
Java性能 -- 序列化
序列化方案
- Java RMI采用的是Java序列化
- Spring Cloud采用的是_JSON序列化_
- Dubbo虽然兼容Java序列化,但默认使用的是_Hessian序列化_
Java序列化
原理

Serializable
- JDK提供了输入流对象ObjectInputStream和输出流对象ObjectOutputStream
- 它们只能对实现了Serializable接口的类的对象进行序列化和反序列化
1 | // 只能对实现了Serializable接口的类的对象进行序列化 |
transient
- ObjectOutputStream的默认序列化方式,仅对对象的非transient的实例变量进行序列化
- 不会序列化对象的transient的实例变量,也不会序列化静态变量
1 |
|
serialVersionUID
- 在实现了Serializable接口的类的对象中,会生成一个serialVersionUID的版本号
- 在反序列化过程中用来验证序列化对象是否加载了反序列化的类
- 如果是具有相同类名的不同版本号的类,在反序列化中是无法获取对象的
1 |
|
writeObject/readObject
具体实现序列化和反序列化的是writeObject和readObject
1 |
|
writeReplace/readResolve
- writeReplace:用在序列化之前替换序列化对象
- readResolve:用在反序列化之后对返回对象进行处理
1 | // 反序列化会通过反射调用无参构造器返回一个新对象,破坏单例模式 |
1 | public class Singleton2 implements Serializable { |
缺陷
无法跨语言
Java序列化只适用于基于Java语言实现的框架
易被攻击
- Java序列化是不安全的
- Java官网:对不信任数据的反序列化,本质上来说是危险的,应该予以回避
- ObjectInputStream.readObject()
- 将类路径上几乎所有实现了Serializable接口的对象都实例化!!
- 这意味着:在反序列化字节流的过程中,该方法可以执行任意类型的代码,非常危险
- 对于需要长时间进行反序列化的对象,不需要执行任何代码,也可以发起一次攻击
- 攻击者可以创建循环对象链,然后将序列化后的对象传输到程序中进行反序列化
- 这会导致haseCode方法被调用的次数呈次方爆发式增长,从而引发栈溢出异常
- 很多序列化协议都制定了一套数据结构来保存和获取对象,如JSON序列化、ProtocolBuf
- 它们只支持一些基本类型和数组类型,可以避免反序列化创建一些不确定的实例
1 | int itCount = 27; |
序列化后的流太大
- 序列化后的二进制流大小能体现序列化的能力
- 序列化后的二进制数组越大,占用的存储空间就越多,存储硬件的成本就越高
- 如果进行网络传输,则占用的带宽就越多,影响到系统的吞吐量
- Java序列化使用ObjectOutputStream来实现对象转二进制编码,可以对比BIO中的ByteBuffer实现的二进制编码
1 |
|
序列化速度慢
- 序列化速度是体现序列化性能的重要指标
- 如果序列化的速度慢,就会影响网络通信的效率,从而增加系统的响应时间
1 | int count = 10_0000; |
