
Kafka -- 术语
主题 + 客户端
- 发布订阅的对象是主题(Topic)
- 向主题发布消息的客户端应用程序称为生产者(Producer),生产者可以持续不断地向多个主题发送消息
- 订阅这些主题消息的客户端应用程序称为消费者(Consumer),消费者能够同时订阅多个主题的消息
- 生产者和消费者统称为客户端
服务端
- Kafka的服务端由被称为Broker的服务进程构成,一个Kafka集群由多个Broker组成
- Broker负责接收和处理客户端发送过来的请求,以及对消息进行持久化
- 多个Broker进程能够运行在同一台机器上,但更常见的做法是将不同的Broker分散运行在不同的机器上
- 这样如果集群中某一台机器宕机了,即使在它上面运行的所有Broker进程都挂掉了
- 其他机器上的Broker也依然能够对外提供服务,这是Kafka提供高可用的手段之一
备份
- 实现高可用的另一个手段是备份机制(Replication)
- 备份:把相同的数据拷贝到多台机器上,这些相同的数据拷贝在Kafka中被称为副本(Replica)
- 副本的数量是可以配置的,Kafka定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)
- 领导者副本:对外提供服务,对外指的是与客户端程序进行交互
- 生产者总是向领导者副本写消息
- 消费者总是从领导者副本读消息
- 追随者副本:被动地追随领导者副本,不能与外界交互
- 向领导者副本发送请求,请求领导者副本把最新生产的消息发给它,进而与领导者副本保持同步
- MySQL的从库是可以处理读请求的
- Master-Slave => Leader-Follower
- 领导者副本:对外提供服务,对外指的是与客户端程序进行交互
- 副本机制可以保证数据的持久化或者消息不丢失,但没有解决伸缩性(Scalability)的问题
- 如果领导者副本积累了太多的数据以至于单台Broker机器无法容纳,该如何处理?
- 可以把数据分割成多份,然后保存在不同的Broker上,这种机制就是分区(Partitioning)
- MongoDB、Elasticsearch – Sharding
- HBase – Region
分区
- Kafka中的分区机制是将每个主题划分成多个分区(Partition),每个分区是_一组有序的消息日志_
- 生产者生产的每条消息只会被发送到一个分区中,Kafka的分区编号是从0开始的
- 副本是在分区这个层级定义的,每个分区下可以配置N个副本,只能有1个领导者副本和N-1个追随者副本
- 生产者向分区(分区的领导者副本)写入消息,每条消息在分区中的位置由位移(Offset)来表征,而分区位移总是从0开始
- 三层消息架构
- 第一层是主题层,每个主题可以配置M个分区,而每个分区又可以配置N个副本
- 第二层是分区层
- 每个分区的N个副本中只能有1个领导者副本,对外提供服务
- 其他N-1个副本是追随者副本,只能提供数据冗余
- 第三层是消息层,分区中包含若干条消息,每条消息的位移从0开始,依次递增
- 最后,客户端程序只能与分区的领导者副本进行交互
持久化
- Kafka使用消息日志(Log)来保存数据,一个日志是磁盘上一个只能追加写(Append-Only)消息的物理文件
- 只能追加写入,避免了缓慢的随机IO操作,改为性能较好的顺序IO操作,这是实现Kafka高吞吐量的一个重要手段
- Kafka需要定期删除消息以回收磁盘空间,可以通过日志片段(Log Segment)机制来实现
- 在Kafka底层,一个日志又被细分成多个日志段,消息被追加到当前最新的日志段中
- 当写满一个日志段后,Kafka会自动切分出一个新的日志段,并将老的日志段封存起来
- Kafka在后台有定时任务定期地检查这些老的日志段是否能够被删除,从而实现回收磁盘空间的目的
