
Java性能 -- 正则表达式
元字符

- 正则表达式使用一些特定的元字符来检索、匹配和替换符合规则的字符串
- 元字符:普通字符、标准字符、限定字符(量词)、定位字符(边界字符)
正则表达式引擎
- 正则表达式是一个用正则符号写出来的公式
- 程序对正则表达式进行语法分析,建立语法分析树
- 再根据语法分析树结合正则表达式引擎生成执行程序(状态机),用于字符匹配
- 正则表达式引擎是一套核心算法,用于建立状态机
- 小结
- 正则表达式 => 语法分析树
- 语法分析树 + 正则表达引擎 => 状态机 => 用于字符匹配
- 目前实现正则表达式引擎的方式有两种
- DFA自动机(Deterministic Finite Automaton,确定有限状态自动机)
- NFA自动机(Nondeterministic Finite Automaton,非确定有限状态自动机)
- DFA自动机的构造代价远大于NFA自动机,但DFA自动机的执行效率高于NFA自动机
- 假设一个字符串的长度为n,如果采用DFA自动机作为正则表达式引擎,则匹配的时间复杂度为
O(n) - 如果采用NFA自动机作为正则表达式引擎,NFA自动机在匹配过程中存在大量的分支和回溯,假设NFA的状态数为s,
- 则匹配的时间复杂度为**
O(ns)**
- 则匹配的时间复杂度为**
- 假设一个字符串的长度为n,如果采用DFA自动机作为正则表达式引擎,则匹配的时间复杂度为
- NFA自动机的优势是支持更多高级功能,但都是基于_子表达式独立进行匹配_
- 因此在编程语言里,使用的正则表达式库都是基于NFA自动机实现的
NFA自动机
匹配过程
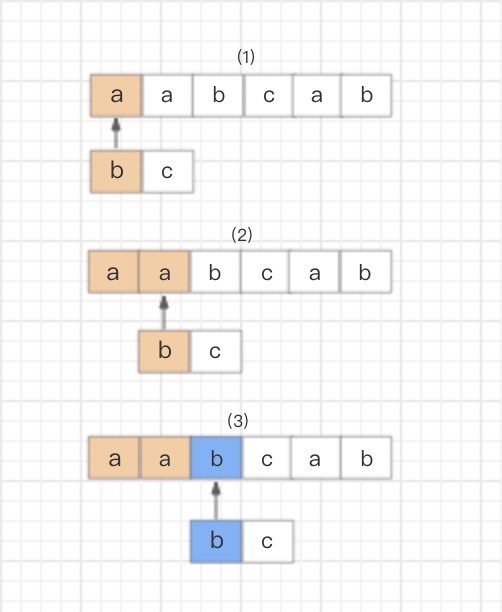
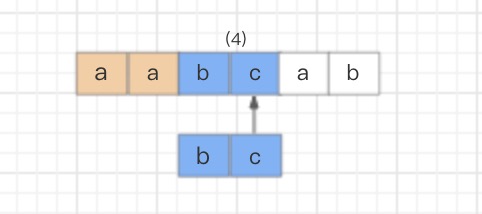
- NFA自动机会读取正则表达式的每一个字符,拿去和目标字符串匹配
- 匹配成功则换正则表达式的下一个字符,反之就继续就和目标字符串的下一个字符进行匹配
1 | text="aabcab" |
回溯
- 用NFA自动机实现的比较复杂的正则表达式,在匹配过程中经常会引起回溯问题
- 大量的回溯会长时间占用CPU,从而带来系统性能开销
1 | text="abbc" |
读取正则表达式第一个匹配符a和字符串第一个字符a进行比较,a对a,匹配![]()
读取正则表达式第二个匹配符b{1,3}和字符串的第二个字符b进行比较,匹配,但b{1,3}表示1~3个字符,而NFA自动机具有贪婪特性,所以不会读取正则表达式的下一个匹配符c![]()
使用b{1,3}和字符串的第四个字符c进行比较,发现不匹配,此时就会发生回溯,已经读取的字符串第四个字符c将被吐出去,指针回到第三个字符b的位置![]()
发生回溯后,读取正则表达式的下一个匹配符c,和字符串的第四个字符c进行比较,结果匹配![]()
避免回溯
避免回溯的方法:使用懒惰模式和独占模式
贪婪模式(Greedy)
- 在数量匹配中,如果单独使用
+、?、*、{min,max}等量词,正则表达式会匹配尽可能多的内容 text="abbc" , regex="ab{1,3}c",发生了一次匹配失败,就会引起一次回溯text="abbbc" , regex="ab{1,3}c",匹配成功
懒惰模式(Reluctant)
- 在懒惰模式下,正则表达式会尽可能少地重复匹配字符,如果匹配成功,会继续匹配剩余的字符串
