
Kafka -- 调优
调优目标
- 主要目标:高吞吐量、低延时
- 吞吐量
- 即TPS,指的是Broker端进程或Client端应用程序每秒能处理的字节数或消息数
- 延时,可以有两种理解
- 从Producer发送消息到Broker持久化完成之间的时间间隔
- 端到端的延时,即从Producer发送消息到Consumer成功消费该消息的总时长
优化漏斗
优化漏斗是调优过程中的分层漏斗,层级越靠上,调优的效果越明显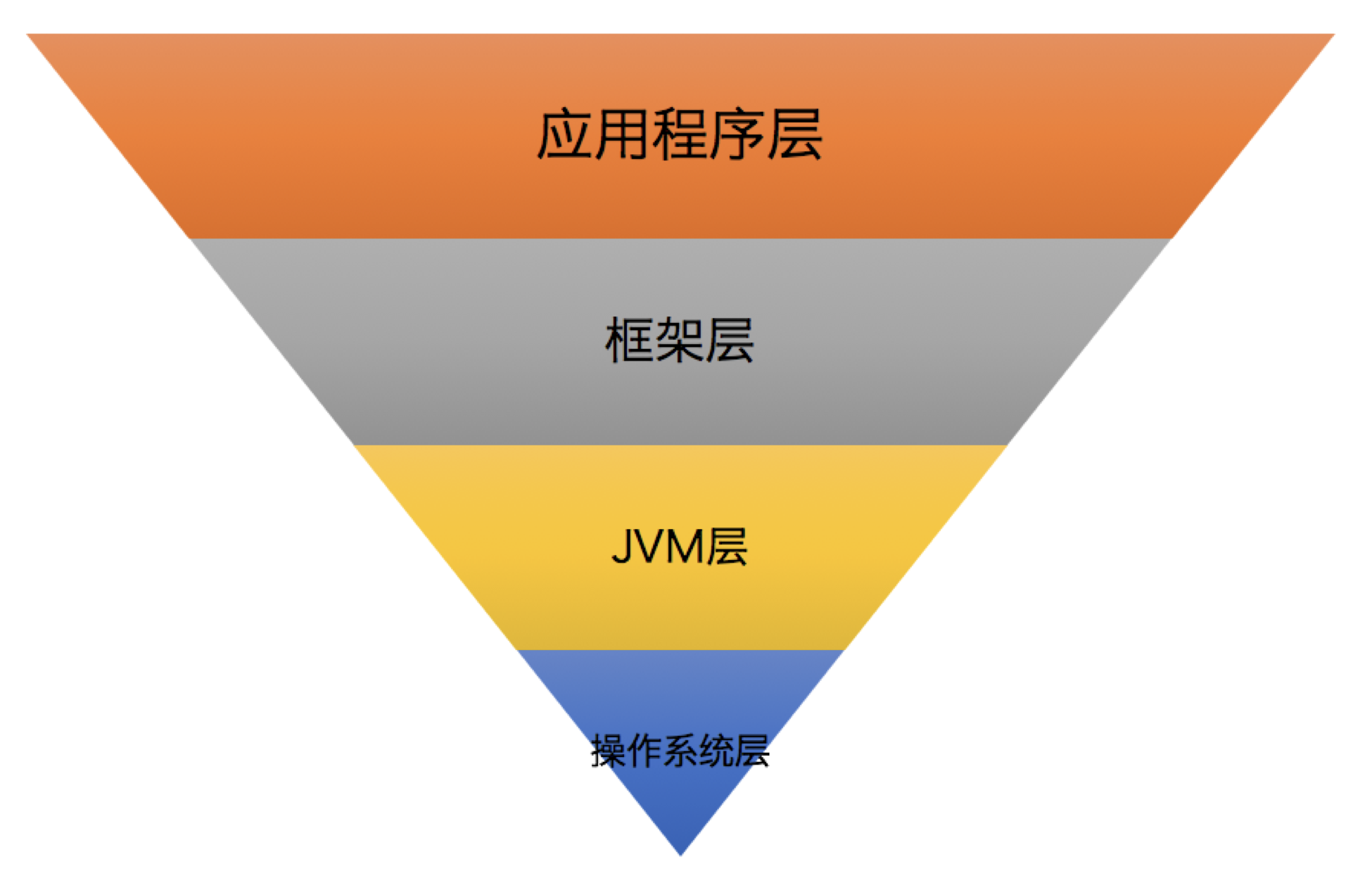
操作系统层
mount -o noatime- 在挂载文件系统时禁用atime(Access Time)更新,记录的是文件最后被访问的时间
- 记录atime需要操作系统访问inode资源,禁用atime可以避免inode访问时间的写入操作
- 文件系统选择ext4、XFS、ZFS
- 将swappiness设置成一个很小的值(1~10,默认是60),防止Linux的
OOM Killer开启随机杀掉进程- swappiness=0,并不会禁止对swap的使用,只是最大限度地降低使用swap的可能性
- 因为一旦设置为0,当物理内存耗尽时,操作系统会触发OOM Killer
- OOM Killer会随机挑选一个进程然后kill掉,不会给出任何预警
- swappiness=N,表示内存使用**
(100-N)%**时,开始使用Swap
- swappiness=0,并不会禁止对swap的使用,只是最大限度地降低使用swap的可能性
ulimit -n设置大一点,否则可能会出现Too Many File Open错误vm.max_map_count也设置大一点(如655360,默认值65530)- 在一个主题数超多的机器上,可能会碰到OutOfMemoryError:Map failed错误
- 页缓存大小
- 给Kafka预留的页缓存至少也要容纳一个日志段的大小(
log.segment.bytes,默认值为1GB) - 消费者程序在消费时能直接命中页缓存,从而避免昂贵的物理磁盘IO操作
- 给Kafka预留的页缓存至少也要容纳一个日志段的大小(
JVM层
- 堆大小,经验值为6~8GB
- 如果需要精确调整,关注Full GC后堆上存活对象的总大小,然后将堆大小设置为该值的1.5~2倍
jmap -histo:live <pid>可以人为触发Full GC
- 选择垃圾收集器
- 推荐使用G1,主要原因是优化难度比CMS小
- 如果使用G1后,频繁Full GC,配置
-XX:+PrintAdaptiveSizePolicy,查看触发Full GC的原因 - 使用G1的另一个问题是大对象,即
too many humongous allocations- 大对象一般指的是至少占用半个Region大小的对象,大对象会被直接分配在大对象区
- 可以适当增大
-XX:+G1HeapRegionSize=N
- 尽量避免Full GC!!
