
Kafka -- 高水位 + Leader Epoch
高水位
水位的定义
- 经典教科书
- 在时刻T,任意创建时间(Event Time)为
T',且T'<=T的所有事件都已经到达,那么T就被定义为水位
- 在时刻T,任意创建时间(Event Time)为
- 《Streaming System》
- 水位是一个单调增加且表征最早未完成工作的时间戳
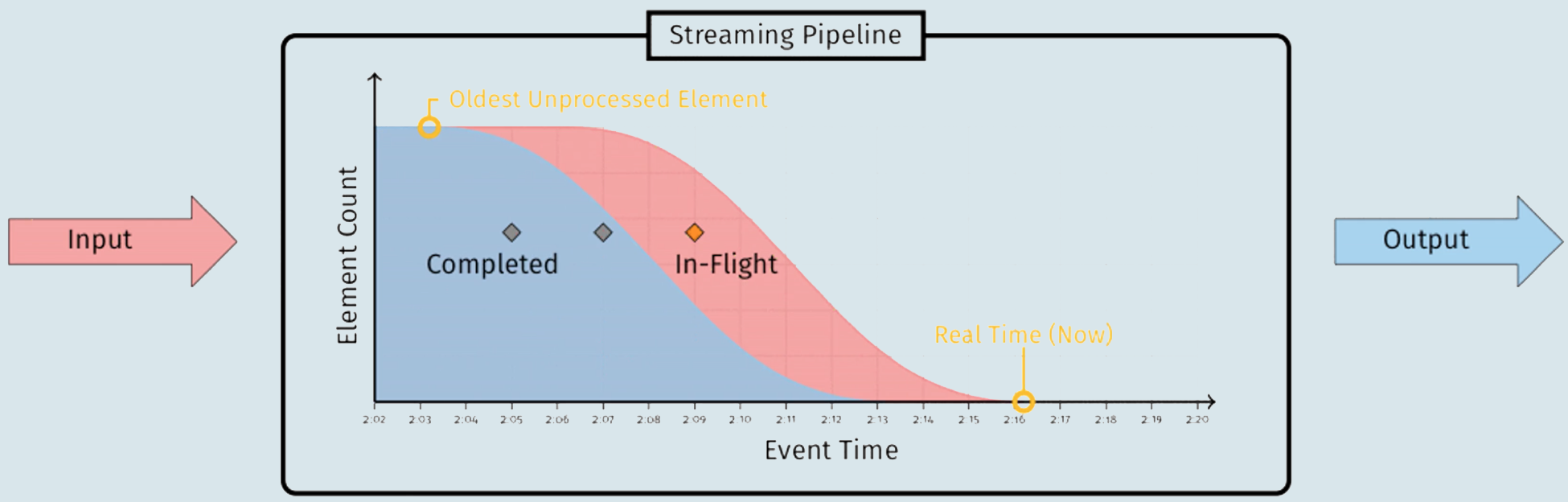
- 上图中标注为
Completed的蓝色部分代表已经完成的工作,标注为In-Flight的红色部分代表正在进行中的工作- 两者的边界就是水位线
- 在Kafka中,水位不是时间戳,而是与位置信息绑定的,即用消息位移来表征水位
- Kafka中也有低水位(Low Watermark),是与Kafka删除消息相关联的概念
高水位的作用
- 两个作用
- 定义消息可见性,即用来标识分区下的哪些消息可以被消费者消费的
- 帮助Kafka完成副本同步
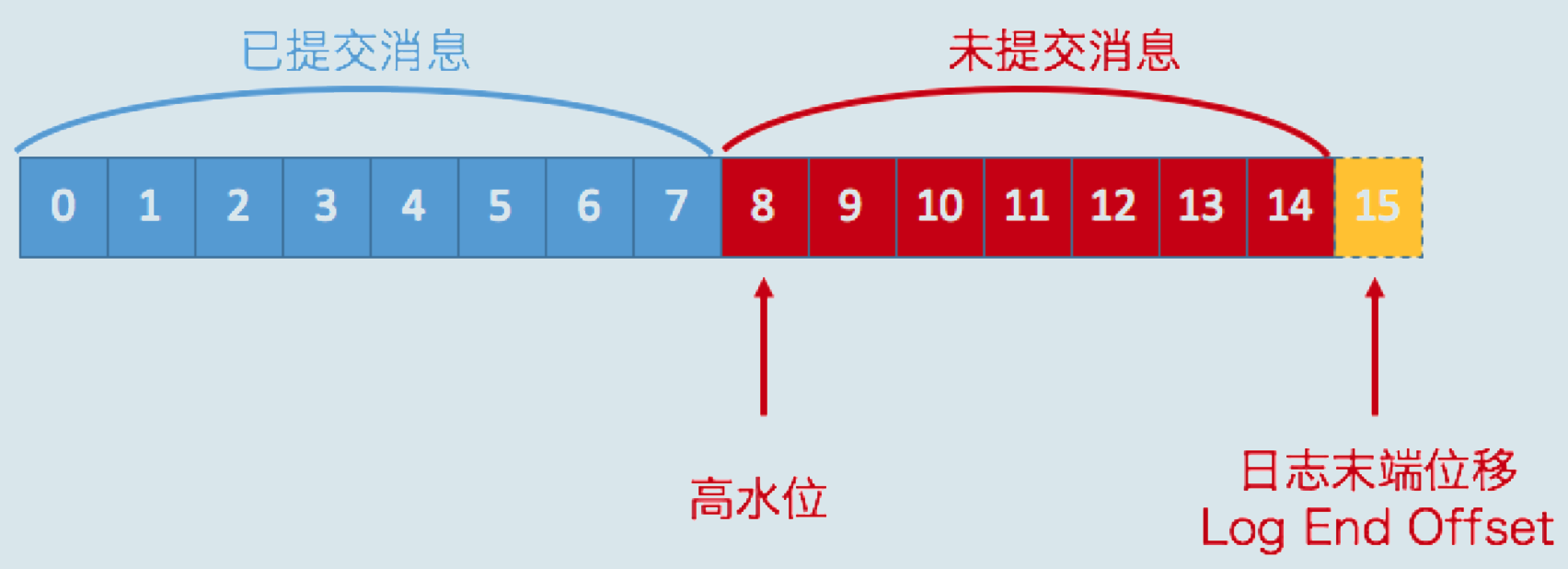
- 上图是某个分区Leader副本的高水位图,在分区高水位以下的消息被认为是已提交消息,反之为未提交消息
- 消费者只能消费已提交消息,即位移小于8的所有消息
- 暂不讨论Kafka事务,Kafka的事务机制会影响消费者所能看到的消息的范围,不只是简单依赖高水位来判断
- 而是依靠LSO(Log Stable Offset)的位移值来判断事务型消费者的可见性
- 位移值等于高水位的消息也属于未提交消息,即高水位上的消息是不能被消费者消费的
- 图中还有一个日志末端位移(Log End Offset,LEO)的概念,表示副本写入下一条消息的位移值
- LEO为15,方框是虚线,表示当前副本只有15条消息,位移从0到14,下一条新消息的位移为15
