
Cloud Native Foundation - Go Thread Scheduling
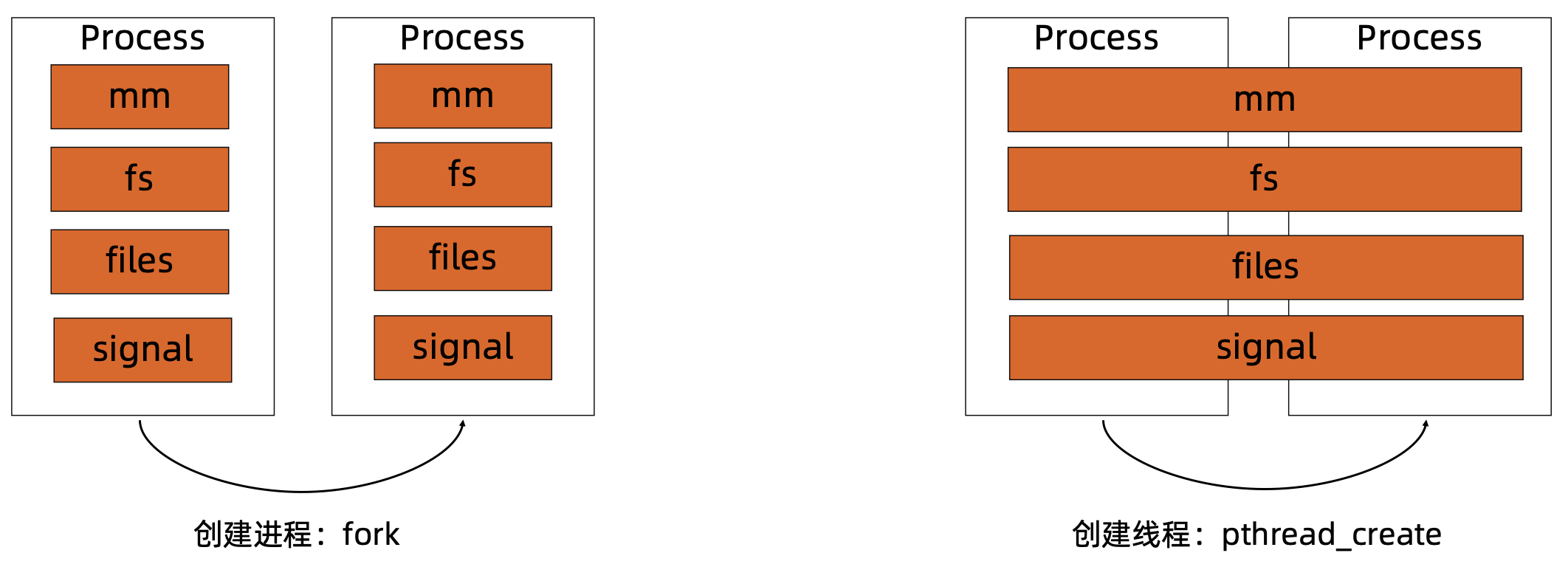
进程 & 线程
- 进程:资源分配的基本单位
- 线程:调度的基本单位
- 在内核视角,线程与进程无本质差别,在 Linux 中都是以**
task_struct**进行描述- glibc 中的 pthread 库提供了
Native POSIX Thread Library支持 - Native POSIX Thread Library (NPTL)
- is an implementation of the POSIX Threads specification for the Linux operating system.
