Java并发 -- Disruptor
有界队列
- JUC中的有界队列ArrayBlockingQueue和LinkedBlockingQueue,都是基于ReentrantLock
- 在高并发场景下,锁的效率并不高,Disruptor是一款性能更高的有界内存队列
- Disruptor高性能的原因
- 内存分配更合理,使用RingBuffer,数组元素在初始化时一次性全部创建
- 提升缓存命中率,对象循环利用,避免频繁GC
- 能够避免伪共享,提升缓存利用率
- 采用无锁算法,避免频繁加锁、解锁的性能消耗
- 支持批量消费,消费者可以以无锁的方式消费多个消息
- 内存分配更合理,使用RingBuffer,数组元素在初始化时一次性全部创建
简单使用
1 | public class DisruptorExample { |
- 在Disruptor中,生产者生产的对象和消费者消费的对象称为Event,使用Disruptor必须定义Event
- 构建Disruptor对象需要传入EventFactory(LongEvent::new)
- 消费Disruptor中的Event需要通过handleEventsWith方法注册一个事件处理器
- 发布Event需要通过publishEvent方法
优点
RingBuffer
局部性原理
- 在一段时间内程序的执行会限定在一个局部范围内,包括时间局部性和空间局部性
- 时间局部性
- 程序中的某条指令一旦被执行,不久之后这条指令很可能被再次执行
- 如果某条数据被访问,不久之后这条数据很可能被再次访问
- 空间局部性
- 某块内存一旦被访问,不久之后这块内存附近的内存也有可能被访问
- CPU缓存利用了程序的局部性原理
- CPU从内存中加载数据X时,会将数据X及其附近的数据缓存在高速Cache中
- 如果程序能够很好地体现出局部性原理,就能更好地利用CPU缓存,从而提升程序的性能
ArrayBlockingQueue
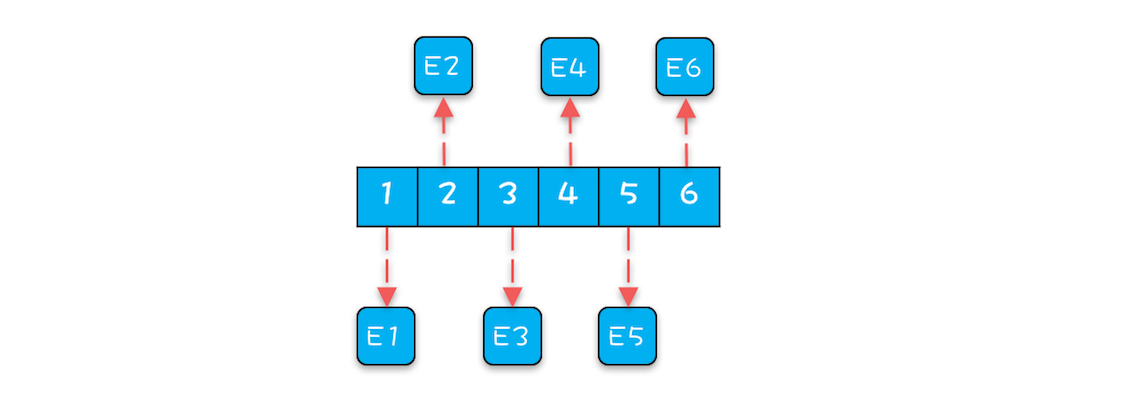
- 生产者向ArrayBlockingQueue增加一个元素之前,都需要先创建对象E
- 创建这些元素的时间基本上是离散的,所以这些元素的内存地址大概率也不是连续的
Disruptor
1 | // com.lmax.disruptor.RingBufferFields |
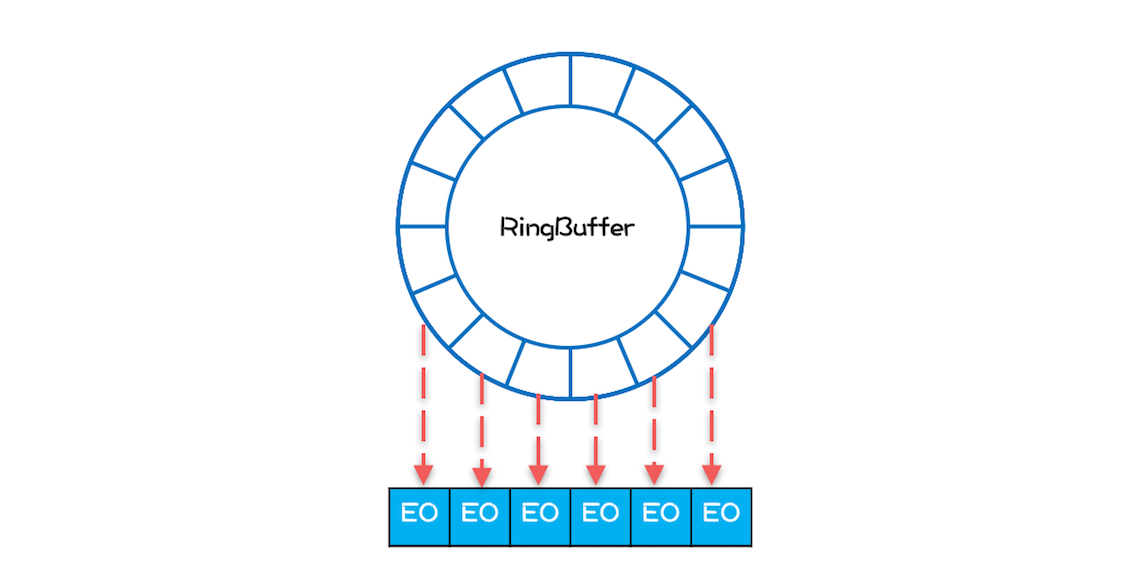
