
Docker Foundation - Namespace + Cgroup
概要
- 基于 Linux Kernel 的 Cgroup、Namespace、Union FS 等技术,对进程进行封装隔离,属于 OS 层面的虚拟化技术
- 由于被隔离的进程独立于宿主机和其它被隔离的进程,因此称为容器
- 演变历史
- 最早基于 LXC – a linux container runtime
- 0.7:去除 LXC,转而使用自研的
Libcontainer - 1.11:使用
runC和containerd
- Docker 在容器的基础上,进行了进一步的封装,极大地简化了容器的创建和维护
Docker vs VM
Docker Engine 是一个 Daemon 进程,启动一个容器的时候,相当于执行了一次进程的 Fork 操作

| Container | VM | |
|---|---|---|
| 启动时间 | 秒级 | 分钟级 |
| 硬盘使用 | MB 级别 | GB 级别 |
| 性能 | 接近原生 | 弱于 |
| 单机支持量 | 上千 | 几十 |
容器标准
- OCI – Open Container Initiative
- K8S 的主要贡献:标准化
- 后期 Docker 公司不得不让步,兼容 OCI 标准
- 核心规范:Image + Runtime
- Image Specification
- Docker 公司的主要贡献:基于 Union FS,创造了 Image,解决了容器分发的问题
- 如何通过构建系统打包、生成镜像清单(Manifest)、文件系统序列化文件、镜像配置
- Runtime Specification
- Cgroup(由 Google 开源) + Namespace
- 文件系统如何解压到硬盘、Runtime 运行
- Image Specification
Namespace
隔离性
概念
- Linux Namespace 是一种 Linux Kernel 提供的资源隔离方案
- Kernel 为进程分配不同的 Namespace,不同的 Namespace 下的进程互不干扰
- Linux 进程在运行时都会归属于某个 Namespace
1 | struct task_struct { |
1 | struct nsproxy { |
场景
- clone
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg)- 1 号进程一般是
systemd,会有默认的 Namespace - 创建新进程时,可以通过
flags指定需要新建的 Namespace- CLONE_NEWCGROUP
- CLONE_NEWIPC
- CLONE_NEWNET
- CLONE_NEWNS
- CLONE_NEWPID
- CLONE_NEWUSER
- CLONE_NEWUTS
- setns
int setns(int fd, int nstype)- 让调用进程加入已经存在的 Namespace 中
- unshare
