
计算机组成 -- 冒险
冒险
- 流水线架构的CPU,是主动进行的冒险选择,期望通过冒险带来更高的回报
- 对于各种冒险可能造成的问题,都准备好了应对方案
- 分类
- 结构冒险(Structural Hazard)
- 数据冒险(Data Hazard)
- 控制冒险(Control Hazard)
结构冒险
- 结构冒险,本质上是一个硬件层面的资源竞争问题
- CPU在同一个时钟周期,同时在运行两条计算机指令的不同阶段,但这两个不同的阶段可能会用到同样的硬件电路
内存的数据访问
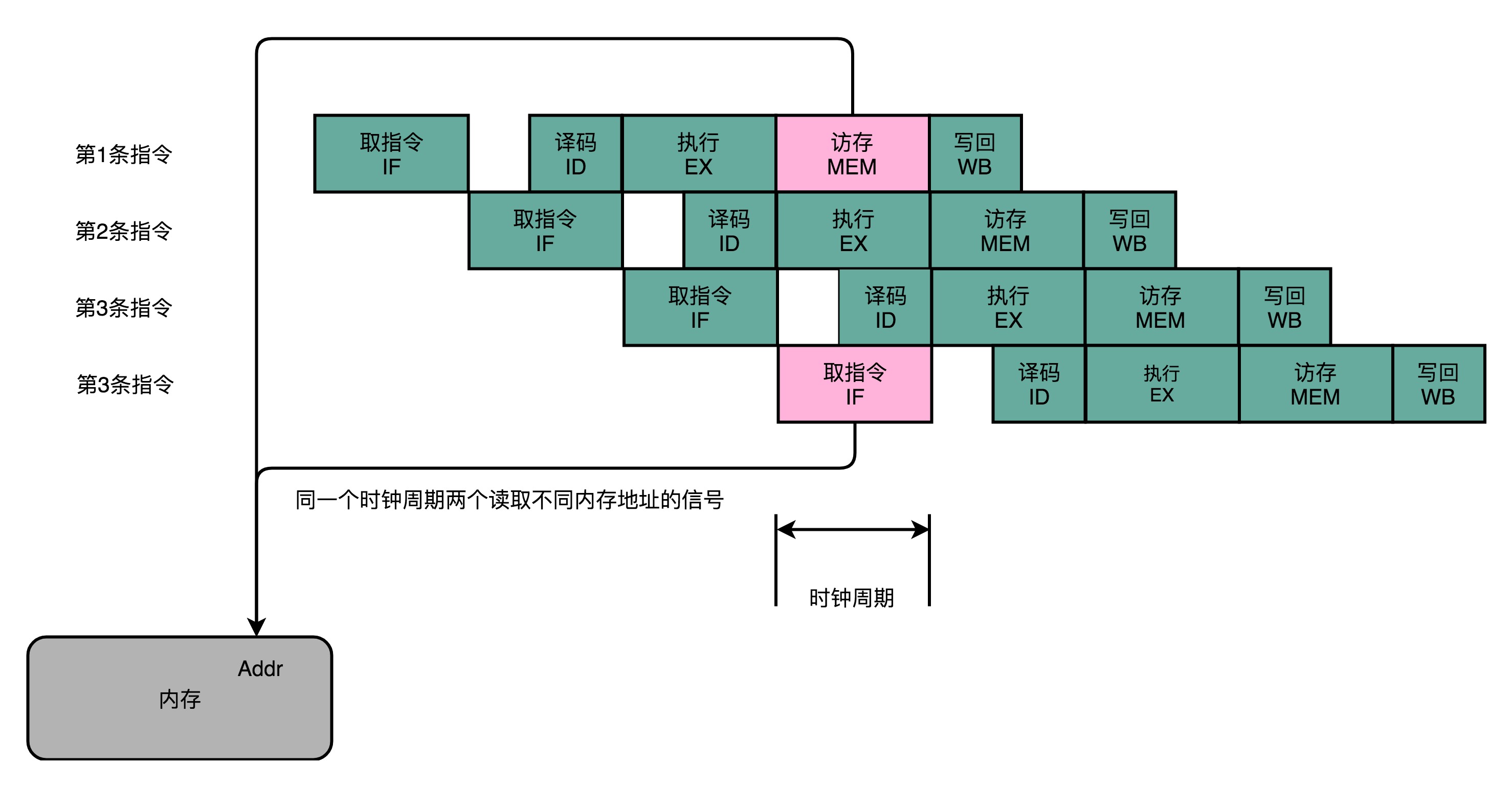
- 第1条指令执行到访存(MEM)阶段的时候,流水线的第4条指令,在执行取指令(Fetch)操作
- 访存和取指令,都是要进行内存数据的读取,而内存只有一个地址译码器,只能在一个时钟周期内读取一条数据
- 无法同时执行第1条指令的读取内存数据和第4条指令的读取指令代码
解决方案
- 解决方案:增加资源
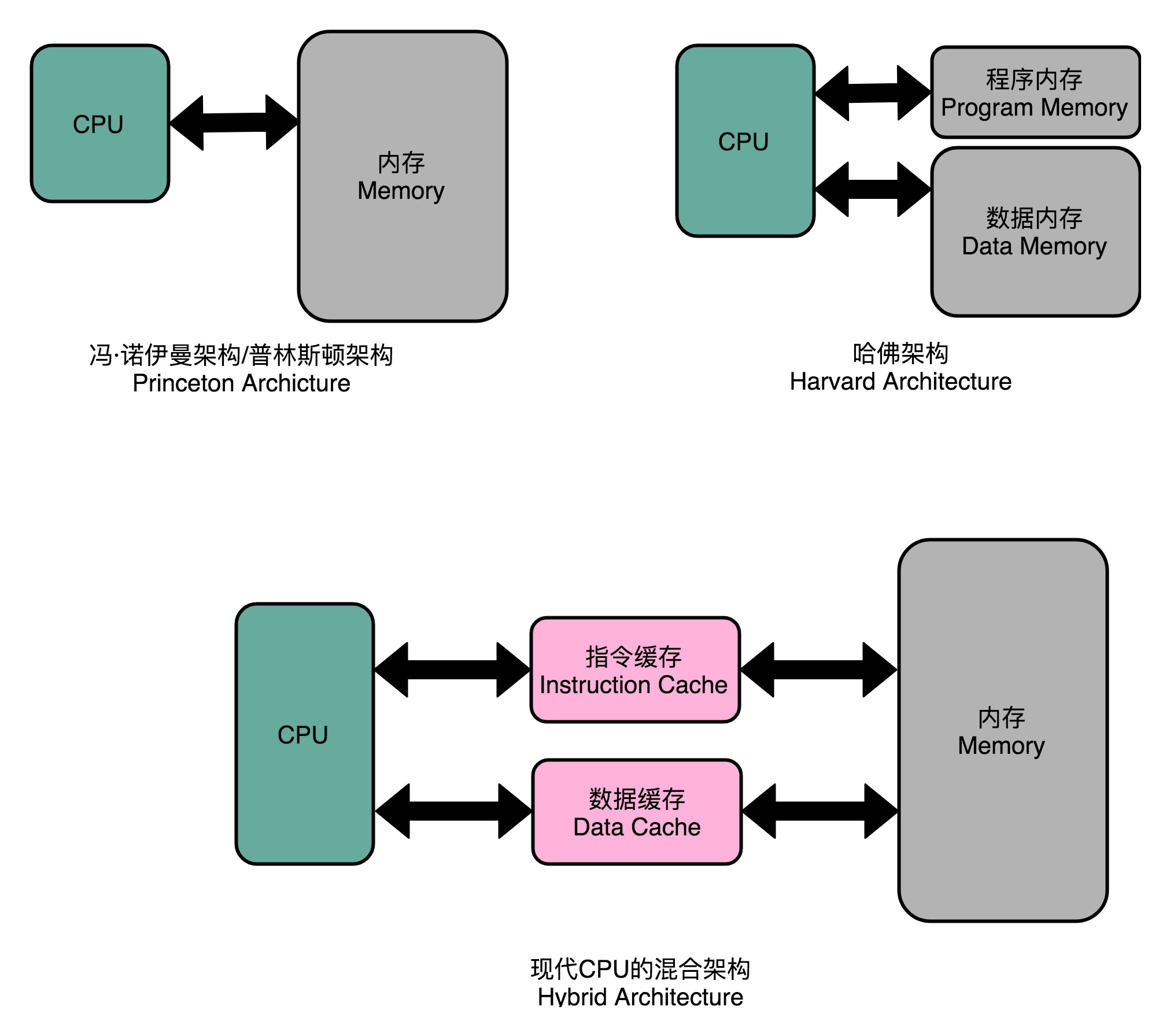
- 哈佛架构
- 把内存分成两部分,它们有各自的地址译码器,这两部分分别是存放指令的程序内存和存放数据的数据内存
- 缺点:无法根据实际情况去动态调整
- 普林斯顿架构 – 冯.诺依曼体系架构
- 今天使用的CPU,仍然是冯.诺依曼体系架构,并没有把内存拆成程序内存和数据内存两部分
- 混合架构
- 现代CPU没有在内存层面进行对应的拆分,但在CPU内部的高速缓存部分进行了区分,分成了指令缓存和数据缓存
- 内存的访问速度远比CPU的速度慢,现代CPU并不会直接读取主内存
- 会从主内存把指令和数据加载到高速缓存中,后续的访问都是访问高速缓存
- 指令缓存和数据缓存的拆分,使得CPU在进行数据访问和取指令的时候,不会再发生资源冲突的情况
数据冒险
- 结构冒险是硬件层面的问题,可以通过增加硬件资源的方式来解决;但还有很多冒险问题属于程序逻辑层面,最常见是数据冒险
- 数据冒险:同时在执行多个指令之间,有数据依赖的情况
- 依赖分类
- 先写后读(Read After Write,RAW)
- 先读后写(Write After Read,WAR)
- 写后再写(Write After Write,WAW)
依赖
写 -> 读
1 | int main() { |
1 | $ gcc -g -c raw.c |
1 | ...... |
- 内存地址12的机器码,把0x2添加到
rbp-0x4对应的内存地址 - 内存地址16的机器码,从
