
计算机组成 -- Disruptor
缓存行填充
缓存行大小
1 | $ sysctl -a | grep -E 'cacheline|cachesize' |
RingBufferPad
1 | abstract class RingBufferPad |
- 变量p1~p7本身没有实际意义,只能用于缓存行填充,为了尽可能地用上CPU Cache
- 访问CPU里的L1 Cache或者L2 Cache,访问延时是内存的1/15乃至1/100(内存的访问速度,是远远慢于CPU Cache的)
- 因此,为了追求极限性能,需要尽可能地从CPU Cache里面读取数据
- CPU Cache装载内存里面的数据,不是一个个字段加载的,而是加载一整个缓存行
- 64位的Intel CPU,缓存行通常是64 Bytes,一个long类型的数据需要8 Bytes,因此会一下子加载8个long类型的数据
- 遍历数组元素速度很快,后面连续7次的数据访问都会命中CPU Cache,不需要重新从内存里面去读取数据
缓存失效
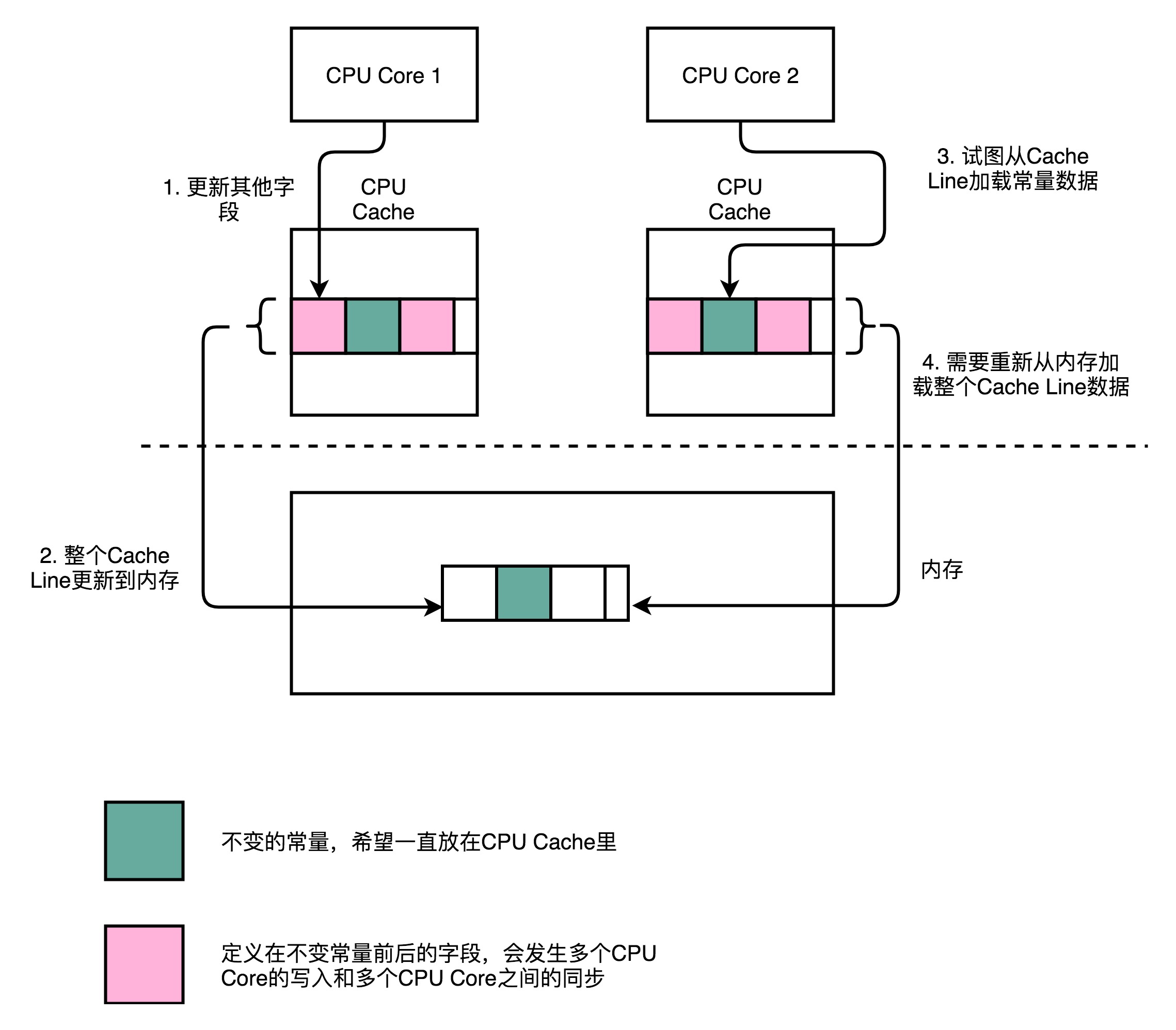
- CPU在加载数据的时候,会把这个数据从内存加载到CPU Cache里面
- 此时,CPU Cache里面除了这个数据,还会加载这个数据前后定义的其他变量
