
计算机组成 -- 内存
程序装载
- 在Linux或Windows下,程序并不能直接访问物理内存
- 内存需要被分成固定大小的页,然后通过虚拟内存地址到物理内存地址的地址转换,才能到达实际存放数据的物理内存位置
- 程序看到的内存地址,都是虚拟内存地址
地址转换
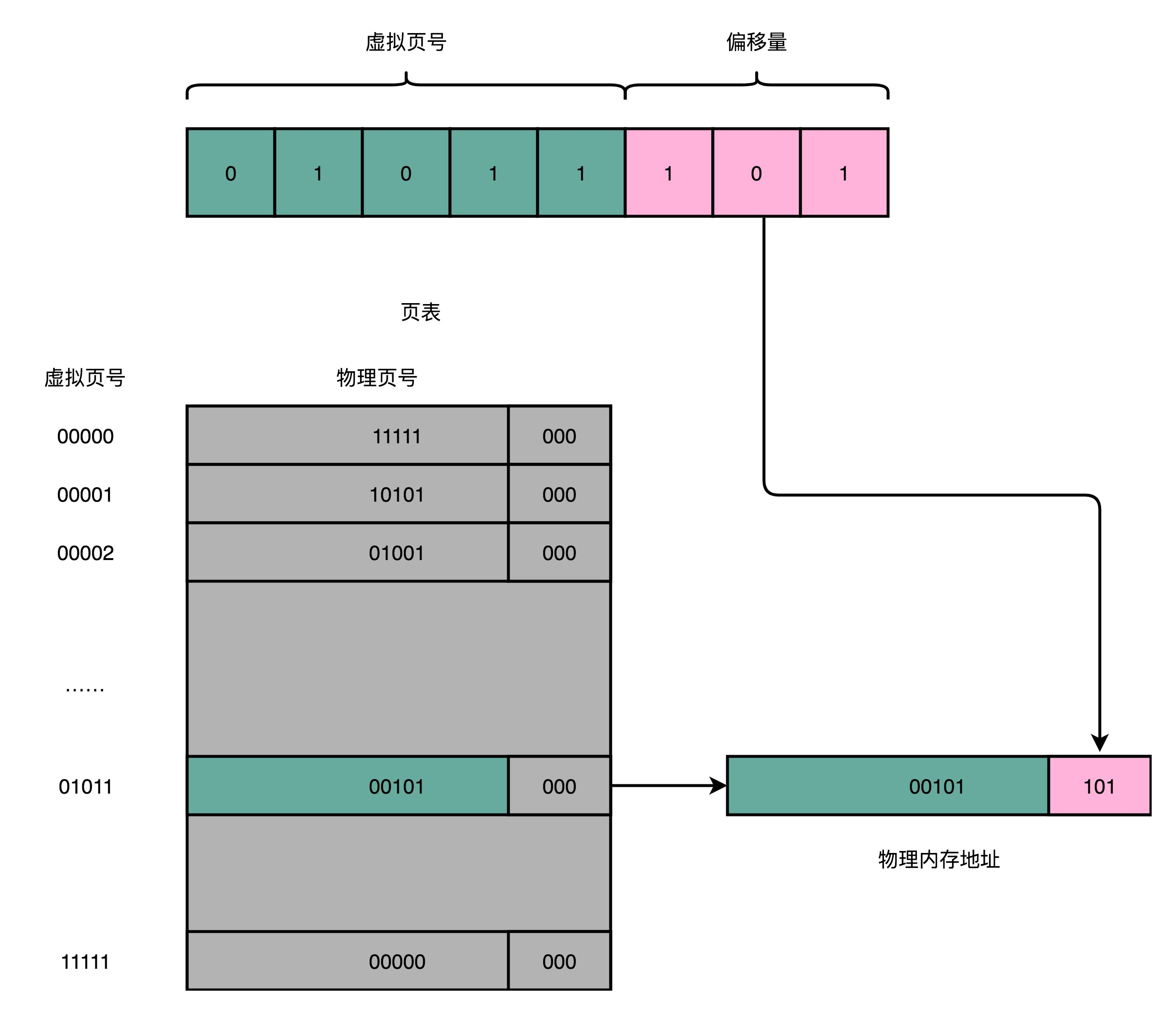
简单页表
- 页表(Page Table,一一映射):<**虚拟**内存的页, **物理**内存的页>
- 页表:把一个内存地址分成页号(Directory)和偏移量(Offset)两部分
- 前面的高位,是内存地址的页号;后面的低位,是内存地址的偏移量
- 页表只需要保留虚拟内存地址的页号和物理内存地址的页号之间的映射关系即可
- 同一个页里面的内存,在物理层面是连续的
- 对于32位的内存地址,4KB大小的页,需要保留20位的高位,12位的低位
- 内存地址转换步骤
- 把虚拟内存地址,切分成页号和偏移量
- 从页表里面,查询出虚拟页号对应的物理页号
- 直接拿到物理页号,加上前面的偏移量,得到物理内存地址
空间问题
