
Kafka -- 多线程消费者
Kafka Java Consumer设计原理
- Kafka Java Consumer从Kafka 0.10.1.0开始,KafkaConsumer变成了双线程设计,即用户主线程和心跳线程
- 用户主线程:启动Consumer应用程序main方法的那个线程
- 心跳线程:只负责定期给对应的Broker机器发送心跳请求,以标识消费者应用的存活性
- 引入心跳线程的另一个目的
- 将心跳频率和主线程调用KafkaConsumer.poll方法的频率分开,解耦真实的消息处理逻辑和消费组成员存活性管理
- 虽然有了心跳线程,但实际的消息获取逻辑依然是在用户主线程中完成
- 因此在消费消息的这个层面,依然可以安全地认为KafkaConsumer是单线程的设计
- 老版本Consumer是多线程的架构
- 每个Consumer实例在内部为所有订阅的主题分区创建对应的消息获取线程,即Fetcher线程
- 老版本Consumer同时也是阻塞式的,Consumer实例启动后,内部会创建很多阻塞式的消息获取迭代器
- 但在很多场景下,Consumer端有非阻塞需求,如在流处理应用中执行过滤、分组等操作就不能是阻塞式的
- 基于这个原因,社区为新版本Consumer设计了单线程+轮询的机制,该机制能较好地实现非阻塞的消息获取
- 单线程的设计简化了Consumer端的设计
- Consumer获取到消息后,处理消息的逻辑是否采用多线程,完全由使用者决定
- 不论使用哪一种编程语言,单线程的设计都比较容易实现
- 并不是所有的编程语言都能很好地支持多线程,而单线程设计的Consumer更容易移植到其他语言上
多线程方案
- KafkaConsumer是线程不安全的
- 不能多线程共享一个KafkaConsumer实例,否则会抛出ConcurrentModificationException
- 但KafkaConsumer.wakeup()是线程安全的
方案1
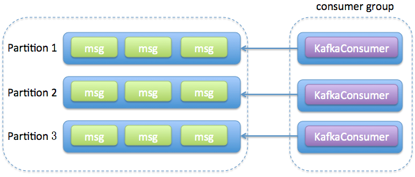
- 消费者程序启动多个线程,每个线程维护专属的KafkaConsumer实例,负责完整的消息获取、消息处理流程
- 优点
- 实现简单,比较符合目前使用Consumer API的习惯
- 多个线程之间没有任何交互,省去了很多保障线程安全方面的开销
- Kafka主题中的每个分区都能保证只被一个线程处理,容易实现分区内的消息消费顺序
- 缺点
- 每个线程都维护自己的KafkaConsumer实例,必然会占用更多的系统资源,如内存、TCP连接等
- 能使用的线程数受限于Consumer订阅主题的总分区数
- 每个线程完整地执行消息获取和消息处理逻辑
- 一旦消息处理逻辑很重,消息处理速度很慢,很容易出现不必要的Rebalance,引发整个消费者组的消费停滞
1 | public class KafkaConsumerRunner implements Runnable { |
方案2
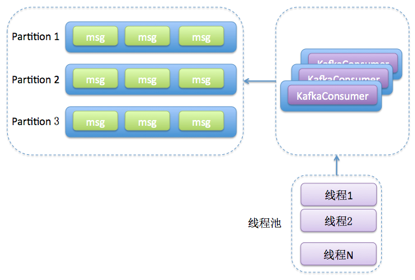
- 消费者程序使用单个或多个线程获取消息,同时创建多个消费线程执行消息处理逻辑
- 获取消息的线程可以是一个,也可以是多个,每个线程维护专属的KafkaConsumer实例
- 处理消息则由特定的线程池来做,从而实现消息获取和消息处理的真正解耦
- 优点
- 把任务切分成消息获取和消息处理两部分,分别由不同的线程来处理
- 相对于方案1,方案2最大的优势是它的高伸缩性
- 可以独立地调节消息获取的线程数,以及消息处理的线程数,不必考虑两者之间是否相互影响
- 缺点
- 实现难度大,因为要分别管理两组线程
- 消息获取和消息处理解耦,无法保证分区内的消费顺序
- 两组线程,使得整个消息消费链路被拉长,最终导致正确位移提交会变得异常困难,可能会出现消息的重复消费
1 | private final KafkaConsumer<String, String> consumer; |
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-09-27
Kafka -- 常用脚本
脚本列表12345678connect-distributed kafka-consumer-perf-test kafka-reassign-partitions kafka-verifiable-producerconnect-standalone kafka-delegation-tokens kafka-replica-verification trogdorkafka-acls kafka-delete-records kafka-run-class zookeeper-security-migrationkafka-broker-api-versions kafka-dump-log kafka-server-start zookeeper-server-startkafka-configs ...

