中的脏页写入磁盘 flush – 刷脏页;purge – 清undolog;merge – 应用change buffer flush过程 触发flushredolog写满 当InnoDB的redolog写满,系统会停止所有的更新操作,推进checkpoint 把checkpoint从CP推进到CP’,需要将两点之间的日志(绿色),所对应的所有脏页都flush到磁盘上 然后write pos到CP’之间(红色+绿色)可以再写入redolog 性能影响InnoDB应该尽量避免,此时所有更新都会被堵住,更新数(写性能)跌为0 内存不足 当需要新的内存页,而内存不够用时,就需要淘汰一些内存数据页(LRU) 如果淘汰的是脏页,就需要先将脏页flush到磁盘 该过程不会动redolog,因为redolog在重放的时候 如果一个数据页已经flush过,会识别出来并跳过 性能影响 这种情况是常态,InnoDB使用buffer pool管理内存 buffer pool中内存页有3种状...
2019-03-12
MySQL -- 用户临时表
临时表 VS 内存表 内存表,指的是使用Memory引擎的表,建表语法:CREATE TABLE ... ENGINE=Memory 所有数据都保存在内存中,系统重启时被清空,但表结构还在 临时表,可以使用各种引擎 如果使用的是InnoDB或者MyISAM引擎,数据需要写到磁盘上 当然也可以使用Memory引擎 特征 session A session B CREATE TEMPORARY TABLE t(c int) ENGINE=MyISAM;(创建临时表) SHOW CREATE TABLE t;(Table ‘test.t’ doesn’t exist) CREATE TABLE t(id INT PRIMARY KEY) ENGINE=InnoDB;(创建普通表) SHOW CREATE TABLE t;(显示临时表) SHOW TABLES;(显示普通表) INSERT INTO t VALUES (1); SELECT * FROM t;(返回1) SELECT * FROM t;(Empty set) ...




