Kubernetes - etcd
概述
CoreOS基于Raft开发的分布式KV存储,可用于服务发现、共享配置和一致性保障(Leader 选举、分布式锁)
A distributed, reliable key-value store for the most
critical dataof adistributed system
| Key | Desc |
|---|---|
KV 存储 |
将数据存储在分层组织的目录中,类似于标准的文件系统 |
监测变更 |
监测特定的 Key 或者目录以进行变更,并对值的更改做出反应 |
| 简单 | curl: HTTP + JSON |
| 安全 | TLS 客户端证书认证,有一套完备的授权认证体系,但 Kubernetes 并没有使用 |
| 快速 | 单实例:1000 TPS、2000 QPS |
| 可靠 | 使用 Raft 算法保证分布式一致性 |
主要功能
- 基本的
KV存储 - Kubernetes 使用最多 监听机制- Key 的
过期和续约机制,用于监控和服务发现 - 原生支持
Compare And Swap和Compare And Delete,用于Leader 选举和分布式锁
KV存储
- KV 存储,一般都会比关系型数据库
快 - 支持
动态存储(内存,用于索引,基于B Tree)和静态存储(磁盘,基于B+ Tree) 分布式存储,可构成多节点集群- 高可用的 Kubernetes 集群,依赖于
高可用的 etcd 集群
- 高可用的 Kubernetes 集群,依赖于
- 存储方式:类似
目录结构(B+ Tree)- 只有
叶子节点才能真正存储数据,相当于文件 非叶子节点是目录(不能存储数据)
- 只有
服务注册与发现
强一致性、高可用的服务存储目录- 基于
Raft算法
- 基于
- 服务
注册+ 服务健康监控- 在 etcd 中注册服务,并对注册的服务配置
Key TTL,保持心跳以完成 Key 的续约
- 在 etcd 中注册服务,并对注册的服务配置
消息发布与订阅:
List & Watch
- 应用在启动时,主动从 etcd 获取一次配置信息,同时在 etcd 节点上注册一个
Watcher并等待 - 后续配置变更,etcd 会
实时通知订阅者
安装
下载解压
1 | ETCD_VER=v3.4.26 |
1 | export ETCD_UNSUPPORTED_ARCH=arm64 |
本地启动
listen-client-urlsandlisten-peer-urls- specify the local addresses etcd server binds to for
accepting incoming connections.
- specify the local addresses etcd server binds to for
advertise-client-urlsandinitial-advertise-peer-urls- specify the addresses