- glibc 中的 pthread 库提供了
- 子进程通过
fork的方式产生,基于父子关系形成进程树,Linux 中的初始进程一般为systemd
1 | $ pmap 1 |
Linux 进程内存
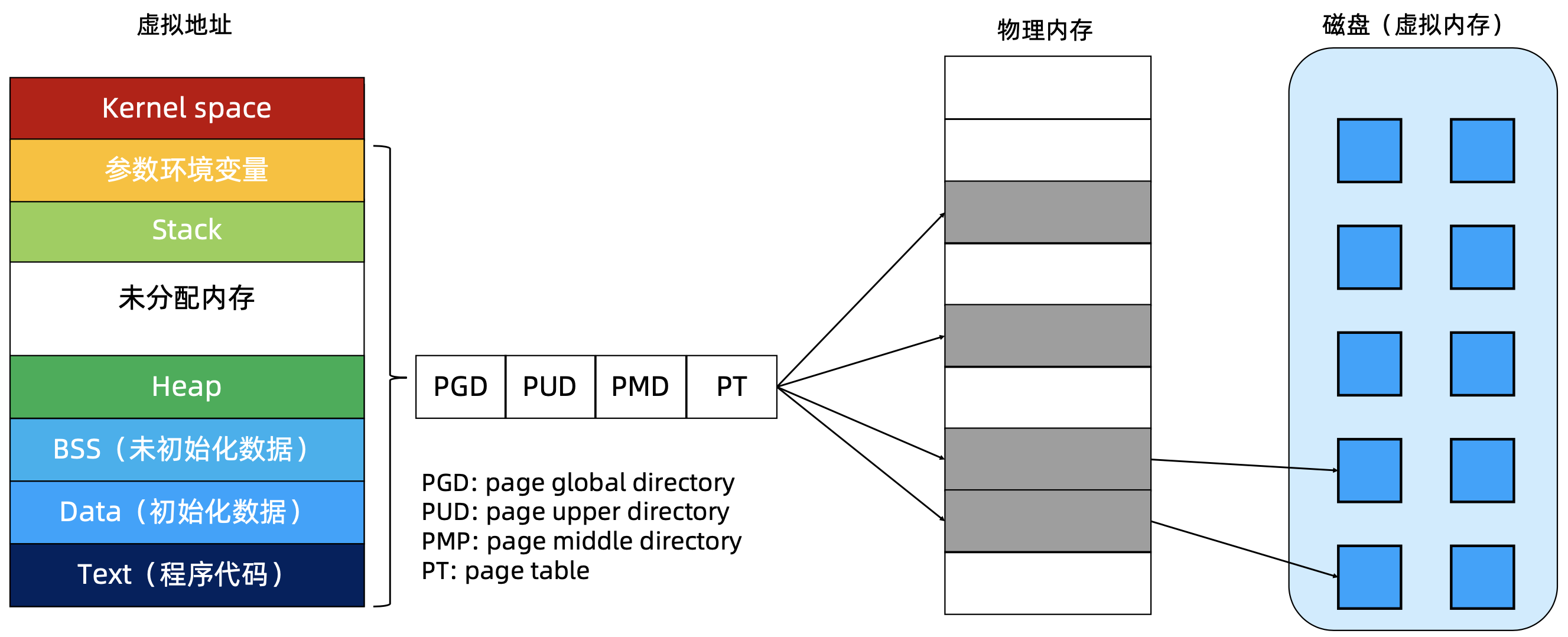
虚拟地址
https://ggirjau.com/text-data-bss-heap-stack-and-where-in-memory-are-stored-variables-of-c-program/
| Segment | Desc |
|---|---|
| .text | contains executable instructions |
| .data | contains any global or static variables which have a pre-defined value and can be modified |
| The values for these variables are initially stored within the read-only memory (typically within .text) and are copied into the .data segment during the start-up routine of the program | |
| .bss | Named after an ancient assembler operator that stood for “block started by symbol” |
| Data in this segment is initialized by the kernel to arithmetic 0 before the program starts executing | |
| Uninitialized data starts at the end of the data segment and contains all global variables and static variables that are initialized to zero or do not have explicit initialization in source code. | |
