
Kafka -- Docker + Schema Registry
Avro
- Avro的数据文件里包含了整个Schema
- 如果每条Kafka记录都嵌入了
Schema,会让记录的大小成倍地增加 - 在读取记录时,仍然需要读到整个Schema,所以需要先找到
Schema - 可以采用通用的结构模式并使用Schema注册表的方案
- 开源的
Schema注册表实现:Confluent Schema Registry
- 开源的
Confluent Schema Registry
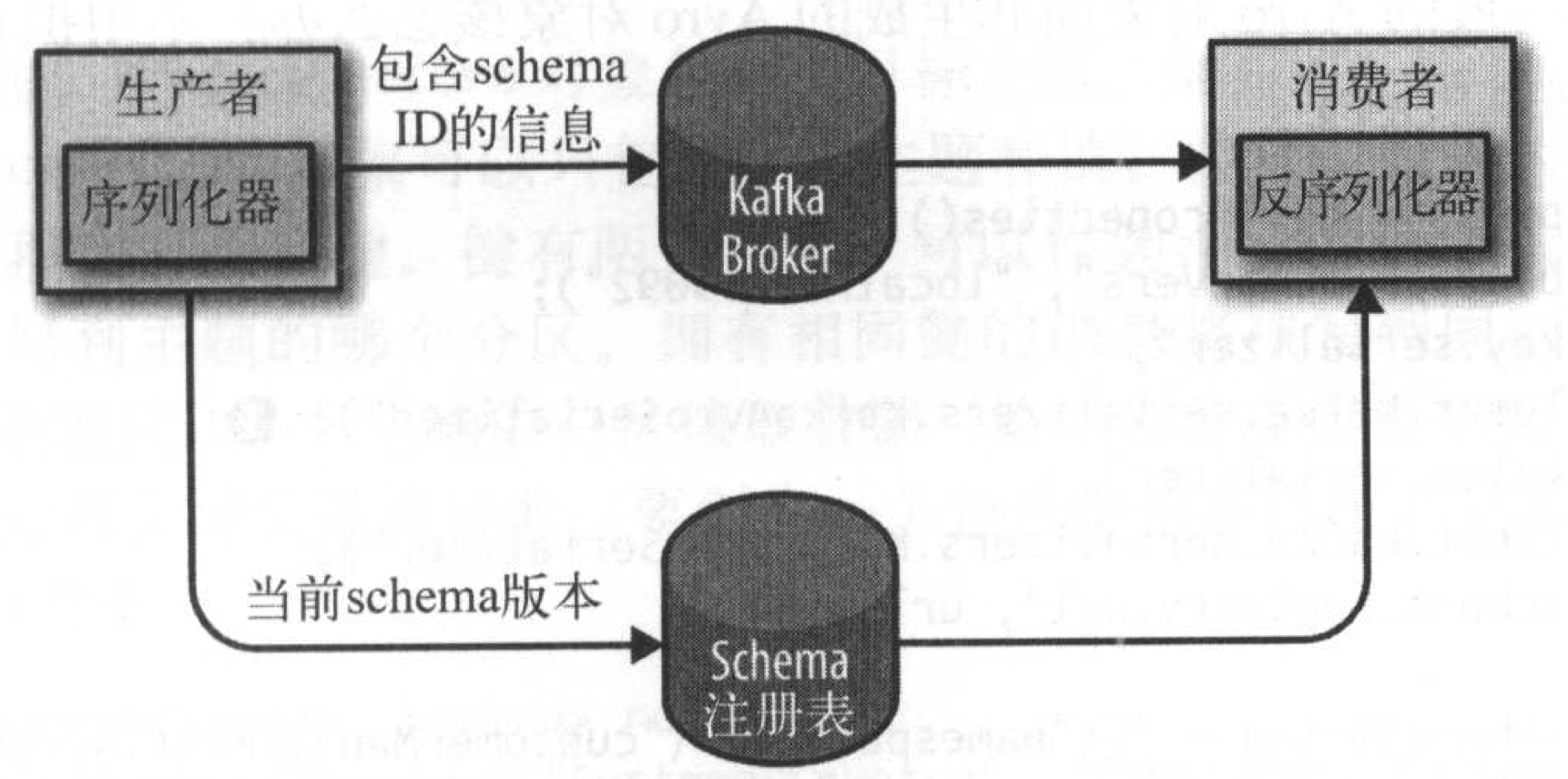
- 把所有写入数据需要用到的
Schema保存在注册表里,然后在_记录里引用Schema ID_ - 负责读数据的应用程序使用
Schema ID从注册表拉取Schema来反序列化记录 - 序列化器和反序列化器分别负责处理Schema的注册和拉取
Confluent Schema Registry
1 | # Start Zookeeper and expose port 2181 for use by the host machine |
注册Schema
user.json
1 | { |
注册
1 | $ curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \ |
ConfluentProducer
1 | private static final String TOPIC = "zhongmingmao"; |
ConfluentConsumer
1 | private static final String TOPIC = "zhongmingmao"; |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2018-10-15
Kafka -- Avro入门
引入依赖12345<dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>1.8.2</version></dependency> 1234567891011121314151617<plugin> <groupId>org.apache.avro</groupId> <artifactId>avro-maven-plugin</artifactId> <version>1.8.2</version> <executions> <execution> <phase>generate-sources</phase> <goals> ...