- 32位的内存地址空间,页表一共需要记录2^20个到物理页号的映射关系
- 一个页号是完整的32位的4 Bytes,一个页表就需要4MB的空间(2^20 * 4 Bytes = 4MB)
- 每一个进程,都有属于自己独立的虚拟内存地址空间,每个进程都需要这样的一个页表 – 占用的内存空间非常大
- 32位的内存地址空间只能支持4GB的内存,现在大多都是64位的计算机和操作系统
多级页表
- 其实没有必要存下2^20个物理页表,大部分进程所占用的内存是有限的,需要的页也自然是有限的
- 只需要去存那些用到的页之间的映射关系 – 多级页表
- 整个进程的内存地址空间,通常是两头实、中间空
- 栈:内存地址从顶向下,不断分配占用
- 堆:内存地址从底向下,不断分配占用
- 虚拟内存占用的地址空间,通常是两段连续的空间
- 多级页表特别适合这样的内存地址分布!!
4级的多级页表
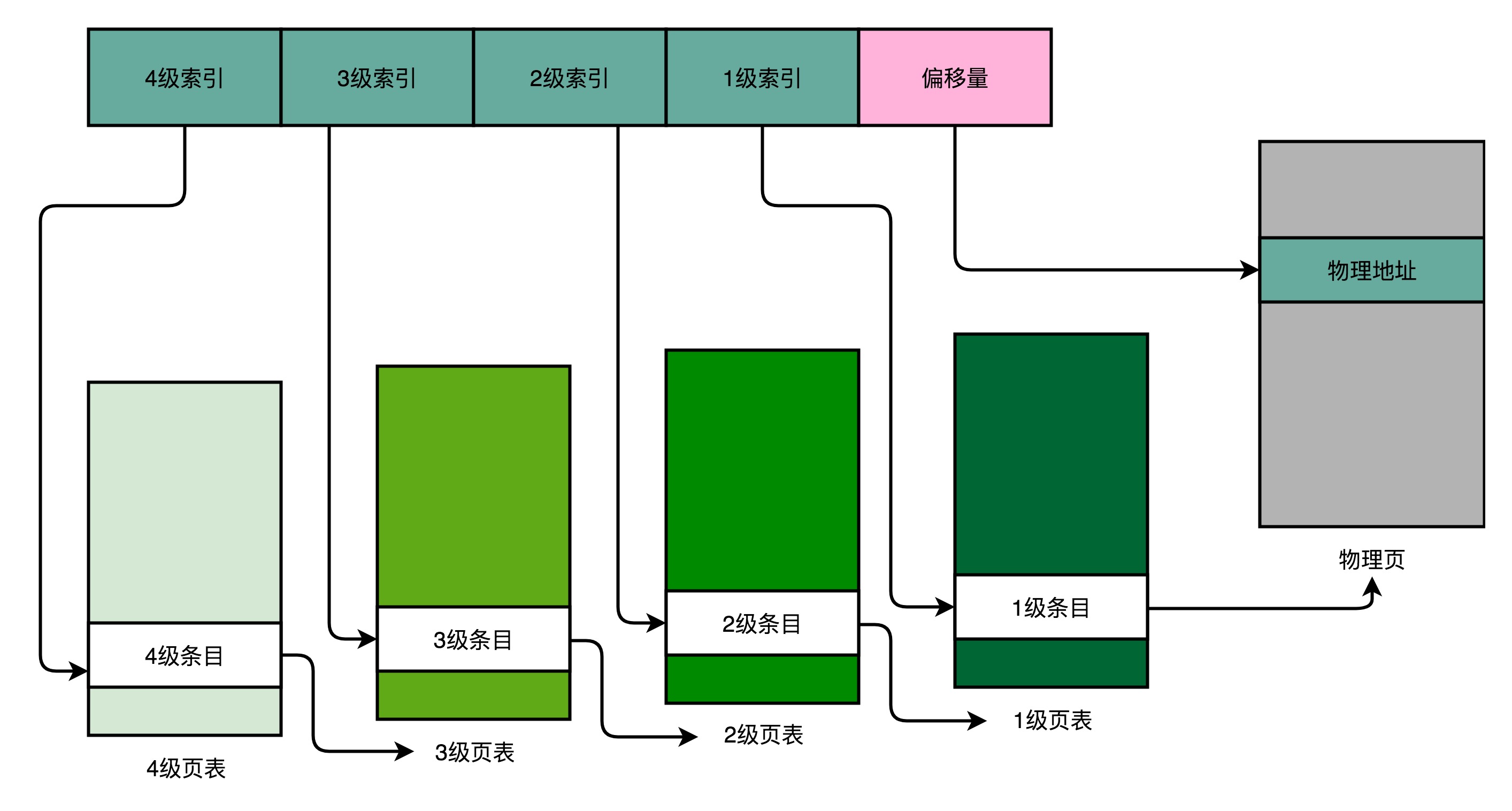
- 同样一个虚拟内存地址,偏移量的部分和上面的简单页表是一样的,但原先的页号部分,拆分成了4部分
- 对应的,一个进程会有一个4级页表
