
MySQL -- 拷贝表
初始化
1 | CREATE DATABASE db1; |
mysqldump
1 | $ mysqldump -uroot --add-locks=0 --no-create-info --single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --result-file=/tmp/t.sql |
- mysqldump命令将数据导出成一组
INSERT语句,把结果输出到客户端的临时文件 --single-transaction- 导出数据时不需要对表db1.t加表锁
- 采用的是
START TRANSACTION WITH CONSISTENT SNAPSHOT
--add-locks=0- 表示在输出到文件结果里,不增加
LOCK TABLES t WRITE
- 表示在输出到文件结果里,不增加
--no-create-info- 不需要导出表结构
--set-gtid-purged=OFF- 不输出跟GTID相关的信息
--result-file- 执行客户端上输出文件的路径
- 输出结果中的
INSERT语句会包含多个value对,为了后续如果使用这个文件写入数据,执行会更快- 如果要一个
INSERT语句只插入一行数据的话,增加参数--skip-extended-insert
- 如果要一个
应用到db2
1 | $ mysql -h$host -P$port -u$user db2 -e "source /client_tmp/t.sql" |
source是一个客户端命令,打开文件,默认以分号结尾读取一条条的SQL语句- 将SQL语句发送到服务端执行,
slowlog和binlog都会记录这些语句
导出CSV
1 | mysql> SYSTEM cat cat /usr/local/etc/my.cnf |
- secure-file-priv
secure-file-priv="",表示不限制文件生成的位置,不安全secure-file-priv="/XXX",要求生成的文件只能存放在指定的目录或其子目录secure-file-priv=NULL,表示禁止在这个MySQL实例上执行SELECT...INTO OUTFILE
SELECT...INTO OUTFILE语句- 将结果保存在服务端
- 不会覆盖文件
- 原则上一个数据行对应文本文件的一行
- 不会生成表结构文件
- mysqldump提供
--tab参数,可以同时导出表结构定义文件和csv数据文件
- mysqldump提供
LOAD DATA
1 | LOAD DATA INFILE '/tmp/t.csv' INTO TABLE db2.t; |
- 打开文件
/tmp/t.csv- 以制表符
\t作为字段间的分隔符,以换行符\n作为记录间的分隔符,进行数据读取
- 以制表符
- 启动事务
- 判断每一行的字段数和
db.t是否相同- 如果不相同,则直接报错,回滚事务
- 如果相同,则构造这一行,调用InnoDB引擎的接口,写入到表中
- 重复步骤3,直到
/tmp/t.csv整个文件读入完成,提交事务
主备同步
binlog_format=STATEMENT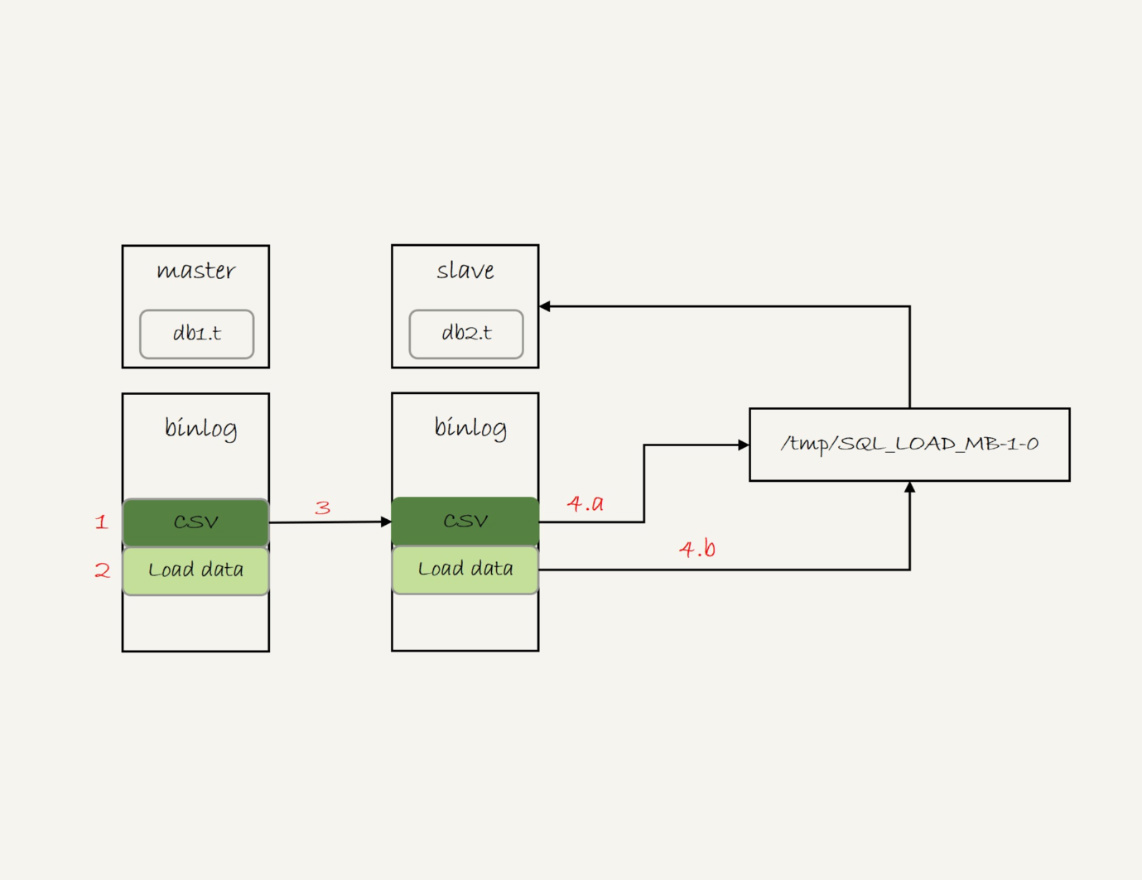
- 主库执行完成后,将
/tmp/t.csv文件的内容都直接写到binlog文件中 - 往binlog文件写入
LOAD DATA LOCAL INFILE '/tmp/SQL_LOAD_MB-1-0' INTO TABLE db2.t;
- 把binlog传到备库
- 备库的应用日志线程在执行这个事务日志时
- 先把binlog中的t.csv文件的内容读出来,写到本地临时目录
/tmp/SQL_LOAD_MB-1-0 - 再执行
LOAD DATA LOCAL语句,往备库的db2.t插入跟主库相同的数据LOCAL,表示执行这条命令的客户端本地文件(这里的客户端即备库本身)
- 先把binlog中的t.csv文件的内容读出来,写到本地临时目录
LOCAL
LOAD DATA- 读取的是服务端文件,文件必须在
secure_file_priv指定的目录或其子目录
- 读取的是服务端文件,文件必须在
LOAD DATA LOCAL- 读取的是客户端文件,只需要MySQL客户端有访问这个文件的权限即可
- 此时,MySQL客户端会先把本地文件传给服务端,然后再执行流程
物理拷贝
- 直接把db1.t的frm文件和ibd文件拷贝到db2目录下,是不行的
- 因为一个InnoDB表,除了包含这两个物理文件外,还需要在数据字典中注册
- MySQL 5.6引入了可传输表空间,可以通过导出+导入表空间的方式,实现物理拷贝表
执行步骤