rbp-0x4这个内存地址里面读取,把值把写入到eax这个寄存器里面 - 必须保证:在内存地址16的指令读取
rbp-0x4里面的值之前,内存地址12的指令写入到rbp-0x4的操作已经完成 - 写 -> 读的依赖关系,一般称为数据依赖,即Data Dependency
- 简单理解:先写入,才能读
读 -> 写
1 | int main() { |
1 | $ gcc -g -c war.c |
1 | ...... |
- 内存地址15的指令,要把
eax寄存器里面的值读出来,再加到rbp-0x4的内存地址 - 内存地址18的指令,要更新
eax寄存器 - 如果内存地址18的
eax的写入先完成,在内存地址为15的代码里面取出eax才发生,程序就会出错
- 同样要保证对于
eax的先读后写的操作顺序
- 读 -> 写的依赖关系,一般称为反依赖,即Anti Dependency
- 简单理解:前一个读操作取出来的数据用于其它运算,后一个写操作就不能先执行完成
写 -> 写
1 | int main() { |
1 | $ gcc -g -c waw.c |
1 | ...... |
- 内存地址4的指令和内存地址b的指令,都是将对应的数据写入到
rbp-0x4的内存地址里面 - 必须保证:内存地址4的指令的写入,在内存地址b的指令的写入之前完成
- 写 -> 写的依赖关系,一般称为输出依赖,即Output Dependency
- 简单理解:覆盖写
解决方案 – 流水线停顿
- 除了读 -> 读,对于同一个寄存器或者内存地址的操作,都有明确强制的顺序要求
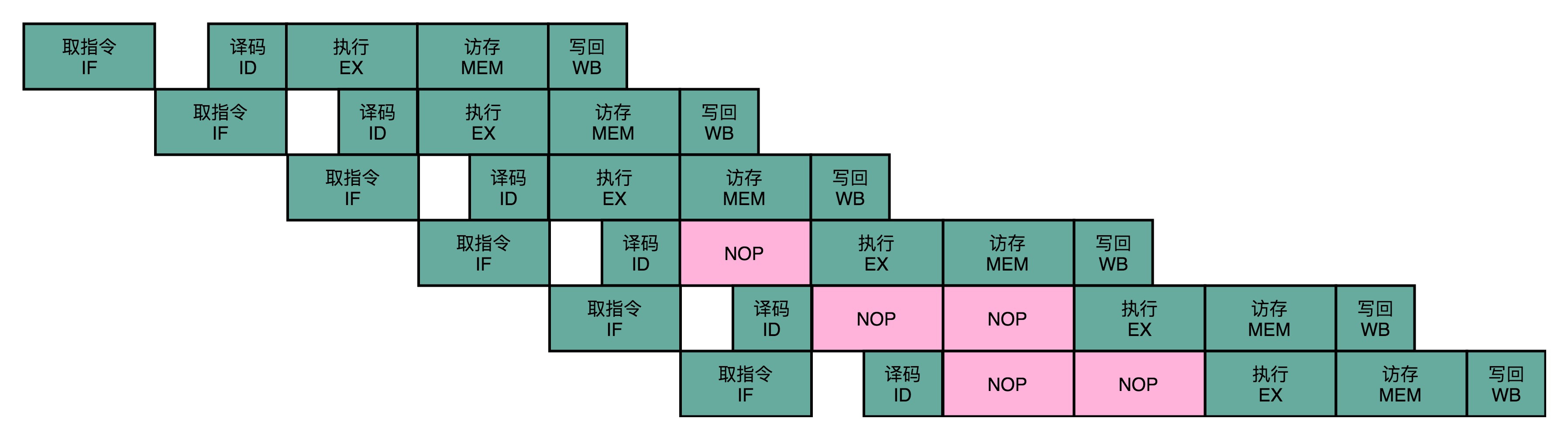
- 解决数据冒险的简单方案:流水线停顿(Pipeline Stall)、别称:流水线冒泡(Pipeline Bubbling)
- 这是一种以牺牲CPU性能为代价的方案,在最坏的情况下,流水线架构的CPU会退化成单指令周期的CPU!!
- 在进行指令译码的时候,会拿到对应指令所需要访问的寄存器和内存地址
- 此时能判断这个指令是否会触发数据冒险,如果会触发数据冒险,可以决定让整个流水线停顿一个或多个周期
- 时钟信号会不停地在0和1之间自动切换,并没有办法真的停顿下来
- 在实践过程中,并不是让流水线停下来,而是在执行后面的操作步骤前插入一个NOP(No Option)操作
- 好像在一个水管里面,进了一个空气泡,因此也叫流水线冒泡
操作数前推
流水线对齐
五级流水线
取指令(IF) -> 指令译码(ID) -> 指令执行(EX) -> 内存访问(MEM) -> 数据写回(WB)
