
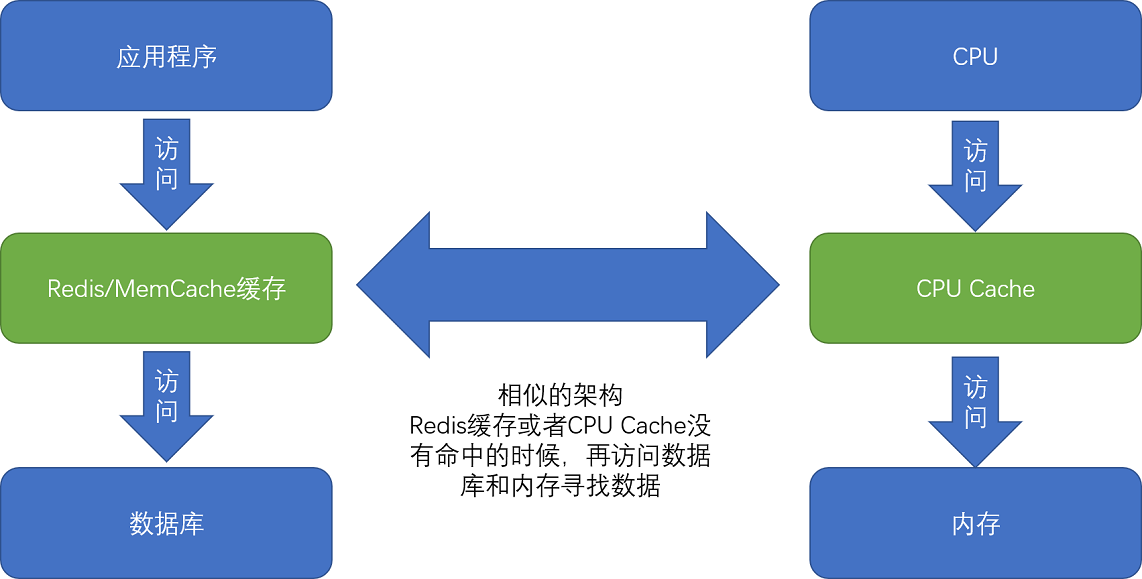
计算机组成 -- 高速缓存
缓存行
1 | $ sysctl -a | grep -E 'cacheline|cachesize' |
1 | public static void f1() { |
高速缓存
- 按照摩尔定律,CPU(寄存器)的访问速度每18个月会翻一翻,相当于每年增长60%
- 虽然内存的访问速度也在不断增长,但远没有那么快,每年只增长**7%**左右
- 两个增长速度的差异,使得CPU访问性能和内存访问性能的差异不断拉大,至今,大概是120倍的差异
- 为了弥补两者之间的性能差异,在现代CPU中引入了高速缓存(L1 Cache、L2 Cache、L3 Cache)
- 内存中的指令和数据会被加载到L1~L3 Cache中,而不是直接由CPU访问内存去读取
- 在95%的情况下,CPU都只需要访问L1~L3 Cache,从里面读取指令和数据,而无需访问内存
- CPU Cache指的是由SRAM组成的物理芯片
- 运行程序的时间主要花在了将对应的数据从内存中读取出来,加载到CPU Cache里,该过程是按照Cache Line来读取的
- 日常使用的Intel服务器或者PC,Cache Line的大小通常是_64字节_
f2()每隔16个整型数计算一次,16个整型数正好是64个字节f1()和f2()需要把同样数量的Cache Line数据从内存中读取到CPU Cache中,最终两个程序花费的时间差不多
类比
- 现代CPU进行数据读取的时候,无论数据是否已经存储在Cache中,CPU始终会首先访问Cache