etcd clientsor otheretcd membersshould use to contact theetcd server. - The
advertise addressesmust bereachablefrom theremote machines.
- specify the addresses
1 | $ /tmp/etcd-download-test/etcd \ |
简单使用
1 | $ /tmp/etcd-download-test/etcdctl --endpoints=localhost:12379 member list --write-out=table |
1 | $ /tmp/etcd-download-test/etcdctl --endpoints=localhost:12379 put /k v1 |
etcdctl --debug类似于kubectl -v 9
1 | $ /tmp/etcd-download-test/etcdctl --endpoints=localhost:12379 get --prefix / --keys-only --debug |
Kubernetes 使用 etcd:/api/v1/namespaces/default 在 etcd 中的 Key 是
一致的,Value 为 API 对象的Protobuf值
1 | $ k get ns default -v 9 |
双向 TLS 认证
| Options | Value |
|---|---|
--name |
mac-k8s |
--initial-cluster |
mac-k8s=https://192.168.191.138:2380 |
--listen-client-urls |
https://127.0.0.1:2379,https://192.168.191.138:2379 |
--listen-peer-urls |
https://192.168.191.138:2380 |
--advertise-client-urls |
https://192.168.191.138:2379 |
--initial-advertise-peer-urls |
https://192.168.191.138:2380 |
--cert-file |
/etc/kubernetes/pki/etcd/server.crt |
--key-file |
/etc/kubernetes/pki/etcd/server.key |
--trusted-ca-file |
/etc/kubernetes/pki/etcd/ca.crt |
--peer-cert-file |
/etc/kubernetes/pki/etcd/peer.crt |
--peer-key-file |
/etc/kubernetes/pki/etcd/peer.key |
--peer-trusted-ca-file |
/etc/kubernetes/pki/etcd/ca.crt |
--data-dir |
/var/lib/etcd |