- 使用
?开启懒惰模式,text="abc" , regex="ab{1,3}?c"- 匹配结果是
"abc",在该模式下NFA自动机首先选择最小的匹配范围,即匹配1个b字符,避免了回溯问题
- 匹配结果是
独占模式(Possessive)
- 和贪婪模式一样,独占模式一样会最大限度地匹配更多内容,但在匹配失败时会结束匹配,不会发生回溯问题
- 使用
+开启懒惰模式,text="abbc" , regex="ab{1,3}+bc"- 结果是不匹配,结束匹配,不会发生回溯问题
代码
1 | match("ab{1,3}c", "abbc"); // abbc,贪婪模式,产生回溯 |
正则表达式的优化
- 少用贪婪模式,多用独占模式(避免回溯)
- 减少分支选择,分支选择类型
"(X|Y|Z)"的正则表达式会降低性能,尽量减少使用,如果一定要使用- 考虑选择的顺序,将比较常用的选择放在前面,使它们可以较快地被匹配
- 提取共用模式,
(abcd|abef)=>ab(cd|ef) - 如果是简单的分支选择类型,可以用三次index代替
(X|Y|Z)
- 减少捕获嵌套
- 捕获组:把正则表达式中,子表达式匹配的内容保存到以数字编号或显式命名的数组中,一般一个
()就是一个捕获组- 每个捕获组都有一个编号,编号0代表整个匹配到的内容
- 非捕获组:参与匹配却不进行分组编号的捕获组,其表达式一般由
(?:exp)组成 - 减少不需要获取的分组,可以提高正则表达式的性能
- 捕获组:把正则表达式中,子表达式匹配的内容保存到以数字编号或显式命名的数组中,一般一个
捕获组
1 | String text = "<input high=\"20\" weight=\"70\">test</input>"; |
非捕获组
1 | String text = "<input high=\"20\" weight=\"70\">test</input>"; |
小结
在做好性能测试的前提下,可以使用正则表达式,否则能不用就不用,避免造成更多的性能问题
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-07-18
Java性能 -- HashMap
实现结构 HashMap是基于哈希表实现的,继承了AbstractMap并且实现了Map接口 HashMap根据键的Hash值来决定对应值的存储位置,通过这种索引方式,HashMap获取数据的速度会非常快 当发生哈希冲突时,有3种常用的解决方法:开放定址法、再哈希函数法、链地址法 开放定址法 当发生哈希冲突时,如果哈希表未被填满,说明在哈希表中必然还有空位置 可以把Key存放到冲突位置后面的空位置上 该方法存在很多问题,例如查找、扩容等,不推荐 再哈希函数法 在同义词产生地址冲突时再计算另一个哈希函数地址,直到不再冲突 这种方法不容易产生聚集,但却增加了计算时间 链地址法 HashMap综合考虑了所有因素,采用了链地址法来解决哈希冲突问题 该方法采用了数组(哈希表)+链表的数据结构,当发生哈希冲突时,就用一个链表结构存储相同Hash值的数据 重要属性NodeHashMap是由一个Node数组构成的,每个Node包含一个Key-Value键值对 1transient Node<K,V>[] table; Node类是HashMap的一个内部类,定义了一个next指针,指...