| Heap | Heap is the segment where dynamic memory allocation usually takes place. |
| The heap area begins at the end of the BSS segment and grows to larger addresses from there. | |
| The Heap area is shared by all shared libraries and dynamically loaded modules in a process. | |
| Stack | The stack area contains the program stack, a LIFO structure, typically located in the higher parts of memory. |
| A “stack pointer“ register tracks the top of the stack; it is adjusted each time a value is “pushed” onto the stack. | |
| The set of values pushed for one function call is termed a “stack frame“. A stack frame consists at minimum of a return address. Automatic variables are also allocated on the stack. 方法中的本地变量会分配到栈上 |
|
| The stack area traditionally adjoined the heap area and they grew towards each other; when the stack pointer met the heap pointer, free memory was exhausted. | |
| On the standard PC x86 architecture the stack grows toward address zero, meaning that more recent items, deeper in the call chain, are at numerically lower addresses and closer to the heap. |
1 | int debug_sesion = 1; |
1 | static int i; |
Go 样例
Go 不支持静态变量,Go 代码本身编译后在 .data 和 .bss 没有值(里面实际存储的是 Go Runtime 的值)
1 | package main |
1 | $ go build main.go |
多级页表
- 页表的作用:虚拟地址与物理地址的映射关系
- 单级页表相当于一一映射,本身就非常浪费内存,为了节省内存,发展出了多级页表(常见为4级)
- 寻址:多级索引 + 页内偏移
1 | $ getconf PAGE_SIZE |
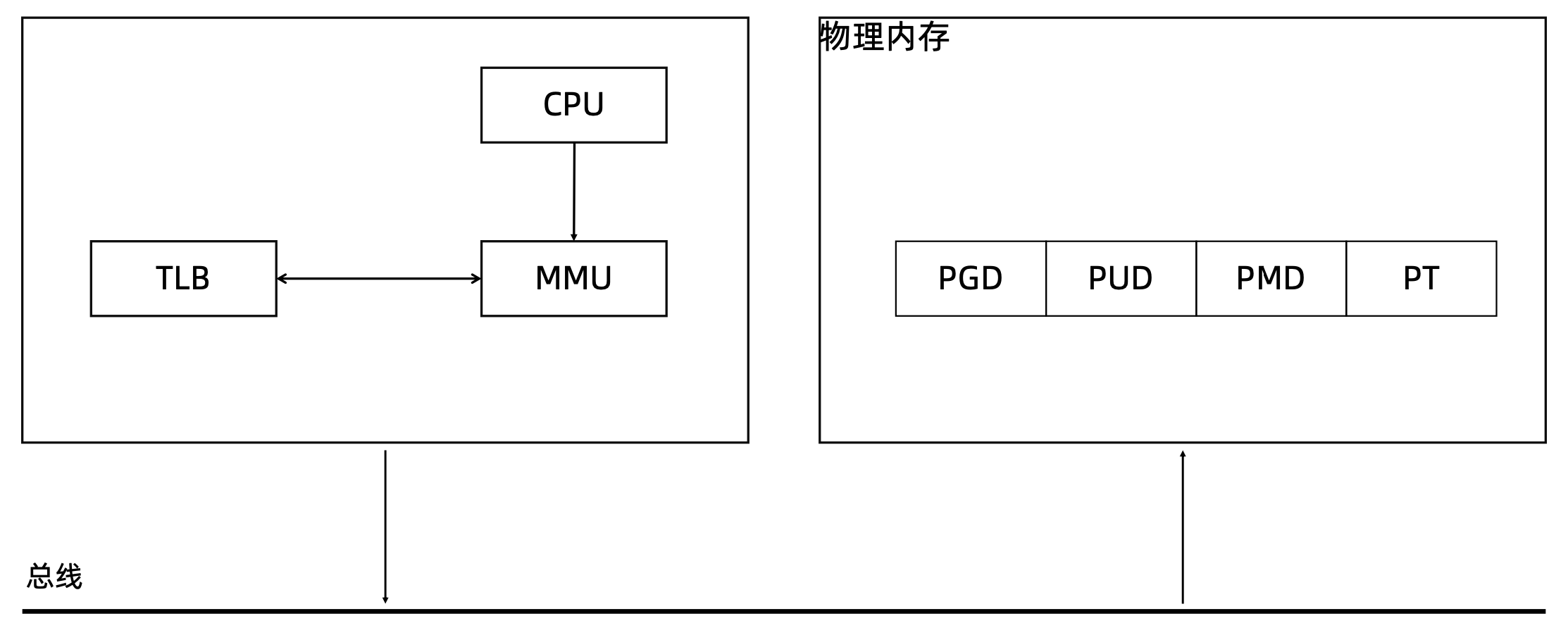
CPU 访问内存
- MMU: Memory Management Unit
- TLB: Translation Lookaside Buffer,用于缓存虚拟地址和物理地址的映射关系
- TLB 在 CPU 内部,比 L1 Cache 都要快
- 注意区分 JVM 中的 TLAB(Thread Local Allocation Buffer)
- 过程(缓存模式:Cache-Aside)
- 第一次访问,CPU 把虚拟地址交给 MMU,MMU 去物理内存中查找多级页表,得到实际的物理地址
- 然后将虚拟地址与物理地址的映射关系缓存到 TLB
- 对于同一个虚拟地址的后续访问,将直接访问 TLB
切换开销
| 内核参与(系统调用) | 虚拟地址空间切换 | |
|---|---|---|
| 进程 | Y | Y |
| 线程 | Y | N |
| 用户线程 - goroutine | N | N |