MIPS指令
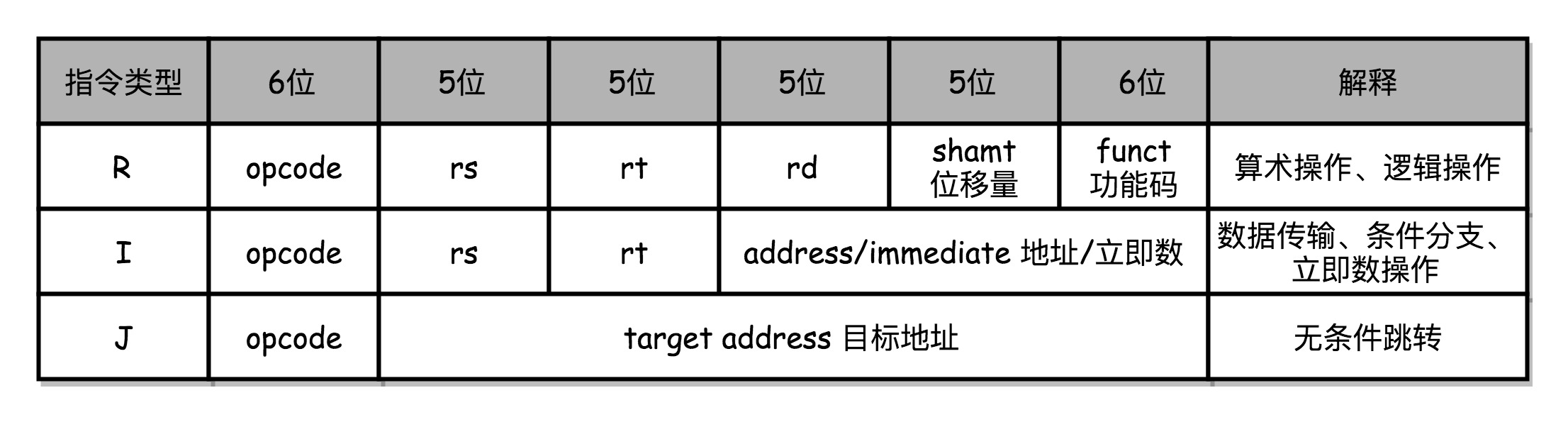
- 在MIPS的体系结构下,不同类型的指令,会在流水线的不同阶段进行不同的操作
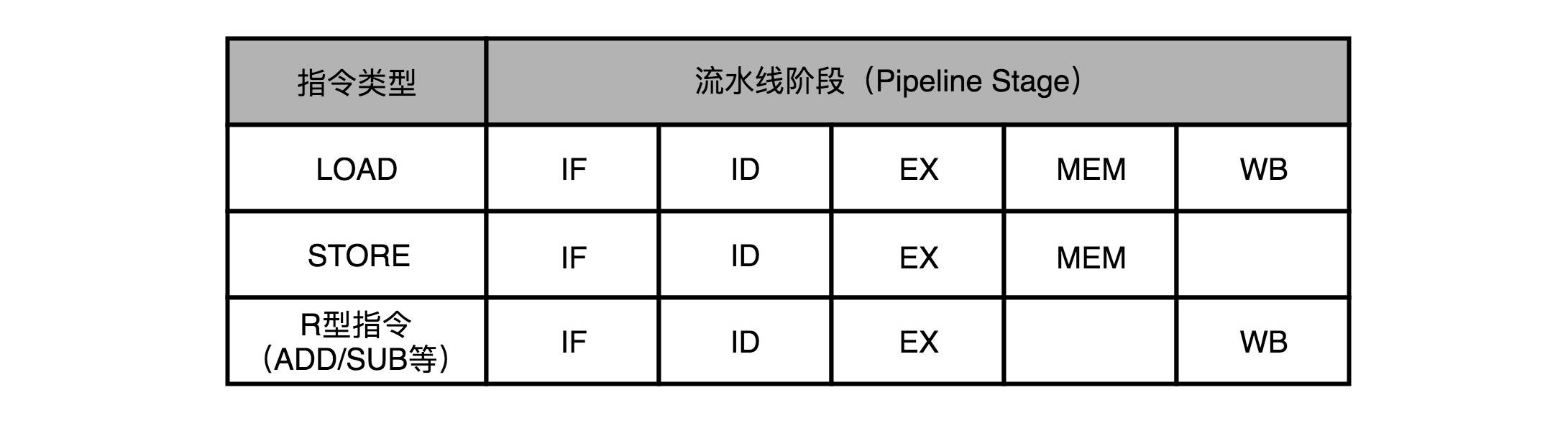
- LOAD:从内存里读取数据到寄存器
- 需要经历5个完整的流水线
- STORE:从寄存器往内存里写入数据
- 不需要有写回寄存器的操作,即没有数据写回(WB)的流水线阶段
- ADD、SUB
- 加减法指令,所有操作都在寄存器完成,没有实际的内存访问(MEM)操作
- 有些指令没有对应的流水线阶段,但不能跳过对应的阶段直接执行下一阶段
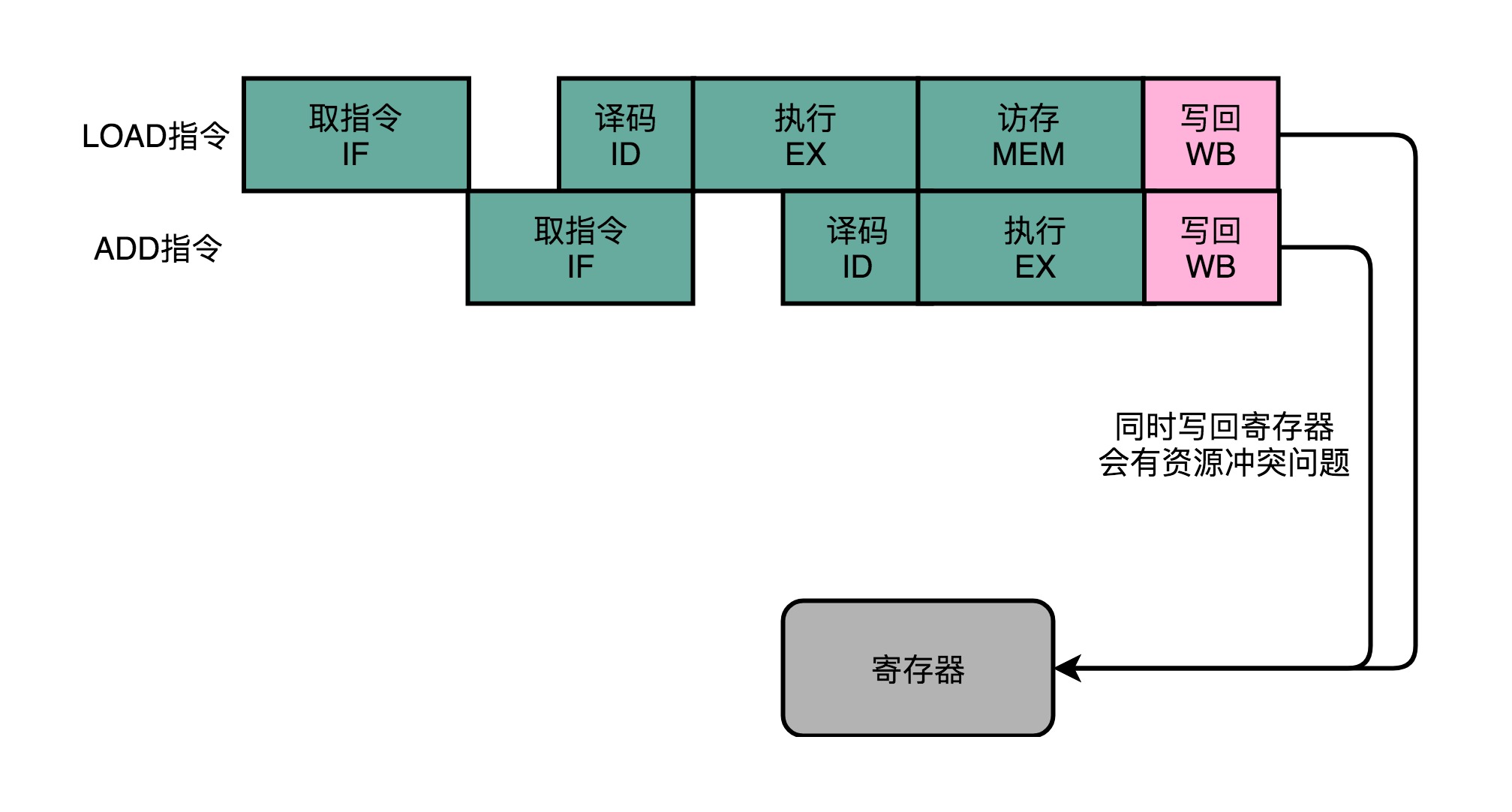
- 如果先后执行一条LOAD指令和一条ADD指令,LOAD指令的WB阶段和ADD指令的WB阶段,在同一个时钟周期发生
- 相当于触发了一个结构冒险事件,产生了资源竞争
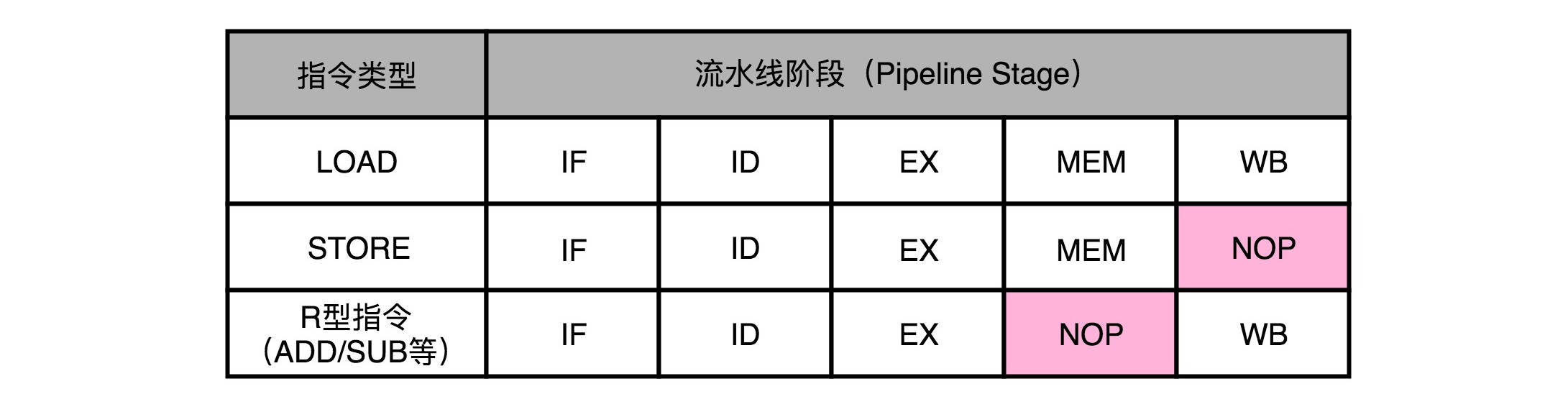
- 在实践中,各个指令不需要的阶段,不会直接跳过,而是会运行一次NOP操作
操作数前推
- 通过NOP操作进行对齐,在流水线里,就不会遇到资源竞争产生的结构冒险问题
- NOP操作,即流水线停顿插入的对应操作
- 插入过多的NOP操作,意味着CPU空转增多
1 | // s1 s2 t0都是寄存器 |
- 后一条add指令,依赖寄存器t0的值,而t0里面的值,又来自于前一条add指令的计算结果
- 因此后一条add指令,需要等待前一条add指令的数据写回(WB)阶段完成之后才能执行
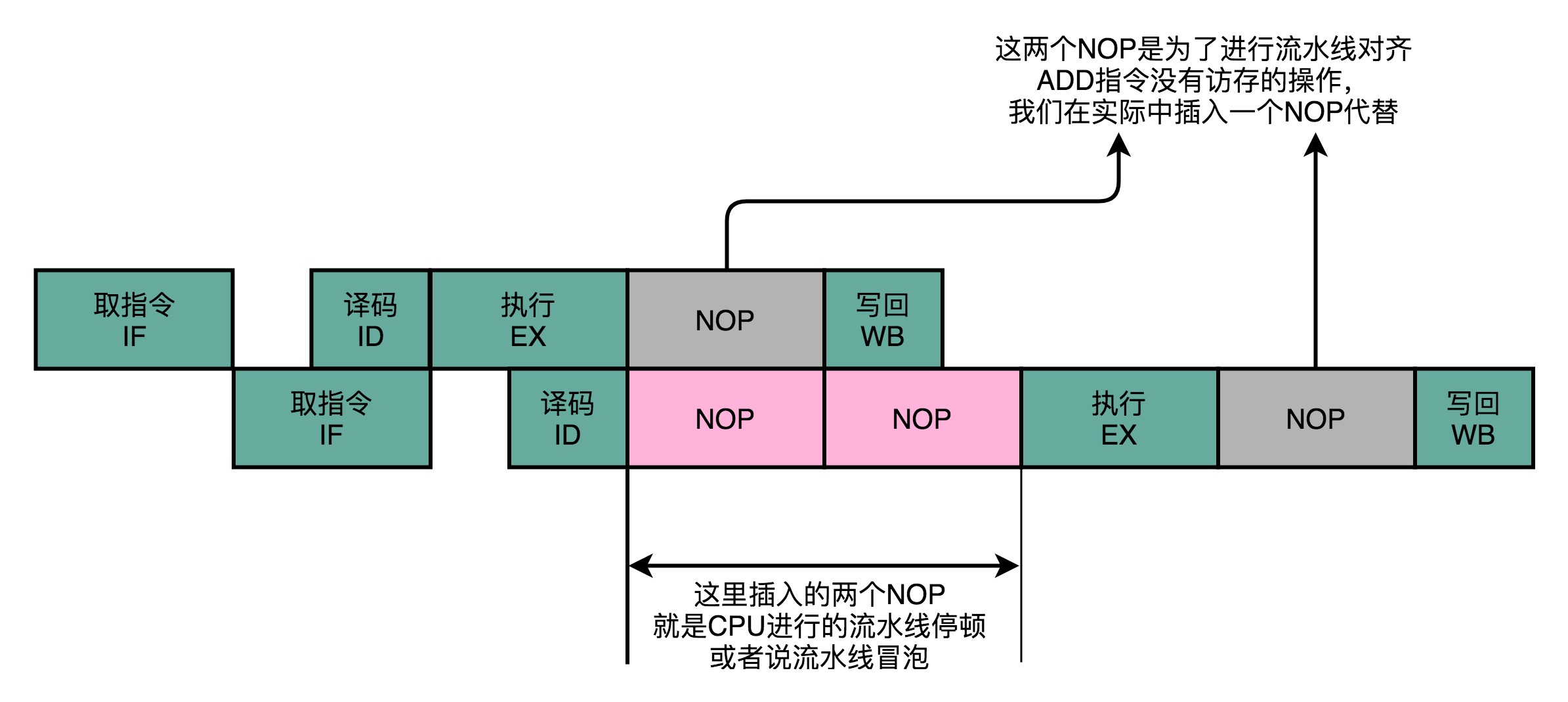
- 这是一个数据冒险:数据依赖类型(写 -> 读),上面的方案是通过流水线停顿来解决这个问题
- 要在第二条指令的译码阶段之后,插入对应的NOP指令,直到前一条指令的数据写回完成之后,才能继续执行
- 这虽然解决了数据冒险的问题,但也浪费了两个时钟周期
- 第二条指令的执行,未必需要等待第一条指令写回完成才能进行
- 如果能够把第一条指令的执行结果作为输入直接传输到第二条指令的执行阶段
- 那第二条指令就不用再从寄存器里面,把数据再单独读取出来才能执行代码
- 可以在第一条指令的执行(EX)阶段完成之后,直接将结果数据传输到下一条指令的ALU
- 这样,下一条指令不再需要再插入两个NOP阶段,就可以正常走到执行阶段