- Disruptor内部的RingBuffer也是用数组实现的
- 但这个数组中的所有元素在初始化时是一次性全部创建,所以这些元素的内存地址大概率是连续的
- 如果数组中所有元素的内存地址是连续的,能够提升性能
- 消费者线程在消费的时候,遵循空间局部性原理,消费完第1个元素,很快就会消费第2个元素
- 而在消费第1个元素的时候,CPU会把内存中E1后面的数据也加载进高速Cache
- 如果E1和E2是连续的,那么E2也就会被加载进高速Cache
- 当消费第2个元素的时候,由于E2已经在高速Cache中了,不再需要从内存中加载,能大大提升性能
- 另外在Disruptor中,生产者线程通过publishEvent发布Event时,并不是创建一个新的Event
- 而是通过event.setValue来修改Event,即循环利用RingBuffer中的Event
- 这样能避免频繁创建和销毁Event而导致的GC问题
避免伪共享
伪共享
- CPU缓存内部是按照缓存行(Cache Line)进行管理的,一个缓存行通常为64 Bytes
- CPU从内存中加载数据X,会同时加载后面(64-size(X))个字节的数据
ArrayBlockingQueue
1 | /** The queued items */ |
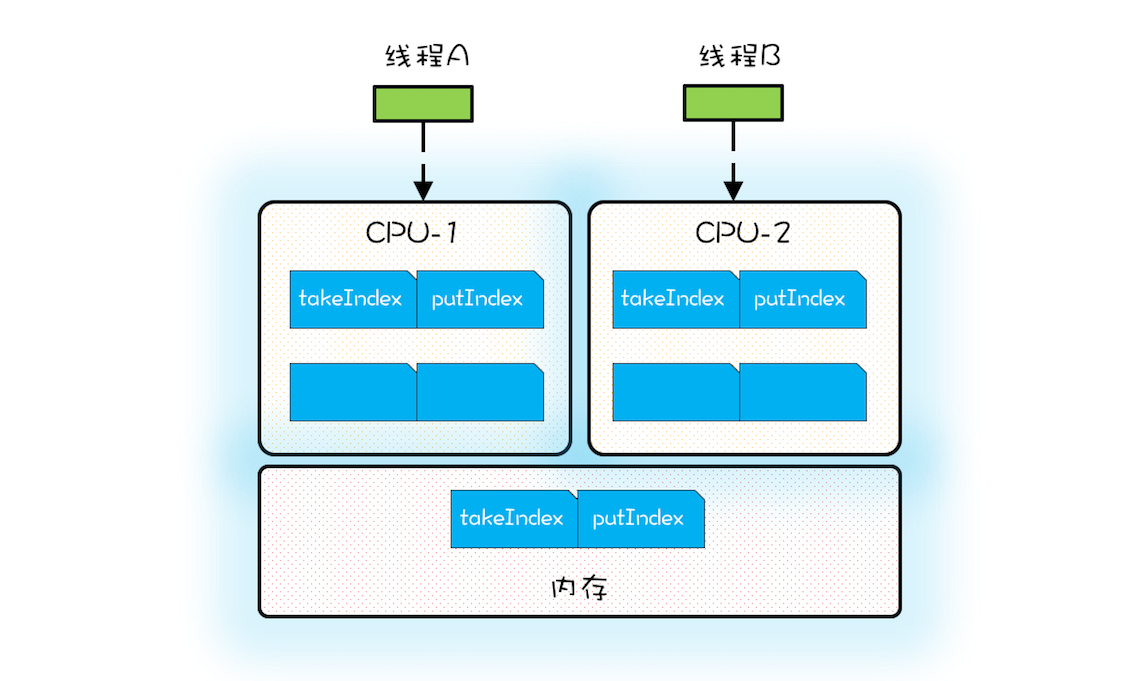
- 当CPU从内存中加载takeIndex时,会同时将putIndex和count都加载进高速Cache
- 假设线程A运行在CPU-1上,执行入队操作,入队操作会修改putIndex
- 而修改putIndex会导致CPU-2上putIndex所在的缓存行失效
- 假设线程B运行在CPU-2上,执行出队操作,出队操作需要读取takeIndex
- 但由于takeIndex所在的缓存行已经失效,所以CPU-2必须从内存中重新读取
- 入队操作本身不会修改takeIndex,但由于takeIndex和putIndex共享同一个缓存行
- 导致出队操作不能很好地利用Cache,这就是伪共享
- 伪共享:由于共享缓存行而导致缓存无效的场景
- ArrayBlockingQueue的入队操作和出队操作是用锁来保证互斥的,所以入队和出队不会同时发生
- 如果允许入队和出队同时发生,可以采用缓存行填充,保证每个变量独占一个缓存行
- 如果想让takeIndex独占一个缓存行,可以在takeIndex的前后各填充56个字节