进程
- 直接开销
- 切换 PGD
- 刷新 TLB
- 切换硬件上下文(即:进程恢复前,必须装入寄存器的数据)
- 切换内核态堆栈
- 系统调度器的代码执行
- 间接开销
- 新切入的进程,由于 CPU 缓存失效,导致该进程直接访问内存的操作变多
线程
- 线程本质上只是一批共享资源的进程,线程切换本质上依然需要内核(系统调用)进行进程切换
- 共享 => 节省
- 进程内的所有线程共享虚拟地址空间 – 即mm,线程切换相比进程切换,主要节省了虚拟地址空间的切换,开销小很多
用户线程
应用程序在用户空间创建的可执行单元(goroutine),创建销毁完全在用户态完成,无需切换,无需内核参与(系统调用)
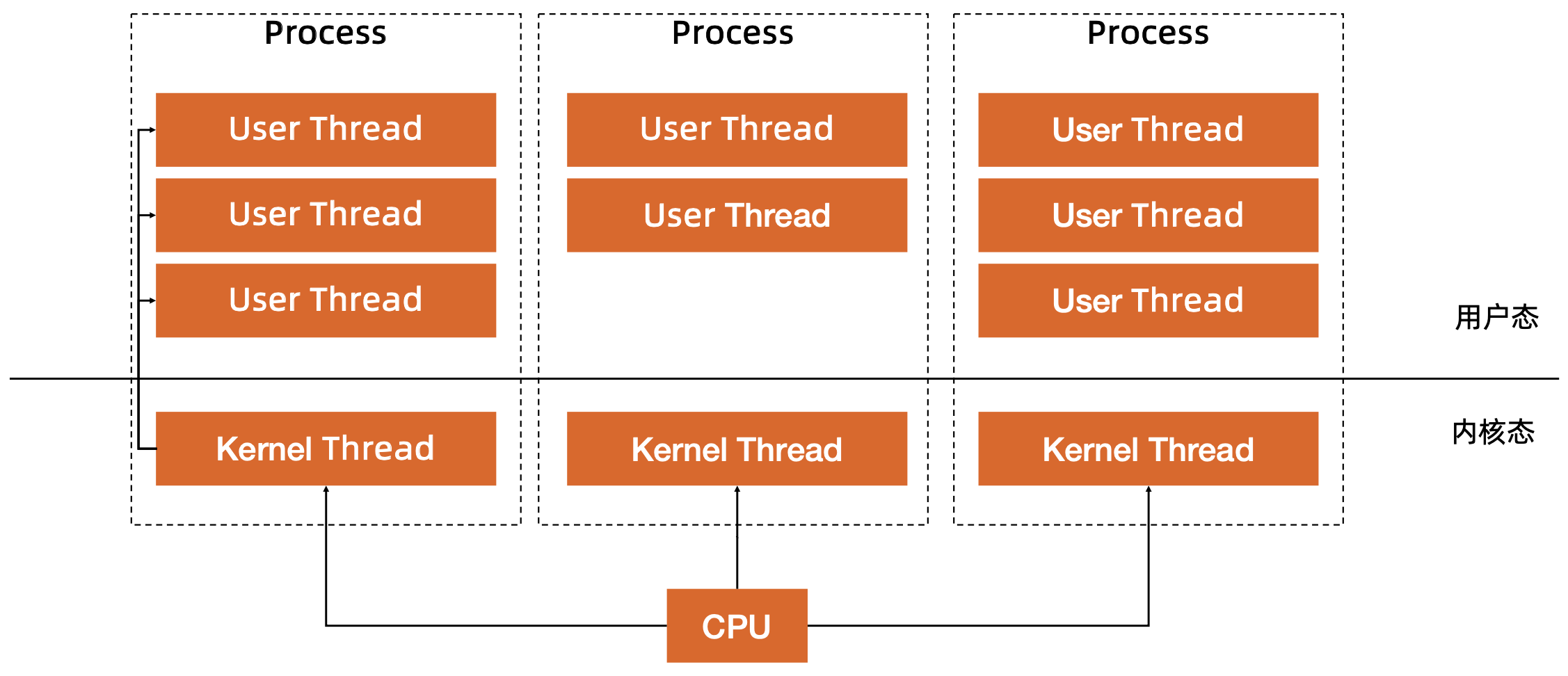
GMP 模型
Go 基于 GMP 模型实现用户态线程
概要
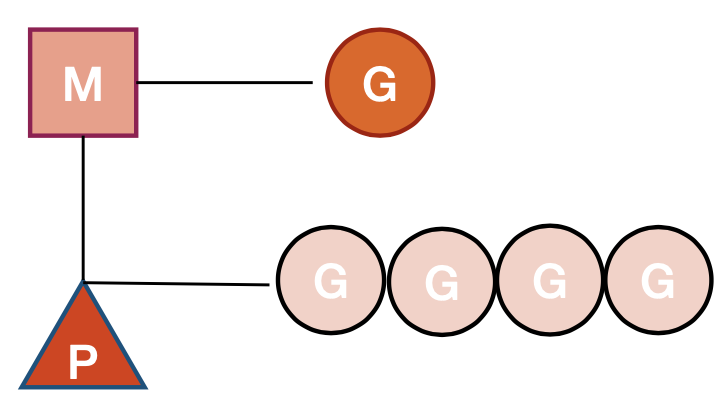
| Component | Desc |
|---|---|
| G : Goroutine | goroutine 每个 goroutine 都有自己的栈空间和和定时器,初始化的栈空间在 2K 左右,后续可能增长 |
| M : Machine | 抽象化代表内核线程,记录内核线程栈信息 当 goroutine 调度到线程时,使用该 goroutine 自身的栈信息 任何运行中的 goroutine 会与某个内核态的线程绑定 |
| P : Processor | 代表调度器,负责调度 goroutine 维护一个本地 goroutine 队列,M 从 P 上获取 goroutine 并执行,同时还负责部分内存的管理 |
KSE: Kernel Scheduling Entity – 轻量级进程
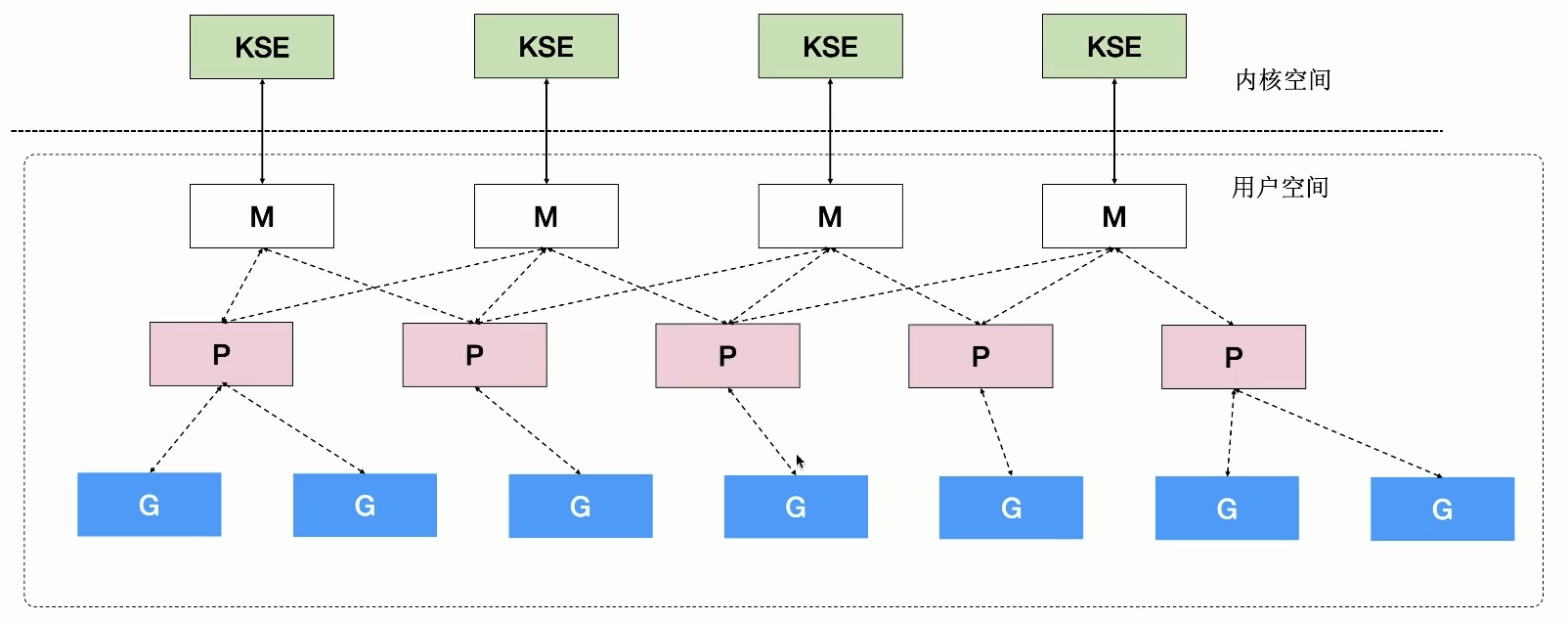
细节
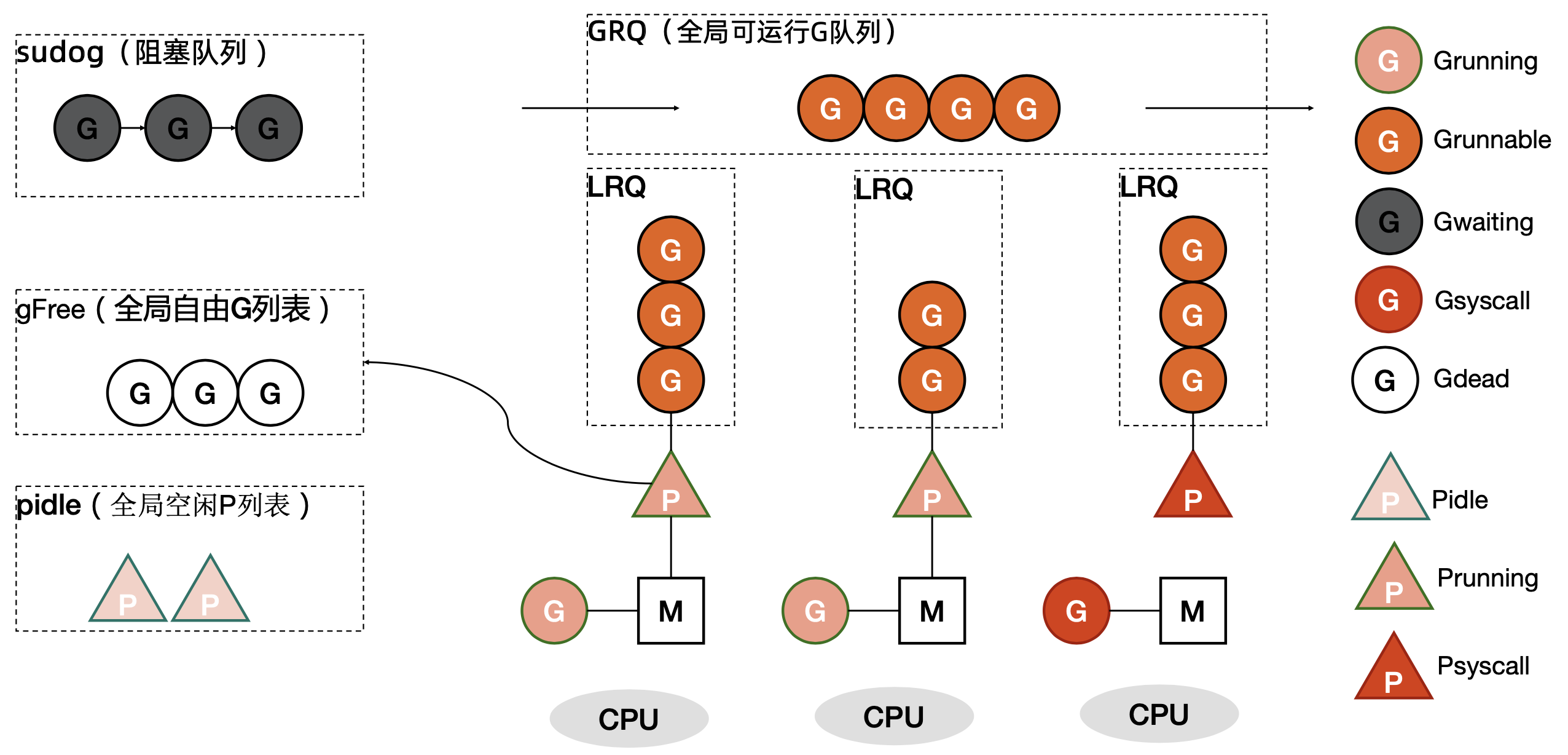
P 状态
| State | Desc |
|---|---|
| _Pidle | 没有运行用户代码或者调度逻辑,执行队列为空 |