- 假设在db1库下,复制一个跟表t相同的表r
- 执行
CREATE TABLE r LIKE t;,创建一个相同表结构的空表 - 执行
ALTER TABLE r DISCARD TABLESPACE;,此时r.ibd文件会被删除 - 执行
FLUSH TABLE t FOR EXPORT;- 此时在db1目录下会生成
t.cfg文件 - 整个
db1.t处于只读状态,直到执行UNLOCK TABLES
- 此时在db1目录下会生成
- 在db1目录下执行
cp t.cfg r.cfg和cp t.ibd r.ibd - 执行
UNLOCK TABLES;,此时t.cfg文件会被删除 - 执行
ALTER TABLE r IMPORT TABLESPACE;- 将这个
r.ibd文件作为表r新的表空间 - 由于这个文件的内容与
t.ibd是相同的,因此表r中数据与表t相同 - 为了让文件里的表空间id和数据字典中的一致,会修改
r.ibd的表空间id- 而表空间id存在于每一个数据页
- 如果是一个很大的文件,每个数据页都需要修改,
IMPORT语句会需要点时间 - 但相对于逻辑拷贝的方法,
IMPORT语句的耗时还是非常短的
- 将这个
1 | mysql> CREATE TABLE r LIKE t; |
小结
- 物理拷贝速度最快,尤其对于大表来说
- 必须全表拷贝
- 需要到服务器上拷贝数据
- 不支持跨引擎使用,源表和目标表都是使用InnoDB引擎
- mysqldump生成包含
INSERT语句的方法,加上where过滤,可以只导出部分数据- 不支持类似join等复杂的写法
- 逻辑拷贝,支持跨引擎使用
SELECT...INTO OUTFILE最灵活,支持所有的SQL语法- 每次只能导出一张表的数据,而且表结构需要另外的语句单独备份
- 逻辑拷贝,支持跨引擎使用
参考资料
《MySQL实战45讲》
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-02-07
MySQL -- 无过滤条件的count
count(*)实现 MyISAM:将表的总行数存放在磁盘上,针对无过滤条件的查询可以直接返回 如果有过滤条件的count(*),MyISAM也不能很快返回 InnoDB:从存储引擎一行行地读出数据,然后累加计数 由于MVCC,在同一时刻,InnoDB应该返回多少行是不确定 样例假设表t有10000条记录 session A session B session C BEGIN; SELECT COUNT(*) FROM t;(返回10000) INSERT INTO t;(插入一行) BEGIN; INSERT INTO t(插入一行); SELECT COUNT(*) FROM t;(返回10000) SELECT COUNT(*) FROM t;(返回10002) SELECT COUNT(*) FROM T;(返回10001) 最后时刻三个会话同时查询t的总行数,拿到的结果却是不同的 InnoDB默认事务隔离级别是RR,通过MVCC实现 每个事务都需要判断每一行记录是否对自己可见 优化 InnoDB是索引组织表 聚簇索引...

