
计算机组成 -- 超线程 + SIMD
超线程 – 线程级并行
Pentium 4
- Pentium 4失败的原因:CPU的流水线级数太深
- 超长的流水线,使得之前很多解决冒险、提升并发的方案都用不上
- 解决冒险、提升并发的方案,本质上是一种指令级并行的技术方案,即CPU希望在同一个时间,去并行执行两条指令
- 但这两条指令,原本在代码里是有先后顺序的
- 无论是流水线架构、分支预测以及乱序执行,还是超标量和超长指令字
- 都是想通过在同一时间执行两条指令,来提升CPU的吞吐率
- 但在Pentium 4上,上面这些方法都可能因为流水线太深,而起不到效果
- 更深的流水线意味着同时在流水线里面的指令就很多,相互的依赖关系就多
- 因此,很多时候不得不把流水线停顿下来,插入很多NOP操作,来解决这些依赖带来的冒险问题
超线程
- 无论是多个CPU核心运行不同的程序,还是单个CPU核心里切换运行不同线程的任务
- 在同一时间点上,一个物理的CPU核心只会运行一个线程的指令,其实并没有做到真正的指令级并行
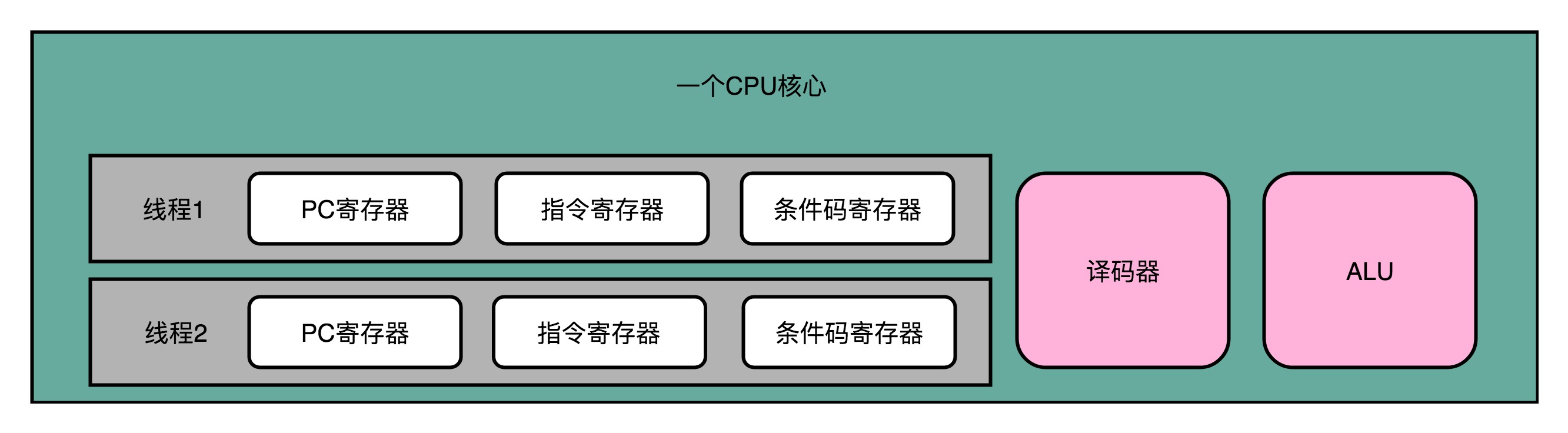
- 超线程的CPU,把一个物理层面的CPU核心,伪装成两个逻辑层面的CPU核心
- 这个CPU会在硬件层面增加很多电路,使得可以在一个CPU核心内部,维护两个不同线程的指令的状态信息
- 在一个物理CPU核心内部,会有双份的PC寄存器、指令寄存器、条件码寄存器
- 在外面看来,似乎有两个逻辑层面的CPU在同时运行
- 因此,超线程技术也被叫为同时多线程(Simultaneous Multi-Threading,SMT)技术
- 但CPU的其它功能组件,没有提供双份,无论是指令译码器还是ALU,一个物理CPU核心仍然只有一份
- 因为超线程并不是真的去同时运行两个指令
- 超线程的目的:在线程A的指令在流水线停顿的时候,让线程B去执行指令,此时CPU的指令译码器和ALU是空闲的
- 线程B没有对线程A里面的指令有关联和依赖
- CPU通过很小的代价,就能实现同时运行多个线程的效果
- 只需要在CPU核心增加10%左右的逻辑功能,增加可以忽略不计的晶体管数量
- 超线程并没有增加功能单元(ALU),所以超线程只在特定的应用场景下效果比较好
- 一般是各个线程等待时间比较长的应用场景