- 上面的方案就是操作数前推(Operand Forwarding)、操作数旁路(Operand Bypassing)
- Forwarding:逻辑含义,第一条指令的执行结果作为输入直接转发给第二条指令的ALU
- Bypassing:硬件含义,为了实现Forwarding,在CPU的硬件层面,需要单独拉出一根信号传输的线路
- 使得ALU的计算结果能够重新回到ALU的输入
- 越过了写入寄存器,再从寄存器读出来的过程,可以节省两个时钟周期
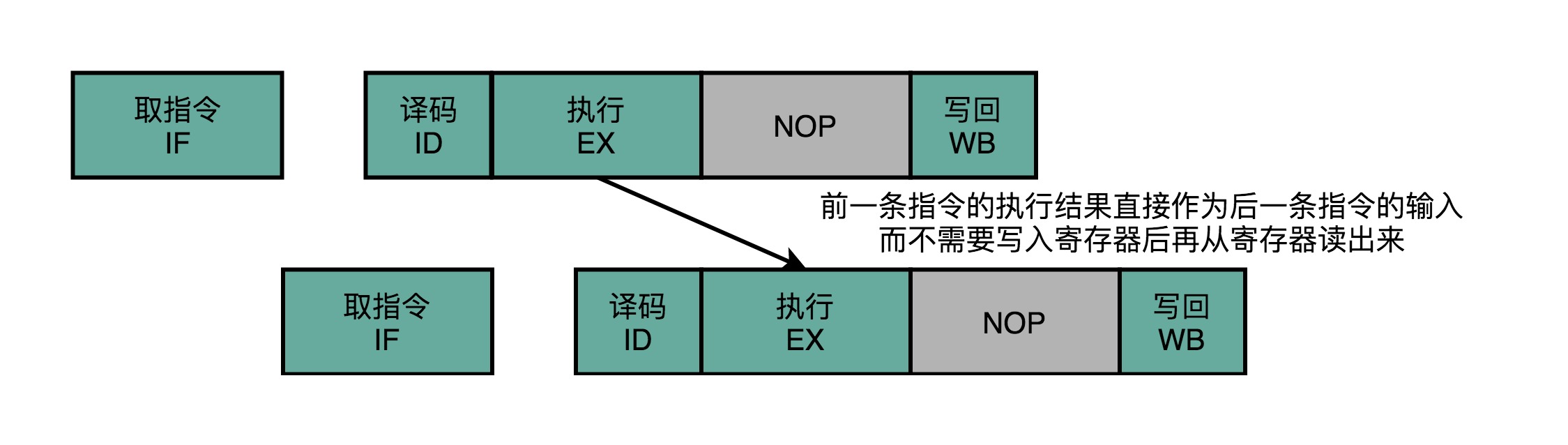
- 操作数前推的解决方案可以和流水线停顿一起使用
- 虽然可以把操作数转发到下一条指令,但下一条指令仍然需要停顿一个时钟周期
- 先执行一条LOAD指令,再执行ADD指令
- LOAD指令在访存阶段才能把数据读取出来,下一条指令的执行阶段,需要等上一阶段的访存阶段完成之后,才能进行
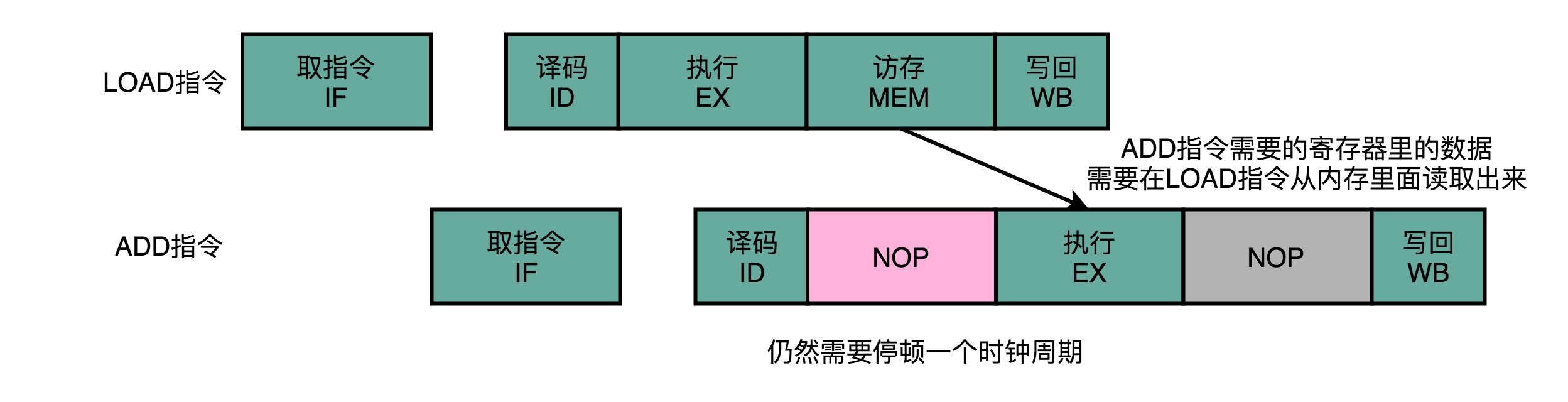
操作数前推并不能减少所有冒泡,只能去掉其中一部分,仍然需要通过插入一些NOP来解决数据冒险问题
乱序执行
- 结构冒险
- 限制来源:在同一时钟周期内,不同的指令的不同流水线阶段,要访问相同的硬件资源
- 解决方案:_增加资源_
- 数据冒险
- 限制来源:数据之间的各种依赖
- 解决方案:_流水线停顿、操作数前推_
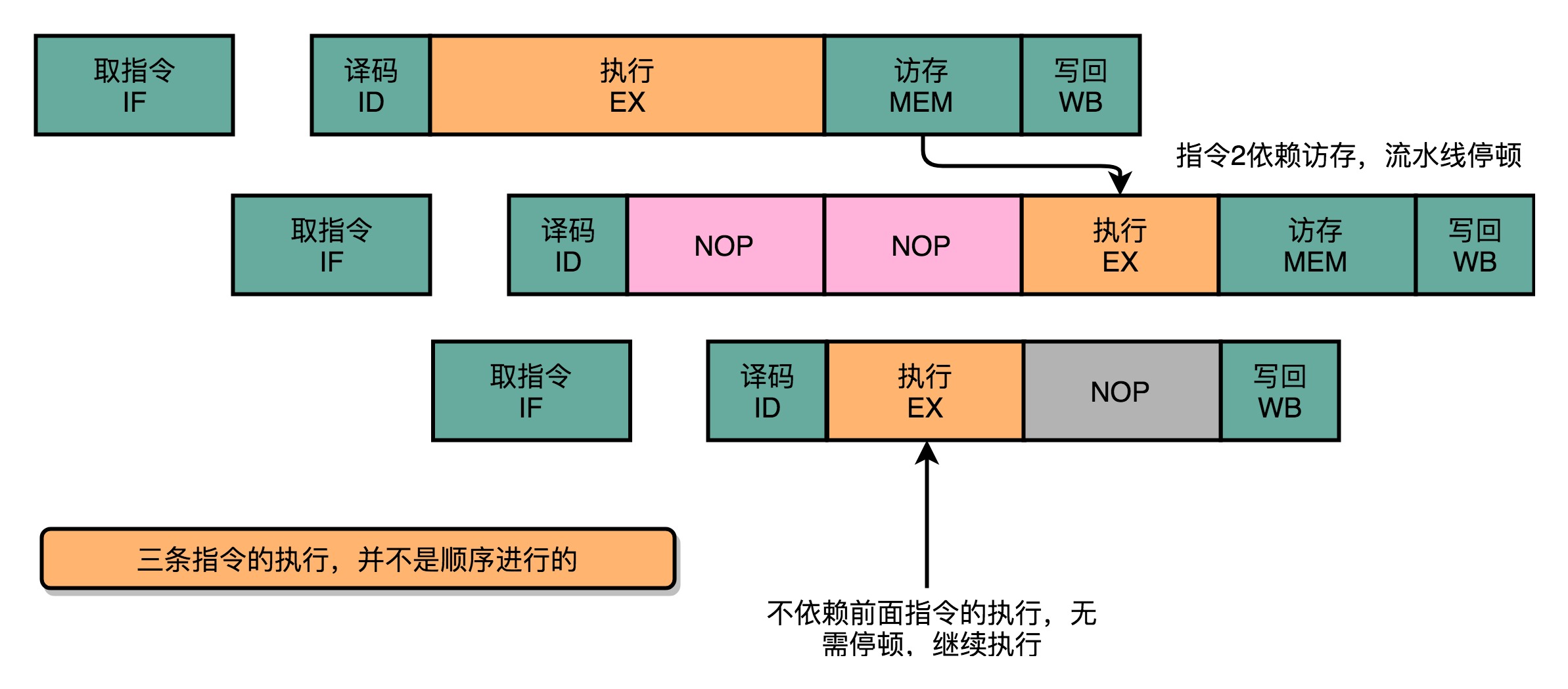
- 即便综合运用这三个技术,仍然会遇到不得不停下整个流水线,等待前面的指令完成的情况
填补空闲的NOP
- 无论是流水线停顿,还是操作数前推,只要前面指令的特定阶段还没有执行完成,后面的指令就会被阻塞
- 虽然代码生成的指令是顺序的,如果后面的指令不需要依赖前面指令的执行结果,完全可以不必等待前面的指令执行完成
- 这样的解决方案,在计算机组成里面,被称为乱序执行(Out-of-Order Execution,OoOE)
1 | a = b + c |
实现过程
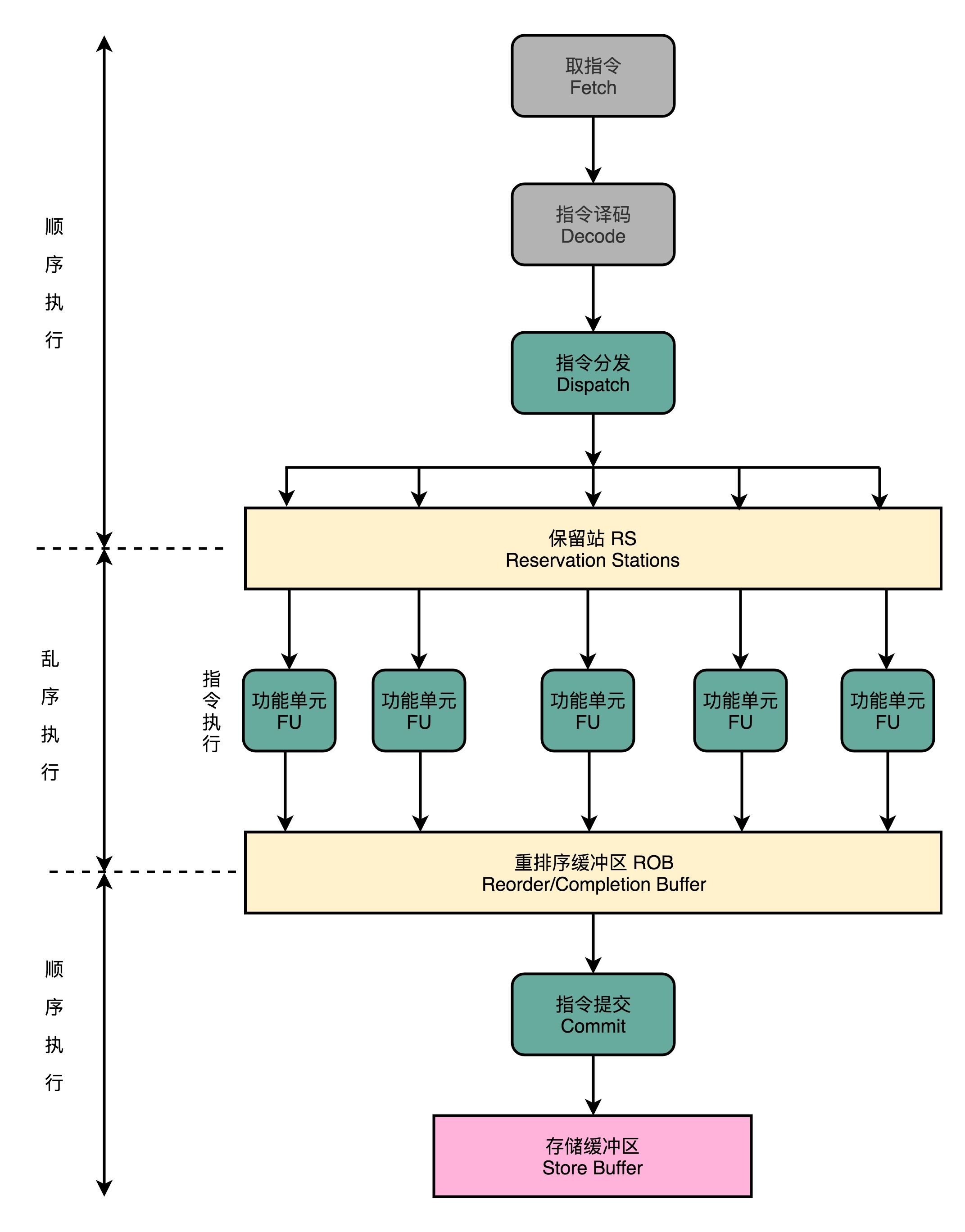
- 取指令和指令译码阶段,乱序执行的CPU和使用流水线架构的CPU是一样的,会一级一级顺序进行
- 指令译码完成后,CPU不会直接进行指令执行,而是进行一次指令分发
- 指令分发:把指令分发到保留站(Reservation Stations,RS)
- 类比:保留站 -> 火车站,指令 -> 火车
- 这些指令不会立即执行,而是等待它们所依赖的数据,传递给它们之后才会执行