框架层
尽量保持客户端版本和Broker端版本一致,否则可能会丧失很多性能收益,如Zero Copy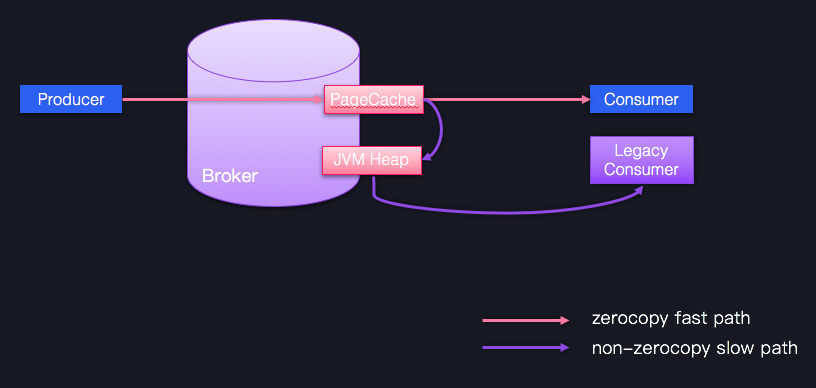
应用程序层
- 不要频繁创建Producer和Consumer对象实例,构造这些对象的开销很大
- 用完及时关闭
- Producer对象和Consumer对象会创建很多物理资源,如Socket连接、ByteBuffer缓冲区,很容易造成资源泄露
- 合理利用多线程来改善性能,Kafka的Java Producer是线程安全的,而Java Consumer不是线程安全的
性能指标调优
TPS != 1000 / Latency(ms)
- 假设Kafka Producer以2ms的延时来发送消息,如果每次都只发送一条消息,那么
TPS=500 - 但如果Producer不是每次只发送一条消息,而是在发送前等待一段时间,然后统一发送一批消息
- 如Producer每次发送前等待8ms,总共缓存了1000条消息,总延时累加到了10ms,但
TPS=100,000- 虽然延时增加了4倍,但TPS却增加了200倍,这就是批次化或微批次化的优势
- 用户一般愿意用较小的延时增加的代价,去换取TPS的显著提升,Kafka Producer就是采用了这样的思路
- 基于的前提:内存操作(几百纳秒)和网络IO操作(毫秒甚至秒级)的时间量级不同
调优吞吐量
- Broker端
- 适当增加**
num.replica.fetchers(默认值为1),但不用超过CPU核数**- 生产环境中,配置了
acks=all的Producer程序吞吐量被拖累的首要因素,就是副本同步性能
- 生产环境中,配置了
- 调优GC参数避免频繁Full GC
- 适当增加**
- Producer端
- 适当增加
batch.size(默认值为16KB,可以增加到512KB或1MB)- 增加消息批次的大小
- 适当增加
linger.ms(默认值为0,可以增加到10~100)- 增加消息批次的缓存时间
- 修改
compression.type(默认值为none,可以修改为lz4或zstd,适配最好) - 修改
acks(默认值为1,可以修改为0或1)- 优化的目标是吞吐量,不要开启
acks=all(引入的副本同步时间通常是吞吐量的瓶颈)
- 优化的目标是吞吐量,不要开启
- 修改
retries(修改为0)- 优化的目标是吞吐量,不要开启重试
- 如果多线程共享同一个Producer,增加
buffer.memory(默认为32MB)TimeoutException:Failed to allocate memory within the configured max blocking time
- 适当增加
- Consumer端
- 采用多Consumer进程或线程同时消费数据
- 适当增加
fetch.min.bytes(默认值为1Byte,可以修改为1KB或更大)