[高水位,LEO)的消息属于未提交消息,在同一个副本对象,高水位值不会大于LEO值- 高水位和LEO是副本对象的两个重要属性
- Kafka所有副本对象都有对应的高水位和LEO,而Kafka使用Leader副本的高水位来定义所在分区的高水位
高水位的更新机制
远程副本
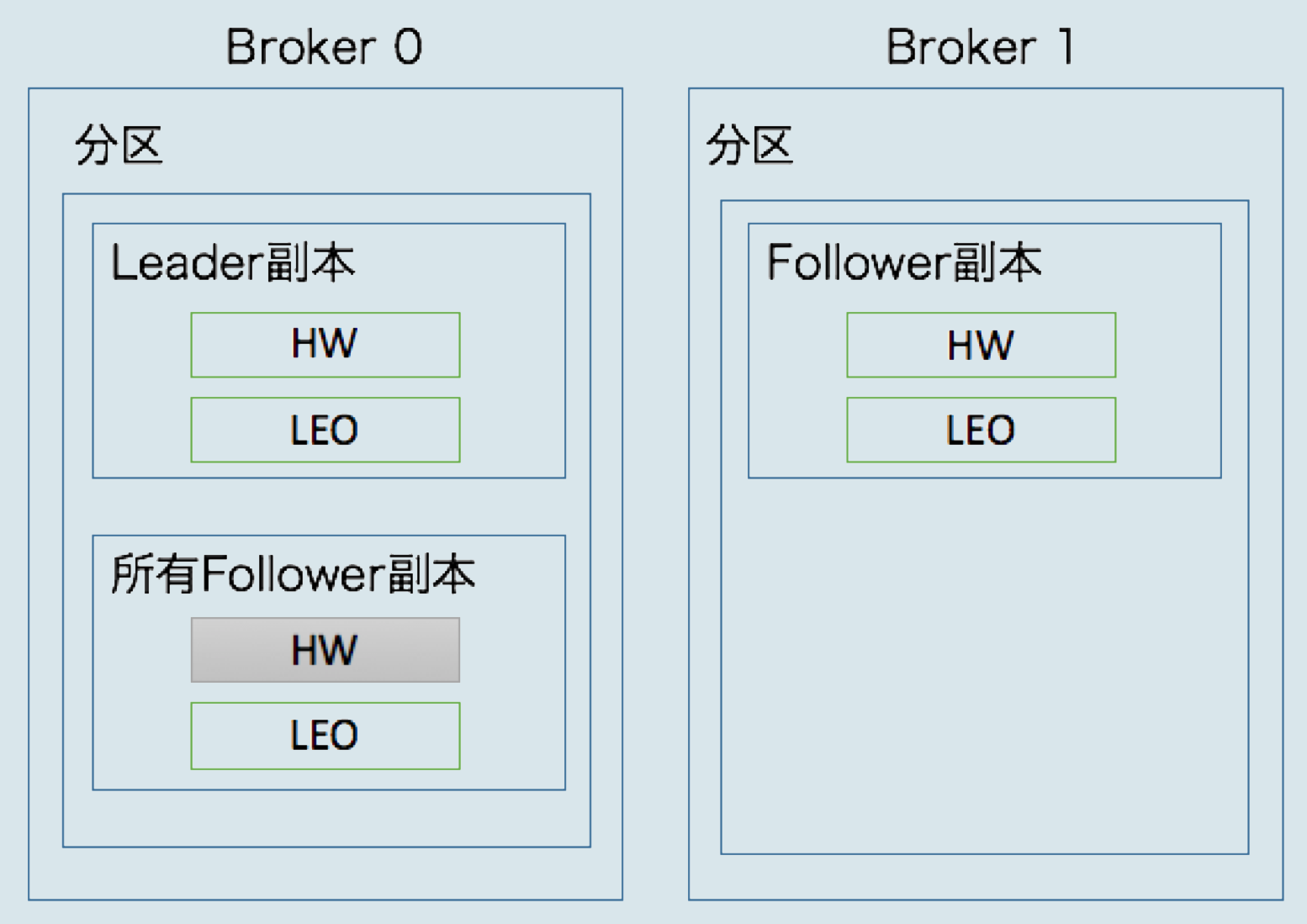
- 每个副本对象都保存了一组高水位和LEO值,Leader副本所在的Broker还保存了_其它Follower副本的LEO值_
- Kafka把Broker 0上保存的Follower副本又称为远程副本(Remote Replica)
- Kafka副本机制在运行过程中
- 会更新
- Broker 1上Follower副本的高水位和LEO值
- Broker 0上Leader副本的高水位和LEO以及所有远程副本的LEO
- 不会更新
- Broker 0所有远程副本的高水位值,即图中标记为灰色的部分
- 会更新
- Broker 0保存远程副本的作用
- 帮助Leader副本确定其高水位,即分区高水位
更新时机
| 更新对象 | 更新时机 |
|---|---|
| Broker 0上Leader副本的LEO | Leader副本接收到生产者发送的消息,写入到本地磁盘后,会更新其LEO值 |
| Broker 1上Follower副本的LEO | Follower副本从Leader副本拉取消息,写入本地磁盘后,会更新其LEO值 |
| Broker 0上远程副本的LEO | Follower副本从Leader副本拉取消息时,会告诉Leader副本从哪个位移开始拉取, Leader副本会使用这个位移值来更新远程副本的LEO |
| Broker 0上Leader副本的高水位 | 两个更新时机:一个是Leader副本更新其LEO之后,一个是更新完远程副本LEO之后 具体算法:取Leader副本和所有与Leader同步的远程副本LEO中的最小值 |
