
Java性能 -- HashMap
实现结构
- HashMap是基于哈希表实现的,继承了AbstractMap并且实现了Map接口
- HashMap根据键的Hash值来决定对应值的存储位置,通过这种索引方式,HashMap获取数据的速度会非常快
- 当发生哈希冲突时,有3种常用的解决方法:开放定址法、再哈希函数法、链地址法
- 开放定址法
- 当发生哈希冲突时,如果哈希表未被填满,说明在哈希表中必然还有空位置
- 可以把Key存放到冲突位置后面的空位置上
- 该方法存在很多问题,例如查找、扩容等,不推荐
- 再哈希函数法
- 在同义词产生地址冲突时再计算另一个哈希函数地址,直到不再冲突
- 这种方法不容易产生聚集,但却增加了计算时间
- 链地址法
- HashMap综合考虑了所有因素,采用了链地址法来解决哈希冲突问题
- 该方法采用了数组(哈希表)+链表的数据结构,当发生哈希冲突时,就用一个链表结构存储相同Hash值的数据
- 开放定址法
重要属性
Node
HashMap是由一个Node数组构成的,每个Node包含一个Key-Value键值对
1 | transient Node<K,V>[] table; |
Node类是HashMap的一个内部类,定义了一个next指针,指向具有相同hash值的Node对象,构成链表
1 | static class Node<K,V> implements Map.Entry<K,V> { |
loadFactor + threshold
1 | int threshold; |
- HashMap还有两个重要的属性:加载因子(loadFactor)和边界值(threshold)
- loadFactor用来间接设置Entry数组(哈希表)的内存空间大小,默认值为0.75
- 对于使用链表法的哈希表来说,查找一个元素的平均时间为
O(1+n),n为遍历链表的长度- 加载因子越大,对空间的利用越充分,链表的长度越长,查找效率越低
- 加载因子太小,哈希表的数据将过于稀疏,对空间造成严重浪费
- Entry数组的threshold是通过初始容量和loadFactor计算所得
