
计算机组成 -- DMA
背景
- 无论IO速度如何提升,比起CPU,还是太慢,SSD的IOPS可以达到2W,但CPU的主频有2GHz
- 对于IO操作,都是由CPU发出对应的指令,然后等待IO设备完成操作后返回,CPU有大量的时间都是在等待IO设备完成操作
- 在很多时候,CPU的等待是没有太多的实际意义的
- 对于IO设备的大量操作,其实都只是把内存里面的数据,传输到IO设备而已,此时CPU只是在傻等
- 当传输的数据量比较大的时候,如大文件复制,如果所有数据都要经过CPU,实在有点太浪费时间
- 因此发明了DMA技术,即直接内存访问(Direct Memory Access),来减少CPU等待的时间
协处理器
- 本质上,DMA技术就是在主板上一块独立的芯片
- 在进行内存和IO设备的数据传输的时候,不再通过CPU来传输数据
- 而直接通过DMA控制器(DMA Controller,DMAC),其实是一个协处理器(Co-Processor)
- DMAC最有价值的地方:当要传输的数据特别大,速度特别快,或者传输的数据特别小、速度特别慢的时候
- 用千兆网卡或者硬盘传输大量数据的时候,如果都用CPU来搬运的话,肯定忙不过来,可以选择DMAC
- 当数据传输很慢的时候,DMAC可以等数据到齐后,再发送信号,给到CPU去处理,而不是让CPU忙等待
- DMAC是在协助CPU,完成对应的数据传输工作,在DMAC控制数据传输的过程中,还是需要CPU介入的
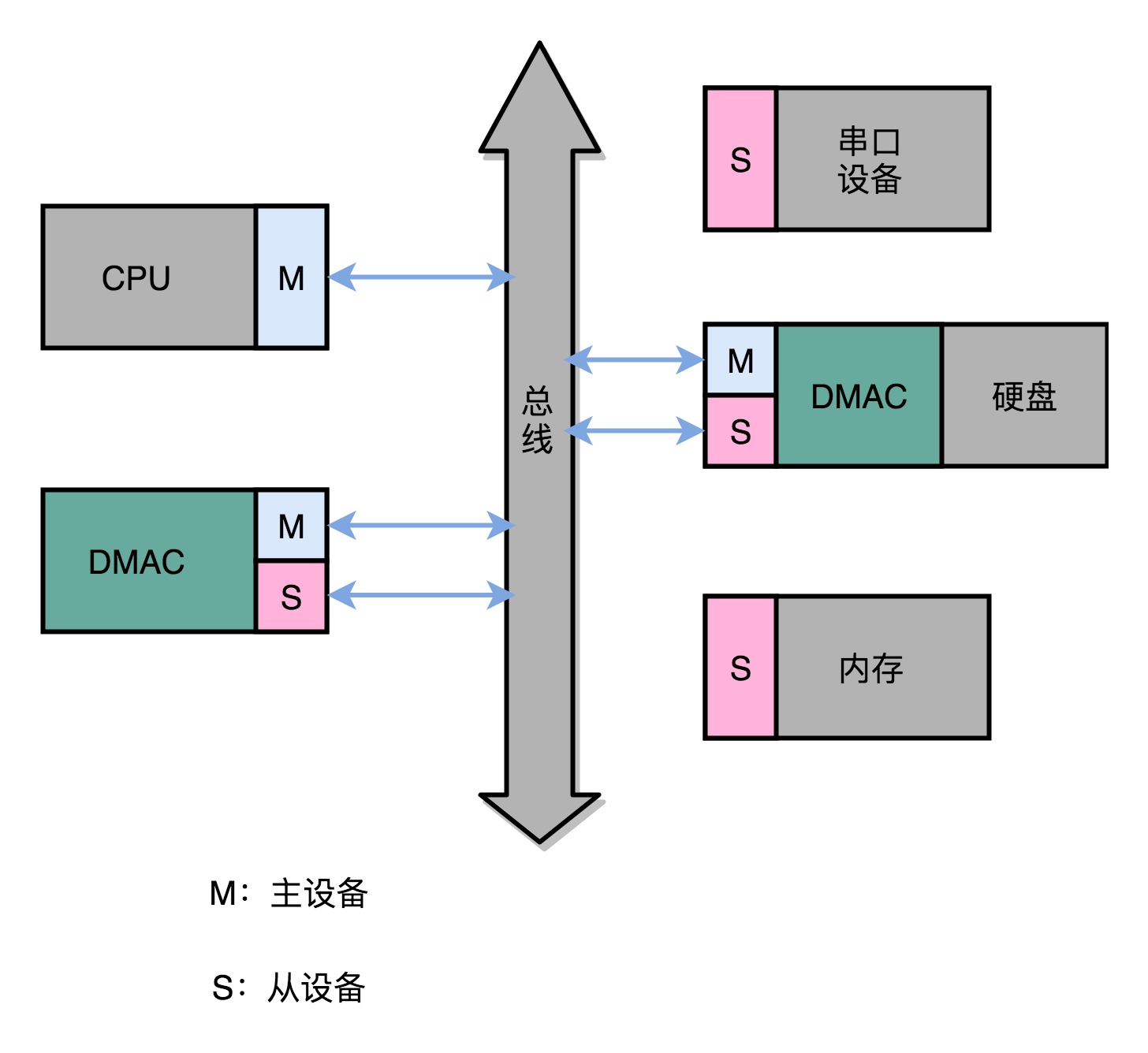
主设备 + 从设备
- DMAC其实是一个特殊的IO设备,通过连接到总线上来进行实际的数据传输