- 类比:数据 -> 乘客,火车需要等乘客
- 一旦指令依赖的数据到齐了,指令就可以交到后面的功能单元(Function Unit,FU,本质是ALU)去执行了
- 很多功能单元是可以并行运行的,但不同的功能单元能够支持执行的指令是不相同的
- 指令执行阶段完成后,我们并不能立即把结果写回到寄存器里面,而是把结果先存放到重排序缓冲区(ReOrder Buffer,ROB)
- 在重排序缓冲区里,我们的CPU会按照取指令的顺序,对指令的计算结果重新排序
- 只有排在前面的指令都已经完成了,才会提交指令,完成整个指令的运算结果
- 实际的指令计算结果数据,并不是直接写到内存或者高速缓存,而是先写入存储缓冲区(Store Buffer)
- 最终才会写入内存和高速缓存
- 在乱序执行的情况下,只有CPU内部指令的执行层面,可能是乱序的
- 只要能在指令译码阶段正确地分析出指令之间的数据依赖关系,『乱序』就只会在相互没有影响的指令之间发生
- 相互没有影响 ≈ 不破坏数据依赖
- 即便指令的执行过程是乱序的,在指令的计算结果最终写入到寄存器和内存之前,依然会进行一次排序
- 以确保所有指令在外部看来仍然是有序完成的
回到样例
1 | a = b + c |
- d依赖于a的计算结果,不会在a的计算完成之前执行
x = y * z的指令同样会被分发到保留站,x所依赖的y和z的数据是准备好的,这里的乘法运算不会等待d的计算结果- 如果只有一个FU能够计算乘法,那么这个FU并不会因为d要等待a的计算结果而被限制,会先被拿来计算x
- x计算完成后,d也等来了a的计算结果,此时,唯一的乘法FU会去计算d的结果
- 在重排序缓冲区里,把对应的计算结果的提交顺序,仍然设置为a->d->x,但实际计算完成的顺序是x->a->d
- 整个过程中,计算乘法的FU没有被闲置,意味着CPU的吞吐率最大化
小结
- 整个乱序执行技术,类似于在指令的执行阶段提供了一个线程池,FU就是线程
- 指令不再是顺序执行的,而是根据线程池所拥有的资源,各个任务是否可以进行执行,进行动态调度
- 在执行完成之后,又重新把结果放在一个队列里面,按照指令的分发顺序重新排序
- 即使内部是『乱序』的,但外部看来,仍然是顺序执行的
- 乱序执行,极大地提高了CPU的运行效率
- 核心原因:CPU的运行速度比访问主内存的速度快很多
- 如果采用顺序执行的方式,很多时间会被浪费在前面指令等待获取内存数据
- 为此,CPU不得不加入NOP操作进行空转
- 乱序执行充分利用了较深流水线带来的并发性,可以充分利用CPU的性能
控制冒险