消费者
- 点对点模型(Peer to Peer,P2P):同一条消息只能被下游的一个消费者消费,其他消费者不能染指
- Kafka通过消费者组(Consumer Group)来实现P2P模型
- 消费者组:多个消费者实例共同组成一个组来消费一组主题
- 这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它
- 即消费者对分区有所有权
- 引入消费者组的目的:提高消费者端的吞吐量(TPS)
- 消费者实例(Consumer Instance):即可以是运行消费者应用的进程,也可以是一个线程
- 重平衡(Rebalance)
- 若组内的某个实例挂了,Kafka能够自动检测到,然后把这个挂掉的实例之前负责的分区转移给组内其他存活的消费者
- 重平衡引发的消费者问题很多,目前很多重平衡的Bug社区都无力解决
- 消费者位移(Consumer Offset):记录消费者当前消费到了分区的哪个位置,随时变化
- 分区位移:表征的是消息在分区内的位置,一旦消息被成功写入到一个分区上,消息的分区位移就固定了
小结
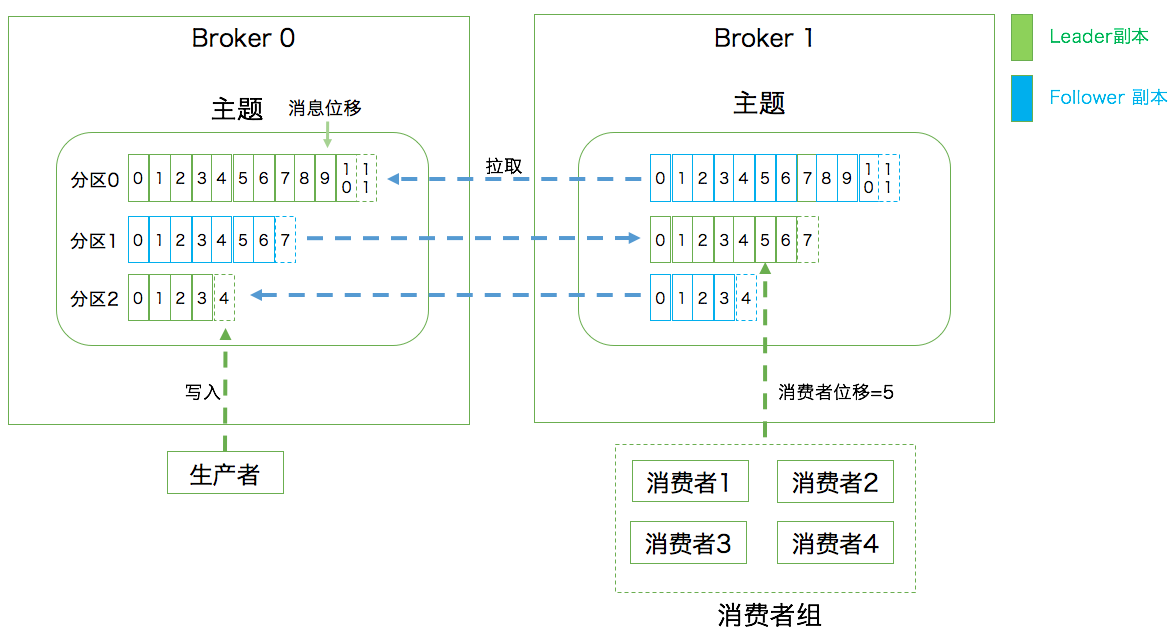
- 消息(Record):消息是Kafka处理的主要对象
- 主题(Topic):主题是承载消息的逻辑容器,实际使用中多用来区分具体的业务
- 分区(Partition):一个有序不变的消息序列,每个主题下有多个分区
- 消息位移(Offset):也叫分区位移,表示一条消息在分区中的位置,是一个单调递增且不变的值
- 副本(Replica)
- Kafka中同一条消息能够被拷贝到多个地方以提供数据冗余
- 副本分为领导者副本和追随者副本,副本在分区的层级下,每个分区可配置多个副本实现高可用
- 生产者(Producer):向主题发布消息的应用程序
- 消费者(Consumer):从主题订阅消息的应用程序
- 消费者位移(Consumer Offset):表征消费者的消费进度,每个消费者都有自己的消费者位移
- 消费者组(Consumer Group):多个消费者实例共同组成一个组,同时消费多个分区以实现高吞吐
- 重平衡(Rebalance)
- 消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅分区的过程
- 重平衡是Kafka消费者端实现高可用的重要手段
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-03-26
Kafka -- 内部原理
群组成员关系 Kakfa使用ZooKeeper来维护集群成员的信息 每个Broker都有一个唯一的ID,这个ID可以在配置文件里面指定,也可以自动生成 在Broker启动的时候,通过创建临时节点把自己的ID注册到ZooKeeper Kakfa组件订阅ZooKeeper的/brokers/ids路径,当有Broker加入集群或者退出集群时,Kafka组件能获得通知 如果要启动另一个具有相同ID的Broker,会得到一个错误,这个Broker会尝试进行注册,但会失败 在Broker停机,出现网络分区或者长时间垃圾回收停顿时,Broker会从ZooKeeper上_断开连接_ 此时,Broker在启动时创建的临时节点会从ZooKeeper上自动移除(ZooKeeper特性) 订阅Broker列表的Kafka组件会被告知该Broker已经被移除 在关闭Broker时,它对应的临时节点也会消失,不过它的ID会继续存在于其他数据结构中 例如,主题的副本列表里可能会包含这些ID 在完全关闭了一个Broker之后,如果使用相同的ID启动另一个全新的Broker 该Broker会立即加入集群,并拥有与旧Broker...