int unshare(int flags)- 让调用进程移动到新的 Namespace 中
- Run a program with some namespaces unshared from the parent.
1 | # ls -l /proc/1/ns |
分类
systemd Namespace 一般就是主机 Namespace
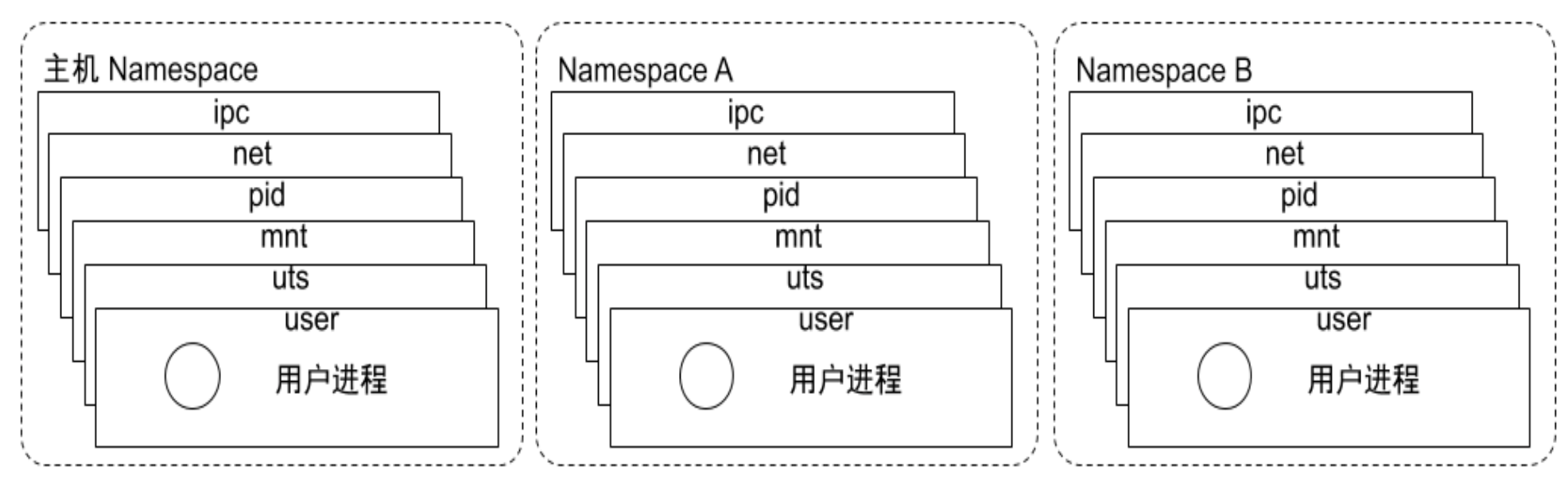
| Type | Resource | Kernel |
|---|---|---|
| PID | 进程 | 2.6.14 |
| Network | 网络设备、网络协议栈、网络端口 | 2.6.29 |
| IPC | System V IPC 和 POSIX 消息队列 | 2.6.19 |
| Mount | 挂载点 | 2.4.19 |
| UTS | 主机名、域名 | 2.6.19 |
| USR | 用户、用户组 | 3.8 |
- pid namespace
- 不同用户的进程是通过 pid namespace 进行隔离,不同 namespace 中可以有相同的 pid
- 每个 namespace 中的 pid 可以相互隔离
- net namespace
- 网络隔离通过 net namespace 实现
- 每个 net namespace 有独立的 network devices、ip addresses、ip routing tables、/proc/net等
- Docker 默认采用 veth(Virtual Ethernet devices) 的方式
- 将 container 中的虚拟网卡同 host 上的一个 docker bridge:docker0 连接在一起
- 网络隔离通过 net namespace 实现
- ipc namespace
- container 中的进程交互采用的还是 Linux 进程交互的方法:信号量、消息队列、共享内存等
- container 的进程间交互实际上还是 host 上具有相同 pid namespace 中的进程间交互
- 在 ipc 资源申请时加入 pid namespace 的信息
- 每个 ipc 资源有一个唯一的32位ID
- mnt namespace
- 允许不同 namespace 的进程看到不同的文件结构
- uts namespace
- UTS – UNIX Time-sharing System
- 允许每个 container 拥有独立的 hostname 和 domain name
- 使其在网络上被视为一个独立的节点而非 host 上的一个进程
- user namespace
- 每个 container 可以有不同的 user 和 group id
- 在 container 内部用 container 内部的用户执行程序而非 host 上的用户
1 | # ip a show docker0 |
container 中的 eth0@if13 与宿主机上的 docker0 连接在一起
1 | # docker run -it --rm busybox ip a show eth0 |