| Broker 1上Follower副本的高水位 | Follower副本成功更新完LEO后,会比较其LEO与Leader副本发来的高水位值, 并用两者的较小值去更新自己的高水位 |
- 与Leader副本保持同步,需要满足两个条件
- 该远程Follower副本在ISR中
- 该远程Follower副本LEO值落后Leader副本LEO值的时间不超过参数
replica.lag.time.max.ms(10秒)
- 某个副本能否进入ISR是由第二个条件判断的
- 2个条件判断是为了应对意外情况:Follower副本已经追上Leader,却不在ISR中
- 假设Kafka只判断第1个条件,副本F刚刚重启,并且已经具备进入ISR的资格,但此时尚未进入到ISR
- 由于缺少了副本F的判断,分区高水位有可能超过真正ISR中的副本LEO,而高水位>LEO是不允许的
Leader副本
- 处理生产者请求
- 写入消息到本地磁盘,更新LEO
- 更新分区高水位值
- 获取Leader副本所在Broker端保存的所有远程副本LEO值
{LEO-1, LEO-2,... LEO-n} - 获取Leader副本的LEO值:
currentLEO - 更新**
currentHW = min(currentLEO, LEO-1, LEO-2,... LEO-n)**
- 获取Leader副本所在Broker端保存的所有远程副本LEO值
- 处理Follower副本拉取消息
- 读取磁盘(或页缓存)中的消息数据
- 使用Follower副本发送请求中的位移值来更新远程副本的LEO值
- 更新分区高水位值(与上面一致)
Follower副本
- 从Leader拉取消息
- 写入消息到本地磁盘
- 更新LEO
- 更新高水位值
- 获取Leader发送的高水位值:
currentHW - 获取步骤2中更新的LEO值:
currentLEO - 更新高水位**
