
Kafka -- 生产者消息分区机制
分区概念
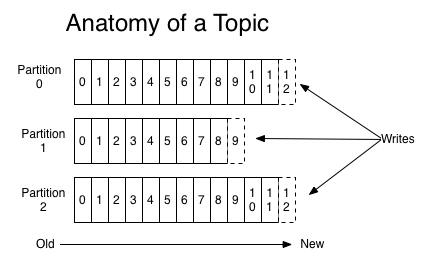
- 主题是承载真实数据的逻辑容器,主题之下分为若干个分区,Kafka的消息组织方式为三级结构:主题、分区、消息
- 主题下的每条消息只会保存在某个分区中,而不会在多个分区中被保存多份
- 分区的作用是提供负载均衡的能力,实现系统的高伸缩性
- 不同的分区能够被放置在不同的机器节点上,而数据读写操作的粒度也是分区
- 每个机器节点都能独立地执行各自分区的读写请求处理,还可以通过添加新的机器节点来增加整体系统的吞吐量
- 分区在不同的分布式系统有不同的叫法,但分区的思想都是类似的
- Kafka – Partition
- MongoDB、Elasticsearch – Shard
- HBase – Region
分区策略
- 分区策略:决定生产者将消息发送到哪个分区的算法,Kafka提供了默认的分区策略,也支持自定义的分区策略
- 自定义的分区策略,需要显式地配置生产者端的参数partitioner.class
- 实现接口:org.apache.kafka.clients.producer.Partitioner
- 消息数据:topic、key、keyBytes、value、valueBytes
- 集群数据:cluster
1 | public interface Partitioner extends Configurable, Closeable { |
轮询策略
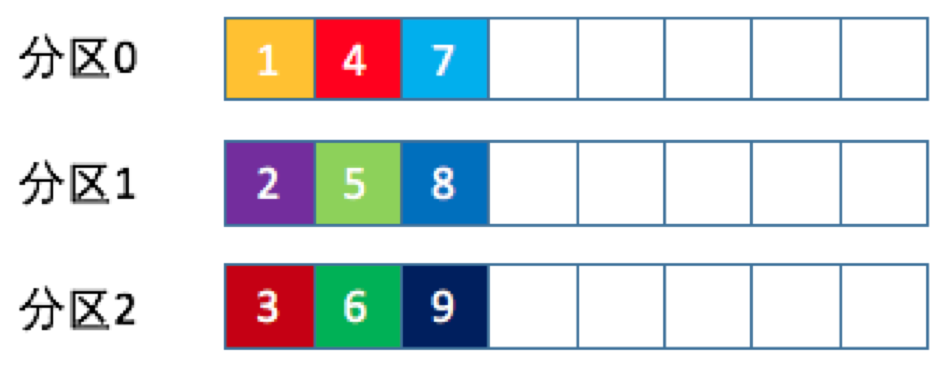
- 轮询策略是Kafka Java生产者的默认分区策略
- 轮询策略的负载均衡表现非常优秀,总能保证消息最大限度地被平均分配到所有分区上,默认情况下它是最合理的分区策略
随机策略
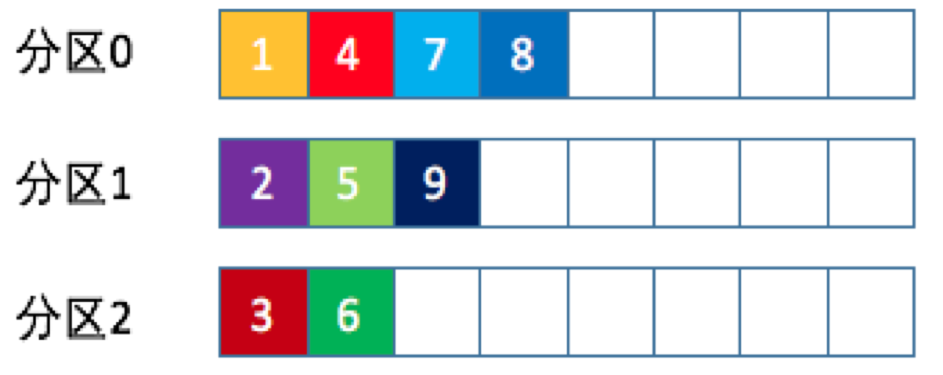
从实际表现来看,随机策略要逊于轮询策略,如果追求数据的均匀分布,建议使用轮询策略
1 |
|
按消息键保序策略
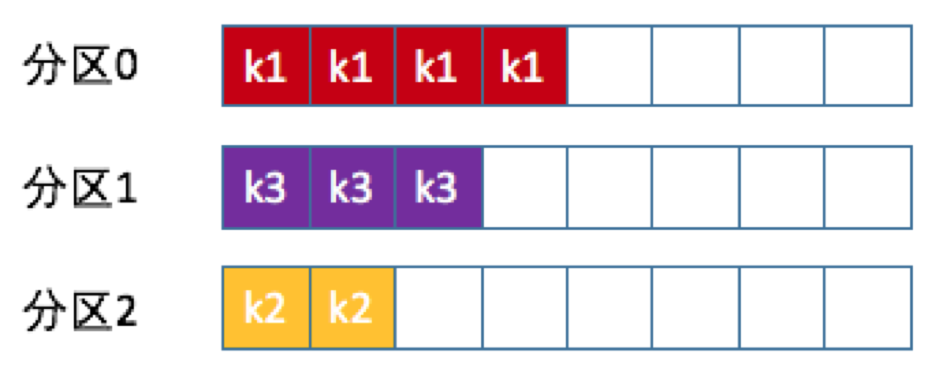
- Kafka允许为每条消息定义消息键,简称为Key
- Key可以是一个有明确业务含义的字符串:客户代码、部门编号、业务ID、用来表征消息的元数据等
- 一旦消息被定义了Key,可以保证同一个Key的所有消息都进入到相同的分区里
- 由于每个分区下的消息处理都是顺序的,所以这个策略被称为按消息键保序策略
- Kafka Java生产者的默认分区策略
- 如果指定了Key,采用按消息键保序策略