- Disruptor是一个多线程的服务器框架,在这个数据前后定义的其他变量,可能会被多个不同的线程去更新数据,读取数据
- 这些写入和读取请求,可能会来自于不同的CPU Core
- 为了保证数据的同步更新,不得不把CPU Cache里面的数据,重新写回到内存里面或者重新从内存里面加载
- CPU Cache的写回和加载,都是以整个Cache Line作为单位的
- 如果常量的缓存失效,当再次读取这个值的时候,需要重新从内存读取,读取速度会大大变慢
缓存行填充
1 | abstract class RingBufferPad |
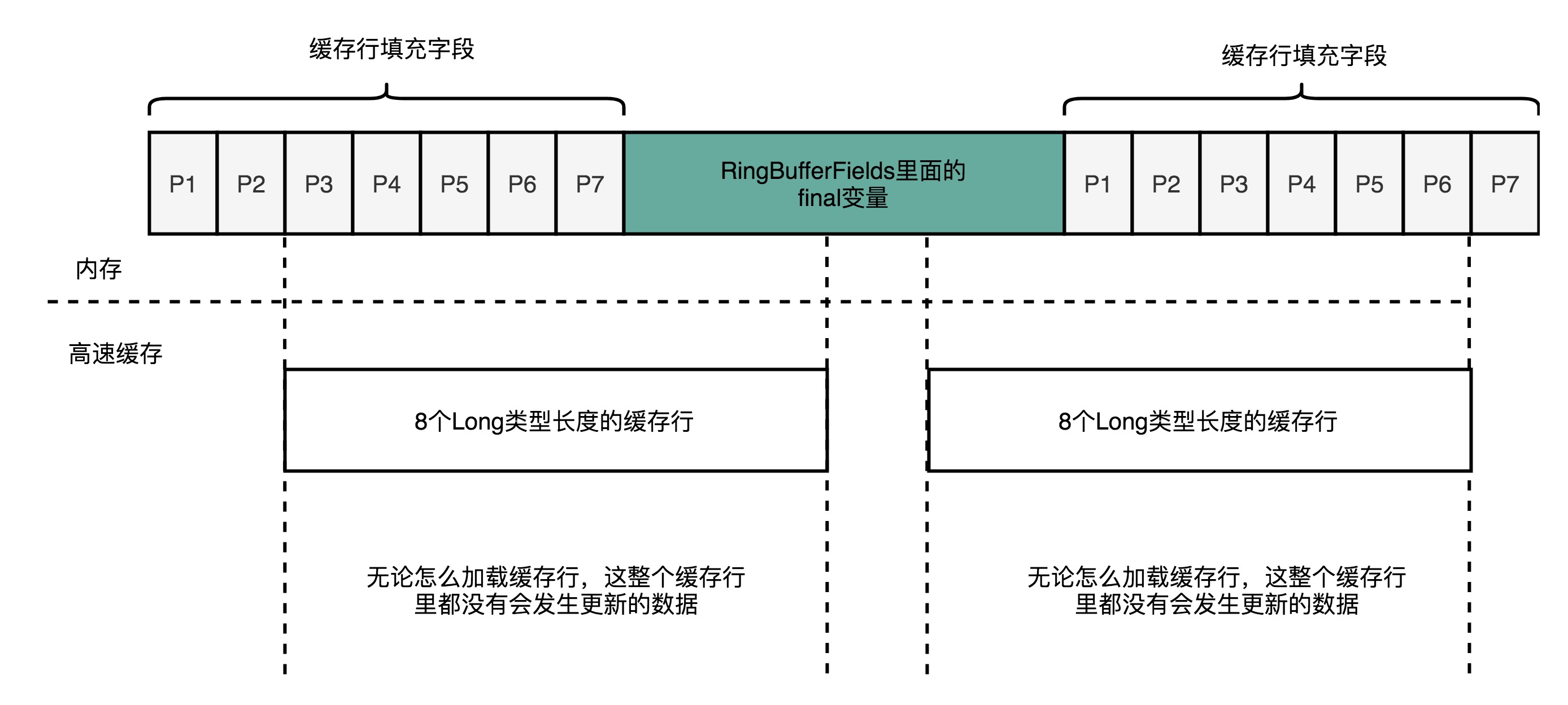
- Disruptor在RingBufferFields里面定义的变量前后分别定义了7个long类型的变量
- 前面7个继承自RingBufferPad,后面7个直接定义在RingBuffer类中
- 这14个变量没有任何实际用途,既不会去读,也不会去写
- RingBufferFields里面定义的变量都是
final的,第一次写入之后就不会再进行修改- 一旦被加载到CPU Cache之后,只要被频繁地读取访问,就不会被换出CPU Cache
- 无论在内存的什么位置,这些变量所在的Cache Line都不会有任何写更新的请求
