
Java并发 -- 原子类
add
1 | private long count = 0; |
- add()方法不是线程安全的,主要原因是count的可见性和count+=1的原子性
- 可见性的问题可以用volatile来解决,原子性的问题一般采用互斥锁来解决
无锁方案
1 | private AtomicLong atomicCount = new AtomicLong(0); |
- 无锁方案相对于互斥锁方案,最大的好处是_性能_
- 互斥锁方案为了保证互斥性,需要执行加锁、解锁操作,而加锁、解锁操作本身会消耗性能
- 拿不到锁的线程会进入阻塞状态,进而触发线程切换,线程切换对性能的消耗也很大
- 无锁方案则完全没有加锁、解锁的性能消耗,同时能保证互斥性
实现原理
- CPU为了解决并发问题,提供了CAS(Compare And Swap)指令
- CAS指令包含三个参数:共享变量的内存地址A,用于比较的值B、共享变量的新值C
- 只有当内存地址A处的值等于B时,才能将内存地址A处的值更新为新值C
- CAS指令是一条CPU指令,本身能保证原子性
自旋
1 | public class SimulatedCAS { |
- 使用CAS解决并发问题,一般都会伴随着自旋(循环尝试)
- 首先计算newValue=count+1,如果count!=cas(count, newValue)
- 说明线程执行完代码1之后,在执行代码2之前,count的值被其他线程更新过,此时采用自旋(循环尝试)
- 通过CAS+自旋实现的无锁方案,完全没有加锁、解锁操作,不会阻塞线程,相对于互斥锁方案来说,性能提升了很多
ABA问题
- 上面的count==cas(count, newValue),并不能说明执行完代码1之后,在执行代码2之前,count的值没有被其他线程更新过
- 假设count原本为A,线程T1在执行完代码1之后,执行代码2之前,线程T2将count更新为B,之后又被T3更新回A
count+=1 原子化
1 | // AtomicLong |
原子类
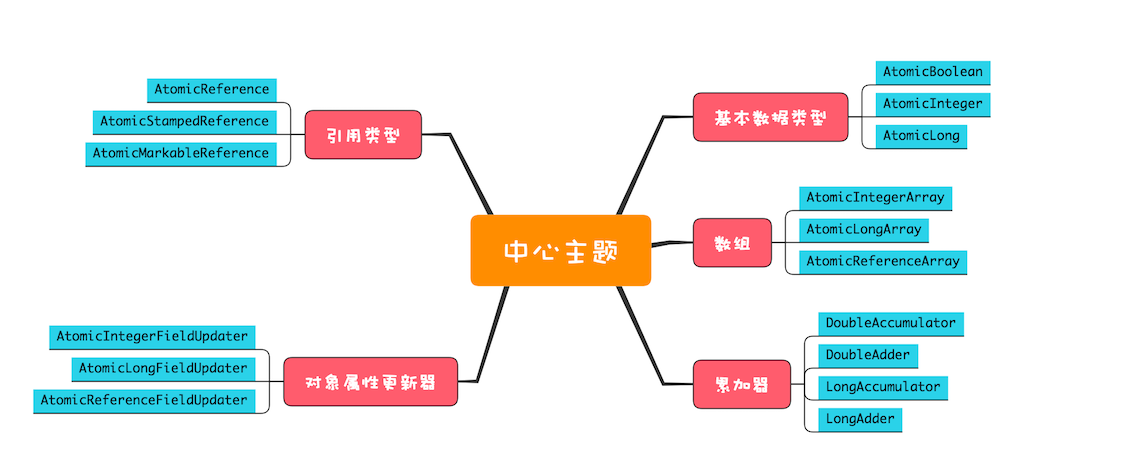
原子化的基本类型
相关实现有AtomicBoolean、AtomicInteger和AtomicLong
1 | getAndIncrement() // 原子化 i++ |
原子化的对象引用类型
- 相关实现有AtomicReference、AtomicStampedReference和AtomicMarkableReference,可以实现对象引用的原子化更新
- 对象引用的更新需要重点关注ABA问题,而AtomicStampedReference和AtomicMarkableReference可以解决ABA问题
AtomicStampedReference
1 | public boolean compareAndSet(V expectedReference, |
- 通过增加一个版本号即可解决ABA问题