- 先通过4级页表索引,找到4级页表里对应的条目
- 这个条目里存放的是一个3级页表所在的位置
- 4级页表里面的每一个条目,都对应着一张3级页表,因此可能会有多张3级页表
- 找到对应的3级页表之后,再用3级页表索引去3级页表找到对应的条目(指向一个2级页表)
- 2级页表里,可以用2级页表索引指向一个1级页表
- 最后一层的1级页表里面的条目,对应的数据内容就是物理页号了
- 拿到物理页号后,可以用页号+偏移量的方式,来获取最终的物理内存地址
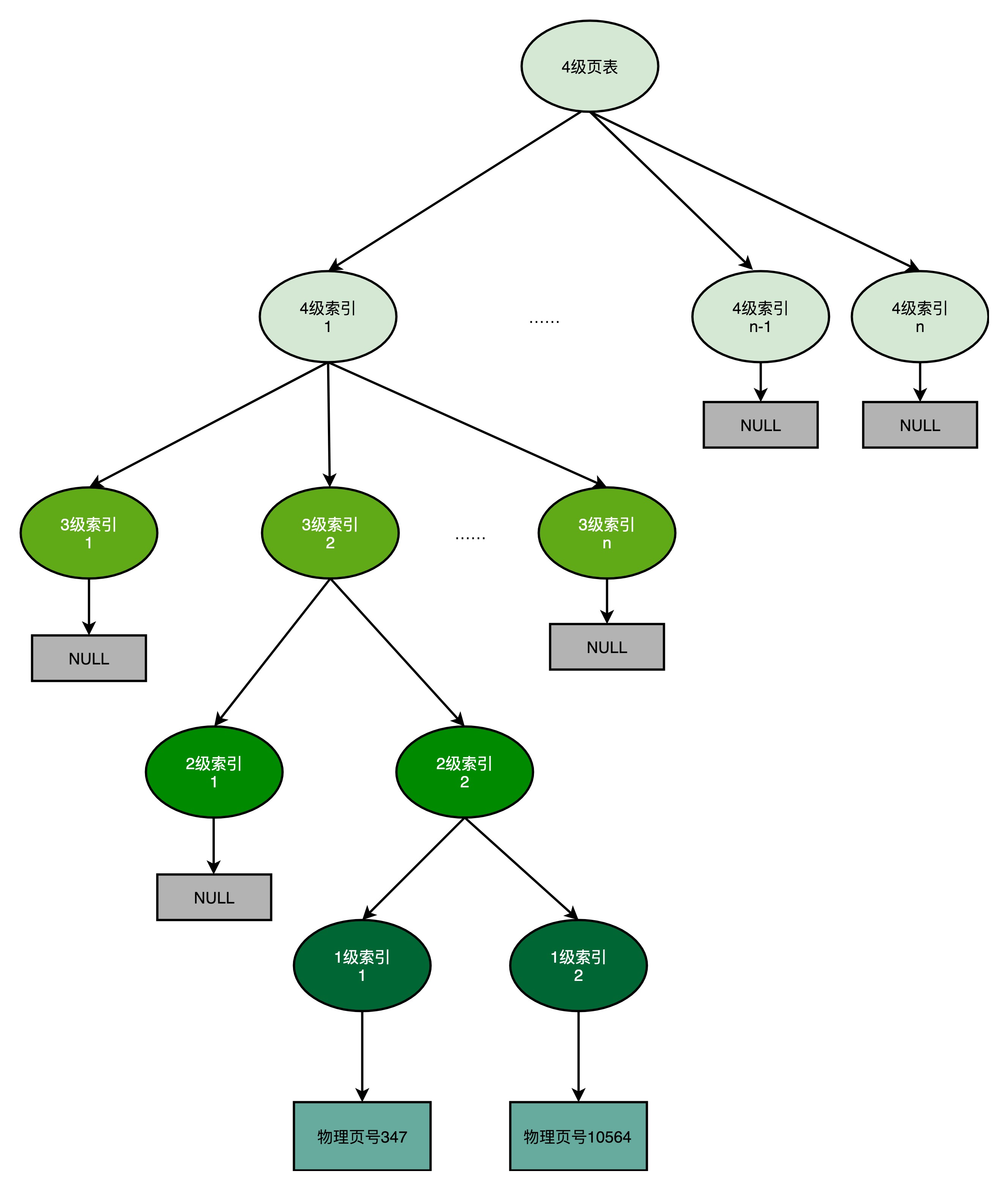
- 因为实际的虚拟内存空间通常是连续的,可能只需要很少的2级页表,甚至只需要1张3级页表即可
- 多级页表类似于一个多叉树的数据结构,因此常常称之为页表树(Page Table Tree)
- 因为虚拟内地址分布的连续性,树的第一层节点的指针,很多是空的,即不需要对应的子树
- 不需要子树,也就是不需要对应的2级、3级的页表
- 找到最终的物理页号,相当于通过特定的访问路径,走到树最底层的叶子节点
- 因为虚拟内地址分布的连续性,树的第一层节点的指针,很多是空的,即不需要对应的子树
空间对比
- 多级页表
- 如果每一级都用5个bit来表示,那么每一张某1级的页表,只需要2^5=32个条目
- 如果每个条目都还是4 Bytes,一共需要128 Bytes
- 一个填满的1级索引表,对应32个Page(4KB),即128KB的大小
- 一个填满的2级索引表,对应32个1级索引表,即4MB的大小
- 如果每一级都用5个bit来表示,那么每一张某1级的页表,只需要2^5=32个条目
- 如果一个进程占用了8MB的内存空间,分成了2个4MB的连续空间,一共需要2个独立的、填满的2级索引表
- 意味着:64个1级索引表、2个独立的3级索引表、1个4级索引表
- 总共需要69个索引表,大概需要128Bytes * 69 ≈ 9KB的空间,相比于4MB,只有_1/464_
小结
- 多级页表节省了存储空间,但却带来了时间上的开销,是一种『以时间换空间』的策略
- 原本进行一次地址转换,只需要访问一次内存就能找到物理页号,就能计算出物理内存地址
- 但用了4级页表,就需要访问4次内存,才能找到物理页号
- 访问内存比访问Cache要慢很多!!