--snapshot-count |
10000 |
1 | $ ps -ef | grep etcd |
etcd 的数据不能存储在容器中,因为容器的rootfs是基于Overlay,本身性能很低
| Options | Desc |
|---|---|
--cacert |
verify certificates of TLS-enabled secure servers using this CA bundle |
--cert |
identify secure client using this TLS certificate file |
--key |
identify secure client using this TLS key file |
1 | $ sudo /tmp/etcd-download-test/etcdctl --endpoints https://192.168.191.138:2379 \ |
TTL & CAS
TTL– Kubernetes 中用的比较少- 常用于
分布式锁,用于保证锁的实时有效性
- 常用于
CAS– 由CPU架构保证原子性- 在对 Key
赋值时,客户端需要提供一些条件,当条件满足时,才能赋值成功
- 在对 Key
常用条件
| Key | Desc |
|---|---|
prevExist |
Key 当前是否存在 |
prevValue |
Key 当前的值 |
prevIndex |
Key 当前的 Index |
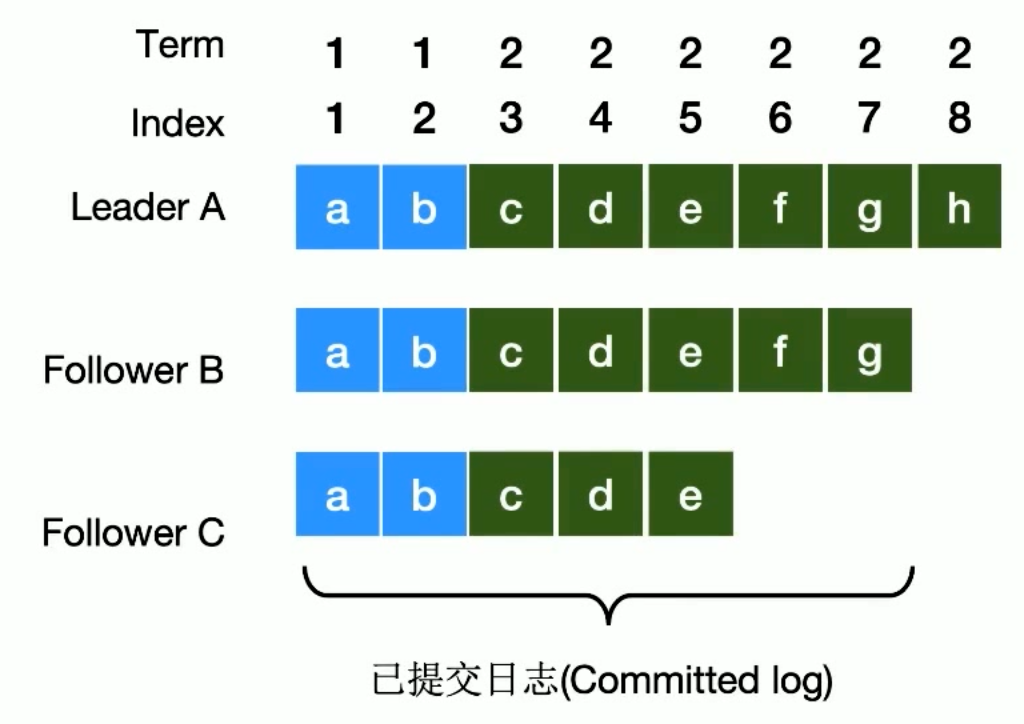
Raft
Raft 基于
Quorum机制,即多数同意原则,任何的变更都需要超过半数的成员确认
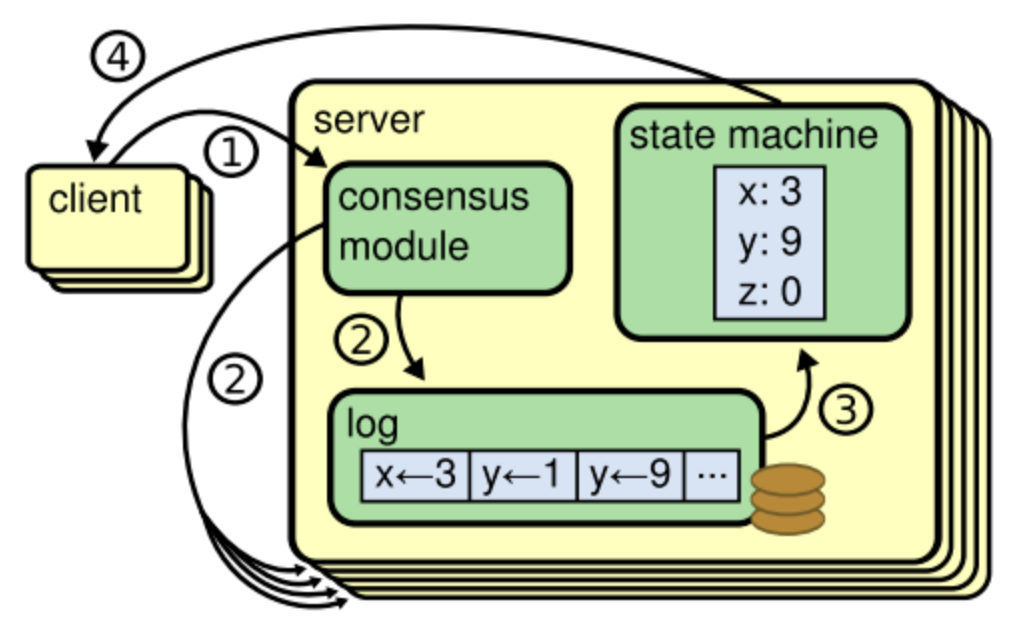
日志模块一开始将数据记录到本地,尚未确认,一致性模块得到
超过半数的成员确认后,才会将数据持久化到状态机
协议
Raft is a protocol for implementing
distributed consensus
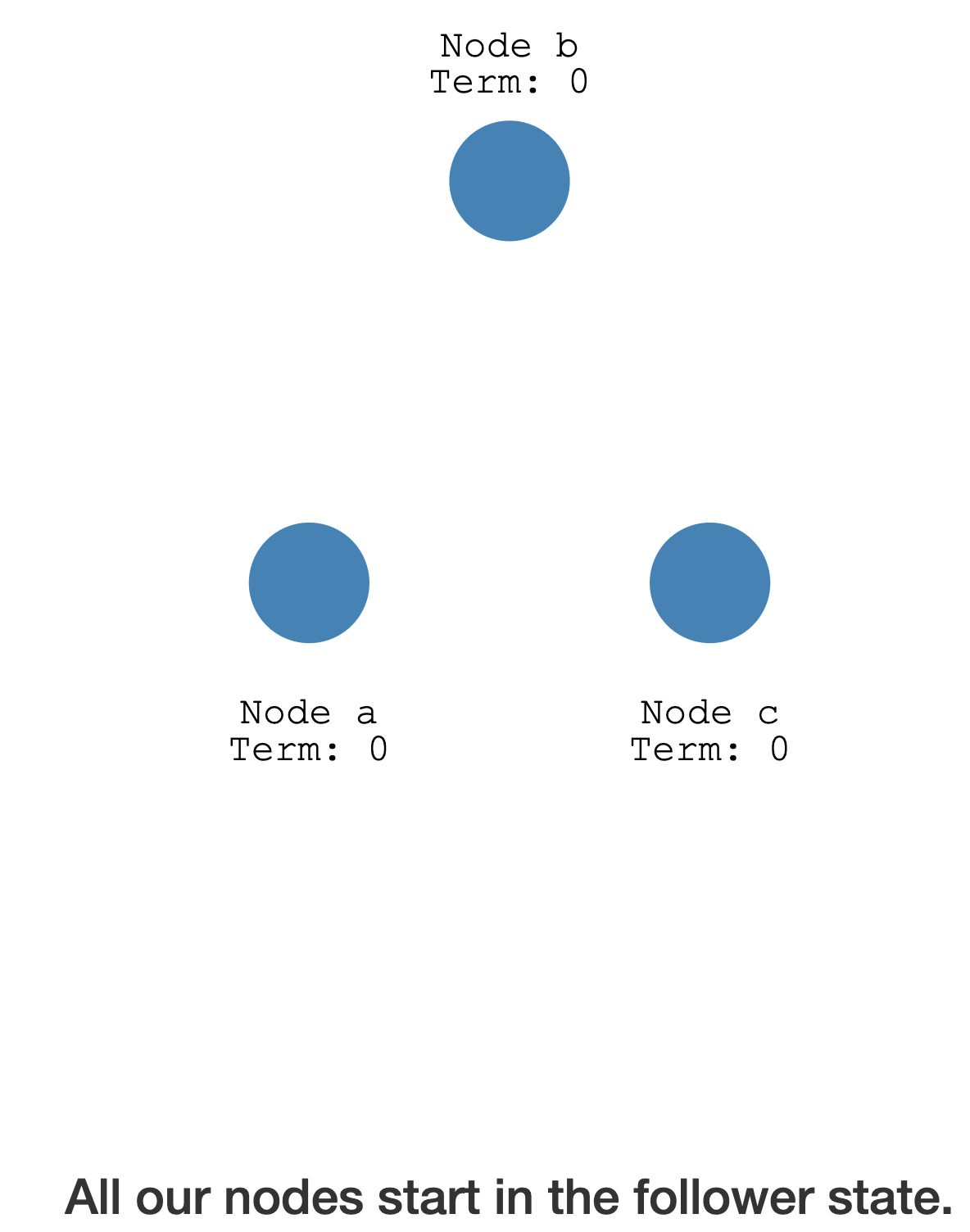
节点可以有 3 种状态:Follower、Candidate、Leader
| State | Desc |
|---|---|
Follower |
|
Candidate |
参与选举和投票 |
Leader |
与
ZAB协议类似:Leader Election->Log Replication
An Example
Leader Election
所有节点的初始状态为
Follower,等待Leader的心跳
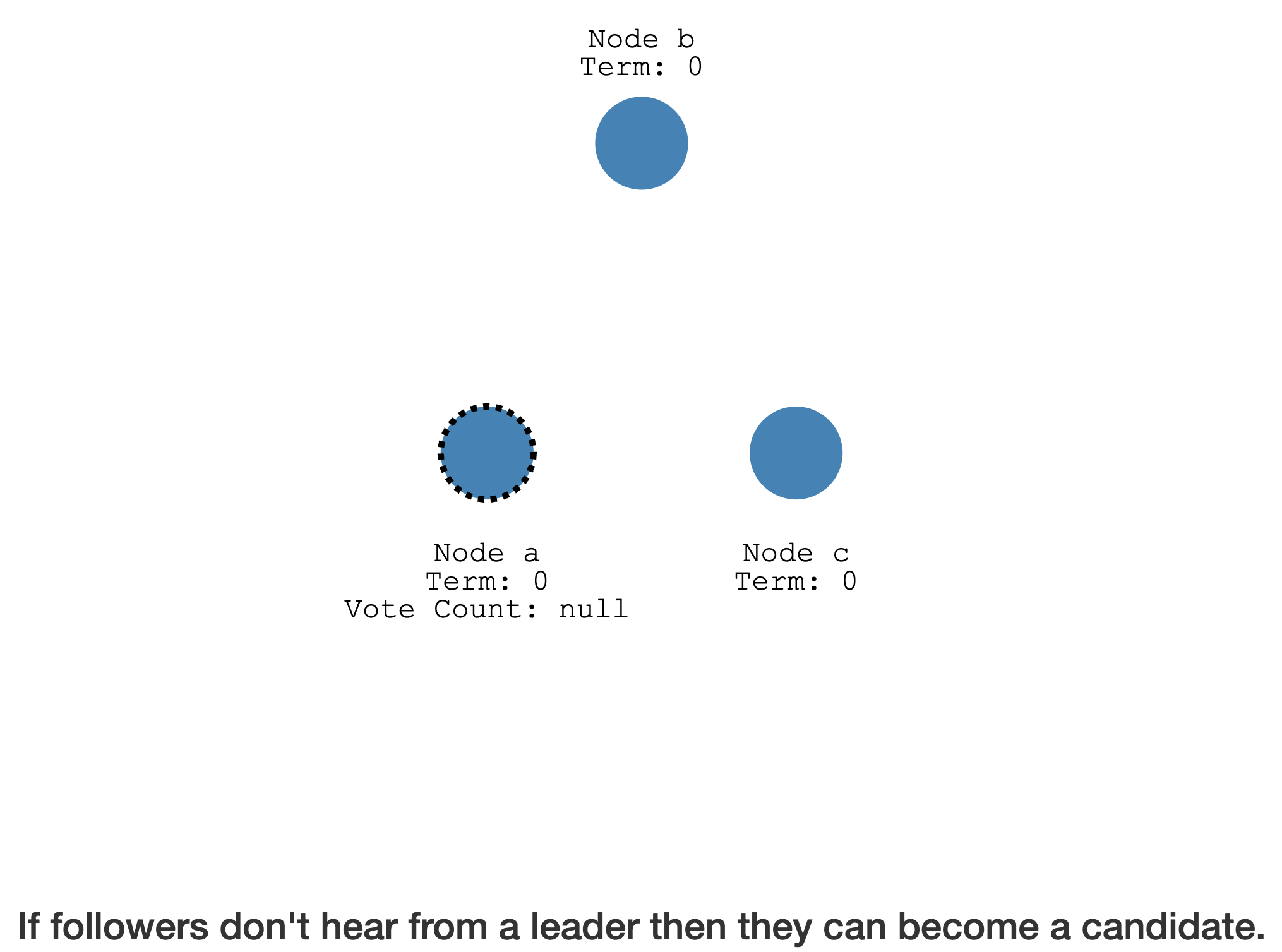
节点启动时,设置
随机的Election Timeout,即处于 Follower 状态的超时时间
一旦超过这个时长都没有收到Leader的心跳,会变成Candidate
Follower 变成 Candidate 后,会去向其他节点发起
拉票