| _Prunning | 被 M 持有,并且正在执行用户代码或者调度逻辑 |
| _Psyscall | 没有执行用户代码,当前线程陷入系统调用 |
| _Pgcstop | 被 M 持有,当前 P 由于 GC 被停止 |
| _Pdead | 不再被使用 |
G 状态
| State | Desc |
|---|---|
| _Gidle | 刚被分配还未初始化,值为0,为创建 goroutine 后的默认值 |
| _Grunnable | 没有执行代码,没有栈的所有权,存储在执行队列中(LRQ 或者 GRQ) |
| _Grunning | 正在执行代码,拥有栈的所有权 |
| _Gsyscall | 正在执行系统调用,拥有栈的所有权,与 P 脱离,与 M 绑定 系统调用结束后会被分配到执行队列 |
| _Gwaiting | 被阻塞的 goroutine,阻塞在某个 channel 的发送或者接收队列 |
| _Gdead | 当前 goroutine 未被使用,没有执行代码,分布在 gFree 1. 可能是一个刚初始化的 goroutine 2. 也可能是刚执行完的 goroutine |
| _Gcopystac | 栈正在被拷贝,没有执行代码,不在执行队列上,执行权在 |
| _Gscan | GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 |
G 位置
- 进程都有一个全局的 G 队列
- 每个 P 拥有一个本地执行队列 LRQ
- 不在执行队列(LRQ 或者 GRQ)中的 G
- 处于 channel 阻塞态的 G 被放在 sudog
- 脱离 P 绑定在 M 上的 G,例如系统调用
- 为了复用,执行结束后进入 P 的 gFree 列表中的 G
创建 G
- 创建过程
- 从 P 的 gFree 列表中查找空闲的 goroutine
- 如果不存在空闲的 goroutine,会创建一个栈大小足够的新结构体
- 将函数传入的参数移到 goroutine 的栈上
- 更新 goroutine 调度相关的属性,更新状态为 _Grunnable
- 返回的 goroutine 会存储到全局变量 allgs 中