- 只有当CPU在Cache中找不到数据的时候,才会去访问内存,并将读取到的数据写入Cache中
- 在各类基准测试和实际应用场景中,CPU Cache的命中率通常能到达**95%**以上
Direct Mapped Cache
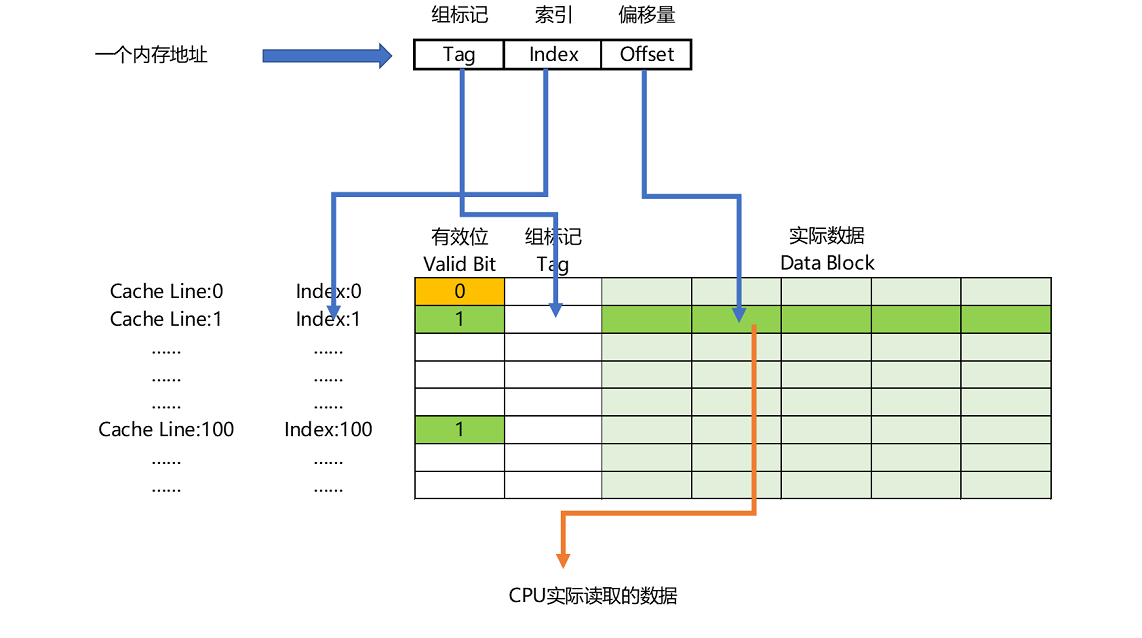
- 直接映射Cache策略:确保任何一个内存块的地址,始终映射(mod)到一个固定的CPU Cache Line地址
- 假设主内存被分成32块(0~31),一共有8个缓存块,要访问第21号内存块,如果21号内存块在缓存块中,一定在5号缓存块
- 在实际计算中,通常会把缓存块的数量设置成2的N次方,在计算取模的时候,可以直接取内存地址的低N位
- 对应的缓存块中,会存储一个组标记(Tag),缓存块本身的地址表示访问内存地址的低N位,对应的组标记记录剩余的高位即可
- 缓存块中还有两个数据,一个是从主内存中加载来的实际存放的数据(Data Block),另一个是有效位(Valid Bit)
- 有效位用来标记对应的缓存块中的数据是否有效
- 如果有效位为0,无论其中的组标记和Cache Line里的数据内容是什么,CPU都会直接访问内存,重新加载数据
- CPU在读取数据的时候,并不是要读取一整个Data Block,而是读取一个所需要的数据片段(叫作CPU里面的一个字(Word))
- 具体是哪个字,由这个字在整个Data Block里面的位置来决定,该位置称为偏移量(Offset)
- 一个内存的访问地址,最终包括
- Tag:高位代表的组标记
- Index:低位代表的索引
- Offset:在对应的Data Block中定位对应字的位置偏移量