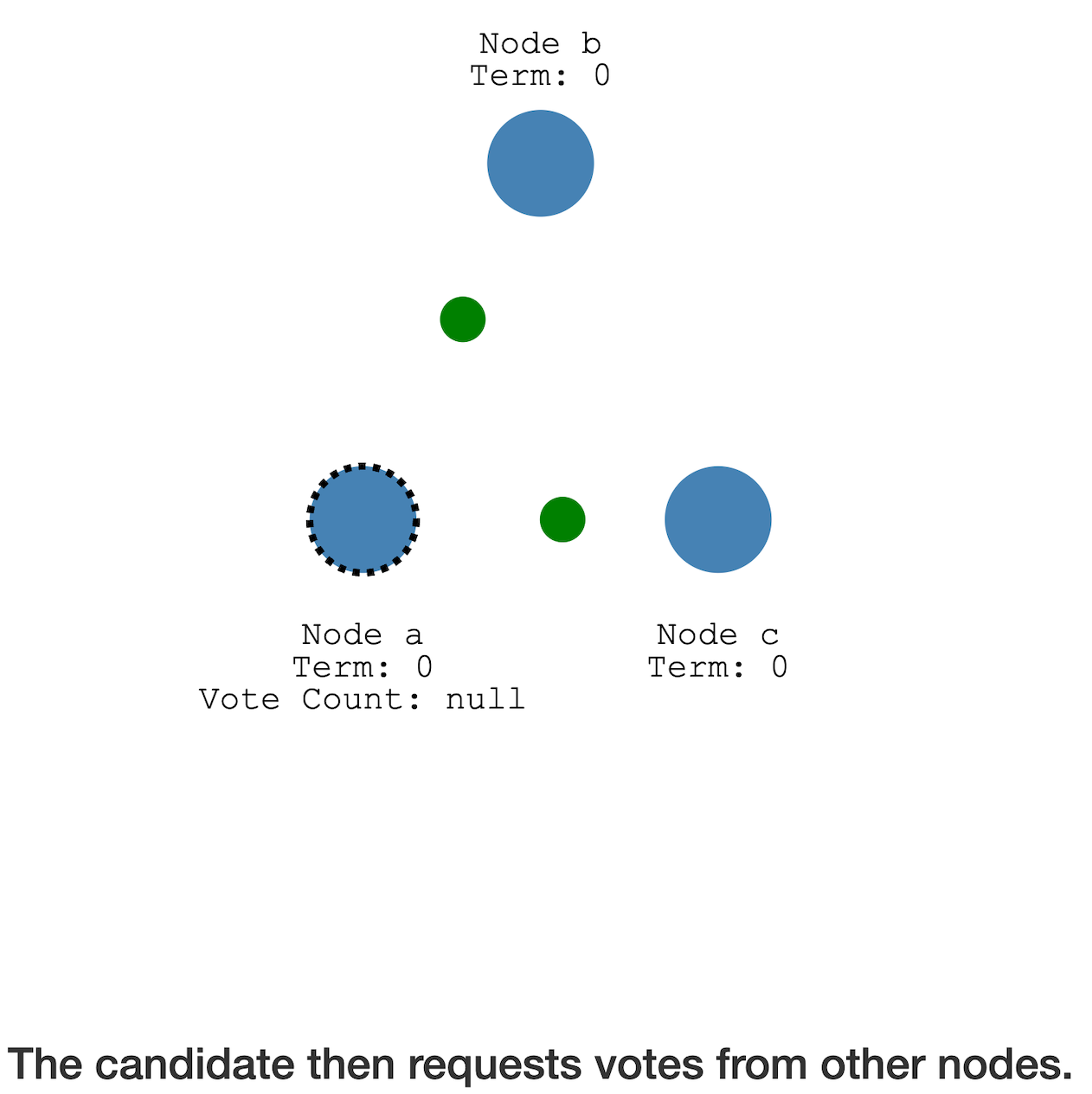
其他节点此时也没有跟从的 Leader,所以可以
接收拉票
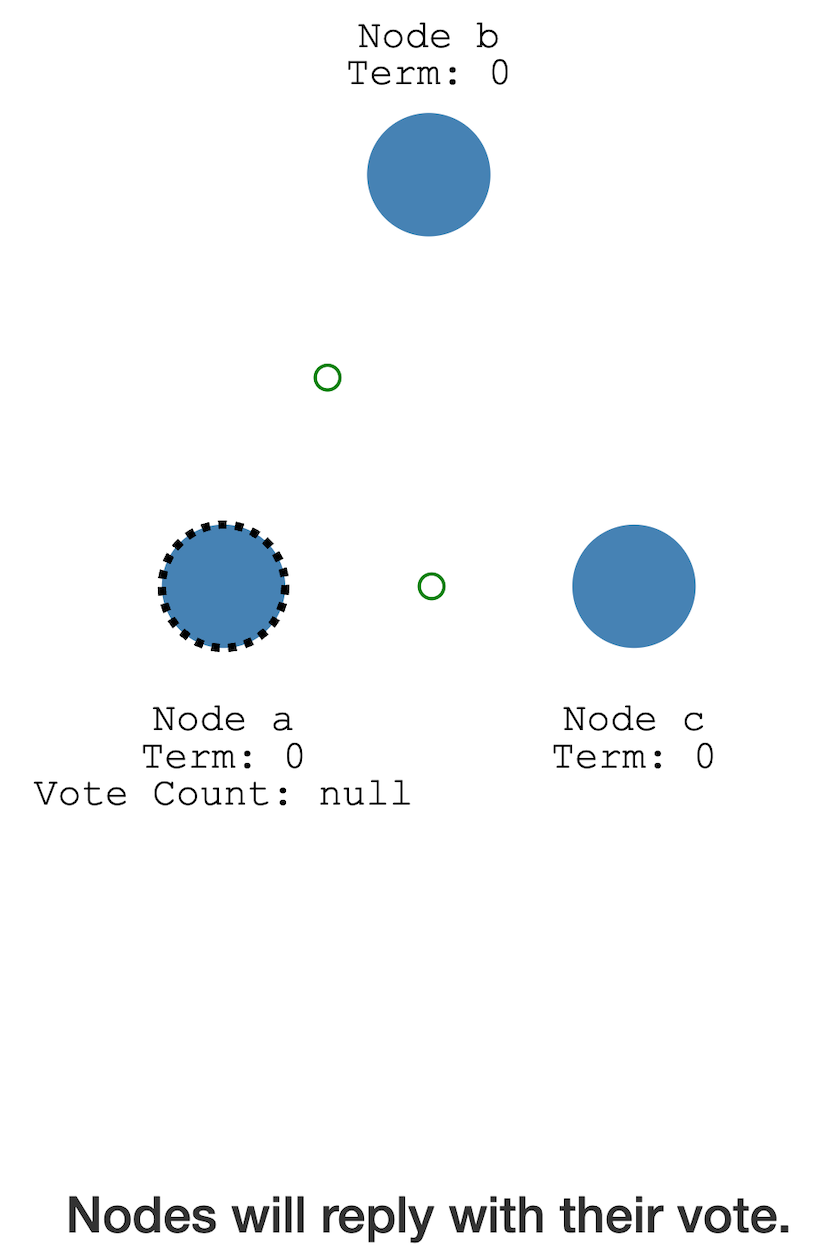
A 想当 Leader,B 和 C 此时没有 Leader,
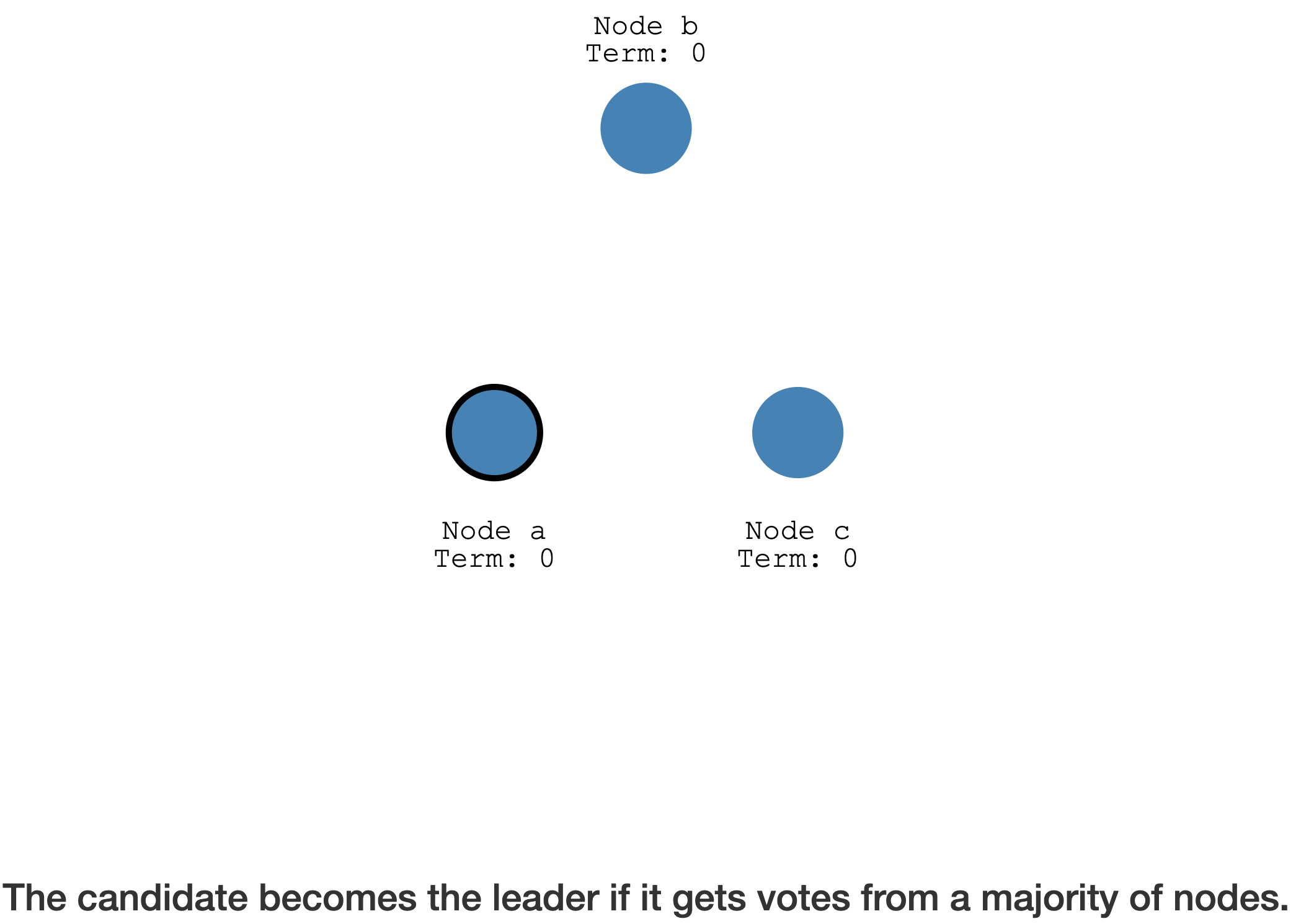
直接同意,超过半数,A 成为了 Leader
Log Replication
选主完成后,所有的变更都需要经过Leader
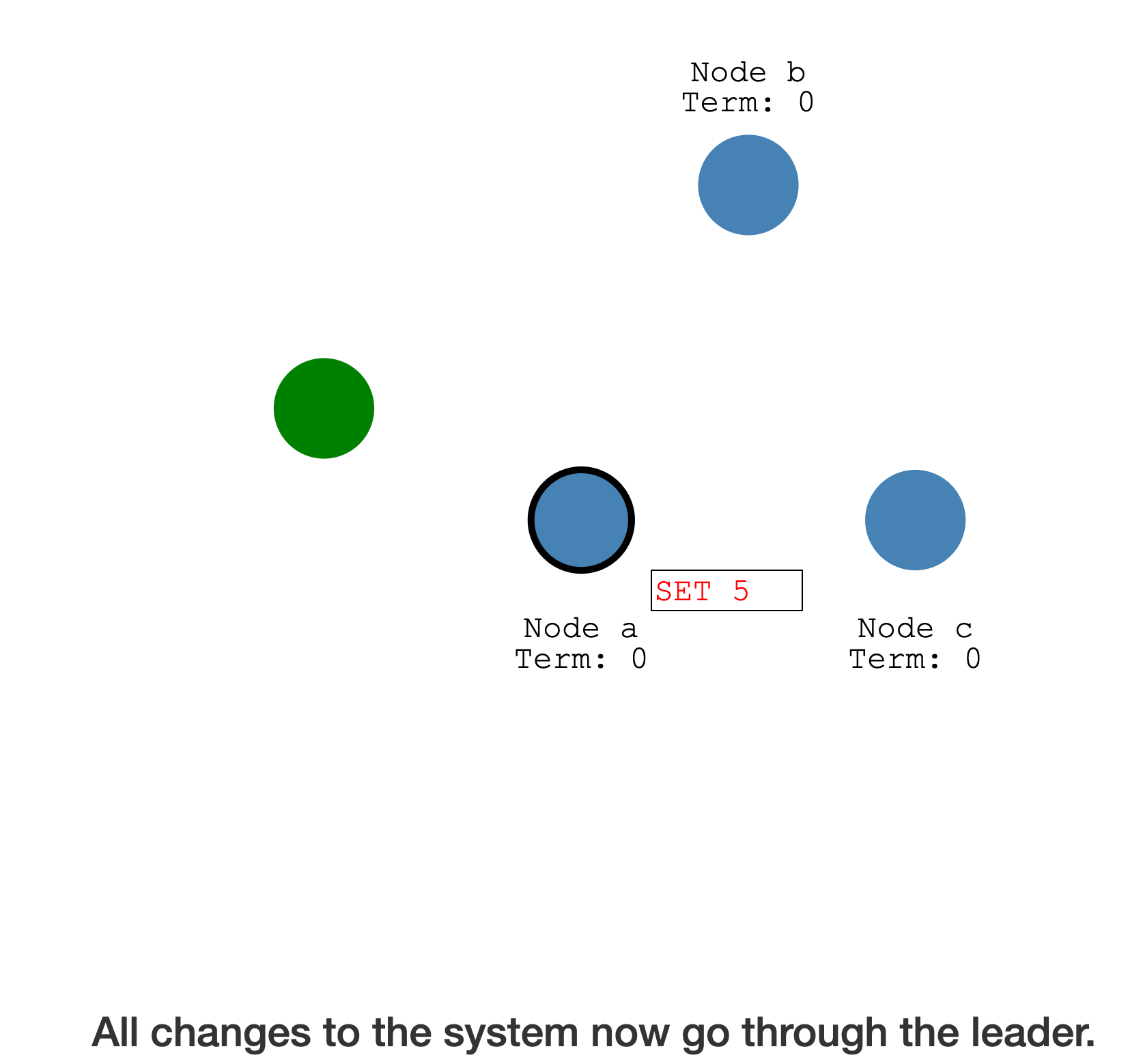
每个变更都会先在
Leader上新增一个Log entry,但此时的Log entry是尚未确认,所以不会变更状态机
如果此时 A
宕机,对应的 Log entry 也会丢失
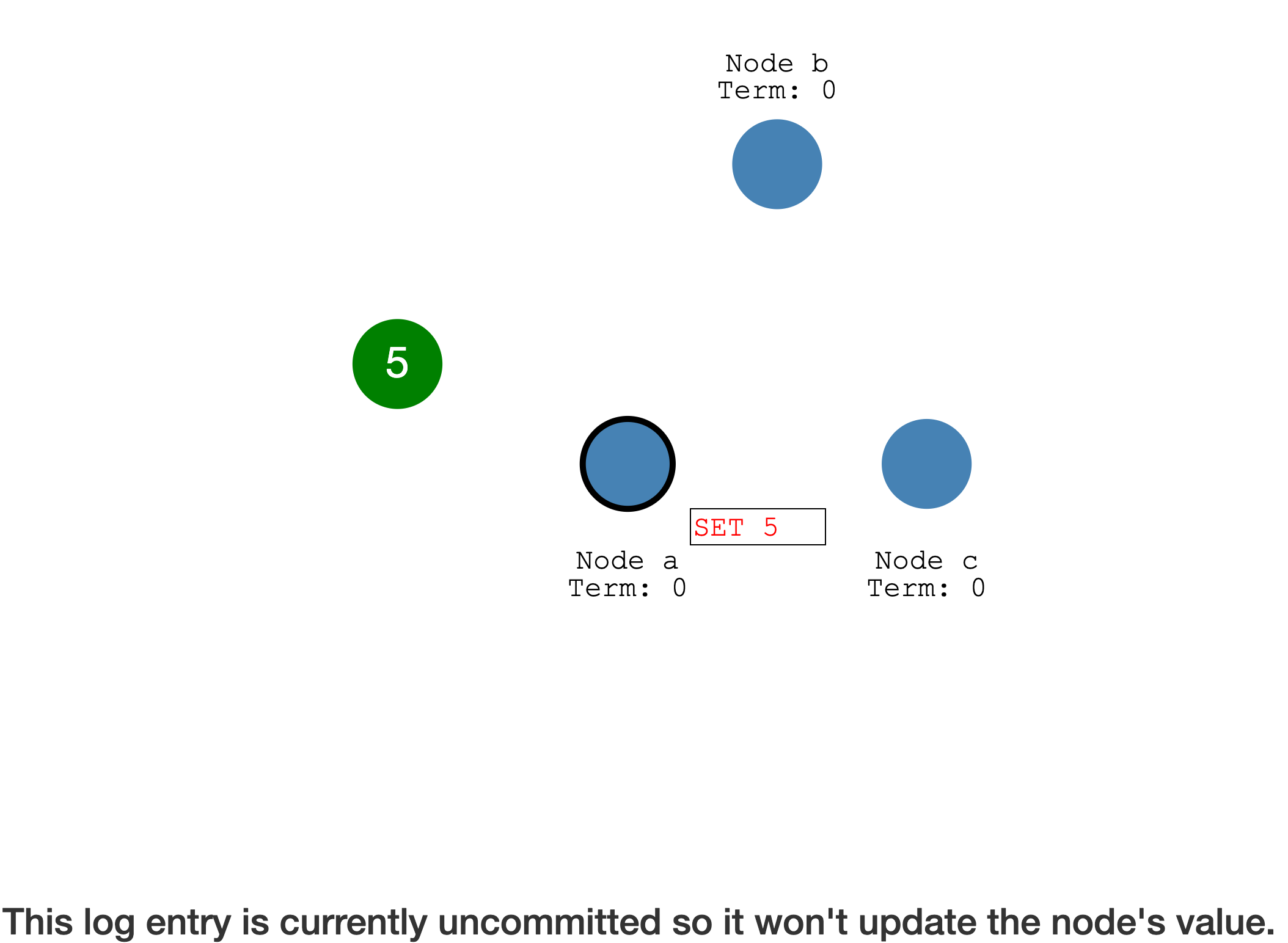
通过
心跳,将未经确认的 Log entry传播到其他 Follower(也是写入到 Log entry)
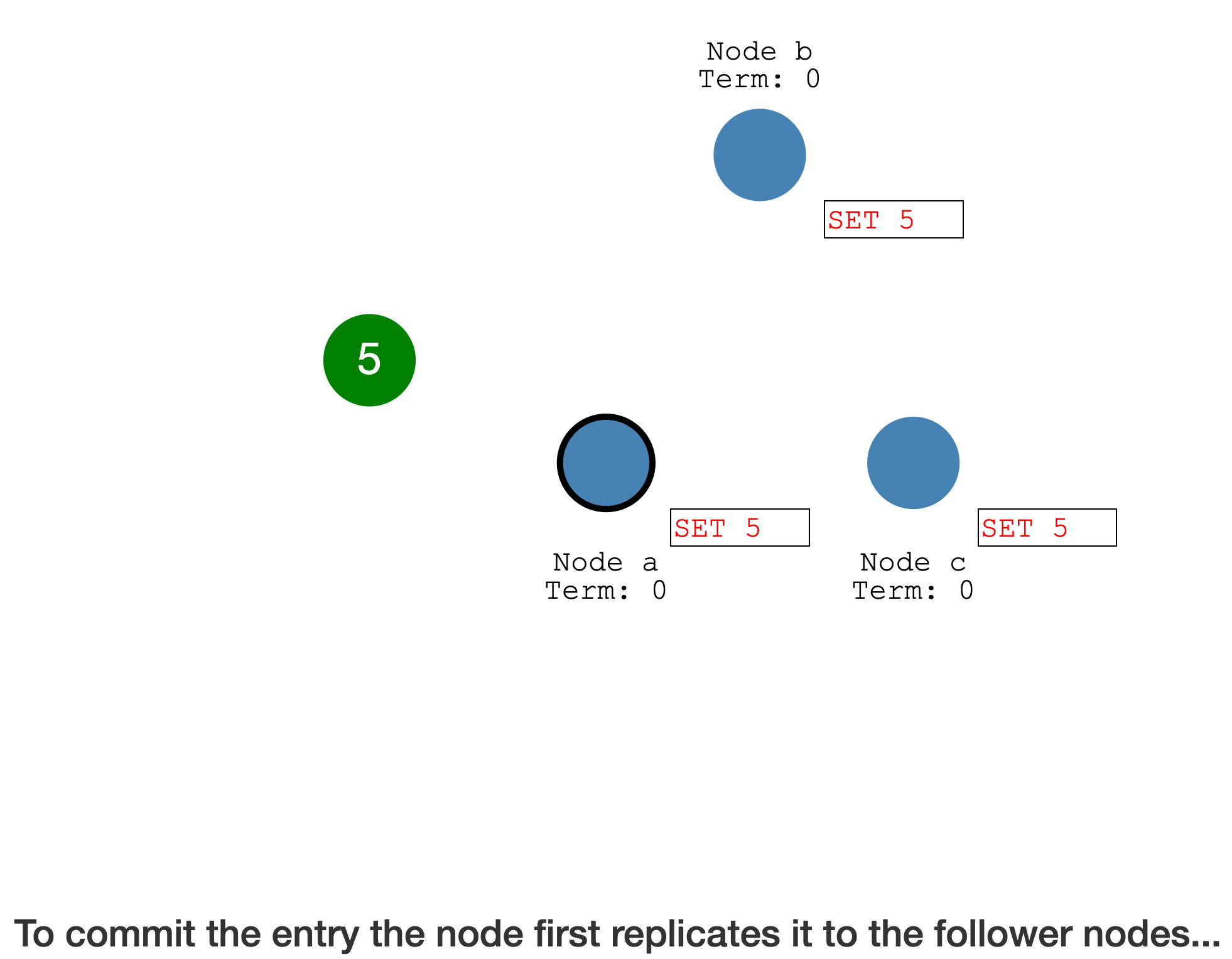
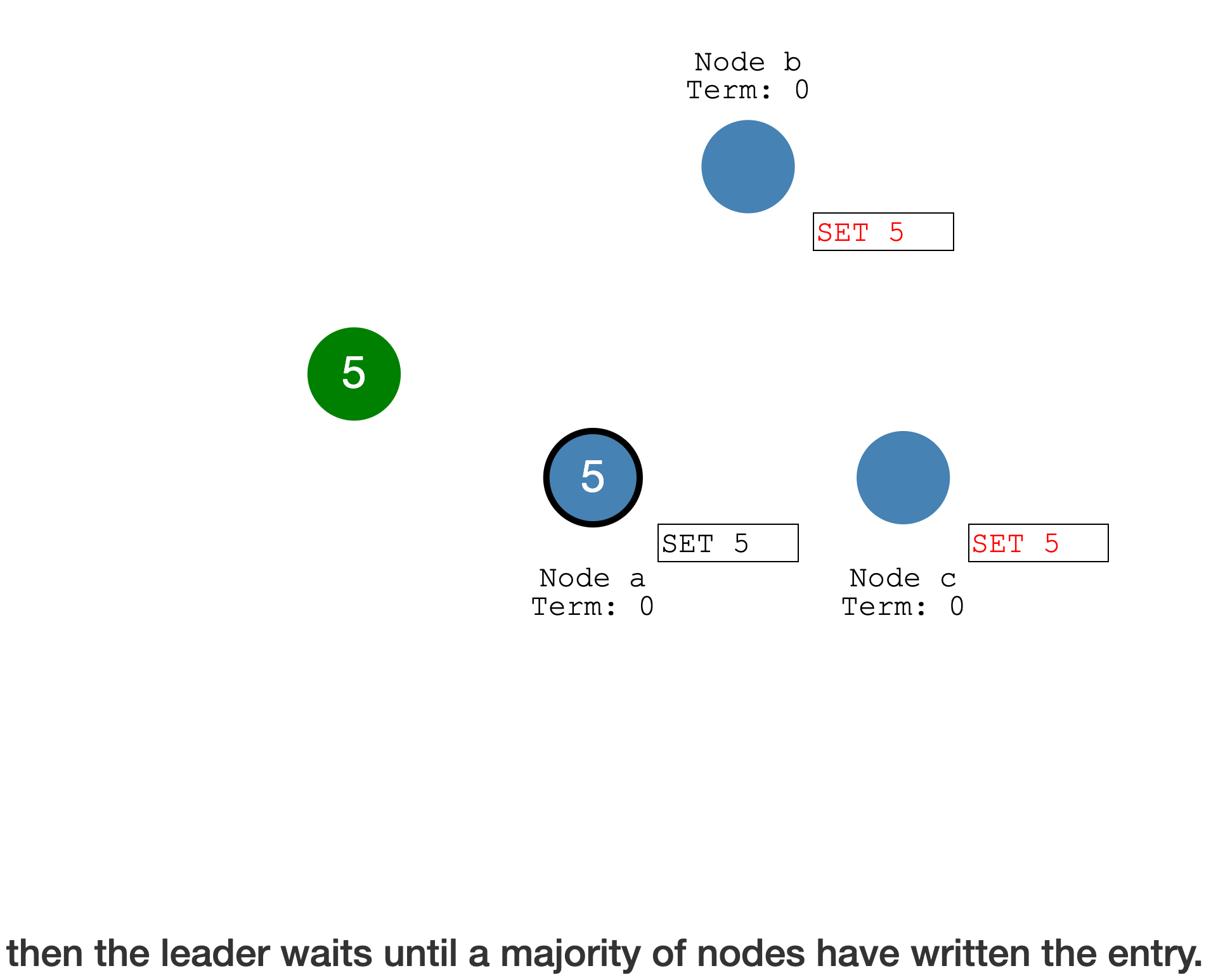
Leader 会等待
超过半数的成员确认,然后才会确认本地的 Log entry,并提交到状态机
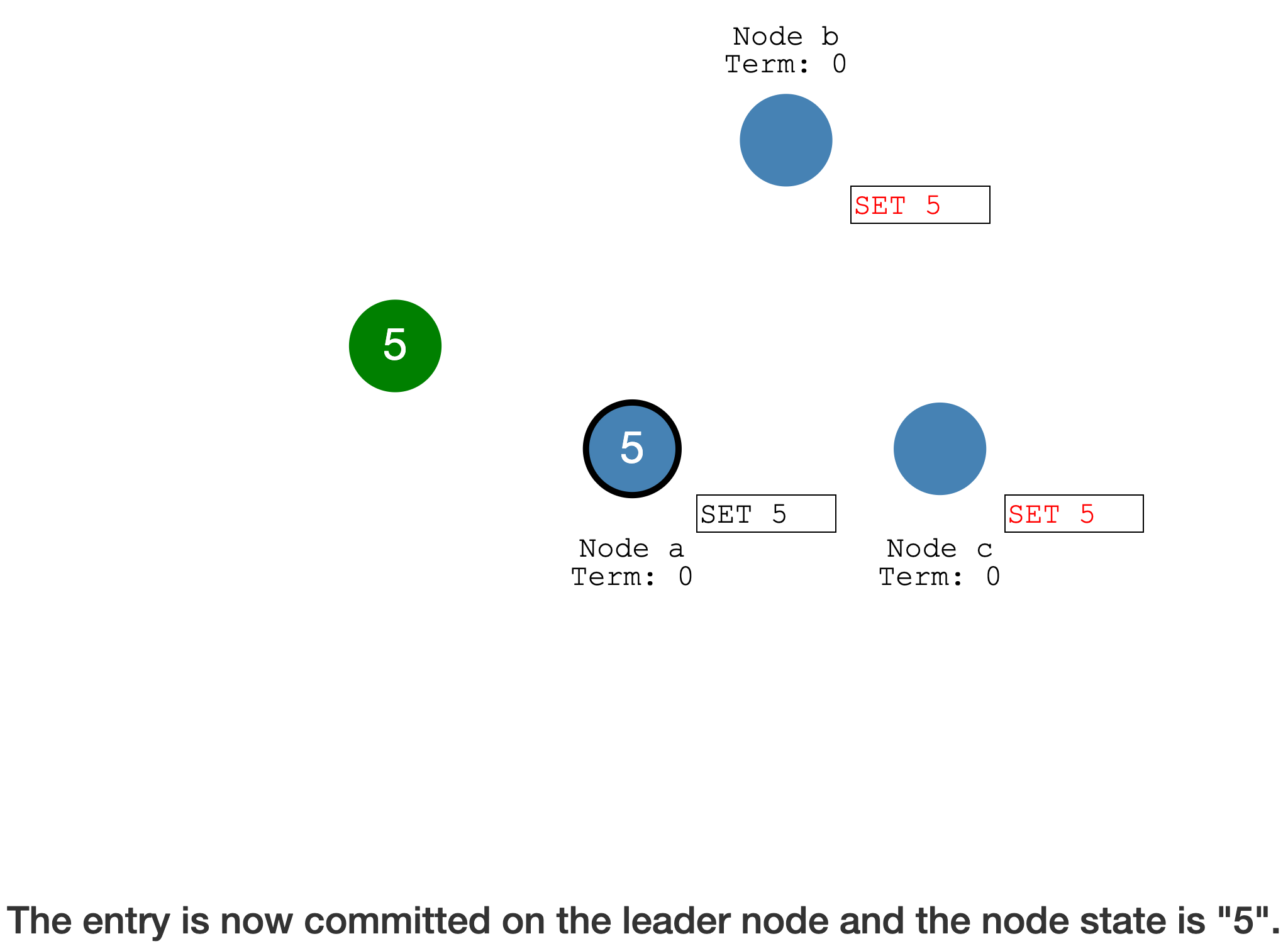
Leader Commit 后,通过
心跳通知 Follower 也可以 Commit(从 Log entry 提交到状态机)
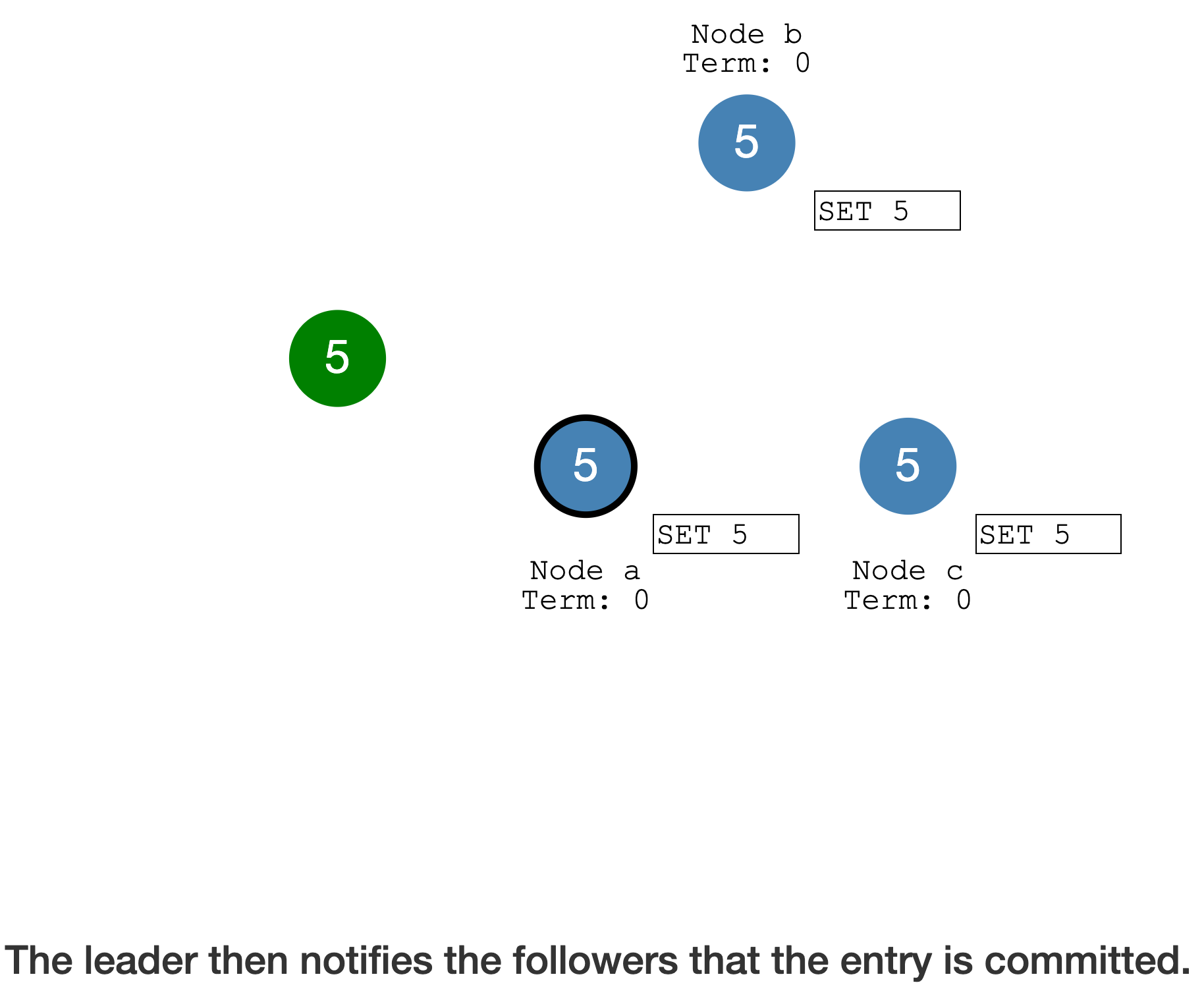
此时达成了
分布式共识
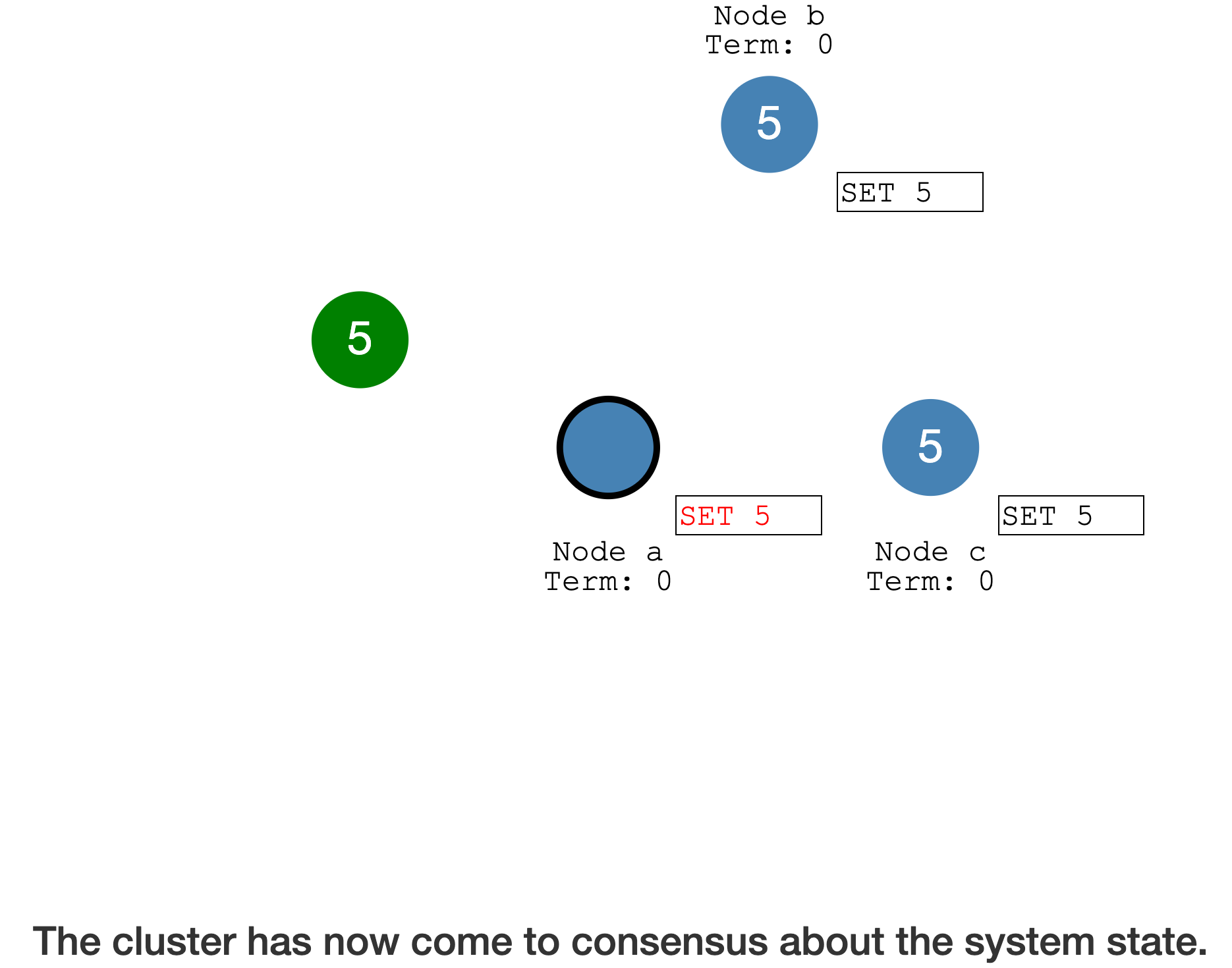
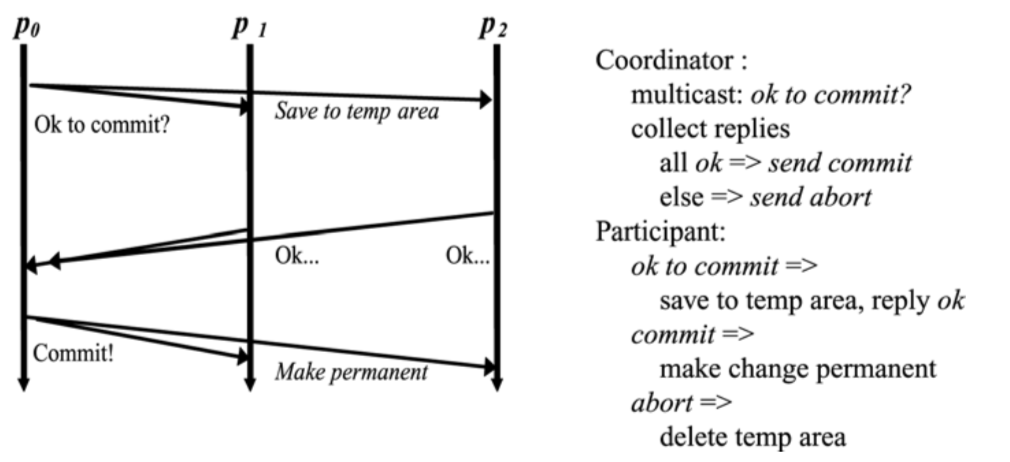
上述过程有点类似于
Two-stage confirmation,主要区别
We use Raft to gethigh availabilityby replicating the data on multiple servers, where all servers do the same thing.
This differs fromtwo-phase commitin that 2PCdoes not help with availability, and all theparticipantservers hereperform different operations.
Detail
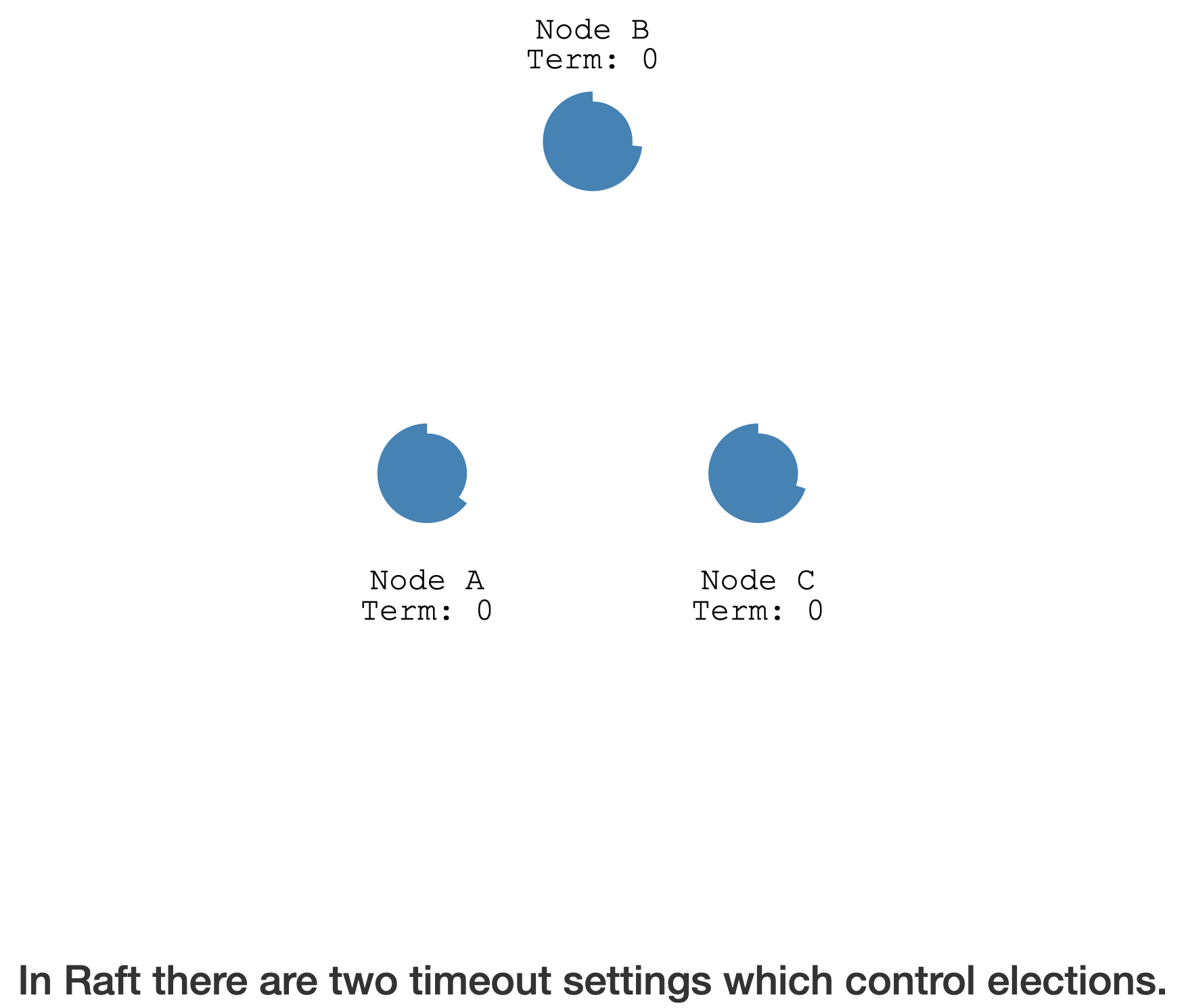
Leader Election
The election timeout is the amount of time a follower waits until
becoming a candidate.
The election timeout is randomized to be between150msand300ms.