- 例如需要应对很多请求的数据库应用,就比较适合使用超线程,各个指令都要等待访问内存数据,但并不需要做太多计算
SIMD – 指令级并行
- SIMD:Single Instruction Multiple Data,单指令多数据流,支持SIMD的指令集:MMX、SSE
- 两段代码
- 通过循环的方式,给list里面的每一个数加1
- 实现相同的功能,直接调用NumPy库的add方法
- 性能差异:32.72
- 原因:NumPy直接用了SIMD指令,能够并行进行向量的操作
- 通过循环来一步一步计算的算法,称为SISD,单指令单数据
- 如果是多核CPU,可以同时处理多个指令的方式称为MIMD,多指令多数据
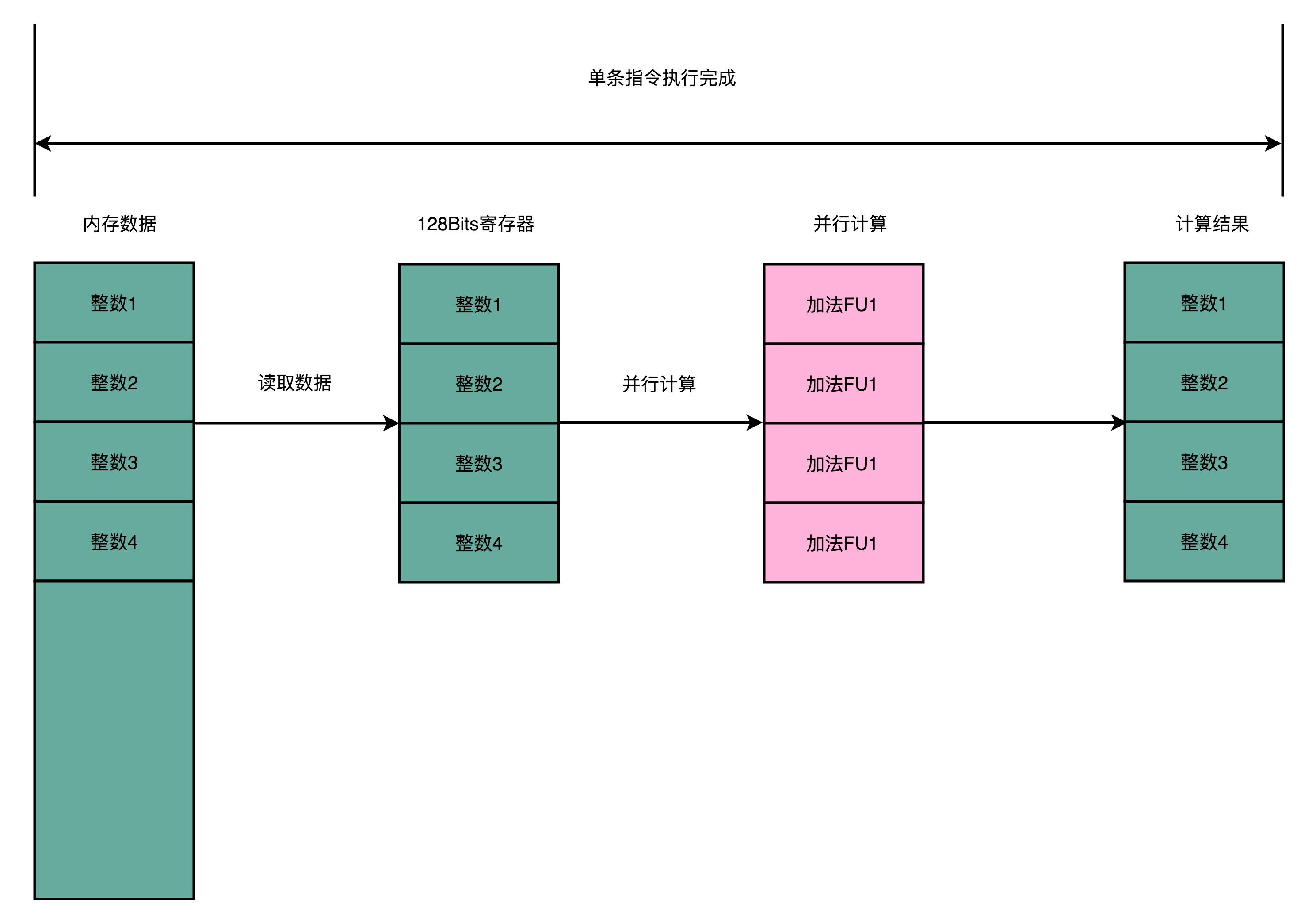
- SIMD在获取数据和执行指令的时候,都做了并行
- 从内存读取数据的时候,SIMD一次性读取多个数据
- 下面程序数组里面的元素是integer,需要4Bytes的内存空间
- Intel在引入SSE指令集的时候,在CPU里添加了8个128Bits的寄存器
- 128Bits ≈ 16Bytes,即一个寄存器可以一次性加载4个整数
- 比循环分别读取4次对应的数据,能节省不少时间
- 在数据读取之后,到了指令的执行层面,SIMD也是可以并行执行的
- 4个整数各自加1,互相之间完全没有依赖,即不需要处理冒险问题
- 只要CPU里有足够的功能单元,能够同时进行这些计算,那这个加法就是4路同时并行的
- 因此那些在计算层面存在大量『数据并行』的计算中,使用SIMD能够很好地提升性能
- 实践:向量运算(同一向量的不同维度之间的计算是相互独立的)、矩阵运算
- 图片、视频、音频的处理
- 机器学习算法的计算
- 从内存读取数据的时候,SIMD一次性读取多个数据
- 基于SIMD的向量计算指令,是在Intel发布Pentium处理器的时候引入的指令集
- 当时的指令集叫作MMX(Matrix Math eXtensions,矩阵数学扩展)
- Pentium处理器,第一个有能力进行多媒体处理的CPU
1 | $ python |
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2020-01-31
