
Java并发 -- 问题源头
CPU、内存、IO设备
- 核心矛盾:三者的_速度差异_
- 为了合理利用CPU的高性能,平衡三者的速度差异,计算机体系结构、操作系统和编译程序都做出了贡献
- 计算机体系结构:CPU增加了缓存、以均衡CPU与内存的速度差异
- 操作系统:增加了进程、线程,分时复用CPU,以平衡CPU和IO设备的速度差异
- 编译程序:优化指令执行次序,使得缓存能够得到更加合理地利用
CPU缓存 -> 可见性问题
单核
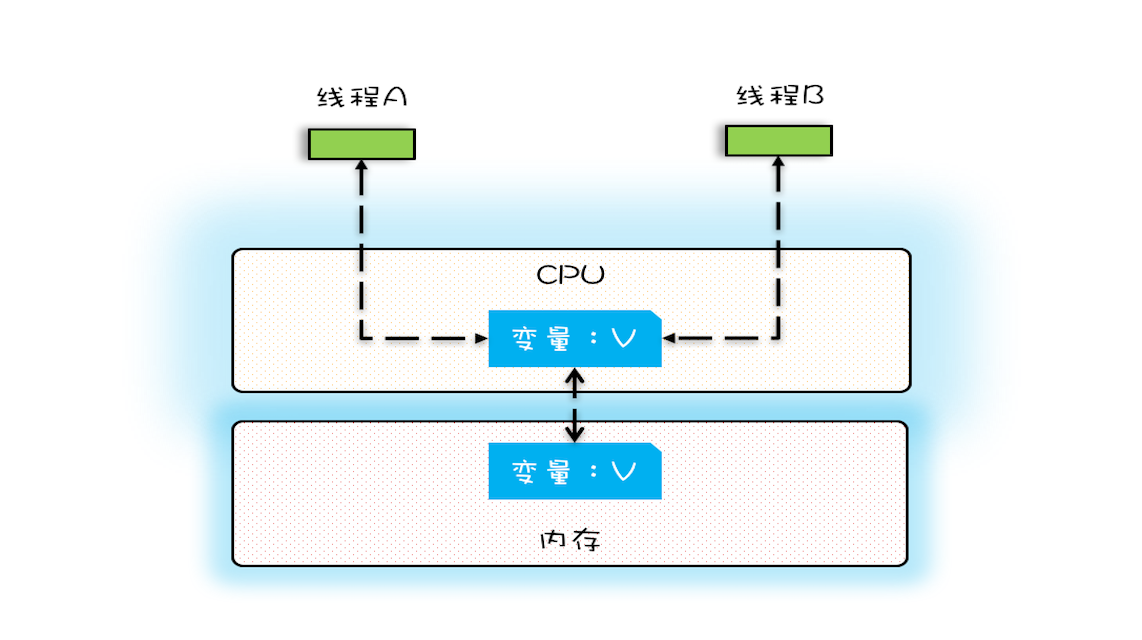
- 在单核时代,所有的线程都在一颗CPU上执行,CPU缓存与内存的数据一致性很容易解决
- 因为所有线程操作的都是同一个CPU的缓存,一个线程对CPU缓存的写,对另外一个线程来说一定是可见的
- 可见性:一个线程对共享变量的修改,另一个线程能够立即看到
多核
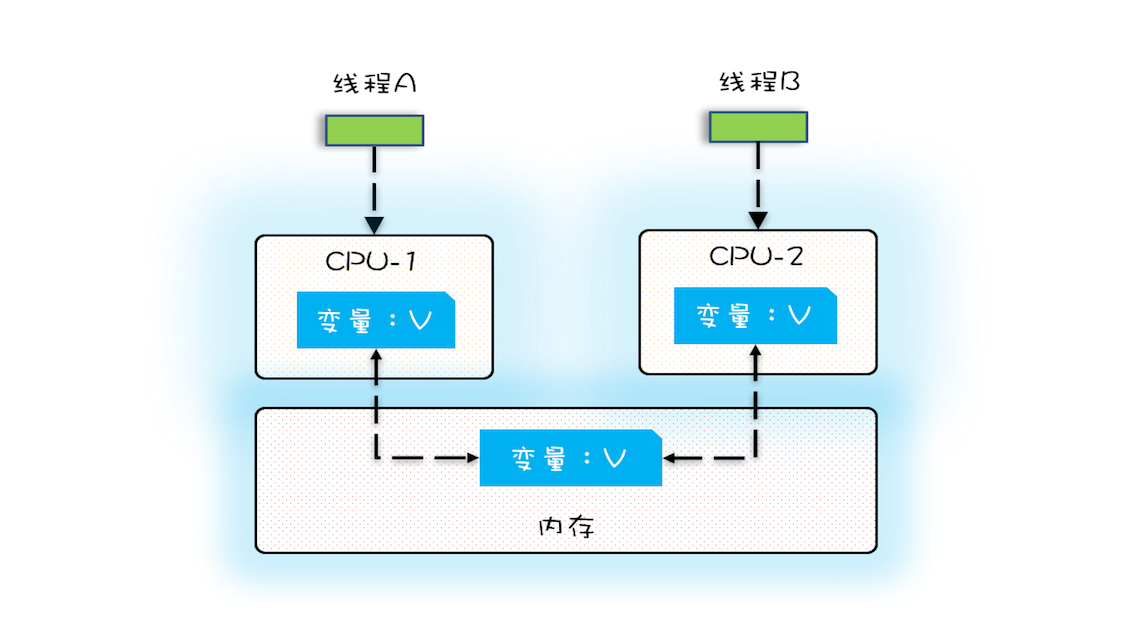
- 在多核时代,每颗CPU都有自己的缓存,此时CPU缓存与内存的数据一致性就没那么容易解决了
- 当多个线程在不同的CPU上执行时,操作的是不同的CPU缓存
- 线程A操作的是CPU-1上的缓存,线程B操作的是CPU-2上的缓存,此时线程A对变量V的操作对于线程B而言不具备可见性
代码验证