- 总线上的设备,有两种类型,一种称之为主设备(Master),另一种,称之为从设备(Slave)
- 想要主动发起数据传输,必须是一个主设备才可以,CPU是一个主设备
- 从设备(如硬盘)只能接受数据传输
- 因此,如果通过CPU来传输数据,要么CPU从IO设备读数据,要么是CPU向IO设备写数据
- IO设备只能向CPU发送控制信号,告诉CPU有数据要传输给他,实际数据是CPU去读取的,而不是IO设备推给CPU的
- DMAC即是一个主设备,也是一个从设备
- 对于CPU来说,它是一个从设备
- 对于硬盘来说,它是一个主设备
数据传输过程
- CPU作为一个主设备,通过总线,向DMAC设备(此时作为一个从设备)发起请求
- 该请求的作用:在DMAC里面修改配置寄存器
- CPU修改DMAC配置
- 源地址的初始值 + 传输时的地址递减方式
- 源地址是数据要从哪里传输过来
- 如果要从内存里面写入数据到硬盘上,那就是要读取的数据在内存里面的地址
- 如果要从硬盘读取数据到内存里,那就是硬盘的IO接口的地址
- IO的地址可以是一个内存地址,也可以是一个端口地址
- 地址递减方式:数据是从大的地址向小的地址传输,还是从小的地址向大的地址传输
- 目标地址初始值 + 传输时的地址递减方式
- 与源地址对应
- 要传输的数据长度
- 源地址的初始值 + 传输时的地址递减方式
- CPU设置完这些信息后,DMAC就会变成一个空闲(Idle)的状态
- 如果要从硬盘上往内存里面加载数据,此时,硬盘就会向DMAC发起一个数据传输请求
- 该请求并不是通过总线,而是通过一个额外的连线
- DMAC需要再通过一个额外的连线来响应这个申请
- DMAC(此时是主设备)向硬盘接口(从设备)发起要总线读的传输请求