2019-01-25
MySQL -- 锁
全局锁 全局锁:对整个数据库实例加锁 加全局读锁:FLUSH TABLES WITH READ LOCK,阻塞其他线程的下列语句 数据更新语句(增删改) 数据定义语句(建表、修改表结构) 更新类事务的提交语句 主动解锁:UNLOCK TABLES 典型使用场景:全库逻辑备份 把整库每个表都SELECT出来,然后存成文本 缺点 如果在主库上执行逻辑备份,备份期间不能执行更新操作,导致业务停摆 如果在备库上执行逻辑备份,备份期间从库不能执行由主库同步过来的binlog,导致主从延时 备份加全局锁的必要性 保证全局视图是逻辑一致的 mysqldump --single-transaction 导数据之前启动一个事务,确保拿到_一致性视图_ 由于MVCC的支持,在这个过程中是可以正常更新数据的 需要存储引擎支持_RR的事务隔离级别_ MyISAM不支持事务,如果备份过程中有更新,总是能取到最新的数据,破坏了备份的一致性 因此MyISAM只能依赖于FLUSH TABLES WITH READ LOCK,不能使用--single-transaction 针对全库逻辑备份的场景,--si...

2019-02-12
MySQL -- 索引上的函数
结论先行如果对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器会决定放弃走树搜索功能 条件字段函数操作交易日志表123456789CREATE TABLE `tradelog` ( `id` INT(11) NOT NULL, `tradeid` VARCHAR(32) DEFAULT NULL, `operator` INT(11) DEFAULT NULL, `t_modified` DATETIME DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `tradeid` (`tradeid`), KEY `t_modified` (`t_modified`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 123456789101112131415-- 94608000 = 3 * 365 * 24 * 3600-- t_modified : 2016-01-01 00:00:00 ~ 2019-01-01 00:00:00DELIMITER ;;CREATE ...

2019-02-13
MySQL -- 问题排查
表初始化12345678910111213141516171819CREATE TABLE `t` ( `id` INT(11) NOT NULL, `c` INT(11) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB;DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=1; WHILE (i<=100000) DO INSERT INTO t VALUES (i,i); SET i=i+1; END WHILE;END;;DELIMITER ;CALL idata(); 查询长时间等待大概率是表t被锁住了,通过SHOW PROCESSLIST;查看语句处于什么状态 1SELECT * FROM t WHERE id=1; 等MDL执行时序 session A session B LOCK TABLE t WRITE; SELECT * FROM t WHERE id=1...

2019-02-21
MySQL -- 数据可靠性
binlog的写入机制 事务在执行过程中,先把日志写到binlog cache,事务提交时,再把binlog cache写到binlog file 一个事务的binlog是不能被拆开的,不论事务多大,也要确保一次性写入 系统会给每个线程分配一块内存binlog cache,由参数binlog_cache_size控制 如果超过了binlog_cache_size,需要暂存到磁盘 事务提交时,执行器把binlog cache里面的完整事务写入到binlog file,并清空binlog cache 12345678-- 2097152 Bytes = 2 MBmysql> SHOW VARIABLES LIKE '%binlog_cache_size%';+-----------------------+----------------------+| Variable_name | Value |+-----------------------+----------------------+| binlog_cache_siz...
2019-03-13
MySQL -- 内部临时表
UNIONUNION语义:取两个子查询结果的并集,重复的行只保留一行 表初始化1234567891011121314CREATE TABLE t1(id INT PRIMARY KEY, a INT, b INT, INDEX(a));DELIMITER ;;CREATE PROCEDURE idata()BEGIN DECLARE i INT; SET i=1; WHILE (i<= 1000) DO INSERT INTO t1 VALUES (i,i,i); SET i=i+1; END WHILE;END;;DELIMITER ;CALL idata(); 执行语句12345678910(SELECT 1000 AS f) UNION (SELECT id FROM t1 ORDER BY id DESC LIMIT 2);mysql> EXPLAIN (SELECT 1000 AS f) UNION (SELECT id FROM t1 ORDER BY id DESC LIMIT 2);+----+------------...