空间局部性 + 分支预测
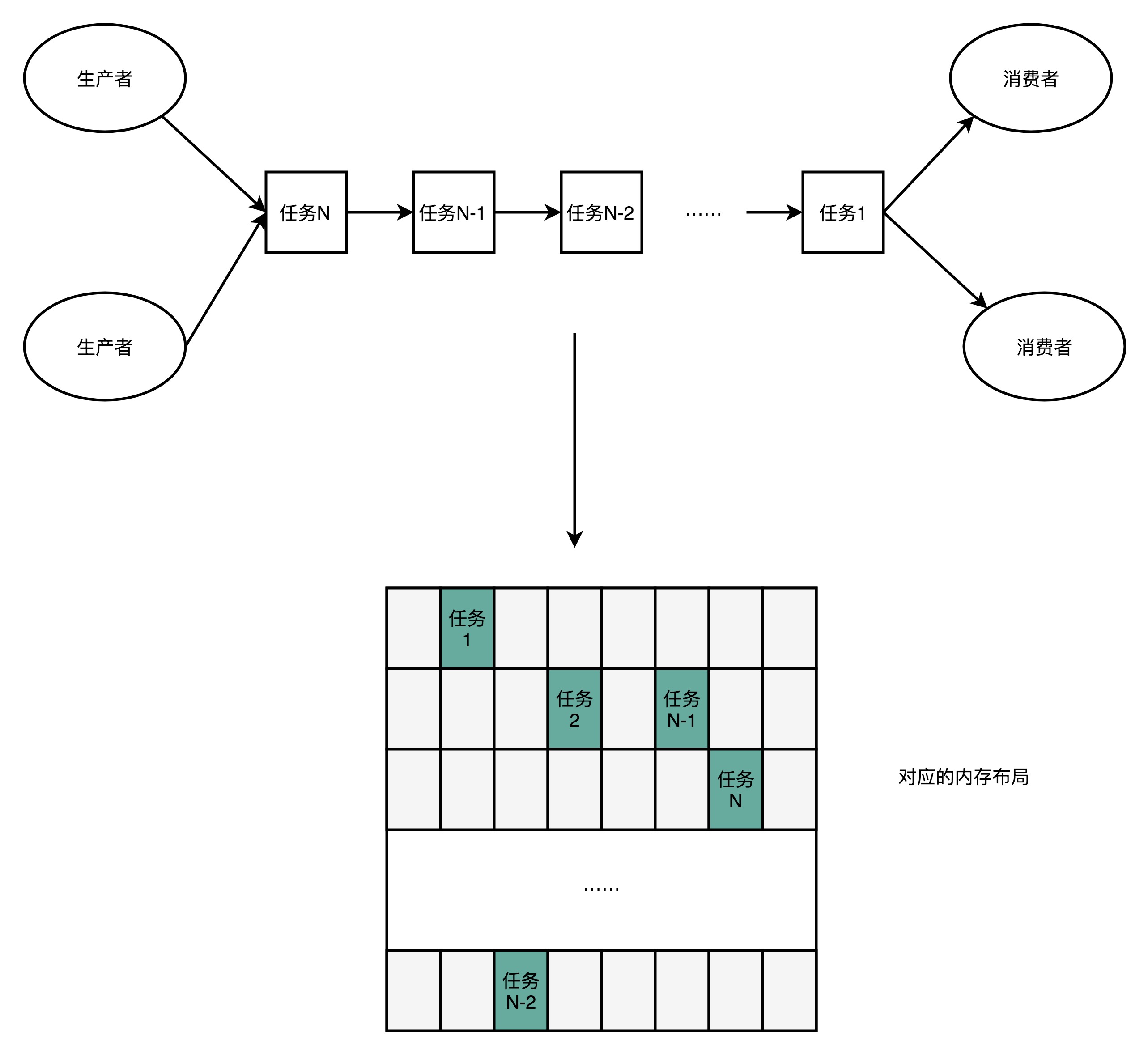
- Disruptor整个框架是一个高速的生产者-消费者模型下的队列
- 生产者不停地往队列里面生产新的需要处理的任务
- 消费者不停地从队列里面处理掉这些任务
- 要实现一个队列,最合适的数据结构应该是链表,如Java中的LinkedBlockingQueue
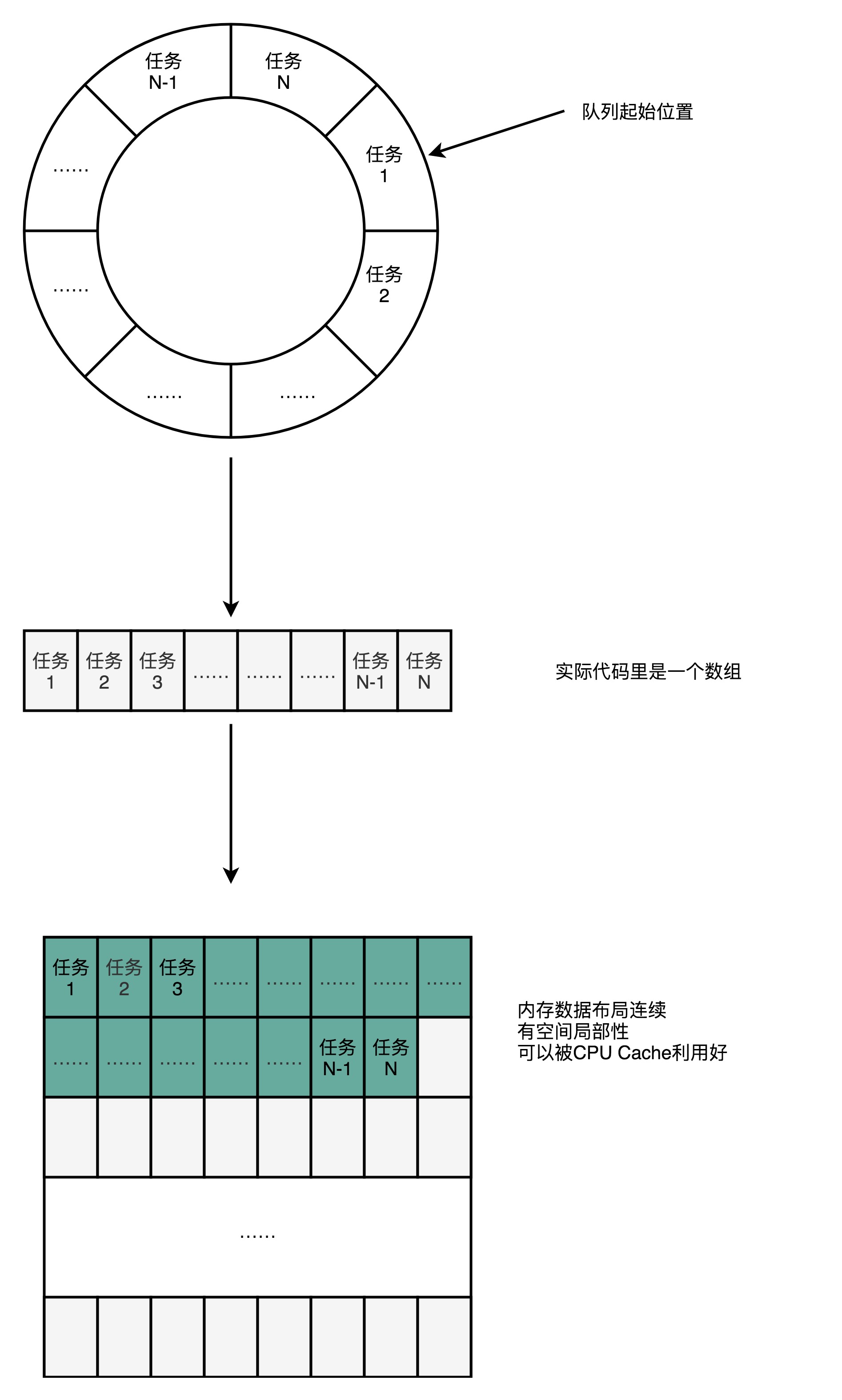
- Disruptor并没有使用LinkedBlockingQueue,而是使用了RingBuffer的数据结构
- RingBuffer的底层实现是一个固定长度的数组
- 比起链表形式的实现,数组的数据在内存里面会存在空间局部性
- 数组的连续多个元素会一并加载到CPU Cache里面,所以访问遍历的速度会更快
- 链表里面的各个节点的数据,多半不会出现在相邻的内存空间
- 数据的遍历访问还有一个很大的优势,就是CPU层面的分支预测会很准确
- 可以更有效地利用CPU里面的多级流水线
CAS -> 无锁
缓慢的锁
- Disruptor作为一个高性能的生产者-消费者队列系统,一个核心的设计:通过RingBuffer实现一个无锁队列
