Java并发 -- Copy-on-Write模式
fork
- 类Unix操作系统调用fork(),会创建父进程的一个完整副本,很耗时
- Linux调用fork(),创建子进程时并不会复制整个进程的地址空间,而是让父子进程共享同一个地址空间
- 只有在父进程或者子进程需要写入时才会复制地址空间,从而使父子进程拥有各自独立的地址空间
- 本质上来说,父子进程的地址空间和数据都是要隔离的,使用Copy-on-Write更多体现的是一种延时策略
- Copy-on-Write还支持按需复制,因此在操作系统领域能够提升性能
- Java提供的Copy-on-Write容器,会复制整个容器,所以在提升读操作性能的同时,是以内存复制为代价的
- CopyOnWriteArrayList / CopyOnWriteArraySet
RPC框架
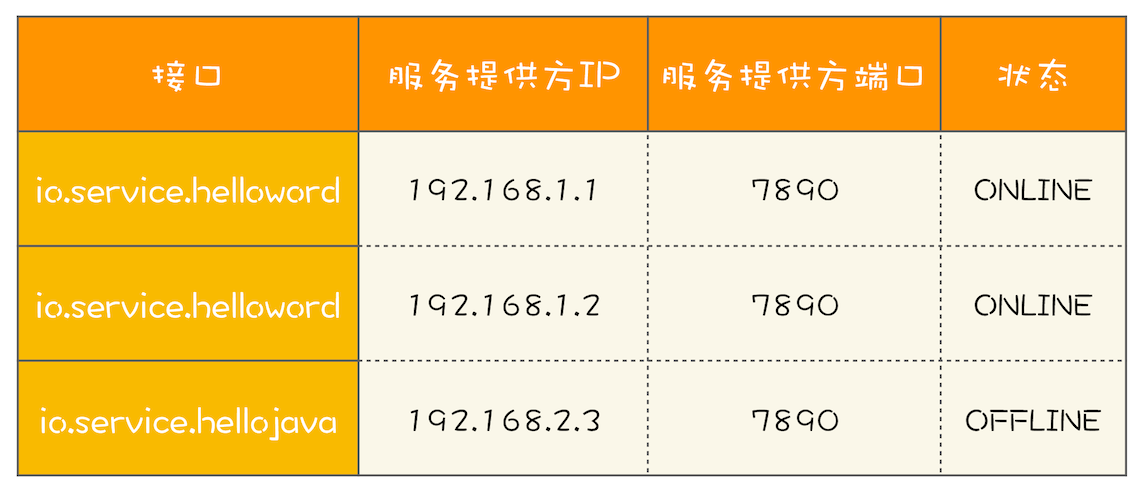
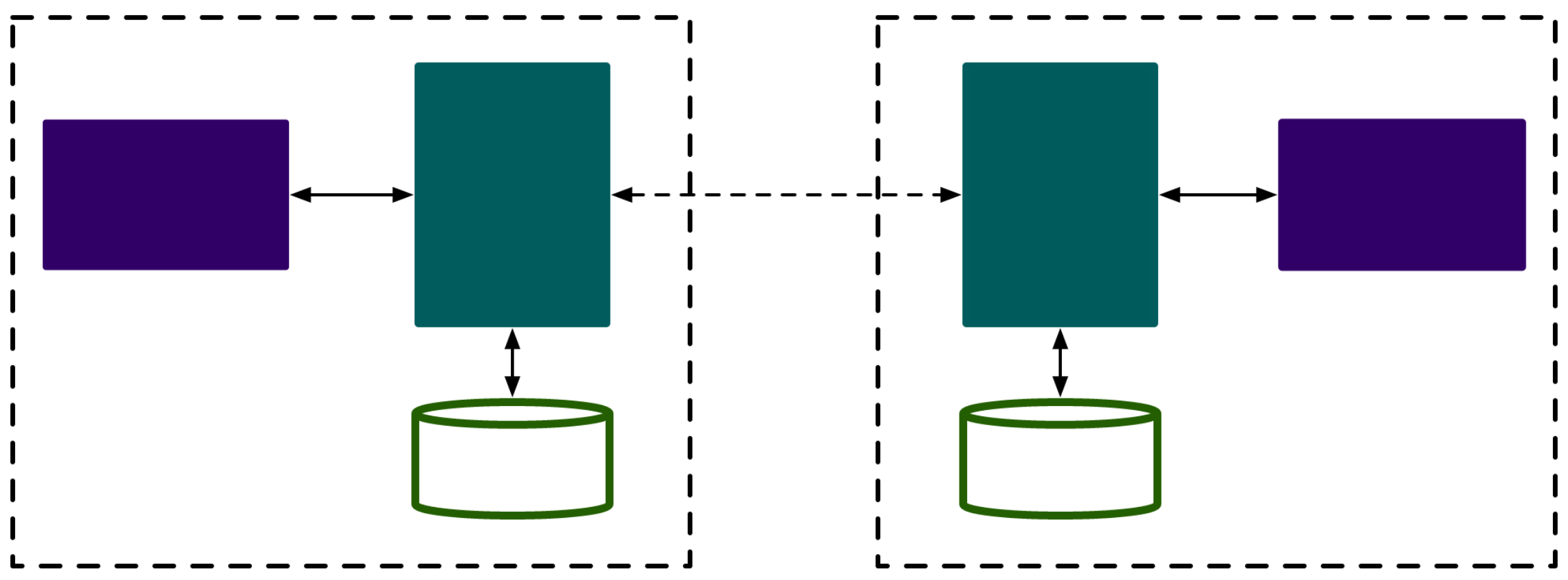
- 服务提供方是多实例分布式部署的,服务的客户端在调用RPC时,会选定一个服务实例来调用
- 这个过程的本质是负载均衡,而做负载均衡的前提是客户端要有全部的路由信息
- 一个核心任务就是维护服务的路由关系,当服务提供方上线或者下线的时候,需要更新客户端的路由表信息
- RPC调用需要通过负载均衡器来计算目标服务的IP和端口号,负载均衡器通过路由表获取所有路由信息
- 访问路由表这个操作对性能的要求很高,但路由表对数据一致性要求不高
1 | // 采用Immutability模式,每次上线、下线都创建新的Router对象或删除对应的Router对象 |
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-05-16
Java并发 -- CompletionService
场景1234567// 从3个电商询价,保存到数据库,串行执行,性能很慢int p1 = getPriceByS1();save(p1);int p2 = getPriceByS2();save(p2);int p3 = getPriceByS3();save(p3); ThreadPoolExecutor + Future1234567891011ExecutorService pool = Executors.newFixedThreadPool(3);Future<Integer> f1 = pool.submit(() -> getPriceByS1());Future<Integer> f2 = pool.submit(() -> getPriceByS2());Future<Integer> f3 = pool.submit(() -> getPriceByS3());int p1 = f1.get(); // 阻塞,如果f2.get()很快,但f1.get()很慢,依旧需要等待pool.execute(() -> save(...