min(currentHW, currentLEO)**
- 获取Leader发送的高水位值:
副本同步样例
主题是单分区两副本,首先是初始状态,所有值都是0
当生产者向主题分区发送一条消息后,状态变更为
此时,Leader副本成功将消息写入到本地磁盘,将LEO值更新为1(更新高水位值为0,并把结果发送给Follower副本)
Follower再次尝试从Leader拉取消息,此时有消息可以拉取,Follower副本也成功更新LEO为1(并将高水位更新为0)
此时,Leader副本和Follower副本的LEO都是1,但各自的高水位依然是0,需要等到下一轮的拉取中被更新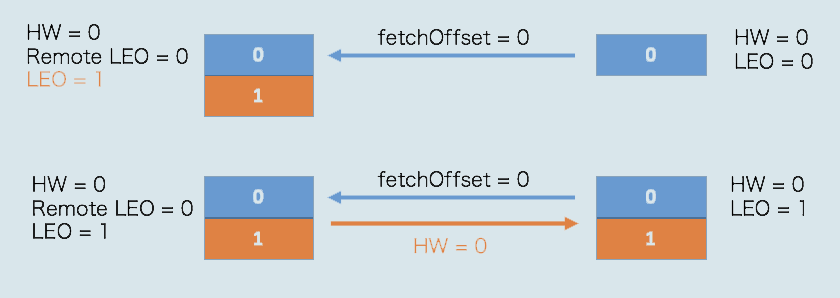
在新一轮的拉取请求中,由于位移值为0的消息已经拉取成功,因此Follower副本这次拉取请求的位移值为1
Leader副本接收到此请求后,更新远程副本LEO为1,然后更新Leader高水位值为1
最后,Leader副本会将当前更新过的高水位值1发送给Follower副本,Follower副本接收到后,也会将自己的高水位值更新为1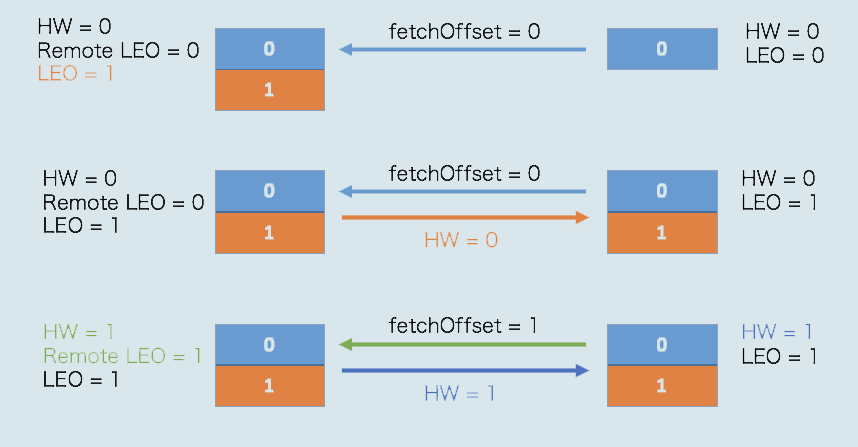
Leader Epoch
基本概念
- 上面的副本同步过程中,Follower副本的高水位更新需要一轮额外的拉取请求才能实现
- 如果扩展到多个Follower副本,可能需要多轮拉取请求
- 即Leader副本高水位更新和Follower副本高水位更新在时间上存在错配
- 这种错配是很多数据丢失或数据不一致问题的根源
- 因此,社区在0.11版本正式引入了
Leader Epoch概念,来规避高水位更新错配导致的各种不一致问题
- Leader Epoch可以大致认为是Leader版本,由两部分数据组成
- Epoch
- 一个单调递增的版本号
- 每当副本领导权发生变更时,都会增加该版本号