- 如果内存中的数据已经在CPU Cache中,那对一个内存地址的访问,会经历下面4个步骤
- 根据内存地址的低位,计算在Cache中的索引
- 判断有效位,确认Cache中的数据是否有效
- 对比内存地址的高位和Cache中的组标记
- 确认Cache中的数据就是要访问的内存数据,从Cache Line中读取对应的Data Block
- 根据内存地址的Offset位,从Data Block中,读取希望取到的字
- 如果2、3步骤失效,CPU会访问内存,并把对应的Block Data更新到Cache Line中,同时更新对应的有效位和组标记的数据
迭代性能对比
1 | public static void iterateByRow(int rows, int cols) { |
1 | iterateByRow : 30 |
volatile
- 常见误解
- 把
volatile当成一种锁机制,等同于sychronized,不同线程访问特定变量都会去加锁 - 把
volatile当成一个原子化的操作机制,认为加了volatile之后,对于一个变量的自增操作就会变成原子性的
- 把
volatile关键字最核心的知识点,要关系到Java内存模型上- Java内存模型(JMM)是Java虚拟机这个进程级虚拟机里的一个内存模型
- JMM和计算机组成里的CPU、高速缓存和主内存组合在一起的硬件体系非常相似
1 | public class VolatileTest { |
1 | Incrementing COUNTER to : 1 |
1 | // 去掉volatile关键字 |
1 | # ChangeListener不再工作,在ChangeListener眼里,觉得COUNTER的值一直为0 |