- 在结构冒险和数据冒险中,所有的流水线停顿都要从指令执行(EX)阶段开始
- 流水线的前两个阶段,即取指令(IF)和指令译码(ID),是不需要停顿的
- 基于一个基本假设:所有的指令代码都是顺序加载执行的
- 不成立的情况:在执行的代码中,遇到if/else条件分支,或者for/while循环
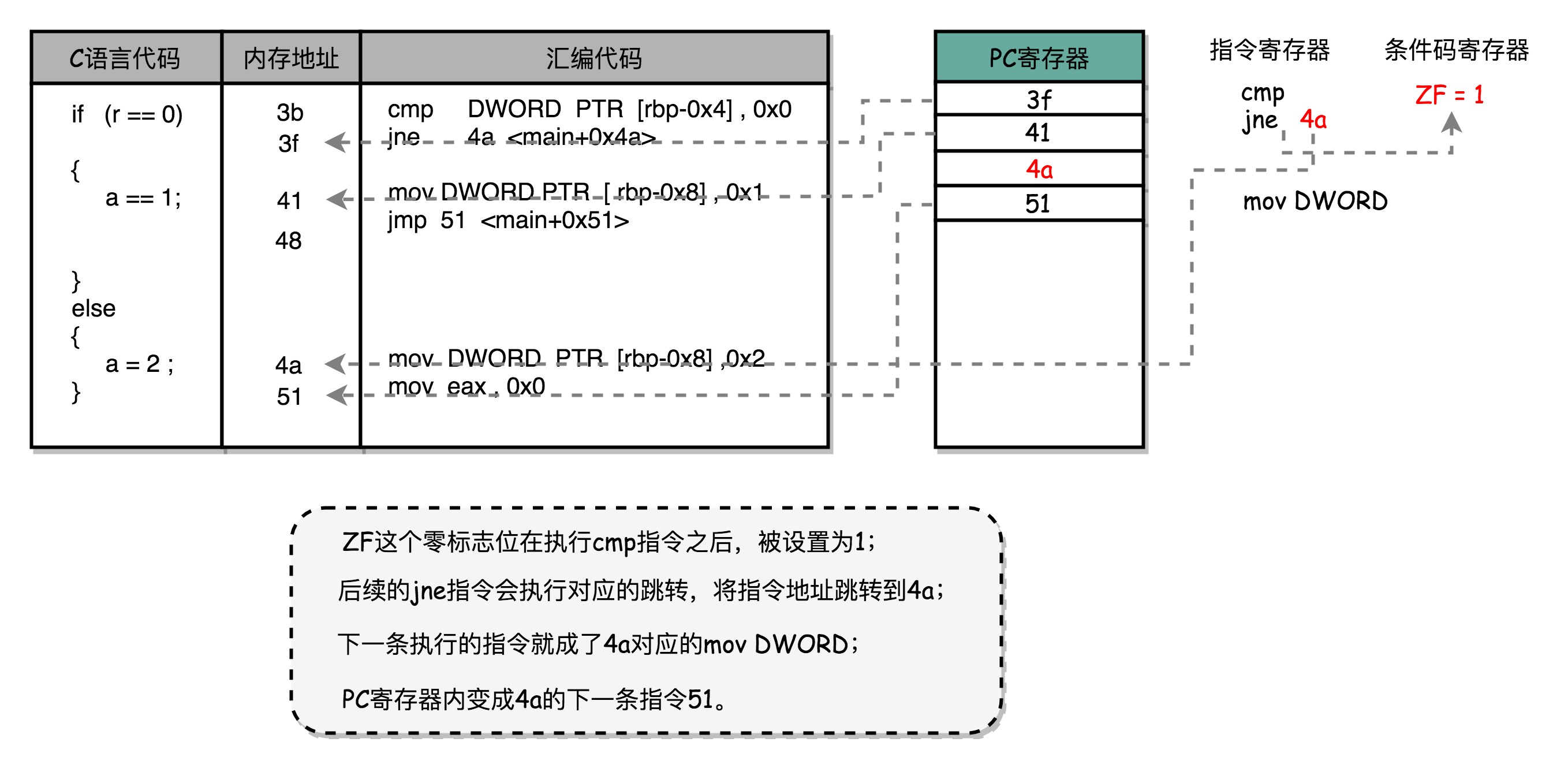
- jne指令发生的时候,CPU可能会跳转去执行其它指令
- jne后的那一条指令是否应该顺序加载执行,在流水线里进行取指令的时候,是无法知道的
- 要等到jne指令执行完成,更新了PC寄存器后,才能知道是否执行下一条指令,还是跳转到另一个内存地址,去取别的指令
- 为了确保能取到正确的指令,不得不进行等待延迟的情况,这就是控制冒险
缩短分支延迟
- 条件跳转指令实际上进行了两种电路操作:条件比较 + 实际跳转
- 条件跳转
- 根据指令的opcode,就能确认对应的条件码寄存器
- 实际跳转
- 把要跳转的地址写入到PC寄存器
- 无论是指令的opcode,还是对应的条件码寄存器,还是跳转的地址,都是在指令译码阶段就能获得的
- 对应的条件码比较电路,只需要简单的逻辑门电路即可,并不需要一个完整而复杂的ALU
- 可以将条件判断、地址跳转,都提前到指令译码阶段进行,而不需要放在指令执行阶段
- 在CPU里面设计对应的旁路,在指令译码阶段,就提供对应的判断比较的电路
- 这种方式,本质上和前面数据冒险的操作数前推的解决方案类似,就是在硬件电路层面,把一些计算结果更早地反馈到流水线中
- 这样反馈会变得更快,后面的指令需要等待的时间就会变短
- 只是改造硬件,并不能彻底解决问题
- 跳转指令的比较结果,仍然要在指令执行完成后才能知道
- 在流水线里,第一条指令进行指令译码的时钟周期里,其实就要取下一条指令了
- 但由于第一条指令还没开始指令执行阶段,此时并不知道比较的结果,自然也就无法准确知道要取哪一条指令了
分支预测
静态预测
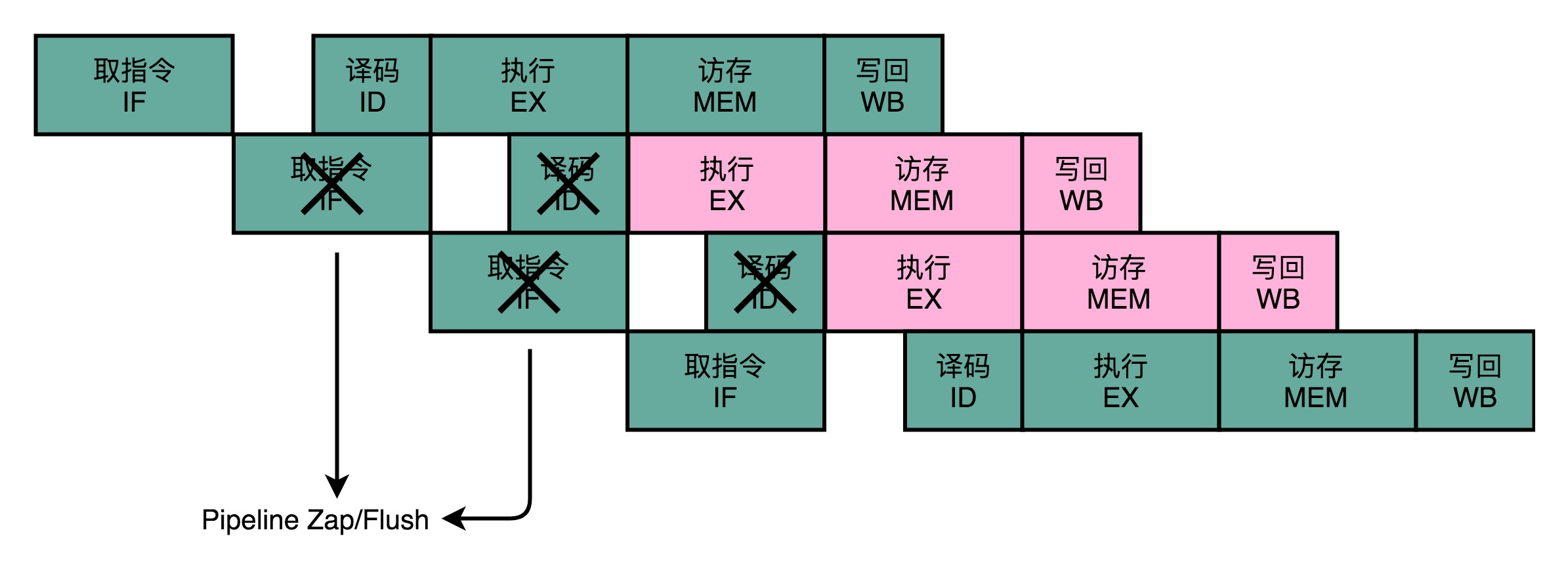
- CPU预测:条件跳转一定不发生
- 如果预测成功,可以节省本来需要停顿下来等待的时间
- 如果预测失败,需要丢弃后面已经取出指令且已经执行的部分
- 这个丢弃的操作,在流水线里面叫作Zap或者Flush
- CPU不仅要执行后面的指令,对于已经在流水线里面执行到一半的指令,还需要做对应的清除操作
- 例如清空已经使用的寄存器里面的数据,而这些清除操作,有一定的开销
动态预测