调优延时
- Broker端
- 适当增加
num.replica.fetchers
- 适当增加
- Producer端
- 设置
linger.ms=0 - 设置
compression.type=none- 压缩会消耗CPU时间
- 设置
acks=1
- 设置
- Consumer端
- 设置
fetch.min.bytes=1
- 设置
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2019-08-02
Kafka -- 压缩
压缩的目的时间换空间,用CPU时间去换磁盘空间或网络IO传输量 消息层次 消息集合(Message Set)和消息 一个消息集合中包含若干条日志项(Record Item),而日志项用于封装消息 Kafka底层的消息日志由一系列消息集合日志项组成 Kafka不会直接操作具体的消息,而是在消息集合这个层面上进行写入操作 消息格式 目前Kafka共有两大类消息格式,社区分别称之为V1版本和V2版本(在0.11.0.0引入) V2版本主要针对V1版本的一些弊端进行了优化 优化1:把消息的公共部分抽取到外层消息集合里面 在V1版本中,每条消息都需要执行CRC校验,但在某些情况下,消息的CRC值会发生变化 Broker端可能对消息的时间戳字段进行更新,重新计算后的CRC值也会相应更新 Broker端在执行消息格式转换时(兼容老版本客户端),也会带来CRC值的变化 因此没必要对每条消息都执行CRC校验,浪费空间和时间 在V2版本中,消息的CRC校验被移到了消息集合这一层 优化2:对整个消息集合进行压缩 在V1版本中,对多条消息进行压缩,然后保存到外层消息的消息体字段中 压缩的时机在Kafka...

2018-10-11
Kafka -- 生产者
生产者概述 创建一个ProducerRecord对象,ProducerRecord对象包含Topic和Value,还可以指定Key或Partition 在发送ProducerRecord对象时,生产者先将Key和Partition序列化成字节数组,以便于在网络上传输 字节数组被传给分区器 如果在ProducerRecord对象里指定了Partition 那么分区器就不会做任何事情,直接返回指定的分区 如果没有指定分区,那么分区器会根据ProducerRecord对象的Key来选择一个Partition 选择好分区后,生产者就知道该往哪个主题和分区发送这条记录 这条记录会被添加到一个记录批次里,一个批次内的所有消息都会被发送到相同的Topic和Partition上 有一个单独的线程负责把这些记录批次发送到相应的Broker 服务器在收到这些消息时会返回一个响应 如果消息成功写入Kafka,就会返回一个RecordMetaData对象 包含了Topic和Partition信息,以及记录在分区里的偏移量 如果写入失败,就会返回一个错误 生产者在收到错误之后会尝试重新发送消息,几次之后如果还...

