
MySQL -- Memory引擎
数据组织
表初始化
1 | CREATE TABLE t1 (id INT PRIMARY KEY, c INT) ENGINE=Memory; |
执行语句
1 | -- 0在最后 |
组织形式
- 索引组织表(Index Organizied Table):InnoDB引擎把数据放在主键索引上,其它索引上保存主键ID
- 堆组织表(Heap Organizied Table):Memory引擎把数据单独存放,索引上保存数据位置
索引组织表
t2的数据组织方式,主键索引上的值是有序存储的,执行SELECT *时,按叶子节点从左到右扫描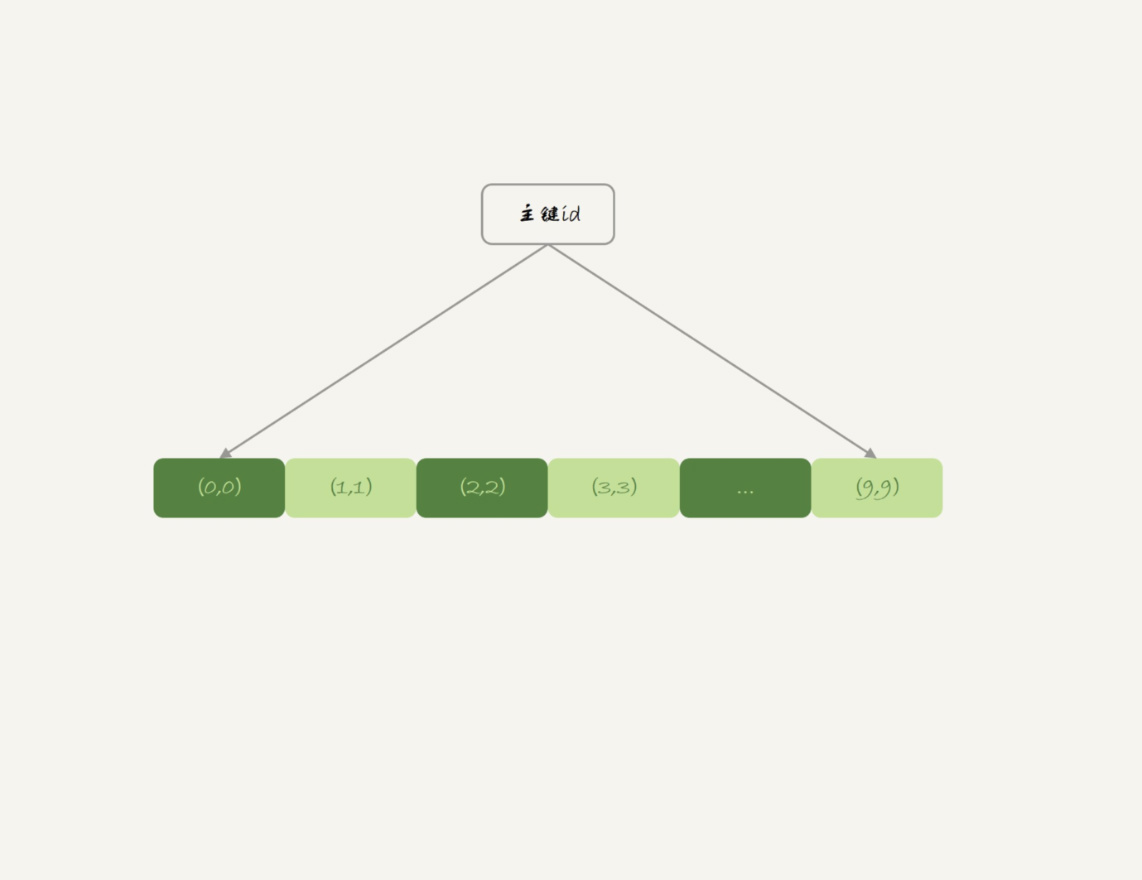
堆组织表
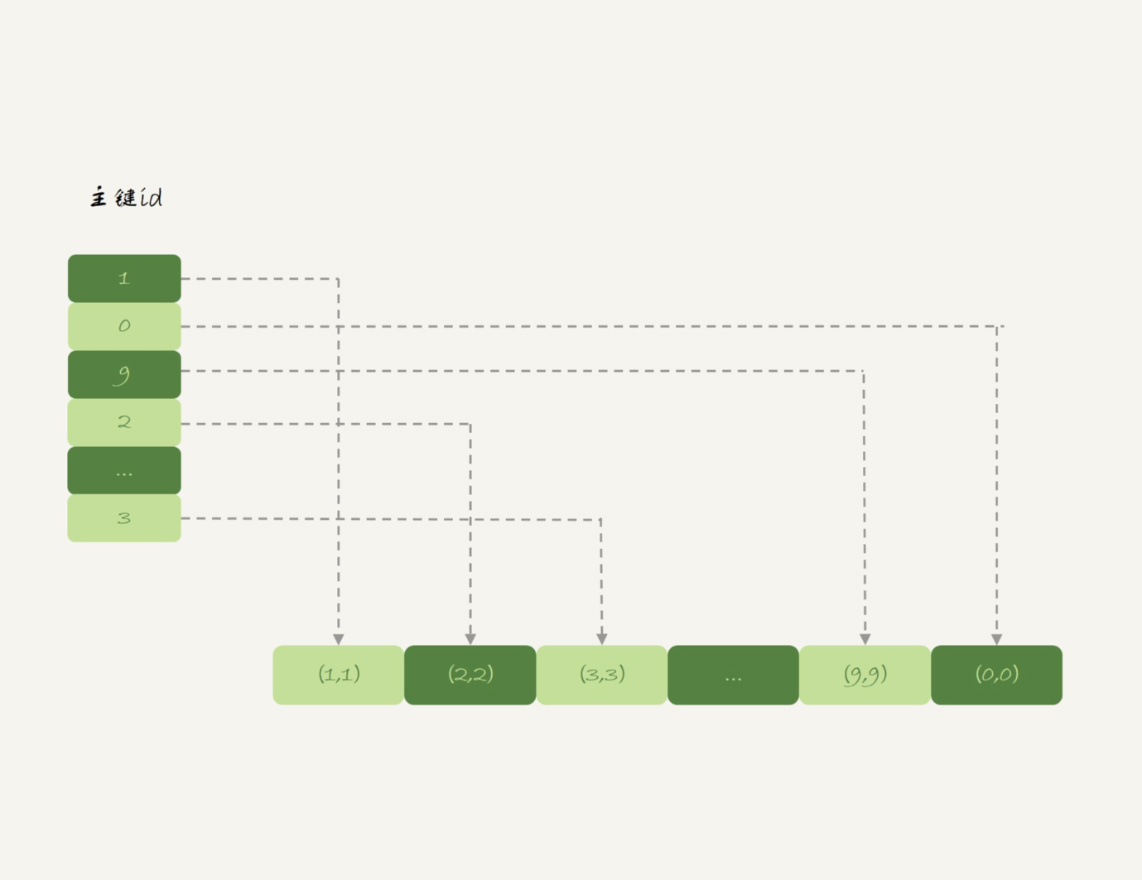
- Memory引擎的数据和索引是分开存储的
- 数据部分以数组的方式单独存放,主键索引(采用哈希索引)存的是数据位置
- 在t1上执行
SELECT *时,走的也是全表扫描,即顺序扫描整个数组,因此0是最后一个被读到的 - t1的主键索引是哈希索引,如果是范围查询,需要走全表扫描,例如
SELECT * FROM t1 WHERE id<5 - Memory表也支持B-Tree索引
B-Tree索引
1 | ALTER TABLE t1 ADD INDEX a_btree_index USING BTREE (id); |