- Java里面的LinkedBlockingQueue,比起Disruptor的RingBuffer要慢很多,主要原因
- 链表的数据在内存里面的布局对于高速缓存并不友好
- LinkedBlockingQueue对于锁的依赖
- 一般来说消费者比生产者快(不然队列会堆积),因为大部分时候,队列是空的,生产者和消费者一样会产生竞争
- LinkedBlockingQueue的锁机制是通过ReentrantLock,需要JVM进行裁决
- 锁的争夺,会把没有拿到锁的线程挂起等待,也需要进行一次上下文切换
- 上下文切换的过程,需要把当前执行线程的寄存器等信息,保存到内存中的线程栈里面
- 意味:已经加载到高速缓存里面的指令或者数据,又回到主内存里面,进一步拖慢性能
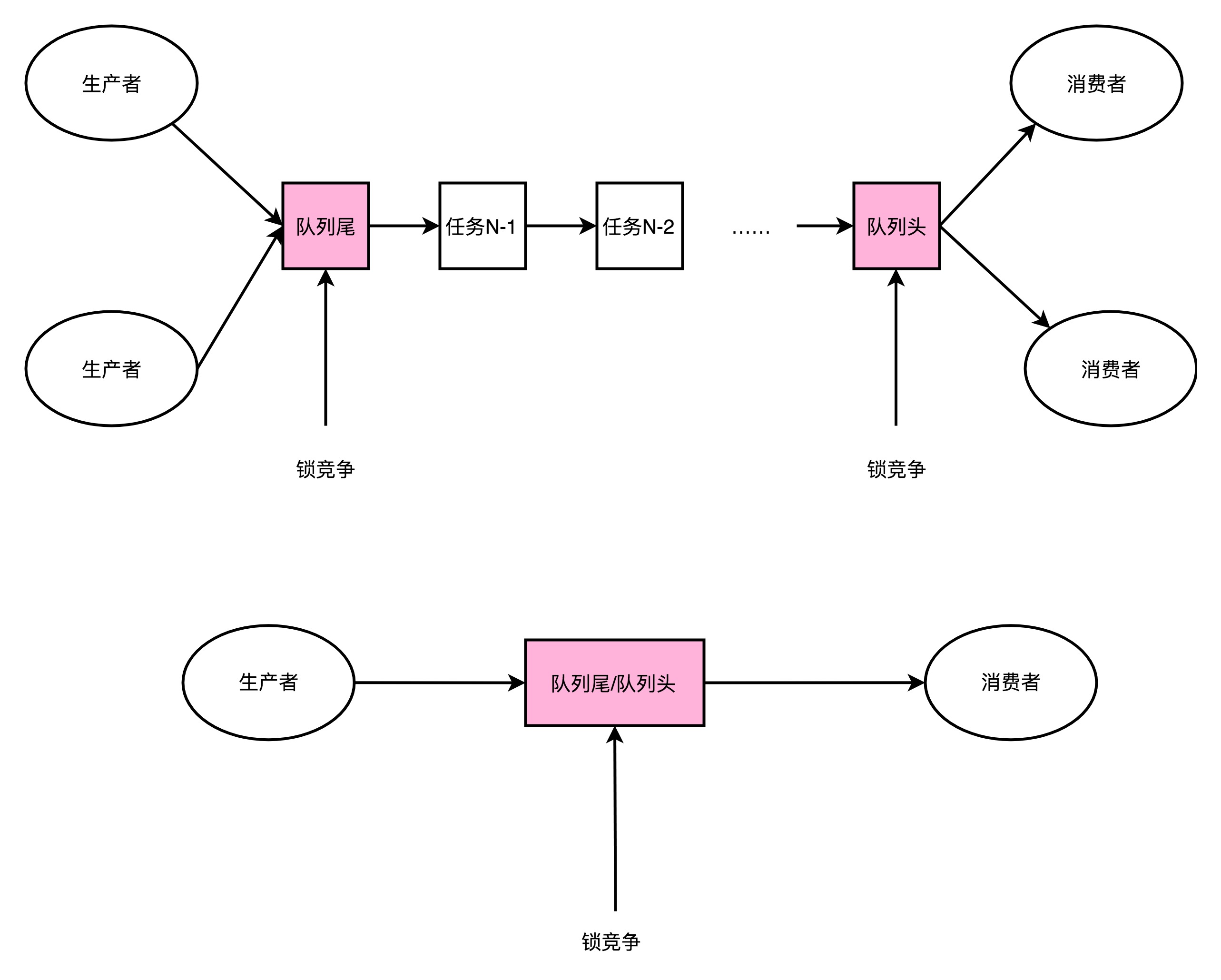
RingBuffer
- 加锁很慢,所以Disruptor的解决方案是无锁(没有操作系统层面的锁)
- Disruptor利用了一个CPU硬件支持的指令,称之为CAS(Compare And Swap)
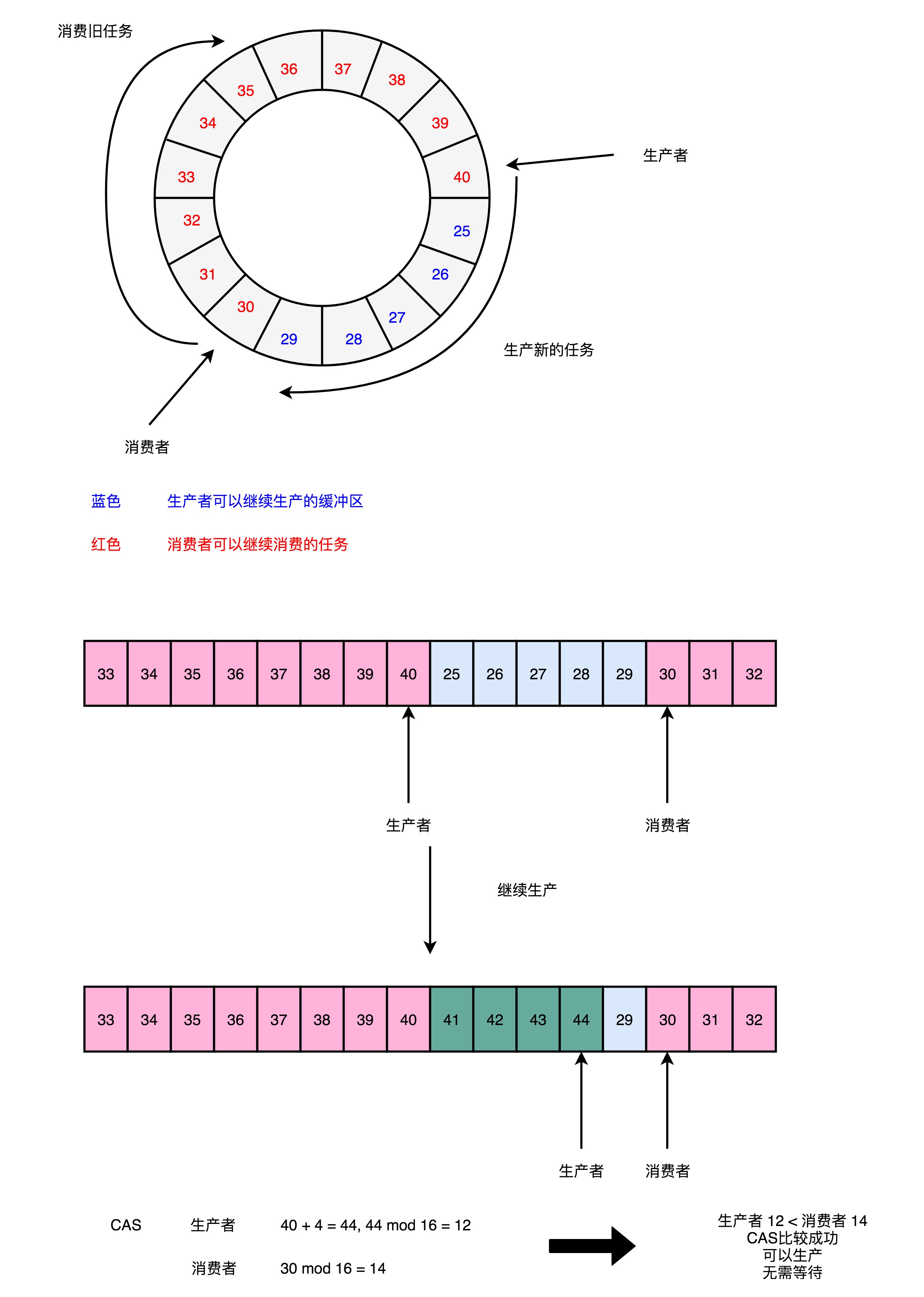
- Disruptor的RingBuffer创建一个Sequence对象,用来指向当前的RingBuffer的头和尾
- 头和尾的标识,不是通过一个指针来实现的,而是通过一个序号
