
Java性能 -- 协程
线程实现模型
- 轻量级进程和内核线程一对一相互映射实现的1:1线程模型
- 用户线程和内核线程实现的N:1线程模型
- 用户线程和轻量级进程混合实现的N:M线程模型
1:1线程模型
- 内核线程(Kernel-Level Thread)是由操作系统内核支持的线程,内核通过调度器对线程进行调度,负责完成线程的切换
- 在Linux中,往往通过fork函数创建一个子进程来代表一个内核中的线程
- 一个进程调用fork函数后,系统会先给新的子进程分配资源,然后复制主进程,只有少数值与主进程不一样
- 采用fork的方式,会产生大量的冗余数据,占用大量内存空间,也会消耗大量CPU时间来初始化内存空间和复制数据
- 如果是一模一样的数据,可以共享主进程的数据,于是轻量级进程(Light Weight Process,LWP)出现了
- LWP使用clone系统调用创建线程
- clone函数将部分父进程的资源的数据结构进行复制,复制内容可选,且没有被复制的资源可以通过指针共享给子进程
- LWP运行单元更小,运行速度更快,LWP和内核线程一一映射,每个LWP都是由一个内核线程支持
N:1线程模型
- 1:1线程模型的缺陷
- 在线程创建、切换上都存在用户态和内核态的切换
- 系统资源有限,无法支持创建大量LWP
- 该线程模型在用户空间完成了线程的创建、同步、销毁和调度,并不需要内核的帮助,不会产生用户态和内核态的空间切换
N:M线程模型
- N:1线程模型的缺陷
- 操作系统无法感知用户态的线程,容易造成某个线程进行系统调用内核线程时被阻塞,从而导致整个进程被阻塞
- N:M线程模型是一种混合线程管理模型
- 支持用户态线程通过LWP与内核线程连接,用户态的线程数量和内核态的LWP数量是N:M的映射关系
Java线程 / Go协程
- Java线程
- Thead#start通过调用native方法start0实现
- 在Linux下,JVM Thread是基于pthread_create实现的,而pthread_create实际上调用了clone系统调用来创建线程
- 所以,Java在Linux下采用的是1:1线程模型(用户线程与轻量级线程一一映射),线程通过内核调度,涉及上下文切换
- Go协程
- Go语言使用了N:M线程模型实现了自己的调度器,在N个内核线程上多路复用M个协程
- 协程的上下文切换在用户态由协程调度器完成,不需要陷入到内核,相比Java线程,代价很小
协程的实现原理
- 协程可以看作一个类函数或者一块函数中的代码,可以在主线程里面轻松创建多个协程
- 程序调用协程和调用函数是不一样的,协程可以通过暂停或者阻塞的方式将协程的执行挂起,而其他协程可以继续执行
- 协程的挂起只是在程序中(用户态)的挂起,同时将代码执行权转让给其他协程使用
- 待获取执行权的协程执行完之后,将从挂起点唤醒挂起的协程
- 协程的挂起和唤醒是通过一个调度器完成的
图例解释
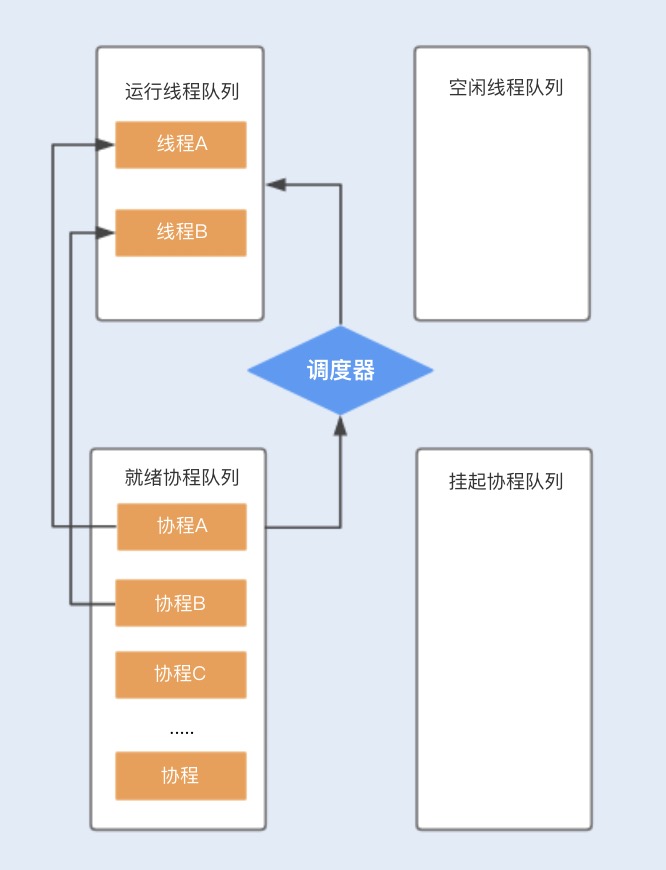
- 假设程序中默认创建两个线程为协程使用,在主线程中创建协程ABCD…,分别存储在就绪队列中
- 调度器首先会分配工作线程A执行协程A,工作线程B执行协程B,其他创建的协程将会在等待队列中进行排队等待
- 当协程A调用暂停方法或被阻塞时,协程A会进入到挂起队列,调度器会调用等待队列中的其他协程抢占线程A执行
- 当协程A被唤醒时,它需要重新进入到就绪队列中,通过调度器抢占线程
- 如果抢占成功,就继续执行协程A;如果抢占失败,就继续等待抢占线程