- 数据就从硬盘里面读到DMAC的控制器里面
- 然后,DMAC(主设备)再向内存(从设备)发起总线写的数据传输请求,把数据写入到内存里
- DMAC会重复6、7步,直到DMAC的寄存器里面设置的数据长度传输完成
- 数据传输完成后,DMAC重新回到空闲状态
设备独立的DMAC
- 最早的计算机里面是没有DMAC的,所有数据都是由CPU来搬运的
- 随着对于数据传输的需求越来越多,先是出现在主板上独立的DMAC控制器
- 现在各个设备里面都有自己独立的的DMAC芯片了
Kafka的实现原理
- Kafka是一个用来处理实时数据的管道,常用来做一个消息队列,或者用来收集和落地海量日志
- 作为一个处理实时数据和日志的管道,瓶颈自然在IO层面
- Kafka里面会有两种常见的海量数据传输的情况
- 一种是从网络中接收上游的数据,然后需要落地到本地的磁盘上,确保数据不丢失
- 一种是从本地磁盘读取出来,通过网络发送出去
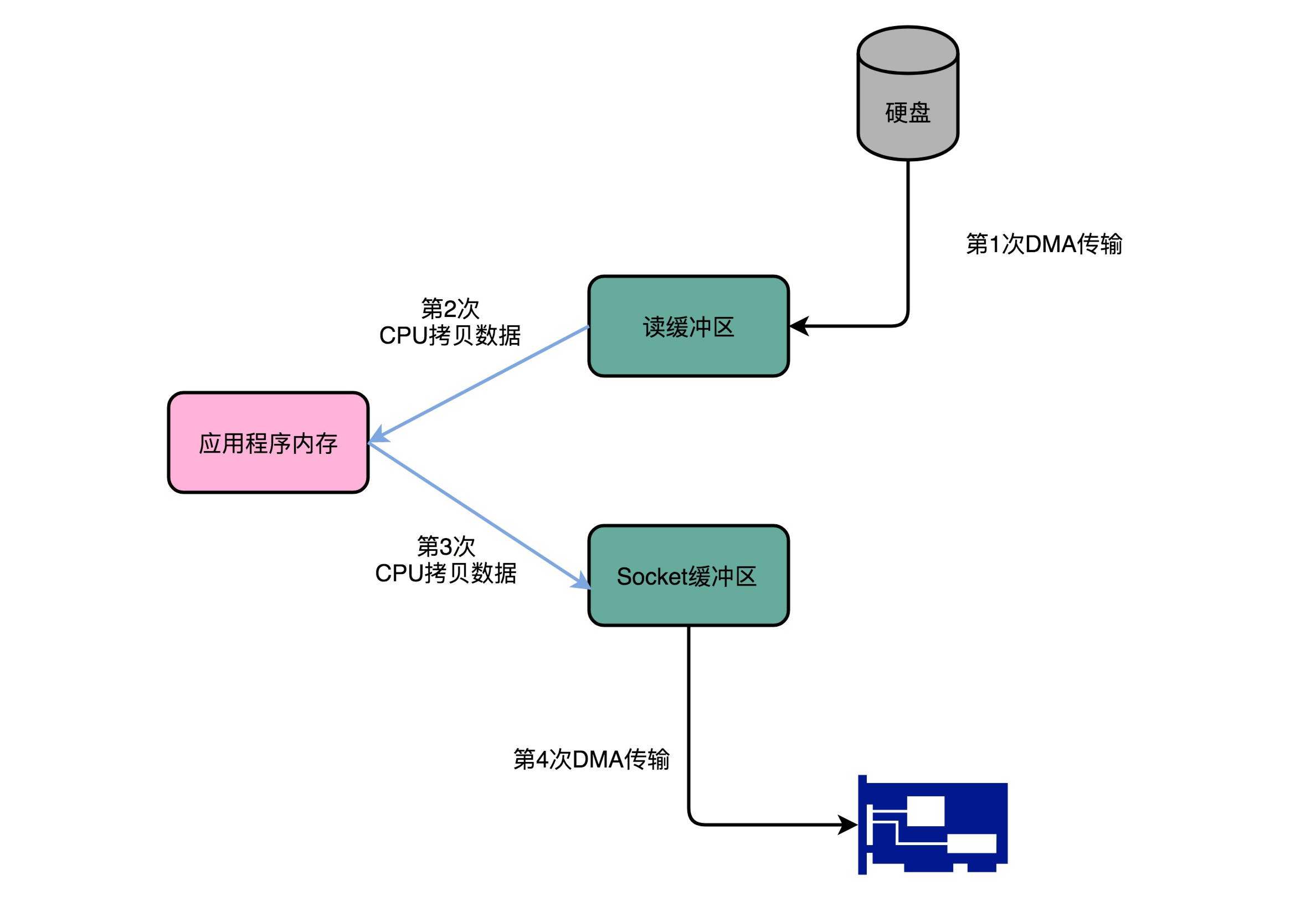
4次传输
1 | File.read(fileDesc, buf, len); |
- 第一次传输
- 通过DMA搬运:硬盘 -> 操作系统内核的读缓冲区
- 第二次传输
- 通过CPU搬运:内核的读缓冲区 -> 应用的内存
- 第三次传输
- 通过CPU搬运:应用的内存 -> 操作系统内核的Socket缓冲区
- 第四次传输
- 通过DMA搬运:内核的Socket缓冲区 -> 网卡的缓冲区
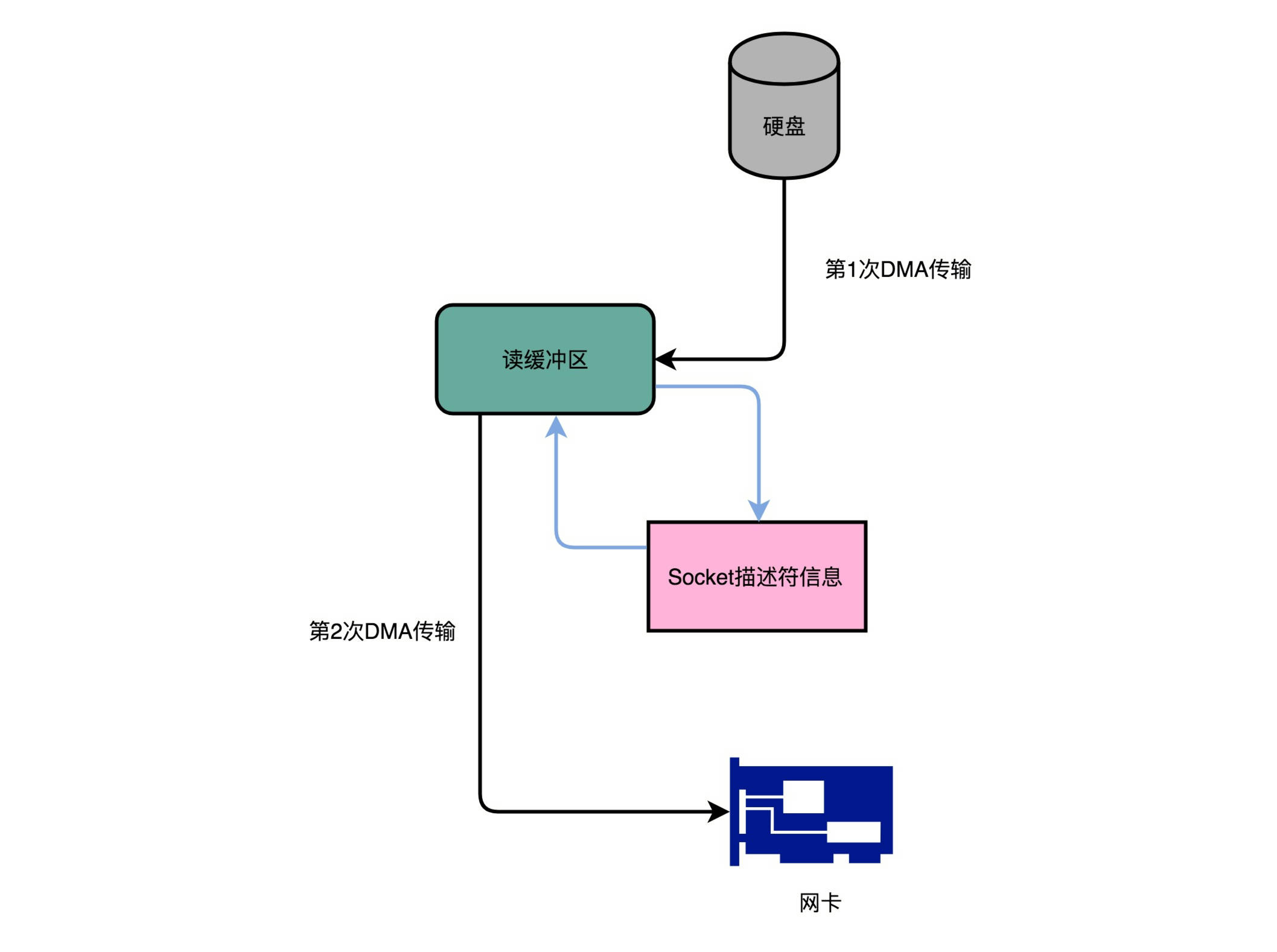
2次传输
1 |
|
- Kafka的代码调用了Java NIO库(