优化
添加元素
根据key的hashCode()返回值,再通过hash()计算出hash值,再通过(n-1)&hash决定Node的存储位置
1 | public V put(K key, V value) { |
流程
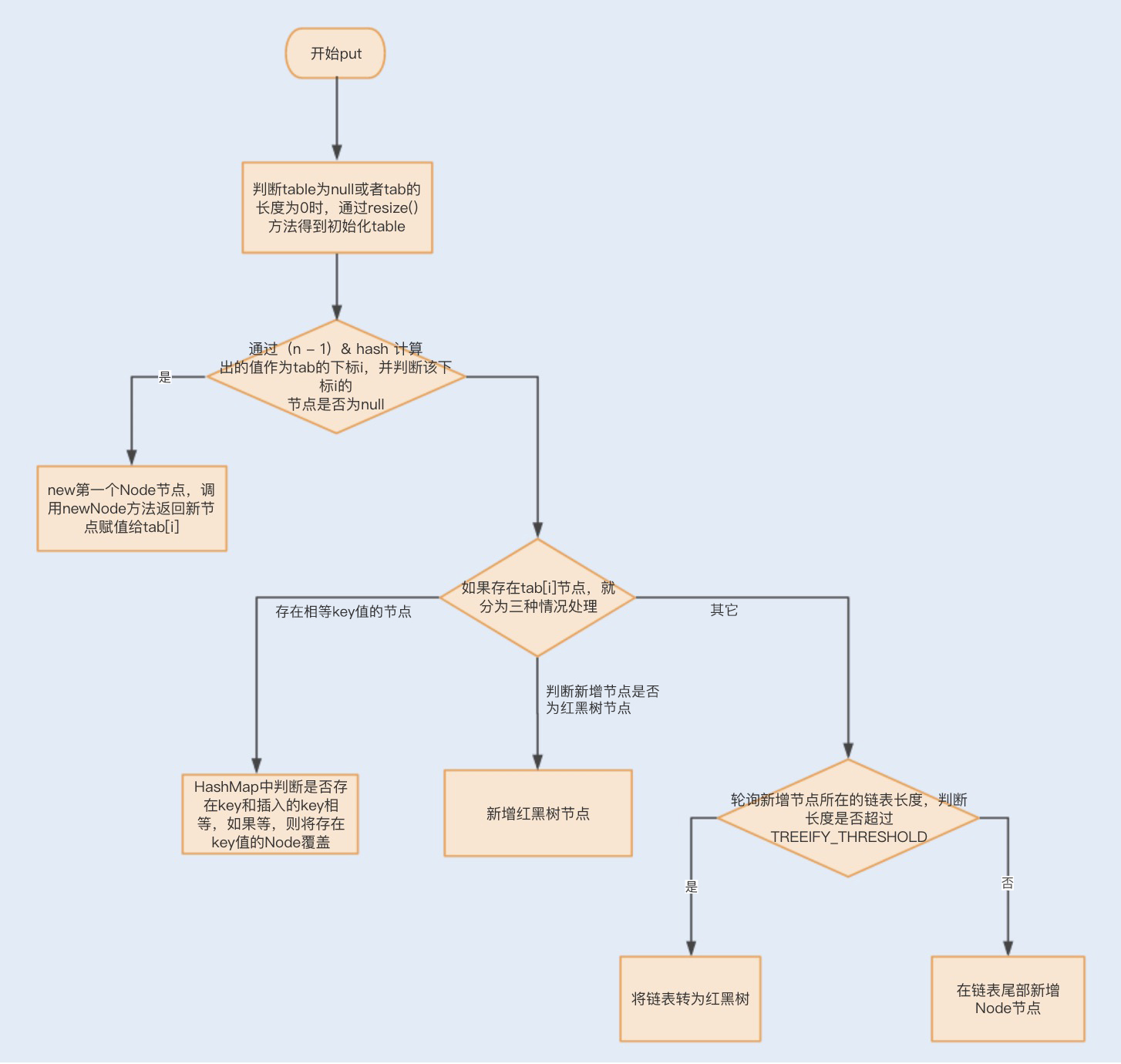
putVal
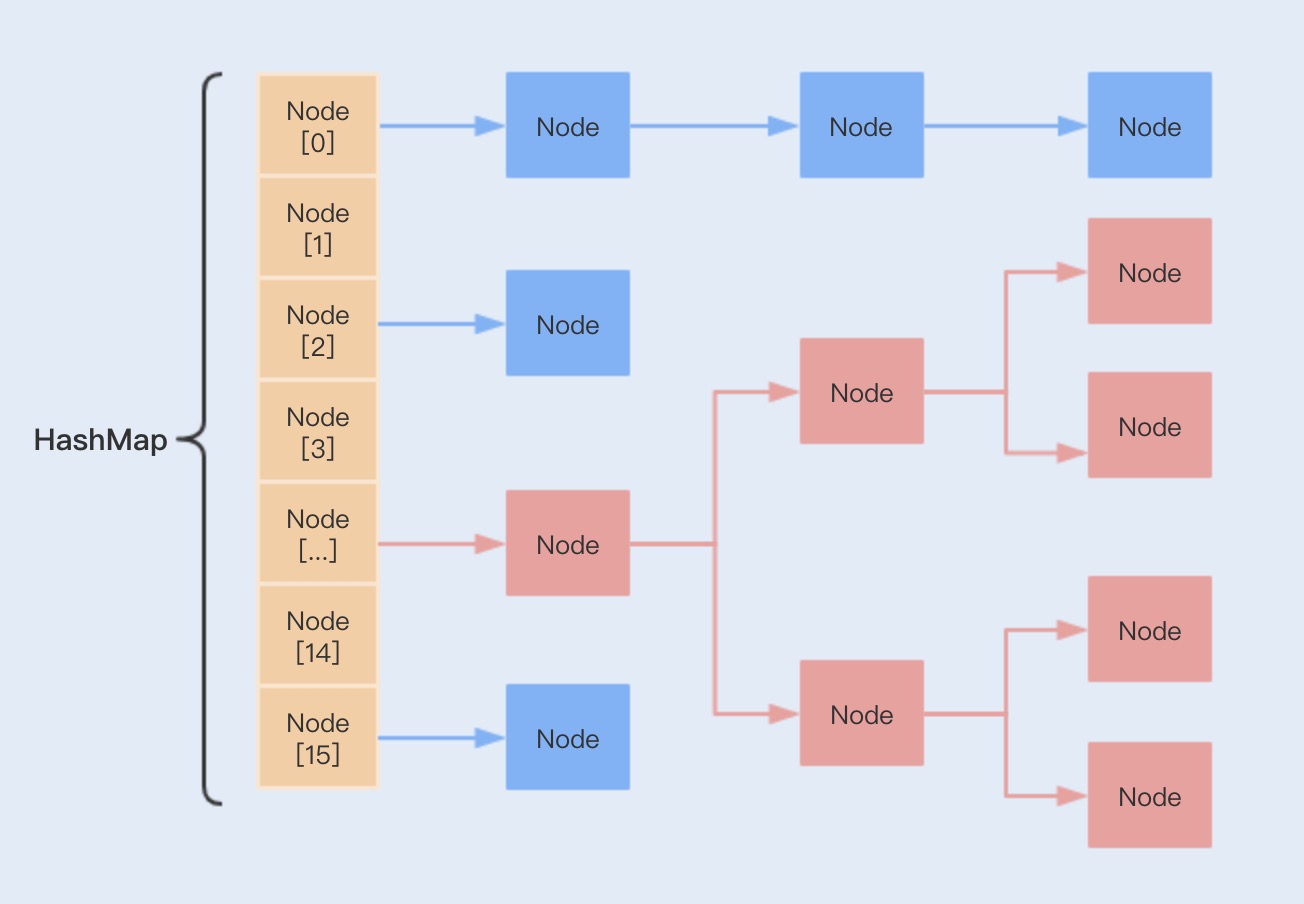
在JDK 1.8中,HashMap引入了红黑树数据结构来提升链表的查询效率(当链表的长度超过8,红黑树的查询效率比链表高)
当链表长度超过8,HashMap会将链表转换为红黑树,此时新增元素会存在左旋和右旋,因此效率会降低
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
获取元素
- 当HashMap中只存在数组,而数组中没有Node链表时,是HashMap查询数据性能最好的时候
- 一旦发生大量的哈希冲突,就会产生Node链表,这时每次查询都可能遍历Node链表,从而降低查询性能
- 特别在链表长度过长的情况下,性能将明显降低,而红黑树能很好地解决了这个问题
- 使得查询的平均时间复杂度降低到
O(log(n)),链表越长,使用红黑树替换后的查询效率提升越明显
- 也可以重写Key的hashCode方法,降低哈希冲突,从而减少链表的产生
扩容
- HashMap也是数组类型的数据结构,也一样存在扩容的情况
- JDK 1.7
- 分别取出数组元素,一般该元素是最后一个放入链表的元素
- 然后遍历以该元素为头的单向链表元素,依据每个被遍历元素的hash值计算其在新数组中的下标,然后进行交换
- 将原来哈希冲突的单向链表尾部变成扩容后单向链表的头部
- JDK 1.8
- 扩容数组的长度是2倍的关系,假设初始tableSize=4要扩容到8,就是0100到1000的变化
- 在扩容时,只需要判断原来hash值与oldCap的按位与结果,重新分配索引