线程 / 协程
- 相比于线程,协程少了由于同步资源竞争带来的_CPU上下文切换_
- 应用场景:_IO阻塞型场景_
- 比较适合IO密集型的应用,特别在网络请求中,有较多的时间在等待服务端响应
- 协程可以保证线程不会阻塞在等待网络响应(可以在协程层面阻塞)中,充分利用了多核多线程的能力
- 对于CPU密集型的应用,由于多数情况下CPU都比较繁忙,协程的优势就不会特别明显
- 比较适合IO密集型的应用,特别在网络请求中,有较多的时间在等待服务端响应
- 线程是通过共享内存的方式来实现数据共享,而协程是使用了通信(MailBox)的方式来实现数据共享
- 这主要为了避免内存共享数据而带来的线程安全问题
小结
- 协程可以认为是运行在线程上的代码块,协程提供的挂起操作会使协程暂停执行,而不会导致线程阻塞
- 协程是一种轻量级资源,即使创建上千个协程,对系统来说也不会是很大的负担,而线程则不然
- 协程的设计方式极大地提高了线程的使用率
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-08-31
Java性能 -- 线程池大小
线程池原理 在Hotspot JVM的线程模型中,Java线程被一对一映射为内核线程 Java使用线程执行程序时,需要创建一个内核线程,当该Java线程被终止时,这个内核线程也会被回收 Java线程的创建和销毁将会消耗一定的计算机资源,从而增加系统的性能开销 大量创建线程也会给系统带来性能问题,线程会抢占内存和CPU资源,可能会发生内存溢出、CPU超负载等问题 线程池:即可以提高线程复用,也可以固定最大线程数,防止无限制地创建线程 当程序提交一个任务需要一个线程时,会去线程池查找是否有空闲的线程 如果有,则直接使用线程池中的线程工作,如果没有,则判断当前已创建的线程数是否超过最大线程数 如果未超过,则创建新线程,如果已经超过,则进行排队等待或者直接抛出异常 线程池框架Executor Java最开始提供了ThreadPool来实现线程池,为了更好地实现用户级的线程调度,Java提供了一套Executor框架 Executor框架包括了ScheduledThreadPoolExecutor和ThreadPoolExecutor两个核心线程池,核心原理一样 ScheduledThreadPoo...

2019-08-15
Java性能 -- synchronized锁升级优化
synchronized / Lock JDK 1.5之前,Java通过synchronized关键字来实现锁功能 synchronized是JVM实现的内置锁,锁的获取和释放都是由JVM隐式实现的 JDK 1.5,并发包中新增了Lock接口来实现锁功能 提供了与synchronized类似的同步功能,但需要显式获取和释放锁 Lock同步锁是基于Java实现的,而synchronized是基于底层操作系统的Mutex Lock实现的 每次获取和释放锁都会带来用户态和内核态的切换,从而增加系统的性能开销 在锁竞争激烈的情况下,synchronized同步锁的性能很糟糕 在JDK 1.5,在单线程重复申请锁的情况下,synchronized锁性能要比Lock的性能差很多 JDK 1.6,Java对synchronized同步锁做了充分的优化,甚至在某些场景下,它的性能已经超越了Lock同步锁 实现原理12345678910public class SyncTest { public synchronized void method1() { ...