G -> Q
- 首先尝试将 G 放入对应的 LRQ
- 如果 LRQ 已经满了(256),会把 LRQ 中的一部分 G 和待加入的 G 一起放到 GRQ
P
- 为了保证公平,当 GRQ 中有 G,首先以一定的概率(1/61)尝试从 GRQ 中获取 G,获取失败再尝试从 LRQ 中获取
- 如果还是失败,则随机从其他 P 对应的 LRQ 中获取 G
M & P
- 默认情况下,P 的数量 = CPU 个数,可以通过
GOMAXPROCS修改,上限为256 - M 的数量为内核线程数量,M > P,上限为10,000
- P 的数量在调度器初始化的 procresize 中控制
- 当调度器进行调度,唤醒 P 的时候,会尝试获取 idle m,如果获取不到,则创建新的 M(内核线程)
- 因为 M 可能陷入系统调用,而系统调用可能是阻塞的,如 IO,此时 CPU 是空闲的
- 创建新的 M 与 P 关联,可以让更多的 G 被调度,充分利用 CPU
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2022-10-08
Cloud Native Foundation - Go Scheduling
线程加锁 线程安全 123456789// fatal error: concurrent map writesfunc unsafeWrite() { conflictMap := map[int]int{} for i := 0; i < 1<<10; i++ { go func(i int) { conflictMap[0] = i }(i) }} 锁 Go 不仅支持基于 CSP 的通信模型,也支持基于共享内存的多线程数据访问 Sync 包提供了锁的基本原语 原语 描述 sync.Mutex 互斥锁 sync.RWMutex 读写分离锁 sync.WaitGroup 等待一组 goroutine 返回 sync.Once 保证某段代码只执行 1 次 sync.Cond 让一组 goroutine 在满足特定条件时被唤醒 Mutex12345678910111213141516171819...