FileChannel#transferTo) - 数据并没有复制到中间的应用内存里面,而是直接通过**
Channel,写入到对应的网络设备**里 - 对于Socket的操作,也不是写入到Socket缓冲区里面,而是直接根据Socket描述符(Descriptor)写入到网卡的缓冲区里
- 具体过程
- 通过DMA搬运:硬盘 -> 操作系统内核的读缓冲区
- 通过DMA搬运:根据Socket的描述符信息,直接从内核的读缓冲区里面,写入到网卡的缓冲区里面
- 只有两次传输,只有DMA来进行数据搬运,并不需要CPU
- 没有在内存层面进行数据复制 -> 零拷贝
- 吞吐率提升:300%
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2020-01-04
计算机组成 -- 指令
CPU + 计算机指令 硬件的角度 CPU是一个超大规模集成电路,通过电路实现了加法、乘法乃至各种各样的处理逻辑 软件工程师的角度 CPU就是一个执行各种计算机指令的逻辑机器 计算机指令是一门CPU能听懂的语言,也称为机器语言 不同的CPU能够听懂的语言不太一样,两种CPU各自支持的语言,就是两组不同的计算机指令集 计算机程序平时是存储在存储器中,这种程序指令存储在存储器里面的计算机,叫作存储程序型计算机 代码 -> 机器码(编译 -> 汇编)1234567// test.cint main(){ int a = 1; int b = 2; a = a + b;} 编译(Compile)成汇编代码:把整个程序翻译成一个汇编语言(ASM,Assembly Language)的程序 