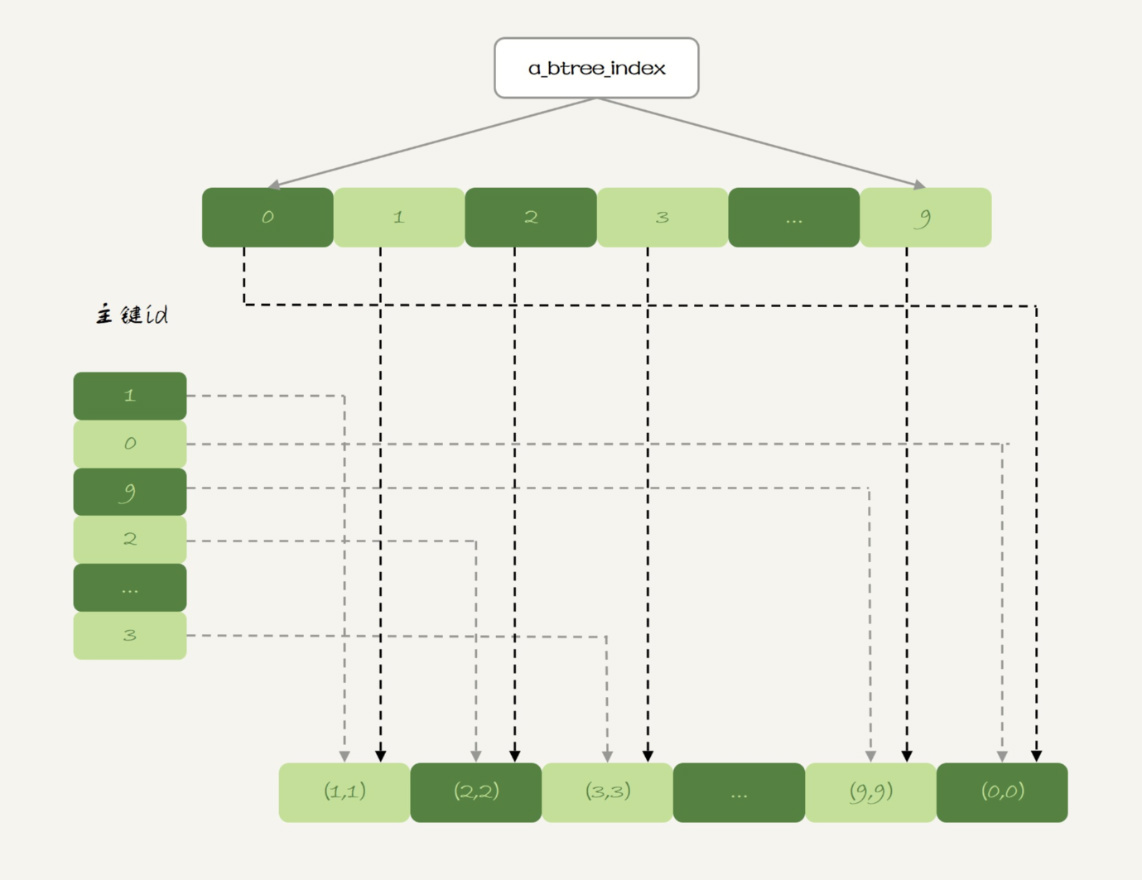
1 | -- 优化器选择了a_btree_index索引 |
对比
- InnoDB的数据总是有序存放的,而内存表的数据是按照写入顺序存放的
- 当数据文件有空洞时
- InnoDB表在插入新数据时,为了保证数据的有序性,只能在固定位置写入新值
- 而Memory表只要找到空位就可以插入新值
- 数据位置发生变化时,InnoDB只需要修改主键索引,而Memory表需要修改所有索引
- 数据查找
- InnoDB表利用主键查找需要走一次索引查找,用辅助索引查找需要走两次索引查找
- Memory表中所有索引的地位都是相同的
- 变长数据类型
- InnoDB表支持变长数据类型
- Memory表不支持
BLOB和TEXT类型- 即使定义了
VARCHAR(N),实际也会当做CHAR(N),固定长度 - 因此Memory表的每行数据长度相同
- 每个数据被删除后,空出的位置可以被接下来要插入的数据复用
- 即使定义了
1 | DELETE FROM t1 WHERE id=5; |
缺点
不推荐在生产环境使用Memory表
锁粒度
Memory表不支持行锁,只支持表锁(并不是MDL锁),对并发访问的支持不够好
| session A | session B | session C |
|---|---|---|