Follower 变成 Candidate 后,首先
给自己投票
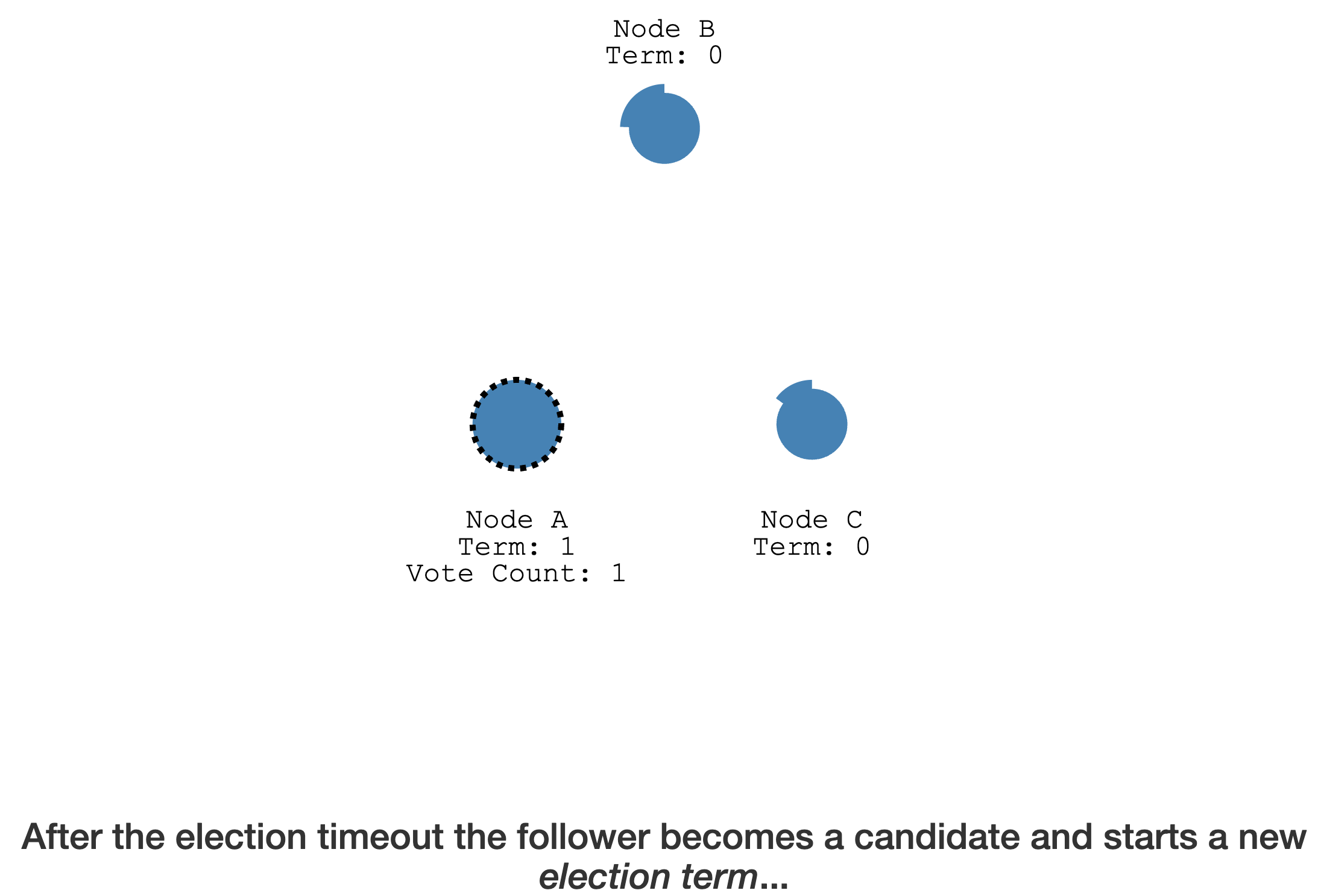
然后请求其它节点给自己投票

如果其它节点在这个 Term 内未投票,会直接给 Candidate 投票
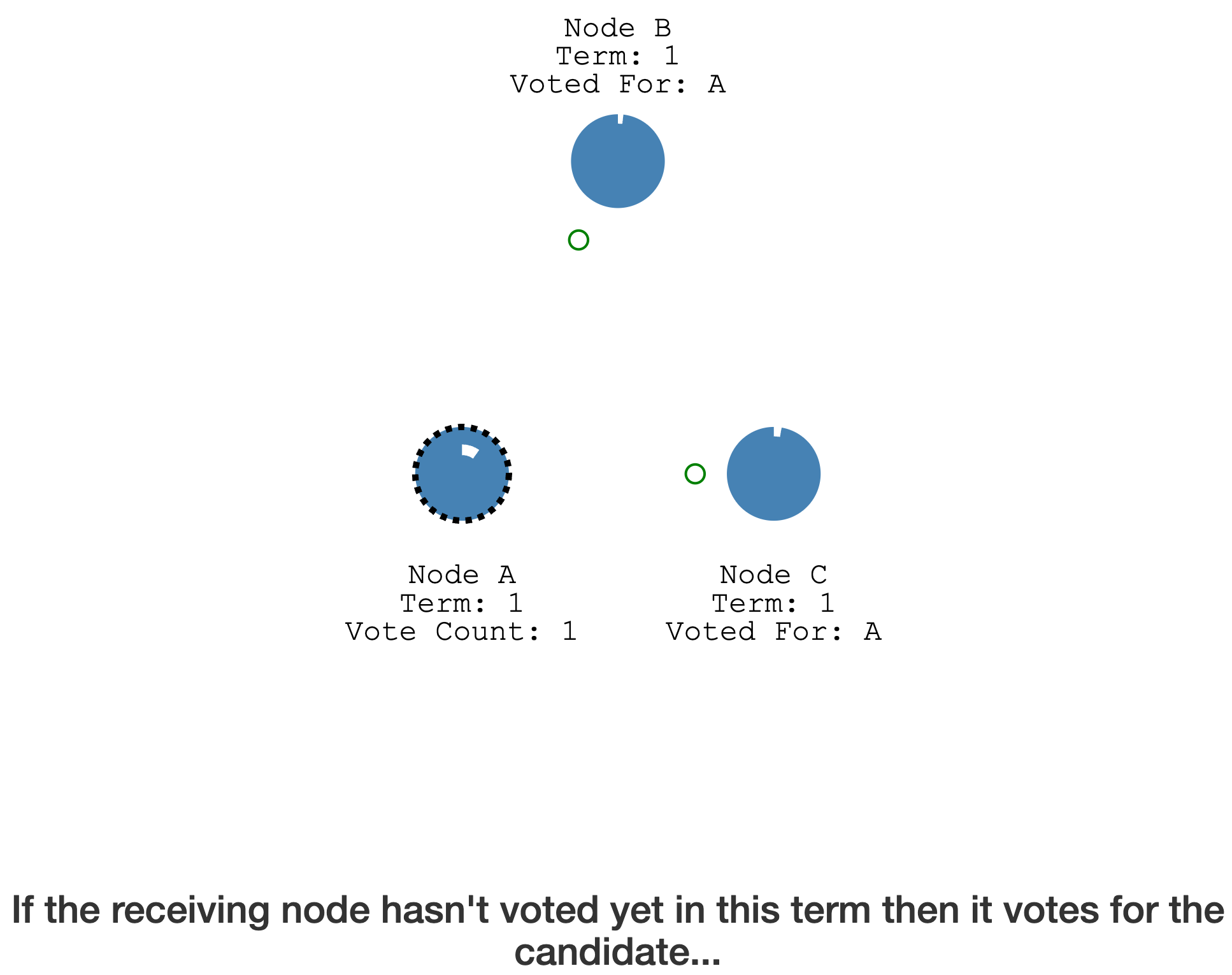
完成投票后,其它节点会重置自身的 election timeout(不会变成 Candidate)
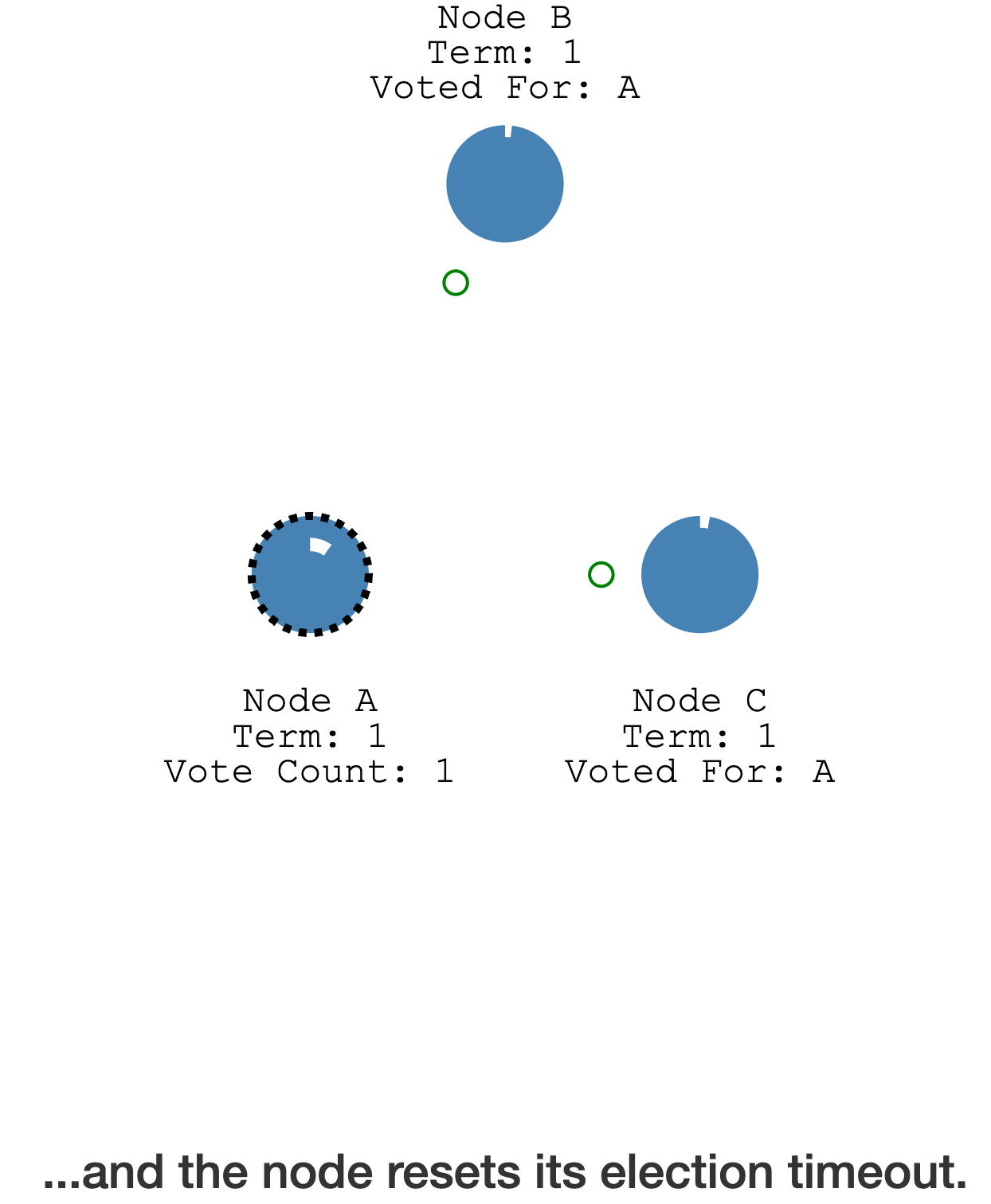
得到超过半数的成员投票后,Candidate 成为了 Leader

Log Replication
Leader 通过
心跳(heartbeat timeout)发送它本身的Append Entries到其它 Follower
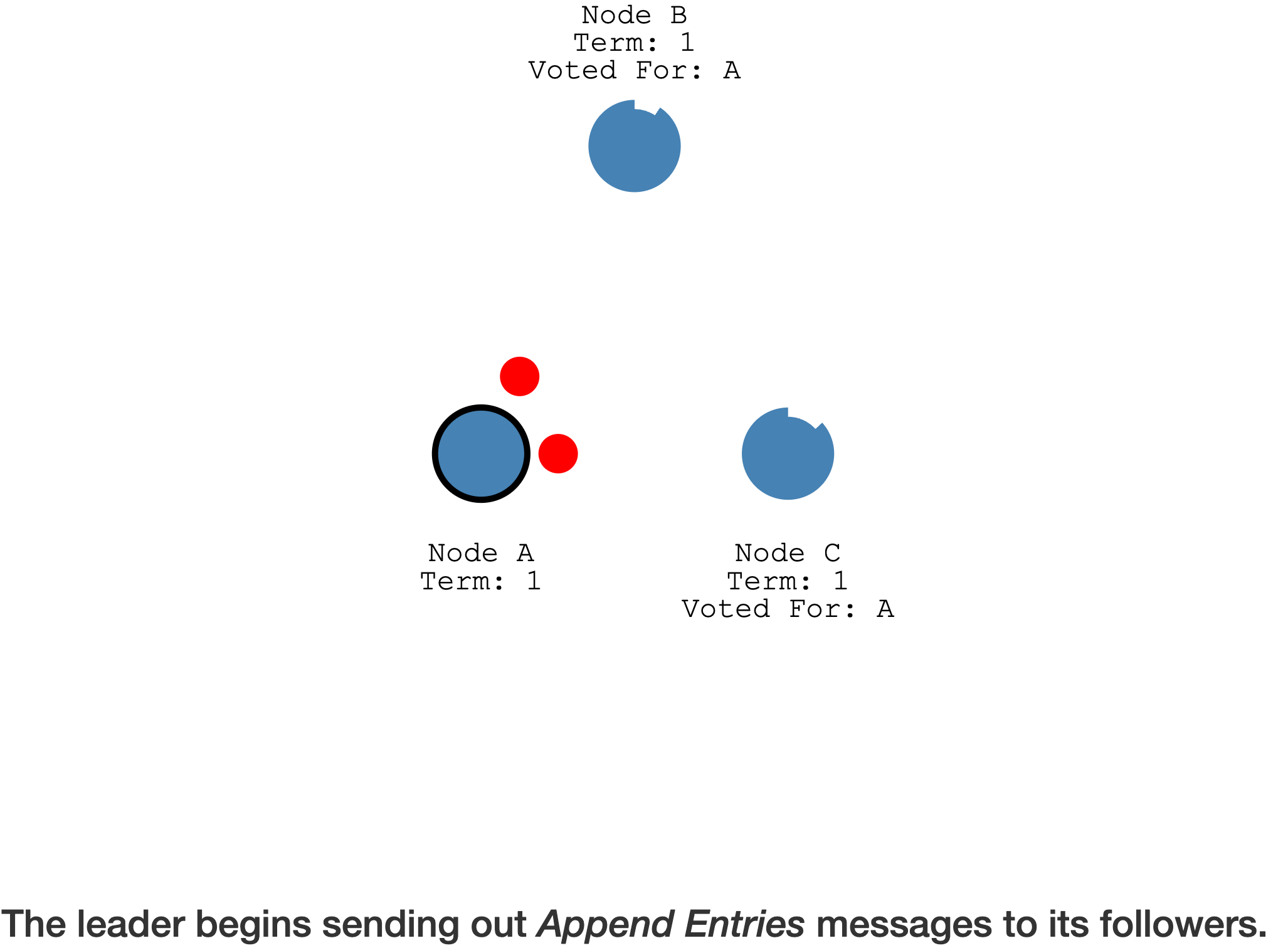
Follower 会响应每个
Append Entries消息