操作
container id: afde0a1ff737, pid@host: 1771
1 | # docker run -it --rm centos bash |
1 | # lsns |
1 | # ls -l /proc/1771/ns |
nsenter是常用调试命令,适用场景:container 本身没有太多可用命令
1 | # nsenter -t 1771 -n ip a show eth0 |
Cgroup
可配额
概念
- Cgroup(Control Group):Linux 下对一个或者一组进程进行资源控制的机制
- 资源分类:CPU 使用时间、内存、磁盘 IO 等
- 不同资源的具体管理工作由相应的 Cgroup 子系统来实现
- 针对不同类型的资源限制,只需要将限制策略在不同的子系统上进行关联即可
- Cgroup 在不同的系统资源管理子系统中以层级树的方式来组织管理
- 每个 Cgroup 可以包含其他子 Cgroup,子 Cgroup 受到 父 Cgroup 设置的资源限制
Cgroup Driver
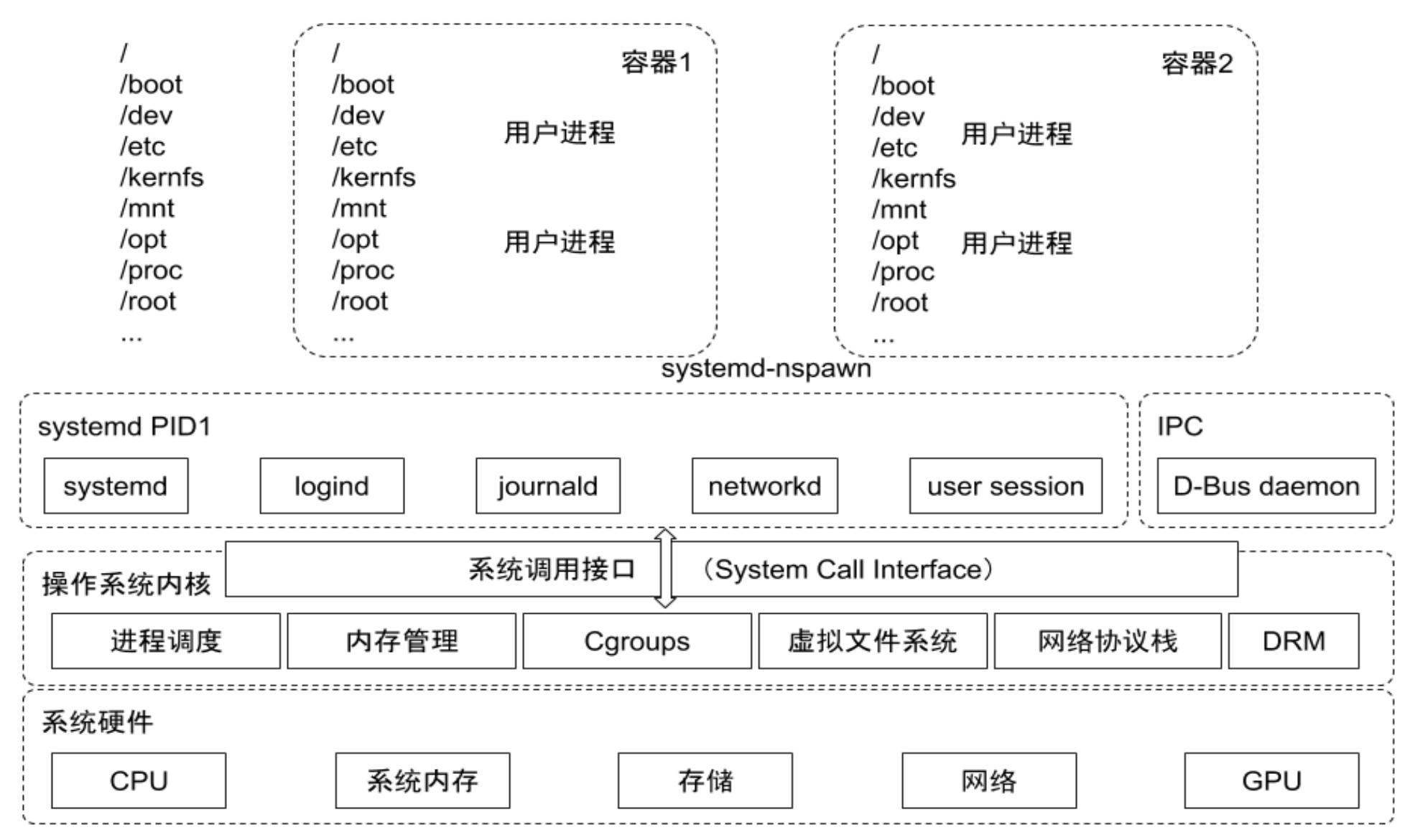
- Cgroup 本身需要一个
driver去实现(通过控制文件去实现功能),systemd 在启动时会加载该文件系统 - systemd
- 当操作系统使用 systemd 作为 init system 时,初始化进程会生成一个根 cgroup 目录并作为 cgroup 管理器
- systemd 与 cgroup 紧密结合,并且为每个 systemd unit 分配 cgroup
- Docker
- Docker 默认使用 cgroupfs 作为 cgroup driver
- 问题
- 在 systemd 作为 init system 的系统中,默认并存两套 cgroup driver,管理混乱
- 因此,kubelet 会默认
--cgroup-driver=systemd
子系统
资源分类:可压缩资源(cpu等)、不可压缩资源(memory等)
| 子系统 | 描述 |
|---|---|
| blkio | 设置限制每个块设备的输入输出控制 |
| cpu | 控制一个进程可以使用多少 CPU |
| cpuacct | 产生 cgroup 任务的 CPU 资源报告 |
| cpuset | 绑核:如果是多核 CPU,为 cgroup 任务分配单独的 CPU 和内存 |
| devices | 允许或者拒绝 cgroup 任务对设备的访问 |
| freezer | 暂停和恢复 cgroup 任务 |
| memory | 设置每个 cgroup 的内存限制以及产生内存资源报告 |
| net_cls | 标记每个网络包以供 cgroup 方便使用 |
| ns | 命名空间 |
| pid | 进程标识 |
cpu
| 配置项 | 描述 |
|---|---|
| cpu.shares | 可出让的能获得 CPU 使用时间的相对值 |
| cpu.cfs_period_us | 配置时间周期长度,单位为微秒 |
