Kafka -- KafkaAdminClient
背景
- 命令行脚本只能运行在控制台上,在应用程序、运维框架或者监控平台中集成它们,会非常困难
- 很多命令行脚本都是通过连接ZK来提供服务的,这会存在潜在的问题,即绕过Kafka的安全设置
- 运行这些命令行脚本需要使用Kafka内部的类实现,也就是Kafka服务端的代码
- 社区是希望用户使用Kafka客户端代码,通过现有的请求机制来运维管理集群
- 基于上述原因,社区于0.11版本正式推出Java客户端版的KafkaAdminClient
功能
- 主题管理
- 主题的创建、删除、查询
- 权限管理
- 具体权限的配置和删除
- 配置参数管理
- Kafka各种资源(Broker、主题、用户、Client-Id等)的参数设置、查询
- 副本日志管理
- 副本底层日志路径的变更和详情查询
- 分区管理
- 创建额外的主题分区
- 消息删除
- 删除指定位移之前的分区消息
- Delegation Token管理
- Delegation Token的创建、更新、过期、查询
- 消费者组管理
- 消费者组的查询、位移查询和删除
- Preferred领导者选举
- 推选指定主题分区的Preferred Broker为领导者
工作原理
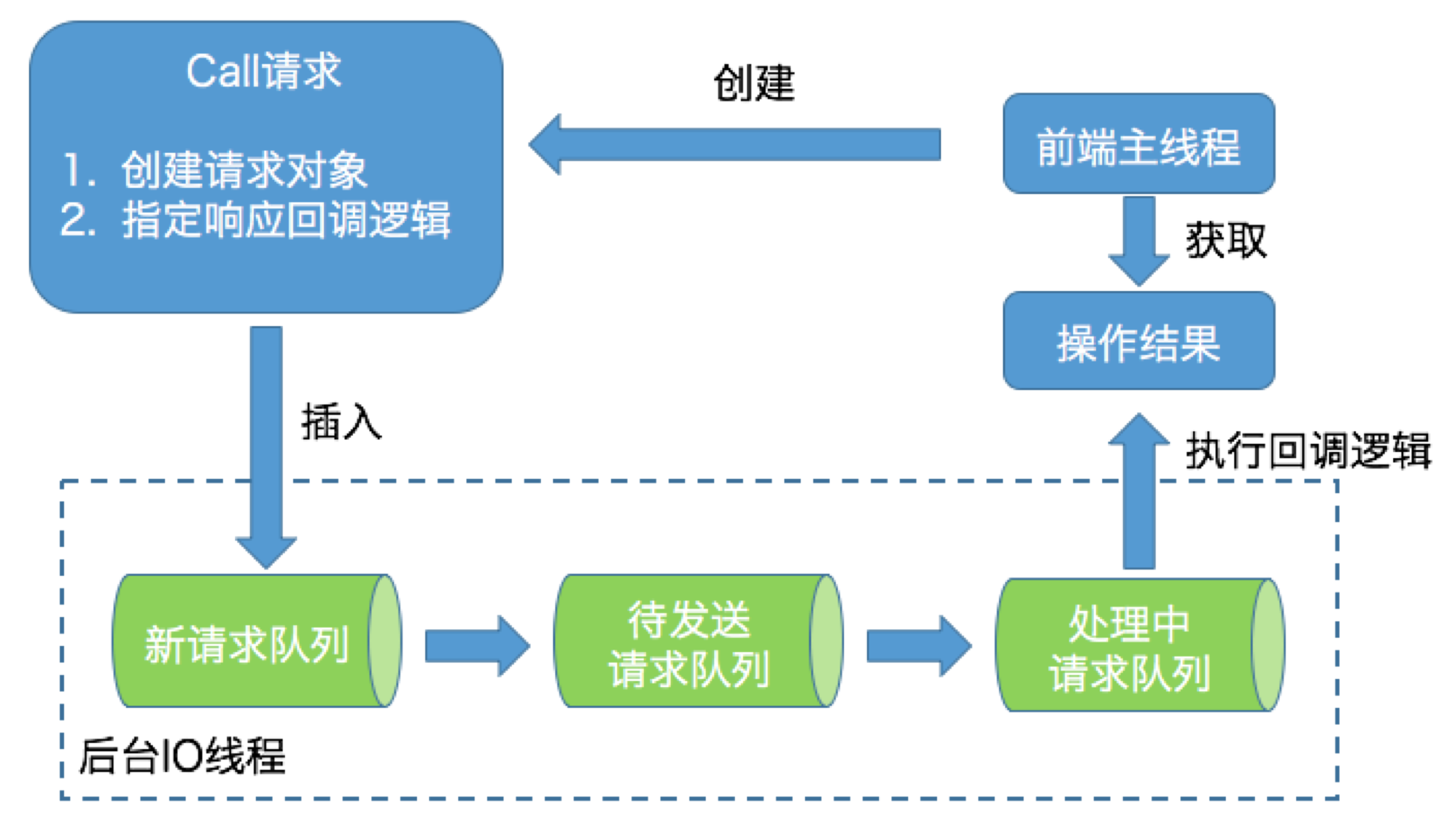
- KafkaAdminClient是双线程设计
- 前端主线程
- 负责将用户要执行的操作转换成对应的请求,然后将请求发送到后端IO线程的队列中
- 后端IO线程
- 从队列中读取相应的请求,再发送到对应的Broker节点上,之后把执行结果保存起来,等待前端线程的获取
- 前端主线程
- KafkaAdminClient在内部大量使用生产者-消费者模式将请求生成和处理解耦
- 前端主线程会创建名为Call的请求对象实例,该实例有两个主要任务
- 构建对应的请求对象
- 创建主题:CreateTopicsRequest
- 查询消费者组位移:OffsetFetchRequest
- 指定响应的回调逻辑
- 比如从Broker端接收到CreateTopicsResponse之后要执行的动作
- 构建对应的请求对象
- 后端IO线程使用了3个队列来承载不同时期的请求对象,分别为新请求队列、待发送请求队列和处理中请求队列
- 原因:新请求队列的线程安全是由Java的Monitor锁来保证的
- 为了保证前端线程不会因为Monitor锁被阻塞,后端IO线程会定期地将新请求队列中的所有Call实例全部搬移到待发送请求队列中进行处理
- 待发送请求队列和处理中请求队列只由后端IO线程处理,因为无需任何锁机制来保证线程安全