1 | // ChangeListener不再忙等待,稍微sleep 5ms |
1 | # "恢复正常" |
volatile关键字的含义:确保对于volatile变量的读取和写入,都一定会同步到主内存里,而不是从Cache里面读取- 样例1
- 使用
volatile关键字,所有数据的读和写都是来自主内存,ChangeMaker和ChangeListener看到的COUNTER是一样的
- 使用
- 样例2
- 去掉
volatile关键字,ChangeListener一直忙等待循环 - 尝试不停地获取COUNTER的值,这样就会从当前线程的『Cache』里面获取
- 于是,这个线程没有时间从主内存里同步更新后的COUNTER值,一直卡死在COUNTER=0的死循环上
- 去掉
- 样例3
Thread.sleep(5)给了这个线程喘息的机会,就有机会把最新的数据从主内存同步到自己的高速缓存中
CPU vs JMM
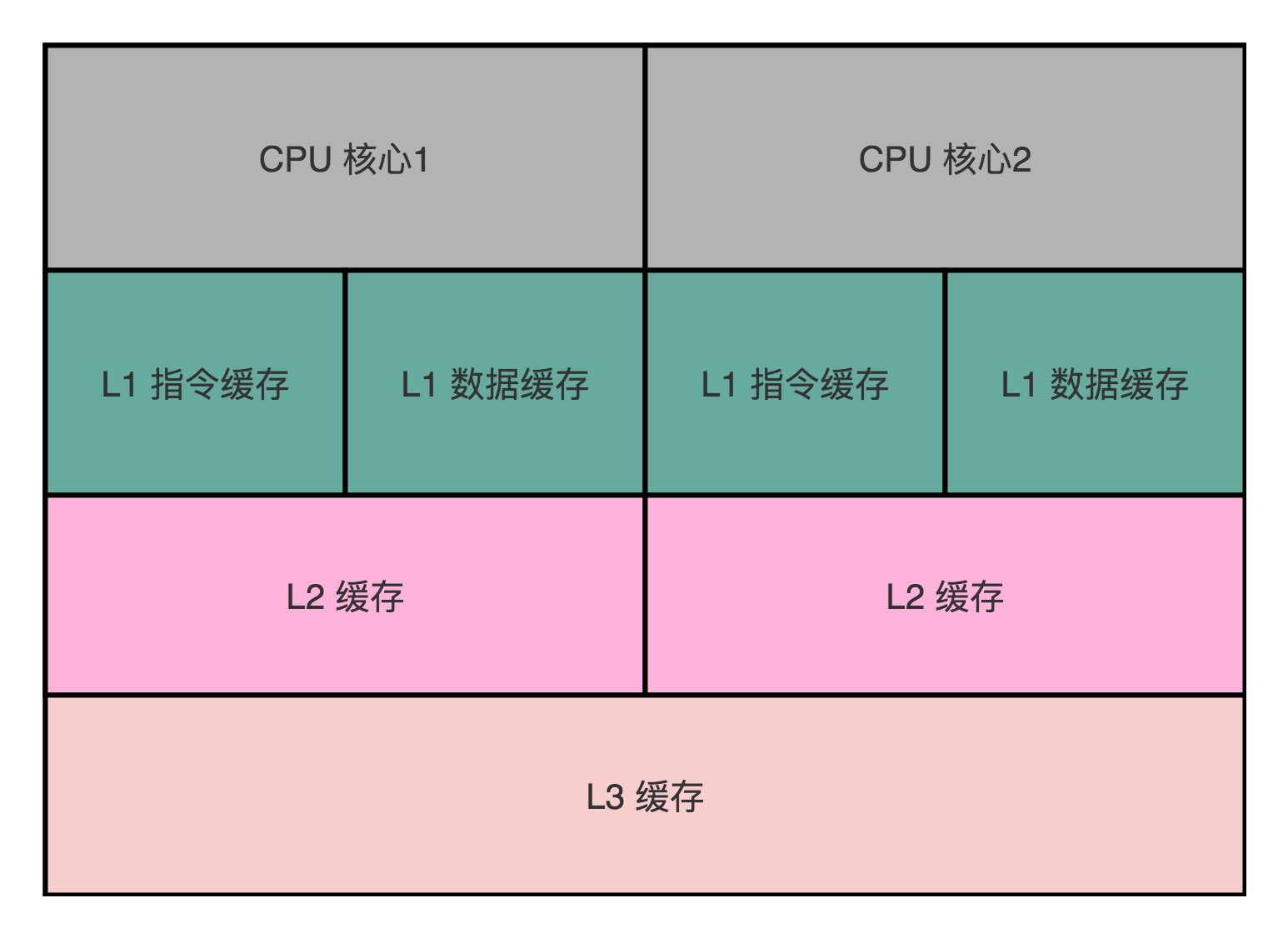
- 现在的Intel CPU,通常都是多核的,每个CPU核里面,都有独立的L1、L2 Cache,然后有多个CPU核共用的L3 Cache、主内存
- 在Java内存模型里面,每个线程都有独立的线程栈
- 线程在读取COUNTER的数据的时候,其实是从本地的线程栈的Cache副本里面读取数据,而不是从主内存里面读取数据
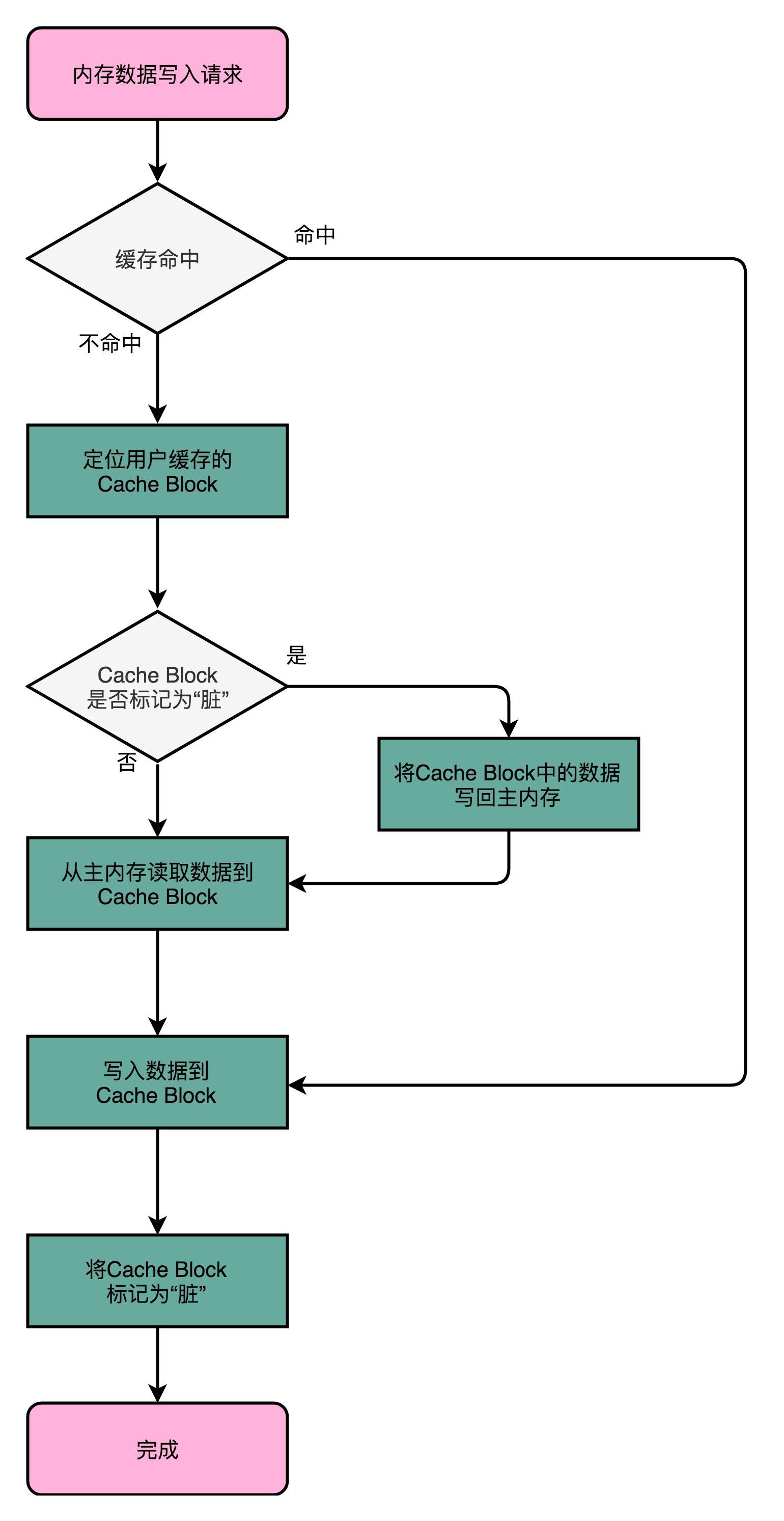
写入策略
写直达 – Write-Through