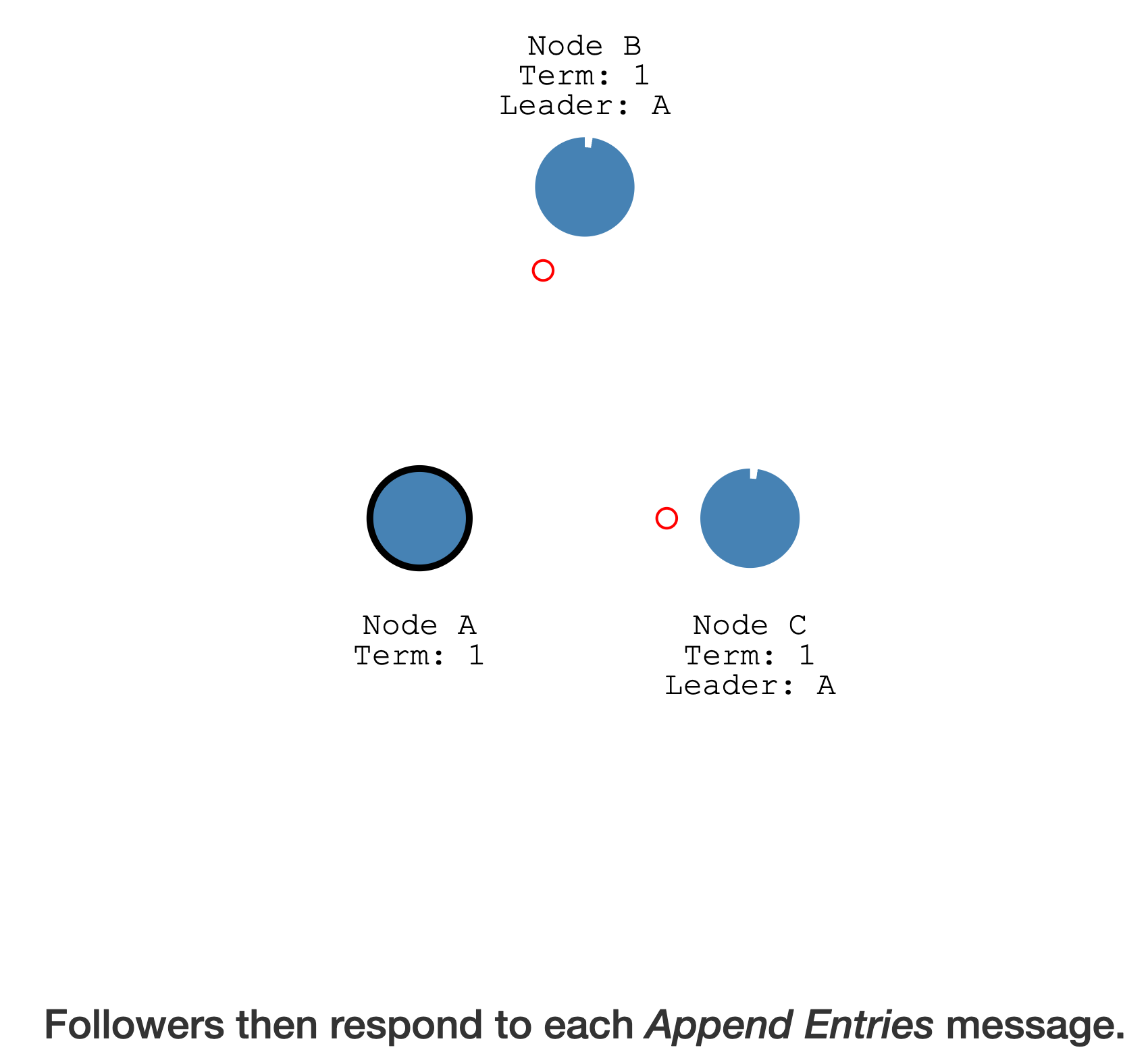
只要 Follower 能按时收到 Leader 的心跳,就会维持当前的选举周期(认可当前的 Leader),不会变成 Candidate
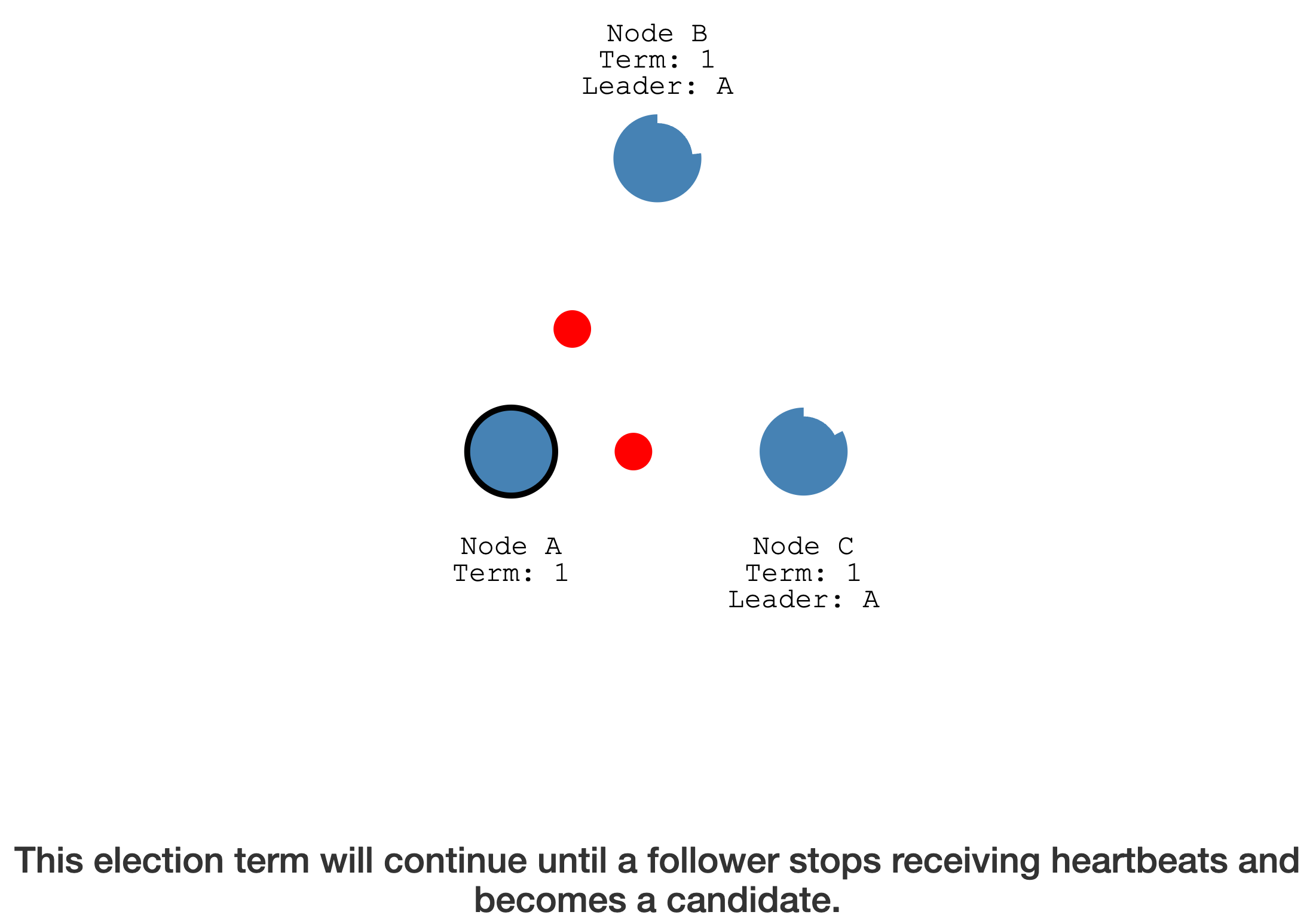
停掉 Leader 后,会发生重新选举
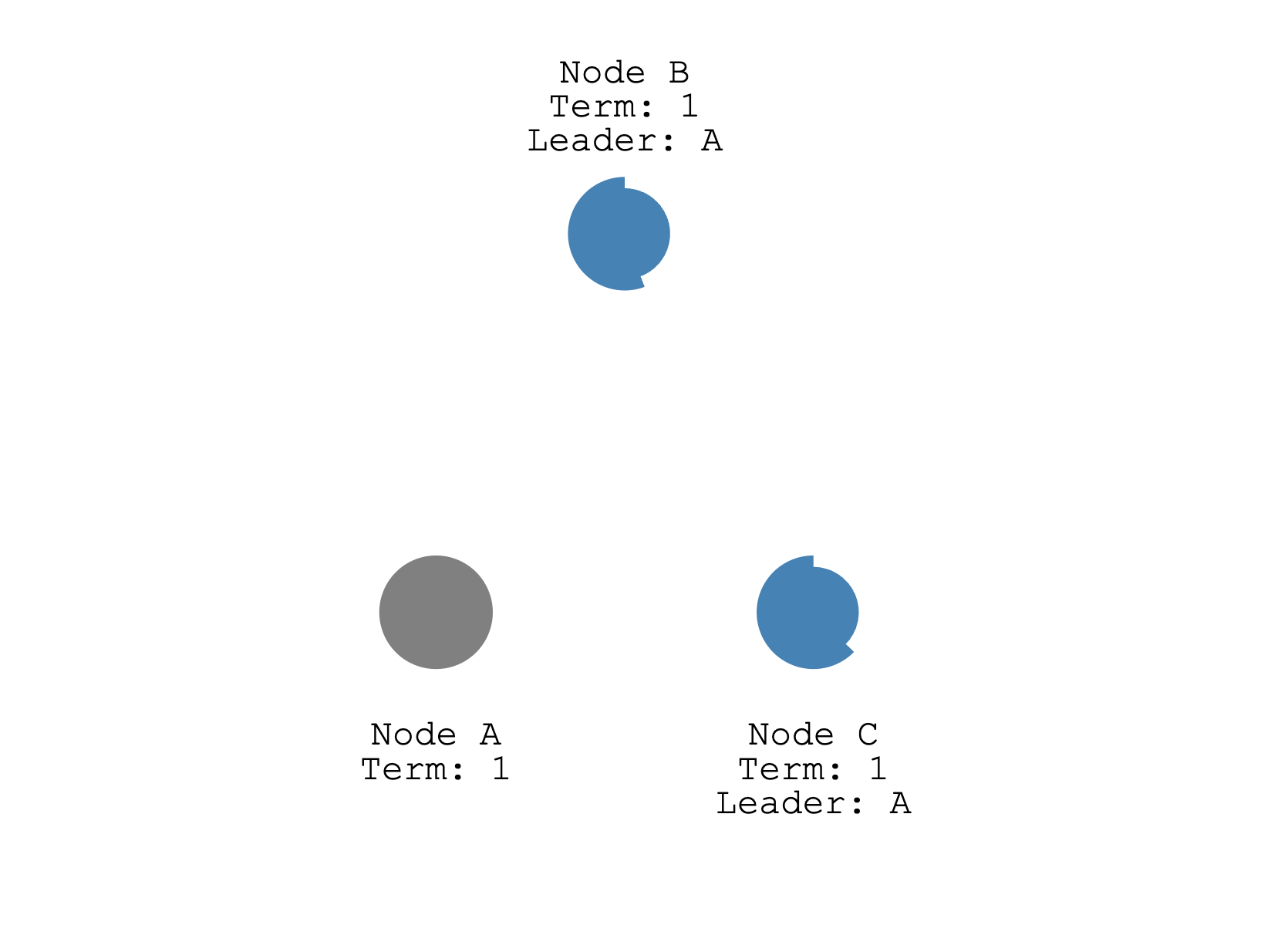
其它节点因为没有收到 Leader 的心跳,变成了 Candidate,发起新一轮的选举
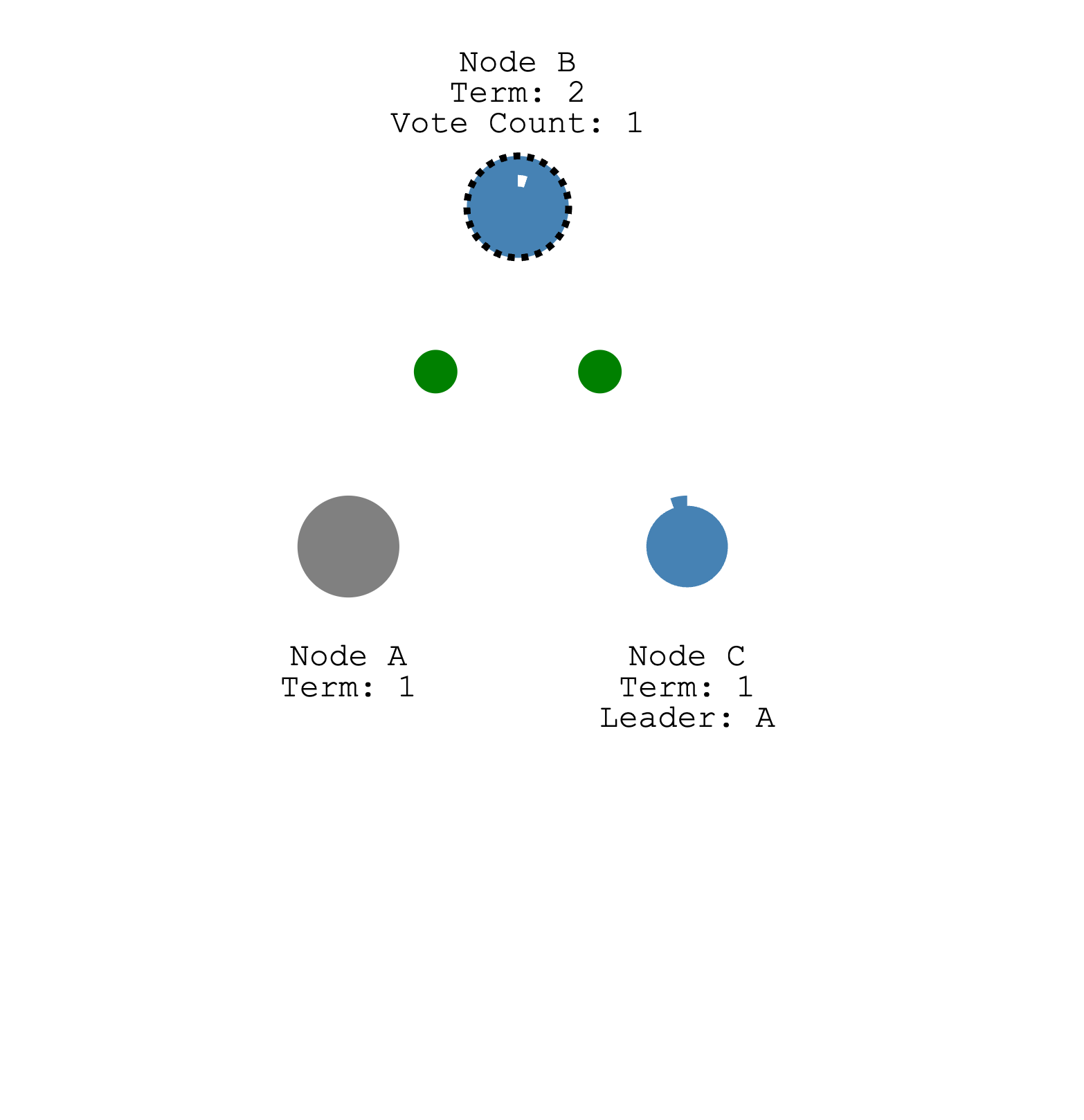
存活节点超过半数,能成功选举
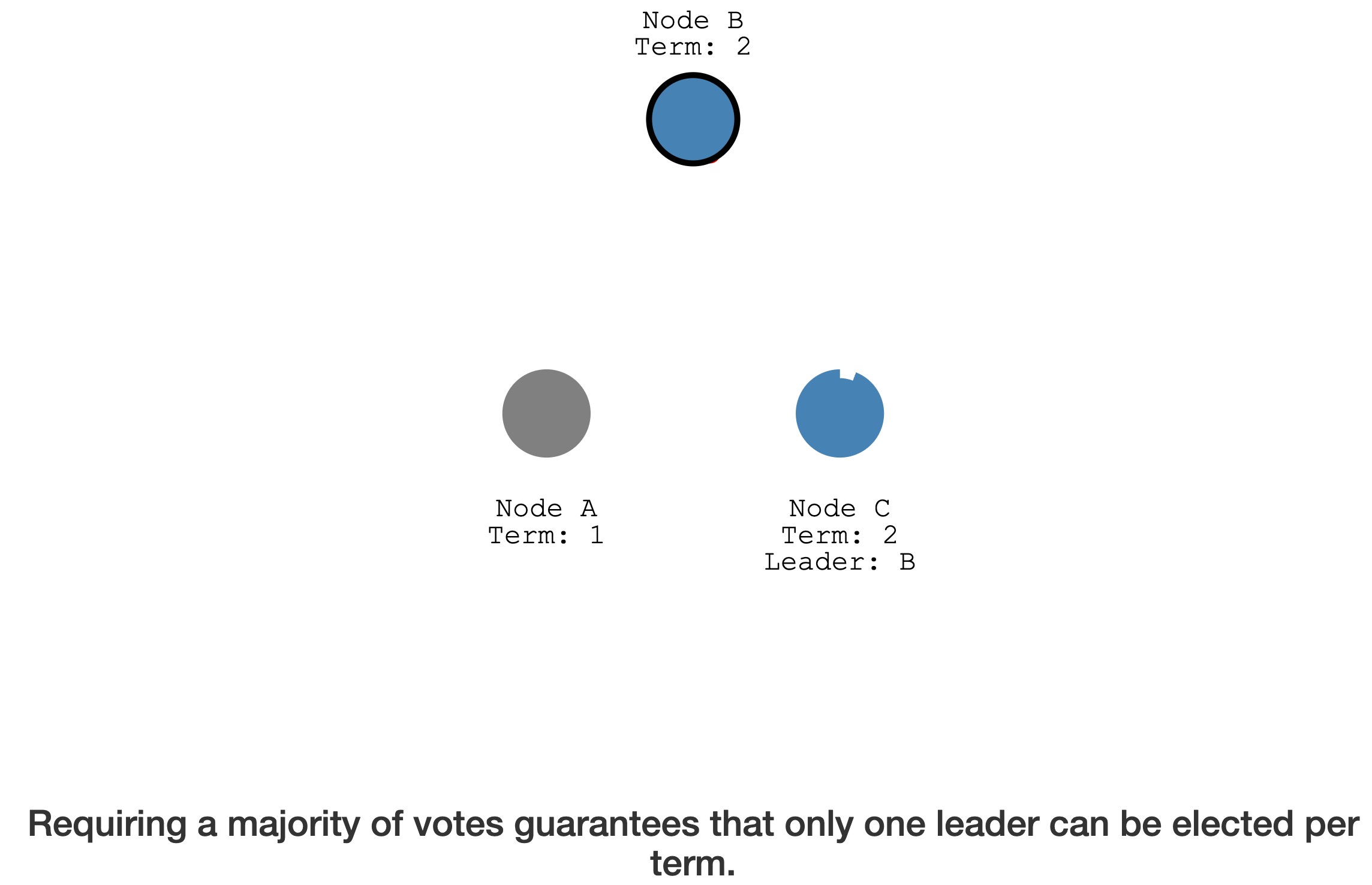
Requiring a
majorityof votesguaranteesthatonly one leadercan be electedper term.