- 小版本号的Leader被认为是过期Leader,不能再行使Leader权利
- 起始位移(Start Offset)
- Leader副本在该Epoch值上写入的首条消息的位移
- Epoch
- 两个Leader Epoch,
<0,0>和<1,120><0,0>表示版本号为0,该版本的Leader从位移0开始保存消息,一共保存了120条消息- 之后Leader发生了变更,版本号增加到1,新版本的起始位移是120
- Broker在内存中为每个分区都缓存
Leader Epoch数据,同时还会定期地将这些数据持久化到一个checkpoint文件中- 当Leader副本写入消息到磁盘时,Broker会尝试更新这部分缓存
- 如果Leader是首次写入消息,那么Broker会向缓存中增加Leader Epoch条目,否则不做更新
- 这样每次有Leader变更时,新的Leader副本会查询这部分缓存,取出对应的Leader Epoch的起始位移
- 然后进行相关的逻辑判断,避免数据丢失和数据不一致的情况
数据丢失
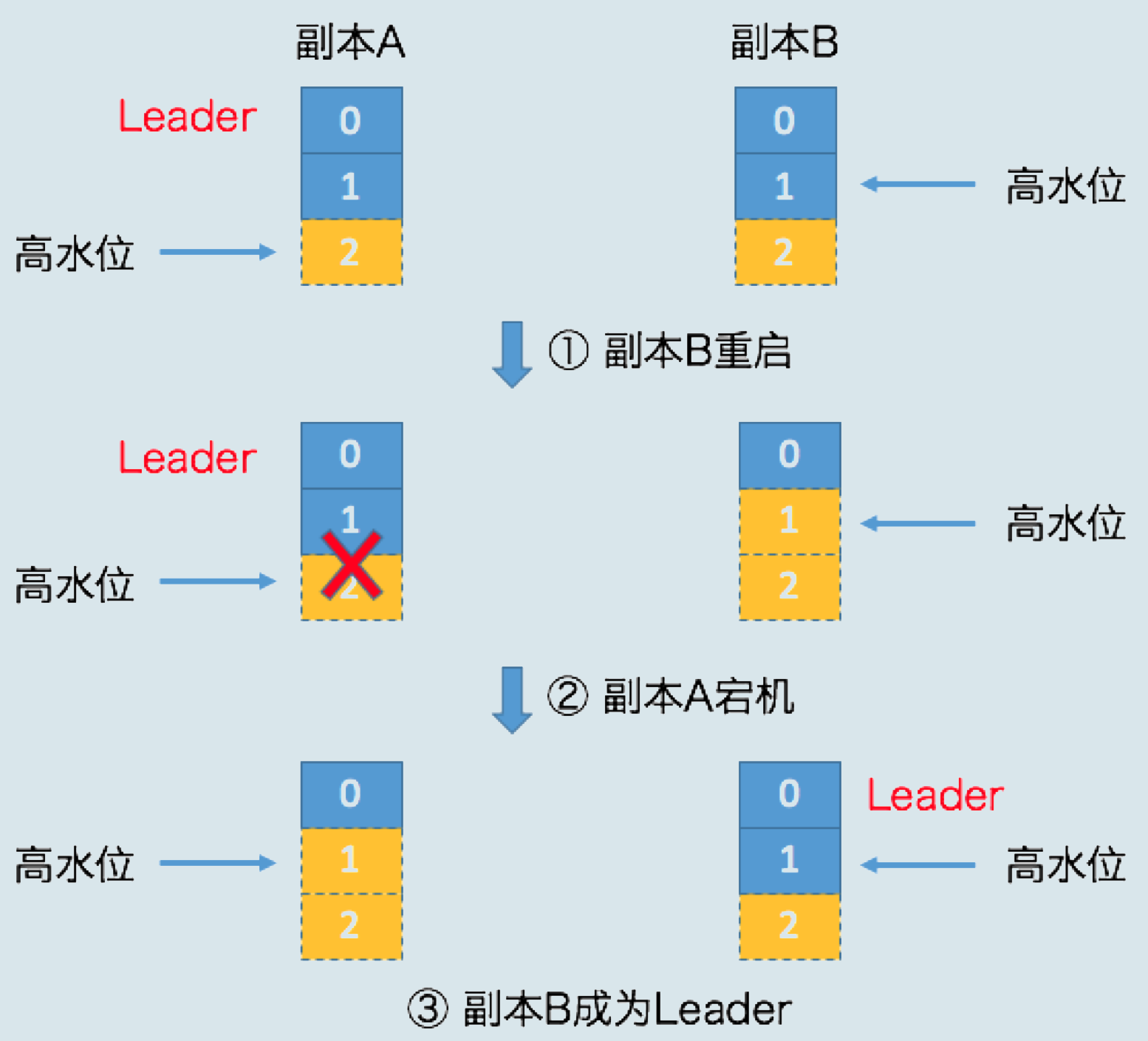
- 开始时,副本A和副本B都处于正常状态,A是Leader副本
- 某个的生产者(默认acks设置)向A发送了两条消息,A全部写入成功,Kafka会通知生产者说两条消息全部发送成功
- 假设Leader和Follower都写入了这两条消息,而且Leader副本的高水位也更新了,但_Follower副本的高水位还未更新_
- 此时副本B所在的Broker宕机,当它重启回来后,副本B会执行_日志截断!!_
- **将LEO值调整为之前的高水位值!!**,也就是1
- 位移值为1的那条消息被副本B从磁盘中删除,此时副本B的底层磁盘文件中只保留1条消息,即位移为0的消息
- 副本B执行完日志截断操作后,开始从A拉取消息,此时恰好副本A所在的Broker也宕机了,副本B自然成为新的Leader