2019-09-01
Kafka -- 避免重平衡
概念 Rebalance是让Consumer Group下所有的Consumer实例就如何消费订阅主题的所有分区达成共识的过程 在Rebalance过程中,所有Consumer实例共同参与,在协调者组件的帮助下,完成订阅主题分区的分配 整个Rebalance过程中,所有Consumer实例都不能消费任何消息,因此对Consumer的TPS影响很大 协调者 协调者,即Coordinator,负责为Consumer Group执行Rebalance以及提供位移管理和组成员管理等 Consumer端应用程序在提交位移时,其实是向Coordinator所在的Broker提交位移 Consumer应用启动时,也是向Coordinator所在的Broker发送各种请求 然后由Coordinator负责执行消费组的注册、成员管理记录等元数据管理操作 所有Broker在启动时,都会创建和开启相应的Coordinator组件,所有Broker都有各自的Coordinator组件 内部位移主题__consumer_offsets记录了为Consumer Group服务的Coordinator在哪一台Broker上...
2018-10-09
Kafka -- 集群安装与配置(Docker)
配置文件文件列表123$ tree.└── docker-compose.yml docker-compose.yml123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103version: '2'services: zk1: image: confluentinc/cp-zookeeper:latest hostname: zk1 container_name: zk1 restart: always ports: - "12181:2181" environment: ZOOKEEPER_SERVER_ID: 1 ZOOKEEPER_CLIENT_...

2019-09-29
Kafka -- 监控
主机监控 主机监控:监控Kafka集群Broker所在的节点机器的性能 常见的主机监控指标 机器负载 CPU使用率 内存使用率,包括空闲内存和已使用内存 磁盘IO使用率,包括读使用率和写使用率 网络IO使用率 TCP连接数 打开文件数 inode使用情况 JVM监控 重点指标 Full GC发生频率和时长 活跃对象大小 应用线程总数 设置堆大小 经历一次Full GC后,堆上存活的活跃对象大小为S,可以安全地将老年代堆大小设置为1.5S或者2S 从0.9.0.0版本开始,社区将默认的GC收集器设置为G1,而G1的Full GC是由单线程执行的,速度非常慢 一旦发现Broker进程频繁Full GC,可以开启G1的**-XX:+PrintAdaptiveSizePolicy,获知引发Full GC的原因** 集群监控 查看Broker进程是否启动,端口是否建立 在容器化的Kafka环境,容器虽然启动成功,但由于网络配置有误,会出现进程已经启动但端口未成功监听的情形 查看Broker端关键日志 Broker端服务器日志server.log – 最重要 控制器日志controlle...

2019-06-22
Kafka -- 术语
主题 + 客户端 发布订阅的对象是主题(Topic) 向主题发布消息的客户端应用程序称为生产者(Producer),生产者可以持续不断地向多个主题发送消息 订阅这些主题消息的客户端应用程序称为消费者(Consumer),消费者能够同时订阅多个主题的消息 生产者和消费者统称为客户端 服务端 Kafka的服务端由被称为Broker的服务进程构成,一个Kafka集群由多个Broker组成 Broker负责接收和处理客户端发送过来的请求,以及对消息进行持久化 多个Broker进程能够运行在同一台机器上,但更常见的做法是将不同的Broker分散运行在不同的机器上 这样如果集群中某一台机器宕机了,即使在它上面运行的所有Broker进程都挂掉了 其他机器上的Broker也依然能够对外提供服务,这是Kafka提供高可用的手段之一 备份 实现高可用的另一个手段是备份机制(Replication) 备份:把相同的数据拷贝到多台机器上,这些相同的数据拷贝在Kafka中被称为副本(Replica) 副本的数量是可以配置的,Kafka定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follow...