hash & oldCap == 0,说明旧有的索引就能覆盖hash & oldCap == 1,说明旧有的索引不能覆盖,索引需要+oldCap
1 | // JDK 1.8 |
小结
- HashMap通过哈希表的数据结构来存储键值对,好处:查询效率高
- 如果查询操作比较频繁,可以适当减小loadFactor,如果对内存利用率要求比较高,可以适当增加loadFactor
- 在预知存储数据量的情况下,可以提前设置初始容量(初始容量 = 预知数据量 / 加载因子)
- 可以减少resize()操作,提高HashMap的效率
- HashMap使用数组+链表方式实现链地址法,当有哈希冲突时,将冲突的键值对链成一个链表
- 如果链表过长,查询数据的时间复杂度会增加,HashMap在JDK 1.8中使用红黑树来解决这个问题
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-08-07
Java性能 -- 优化RPC网络通信
服务框架的核心 大型服务框架的核心:RPC通信 微服务的核心是远程通信和服务治理 远程通信提供了服务之间通信的桥梁,服务治理提供了服务的后勤保障 服务的拆分增加了通信的成本,因此远程通信很容易成为系统瓶颈 在满足一定的服务治理需求的前提下,对远程通信的性能需求是技术选型的主要影响因素 很多微服务框架中的服务通信是基于RPC通信实现的 在没有进行组件扩展的前提下,Spring Cloud是基于Feign组件实现RPC通信(基于HTTP+JSON序列化) Dubbo是基于SPI扩展了很多RPC通信框架,包括RMI、Dubbo、Hessian等(默认为Dubbo+Hessian序列化) 性能测试基于Dubbo:2.6.4,单一TCP长连接+Protobuf(响应时间和吞吐量更优),短连接的HTTP+JSON序列化 RPC通信架构演化无论是微服务、SOA、还是RPC架构,都是分布式服务架构,都需要实现服务之间的互相通信,通常把这种通信统称为RPC通信 概念 RPC:Remote Process Call,远程服务调用,通过网络请求远程计算机程序服务的通信技术 RPC框架封装了底层网络通信和序列...

