
Java性能 -- HashMap
实现结构
- HashMap是基于哈希表实现的,继承了AbstractMap并且实现了Map接口
- HashMap根据键的Hash值来决定对应值的存储位置,通过这种索引方式,HashMap获取数据的速度会非常快
- 当发生哈希冲突时,有3种常用的解决方法:开放定址法、再哈希函数法、链地址法
- 开放定址法
- 当发生哈希冲突时,如果哈希表未被填满,说明在哈希表中必然还有空位置
- 可以把Key存放到冲突位置后面的空位置上
- 该方法存在很多问题,例如查找、扩容等,不推荐
- 再哈希函数法
- 在同义词产生地址冲突时再计算另一个哈希函数地址,直到不再冲突
- 这种方法不容易产生聚集,但却增加了计算时间
- 链地址法
- HashMap综合考虑了所有因素,采用了链地址法来解决哈希冲突问题
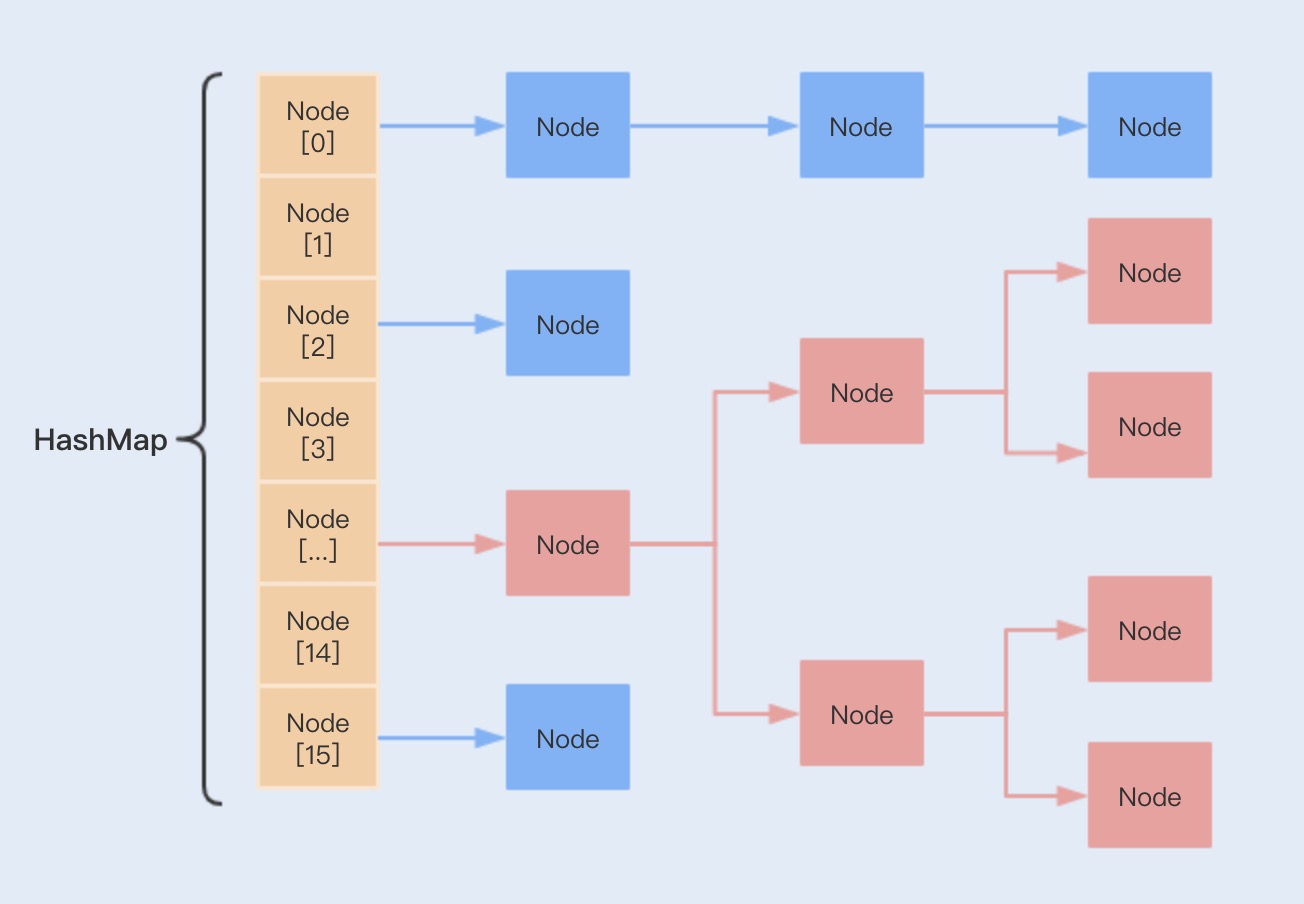
- 该方法采用了数组(哈希表)+链表的数据结构,当发生哈希冲突时,就用一个链表结构存储相同Hash值的数据
- 开放定址法
重要属性
Node
HashMap是由一个Node数组构成的,每个Node包含一个Key-Value键值对
1 | transient Node<K,V>[] table; |
Node类是HashMap的一个内部类,定义了一个next指针,指向具有相同hash值的Node对象,构成链表
1 | static class Node<K,V> implements Map.Entry<K,V> { |
loadFactor + threshold
1 | int threshold; |
- HashMap还有两个重要的属性:加载因子(loadFactor)和边界值(threshold)
- loadFactor用来间接设置Entry数组(哈希表)的内存空间大小,默认值为0.75
- 对于使用链表法的哈希表来说,查找一个元素的平均时间为
O(1+n),n为遍历链表的长度- 加载因子越大,对空间的利用越充分,链表的长度越长,查找效率越低