- 当后端IO线程在处理某个请求时,会显式地将请求保存在处理中请求队列
- 一旦处理完毕,后端IO线程会自动调用Call对象中的回调逻辑完成最后的处理
- 最后,后端IO线程会通知前端主线程说结果已经准备完毕,这样前端主线程就能够及时获取到执行操作的结果
- KafkaAdminClient是使用了Object的wait和notify来实现通知机制
- KafkaAdminClient并没有使用Java已有的队列去实现请求队列
- 而是使用ArrayList和HashMap等简单容器,再配合Monitor锁来保证线程安全
- 后端线程名称:**
kafka-admin-client-thread,可以用jstack**去确认程序是否正常工作- 后端IO线程可能由于未捕获某些异常而意外挂掉
- 原因:新请求队列的线程安全是由Java的Monitor锁来保证的
应用场景
创建主题
1 | Properties props = new Properties(); |
查询消费者组位移
1 | String groupId = "zhongmingmao"; |
获取Broker磁盘占用
1 | try (AdminClient client = AdminClient.create(props)) { |
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-06-18
Kafka -- 消息引擎系统
术语 Apache Kafka是一款开源的消息引擎系统 消息队列:给人某种暗示,仿佛Kafka是利用队列实现的 消息中间件:过度强调中间件,而不能清晰地表达实际解决的问题 解决的问题 系统A发送消息给消息引擎系统,系统B从消息引擎系统中读取A发送的消息 消息引擎传输的对象是消息 如何传输消息属于消息引擎设计机制的一部分 消息格式 成熟解决方案:CSV、XML、JSON 序列化框架:Google Protocol Buffer、Facebook Thrift Kafka:纯二进制的字节序列 消息引擎模型 点对点模型 即消息队列模型,系统A发送的消息只能被系统B接收,其他任何系统不能读取A发送的消息 发布订阅模型 主题(Topic)、发布者(Publisher)、订阅者(Subscriber) 多个发布者可以向相同的主题发送消息,多个订阅者可以接收相同主题的消息 Kafka同时支持上面两种消息引擎模型 JMS JMS:Java Message Service JMS也支持上面的两种消息引擎模型 JMS并非传输协议,而是一组API JMS非常出名,很多主流的消息引擎系统都支持JMS规范 A...