2019-07-31
Java性能 -- 序列化
序列化方案 Java RMI采用的是Java序列化 Spring Cloud采用的是_JSON序列化_ Dubbo虽然兼容Java序列化,但默认使用的是_Hessian序列化_ Java序列化原理 Serializable JDK提供了输入流对象ObjectInputStream和输出流对象ObjectOutputStream 它们只能对实现了Serializable接口的类的对象进行序列化和反序列化 12345// 只能对实现了Serializable接口的类的对象进行序列化// java.io.NotSerializableException: java.lang.ObjectObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(FILE_PATH));oos.writeObject(new Object());oos.close(); transient ObjectOutputStream的默认序列化方式,仅对对象的非transient的实例变量进行序列化 不会序列化对象的transient的实例变量...

2019-08-18
Java性能 -- Lock优化
Lock / synchronizedLock锁的基本操作是通过乐观锁实现的,由于Lock锁也会在阻塞时被挂起,依然属于悲观锁 synchronized Lock 实现方式 JVM层实现 Java底层代码实现 锁的获取 JVM隐式获取 lock() / tryLock() / tryLock(timeout, unit) / lockInterruptibly() 锁的释放 JVM隐式释放 unlock() 锁的类型 非公平锁、可重入 非公平锁/公平锁、可重入 锁的状态 不可中断 可中断 锁的性能 高并发下会升级为重量级锁 更稳定 实现原理 Lock锁是基于Java实现的锁,Lock是一个接口 常见的实现类:ReentrantLock、ReentrantReadWriteLock,都是依赖AbstractQueuedSynchronizer(AQS)实现 AQS中包含了一个基于链表实现的等待队列(即CLH队列),用于存储所有阻塞的线程 AQS中有一个state变量,该变量对ReentrantLock来说表示加...

2019-06-02
Java性能 -- 性能调优标准
性能瓶颈 CPU 如果应用需要大量计算,会长时间占用CPU资源,导致其它应用因无法争夺到CPU而响应缓慢 场景:代码递归导致的无限循环,JVM频繁的Full GC、多线程编程造成的大量上下文切换 内存 Java程序一般通过JVM对内存进行分配管理,主要使用JVM中的堆内存来存储Java创建的对象 但内存空间有限,当内存空间被占满,对象无法回收,会导致内存溢出,内存泄露等问题 磁盘IO 网络:带宽 异常:Java应用中,抛出异常需要构建异常栈,对异常进行捕获和处理,这个过程非常消耗系统性能 数据库:数据库的操作往往涉及到磁盘IO的读写,大量的数据库读写操作,会导致磁盘IO的性能瓶颈 锁竞争 在并发编程中,经常需要使用到多线程,并发读写同一个共享资源,为了保证数据原子性,会用到锁 锁的使用会带来上下文切换,从而给系统带来性能开销 性能指标响应时间 一个接口的响应时间一般在毫秒级 数据库响应时间:数据库操作所消耗的时间,往往是整个请求链中最耗时的 服务端响应时间:包括Nginx分发请求所消耗的时间以及服务端程序执行所消耗的时间 网络响应时间:在网络传输时,网络硬件对需要传输的请求进行解析...

2019-06-09
Java性能 -- 字符串
实现 在Java 6以及之前的版本中,String对象是对char数组进行了封装实现的对象 主要四个成员变量:char数组、偏移量offset、字符数量count、哈希值hash String对象通过offset和count两个属性来定位char数组,获取字符串 这样可以高效快速地共享数组对象,同时节省内存空间,但也有可能会导致内存泄露 Java 7/8,String类中不再有offset和count两个变量 这样String对象占用的内存稍微少了一点 另外,String.substring不再共享char[],从而解决了使用该方法可能导致的内存泄露问题 从Java 9开始,将char[]修改为byte[],同时维护了一个新的属性coder,它是一个编码格式的标识 一个char字符占用16位,2个字节,用一个char去存储单字节编码的字符会非常浪费 Java 9的String类为了节约内存空间,使用了占用8位,1个字节的byte数组来存放字符串 coder的作用:使用length()或者indexOf() coder有两个默认值:0代表LATIN1,1代表UTF16 ...
2019-09-22
Java性能 -- 生产者消费者模式 + 装饰器模式
生产者消费者模式实现方式Object的wait/notify/notifyAll 基于Object的wait/notify/notifyAll与对象监视器(Monitor)实现线程间的等待和通知 这种方式实现的生产者消费者模式是基于内核实现的,可能会导致大量的上下文切换,性能不是最理想的 Lock中Condition的await/signal/signalAll 相对于Object的wait/notify/notifyAll,更推荐JUC包提供的Lock && Condition实现的生产者消费者模式 Lock && Condition实现的生产者消费者模式,是基于Java代码层实现的,在性能和扩展性方面更有优势 BlockingQueue 简单明了 限流算法漏桶算法通过限制容量池大小来控制流量,而令牌桶算法则通过限制发放令牌的速率来控制流量 漏桶算法 请求如果要进入业务层,就必须经过漏桶,而漏桶出口的请求速率是均衡的 如果漏桶已经满了,请求将会溢出,不会因为入口的请求量突然增加而导...