- 当A回来后,需要执行相同的日志截断操作,但不能超过新Leader,即将高水位调整与B相同的值,也就是1
- 操作完成后,位移值为1的那条消息就从两个副本中被永远抹掉,造成了数据丢失
Leader Epoch规避数据丢失

- Follower副本B重启后,需要向A发送一个特殊的请求去获取Leader的LEO值,该值为2
- 当获知Leader LEO后,B发现该LEO值大于等于自己的LEO,而且缓存中也没有保存任何起始位移值>2的Epoch条目
- B无需执行任何日志截断操作
- 明显改进:_副本是否执行日志截断不再依赖于高水位进行判断_
- A宕机,B成为Leader,当A重启回来后,执行与B相同的逻辑判断,发现同样不需要执行日志截断
- 至此位移值为1的那条消息在两个副本中均得到保留
- 后面生产者向B写入新消息后,副本B所在的Broker缓存中会生成新的Leader Epoch条目:**
[Epoch=1, Offset=2]**
小结
- 高水位在界定Kafka消息对外可见性以及实现副本机制方面起到非常重要的作用
- 但设计上的缺陷给Kafka留下了很多数据丢失或数据不一致的潜在风险
- 为此,社区引入了**
Leader Epoch**机制,尝试规避这类风险,并且效果不错
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-08-02
Kafka -- 压缩
压缩的目的时间换空间,用CPU时间去换磁盘空间或网络IO传输量 消息层次 消息集合(Message Set)和消息 一个消息集合中包含若干条日志项(Record Item),而日志项用于封装消息 Kafka底层的消息日志由一系列消息集合日志项组成 Kafka不会直接操作具体的消息,而是在消息集合这个层面上进行写入操作 消息格式 