性能 + 安全
- 性能
- 机器指令里面的内存地址都是虚拟内存地址,每一个进程,都有一个独立的虚拟内存地址空间
- 通过地址转换来获得最终的实际物理地址
- 每一个指令都是放在内存里面,每一条数据都存放在内存里面
- 因此地址转换是一个非常高频的动作,地址转换的性能至关重要
- 安全
- 因为所有指令和数据都存放在内存里面,就不得不考虑内存安全问题
- 如果有人修改了内存里面的内容,CPU就可能会执行计划之外的指令
- 破坏服务器里面的数据、获取服务器里面的敏感信息
TLB – 加速地址转换
- 多级页表(空间换时间):节约了存储空间,但却带来了时间上的开销
- 程序所需要使用的指令,都顺序存放在虚拟内存里面(空间局部性);指令也是一条条顺序执行的(时间局部性)
- 因此对于指令地址的访问,存在空间局部性和时间局部性 – 缓存!!
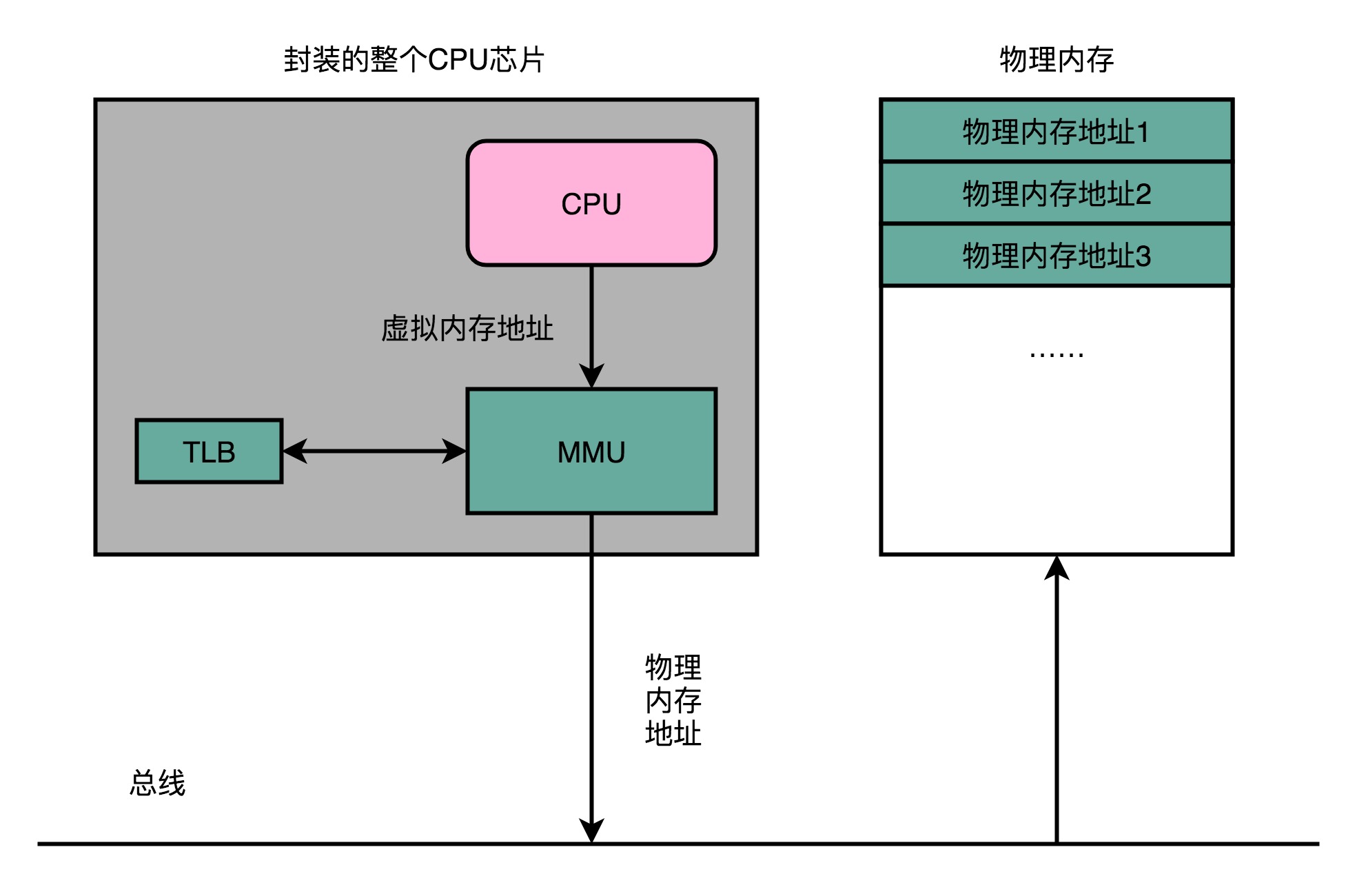
- 计算机工程师专门在CPU里面存放了一块缓存芯片,称为TLB(Translation-Lookaside Buffer,地址变换高速缓冲)
- TLB里面存放了之前已经进行过地址转换的查询结果
- TLB与CPU Cache类似
- 可以分为指令TLB(ITLB)和数据TLB(DTLB)
- 可以根据大小对它进行分级,变成L1、L2 TLB
- 需要用脏标记位,来实现写回这样的缓存策略
- 为了性能,整个的内存转换过程也需要由硬件来执行
- 在CPU芯片里面,封装了内存管理单元(MMU,Memory Management Unit)芯片,用来完成地址转换
- 和TLB的访问和交互,都是由MMU控制的
安全性 + 内存保护
对于内存管理,计算机也有一些最底层的安全保护机制,这些机制统称为内存保护(Memory Protection)
可执行空间保护
- 对于一个进程使用的内存,只把其中的指令部分设置成可执行的
- 其实无论是指令还是数据,在CPU看来,都是二进制的数据
- 直接把数据部分拿给CPU,如果这些数据解码后,也能变成一条合理的指令,其实是可执行的