2019-08-02
Kafka -- 压缩
压缩的目的时间换空间,用CPU时间去换磁盘空间或网络IO传输量 消息层次 消息集合(Message Set)和消息 一个消息集合中包含若干条日志项(Record Item),而日志项用于封装消息 Kafka底层的消息日志由一系列消息集合日志项组成 Kafka不会直接操作具体的消息,而是在消息集合这个层面上进行写入操作 消息格式 目前Kafka共有两大类消息格式,社区分别称之为V1版本和V2版本(在0.11.0.0引入) V2版本主要针对V1版本的一些弊端进行了优化 优化1:把消息的公共部分抽取到外层消息集合里面 在V1版本中,每条消息都需要执行CRC校验,但在某些情况下,消息的CRC值会发生变化 Broker端可能对消息的时间戳字段进行更新,重新计算后的CRC值也会相应更新 Broker端在执行消息格式转换时(兼容老版本客户端),也会带来CRC值的变化 因此没必要对每条消息都执行CRC校验,浪费空间和时间 在V2版本中,消息的CRC校验被移到了消息集合这一层 优化2:对整个消息集合进行压缩 在V1版本中,对多条消息进行压缩,然后保存到外层消息的消息体字段中 压缩的时机在Kafka...

2019-09-26
Kafka -- 重设消费者组位移
背景 Kafka和传统的消息引擎在设计上有很大的区别,Kafka消费者读取消息是可以重演的 像RabbitMQ和ActiveMQ等传统消息中间件,处理和响应消息的方式是破坏性 一旦消息被成功处理,就会从Broker上被删除 Kafka是基于日志结构(Log-based)的消息引擎 消费者在消费消息时,仅仅是从磁盘文件中读取数据而已,是只读操作,因为消费者不会删除消息数据 同时,由于位移数据是由消费者控制的,因此能够很容易地修改位移值,实现重复消费历史数据的功能 Kafka Or 传统消息中间件 传统消息中间件:消息处理逻辑非常复杂,处理代价高、又不关心消息之间的顺序 Kafka:需要较高的吞吐量、但每条消息的处理时间很短,又关心消息的顺序 重设位移策略 位移维度 直接把消费者的位移值重设成给定的位移值 时间维度 给定一个时间,让消费者把位移调整成大于该时间的最小位移 维度 策略 含义 位移维度 Earliest 把位移调整到当前最早位移处 Latest 把位移调整到当前最新位移处 Current 把位移调整到当前最新提交位移处 Specified...

2019-09-27
Kafka -- 常用脚本
脚本列表12345678connect-distributed kafka-consumer-perf-test kafka-reassign-partitions kafka-verifiable-producerconnect-standalone kafka-delegation-tokens kafka-replica-verification trogdorkafka-acls kafka-delete-records kafka-run-class zookeeper-security-migrationkafka-broker-api-versions kafka-dump-log kafka-server-start zookeeper-server-startkafka-configs ...
2018-10-15
Kafka -- Avro入门
引入依赖12345<dependency> <groupId>org.apache.avro</groupId> <artifactId>avro</artifactId> <version>1.8.2</version></dependency> 1234567891011121314151617<plugin> <groupId>org.apache.avro</groupId> <artifactId>avro-maven-plugin</artifactId> <version>1.8.2</version> <executions> <execution> <phase>generate-sources</phase> <goals> ...

2019-09-14
Kafka -- 副本
副本机制的优点 提供数据冗余 即使系统部分组件失效,系统依然能够继续运转,增加了整体可用性和数据持久性 提供高伸缩性 支持横向扩展,能够通过增加机器的方式来提升读性能,进而提高读操作吞吐量 改善数据局部性 允许将数据放入与用户地理位置相近的地方,从而降低系统延时 Kafka只能享受副本机制提供数据冗余实现的高可用性和高持久性 副本定义 Kafka主题划分为若干个分区,副本的概念上是在分区层级下定义的,每个分区配置若干个副本 副本:本质上是一个_只能追加写消息的提交日志_ 同一个分区下的所有副本保存有相同的消息序列,这些副本分散保存在不同的Broker上,提高了数据可用性 实际生产环境中,每台Broker都可能保存有各个主题不同分区的不同副本 副本角色 Kafka采用基于领导者(Leader-based)的副本机制 副本分为两类:领导者副本(Leader Replica)和追随者副本(Follower Replica) 每个分区在创建时都要选举一个副本,称为领导者副本,其余的副本自动称为追随者副本 追随者副本是不对外提供服务的,所有的读写请求都必须发往领导者副本所在的B...