- 每次执行CAS操作时,附加再更新一个版本号,只要保证版本号是递增的,即使A->B->A,版本号也不会回退
AtomicMarkableReference
将版本号简化成一个Boolean值
1 | public boolean compareAndSet(V expectedReference, |
原子化的数组
- 相关实现有AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray
- 利用这些原子类,可以原子化地更新数组里面的每一个元素
原子化的对象属性更新器
- 相关实现有AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater
- 利用这些原子类,都可以原子化地更新对象的属性,这三个方法都是利用反射机制实现的
- 对象属性必须是volatile类型,只有这样才能保证可见性
- 如果对象属性不是volatile类型的,newUpdater会抛出IllegalArgumentException
1 | // AtomicLongFieldUpdater |
原子化的累加器
- 相关实现有DoubleAccumulator、DoubleAdder、LongAccumulator和LongAdder
- 这几个原子类仅仅用来执行累加操作,相比于原子化的基本数据类型,速度更快,但不支持compareAndSet
- 如果仅仅需要累加操作,使用原子化的累加器的性能会更好
小结
- 无锁方案相对于互斥锁方案,性能更好,不会出现死锁问题,但可能出现饥饿和活锁问题(由于自旋)
- Java提供的原子类只能够解决一些简单的原子性问题
- 所有原子类的方法都是针对单个共享变量的,如果需要解决多个变量的原子性问题,还是要采用互斥锁的方案
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-05-10
Java并发 -- StampedLock
StampedLock VS ReadWriteLock StampedLock同样适用于读多写少的场景,性能比ReadWriteLock好 ReadWriteLock支持两种模式:写锁、读锁 StampedLock支持三种模式:写锁、悲观读锁、_乐观读_(关键) StampedLock的写锁、悲观读锁的语义和ReadWriteLock的写锁、读锁的语义非常类似 允许多个线程同时获取悲观读锁,只允许一个线程获取写锁,写锁和悲观读锁是互斥的 但StampedLock里的写锁和悲观读锁加锁成功之后,都会返回一个stamp,然后解锁的时候需要传入这个stmap 12345678910111213141516171819202122232425public class StampedLockExample { private final StampedLock stampedLock = new StampedLock(); @Test // 悲观读锁 public void pessimisticReadLockTest() { long...