Disruptor
1 | // 前:填充56字节 |
Contended
- Java 8引入了@sun.misc.Contended注解,能够轻松避免伪共享,需要设置JVM参数-XX:RestrictContended
- 避免伪共享是以牺牲内存为代价的
无锁算法
- ArrayBlockingQueue利用管程实现,生产和消费都需要加锁,实现简单,但性能不太理想
- Disruptor采用的是无锁算法,实现复杂,核心操作是生产和消费,最复杂的是入队操作
- 对于入队操作,不能覆盖没有消费的元素,对于出队操作,不能读取没有写入的元素
- Disruptor中的RingBuffer维护了入队索引,但没有维护出队索引
- 因为Disruptor支持多个消费者同时消费,每个消费者都会有一个出队索引
- 所以RingBuffer的出队索引是所有消费者里最小的一个
- 入队逻辑:_如果没有足够的空余位置,就出让CPU使用权,然后重新计算,反之使用CAS设置入队索引_
1 | // com.lmax.disruptor.MultiProducerSequencer |
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-05-14
Java并发 -- Future
ThreadPoolExecutor12345678910// 无法获取任务的执行结果public void execute(Runnable command);// 可以获取任务的执行结果// Runnable接口的run()方法没有返回值,返回的Future只能断言任务是否已经结束,类似于Thread.join()public Future<?> submit(Runnable task)// Callable接口的call()方法有返回值,可以通过调用返回的Future对象的get()方法获取任务的执行结果public <T> Future<T> submit(Callable<T> task);// 返回的Future对象f,f.get()的返回值就是传给submit方法的参数resultpublic <T> Future<T> submit(Runnable task, T result) Future1234567891011// 取消任务boolean cancel(boolean mayInterruptIfR...

