
Kafka -- 压缩
压缩的目的
时间换空间,用CPU时间去换磁盘空间或网络IO传输量
消息层次
- 消息集合(Message Set)和消息
- 一个消息集合中包含若干条日志项(Record Item),而日志项用于封装消息
- Kafka底层的消息日志由一系列消息集合日志项组成
- Kafka不会直接操作具体的消息,而是在消息集合这个层面上进行写入操作
消息格式
- 目前Kafka共有两大类消息格式,社区分别称之为V1版本和V2版本(在0.11.0.0引入)
- V2版本主要针对V1版本的一些弊端进行了优化
- 优化1:把消息的公共部分抽取到外层消息集合里面
- 在V1版本中,每条消息都需要执行CRC校验,但在某些情况下,消息的CRC值会发生变化
- Broker端可能对消息的时间戳字段进行更新,重新计算后的CRC值也会相应更新
- Broker端在执行消息格式转换时(兼容老版本客户端),也会带来CRC值的变化
- 因此没必要对每条消息都执行CRC校验,浪费空间和时间
- 在V2版本中,消息的CRC校验被移到了消息集合这一层
- 在V1版本中,每条消息都需要执行CRC校验,但在某些情况下,消息的CRC值会发生变化
- 优化2:对整个消息集合进行压缩
- 在V1版本中,对多条消息进行压缩,然后保存到外层消息的消息体字段中
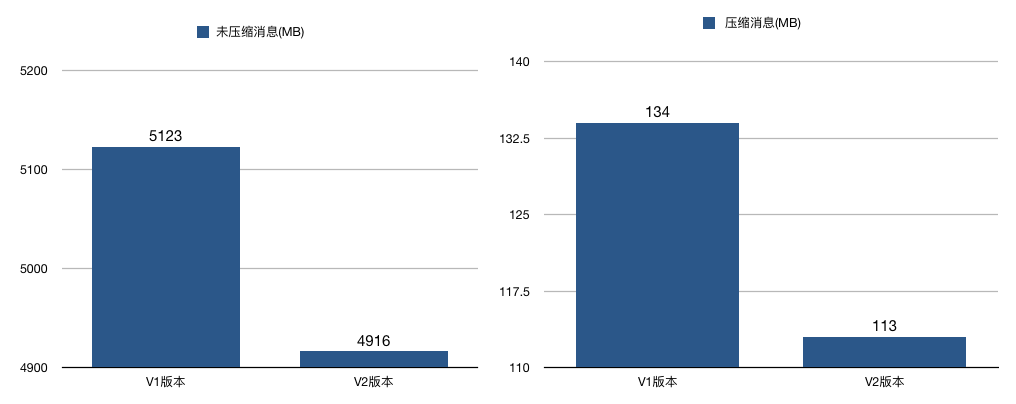
压缩的时机
在Kafka中,压缩可能发生在两个地方:生产者、Broker
生产者
1 | Properties props = new Properties(); |
Broker
大部分情况下,Broker从Producer接收到消息后,仅仅只是原封不动地保存,而不会对其进行任何修改,但存在例外情况
不同的压缩算法
- Producer采用GZIP压缩算法,Broker采用Snappy压缩算法
- Broker接收到GZIP压缩消息后,只能解压后使用Snappy压缩算法重新压缩一遍
- Broker端也有
compression.type参数,默认值是producer,表示Broker端会尊重Producer端使用的压缩算法- 一旦Broker端设置了不同的
compression.type,可能会发生预料之外的压缩/解压缩操作,导致CPU使用率飙升
- 一旦Broker端设置了不同的
消息格式转换
- 消息格式转换主要是为了兼容老版本的消费者程序,在一个Kafka集群中通常同时保存多种版本的消息格式(V1/V2)
- Broker端会对新版本消息执行向老版本格式的转换,该过程中会涉及消息的解压缩和重新压缩
- 消息格式转换对性能的影响很大,除了增加额外的压缩和解压缩操作之外,还会让Kafka丧失引以为傲的Zero Copy特性
- Zero Copy:数据在磁盘和网络进行传输时,避免昂贵的内核态数据拷贝,从而实现快速的数据传输
- 因此,尽量保证消息格式的统一
解压缩的时机
Consumer
- 通常来说解压缩发生在消费者
- Producer压缩,Broker保持、Consumer解压缩
- Kafka会将启用的压缩算法封装进消息集合中,当Consumer读取到消息集合时,会知道这些消息使用了哪一种压缩算法
Broker
- 与消息格式转换时发生的解压缩是不同的场景(主要为了兼容老版本的消费者)
- 每个压缩过的消息集合在Broker端写入时都要发生解压缩操作,目的是为了对消息执行各种验证(主要影响CPU使用率)
压缩算法对比
- Kafka 2.1.0之前,Kafka支持三种压缩算法:GZIP、Snappy、LZ4,从2.1.0开始正式支持zstd算法
- zstd是Facebook开源的压缩算法,能够提供超高的压缩比