2019-09-07
Java性能 -- JVM内存模型
JVM内存模型 堆 堆是JVM内存中最大的一块内存空间,被所有线程共享,几乎所有对象和数组都被分配到堆内存中 堆被划分为新生代和老年代,新生代又被划分为Eden区和Survivor区(From Survivor + To Survivor) 永久代 在Java 6中,永久代在非堆内存中 在Java 7中,永久代的静态变量和运行时常量池被合并到堆中 在Java 8中,永久代被元空间取代 程序计数器 程序计数器是一块很小的内存空间,主要用来记录各个线程执行的字节码的地址 Java是多线程语言,当执行的线程数量超过CPU数量时,线程之间会根据时间片轮询争夺CPU资源 当一个线程的时间片用完了,或者其他原因导致该线程的CPU资源被提前抢夺 那么退出的线程需要单独的程序计数器来记录下一条运行的指令 方法区 方法区 != 永久代 HotSpot VM使用了永久代来实现方法区,但在其他VM(Oracle JRockit、IBM J9)不存在永久代一说 方法区只是JVM规范的一部分,在HotSpot VM中,使用了永久代来实现JVM规范的方法区 方法区主要用来存放已被虚拟机加载的类相关信...

2019-09-22
Java性能 -- 生产者消费者模式 + 装饰器模式
生产者消费者模式实现方式Object的wait/notify/notifyAll 基于Object的wait/notify/notifyAll与对象监视器(Monitor)实现线程间的等待和通知 这种方式实现的生产者消费者模式是基于内核实现的,可能会导致大量的上下文切换,性能不是最理想的 Lock中Condition的await/signal/signalAll 相对于Object的wait/notify/notifyAll,更推荐JUC包提供的Lock && Condition实现的生产者消费者模式 Lock && Condition实现的生产者消费者模式,是基于Java代码层实现的,在性能和扩展性方面更有优势 BlockingQueue 简单明了 限流算法漏桶算法通过限制容量池大小来控制流量,而令牌桶算法则通过限制发放令牌的速率来控制流量 漏桶算法 请求如果要进入业务层,就必须经过漏桶,而漏桶出口的请求速率是均衡的 如果漏桶已经满了,请求将会溢出,不会因为入口的请求量突然增加而导...

2019-08-25
Java性能 -- 线程上下文切换
线程数量 在并发程序中,并不是启动更多的线程就能让程序最大限度地并发执行 线程数量设置太小,会导致程序不能充分地利用系统资源 线程数量设置太大,可能带来资源的过度竞争,导致上下文切换,带来的额外的系统开销 上下文切换 在单处理器时期,操作系统就能处理多线程并发任务,处理器给每个线程分配CPU时间片,线程在CPU时间片内执行任务 CPU时间片是CPU分配给每个线程执行的时间段,一般为几十毫秒 时间片决定了一个线程可以连续占用处理器运行的时长 当一个线程的时间片用完,或者因自身原因被迫暂停运行,此时另一个线程会被操作系统选中来占用处理器 上下文切换(Context Switch):一个线程被暂停剥夺使用权,另一个线程被选中开始或者继续运行的过程 切出:一个线程被剥夺处理器的使用权而被暂停运行 切入:一个线程被选中占用处理器开始运行或者继续运行 切出切入的过程中,操作系统需要保存和恢复相应的进度信息,这个进度信息就是_上下文_ 上下文的内容 寄存器的存储内容:CPU寄存器负责存储已经、正在和将要执行的任务 程序计数器存储的指令内容:程序计数器负责存储CPU正在执行的指令位置、即将执行的下一条...
2019-06-26
Java性能 -- ArrayList + LinkedList
List接口 ArrayList、Vector、LinkedList继承了AbstractList,AbstractList实现了List,同时继承了AbstractCollection ArrayList和Vector使用了数组实现,LinkedList使用了双向链表实现 ArrayList常见问题 ArrayList的对象数组elementData使用了transient(表示不会被序列化)修饰,为什么? ArrayList在大量新增元素的场景下,效率一定会变慢? 如果要循环遍历ArrayList,采用for循环还是迭代循环? 类签名123public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {} ArrayList实现了List接口,继承了AbstractList抽象类,底层是数组实现,并且实现了自增扩容 ArrayList实现了Clone...

2019-09-04
Java性能 -- 命令行工具
free12345$ free -m total used free shared buffers cachedMem: 15948 15261 687 304 37 6343-/+ buffers/cache: 8880 7068Swap: 0 0 0 Mem是从操作系统的角度来看的 总共有15948M物理内存,其中15261M被使用了,还有687可用,15948 = 15261 + 687 有若干线程共享了304M物理内存,已经被弃用(值总为0) buffer / cached :为了提高IO性能,由OS管理 A buffer is something that has yet to be “written” to disk. A cache is something that has been “read” from the disk and sto...