- 一级分支预测(One Level Branch Prediction)、1比特饱和计数(1-bit saturating counter)
- 用1Bit,记录当前分支的比较情况,直接用当前分支的比较情况来预测下一次分支的比较情况
- 状态机(State Machine)
- 如果状态机总共有4个状态,需要2个比特来记录对应的状态,这样的策略叫作2比特饱和计数或者双模态预测器
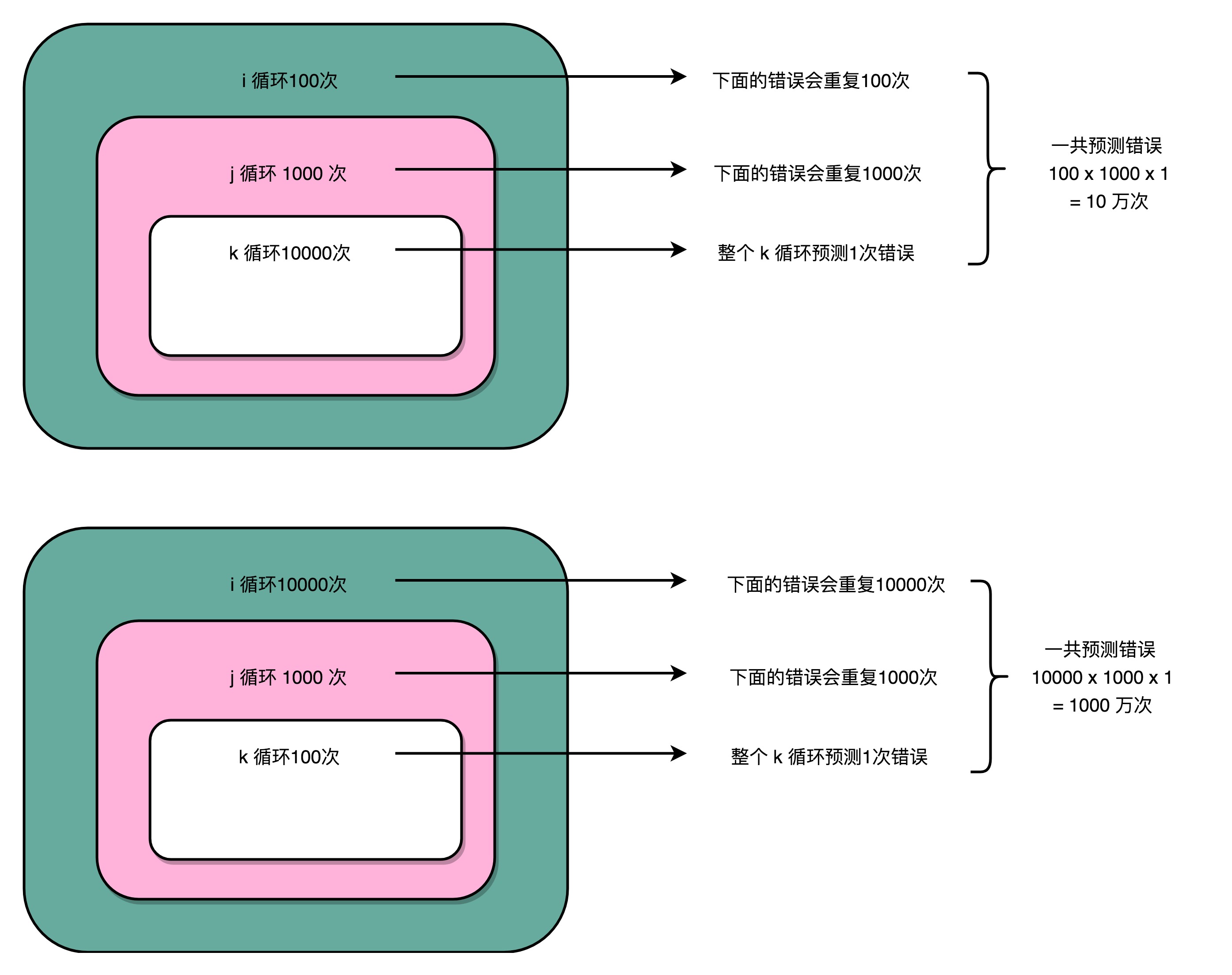
循环嵌套
1 | public class BranchPrediction { |
1 | Time spent is 4 |
- 循环其实也是利用cmp和jle指令来实现的
- 每一次循环都有一个cmp和jle指令
- 每一个jle都意味着要比较条件码寄存器的状态,来决定是顺序执行代码,还是要跳转到另外的地址
- 每一次循环发生的时候,都会有一次『分支』
- 分支预测策略最简单的方式:假设分支不发生
- 对应循环,就是循环始终进行下去
- 上面第一段代码分支预测错误的情况比较少
- 更多的计算机指令,在流水线里顺序运行下去了,而不是把运行到一半的指令丢弃掉,再去重新加载新的指令执行
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2020-01-11
计算机组成 -- 二进制编码
补码表示法 原码表示法 0011为3,1011为-3 缺点:0000和1000都表示为0 浪费 + 模凌两可 由此诞生了补码表示法,其实就是一个简单的翻转而已 用补码表示负数,使得整数的相加变得容易,不需要做任何特殊处理,当成普通的二进制相加即可 字符串 ASCII码类似一个字典,用8位二进制中的128个不同的数字,映射到128个不同的字符里 a在ASCII里面是第97个,二进制为0110 0001,对应的十六进制为0x61 字符串9用0011 1001来表示,字符串15用0011 0001和0011 0101来表示,占用更多的空间 因此存储数据的时候,要采用二进制序列化的形式, 而不是简单地把数据通过CSV或者JSON这样的文本格式存储来进行序列化 不管是整点数,还是浮点数,采用二进制序列化比存储文本能节省不少空间 字符集(Charset)和字符编码(Character Encoding) 字符集:字符的集合 Unicode是字符集,包含150种语言的14万个字符 字符编码:对于字符集里的这些字符,怎么用二进制表示出来的一个字典 Unicode可以用UTF-8、UTF-1...