- 对于进程里内存空间的执行权限进行控制,可以使得CPU只能执行指定区域的代码
- 对于数据区域的内容,即使找到了其他漏洞想要加载成指令来执行,也会因为没有权限而被阻挡掉
地址空间布局随机化
- 内存层面的安全保护核心策略:在可能有漏洞的情况下进行安全预防
- 核心问题
- 其他的人、进程、程序,会去修改掉特定进程的指令和数据,然后,让当前进程去执行这些指令和数据,造成破坏
- 如果要想修改这些指令和数据,需要知道这些指令和数据所在的位置才行
- 原先一个进程的内存布局空间是固定的,任何第三方很容易就知道指令、程序栈、数据、堆的位置
- 地址空间布局随机化:让这些区域的位置不再固定,在内存空间随机去分配这些进程里不同部分所在的内存空间地址
- 如果随便做点修改,程序只会Crash掉,而不会去执行计划之外的代码
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2020-01-11
计算机组成 -- 二进制编码
补码表示法 原码表示法 0011为3,1011为-3 缺点:0000和1000都表示为0 浪费 + 模凌两可 由此诞生了补码表示法,其实就是一个简单的翻转而已 用补码表示负数,使得整数的相加变得容易,不需要做任何特殊处理,当成普通的二进制相加即可 字符串 ASCII码类似一个字典,用8位二进制中的128个不同的数字,映射到128个不同的字符里 a在ASCII里面是第97个,二进制为0110 0001,对应的十六进制为0x61 字符串9用0011 1001来表示,字符串15用0011 0001和0011 0101来表示,占用更多的空间 因此存储数据的时候,要采用二进制序列化的形式, 而不是简单地把数据通过CSV或者JSON这样的文本格式存储来进行序列化 不管是整点数,还是浮点数,采用二进制序列化比存储文本能节省不少空间 字符集(Charset)和字符编码(Character Encoding) 字符集:字符的集合 Unicode是字符集,包含150种语言的14万个字符 字符编码:对于字符集里的这些字符,怎么用二进制表示出来的一个字典 Unicode可以用UTF-8、UTF-1...