计算机组成 -- IO_WAIT
IO性能 硬盘厂商的性能报告:响应时间(Response Time)、数据传输率(Data Transfer Rate) HDD硬盘一般用的是SATA 3.0的接口;SSD硬盘通常会用两种接口,一部分用SATA 3.0接口,另一部分用PCI Express接口 数据传输率 SATA 3.0接口的带宽是6Gb/s ≈ 768MB/s 日常用的HDD硬盘的数据传输率,一般在200MB/s SATA 3.0接口的SSD的数据传输率差不多是500MB/s PCI Express接口的SSD,读取时的数据传输率能到2GB/s,写入时的数据传输率也能有1.2GB/s,大致是HDD的10倍 响应时间 程序发起一个硬盘的读取或写入请求,直到请求返回的时间 SSD的响应时间大致在几十微秒这个级别,HDD的响应时间大致在十几毫秒这个级别,相差几十倍到几百倍 IOPS 每秒读写的次数,相对于响应时间,更关注IOPS这个性能指标 在顺序读写和随机读写的情况下,硬盘的性能是完全不同的 IOPS和DTR才是IO性能的核心指标 在实际的应用开发当中,对于数据...

2020-01-04
计算机组成 -- 指令
CPU + 计算机指令 硬件的角度 CPU是一个超大规模集成电路,通过电路实现了加法、乘法乃至各种各样的处理逻辑 软件工程师的角度 CPU就是一个执行各种计算机指令的逻辑机器 计算机指令是一门CPU能听懂的语言,也称为机器语言 不同的CPU能够听懂的语言不太一样,两种CPU各自支持的语言,就是两组不同的计算机指令集 计算机程序平时是存储在存储器中,这种程序指令存储在存储器里面的计算机,叫作存储程序型计算机 代码 -> 机器码(编译 -> 汇编)1234567// test.cint main(){ int a = 1; int b = 2; a = a + b;} 编译(Compile)成汇编代码:把整个程序翻译成一个汇编语言(ASM,Assembly Language)的程序 汇编:针对汇编代码,用汇编器(Assembler)翻译成机器码(Machine Code) 机器码由0和1组成的机器语言表示,一串串的16进制数字,就是CPU能够真正认识的计算机指令 汇编代码 + 机器码12345678910$ gcc --help-c ...