汇编:针对汇编代码,用汇编器(Assembler)翻译成机器码(Machine Code) 机器码由0和1组成的机器语言表示,一串串的16进制数字,就是CPU能够真正认识的计算机指令 汇编代码 + 机器码12345678910$ gcc --help-c ...

2020-01-01
计算机组成 -- First Draft
从输入设备读取输入信息,通过运算器和控制器来执行存储在存储器里的程序,最终把结果输出到输出设备中 参考资料深入浅出计算机组成原理

2020-01-22
计算机组成 -- CISC + RISC
历史 在早期,所有的CPU都是CISC 实际的计算机设计和制造会严格受到硬件层面的限制,当时的计算很慢,存储空间很小 为了让计算机能够尽量多地工作,每个字节乃至每个比特都特别重要 CPU指令集的设计,需要仔细考虑硬件限制,为了性能考虑,很多功能都直接通过硬件电路来完成 为了少用内存,指令长度也是可变的 常用的指令要短一些,不常用的指令要长一些 用尽量少的内存空间,存储尽量多的指令 计算机的性能越来越好,存储的空间也越来越大,70年代末,RISC出现 CPU运行程序,80%的运行代码都在使用20%的简单指令 对比 CISC RISC 以硬件为中心的指令集设计 以软件为中心的指令集设计 通过硬件实现各类程序指令 通过编译器实现简单指令组合,完成复杂功能 更高效地使用内存和寄存器 – 一开始都是CISC,硬件资源非常珍贵 需要更大的内存和寄存器,并更频繁地使用 可变的指令集,支持更复杂的指令长度 简单、定长的指令 大量指令数 少量指令数 CISC的缺点 在硬件层面,如果想要支持更多的复杂指令,CPU里面的电路就要更复杂,设计起来更困难 更复杂的电路,在散热和功...