2018-10-17
Kafka -- Avro + Twitter Bijection
Avro + Kafka Native API 比较繁琐 编译Schema 依赖于Avro实现自定义的序列化器和反序列化器 引入依赖12345<dependency> <groupId>com.twitter</groupId> <artifactId>bijection-avro_2.12</artifactId> <version>0.9.6</version></dependency> Schema路径:src/main/resources/user.json 123456789{ "type": "record", "name": "User", "fields": [ {"name": "id", "type": "int"
...

2018-10-09
Kafka -- 集群安装与配置(Docker)
配置文件文件列表123$ tree.└── docker-compose.yml docker-compose.yml123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103version: '2'services: zk1: image: confluentinc/cp-zookeeper:latest hostname: zk1 container_name: zk1 restart: always ports: - "12181:2181" environment: ZOOKEEPER_SERVER_ID: 1 ZOOKEEPER_CLIENT_...

2018-10-16
Kafka -- Avro + Kafka Native API
Schema123456789101112131415{ "namespace": "me.zhongmingmao.avro", "type": "record", "name": "Stock", "fields": [ {"name": "stockCode", "type": "string"}, {"name": "stockName", "type": "string"}, {"name": "tradeTime", "type": "long"}, {&qu...

2019-09-23
Kafka -- 主题管理
日常管理创建主题1$ kafka-topics --bootstrap-server localhost:9092 --create --topic t1 --partitions 1 --replication-factor 1 从Kafka 2.2版本开始,推荐使用--bootstrap-server代替--zookeeper(标记为已过期) 原因 使用--zookeeper会绕过Kafka的安全体系,不受认证体系的约束 使用--bootstrap-server与集群交互是未来的趋势 查询主题列表12345$ kafka-topics --bootstrap-server localhost:9092 --list__consumer_offsets_schemast1transaction 查询单个主题1234567$ kafka-topics --bootstrap-server localhost:9092 --describe --topic __consumer_offsetsTopic:__consumer_offsets PartitionCount:50 Repl...

2019-09-28
Kafka -- KafkaAdminClient
背景 命令行脚本只能运行在控制台上,在应用程序、运维框架或者监控平台中集成它们,会非常困难 很多命令行脚本都是通过连接ZK来提供服务的,这会存在潜在的问题,即绕过Kafka的安全设置 运行这些命令行脚本需要使用Kafka内部的类实现,也就是Kafka服务端的代码 社区是希望用户使用Kafka客户端代码,通过现有的请求机制来运维管理集群 基于上述原因,社区于0.11版本正式推出Java客户端版的KafkaAdminClient 功能 主题管理 主题的创建、删除、查询 权限管理 具体权限的配置和删除 配置参数管理 Kafka各种资源(Broker、主题、用户、Client-Id等)的参数设置、查询 副本日志管理 副本底层日志路径的变更和详情查询 分区管理 创建额外的主题分区 消息删除 删除指定位移之前的分区消息 Delegation Token管理 Delegation Token的创建、更新、过期、查询 消费者组管理 消费者组的查询、位移查询和删除 Preferred领导者选举 推选指定主题分区的Preferred Broker为领导者 工作原理 Kaf...