2019-09-09
Java性能 -- JIT
编译 前端编译:即常见的**.java文件被编译成.class文件**的过程 运行时编译:机器无法直接运行Java生成的字节码,在运行时,JIT或者解释器会将字节码转换为机器码 类文件在运行时被进一步编译,可以变成高度优化的机器代码 C/C++编译器的所有优化都是在编译期完成的,运行期的性能监控仅作为基础的优化措施是无法进行的 JIT编译器是JVM中运行时编译最重要的部分之一 编译 / 加载 / 执行 类编译 javac:将.java文件编译成.class文件 javap:反编译.class文件,重点关注常量池和方法表集合 常量池主要记录的是类文件中出现的字面量和符号引用 字面量:字符串常量、基本类型的常量 符号引用:类和接口的全限定名、类引用、方法引用、成员变量引用 方法表集合 方法的字节码、方法访问权限、方法名索引、描述符索引、JVM执行指令、属性集合等 类加载 当一个类被创建实例或者被其他对象引用时,JVM如果没有加载过该类,会通过类加载器将**.class文件加载到内存**中 不同的实现类由不同的类加载器加载 JDK中的本地方法类一般由...

2019-06-05
Java性能 -- 性能调优策略
性能测试测试方法 微基准性能测试 可以精准定位到某个模块或者某个方法的性能问题,例如对比一个方法使用同步实现和非同步实现的性能差异 宏基准性能测试 宏基准性能测试是一个综合测试,需要考虑到测试环境、测试场景和测试目标 测试环境:模拟线上的真实环境 测试场景:在测试某个接口时,是否有其他业务的接口也在平行运行,进而造成干扰 测试目标 可以通过吞吐量和响应时间来衡量系统是否达标,如果不达标,就需要进行优化 如果达标,就继续加大测试的并发数,探底接口的TPS 除了关注接口的吞吐量和响应时间外,还需要关注CPU、内存和IO的使用率情况 干扰因素热身问题 在Java编程语言和环境中,.java文件编译成.class文件后,需要通过解析器将字节码转换成本地机器码才能运行 为了节约内存和执行效率,代码在最初被执行时,解析器会率先解析执行这段代码 随着代码被执行的次数增加,当JVM发现某个方法或代码块运行得很频繁时,就会把这些代码认定为热点代码 为了提高热点代码的执行效率,在运行时,JVM将通过即时编译器(JIT)把这些代码编译成与本地平台相关的机器码 并进行各层次的优化,然后存储在内存中,之后每次运...

2019-09-13
Java性能 -- JVM堆内存分配
JVM内存分配性能问题 JVM内存分配不合理最直接的表现就是频繁的GC,这会导致上下文切换,从而降低系统的吞吐量,增加系统的响应时间 对象在堆中的生命周期 在JVM内存模型的堆中,堆被划分为新生代和老年代 新生代又被进一步划分为Eden区和Survivor区,Survivor区由From Survivor和To Survivor组成 当创建一个对象时,对象会被优先分配到新生代的Eden区 此时JVM会给对象定义一个对象年轻计数器(-XX:MaxTenuringThreshold) 当Eden空间不足时,JVM将执行新生代的垃圾回收(Minor GC) JVM会把存活的对象转移到Survivor中,并且对象年龄+1 对象在Survivor中同样也会经历Minor GC,每经历一次Minor GC,对象年龄都会+1 如果分配的对象超过了-XX:PetenureSizeThreshold,对象会直接被分配到老年代 查看JVM堆内存分配 在默认不配置JVM堆内存大小的情况下,JVM根据默认值来配置当前内存大小 在JDK 1.7中,默认情况下新生代和老年代的比例是1:2,可以通过–XX:New...
2019-06-23
Java性能 -- 正则表达式
元字符 正则表达式使用一些特定的元字符来检索、匹配和替换符合规则的字符串 元字符:普通字符、标准字符、限定字符(量词)、定位字符(边界字符) 正则表达式引擎 正则表达式是一个用正则符号写出来的公式 程序对正则表达式进行语法分析,建立语法分析树 再根据语法分析树结合正则表达式引擎生成执行程序(状态机),用于字符匹配 正则表达式引擎是一套核心算法,用于建立状态机 小结 正则表达式 => 语法分析树 语法分析树 + 正则表达引擎 => 状态机 => 用于字符匹配 目前实现正则表达式引擎的方式有两种 DFA自动机(Deterministic Finite Automaton,确定有限状态自动机) NFA自动机(Nondeterministic Finite Automaton,非确定有限状态自动机) DFA自动机的构造代价远大于NFA自动机,但DFA自动机的执行效率高于NFA自动机 假设一个字符串的长度为n,如果采用DFA自动机作为正则表达式引擎,则匹配的时间复杂度为O(n) 如果采用NFA自动机作为正则表达式引擎,NFA自动机在匹配过程...