2019-08-22
Kafka -- 消费者组
消费者组 消费者组(Consumer Group)是Kafka提供的可扩展且具有容错性的消费者机制 一个消费者组内可以有多个消费者或消费者实例(进程/线程),它们共享一个Group ID(字符串) 组内的所有消费者协调在一起来消费订阅主题的所有分区 每个分区只能由同一个消费者组内的一个Consumer实例来消费,Consumer实例对分区有所有权 消息引擎模型 两种模型:点对点模型(消息队列)、发布订阅模型 点对点模型(传统的消息队列模型) 缺陷/特性:消息一旦被消费、就会从队列中被删除,而且只能被下游的一个Consumer消费 伸缩性很差,下游的多个Consumer需要抢占共享消息队列中的消息 发布订阅模型 缺陷:伸缩性不高,每个订阅者都必须订阅主题的所有分区(全量订阅) Consumer Group 当Consumer Group订阅了多个主题之后 组内的每个Consumer实例不要求一定要订阅主题的所有分区,只会消费部分分区的消息 Consumer Group之间彼此独立,互不影响,它们能够订阅相同主题而互不干涉 Kafka使用Consumer Group...

2019-06-18
Kafka -- 消息引擎系统
术语 Apache Kafka是一款开源的消息引擎系统 消息队列:给人某种暗示,仿佛Kafka是利用队列实现的 消息中间件:过度强调中间件,而不能清晰地表达实际解决的问题 解决的问题 系统A发送消息给消息引擎系统,系统B从消息引擎系统中读取A发送的消息 消息引擎传输的对象是消息 如何传输消息属于消息引擎设计机制的一部分 消息格式 成熟解决方案:CSV、XML、JSON 序列化框架:Google Protocol Buffer、Facebook Thrift Kafka:纯二进制的字节序列 消息引擎模型 点对点模型 即消息队列模型,系统A发送的消息只能被系统B接收,其他任何系统不能读取A发送的消息 发布订阅模型 主题(Topic)、发布者(Publisher)、订阅者(Subscriber) 多个发布者可以向相同的主题发送消息,多个订阅者可以接收相同主题的消息 Kafka同时支持上面两种消息引擎模型 JMS JMS:Java Message Service JMS也支持上面的两种消息引擎模型 JMS并非传输协议,而是一组API JMS非常出名,很多主流的消息引擎系统都支持JMS规范 A...

2019-08-02
Kafka -- 压缩
压缩的目的时间换空间,用CPU时间去换磁盘空间或网络IO传输量 消息层次 消息集合(Message Set)和消息 一个消息集合中包含若干条日志项(Record Item),而日志项用于封装消息 Kafka底层的消息日志由一系列消息集合日志项组成 Kafka不会直接操作具体的消息,而是在消息集合这个层面上进行写入操作 消息格式 目前Kafka共有两大类消息格式,社区分别称之为V1版本和V2版本(在0.11.0.0引入) V2版本主要针对V1版本的一些弊端进行了优化 优化1:把消息的公共部分抽取到外层消息集合里面 在V1版本中,每条消息都需要执行CRC校验,但在某些情况下,消息的CRC值会发生变化 Broker端可能对消息的时间戳字段进行更新,重新计算后的CRC值也会相应更新 Broker端在执行消息格式转换时(兼容老版本客户端),也会带来CRC值的变化 因此没必要对每条消息都执行CRC校验,浪费空间和时间 在V2版本中,消息的CRC校验被移到了消息集合这一层 优化2:对整个消息集合进行压缩 在V1版本中,对多条消息进行压缩,然后保存到外层消息的消息体字段中 压缩的时机在Kafka...

2019-09-12
Kafka -- 监控消费进度
Consumer Lag Consumer Lag(滞后程度):消费者当前落后于生产者的程度 Lag的单位是消息数,一般是在主题的级别上讨论Lag,但Kafka是在分区的级别上监控Lag,因此需要手动汇总 对于消费者而言,Lag是最重要的监控指标,直接反应了一个消费者的运行情况 一个正常工作的消费者,它的Lag值应该很小,甚至接近于0,滞后程度很小 如果Lag很大,表明消费者无法跟上生产者的速度,Lag会越来越大 极有可能导致消费者消费的数据已经不在操作系统的页缓存中了,这些数据会失去享有Zero Copy技术的资格 这样消费者不得不从磁盘读取这些数据,这将进一步拉大与生产者的差距 马太效应:_Lag原本就很大的消费者会越来越慢,Lag也会也来越大_ 监控LagKafka自带命令 kafka-consumer-groups是Kafka提供的最直接的监控消费者消费进度的工具 也能监控独立消费者的Lag,独立消费者是没有使用消费者组机制的消费者程序,也要配置group.id 消费者组要调用KafkaConsumer.subscribe,独立消费者要调用KafkaConsumer.assign直...

2018-10-11
Kafka -- 生产者
生产者概述 创建一个ProducerRecord对象,ProducerRecord对象包含Topic和Value,还可以指定Key或Partition 在发送ProducerRecord对象时,生产者先将Key和Partition序列化成字节数组,以便于在网络上传输 字节数组被传给分区器 如果在ProducerRecord对象里指定了Partition 那么分区器就不会做任何事情,直接返回指定的分区 如果没有指定分区,那么分区器会根据ProducerRecord对象的Key来选择一个Partition 选择好分区后,生产者就知道该往哪个主题和分区发送这条记录 这条记录会被添加到一个记录批次里,一个批次内的所有消息都会被发送到相同的Topic和Partition上 有一个单独的线程负责把这些记录批次发送到相应的Broker 服务器在收到这些消息时会返回一个响应 如果消息成功写入Kafka,就会返回一个RecordMetaData对象 包含了Topic和Partition信息,以及记录在分区里的偏移量 如果写入失败,就会返回一个错误 生产者在收到错误之后会尝试重新发送消息,几次之后如果还...