| UPDATE t1 SET id=SLEEP(50) WHERE id=1; | ||
| SELECT * FROM t1 WHERE id=2; (Wait 50s) |
||
| SHOW PROCESSLIST; |
1 | mysql> SHOW PROCESSLIST; |
数据持久化
数据库重启后,所有的Memory表都会被清空
Master-Slave架构
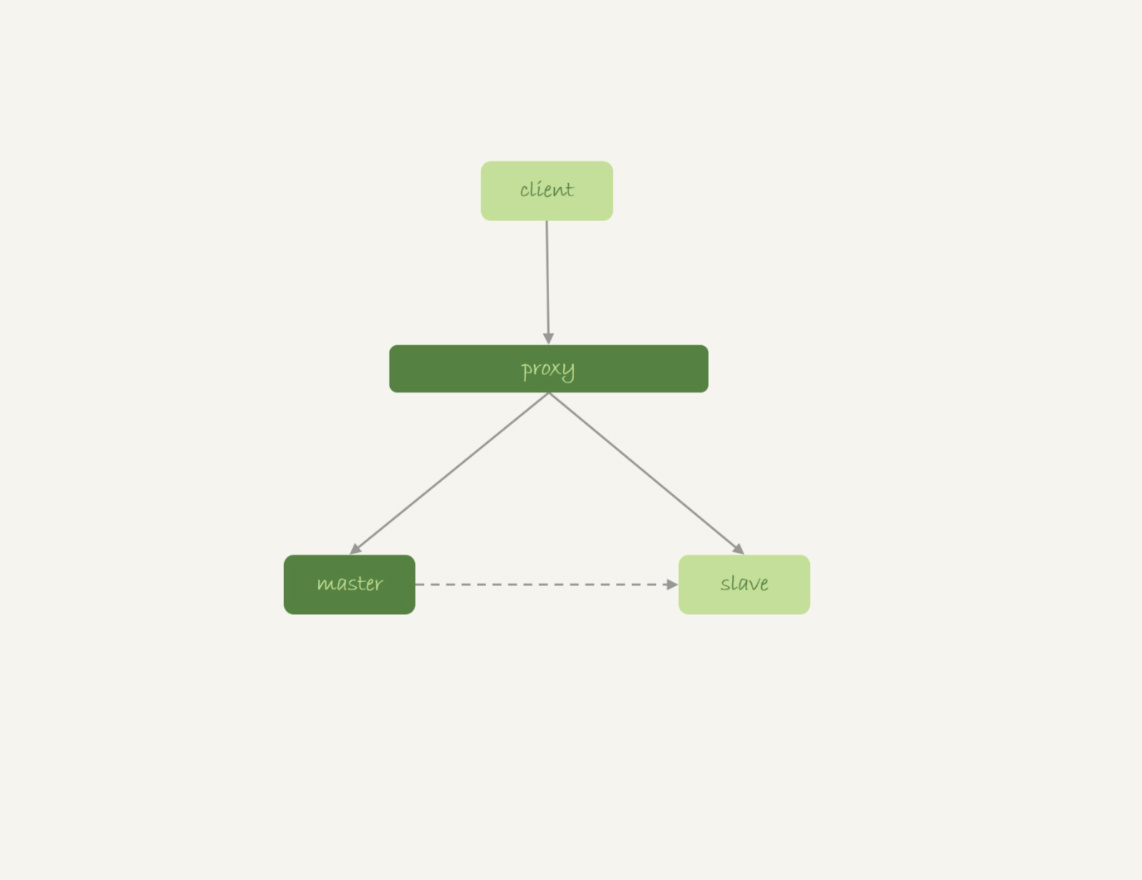
- 业务正常访问主库
- 备库硬件升级,备库重启,内存表t1被清空
- 备库重启后,应用日志线程执行一条
UPDATE t1的语句,备库会报错,导致主备同步停止 - 如果期间发生主备切换,客户端会看到t1的数据丢失了
Master-Master架构
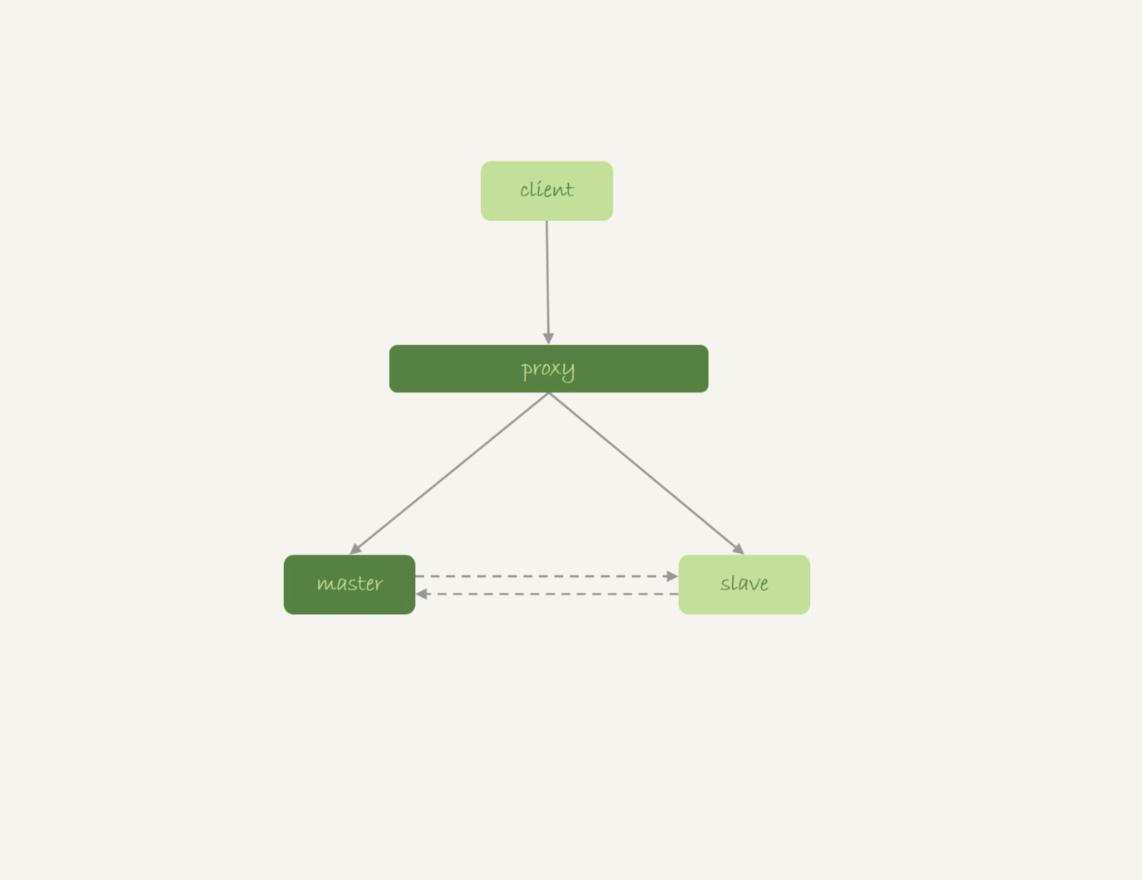
- MySQL知道重启后,Memory表的数据会丢失,所以担心主库重启后,会出现主备不一致
- 在数据库重启之后,自动往binlog里面写一行
DELETE FROM t1
- 在数据库重启之后,自动往binlog里面写一行
- 在备库重启时,备库binlog的
DELETE语句会传到主库,然后主库Memory表的内容被莫名其妙地删除了
选择InnoDB
- 如果表的更新量很大,那么并发度是一个很重要的参考指标,InnoDB支持行锁