- 每一次数据都要写入到主内存里,写入前,会先判断数据是否已经在Cache里
- 如果是,先把数据写入更新到Cache里,再写入到主内存里
- 如果否,只更新主内存
- 缺点:很慢!
- 无论数据是不是在Cache里面,都需要把数据写到主内存里面,类似于**
volatile**关键字
- 无论数据是不是在Cache里面,都需要把数据写到主内存里面,类似于**
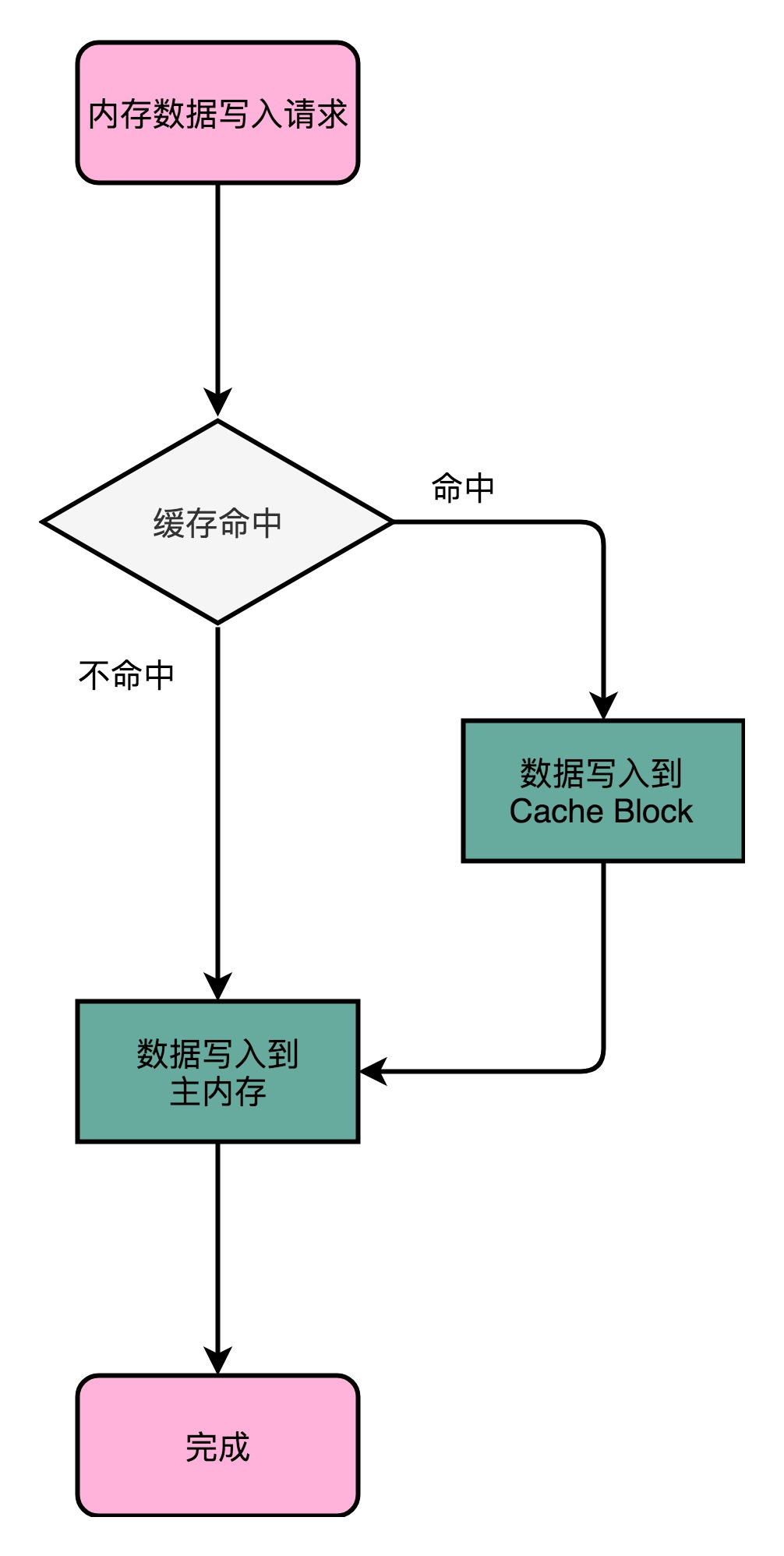
写回 – Write-Back
- 不再是每次都把数据写入到主内存,而是只写到CPU Cache里面
- 只有当CPU Cache里面的数据要被『替换』的时候,才把数据写入到主内存里面
- 如果发现要写入的数据,就在CPU Cache里,那么就只更新CPU Cache里的数据
- 并且标记CPU Cache里的这个Block是脏(Dirty)的
- 脏:CPU Cache里面的Block的数据和主内存是不一致的
- 如果要写入的数据所对应的Cache Block里,放的是别的内存地址的数据,判断那个Cache Block里面的数据是否被标记为脏
- 如果是脏的,就先把这个Cache Block里面的数据,写入到主内存里面
- 然后在把当前要写入的数据,写入到Cache里,同时把Cache Block标记成脏的
- 如果不是脏的,直接把数据写入到Cache里,然后再把Cache Block标记成脏的
- 加载内存数据到Cache里面的时候,也要多出一步同步脏Cache的动作
- 如果加载内存里的数据到Cache的时候,发现Cache Block里面有脏标记
- 需要先把Cache Block里面的数据写回到主内存,才能加载数据覆盖掉Cache