- 评估一个压缩算法的优劣,主要有两个指标:压缩比、压缩/解压缩吞吐量
- 从下面的Benchmarks可以看出
- zstd具有最高的压缩比,LZ4具有最高的吞吐量
- 在Kafka的实际使用中
- 吞吐量:_LZ4_ > Snappy > zstd > GZIP
- 压缩比:_zstd_ > LZ4 > GZIP > Snappy
- 物理资源
- 带宽:由于Snappy的压缩比最低,因此占用的网络带宽最大
- CPU:各个压缩算法差不多,在压缩时Snappy使用更多的CPU,在解压缩时GZIP使用更多的CPU
- 带宽资源比CPU资源和磁盘资源更吃紧(千兆网络是标配),_首先排除Snappy,其次排除GZIP,剩下在LZ4和zstd中选择_
- 如果客户端的CPU资源充足,强烈建议开启zstd压缩,可以极大地节省网络带宽
| Compressor name | Ratio | Compression | Decompress |
|---|---|---|---|
| zstd 1.4.0 -1 | 2.884 | 530 MB/s | 1360 MB/s |
| zlib 1.2.11 -1 | 2.743 | 110 MB/s | 440 MB/s |
| brotli 1.0.7 -0 | 2.701 | 430 MB/s | 470 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 600 MB/s | 800 MB/s |
| lzo1x 2.09 -1 | 2.106 | 680 MB/s | 950 MB/s |
| lz4 1.8.3 | 2.101 | 800 MB/s | 4220 MB/s |
| snappy 1.1.4 | 2.073 | 580 MB/s | 2020 MB/s |
| lzf 3.6 -1 | 2.077 | 440 MB/s | 930 MB/s |
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-09-18
Kafka -- 控制器
控制器 控制器(Controller)是Kafka的核心组件,主要作用是在ZK的帮助下管理和协调整个Kafka集群 集群中任一Broker都能充当控制器的角色,但在运行过程中,只能有一个Broker成为控制器,行使管理和协调的职责 12345678910111213[zk: localhost:2181(CONNECTED) 1] get /controller{"version":1,"brokerid":0,"timestamp":"1571311742367"}cZxid = 0xd68ctime = Thu Oct 17 19:29:02 CST 2019mZxid = 0xd68mtime = Thu Oct 17 19:29:02 CST 2019pZxid = 0xd68cversion = 0dataVersion = 0aclVersion = 0ephemeralOwner = 0x1000209974b0000dataLength = 54numChildren = 0 Zo...

2019-09-06
Kafka -- CommitFailedException
CommitFailedException CommitFailedException是Consumer客户端在提交位移时出现的不可恢复的严重异常 如果异常是可恢复的瞬时错误,提交位移的API方法是支持自动错误重试的,如commitSync方法 解释 Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the max.poll.interval.m...