2018-10-09
Kafka -- 集群安装与配置(Docker)
配置文件文件列表123$ tree.└── docker-compose.yml docker-compose.yml123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103version: '2'services: zk1: image: confluentinc/cp-zookeeper:latest hostname: zk1 container_name: zk1 restart: always ports: - "12181:2181" environment: ZOOKEEPER_SERVER_ID: 1 ZOOKEEPER_CLIENT_...

2019-03-31
Kafka -- 可靠性
可靠性保证 可靠性保证:确保系统在各种不同的环境下能够发生一致的行为 Kafka的保证 保证_分区消息的顺序_ 如果使用同一个生产者往同一个分区写入消息,而且消息B在消息A之后写入 那么Kafka可以保证消息B的偏移量比消息A的偏移量大,而且消费者会先读取消息A再读取消息B 只有当消息被写入分区的所有同步副本时(文件系统缓存),它才被认为是已提交 生产者可以选择接收不同类型的确认,控制参数acks 只要还有一个副本是活跃的,那么已提交的消息就不会丢失 消费者只能读取已经提交的消息 复制 Kafka可靠性保证的核心:_复制机制_ + 分区的多副本架构 把消息写入多个副本,可以使Kafka在发生崩溃时仍能保证消息的持久性 Kafka的主题被分成多个分区,分区是基本的数据块,分区存储在单个磁盘上 Kafka可以保证分区里的事件总是有序的,分区可以在线(可用),也可以离线(不可用) 每个分区可以有多个副本,其中一个副本是首领副本 所有的事件都直接发送给首领副本,或者直接从首领副本读取事件 其他副本只需要与首领副本保持同步,并及时复制最新的事件即可 当首领副本不可用时,其中一个同步副本将成为新的...

2019-09-06
Kafka -- CommitFailedException
CommitFailedException CommitFailedException是Consumer客户端在提交位移时出现的不可恢复的严重异常 如果异常是可恢复的瞬时错误,提交位移的API方法是支持自动错误重试的,如commitSync方法 解释 Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the max.poll.interval.m...

2019-09-10
Kafka -- Java消费者管理TCP连接
创建TCP连接 消费者端的主要程序入口是KafkaConsumer,但构建KafkaConsumer实例不会创建任何TCP连接 构建KafkaProducer实例时,会在后台默默地启动一个Sender线程,Sender线程负责Socket连接的创建 在Java构造函数中启动线程,会造成this指针逃逸,是一个隐患 消费者的TCP连接是在调用**KafkaConsumer.poll**方法时被创建的,poll方法内部有3个时机可以创建TCP连接 发起FindCoordinator请求时 消费者组有个组件叫作协调者(Coordinator) 驻留在Broker端的内存中,负责消费者组的组成员管理和各个消费者的位移提交管理 当消费者程序首次启动调用poll方法时,需要向Kafka集群(集群中的任意Broker)发送FindCoordinator请求 社区优化:消费者程序会向集群中当前负载最小的那台Broker发送请求 单向负载评估(非最优解):消费者连接的所有Broker中,谁的待发送请求最少,谁的负载就越小 连接Coordinator时 Broker处理完FindCoordinator请...

2019-09-29
Kafka -- 监控
主机监控 主机监控:监控Kafka集群Broker所在的节点机器的性能 常见的主机监控指标 机器负载 CPU使用率 内存使用率,包括空闲内存和已使用内存 磁盘IO使用率,包括读使用率和写使用率 网络IO使用率 TCP连接数 打开文件数 inode使用情况 JVM监控 重点指标 Full GC发生频率和时长 活跃对象大小 应用线程总数 设置堆大小 经历一次Full GC后,堆上存活的活跃对象大小为S,可以安全地将老年代堆大小设置为1.5S或者2S 从0.9.0.0版本开始,社区将默认的GC收集器设置为G1,而G1的Full GC是由单线程执行的,速度非常慢 一旦发现Broker进程频繁Full GC,可以开启G1的**-XX:+PrintAdaptiveSizePolicy,获知引发Full GC的原因** 集群监控 查看Broker进程是否启动,端口是否建立 在容器化的Kafka环境,容器虽然启动成功,但由于网络配置有误,会出现进程已经启动但端口未成功监听的情形 查看Broker端关键日志 Broker端服务器日志server.log – 最重要 控制器日志controlle...