- 优点:大量的操作,都能命中缓存,在大部分时间里,都不需要读写主内存,性能比写直达要好很多
缓存一致性问题
- 无论是写直达还是写回,都没有解决多个线程或者多个CPU核心的缓存一致性问题
- 解决方案:MESI协议
- 应用场景:不仅可以在CPU Cache之间,也可以广泛用于各种需要使用缓存,同时缓存之间需要同步的场景
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2020-02-02
计算机组成 -- SSD
对比 访问类型 机械硬盘(HDD) 固态硬盘(SSD) 随机读 慢 非常快 随机写 慢 快 顺序写 快 非常快 耐用性(重复擦写) 非常好 差 读写原理 CPU Cache用的SRAM是用一个电容来存放一个比特的数据 对于SSD硬盘,由一个电容加上一个电压计组合在一起,就可以记录一个或多个比特 分类 SLC:Single-Level Cell MLC:Multi-Level Cell TLC:Triple-Level Cell QLC:Quad-Level Cell QLC 想要表示15个不同的电压,充电和读取的时候,对精度的要求就会更高,这会导致充电和读取的时候更慢 QLC的SSD的读写速度要比SLC慢上好几倍 PE擦写问题 控制电路 常用的是SATA或者PCI Express接口,里面有一个很重要的模块:FTL(Flash-Translation Layer),即内存转换层 FTL是SSD的核心模块,SSD性能的好坏很大程度上取决于FTL的算法好不好 实际的IO设备 新的大容量SSD都是3D封装的,即由很多裸片(Die)叠在一起(跟HDD有点类似)...