1 | public class VisibilityTest { |
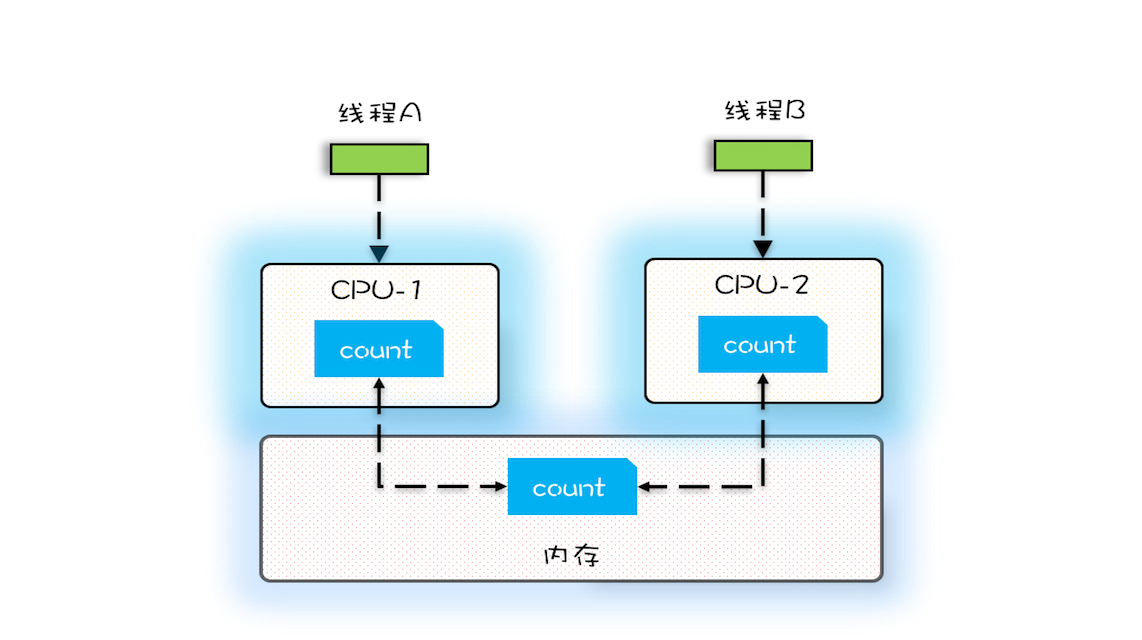
- 假设线程A和线程B同时开始执行,那么第一次都会将count=0读到各自的CPU缓存中
- 之后由于各自的CPU缓存里都有了count的值,两个线程都是基于CPU缓存里的count值来进行计算的
- 所以导致最终count的值小于2MAX,这就是CPU缓存导致的可见性问题
线程切换 -> 原子性问题
分时复用
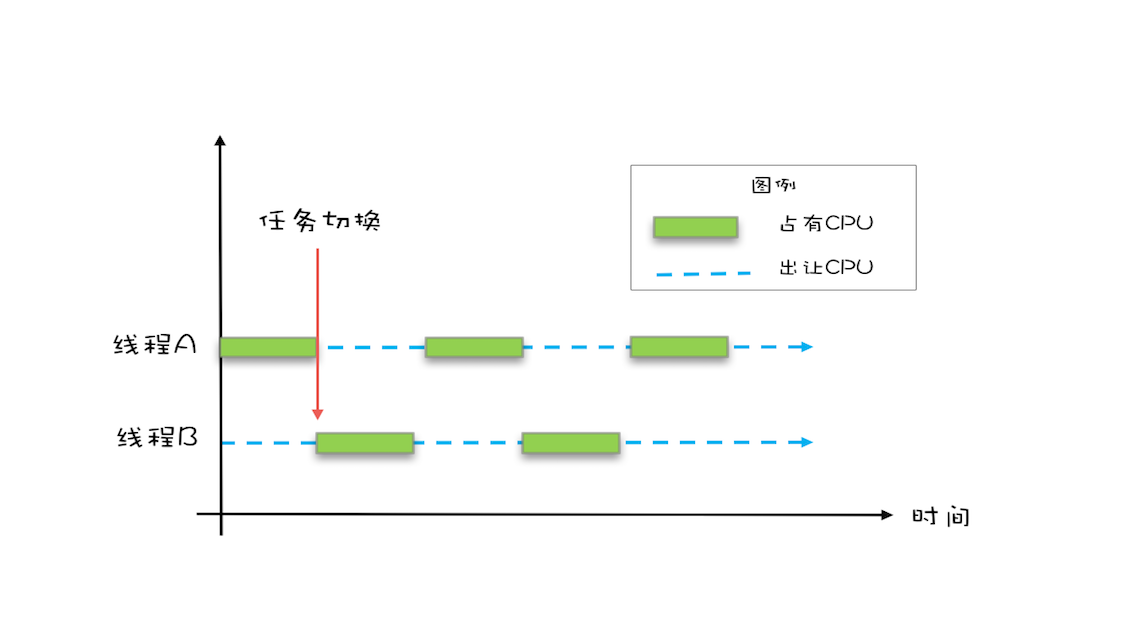
- 由于IO太慢,早期的操作系统发明了多进程,并支持分时复用(时间片)
- 在一个时间片内,如果进程进行一个IO操作,例如读文件,该进程可以把自己标记为休眠状态并让出CPU的使用权
- 待文件读进内存后,操作系统会把这个休眠的进程唤醒,唤醒后的进程就有机会重新获得CPU的使用权了
- 进程在等待IO时释放CPU的使用权,可以让CPU在这段等待时间里执行其他任务,_提高CPU的使用率_
- 另外,如果此时另外一个进程也在读文件,而读文件的操作会先排队
- 磁盘驱动在完成一个进程的读操作后,发现有其他任务在排队,会立即启动下一个读操作,_提高磁盘IO的使用率_
线程切换