2019-04-27
Java并发 -- 管程
概述 Java语言在1.5之前,唯一提供的并发原语是管程 在Java 1.5提供的JUC包中,也是以管程技术为基础的 管程是一把解决并发问题的万能钥匙 管程 在Java 1.5之前,仅仅提供synchronized关键字和wait/notify/notifyAll方法 Java采用的是管程技术,synchronized关键字以及wait/notify/notifyAll方法都是管程的组成部分 管程和信号量是等价的(即用管程能实现信号量,用信号量也能实现管程),但管程更容易使用,所以Java选择了管程 Monitor,在Java领域会翻译成监视器,在操作系统领域会翻译成管程 管程:_管理共享变量以及对共享变量的操作过程,让它们支持并发_ 对应Java领域:管理类的成员变量和成员方法,让这个类是线程安全的 MESA模型 在管程的发展史上,先后出现了三种不同的管程模型,分别是:Hasen模型、Hoare模型和MESA模型 现在广泛应用的是MESA模型,Java管程的实现也参考了MESA模型 管程可以解决并发领域的两大核心问题:_互斥+同步_ 互斥:在同一时刻...

2019-05-07
Java并发 -- Condition
Condition Condition实现了管程模型中的_条件变量_ Java内置的管程(synchronized)只有一个条件变量,而Lock&Condition实现的管程支持多个条件变量 在很多并发场景下,支持多个条件变量能够让并发程序的可读性更好,也更容易实现 阻塞队列1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253// 下列三对操作的语义是相同的// Condition.await() Object.wait()// Condition.signal() Object.notify()// Condition.signalAll() Object.notifyAll()public class BlockedQueue<T> { private static final int MAX_SIZE = 10; // 可重入锁 private final Lock loc...

2019-04-15
Java并发 -- 问题源头
CPU、内存、IO设备 核心矛盾:三者的_速度差异_ 为了合理利用CPU的高性能,平衡三者的速度差异,计算机体系结构、操作系统和编译程序都做出了贡献 计算机体系结构:CPU增加了缓存、以均衡CPU与内存的速度差异 操作系统:增加了进程、线程,分时复用CPU,以平衡CPU和IO设备的速度差异 编译程序:优化指令执行次序,使得缓存能够得到更加合理地利用 CPU缓存 -> 可见性问题单核 在单核时代,所有的线程都在一颗CPU上执行,CPU缓存与内存的数据一致性很容易解决 因为所有线程操作的都是同一个CPU的缓存,一个线程对CPU缓存的写,对另外一个线程来说一定是可见的 可见性:一个线程对共享变量的修改,另一个线程能够立即看到 多核 在多核时代,每颗CPU都有自己的缓存,此时CPU缓存与内存的数据一致性就没那么容易解决了 当多个线程在不同的CPU上执行时,操作的是不同的CPU缓存 线程A操作的是CPU-1上的缓存,线程B操作的是CPU-2上的缓存,此时线程A对变量V的操作对于线程B而言不具备可见性 代码验证123456789101112131415161718192021222324...

2019-05-26
Java并发 -- 生产者-消费者模式
生产者-消费者模式 生产者-消费者模式的核心是一个_任务队列_ 生产者线程生产任务,并将任务添加到任务队列中,消费者线程从任务队列中获取任务并执行 从架构设计的角度来看,生产者-消费者模式有一个很重要的优点:_解耦_ 生产者-消费者模式另一个重要的优点是支持异步,并且能够平衡生产者和消费者的速度差异(任务队列) 支持批量执行 往数据库INSERT 1000条数据,有两种方案 第一种方案:用1000个线程并发执行,每个线程INSERT一条数据 第二种方案(更优):用1个线程,执行一个批量的SQL,一次性把1000条数据INSERT进去 将原来直接INSERT数据到数据库的线程作为生产者线程,而生产者线程只需将数据添加到任务队列 然后消费者线程负责将任务从任务队列中批量取出并批量执行 1234567891011121314151617181920212223242526272829303132333435363738// 任务队列private BlockingQueue<Task> queue = new LinkedBlockingQueue<>(2...

2019-05-08
Java并发 -- Semaphore
历史 信号量是由计算机科学家Dijkstra在1965年提出,在之后的15年,信号量一直都是并发编程领域的终结者 直到1980年管程被提出来,才有了第二选择,目前所有支持并发编程的语言都支持信号量机制 信号量模型 在信号量模型里,计数器和等待队列对外都是透明的,只能通过信号量模型提供的三个方法来访问它们,即init/down/up init():设置计数器的初始值 down():计数器的值减1,如果此时计数器的值小于0,则当前线程将阻塞,否则当前线程可以继续执行 up():计数器加1,如果此时计数器的值大于或等于0,则唤醒等待队列中的一个线程,并将其从等待队列中移除 init/down/up都是原子性的,这个原子性由信号量模型的实现方保证 在JUC中,信号量模型由java.util.concurrent.Semaphore实现,Semaphore能够保证这三个方法的原子性操作 在信号量模型里,down/up这两个操作最早被称为P操作和V操作,因此信号量模型也被称为_PV原语_ 在JUC中,down和up对应的是acquire和release...