- 加载因子太小,哈希表的数据将过于稀疏,对空间造成严重浪费
- Entry数组的threshold是通过初始容量和loadFactor计算所得
优化
添加元素
根据key的hashCode()返回值,再通过hash()计算出hash值,再通过(n-1)&hash决定Node的存储位置
1 | public V put(K key, V value) { |
流程
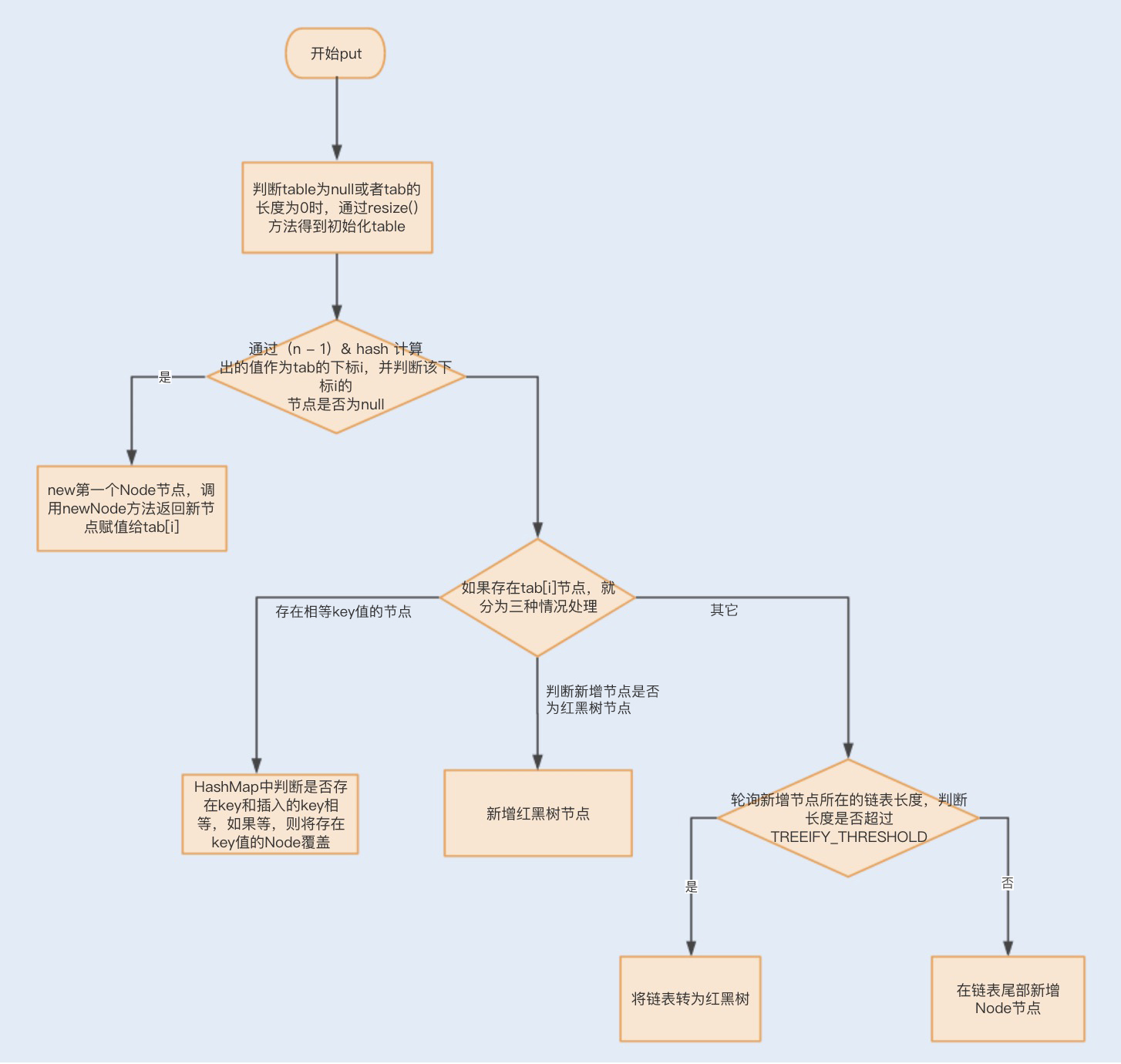
putVal
在JDK 1.8中,HashMap引入了红黑树数据结构来提升链表的查询效率(当链表的长度超过8,红黑树的查询效率比链表高)
当链表长度超过8,HashMap会将链表转换为红黑树,此时新增元素会存在左旋和右旋,因此效率会降低
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
获取元素
- 当HashMap中只存在数组,而数组中没有Node链表时,是HashMap查询数据性能最好的时候
- 一旦发生大量的哈希冲突,就会产生Node链表,这时每次查询都可能遍历Node链表,从而降低查询性能
- 特别在链表长度过长的情况下,性能将明显降低,而红黑树能很好地解决了这个问题
- 使得查询的平均时间复杂度降低到
O(log(n)),链表越长,使用红黑树替换后的查询效率提升越明显
- 也可以重写Key的hashCode方法,降低哈希冲突,从而减少链表的产生
扩容
- HashMap也是数组类型的数据结构,也一样存在扩容的情况
- JDK 1.7
- 分别取出数组元素,一般该元素是最后一个放入链表的元素
- 然后遍历以该元素为头的单向链表元素,依据每个被遍历元素的hash值计算其在新数组中的下标,然后进行交换
- 将原来哈希冲突的单向链表尾部变成扩容后单向链表的头部
- JDK 1.8
- 扩容数组的长度是2倍的关系,假设初始tableSize=4要扩容到8,就是0100到1000的变化
- 在扩容时,只需要判断原来hash值与oldCap的按位与结果,重新分配索引