- 早期的操作系统基于进程来调度CPU,不同进程间是不共享内存空间的,进程切换需要_切换内存映射地址_
- 一个进程创建的所有线程,都是共享同一个内存空间的,因此线程切换的成本很低
- 现代的操作系统都是基于更轻量的线程来调度的,而Java并发程序都是基于多线程的
count+=1
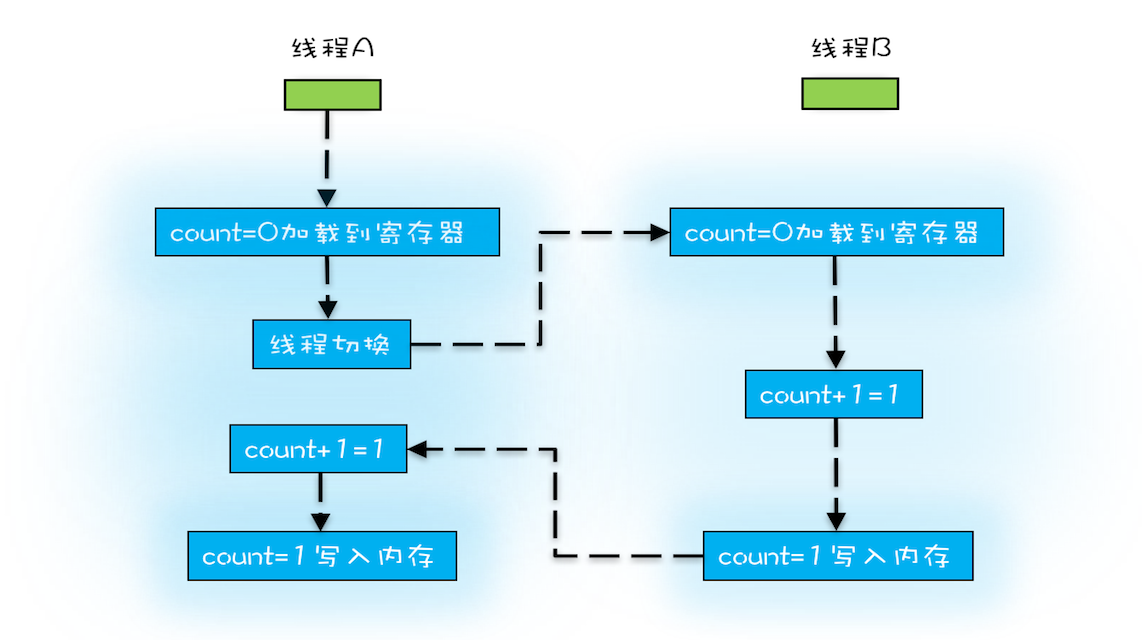
- 线程切换的时机大多在时间片结束的时候,而高级语言里的一条语句往往需要多条CPU指令完成,如
count+=1- 把变量count从内存加载到CPU的寄存器
- 在寄存器中执行+1操作
- 将结果写入CPU缓存(最终会回写到内存)
- 操作系统做线程切换,可以发生在任何一条CPU指令(而非高级语言的语句)执行完
- 按照上图执行,线程A和线程B都执行了
count+=1,但得到的结果却是1,而不是2,因为Java中的+1操作不具有原子性 - 原子性:一个或多个操作在CPU执行的过程中不被中断的特性
- CPU能保证的原子操作是CPU指令级别的,而不是高级语言的操作符
编译优化 -> 有序性问题
- 有序性:程序按照代码的先后顺序执行
- 编译器为了优化性能,有时会改变程序中语句的先后顺序
双重检查
1 | class Singleton { |
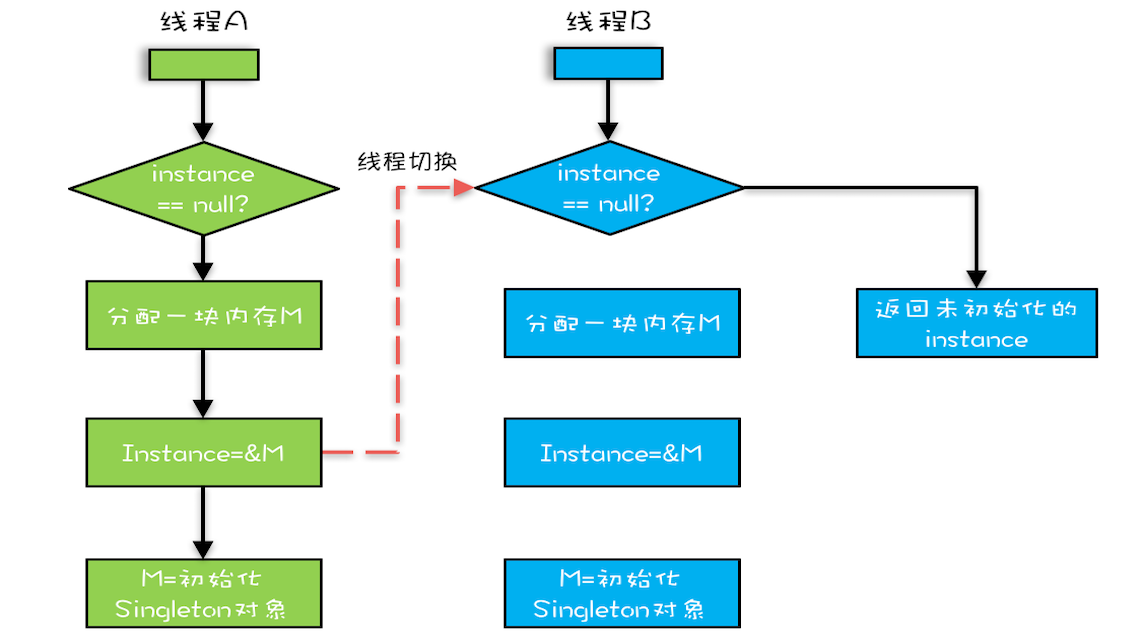