目前Kafka共有两大类消息格式,社区分别称之为V1版本和V2版本(在0.11.0.0引入) V2版本主要针对V1版本的一些弊端进行了优化 优化1:把消息的公共部分抽取到外层消息集合里面 在V1版本中,每条消息都需要执行CRC校验,但在某些情况下,消息的CRC值会发生变化 Broker端可能对消息的时间戳字段进行更新,重新计算后的CRC值也会相应更新 Broker端在执行消息格式转换时(兼容老版本客户端),也会带来CRC值的变化 因此没必要对每条消息都执行CRC校验,浪费空间和时间 在V2版本中,消息的CRC校验被移到了消息集合这一层 优化2:对整个消息集合进行压缩 在V1版本中,对多条消息进行压缩,然后保存到外层消息的消息体字段中 压缩的时机在Kafka...

2019-09-14
Kafka -- 副本
副本机制的优点 提供数据冗余 即使系统部分组件失效,系统依然能够继续运转,增加了整体可用性和数据持久性 提供高伸缩性 支持横向扩展,能够通过增加机器的方式来提升读性能,进而提高读操作吞吐量 改善数据局部性 允许将数据放入与用户地理位置相近的地方,从而降低系统延时 Kafka只能享受副本机制提供数据冗余实现的高可用性和高持久性 副本定义 Kafka主题划分为若干个分区,副本的概念上是在分区层级下定义的,每个分区配置若干个副本 副本:本质上是一个_只能追加写消息的提交日志_ 同一个分区下的所有副本保存有相同的消息序列,这些副本分散保存在不同的Broker上,提高了数据可用性 实际生产环境中,每台Broker都可能保存有各个主题不同分区的不同副本 副本角色 Kafka采用基于领导者(Leader-based)的副本机制 副本分为两类:领导者副本(Leader Replica)和追随者副本(Follower Replica) 每个分区在创建时都要选举一个副本,称为领导者副本,其余的副本自动称为追随者副本 追随者副本是不对外提供服务的,所有的读写请求都必须发往领导者副本所在的B...