hash & oldCap == 0,说明旧有的索引就能覆盖hash & oldCap == 1,说明旧有的索引不能覆盖,索引需要+oldCap
1 | // JDK 1.8 |
小结
- HashMap通过哈希表的数据结构来存储键值对,好处:查询效率高
- 如果查询操作比较频繁,可以适当减小loadFactor,如果对内存利用率要求比较高,可以适当增加loadFactor
- 在预知存储数据量的情况下,可以提前设置初始容量(初始容量 = 预知数据量 / 加载因子)
- 可以减少resize()操作,提高HashMap的效率
- HashMap使用数组+链表方式实现链地址法,当有哈希冲突时,将冲突的键值对链成一个链表
- 如果链表过长,查询数据的时间复杂度会增加,HashMap在JDK 1.8中使用红黑树来解决这个问题
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-08-15
Java性能 -- synchronized锁升级优化
synchronized / Lock JDK 1.5之前,Java通过synchronized关键字来实现锁功能 synchronized是JVM实现的内置锁,锁的获取和释放都是由JVM隐式实现的 JDK 1.5,并发包中新增了Lock接口来实现锁功能 提供了与synchronized类似的同步功能,但需要显式获取和释放锁 Lock同步锁是基于Java实现的,而synchronized是基于底层操作系统的Mutex Lock实现的 每次获取和释放锁都会带来用户态和内核态的切换,从而增加系统的性能开销 在锁竞争激烈的情况下,synchronized同步锁的性能很糟糕 在JDK 1.5,在单线程重复申请锁的情况下,synchronized锁性能要比Lock的性能差很多 JDK 1.6,Java对synchronized同步锁做了充分的优化,甚至在某些场景下,它的性能已经超越了Lock同步锁 实现原理12345678910public class SyncTest { public synchronized void method1() { ...