2020-01-04
计算机组成 -- 指令
CPU + 计算机指令 硬件的角度 CPU是一个超大规模集成电路,通过电路实现了加法、乘法乃至各种各样的处理逻辑 软件工程师的角度 CPU就是一个执行各种计算机指令的逻辑机器 计算机指令是一门CPU能听懂的语言,也称为机器语言 不同的CPU能够听懂的语言不太一样,两种CPU各自支持的语言,就是两组不同的计算机指令集 计算机程序平时是存储在存储器中,这种程序指令存储在存储器里面的计算机,叫作存储程序型计算机 代码 -> 机器码(编译 -> 汇编)1234567// test.cint main(){ int a = 1; int b = 2; a = a + b;} 编译(Compile)成汇编代码:把整个程序翻译成一个汇编语言(ASM,Assembly Language)的程序 汇编:针对汇编代码,用汇编器(Assembler)翻译成机器码(Machine Code) 机器码由0和1组成的机器语言表示,一串串的16进制数字,就是CPU能够真正认识的计算机指令 汇编代码 + 机器码12345678910$ gcc --help-c ...

2020-01-22
计算机组成 -- CISC + RISC
历史 在早期,所有的CPU都是CISC 实际的计算机设计和制造会严格受到硬件层面的限制,当时的计算很慢,存储空间很小 为了让计算机能够尽量多地工作,每个字节乃至每个比特都特别重要 CPU指令集的设计,需要仔细考虑硬件限制,为了性能考虑,很多功能都直接通过硬件电路来完成 为了少用内存,指令长度也是可变的 常用的指令要短一些,不常用的指令要长一些 用尽量少的内存空间,存储尽量多的指令 计算机的性能越来越好,存储的空间也越来越大,70年代末,RISC出现 CPU运行程序,80%的运行代码都在使用20%的简单指令 对比 CISC RISC 以硬件为中心的指令集设计 以软件为中心的指令集设计 通过硬件实现各类程序指令 通过编译器实现简单指令组合,完成复杂功能 更高效地使用内存和寄存器 – 一开始都是CISC,硬件资源非常珍贵 需要更大的内存和寄存器,并更频繁地使用 可变的指令集,支持更复杂的指令长度 简单、定长的指令 大量指令数 少量指令数 CISC的缺点 在硬件层面,如果想要支持更多的复杂指令,CPU里面的电路就要更复杂,设计起来更困难 更复杂的电路,在散热和功...

2020-01-08
计算机组成 -- ELF + 静态链接
代码拆分源代码add_lib.c12345// add_lib.cint add(int a, int b){ return a+b;} link_example.c1234567891011// link_example.c#include <stdio.h>int main(){ int a = 10; int b = 5; int c = add(a, b); printf("c=%d\n", c);} gcc + objdump123$ gcc -g -c add_lib.c link_example.c$ objdump -d -M intel -S add_lib.o$ objdump -d -M intel -S link_example.o add_lib.o1234567891011121314151617add_lib.o: 文件格式 elf64-x86-64Disassembly of section .text:0000000000000000 <add>...

2020-02-03
计算机组成 -- DMA
背景 无论IO速度如何提升,比起CPU,还是太慢,SSD的IOPS可以达到2W,但CPU的主频有2GHz 对于IO操作,都是由CPU发出对应的指令,然后等待IO设备完成操作后返回,CPU有大量的时间都是在等待IO设备完成操作 在很多时候,CPU的等待是没有太多的实际意义的 对于IO设备的大量操作,其实都只是把内存里面的数据,传输到IO设备而已,此时CPU只是在傻等 当传输的数据量比较大的时候,如大文件复制,如果所有数据都要经过CPU,实在有点太浪费时间 因此发明了DMA技术,即直接内存访问(Direct Memory Access),来减少CPU等待的时间 协处理器 本质上,DMA技术就是在主板上一块独立的芯片 在进行内存和IO设备的数据传输的时候,不再通过CPU来传输数据 而直接通过DMA控制器(DMA Controller,DMAC),其实是一个协处理器(Co-Processor) DMAC最有价值的地方:当要传输的数据特别大,速度特别快,或者传输的数据特别小、速度特别慢的时候 用千兆网卡或者硬盘传输大量数据的时候,如果都用CPU来搬运的话,肯定忙不过来,可以选择DMAC 当数据传...
2020-01-01
计算机组成 -- 知识地图
参考资料深入浅出计算机组成原理