2020-01-01
计算机组成 -- First Draft
从输入设备读取输入信息,通过运算器和控制器来执行存储在存储器里的程序,最终把结果输出到输出设备中 参考资料深入浅出计算机组成原理

2020-01-06
计算机组成 -- goto
CPU执行指令 CPU是由一堆寄存器组成的,而寄存器是由多个触发器(Flip-Flop)或者锁存器(Latches)组成的简单电路 触发器和锁存器是两种不同原理的数字电路组成的逻辑门 N个触发器或者锁存器,就可以组成一个N位的寄存器,能保存N位的数据,64位的Intel服务器,寄存器就是64位的 寄存器分类 PC寄存器(Program Counter Register),也称为指令地址寄存器(Instruction Address Register) 用来存放下一条需要执行的计算机指令的内存地址 指令寄存器(Instruction Register) 用来存放当前正在执行的指令 条件码寄存器(Status Register) 用里面的一个个标志位(Flag),存放CPU进行算术或者逻辑计算的结果 其它 整数寄存器、浮点数寄存器、向量寄存器、地址寄存器、通用寄存器 程序执行 CPU会根据PC寄存器里面的地址,从内存里把需要执行的指令读取到指令寄存器里面执行 然后根据指令长度自增,开始顺序读取下一条指令,一个程序的指令,在内存里面是连续保存的,也会一条条顺序加载 特殊指令,如J类指令...

2020-01-02
计算机组成 -- 性能
性能指标 响应时间(Response time)、执行时间(Execution time) 执行一个程序,需要花多少时间 吞吐率(Throughput)、带宽(Bandwidth) 单位时间范围内,能处理多少数据或执行多少指令,可以通过多核、集群等方式来提升吞吐率 性能 = 1/响应时间 CPU时钟 time命令 real time Wall Clock Time/Elapsed Time,运行程序整个过程中流逝掉的时间 user time 在用户态运行指令的时间 sys time 在操作系统内核里运行指令的时间 程序实际花费的CPU执行时间:CPU time = user time + sys time 程序实际占用的CPU time一般比Elapsed Time少(单核情况下) 123456$ time seq 1000000 | wc -l1000000real 0m0.024suser 0m0.018ssys 0m0.005s 程序实际花了0.024s,CPU time只有0.018s+0.005s=0...

2020-01-13
计算机组成 -- 加法器
基本门电路 基本门电路:输入都是两个单独的bit,输出是一个单独的bit 如果要对2个8bit的数字,计算与或非的简单逻辑(无进位),只需要连续摆放8个开关,来代表一个8bit数字 这样的两组开关,从左到右,上下单个的位开关之间,都统一用『与门』或者『或门』连起来 就能实现两个8bit数的AND运算或者OR运算 异或门 + 半加器一bit加法 个位 输入的两位为00和11,对应的输出为0 输入的两位为10和01,对应的输出为1 上面两种关系都是异或门(XOR)的功能 异或门是一个最简单的整数加法,所需要使用的基本门电路 进位 输入的两位为11时,需要向更左侧的一位进行进位,对应一个与门 通过一个异或门计算出个位,通过一个与门计算出是否进位 把这两个门电路打包,叫作半加器(Half Adder) 全加器 半加器只能解决一bit加法的问题,不能解决2bit或以上的加法(因为有进位信号) 二进制加法的竖式,从右往左,第二列称为二位,第三列称为四位,第四列称为八位 全加器:两个半加器和一个或门 把两个半加器的进位输出,作为一个或门的输入 只要两次加法中任何一次需要进位,那么在二位...

2020-01-18
计算机组成 -- 冒险
冒险 流水线架构的CPU,是主动进行的冒险选择,期望通过冒险带来更高的回报 对于各种冒险可能造成的问题,都准备好了应对方案 分类 结构冒险(Structural Hazard) 数据冒险(Data Hazard) 控制冒险(Control Hazard) 结构冒险 结构冒险,本质上是一个硬件层面的资源竞争问题 CPU在同一个时钟周期,同时在运行两条计算机指令的不同阶段,但这两个不同的阶段可能会用到同样的硬件电路 内存的数据访问 第1条指令执行到访存(MEM)阶段的时候,流水线的第4条指令,在执行取指令(Fetch)操作 访存和取指令,都是要进行内存数据的读取,而内存只有一个地址译码器,只能在一个时钟周期内读取一条数据 无法同时执行第1条指令的读取内存数据和第4条指令的读取指令代码 解决方案 解决方案:增加资源 哈佛架构 把内存分成两部分,它们有各自的地址译码器,这两部分分别是存放指令的程序内存和存放数据的数据内存 缺点:无法根据实际情况去动态调整 普林斯顿架构 – 冯.诺依曼体系架构 今天使用的CPU,仍然是冯.诺依曼体系架构,并没有把内存拆成程序内存和数据内存两部分 ...