2019-09-19
Java性能 -- 原型模式 + 享元模式
原型模式 原型模式:通过给出一个原型对象来指明所创建的对象的类型,然后使用自身实现的克隆接口来复制这个原型对象 使用这种方式创新的对象的话,就无需再通过new实例化来创建对象了 Object类的clone方法是一个Native方法,可以直接操作内存中的二进制流,所以相对new实例化来说,性能更佳 实现原型模式12345678910111213141516171819202122232425262728class Prototype implements Cloneable { @Override public Prototype clone() { Prototype prototype = null; try { prototype = (Prototype) super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } ...

2019-09-17
Java性能 -- 单例模式
饿汉模式class1234567891011// 饿汉模式public final class Singleton { private static Singleton instance = new Singleton(); private Singleton() { } public static Singleton getInstance() { return instance; }} 使用了static修饰了成员变量instance,所以该变量会在类初始化的过程中被收集进_类构造器<clinit>_ 在多线程场景下,JVM会保证只有一个线程能够执行该类的<clinit>方法,其它线程将会被阻塞等待 等到唯一的一次<clinit>方法执行完成后,其它线程将不会再执行<clinit>方法,转而执行自己的代码 因此,static修饰的成员变量instance,在多线程的情况下能保证只实例化一次 在类初始化阶段就已经在堆内存中开辟了一块内存,用...

2019-08-31
Java性能 -- 线程池大小
线程池原理 在Hotspot JVM的线程模型中,Java线程被一对一映射为内核线程 Java使用线程执行程序时,需要创建一个内核线程,当该Java线程被终止时,这个内核线程也会被回收 Java线程的创建和销毁将会消耗一定的计算机资源,从而增加系统的性能开销 大量创建线程也会给系统带来性能问题,线程会抢占内存和CPU资源,可能会发生内存溢出、CPU超负载等问题 线程池:即可以提高线程复用,也可以固定最大线程数,防止无限制地创建线程 当程序提交一个任务需要一个线程时,会去线程池查找是否有空闲的线程 如果有,则直接使用线程池中的线程工作,如果没有,则判断当前已创建的线程数是否超过最大线程数 如果未超过,则创建新线程,如果已经超过,则进行排队等待或者直接抛出异常 线程池框架Executor Java最开始提供了ThreadPool来实现线程池,为了更好地实现用户级的线程调度,Java提供了一套Executor框架 Executor框架包括了ScheduledThreadPoolExecutor和ThreadPoolExecutor两个核心线程池,核心原理一样 ScheduledThreadPoo...
2019-06-26
Java性能 -- ArrayList + LinkedList
List接口 ArrayList、Vector、LinkedList继承了AbstractList,AbstractList实现了List,同时继承了AbstractCollection ArrayList和Vector使用了数组实现,LinkedList使用了双向链表实现 ArrayList常见问题 ArrayList的对象数组elementData使用了transient(表示不会被序列化)修饰,为什么? ArrayList在大量新增元素的场景下,效率一定会变慢? 如果要循环遍历ArrayList,采用for循环还是迭代循环? 类签名123public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {} ArrayList实现了List接口,继承了AbstractList抽象类,底层是数组实现,并且实现了自增扩容 ArrayList实现了Clone...
2019-06-02
Java性能 -- 性能调优标准
性能瓶颈 CPU 如果应用需要大量计算,会长时间占用CPU资源,导致其它应用因无法争夺到CPU而响应缓慢 场景:代码递归导致的无限循环,JVM频繁的Full GC、多线程编程造成的大量上下文切换 内存 Java程序一般通过JVM对内存进行分配管理,主要使用JVM中的堆内存来存储Java创建的对象 但内存空间有限,当内存空间被占满,对象无法回收,会导致内存溢出,内存泄露等问题 磁盘IO 网络:带宽 异常:Java应用中,抛出异常需要构建异常栈,对异常进行捕获和处理,这个过程非常消耗系统性能 数据库:数据库的操作往往涉及到磁盘IO的读写,大量的数据库读写操作,会导致磁盘IO的性能瓶颈 锁竞争 在并发编程中,经常需要使用到多线程,并发读写同一个共享资源,为了保证数据原子性,会用到锁 锁的使用会带来上下文切换,从而给系统带来性能开销 性能指标响应时间 一个接口的响应时间一般在毫秒级 数据库响应时间:数据库操作所消耗的时间,往往是整个请求链中最耗时的 服务端响应时间:包括Nginx分发请求所消耗的时间以及服务端程序执行所消耗的时间 网络响应时间:在网络传输时,网络硬件对需要传输的请求进行解析...