- 如果没有指定Key,采用轮询策略
1 |
|
基于地理位置的分区策略
1 |
|
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-09-08
Kafka -- 多线程消费者
Kafka Java Consumer设计原理 Kafka Java Consumer从Kafka 0.10.1.0开始,KafkaConsumer变成了双线程设计,即用户主线程和心跳线程 用户主线程:启动Consumer应用程序main方法的那个线程 心跳线程:只负责定期给对应的Broker机器发送心跳请求,以标识消费者应用的存活性 引入心跳线程的另一个目的 将心跳频率和主线程调用KafkaConsumer.poll方法的频率分开,解耦真实的消息处理逻辑和消费组成员存活性管理 虽然有了心跳线程,但实际的消息获取逻辑依然是在用户主线程中完成 因此在消费消息的这个层面,依然可以安全地认为KafkaConsumer是单线程的设计 老版本Consumer是多线程的架构 每个Consumer实例在内部为所有订阅的主题分区创建对应的消息获取线程,即Fetcher线程 老版本Consumer同时也是阻塞式的,Consumer实例启动后,内部会创建很多阻塞式的消息获取迭代器 但在很多场景下,Consumer端有非阻塞需求,如在流处理应用中执行过滤、分组等操作就不能是阻塞式的 基于这个原因,社区为新版本...

2018-10-18
Kafka -- 消费者
基本概念消费者 + 消费者群组 消费者从属于消费者群组 一个消费者群组里的消费者订阅的是同一个主题,每个消费者接收主题的部分分区的消息 消费者横向扩展1个消费者 主题T1有4个分区,然后创建消费者C1,C1是消费者群组G1里唯一的消费者,C1订阅T1 消费者C1将接收主题T1的全部4个分区的消息 2个消费者 如果群组G1新增一个消费者C2,那么每个消费者将分别从两个分区接收消息 假设C1接收分区0和分区2的消息,C2接收分区1和分区3的消息 4个消费者 如果群组G1有4个消费者,那么每个消费者可以分配到一个分区 5个消费者 如果群组G1有5个消费者,_**消费者数量超过主题的分区数量**_,那么有1个消费者就会被**闲置**,不会接收到任何消息 总结 往群组里增加消费者是横向伸缩消费能力的主要方式 消费者经常会做一些高延迟的操作,比如把数据写到数据库或HDFS,或者使用数据进行比较耗时的计算 有必要为主题创建大量的分区,在负载增长时可以加入更多的消费者,减少消息堆积 不要让消费者的数量超过主题分区的数量,多余的消费者只会被闲置 消费者群组横向扩展 Kafka设计的主要目标...