- 直觉
- 线程A和B同时调用getInstance()方法,同时发现instance==null,同时对Singleton.class加锁
- 此时JVM保证只有一个线程能够加锁成功(假设是线程A),另一个线程则会进入等待状态(假设线程B)
- 线程A会创建一个Singleton实例,然后释放锁,线程B被唤醒并再次尝试加锁,此时加锁成功
- 线程B检查instance==null,发现已经创建过Singleton实例了,不会再创建Singleton实例了
- 直觉上的new操作
- 分配一块内存M
- 在内存M上初始化Singleton对象
- 将M的地址赋值给instance变量
- 编译器优化后的new操作可能是
- 分配一块内存M
- 将M的地址赋值给instance变量
- 在内存M上初始化Singleton对象
- 因此,实际情况可能是
- 假设线程A先执行getInstance()方法,当执行完指令2时恰好发生了线程切换,切换到线程B
- 线程B也在执行getInstance()方法,线程B会执行第一个判断,发现instance!=null,直接返回instance
- 但此时返回的instance是没有初始化过的,如果此时访问instance的成员变量就有可能触发_空指针异常_
小结
- CPU缓存 -> 可见性问题,线程切换 -> 原子性问题,编译优化 -> 有序性问题
- CPU缓存、线程和编译优化的目的与并发程序的目一致,都是为了提高程序性能
- 但技术在解决一个问题的同时,必然会带来另一个问题,因此需要权衡
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-05-23
Java并发 -- Thread-Per-Message模式
概述Thread-Per-Message模式:为每个任务分配一个独立的线程 Thread123456789101112131415161718192021// 处理请求try (ServerSocketChannel ssc = ServerSocketChannel.open().bind(new InetSocketAddress(8080))) { while (true) { // 接收请求 SocketChannel sc = ssc.accept(); // 每个请求都创建一个线程 new Thread(() -> { try { // 读Socket ByteBuffer rb = ByteBuffer.allocateDirect(1024); sc.read(rb); TimeUnit.SECONDS.sleep(1); ...