- RingBuffer在进行生产者和消费者之间的资源协调,采用的是对比序号的方式
- 当生产者想要往队列里面加入新数据的时候,会把当前生产者的Sequence的序号,加上需要加入的新数据的数量
- 然后和实际的消费者所在的位置进行对比,看下队列里是不是有足够的空间加入这些数据
- 而不是直接覆盖掉消费者还没处理完的数据
- CAS指令,既不是基础库里的一个函数,也不是操作系统里面实现的一个系统调用,而是一个CPU硬件支持的机器指令
- 在Intel CPU上,为
cmpxchg指令:compxchg [ax] (隐式参数,EAX累加器), [bx] (源操作数地址), [cx] (目标操作数地址) - 第一个操作数不在指令里面出现,是一个隐式的操作数,即EAX累加寄存器里面的值
- 第二个操作数就是源操作数,指令会对比这个操作数和上面EAX累加寄存器里面的值
- 伪代码:
IF [ax]== [bx] THEN [ZF] = 1, [bx] = [cx] ELSE [ZF] = 0, [ax] = [bx] - 单个指令是原子的,意味着使用CAS操作的时候,不需要单独进行加锁,直接调用即可
- 在Intel CPU上,为
1 | public long addAndGet(final long increment) |
Benchmark
1 | public class LockBenchmark { |
参考资料
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2020-01-30
计算机组成 -- IO设备
接口 + 设备 – 适配器模式 大部分的输入输出设备,都有两个组成部分,一个是接口,另一个是实际的IO设备 硬件设备并不是直接接入到总线上和CPU通信的,而是通过接口,用接口连接到总线上,再通过总线和CPU通信 串行接口、USB接口等都是计算机主板上内置的各个接口,实际使用的硬件设备,都需要插入到这些接口上,才能和CPU通信 接口本身是一块电路板,CPU不需要和实际的硬件设备打交道,只需要和这个接口电路板打交道 设备里面的三类寄存器(状态寄存器、命令寄存器、数据寄存器),都在接口电路上,而不在实际的设备上 除了内置在主板上的接口外,有些接口可以集成在设备上 – IDE(Integrated Device Electronics)硬盘 设备的接口电路直接在设备上,只需要通过一个线缆,把集成了接口的设备连接到主板上即可 接口和设备分离:各种输入输出设备的制造商,根据接口的控制协议,来设计各种外设 Windows设备管理器 Devices:着重实际的IO设备本身 Controllers:着重输入输出设备接口里面的控制电路 Adaptors:着重接口作为一个适配器后面可以插上不同的实际设备 C...