2020-01-03
计算机组成 -- 提升性能
CPU的功耗12CPU time = 时钟周期时间(Clock Cycle Time) × CPU时钟周期数(CPU Cycles) = 时钟周期时间(Clock Cycle Time) × 指令数 × 每条指令的平均周期数(Cycles Per Instruction,CPI) 80年代开始,CPU硬件工程师主要着力提升CPU主频,到功耗是CPU的人体极限 CPU,一般被叫做超大规模集成电路,这些电路,实际上都是一个个晶体管组合而成的 CPU计算,实际上是让晶体管里面的『开关』不断地去打开或关闭,来组合完成各种运算和功能 如果要计算得快,有两个方向:增加密度(7nm制程)、提升主频,但这两者都会增加功耗,带来耗电和散热的问题 密度 -> 晶体管数量 主频 -> 开关频率 如果功耗增加太多,会导致CPU散热跟不上,此时就需要降低电压(低压版CPU) 1功耗 ≈ 1/2 × 负载电容 × 电压的平方 × 开关频率 × 晶体管数量 并行优化 – 阿姆达尔定律1优化后的执行时间 = 受优化影响的执行时间 / 加速倍数 + 不受影响的执行时间 其它 加速大概率事...

2020-01-18
计算机组成 -- 冒险
冒险 流水线架构的CPU,是主动进行的冒险选择,期望通过冒险带来更高的回报 对于各种冒险可能造成的问题,都准备好了应对方案 分类 结构冒险(Structural Hazard) 数据冒险(Data Hazard) 控制冒险(Control Hazard) 结构冒险 结构冒险,本质上是一个硬件层面的资源竞争问题 CPU在同一个时钟周期,同时在运行两条计算机指令的不同阶段,但这两个不同的阶段可能会用到同样的硬件电路 内存的数据访问 第1条指令执行到访存(MEM)阶段的时候,流水线的第4条指令,在执行取指令(Fetch)操作 访存和取指令,都是要进行内存数据的读取,而内存只有一个地址译码器,只能在一个时钟周期内读取一条数据 无法同时执行第1条指令的读取内存数据和第4条指令的读取指令代码 解决方案 解决方案:增加资源 哈佛架构 把内存分成两部分,它们有各自的地址译码器,这两部分分别是存放指令的程序内存和存放数据的数据内存 缺点:无法根据实际情况去动态调整 普林斯顿架构 – 冯.诺依曼体系架构 今天使用的CPU,仍然是冯.诺依曼体系架构,并没有把内存拆成程序内存和数据内存两部分 ...

2020-02-01
计算机组成 -- HDD
物理构造一块机械硬盘由盘面、磁头、悬臂三个部件组成 盘面 盘面(Disk Platter)是我们实际存储数据的盘片 盘面本身通常是用铝、玻璃或者陶瓷这样的材质去做成光滑盘片,然后在盘面上有一层磁性的涂层,数据就存储在磁性的涂层上 盘面中间有一个受电机控制的转轴(控制盘面去旋转),转速:RPM(Rotations Per Minute) 磁头 通过磁头(Drive Head),从盘面上读取数据,然后再通过电路信号传输给控制电路和接口,再到总线上 通常,一个盘面上会有两个磁头,分别是盘面的正反面,盘面在正反面都有对应的磁性涂层来存储数据 一块硬盘不会只有一个盘面,而且上下堆叠了很多个盘面,各个盘面之间是平行的,每个盘面的正反两面都有对应的磁头 悬臂 悬臂(Actutor Arm)链接在磁头上,并且在一定范围内去把磁头定位到盘面的某个特定磁道(Track)上 一个盘面通常是圆形的,由很多同心圆组成,每个同心圆都是一个磁道,每个磁道都有编号 随机读写 一个磁道,会分成多个扇区(Sector),上下平行的盘面的相同扇区,组成一个柱面(Cylinder) 数据读取的步骤 把盘面旋转到某个位置,在这个位...