ProtoBuf
- ProtoBuf是由Google推出且支持多语言的序列化框架
- 在序列化框架性能测试报告中,ProtoBuf无论编解码耗时,还是二进制流压缩大小,都表现很好
- ProtoBuf以一个**.proto**后缀的文件为基础,该文件描述了字段以及字段类型,通过工具可以生成不同语言的数据结构文件
- 在序列化该数据对象的时候,ProtoBuf通过.proto文件描述来生成Protocol Buffers格式的编码
存储格式
- Protocol Buffers是一种轻便高效的结构化数据存储格式
- Protocol Buffers使用T-L-V(标识-长度-字段值)的数据格式来存储数据
- T代表字段的正数序列(tag)
- Protocol Buffers将对象中的字段与正数序列对应起来,对应关系的信息是由生成的代码来保证的
- 在序列化的时候用整数值来代替字段名称,传输流量就可以大幅缩减
- L代表Value的字节长度,一般也只占用一个字节
- V代表字段值经过编码后的值
- T代表字段的正数序列(tag)
- 这种格式不需要分隔符,也不需要空格,同时减少了冗余字段名
编码方式
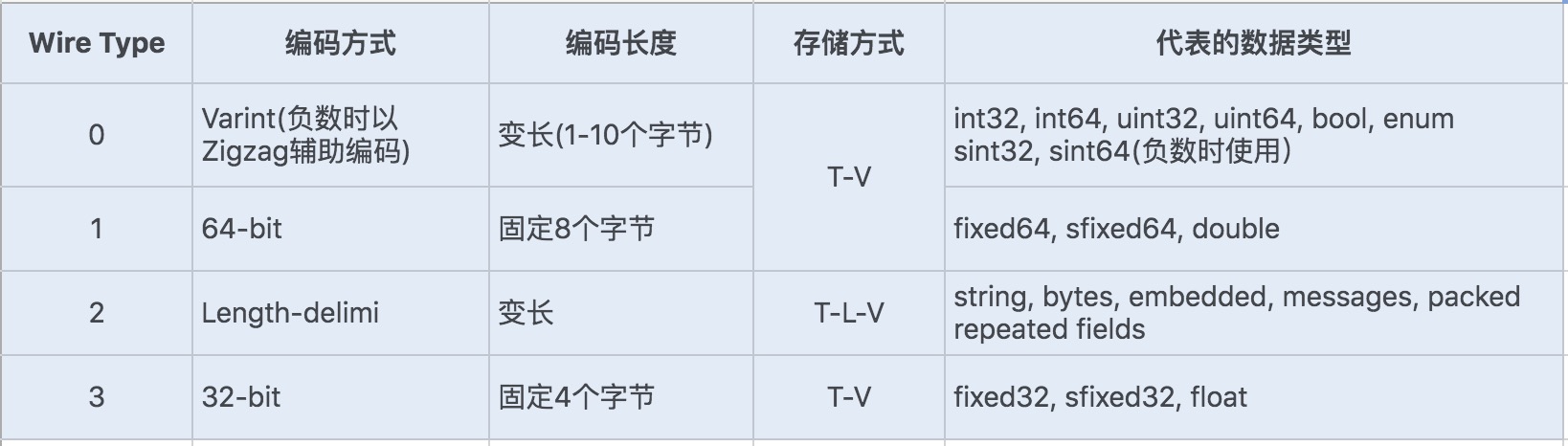
- ProtoBuf定义了一套自己的编码方式,几乎可以映射Java/Python等语言的所有基础数据类型
- 不同的编码方式可以对应不同的数据类型,还能采用不同的存储格式
- 对于Varint编码的数据,由于数据占用的存储空间是固定的,因此不需要存储字节长度length,存储方式采用T-V
- Varint编码是一种变长的编码方式,每个数据类型一个字节的最后一位是标志位(msb)
- 0表示当前字节已经是最后一个字节
- 1表示后面还有一个字节
- 对于int32类型的数字,一般需要4个字节表示,如果采用Varint编码,对于很小的int类型数字,用1个字节就能表示
- 对于大部分整数类型数据来说,一般都是小于256,所以这样能起到很好的数据压缩效果
编解码
- ProtoBuf不仅压缩存储数据的效果好,而且编解码的性能也是很好的
- ProtoBuf的编码和解码过程结合**.proto**文件格式,加上Protocol Buffers独特的编码格式
- 只需要简单的数据运算以及位移等操作就可以完成编码和解码
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-09-04
Java性能 -- 命令行工具
free12345$ free -m total used free shared buffers cachedMem: 15948 15261 687 304 37 6343-/+ buffers/cache: 8880 7068Swap: 0 0 0 Mem是从操作系统的角度来看的 总共有15948M物理内存,其中15261M被使用了,还有687可用,15948 = 15261 + 687 有若干线程共享了304M物理内存,已经被弃用(值总为0) buffer / cached :为了提高IO性能,由OS管理 A buffer is something that has yet to be “written” to disk. A cache is something that has been “read” from the disk and sto...