2019-06-04
Java并发 -- Actor模型
Actor模型 Actor模型在本质上是一种计算模型,基本的计算单元称为Actor,在Actor模型中,所有的计算都在Actor中执行 在面向对象编程里,一切都是对象,在Actor模型里,一切都是Actor,并且Actor之间是完全隔离的,不会共享任何变量 Java本身并不支持Actor模型,如果需要在Java里使用Actor模型,需要借助第三方类库,比较完备的是Akka Hello Actor12345678910111213141516public class HelloActor extends UntypedAbstractActor { // 该Actor在收到消息message后,会打印Hello message @Override public void onReceive(Object message) throws Throwable { System.out.printf("Hello %s%n", message); } public static void main(String[...

2019-05-01
Java并发 -- 面向对象
封装共享变量 面向对象思想里面有一个很重要的特性:_封装_ 封装:将属性和实现细节封装在对象内部,外部对象只能通过目标对象的公共方法来间接访问目标对象的内部属性 利用面向对象思想写并发程序的思路:将共享变量作为对象属性封装在内部,对所有公共方法制定_并发访问策略_ Countervalue为共享变量,作为Counter的实例属性,将get()和addOne()声明为synchronized方法,Counter就是一个线程安全的类 1234567891011public class Counter { private long value; public synchronized long get() { return value; } public synchronized long addOne() { return ++value; }} 不可变的共享变量 实际场景中,会有很多共享变量,如银行账户有卡号、姓名、身份证、信用额度等,其中卡号、姓名和身份证是不会变的 对于不可变的...

2019-05-20
Java并发 -- ThreadLocal模式
并发问题 多个线程同时读写同一个共享变量会存在并发问题 Immutability模式和Copy-on-Write模式,突破的是写 ThreadLocal模式,突破的是共享变量 ThreadLocal的使用线程ID12345678910public class ThreadLocalId { private static final AtomicLong nextId = new AtomicLong(0); private static final ThreadLocal<Long> TL = ThreadLocal.withInitial( () -> nextId.getAndIncrement()); // 为每个线程分配一个唯一的ID private static long get() { return TL.get(); }} SimpleDateFormat12345678public class SafeDateFormat { private...

2019-05-24
Java并发 -- Worker Thread模式
Worker Thread模式 Worker Thread模式可以类比现实世界里车间的工作模式,Worker Thread对应车间里的工人(人数确定) 用阻塞队列做任务池,然后创建固定数量的线程消费阻塞队列中的任务 – 这就是Java中的线程池方案 echo服务123456789101112131415161718192021222324252627private ExecutorService pool = Executors.newFixedThreadPool(500);public void handle() throws IOException { // 处理请求 try (ServerSocketChannel ssc = ServerSocketChannel.open().bind(new InetSocketAddress(8080))) { while (true) { // 接收请求 SocketChannel sc = ssc.accept(); /...
2019-04-17
Java并发 -- 互斥锁
解决什么问题互斥锁解决了并发程序中的原子性问题 禁止CPU中断 原子性:一个或多个操作在CPU执行的过程中不被中断的特性 原子性问题点源头是线程切换,而操作系统依赖CPU中断来实现线程切换的 单核时代,禁止CPU中断就能禁止线程切换 同一时刻,只有一个线程执行,禁止CPU中断,意味着操作系统不会重新调度线程,也就禁止了线程切换 获得CPU使用权的线程可以不间断地执行 多核时代 同一时刻,有可能有两个线程同时在执行,一个线程执行在CPU1上,一个线程执行在CPU2上 此时禁止CPU中断,只能保证CPU上的线程不间断执行,但并不能保证同一时刻只有一个线程执行 互斥:同一时刻只有一个线程执行 如果能保证对共享变量的修改是互斥的,无论是单核CPU还是多核CPU,都能保证原子性 简易锁模型 临界区:一段需要互斥执行的代码 线程在进入临界区之前,首先尝试加锁lock() 如果成功,则进入临界区,此时该线程只有锁 如果不成功就等待,直到持有锁的线程解锁 持有锁的线程执行完临界区的代码后,执行解锁unlock() 锁和资源 synchronized12345678910111213141...