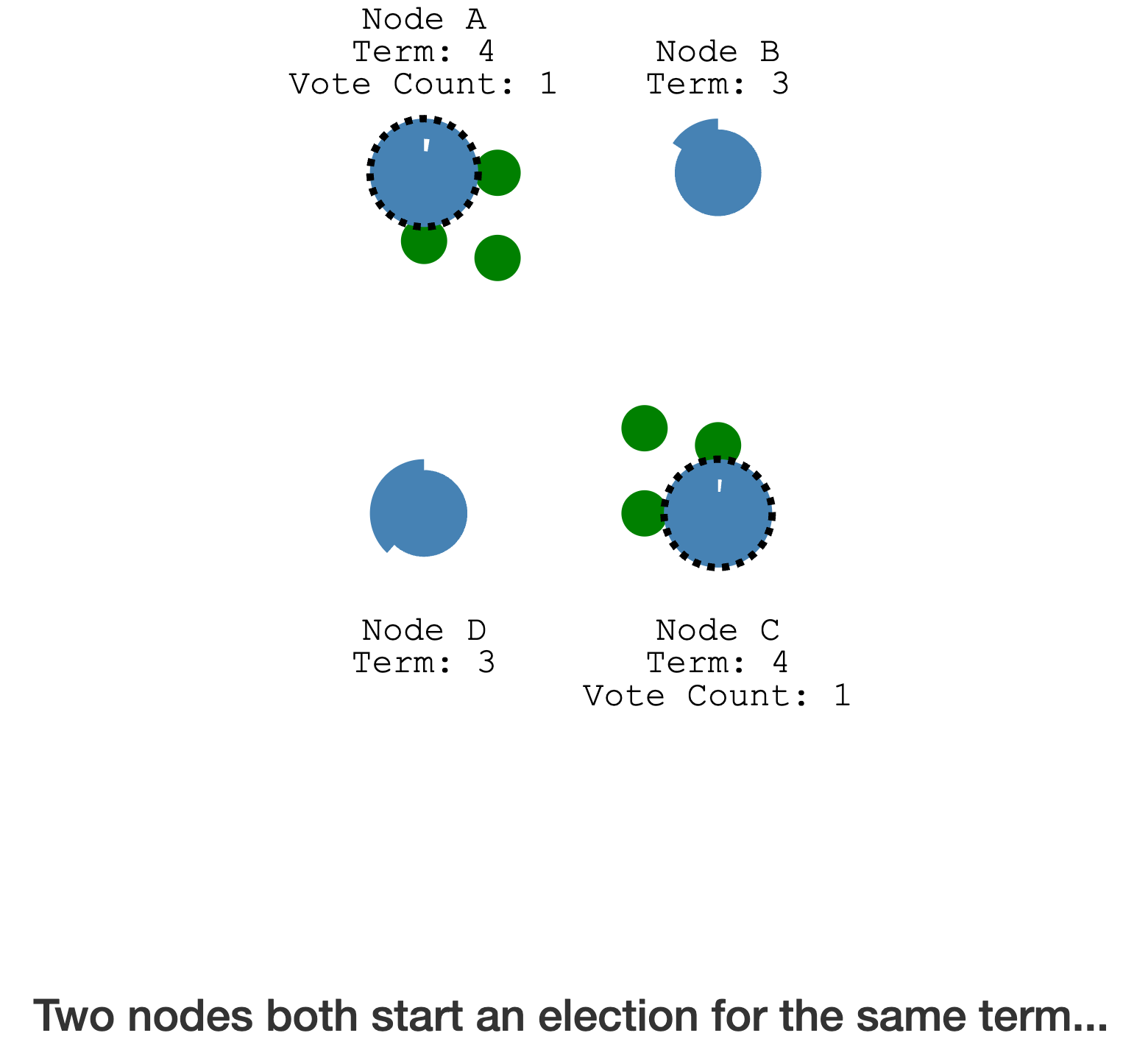
如果在同一个选举任期内,两个节点同时变成 Candidate,有可能会发生
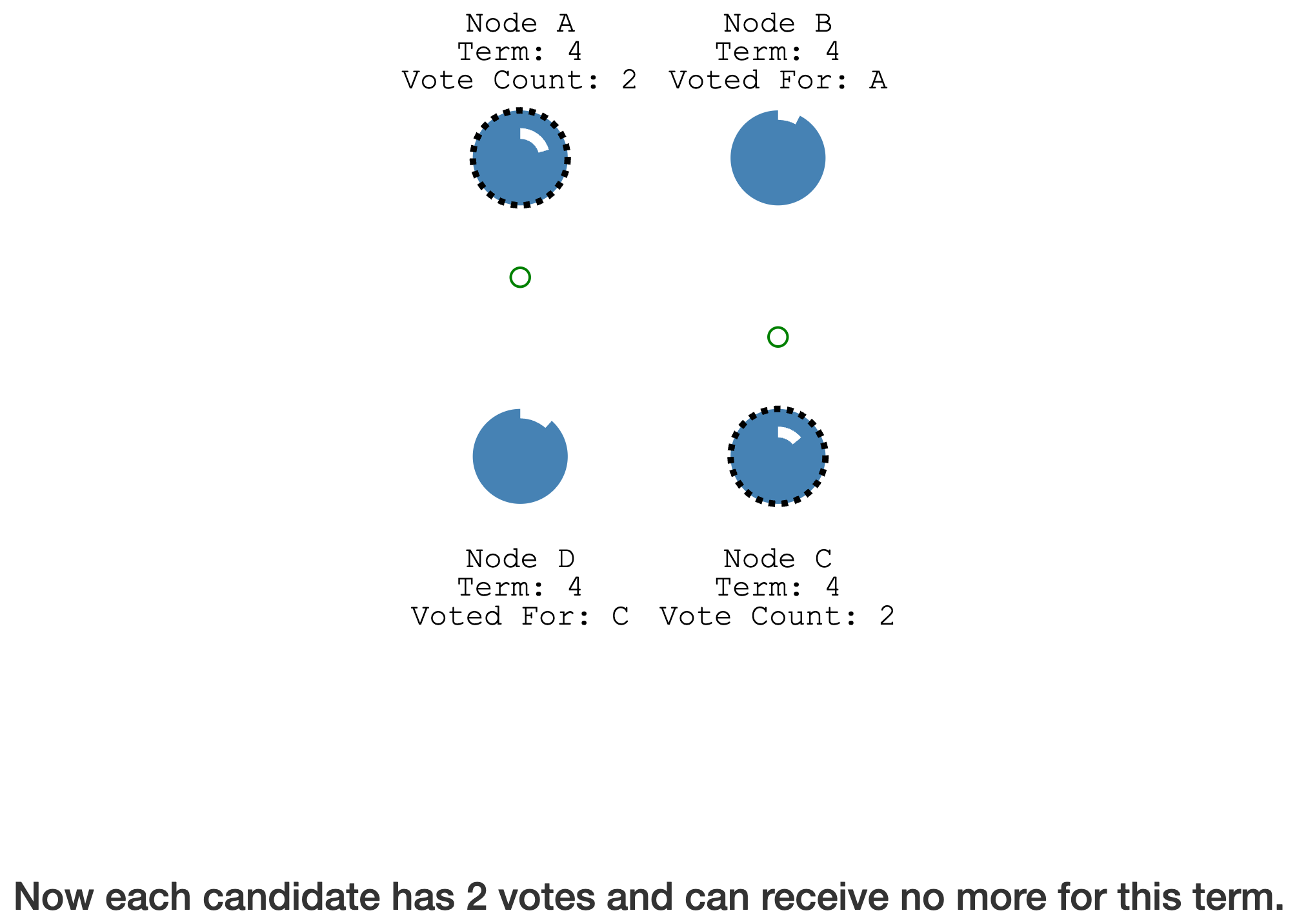
投票分裂
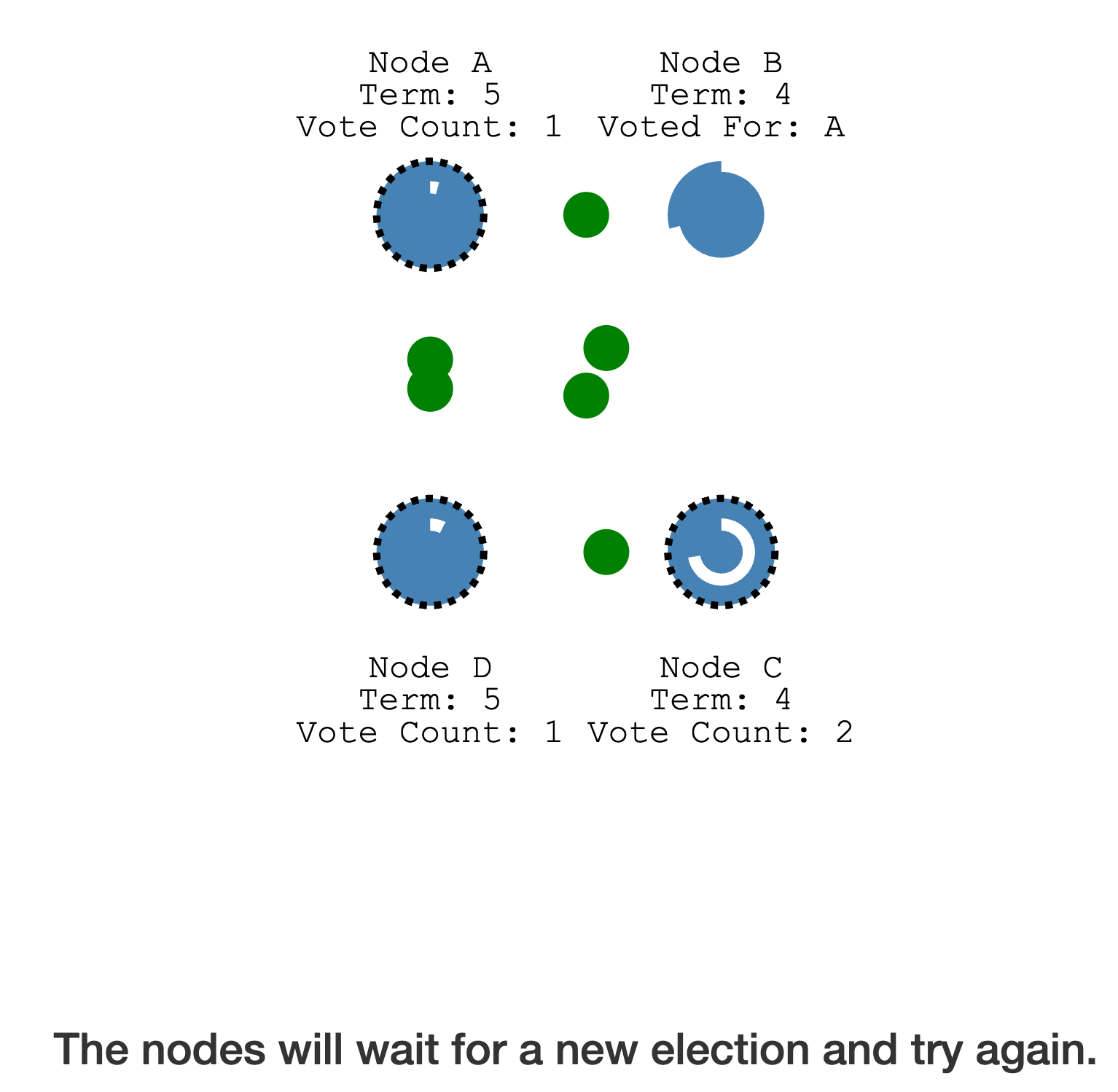
票数相等,但没有超过半数,选举失败
随机等待一段时间后,继续下一轮选举,直到票数超过半数
因此选择
奇数个节点,尽快完成选举,选举成功之前,集群是不可写的

Leader 需要将
所有变更通过心跳(Append Entries message)传播到所有 Follower

客户端向 Leader 发送请求,Leader 会记录 Log entry,此时尚未提交到
状态机(持久化的状态)