2019-05-31
Java并发 -- Disruptor
有界队列 JUC中的有界队列ArrayBlockingQueue和LinkedBlockingQueue,都是基于ReentrantLock 在高并发场景下,锁的效率并不高,Disruptor是一款性能更高的有界内存队列 Disruptor高性能的原因 内存分配更合理,使用RingBuffer,数组元素在初始化时一次性全部创建 提升缓存命中率,对象循环利用,避免频繁GC 能够避免伪共享,提升缓存利用率 采用无锁算法,避免频繁加锁、解锁的性能消耗 支持批量消费,消费者可以以无锁的方式消费多个消息 简单使用123456789101112131415161718192021222324252627public class DisruptorExample { public static void main(String[] args) throws InterruptedException { // RingBuffer大小,必须是2的N次方 int bufferSize = 1024; // 构建Disruptor ...

2016-07-04
JVM基础 -- JOL使用教程 3
本文将通过JOL分析Java对象的内存布局,包括伪共享、DataModel、Externals、数组对齐等内容代码托管在https://github.com/zhongmingmao/java_object_layout 伪共享Java8引入@sun.misc.Contended注解,自动进行缓存行填充,原始支持解决伪共享问题,实现高效并发,关于伪共享,网上已经很多资料,请参考下列连接: https://yq.aliyun.com/articles/62865 http://www.cnblogs.com/Binhua-Liu/p/5620339.html http://blog.csdn.net/zero__007/article/details/54951584 http://blog.csdn.net/aigoogle/article/details/41517213 http://hg.openjdk.java.net/jdk8u/jdk8u/jdk/file/tip/src/share/classes/sun/misc/Contended.java 代码12345678910111...

2019-04-21
Java并发 -- 死锁
Account.class 在《Java并发 – 互斥锁》中,使用了Account.class作为互斥锁来解决银行业务的转账问题 虽然不存在并发问题,但所有账户的转账操作都是串行的,性能太差 例如账户A给账户B转账,账户C给账户D转账,在现实世界中是可以并行的,但该方案中只能串行 账户和账本 每个账户都对应一个账本,账本统一存放在文件架上 银行柜员进行转账操作时,需要到文件架上取出转出账本和转入账本,然后转账操作,会遇到三种情况 如果文件架上有转出账本和转入账本,都同时拿走 如果文件架上只有转出账本或只有转入账本,那需要等待那个缺失的账本 如果文件架上没有转出账本和转入账本,那需要等待两个账本 两把锁123456789101112131415161718public class Account { // 账户余额 private int balance; // 转账 public void transfer(Account target, int amt) { // 锁定转出账户 synchronized (this...

2019-05-09
Java并发 -- ReadWriteLock
读多写少 理论上,利用管程和信号量可以解决所有并发问题,但JUC提供了很多工具类,_细分场景优化性能,提升易用性_ 针对读多写少的并发场景,JUC提供了读写锁,即ReadWriteLock 读写锁 读写锁是一种广泛使用的通用技术,并非Java所特有 所有读写锁都遵守3条基本原则 允许多个线程同时读共享变量 – 与互斥锁的重要区别 只允许一个线程写共享变量 如果一个写线程正常执行写操作,此时禁止读线程读取共享变量 缓存1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253public class Cache<K, V> { private final Map<K, V> map = new HashMap<>(); private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); // 读锁 private...

2019-05-14
Java并发 -- 线程池
创建线程 创建普通对象,只是在JVM的堆里分配一块内存而已 创建线程,需要调用操作系统内核的API,然后操作系统需要为线程分配一系列资源,成本很高 线程是一个重量级对象,应该避免频繁创建和销毁,采用线程池方案 一般的池化资源12345678910111213141516// 假设Java线程池采用一般意义上池化资源的设计方法class ThreadPool { // 获取空闲线程 Thread acquire() { } // 释放线程 void release(Thread t) { }}// 期望的使用ThreadPool pool;Thread T1 = pool.acquire();// 传入Runnable对象T1.execute(() -> { // 具体业务逻辑}); 生产者-消费者模式业界线程池的设计,普遍采用生产者-消费者模式,线程池的使用方是生产者,线程池本身是消费者 123456789101112131415161718192021222324...