2018-10-18
Kafka -- 消费者
基本概念消费者 + 消费者群组 消费者从属于消费者群组 一个消费者群组里的消费者订阅的是同一个主题,每个消费者接收主题的部分分区的消息 消费者横向扩展1个消费者 主题T1有4个分区,然后创建消费者C1,C1是消费者群组G1里唯一的消费者,C1订阅T1 消费者C1将接收主题T1的全部4个分区的消息 2个消费者 如果群组G1新增一个消费者C2,那么每个消费者将分别从两个分区接收消息 假设C1接收分区0和分区2的消息,C2接收分区1和分区3的消息 4个消费者 如果群组G1有4个消费者,那么每个消费者可以分配到一个分区 5个消费者 如果群组G1有5个消费者,_**消费者数量超过主题的分区数量**_,那么有1个消费者就会被**闲置**,不会接收到任何消息 总结 往群组里增加消费者是横向伸缩消费能力的主要方式 消费者经常会做一些高延迟的操作,比如把数据写到数据库或HDFS,或者使用数据进行比较耗时的计算 有必要为主题创建大量的分区,在负载增长时可以加入更多的消费者,减少消息堆积 不要让消费者的数量超过主题分区的数量,多余的消费者只会被闲置 消费者群组横向扩展 Kafka设计的主要目标...

2019-08-22
Kafka -- 消费者组
消费者组 消费者组(Consumer Group)是Kafka提供的可扩展且具有容错性的消费者机制 一个消费者组内可以有多个消费者或消费者实例(进程/线程),它们共享一个Group ID(字符串) 组内的所有消费者协调在一起来消费订阅主题的所有分区 每个分区只能由同一个消费者组内的一个Consumer实例来消费,Consumer实例对分区有所有权 消息引擎模型 两种模型:点对点模型(消息队列)、发布订阅模型 点对点模型(传统的消息队列模型) 缺陷/特性:消息一旦被消费、就会从队列中被删除,而且只能被下游的一个Consumer消费 伸缩性很差,下游的多个Consumer需要抢占共享消息队列中的消息 发布订阅模型 缺陷:伸缩性不高,每个订阅者都必须订阅主题的所有分区(全量订阅) Consumer Group 当Consumer Group订阅了多个主题之后 组内的每个Consumer实例不要求一定要订阅主题的所有分区,只会消费部分分区的消息 Consumer Group之间彼此独立,互不影响,它们能够订阅相同主题而互不干涉 Kafka使用Consumer Group...

2019-09-27
Kafka -- 常用脚本
脚本列表12345678connect-distributed kafka-consumer-perf-test kafka-reassign-partitions kafka-verifiable-producerconnect-standalone kafka-delegation-tokens kafka-replica-verification trogdorkafka-acls kafka-delete-records kafka-run-class zookeeper-security-migrationkafka-broker-api-versions kafka-dump-log kafka-server-start zookeeper-server-startkafka-configs ...

2019-03-26
Kafka -- 内部原理
群组成员关系 Kakfa使用ZooKeeper来维护集群成员的信息 每个Broker都有一个唯一的ID,这个ID可以在配置文件里面指定,也可以自动生成 在Broker启动的时候,通过创建临时节点把自己的ID注册到ZooKeeper Kakfa组件订阅ZooKeeper的/brokers/ids路径,当有Broker加入集群或者退出集群时,Kafka组件能获得通知 如果要启动另一个具有相同ID的Broker,会得到一个错误,这个Broker会尝试进行注册,但会失败 在Broker停机,出现网络分区或者长时间垃圾回收停顿时,Broker会从ZooKeeper上_断开连接_ 此时,Broker在启动时创建的临时节点会从ZooKeeper上自动移除(ZooKeeper特性) 订阅Broker列表的Kafka组件会被告知该Broker已经被移除 在关闭Broker时,它对应的临时节点也会消失,不过它的ID会继续存在于其他数据结构中 例如,主题的副本列表里可能会包含这些ID 在完全关闭了一个Broker之后,如果使用相同的ID启动另一个全新的Broker 该Broker会立即加入集群,并拥有与旧Broker...