2020-01-12
计算机组成 -- 电路
电报机 电报机的本质:蜂鸣器 + 电线 + 按钮开关 蜂鸣器装在接收方,开关留在发送方,双方通过电线连在一起 继电器 电线的线路越长,电线的电阻越大,当电阻很大,而电压不够时,即使按下开关,蜂鸣器也不会响的 继电器(Relay):为了实现接力传输信号 中继:不断地通过新的电源重新放大已经开始衰减的原有信号 中间所有小电报站都使用『螺旋线圈+磁性开关』的方式,来替代蜂鸣器+普通开关 只在电报的始发和终点用普通开关和蜂鸣器 这样就可以将长距离的电报线路,拆成一个个小的电报线路,接力传输电报信号 继电器别名:电驿,驿站的驿 二进制 有了继电器后,输入端通过开关的『开』和『关』表示1和0,输出端也能表示1和0 输出端的作用,不仅仅是通过一个蜂鸣器或者灯泡,提供一个供人观察的输出信号 还可以通过『螺旋线圈+磁性开关』,使得输出也有『开』和『关』两种状态,表示1和0,作为后续线路的输入信号 与(AND) 在输入端的电路上,提供串联的两个开关,只有两个开关都打开,电路才接通,输出的开关才能接通 或(OR) 在输入端的电路上,提供两条独立的线路到输出端 两条线路上各有一个开关,任意一个开关打...