2019-09-10
Kafka -- Java消费者管理TCP连接
创建TCP连接 消费者端的主要程序入口是KafkaConsumer,但构建KafkaConsumer实例不会创建任何TCP连接 构建KafkaProducer实例时,会在后台默默地启动一个Sender线程,Sender线程负责Socket连接的创建 在Java构造函数中启动线程,会造成this指针逃逸,是一个隐患 消费者的TCP连接是在调用**KafkaConsumer.poll**方法时被创建的,poll方法内部有3个时机可以创建TCP连接 发起FindCoordinator请求时 消费者组有个组件叫作协调者(Coordinator) 驻留在Broker端的内存中,负责消费者组的组成员管理和各个消费者的位移提交管理 当消费者程序首次启动调用poll方法时,需要向Kafka集群(集群中的任意Broker)发送FindCoordinator请求 社区优化:消费者程序会向集群中当前负载最小的那台Broker发送请求 单向负载评估(非最优解):消费者连接的所有Broker中,谁的待发送请求最少,谁的负载就越小 连接Coordinator时 Broker处理完FindCoordinator请...

2019-09-12
Kafka -- 监控消费进度
Consumer Lag Consumer Lag(滞后程度):消费者当前落后于生产者的程度 Lag的单位是消息数,一般是在主题的级别上讨论Lag,但Kafka是在分区的级别上监控Lag,因此需要手动汇总 对于消费者而言,Lag是最重要的监控指标,直接反应了一个消费者的运行情况 一个正常工作的消费者,它的Lag值应该很小,甚至接近于0,滞后程度很小 如果Lag很大,表明消费者无法跟上生产者的速度,Lag会越来越大 极有可能导致消费者消费的数据已经不在操作系统的页缓存中了,这些数据会失去享有Zero Copy技术的资格 这样消费者不得不从磁盘读取这些数据,这将进一步拉大与生产者的差距 马太效应:_Lag原本就很大的消费者会越来越慢,Lag也会也来越大_ 监控LagKafka自带命令 kafka-consumer-groups是Kafka提供的最直接的监控消费者消费进度的工具 也能监控独立消费者的Lag,独立消费者是没有使用消费者组机制的消费者程序,也要配置group.id 消费者组要调用KafkaConsumer.subscribe,独立消费者要调用KafkaConsumer.assign直...
2019-09-26
Kafka -- 重设消费者组位移
背景 Kafka和传统的消息引擎在设计上有很大的区别,Kafka消费者读取消息是可以重演的 像RabbitMQ和ActiveMQ等传统消息中间件,处理和响应消息的方式是破坏性 一旦消息被成功处理,就会从Broker上被删除 Kafka是基于日志结构(Log-based)的消息引擎 消费者在消费消息时,仅仅是从磁盘文件中读取数据而已,是只读操作,因为消费者不会删除消息数据 同时,由于位移数据是由消费者控制的,因此能够很容易地修改位移值,实现重复消费历史数据的功能 Kafka Or 传统消息中间件 传统消息中间件:消息处理逻辑非常复杂,处理代价高、又不关心消息之间的顺序 Kafka:需要较高的吞吐量、但每条消息的处理时间很短,又关心消息的顺序 重设位移策略 位移维度 直接把消费者的位移值重设成给定的位移值 时间维度 给定一个时间,让消费者把位移调整成大于该时间的最小位移 维度 策略 含义 位移维度 Earliest 把位移调整到当前最早位移处 Latest 把位移调整到当前最新位移处 Current 把位移调整到当前最新提交位移处 Specified...

2019-08-26
Kafka -- 位移主题
ZooKeeper 老版本Consumer的位移管理依托于Apache ZooKeeper,自动或手动地将位移数据提交到ZK中保存 当Consumer重启后,能自动从ZK中读取位移数据,从而在上次消费截止的地方继续消费 这种设计使得Kafka Broker不需要保存位移数据,减少了Broker端需要持有的状态空间,有利于实现高伸缩性 但ZK并不适用于高频的写操作 位移主题 将Consumer的位移数据作为普通的Kafka消息,提交到__consumer_offsets(保存Consumer的位移信息) 提交过程需要实现高持久性,并需要支持高频的写操作 位移主题是普通的Kafka主题,同时也是一个内部主题,交由Kafka管理即可 位移主题的消息格式由Kafka定义,用户不能修改 因此不能随意向位移主题写消息,一旦写入的消息不能满足格式,那Kafka内部无法成功解析,会造成Broker崩溃 Kafka Consumer有API来提交位移(即向位移主题写消息) 消息格式 常用格式:Key-Value Key为消息键值,Value为消息体,在Kafka中都是字节数组 Key <Group ...