- 能放到Memory表的数据量都不大,InnoDB也有
Buffer Pool,读性能也不差 - 建议将普通Memory表替换成InnoDB表
- 例外场景:在数据量可控,可以采用内存临时表,例如JOIN优化里面的临时表优化
CREATE TEMPORARY TABLE ... ENGINE=Memory
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2017-05-13
InnoDB -- B+Tree索引
本文主要介绍InnoDB存储引擎的B+Tree索引 B+Tree数据结构 所有叶子节点出现在同一层 叶子节点包含关键字信息 叶子节点本身构成单向有序链表 叶子节点内部的记录也构成单向有序链表 索引节点不包含关键字信息,这样能容纳更多的索引信息,B+Tree的高度很低,查找效率很高 关于B+Tree的更多内容请查看维基百科 MyISAM与InnoDBMyISAM 索引文件与数据文件是**分离**的 MyISAM的索引文件采用B+Tree索引 叶子节点data域记录的是**数据存放的地址** 主索引(唯一)与辅助索引(可重复)在结构上没有任何区别 InnoDB 数据文件本身是按照B+Tree组织的索引结构(主索引:Primary Index或聚集索引:Clustered Index),而叶子节点data域记录的是**完整的数据信息** InnoDB**必须有主键**,如果没有显式定义主键或非NULL的唯一索引,InnoDB会自动生成6 Bytes的ROWID作为主键 辅助索引(Secondary Index)也是按B+Tree组织,叶子节点data域记录的是**主键值**,因此主键不宜定...

2017-05-07
InnoDB -- 行记录格式
本文主要介绍InnoDB存储引擎的行记录格式ROW_FORMAT 分类 Named File Format InnoDB早期的文件格式(页格式)为Antelope,可以定义两种行记录格式,分别是Compact和Redundant Named File Format为了解决不同版本下页结构的兼容性,在Barracuda可以定义两种新的行记录格式Compressed和Dynamic 变量为innodb_file_format和innodb_default_row_format 123456789101112131415mysql> SHOW VARIABLES LIKE 'innodb_file_format';+--------------------+-----------+| Variable_name | Value |+--------------------+-----------+| innodb_file_format | Barracuda |+--------------------+-----------+1 row in se...