2019-09-17
Java性能 -- 单例模式
饿汉模式class1234567891011// 饿汉模式public final class Singleton { private static Singleton instance = new Singleton(); private Singleton() { } public static Singleton getInstance() { return instance; }} 使用了static修饰了成员变量instance,所以该变量会在类初始化的过程中被收集进_类构造器<clinit>_ 在多线程场景下,JVM会保证只有一个线程能够执行该类的<clinit>方法,其它线程将会被阻塞等待 等到唯一的一次<clinit>方法执行完成后,其它线程将不会再执行<clinit>方法,转而执行自己的代码 因此,static修饰的成员变量instance,在多线程的情况下能保证只实例化一次 在类初始化阶段就已经在堆内存中开辟了一块内存,用...

2019-09-22
Java性能 -- 生产者消费者模式 + 装饰器模式
生产者消费者模式实现方式Object的wait/notify/notifyAll 基于Object的wait/notify/notifyAll与对象监视器(Monitor)实现线程间的等待和通知 这种方式实现的生产者消费者模式是基于内核实现的,可能会导致大量的上下文切换,性能不是最理想的 Lock中Condition的await/signal/signalAll 相对于Object的wait/notify/notifyAll,更推荐JUC包提供的Lock && Condition实现的生产者消费者模式 Lock && Condition实现的生产者消费者模式,是基于Java代码层实现的,在性能和扩展性方面更有优势 BlockingQueue 简单明了 限流算法漏桶算法通过限制容量池大小来控制流量,而令牌桶算法则通过限制发放令牌的速率来控制流量 漏桶算法 请求如果要进入业务层,就必须经过漏桶,而漏桶出口的请求速率是均衡的 如果漏桶已经满了,请求将会溢出,不会因为入口的请求量突然增加而导...

2019-08-18
Java性能 -- Lock优化
Lock / synchronizedLock锁的基本操作是通过乐观锁实现的,由于Lock锁也会在阻塞时被挂起,依然属于悲观锁 synchronized Lock 实现方式 JVM层实现 Java底层代码实现 锁的获取 JVM隐式获取 lock() / tryLock() / tryLock(timeout, unit) / lockInterruptibly() 锁的释放 JVM隐式释放 unlock() 锁的类型 非公平锁、可重入 非公平锁/公平锁、可重入 锁的状态 不可中断 可中断 锁的性能 高并发下会升级为重量级锁 更稳定 实现原理 Lock锁是基于Java实现的锁,Lock是一个接口 常见的实现类:ReentrantLock、ReentrantReadWriteLock,都是依赖AbstractQueuedSynchronizer(AQS)实现 AQS中包含了一个基于链表实现的等待队列(即CLH队列),用于存储所有阻塞的线程 AQS中有一个state变量,该变量对ReentrantLock来说表示加...

2019-08-25
Java性能 -- 线程上下文切换
线程数量 在并发程序中,并不是启动更多的线程就能让程序最大限度地并发执行 线程数量设置太小,会导致程序不能充分地利用系统资源 线程数量设置太大,可能带来资源的过度竞争,导致上下文切换,带来的额外的系统开销 上下文切换 在单处理器时期,操作系统就能处理多线程并发任务,处理器给每个线程分配CPU时间片,线程在CPU时间片内执行任务 CPU时间片是CPU分配给每个线程执行的时间段,一般为几十毫秒 时间片决定了一个线程可以连续占用处理器运行的时长 当一个线程的时间片用完,或者因自身原因被迫暂停运行,此时另一个线程会被操作系统选中来占用处理器 上下文切换(Context Switch):一个线程被暂停剥夺使用权,另一个线程被选中开始或者继续运行的过程 切出:一个线程被剥夺处理器的使用权而被暂停运行 切入:一个线程被选中占用处理器开始运行或者继续运行 切出切入的过程中,操作系统需要保存和恢复相应的进度信息,这个进度信息就是_上下文_ 上下文的内容 寄存器的存储内容:CPU寄存器负责存储已经、正在和将要执行的任务 程序计数器存储的指令内容:程序计数器负责存储CPU正在执行的指令位置、即将执行的下一条...
2019-09-24
Java性能 -- 高性能SQL
慢SQL诱因 无索引、索引失效 锁等待 InnoDB支持行锁,MyISAM支持表锁 InnoDB支持行锁更适合高并发场景,但行锁有可能会升级为表锁 一种情况是在批量更新时 行锁是基于索引加的锁,如果在更新操作时,条件索引失效,那么行锁会升级为表锁 基于表锁的数据库操作,会导致SQL阻塞等待,影响执行速度 在写大于读的情况下,不建议使用MyISAM 行锁相对于表锁,虽然粒度更细,并发能力提升,但也带来了新的问题,那就是死锁 不恰当的SQL SELECT * SELECT COUNT(*) 大表中使用LIMIT M,N 对非索引字段进行排序 SQL诊断EXPLAIN id:每个执行计划都有一个id,如果是一个联合查询,会有多个id select_type SIMPLE:普通查询,即没有联合查询、子查询 PRIMARY:主查询 UNION:UNION中后面的查询 SUBQUERY:子查询 table:当前执行计划查询的表,如果表有别名,则显示别名 partitions:分区表信息 type 从表中查询到行所执行的方式 由好到坏:_**system > const > eq...