2019-07-24
Kafka -- 生产者消息分区机制
分区概念 主题是承载真实数据的逻辑容器,主题之下分为若干个分区,Kafka的消息组织方式为三级结构:主题、分区、消息 主题下的每条消息只会保存在某个分区中,而不会在多个分区中被保存多份 分区的作用是提供负载均衡的能力,实现系统的高伸缩性 不同的分区能够被放置在不同的机器节点上,而数据读写操作的粒度也是分区 每个机器节点都能独立地执行各自分区的读写请求处理,还可以通过添加新的机器节点来增加整体系统的吞吐量 分区在不同的分布式系统有不同的叫法,但分区的思想都是类似的 Kafka – Partition MongoDB、Elasticsearch – Shard HBase – Region 分区策略 分区策略:决定生产者将消息发送到哪个分区的算法,Kafka提供了默认的分区策略,也支持自定义的分区策略 自定义的分区策略,需要显式地配置生产者端的参数partitioner.class 实现接口:org.apache.kafka.clients.producer.Partitioner 消息数据:topic、key、keyBytes、value、valueBytes 集群数据:cluster ...

2019-09-15
Kafka -- 处理请求
请求协议 Kafka自定义了一组请求协议,用于实现各种各样的交互操作 PRODUCE请求用于生产消息,FETCH请求用于消费消息,METADATA请求用于请求Kafka集群元数据信息 Kafka 2.3总共定义了45种请求格式,所有请求都通过TCP网络以Socket的方式进行通讯 处理请求方案顺序处理实现简单,但吞吐量太差,只适用于请求发送非常不频繁的场景 1234while (true) { Request request = accept(connection); handle(request);} 单独线程处理为每个请求都创建一个新的线程异步处理,完全异步,但开销极大,只适用于请求发送频率很低的场景 12345while (true) { Request request = accept(connection); Thread thread = new Thread(() -> { handle(request); }); thread.start();} Reactor模式 Reac...
2019-08-09
Kafka -- 无消息丢失
持久化保证 Kafka只对已提交的消息做有限度的持久化保证 已提交的消息 当Kafka的若干个Broker成功地接收到一条消息并写入到日志文件后,会告诉生产者这条消息已经成功提交 有限度的持久化保证 Kafka不保证在任何情况下都能做到不丢失消息,例如机房着火等极端情况 消息丢失生产者丢失 目前Kafka Producer是异步发送消息的,Producer.send(record)立即返回,但不能认为消息已经发送成功 丢失场景:网络抖动,导致消息没有到达Broker;消息太大,超过Broker的承受能力,Broker拒收 解决方案:Producer永远要使用带有回调通知的发送API,即**Producer.send(record, callback)** callback能够准确地告知Producer消息是不是真的提交成功,一旦出现消息提交失败,可以进行针对性的处理 消费者丢失 Consumer端丢失数据主要体现在Consumer端要消费的消息不见了 Consumer程序有位移的概念,表示该Consumer当前消费到Topic分区的位置 丢失原因:Consumer接收一批消息后,在未...

2019-03-31
Kafka -- 可靠性
可靠性保证 可靠性保证:确保系统在各种不同的环境下能够发生一致的行为 Kafka的保证 保证_分区消息的顺序_ 如果使用同一个生产者往同一个分区写入消息,而且消息B在消息A之后写入 那么Kafka可以保证消息B的偏移量比消息A的偏移量大,而且消费者会先读取消息A再读取消息B 只有当消息被写入分区的所有同步副本时(文件系统缓存),它才被认为是已提交 生产者可以选择接收不同类型的确认,控制参数acks 只要还有一个副本是活跃的,那么已提交的消息就不会丢失 消费者只能读取已经提交的消息 复制 Kafka可靠性保证的核心:_复制机制_ + 分区的多副本架构 把消息写入多个副本,可以使Kafka在发生崩溃时仍能保证消息的持久性 Kafka的主题被分成多个分区,分区是基本的数据块,分区存储在单个磁盘上 Kafka可以保证分区里的事件总是有序的,分区可以在线(可用),也可以离线(不可用) 每个分区可以有多个副本,其中一个副本是首领副本 所有的事件都直接发送给首领副本,或者直接从首领副本读取事件 其他副本只需要与首领副本保持同步,并及时复制最新的事件即可 当首领副本不可用时,其中一个同步副本将成为新的...