2022-12-22
Go - Variable
内存边界 在编程语言中,为了方便操作内存特定位置的数据,使用变量与特定位置的内存绑定 编译器或者解析器需要知道变量所能引用的内存区域边界 动态语言 解析器可以在运行时通过对变量赋值的分析,自动确定变量的边界 一个变量可以在运行时被赋予大小不同的边界 静态语言 编译器必须明确知道一个变量的边界才允许使用该变量 但编译器无法自动分析,因此边界信息必须由开发者提供 - 变量声明 在具体实现层面,边界信息由变量的类型属性赋予 变量声明 Go 是静态语言,所有变量在使用前必须先进行声明声明:告诉编译器该变量可以操作的内存的边界信息(由变量类型信息提供) 通用 变量声明形式与主流静态语言的差异 - 将变量名放在了类型前面(方便语法糖移除 type) 如果没有显式为变量赋予初值,Go 编译器会为变量赋予类型零值 1var a int // a 的初值为 int 类型的零值 0 Go 的每种原生类型都有其默认值,即类型零值复合类型(array、struct)变量的类型零值为组成元素都为零值的结果 原生类型 类型零值 整型 0 浮点 0.0 布尔 FALSE 字符...

2022-04-16
Go Engineering - Foundation - API - RPC
RPC Client 通过本地调用,调用 Client Stub Client Stub 将参数打包(Marshalling)成一个消息,然后发送这个消息 Client 所在的 OS 将消息发送给 Server Server 接收到消息后,将消息传递给 Server Stub(或者 Server Skeleton) Server Stub 将消息解包(Unmarshalling)后得到消息 Server Stub 调用服务端的子程序,处理完成后,将最终结果按照相反的步骤返回给 Client gRPC概述 gRPC:google Remote Procedure Call gRPC 是由 Google 开发的高性能、开源、跨语言的通用 RPC 框架,基于 HTTP 2.0,默认使用 Protocol Buffers 序列化 gRPC 的特点 支持多语言 基于 IDL(Interface Definition Language)文件定义服务 通过 proto3 生成指定语言的数据结构、服务端接口和客户端 Stub 通信协议基于标准的 HTTP/2,支持特性:双向流、消息头压缩、单 T...

2022-03-27
Go Engineering - Specification - Workflow
集中式 在本地仓库的 master 分支开发,将修改后的代码 commit 到远程仓库,如有冲突先本地解决再提交 适合场景:团队人员少、开发不频繁、不需要同时维护多个版本的小项目 功能分支 12345678910# git checkout -b feature/rate-limiting# git add limit.go# git commit -m "add rate limiting"# git push origin feature/rate-limiting# Github: Compare & pull request -> Create pull request# Github: Code Review -> Merge pull request Merge PR Create a merge commit – 推荐 底层操作:git merge --no-ff With --no-ff, create a merge commit in all cases, even when the merge could instead be...

2022-12-11
Go - Design Philosophy
简单 语言特性始终保持少且足够的水平,不走语言融合的道路,简单的设计哲学是 Go 生产力的源泉 仅有 25 个关键字,主流编程语言最少 内置 GC,降低开发人员内存管理的心智负担 首字母大小写决定可见性,无需通过额外关键字修饰 变量初始为类型零值,避免以随机值作为初值的问题 内置数组边界检查,极大减少越界访问带来的安全隐患 内置并发支持,简化并发程序设计 内置接口类型,为组合的设计哲学奠定基础 原生提供完善的工具链,开箱即用 显式 Go - 程序员应该明确知道在做什么;C - 信任程序员 Go 不允许不同类型的变量进行混合计算,也不会进行隐式自动转换 Go 采用基于值比较的错误处理方案 函数或方法的错误会通过 return 语句显式地返回,并且调用者通常不能忽略对返回的错误的处理 组合 组合是构建 Go 程序骨架的主要方式,可以大幅度降低程序元素间的耦合,提高程序的可扩展性和灵活性 在 Go 中,找不到经典的 OOP 语法元素、类型体系和继承机制,Go 推崇的是组合的设计哲学 提供正交的语法元素,以供后续组合使用 包之间相对独立,没有子包的概念 没有类型层次体系,各类型之间互相独...

2022-04-16
Go Engineering - Specification - Design Pattern
GoF 创建型模式 提供一种在创建对象的同时隐藏创建逻辑的方式,而不是直接使用 new 运算符直接实例化对象 单例模式 分为饿汉方式(包被加载时创建)和懒汉方式(第一次使用时创建) 饿汉方式1234567891011package hungertype singleton struct {}// 实例是在包被导入时被初始化的var ins *singleton = &singleton{}func GetIns() *singleton { return ins} 懒汉方式 非并发安全,需要加锁 1234567891011121314151617181920package singletonimport "sync"type singleton struct {}var ins *singletonvar lock sync.Mutexfunc GetIns() *singleton { if ins == nil { lock.Lock(...