2020-01-01
计算机组成 -- 知识地图
参考资料深入浅出计算机组成原理

2020-01-23
计算机组成 -- 虚拟机
解释型虚拟机 要模拟一个计算机系统,最简单的办法,就是兼容这个计算机系统的指令集 开发一个应用程序,运行在操作系统上,该应用程序可以识别想要模拟的计算机系统的程序格式和指令,然后一条条去解释执行 原先的操作系统称为宿主机(Host),有能力模拟指令执行的软件称为模拟器(Emulator) 实际运行在模拟器上被虚拟出来的系统,称为客户机(Guest VM) 这种方式和运行Java程序的JVM比较类似,只不过JVM运行的是Java中间代码(字节码),而不是一个特定的计算机系统的指令 真实的应用案例:Android模拟器、游戏模拟器 优势 模拟的系统可以跨硬件 Android用的是ARM CPU,开发机用的是Intel X86 CPU,两边的CPU指令集是不一样的,但一样可以正常运行 劣势 无法做到精确模拟 很多老旧的硬件的程序运行,需要依赖特定的电路乃至电路特有的时钟频率,很难通过软件做到100%模拟 性能很差 并不是直接把指令交给CPU去执行,而是要经过各种解释和翻译的工作 编译优化:Java的JIT 把本来解释执行的指令,编译成Host可以直接运行的指令 全虚拟化 全...

2020-01-18
计算机组成 -- 冒险
冒险 流水线架构的CPU,是主动进行的冒险选择,期望通过冒险带来更高的回报 对于各种冒险可能造成的问题,都准备好了应对方案 分类 结构冒险(Structural Hazard) 数据冒险(Data Hazard) 控制冒险(Control Hazard) 结构冒险 结构冒险,本质上是一个硬件层面的资源竞争问题 CPU在同一个时钟周期,同时在运行两条计算机指令的不同阶段,但这两个不同的阶段可能会用到同样的硬件电路 内存的数据访问 第1条指令执行到访存(MEM)阶段的时候,流水线的第4条指令,在执行取指令(Fetch)操作 访存和取指令,都是要进行内存数据的读取,而内存只有一个地址译码器,只能在一个时钟周期内读取一条数据 无法同时执行第1条指令的读取内存数据和第4条指令的读取指令代码 解决方案 解决方案:增加资源 哈佛架构 把内存分成两部分,它们有各自的地址译码器,这两部分分别是存放指令的程序内存和存放数据的数据内存 缺点:无法根据实际情况去动态调整 普林斯顿架构 – 冯.诺依曼体系架构 今天使用的CPU,仍然是冯.诺依曼体系架构,并没有把内存拆成程序内存和数据内存两部分 ...
2020-01-17
计算机组成 -- 指令流水线
单指令周期处理器 一条CPU指令的执行:Fetch -> Decode -> Execute 这个执行过程,最少需要花费一个时钟周期,因为在取指令的时候,需要通过时钟周期的信号,来决定计数器的自增 单指令周期处理器(Single Cycle Processor):在一个时钟周期内,处理器正好能处理一条指令,即CPI为1 时钟周期是固定的,但指令的电路复杂程度是不同的,因此一条指令的实际执行时间是不同的 随着门电路层数的增加,由于门延迟的存在,位数多、计算复杂的指令需要的执行时间会更长 不同指令的执行时间不同,但需要让所有指令都在一个时钟周期内完成,只能把时钟周期和执行时间最长的指令设成一样 快速执行完成的指令,需要等待满一个时钟周期,才能执行下一条指令 CPI能够保持在1,但时钟频率没办法设置太高,因为有些复杂指令是没办法在一个时钟周期内运行完成的 在下一个时钟周期到来,开始执行下一条指令的时候,前一条指令的执行结果可能还没有写入到寄存器里 那么下一条指令读取的数据就是不准确的,会出现错误 无论是PC上使用的Intel CPU,还是手机上使用的ARM CPU,都不是单指令周期...