2020-01-08
计算机组成 -- ELF + 静态链接
代码拆分源代码add_lib.c12345// add_lib.cint add(int a, int b){ return a+b;} link_example.c1234567891011// link_example.c#include <stdio.h>int main(){ int a = 10; int b = 5; int c = add(a, b); printf("c=%d\n", c);} gcc + objdump123$ gcc -g -c add_lib.c link_example.c$ objdump -d -M intel -S add_lib.o$ objdump -d -M intel -S link_example.o add_lib.o1234567891011121314151617add_lib.o: 文件格式 elf64-x86-64Disassembly of section .text:0000000000000000 <add>...

2020-01-27
计算机组成 -- MESI协议
缓存一致性问题 iPhone降价了,要把iPhone最新的价格更新到主内存里,为了性能问题,采用写回策略 先把数据写入到L2 Cache里,然后把Cache Block标记为脏的 此时数据其实没有被同步到L3 Cache或主内存里 1号核心希望在这个Cache Block要被交换出去的时候,数据才写入到主内存里 此时2号核心尝试从内存里读取iPhone的价格,就会读取一个错误的价格 缓存一致性问题:1号核心和2号核心的缓存,此时是不一致的 同步机制能够达到的目标 写传播(Write Propagation) 在一个CPU核心里面的Cache数据更新,必须能够传播到其他对应节点的Cache Line里 事务串行化(Transaction Serialization) 在一个CPU核心里面的读取和写入,在其他节点看起来,顺序是一样的 事务串行化 1号核心先把iPhone的价格改成5000,差不多时间,2号核心把iPhone的价格改成6000,这两个修改会传播到3号核心和4号核心 3号核心先收到2号核心的写传播,再收到1号核心的写传播;4号核心刚好相反 虽然写传播做到了,...

2020-01-21
计算机组成 -- 异常
异常 异常是一个硬件和软件组合在一起的处理过程 异常的发生和捕捉,是在硬件层面完成的 异常的处理,是在软件层面完成的 计算机会为每一种可能发生的异常,分配一个异常代码(Exception Number),别称中断向量(Interrupt Vector) 异常发生的时候,通常是CPU检测到一个特殊的信号 在组成原理里面,一般叫作发生了一个事件(Event),CPU在检测到事件的时候,就已经拿到了对应的异常代码 异常代码 IO发出的信号的异常代码,是由操作系统来分配,即由软件来设定 像加法溢出这样的异常代码,是由CPU预分配的,即由硬件来设定 拿到异常代码后,CPU会触发异常处理流程 计算机在内存里,会保留一个异常表(Exception Table),别称中断向量表(Interrupt Vector Table) 存放的是不同的异常代码对应的异常处理程序所在的地址 CPU拿到异常代码后,会先把当前程序的执行现场(CPU当前运行程序用到的所有寄存器),保存到程序栈里面 然后根据异常代码查询,找到对应的异常处理程序,最后把后续指令执行的指挥权,交给这个异常处理程序 异常可以由硬件触发,也可以由软...

2020-02-05
计算机组成 -- Disruptor
缓存行填充缓存行大小1234567$ sysctl -a | grep -E 'cacheline|cachesize'hw.cachesize: 17179869184 32768 262144 6291456 0 0 0 0 0 0hw.cachelinesize: 64hw.l1icachesize: 32768hw.l1dcachesize: 32768hw.l2cachesize: 262144hw.l3cachesize: 6291456 RingBufferPad1234abstract class RingBufferPad{ protected long p1, p2, p3, p4, p5, p6, p7;} 变量p1~p7本身没有实际意义,只能用于缓存行填充,为了尽可能地用上CPU Cache 访问CPU里的L1 Cache或者L2 Cache,访问延时是内存的1/15乃至1/100(内存的访问速度,是远远慢于CPU Cache的) 因此,为了追求极限性能,需要尽可能地从CPU Cache里面读取数据 C...