| cpu.cfs_quota_us | 配置当前 cgroup 在 cfs_period_us 时间内最多能使用的 CPU 时间数,单位是微秒 |
| cpu.stat | cgroup 内的进程使用 CPU 的时间统计 |
| nr_periods:经过 cpu.cfs_period_us 的时间周期数量 | |
| nr_throttled:在经过的周期内,进程因为在指定的时间周期内用光了配额时间而受到限制的次数 | |
| throttled_time:cgroup 中的进程被限制使用 CPU 的总用时,单位纳秒 |
1 | # pwd |
shares
1 | # cat cpu/cpu.shares |
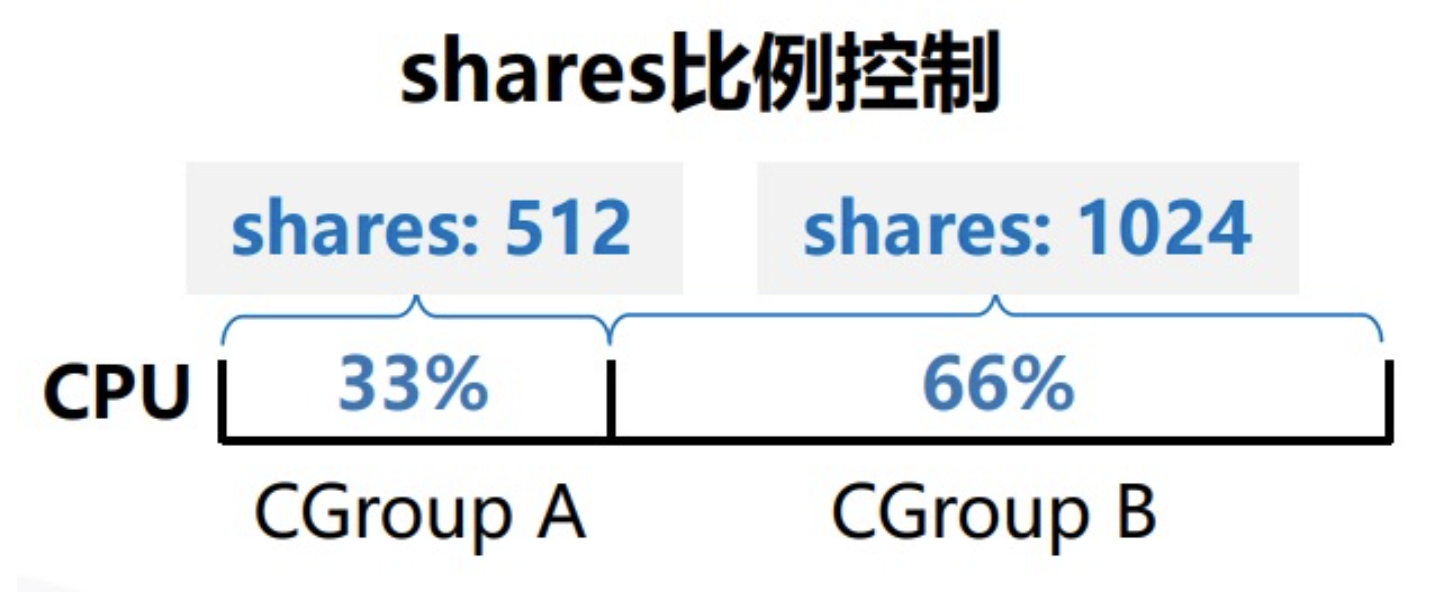
流量控制
cfs_period_us 和 cfs_quota_us 控制进程使用 CPU 的绝对值
cfs_period_us 的视角是单个 CPU
1 | # cat cpu/cpu.cfs_period_us |

样例
1 | # cd cpu && mkdir cpudemo && ls cpudemo |
1 | package main |
1 | # lscpu | grep 'CPU(s):' |
1 | # echo 66313 > /sys/fs/cgroup/cpu/cpudemo/cgroup.procs |
1 | # echo 10000 > /sys/fs/cgroup/cpu/cpudemo/cpu.cfs_quota_us |
1 | # cat /sys/fs/cgroup/cpu/cpudemo/cpu.stat |
cpuacct
容器技术是一系列技术的组合,Linux 本身是没有容器的概念的,因此容器内部执行 top 命令,看到的是宿主机的内容
| 配置项 | 描述 |
|---|---|
| cpuacct.usage | 包含该 cgroup 及其子 cgroup 下进程使用 CPU 的时间,单位纳秒 |
| cpuacct.stat | 包含该 cgroup 及其子 cgroup 下进程使用 CPU 的时间,以及用户态和内核态的时间 |
1 | # ls /sys/fs/cgroup/cpu/cpudemo/cpuacct.* |
memory
| 配置项 | 描述 |
|---|---|
| memory.usage_in_bytes | cgroup 下进程使用的内存,包含 cgroup 及其子 cgroup 下的进程使用的内存 |
| memory.max_usage_in_bytes | cgroup 下进程使用内存的最大值,包含子 cgroup 的内存使用量 |
| memory.limit_in_bytes | 设置 cgroup 下进程最多能使用的内存, -1 = 不限制 |
| memory.soft_limit_in_bytes | 这个限制并不会阻止进程使用超过限额的内存,只是在系统内存足够时,会优先回收超过限额的内存 |
| memory.oom_control | 设置是否在 cgroup 中使用 OOM Killer,默认为使用 |