2020-02-01
计算机组成 -- HDD
物理构造一块机械硬盘由盘面、磁头、悬臂三个部件组成 盘面 盘面(Disk Platter)是我们实际存储数据的盘片 盘面本身通常是用铝、玻璃或者陶瓷这样的材质去做成光滑盘片,然后在盘面上有一层磁性的涂层,数据就存储在磁性的涂层上 盘面中间有一个受电机控制的转轴(控制盘面去旋转),转速:RPM(Rotations Per Minute) 磁头 通过磁头(Drive Head),从盘面上读取数据,然后再通过电路信号传输给控制电路和接口,再到总线上 通常,一个盘面上会有两个磁头,分别是盘面的正反面,盘面在正反面都有对应的磁性涂层来存储数据 一块硬盘不会只有一个盘面,而且上下堆叠了很多个盘面,各个盘面之间是平行的,每个盘面的正反两面都有对应的磁头 悬臂 悬臂(Actutor Arm)链接在磁头上,并且在一定范围内去把磁头定位到盘面的某个特定磁道(Track)上 一个盘面通常是圆形的,由很多同心圆组成,每个同心圆都是一个磁道,每个磁道都有编号 随机读写 一个磁道,会分成多个扇区(Sector),上下平行的盘面的相同扇区,组成一个柱面(Cylinder) 数据读取的步骤 把盘面旋转到某个位置,在这个位...

2020-01-03
计算机组成 -- 提升性能
CPU的功耗12CPU time = 时钟周期时间(Clock Cycle Time) × CPU时钟周期数(CPU Cycles) = 时钟周期时间(Clock Cycle Time) × 指令数 × 每条指令的平均周期数(Cycles Per Instruction,CPI) 80年代开始,CPU硬件工程师主要着力提升CPU主频,到功耗是CPU的人体极限 CPU,一般被叫做超大规模集成电路,这些电路,实际上都是一个个晶体管组合而成的 CPU计算,实际上是让晶体管里面的『开关』不断地去打开或关闭,来组合完成各种运算和功能 如果要计算得快,有两个方向:增加密度(7nm制程)、提升主频,但这两者都会增加功耗,带来耗电和散热的问题 密度 -> 晶体管数量 主频 -> 开关频率 如果功耗增加太多,会导致CPU散热跟不上,此时就需要降低电压(低压版CPU) 1功耗 ≈ 1/2 × 负载电容 × 电压的平方 × 开关频率 × 晶体管数量 并行优化 – 阿姆达尔定律1优化后的执行时间 = 受优化影响的执行时间 / 加速倍数 + 不受影响的执行时间 其它 加速大概率事...

2020-02-04
计算机组成 -- DMP
DMP系统 DMP(Data Management Platform,数据管理平台) DMP系统广泛应用在互联网的广告定向,个性化推荐 DMP系统会通过处理海量的互联网访问数据以及机器学习算法,给用户标注上各种各样的标签 然后在做个性化推荐和广告投放的时候,再利用这些标签,去做实际的广告排序、推荐等工作 对于外部使用DMP的系统或者用户来说,可以简单地把DMP看成一个Key-Value数据库 对Key-Value系统的预期,以广告系统为案例 低响应时间 一般的广告系统留给整个广告投放决策的时间大概是10ms 因此对于访问DMP系统获取用户数据,预期的响应时间都在1ms以内 高可用性 DMP系统常用于广告系统,如果DMP系统出问题,意味着在不可用的时间内,整个广告收入是没有的 因此,对于可用性的追求是没有上限的 高并发 如果每天要响应100亿次广告请求,QPS大概是12K 海量数据 如果有10亿个Key,每个用户有500个标签,标签有对应的分数 标签和分数都用4 Bytes的整数来表示,总共大概需要4TB的数据 低成本 广告系统的收入通常用CPM(Cost Per Mille,千次曝光...

2020-01-25
计算机组成 -- 局部性原理
局部性原理 局部性原理:时间局部性(temporal locality)+空间局部性(spatial locality) 时间局部性:如果一个数据被访问了,在短时间内还会被再次访问 空间局部性:如果一个数据被访问了,和它相邻的数据也很快会被访问 亚马逊的商品假设:总共6亿商品,每件商品需要4MB的存储空间,总共需要2400TB的数据存储 存储成本 如果所有数据都放在内存里面,需要3600万美元 $3600 = \frac{2400TB}{1MB}×0.015$ 如果只在内存里存放前1%的热门商品,其余的放在HDD上,存储成本可以下降为45.6万美元,即原来成本的1.3% $45.5 ≈ 3600 \times 0.01+3600 \times 0.99 \times \frac{0.00004}{0.015}$ 时间局部性 时间局部性:LRU(Least Recently Used)缓存算法 热门商品被访问得多,就会始终被保存在内存里,而冷门商品被访问得少,就只存放在HDD硬盘上 越是热门的商品,越容易在内存中找到,能更好地利用内存的随机访问性能 假设日活为1亿,活跃用户每...

2020-01-20
计算机组成 -- 超线程 + SIMD
超线程 – 线程级并行Pentium 4 Pentium 4失败的原因:CPU的流水线级数太深 超长的流水线,使得之前很多解决冒险、提升并发的方案都用不上 解决冒险、提升并发的方案,本质上是一种指令级并行的技术方案,即CPU希望在同一个时间,去并行执行两条指令 但这两条指令,原本在代码里是有先后顺序的 无论是流水线架构、分支预测以及乱序执行,还是超标量和超长指令字 都是想通过在同一时间执行两条指令,来提升CPU的吞吐率 但在Pentium 4上,上面这些方法都可能因为流水线太深,而起不到效果 更深的流水线意味着同时在流水线里面的指令就很多,相互的依赖关系就多 因此,很多时候不得不把流水线停顿下来,插入很多NOP操作,来解决这些依赖带来的冒险问题 超线程 无论是多个CPU核心运行不同的程序,还是单个CPU核心里切换运行不同线程的任务 在同一时间点上,一个物理的CPU核心只会运行一个线程的指令,其实并没有做到真正的指令级并行 超线程的CPU,把一个物理层面的CPU核心,伪装成两个逻辑层面的CPU核心 这个CPU会在硬件层面增加很多电路,使得可以在一个CPU核心内部,维护两个不同线程的指...