2019-05-07
Java并发 -- Condition
Condition Condition实现了管程模型中的_条件变量_ Java内置的管程(synchronized)只有一个条件变量,而Lock&Condition实现的管程支持多个条件变量 在很多并发场景下,支持多个条件变量能够让并发程序的可读性更好,也更容易实现 阻塞队列1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253// 下列三对操作的语义是相同的// Condition.await() Object.wait()// Condition.signal() Object.notify()// Condition.signalAll() Object.notifyAll()public class BlockedQueue<T> { private static final int MAX_SIZE = 10; // 可重入锁 private final Lock loc...

2019-05-21
Java并发 -- Guarded Suspension模式
概述 Guarded Suspension模式是等待唤醒机制的规范实现 Guarded Suspension模式也被称为Guarded Wait 模式、Spin Lock 模式 Web版的文件浏览器 用户可以在浏览器里查看服务器上的目录和文件 该项目依赖运维部门提供的文件浏览服务,而文件浏览服务仅支持MQ接入 用户通过浏览器发送请求,会被转换成消息发送给MQ,等MQ返回结果后,再将结果返回至浏览器 1234567891011121314151617181920212223242526public class FileBrowser { // 发送消息 private void send(Message message) { } // MQ消息返回后调用该方法 public void onMessage(Message message) { } public Response handleWebReq() { Message message = new Message(1L, &...

2019-05-20
Java并发 -- ThreadLocal模式
并发问题 多个线程同时读写同一个共享变量会存在并发问题 Immutability模式和Copy-on-Write模式,突破的是写 ThreadLocal模式,突破的是共享变量 ThreadLocal的使用线程ID12345678910public class ThreadLocalId { private static final AtomicLong nextId = new AtomicLong(0); private static final ThreadLocal<Long> TL = ThreadLocal.withInitial( () -> nextId.getAndIncrement()); // 为每个线程分配一个唯一的ID private static long get() { return TL.get(); }} SimpleDateFormat12345678public class SafeDateFormat { private...

2019-05-31
Java并发 -- Disruptor
有界队列 JUC中的有界队列ArrayBlockingQueue和LinkedBlockingQueue,都是基于ReentrantLock 在高并发场景下,锁的效率并不高,Disruptor是一款性能更高的有界内存队列 Disruptor高性能的原因 内存分配更合理,使用RingBuffer,数组元素在初始化时一次性全部创建 提升缓存命中率,对象循环利用,避免频繁GC 能够避免伪共享,提升缓存利用率 采用无锁算法,避免频繁加锁、解锁的性能消耗 支持批量消费,消费者可以以无锁的方式消费多个消息 简单使用123456789101112131415161718192021222324252627public class DisruptorExample { public static void main(String[] args) throws InterruptedException { // RingBuffer大小,必须是2的N次方 int bufferSize = 1024; // 构建Disruptor ...

2019-05-24
Java并发 -- Worker Thread模式
Worker Thread模式 Worker Thread模式可以类比现实世界里车间的工作模式,Worker Thread对应车间里的工人(人数确定) 用阻塞队列做任务池,然后创建固定数量的线程消费阻塞队列中的任务 – 这就是Java中的线程池方案 echo服务123456789101112131415161718192021222324252627private ExecutorService pool = Executors.newFixedThreadPool(500);public void handle() throws IOException { // 处理请求 try (ServerSocketChannel ssc = ServerSocketChannel.open().bind(new InetSocketAddress(8080))) { while (true) { // 接收请求 SocketChannel sc = ssc.accept(); /...