https://blog.zhongmingmao.top/2022/03/07/cloud-native-foundation-docker-foundation-namespace-cgroup/
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2022-07-09
Kubernetes - Registry

2022-07-02
Kubernetes - Docker Principle

2022-09-26
Kubernetes - Docker Hub
Registry Registry -> Repository Docker Hub 默认 Registry ImageOfficial Dockerhttps://hub.docker.com/u/library Verified Bitnami / Rancher / Ubuntu Unofficial半官方 开通 Verified publisher,需要付费 民间 个人镜像 Naming user/app:tagtag = version + osslim / fat OS Example Alpine / CentOS alpine3.15 Ubuntu 18.04 bionic Ubuntu 20.04 focal Debian 9 stretch Debian 10 buster Debian 11 bullseye FlowOnline1234567$ docker login -u zhongmingmaoPassword:WARNING! Your pas...

2022-09-18
Kubernetes - Containerization
镜像 只读:依赖的文件系统、依赖库、环境变量、启动参数等 核心解决的问题:应用分发 应用容器化 应用不再直接与 OS 打交道,而是封装成镜像,再交给容器环境去运行 常用命令镜像 命令 作用 docker pull 从远端仓库拉取镜像 docker images 列出当前本地已有的镜像 docker rmi 删除不再使用的镜像 容器12$ docker run -h srv --rm alpine hostnamesrv 1234567891011121314151617181920$ docker run -d nginx:alpine6376e2649ef2d4a6073b977fcc4408f7a3f21b6f32775b42be85711b989dd6ce$ docker run -d --name redis_srv redis2a79d491ecb3108b07df7d369dfe8abc6ac314efc2054951ef7b77e0deba0584$ docker run -it --name ubuntu ubuntu sh# cat /etc/o...

2022-07-10
Kubernetes - Communicate
存储 网络

2022-07-01
Kubernetes - Docker Overview