2019-03-13
MySQL -- 内部临时表
UNIONUNION语义:取两个子查询结果的并集,重复的行只保留一行 表初始化1234567891011121314CREATE TABLE t1(id INT PRIMARY KEY, a INT, b INT, INDEX(a));DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=1; WHILE (i<= 1000) DO INSERT INTO t1 VALUES (i,i,i); SET i=i+1; END WHILE;END;;DELIMITER ;CALL idata(); 执行语句12345678910(SELECT 1000 AS f) UNION (SELECT id FROM t1 ORDER BY id DESC LIMIT 2);mysql> EXPLAIN (SELECT 1000 AS f) UNION (SELECT id FROM t1 ORDER BY id DESC LIMIT 2);+----+------------...

2017-05-19
InnoDB -- Next-Key Lock
本文主要介绍InnoDB存储引擎的Next-Key Lock MVCC InnoDB支持MVCC,与之MVCC相对的是LBCC MVCC中读操作分两类:Snapshot Read(不加锁)和Current Read(加锁) MVCC的好处:**Snapshot Read不加锁**,并发性能好,适用于常规的JavaWeb项目(OLTP应用) 隔离级别InnoDB支持4种事务隔离级别(Isolation Level) 隔离级别 描述 READ UNCOMMITTED (RUC) 可以读取到其他事务中尚未提交的内容,生产环境中不会使用 READ COMMITTED (RC) 可以读取到其他事务中已经提交的内容,Current Read会加锁,存在幻读现象,Oracle和SQL Server的默认事务隔离级别为RC REPEATABLE READ (RR) 保证事务的隔离性,Current Read会加锁,同时会加Gap Lock,不存在幻读现象,InnoDB的默认事务隔离级别为RR SERIALIZABLE MVCC退化为LBCC,不区分Snapshot Read和Curre...

2019-01-21
MySQL -- 索引
索引模型哈希表实现上类似于java.util.HashMap,哈希表适合只有等值查询的场景 有序数组有序数组只适用于静态存储引擎(针对不会再修改的数据) 查找 等值查询:可以采用二分法,时间复杂度为O(log(N)) 范围查询:查找[ID_card_X,ID_card_Y] 首先通过二分法找到第一个大于等于ID_card_X的记录 然后向右遍历,直到找到第一个大于ID_card_Y的记录 更新在中间插入或删除一个纪录就得挪动后面的所有的记录 搜索树平衡二叉树查询的时间复杂度:O(log(N)),更新的时间复杂度:O(log(N))(维持树的平衡) N叉树 大多数的数据库存储并没有采用二叉树,原因:索引不仅仅存在于内存中,还要写到磁盘上 对于有100W节点的平衡二叉树,树高为20,即一次查询可能需要访问20个数据块 假设HDD,随机读取一个数据块需要10ms左右的寻址时间 即一次查询可能需要200ms – 慢成狗 为了让一个查询尽量少的读取磁盘,就必须让查询过程访问尽量少的数据块,因此采用N叉树 N的大小取决于数据页的大小和索引大小 在InnoDB中,以INT(4 Bytes)字段为索引,假...

2017-05-22
InnoDB -- 事务隔离级别
本文主要介绍InnoDB的事务隔离级别关于Next-Key Lock的内容,请参照「InnoDB备忘录 - Next-Key Lock」,这里不再赘述 脏读、不可重复读、幻读脏读在不同的事务下,当前事务可以读到其它事务中尚未提交的数据,即可以读到脏数据 不可重复读在同一个事务中,同一个查询在T1时间读取某一行,在T2时间重新读取这一行时候,这一行的数据已经发生修改,不可重复读的重点是修改(Update) 幻读在同一事务中,同一查询多次进行,由于包含插入或删除操作的其他事务提交,导致每次返回不同的结果集,幻读的重点在于插入(Insert)或者删除(Delete) 两类读操作一致性非锁定读 InnoDB通过行多版本控制的方式来读取当前执行时间数据中行的数据,如果读取的行正在执行DELETE或UPDATE操作,这时读操作不会等待行上锁的释放,而是读取行的一个快照数据 非锁定读机制极大地提高了数据库的并发性,这是InnoDB默认的读取方式 READ COMMITED和REPEATABLE READ支持一致性非锁定读:在READ COMMITED下,总是读取被锁定行的最新的快照数据,在REPEATABLE...