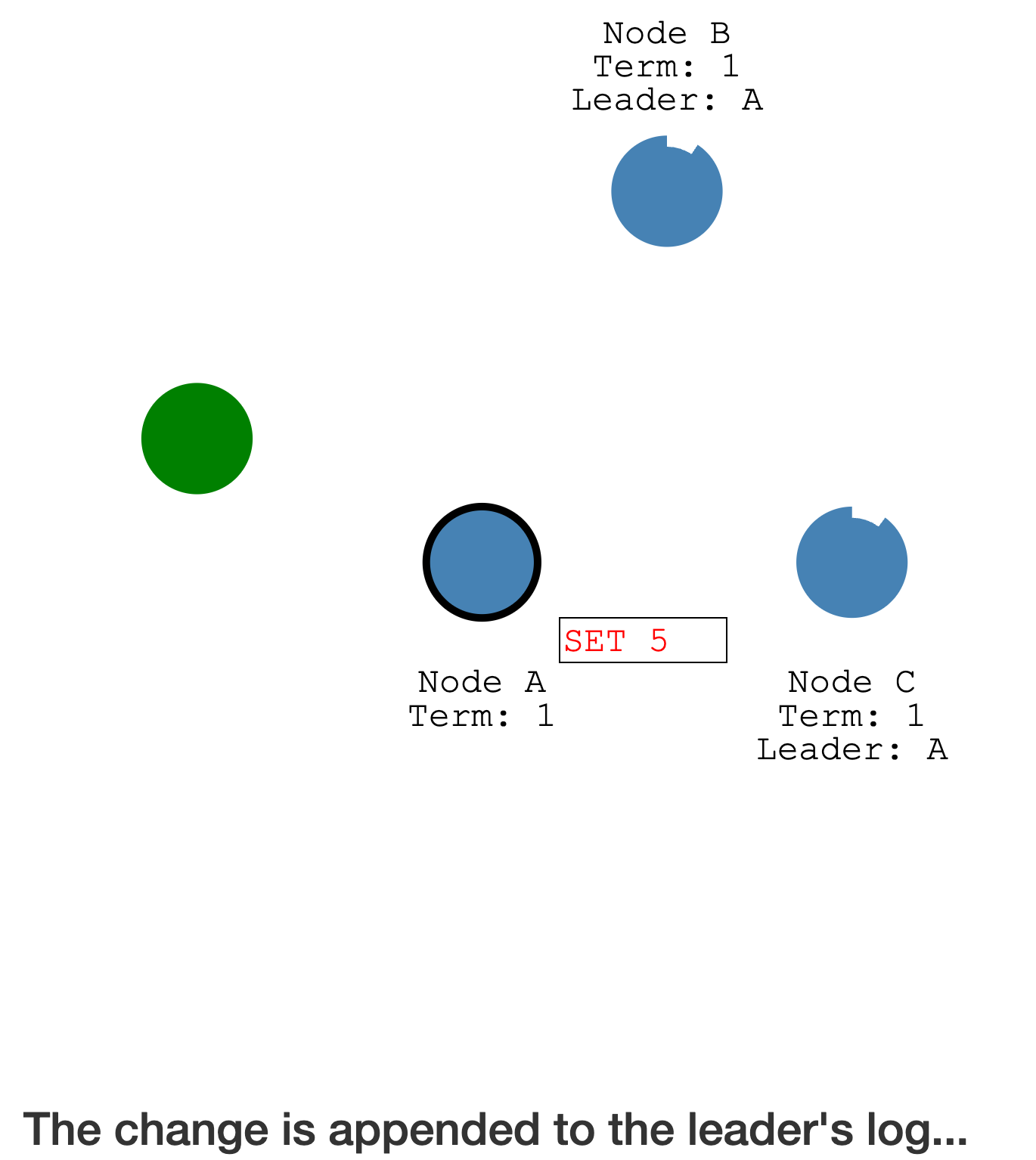
在
下一个心跳,Leader 会将 Log entry 发送给 Follower
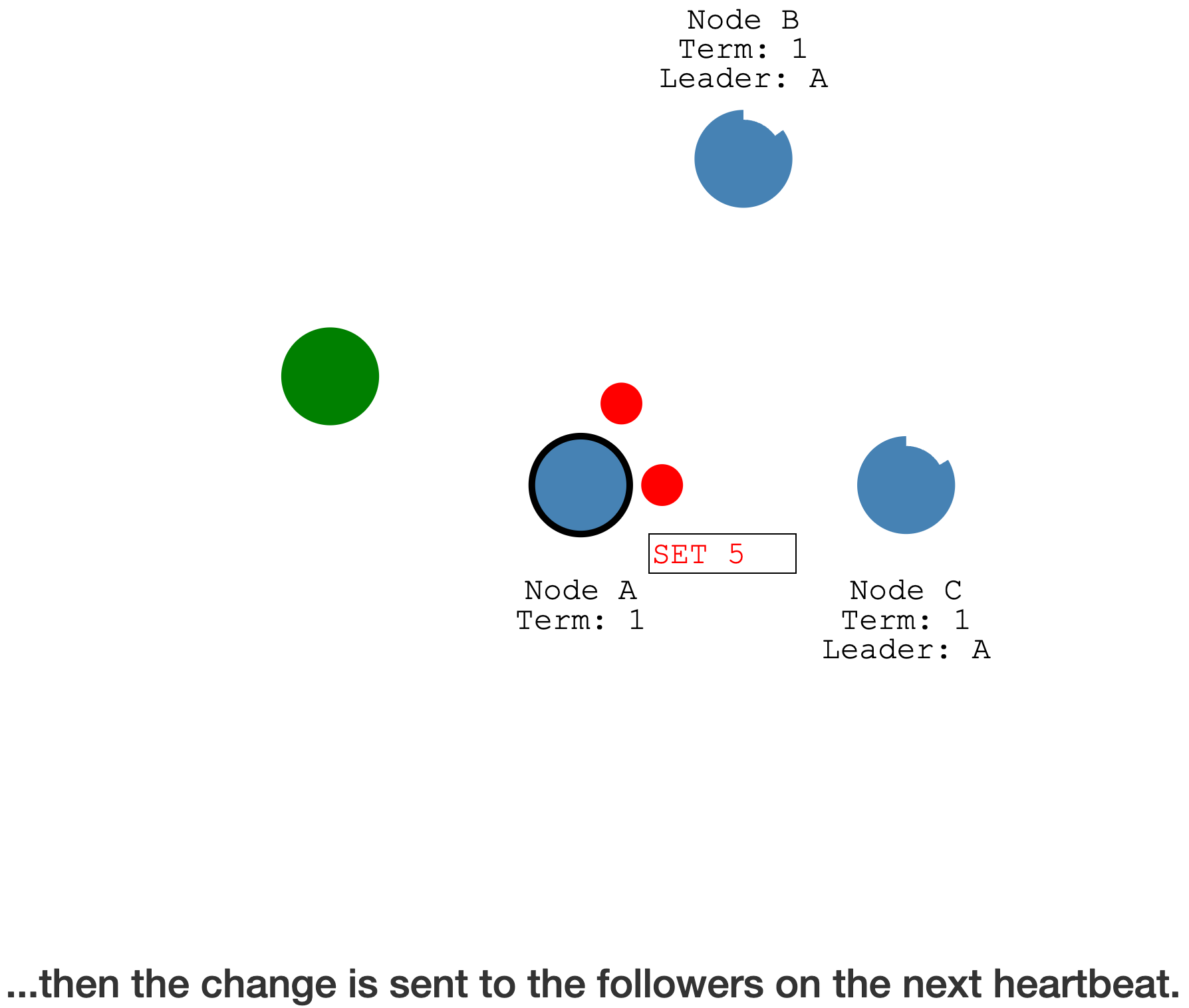
得到超过半数(
包括 Leader 自己)的成员确认已经写入了日志,Leader 会完成提交(状态机)
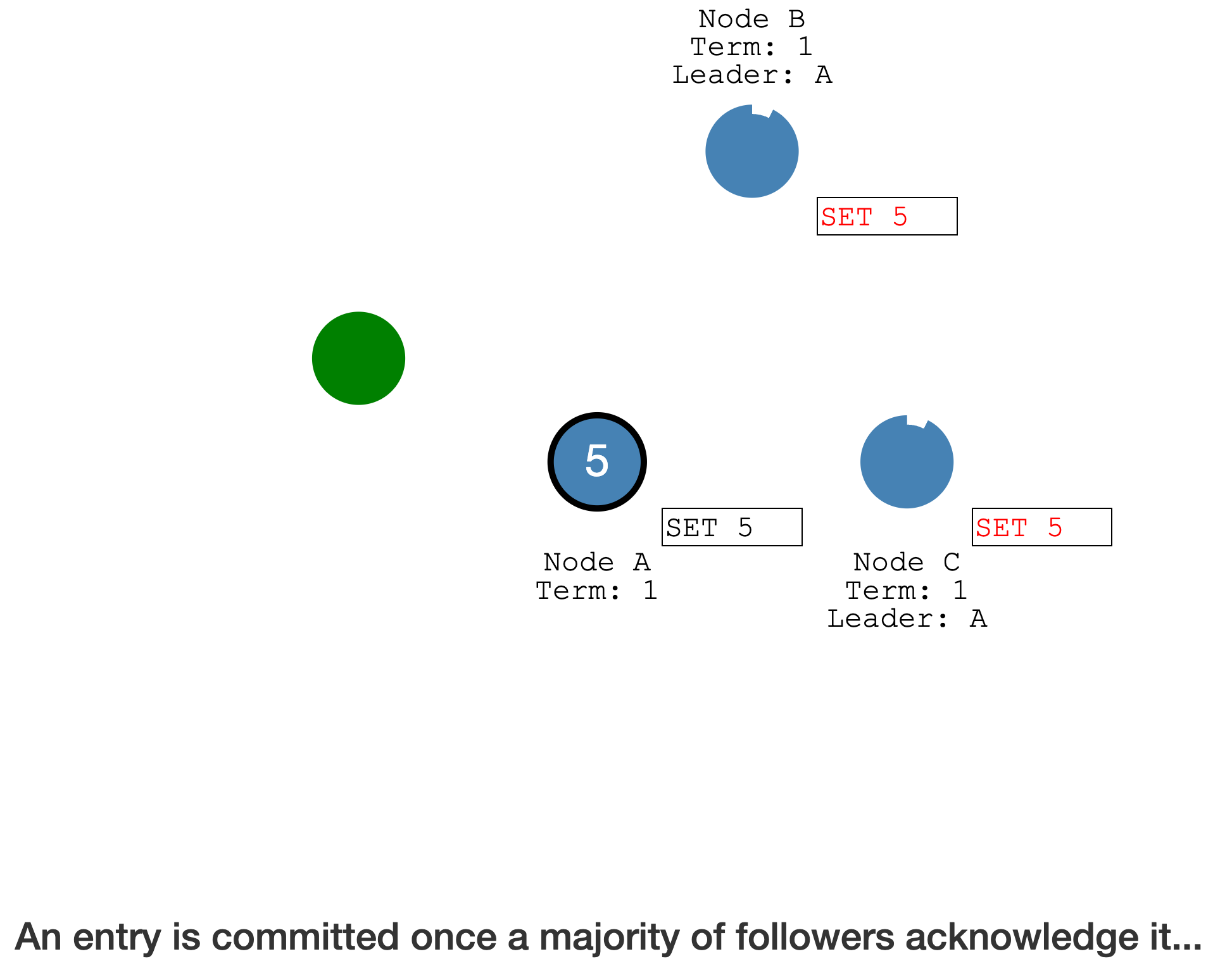
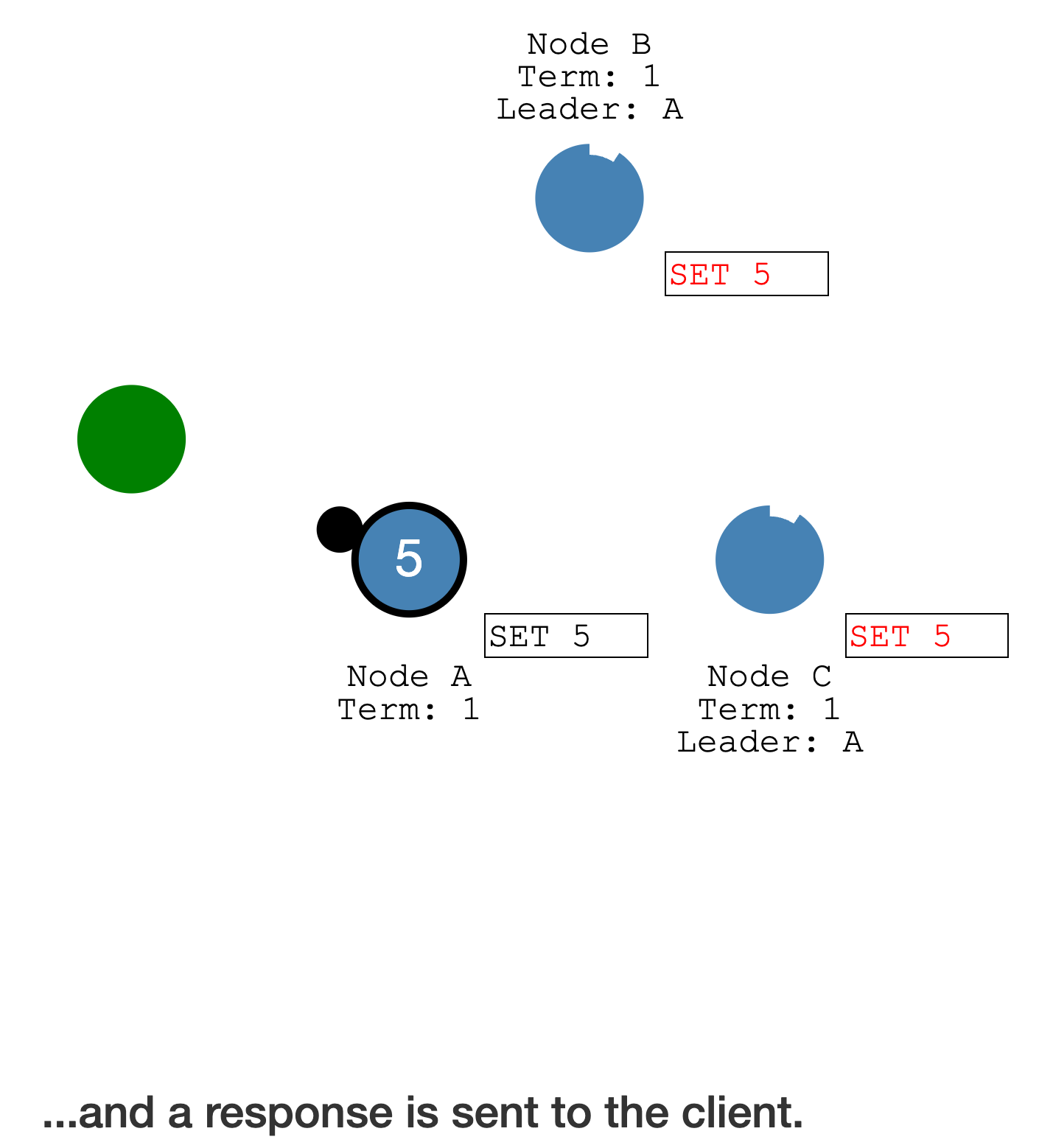
Leader 完成提交后,此时可以响应客户端
等待下个心跳,告知 Follower,该 Log entry 已提交,Follower 也可以完成提交了
在 etcd 中是一个配置参数(默认是
弱一致性,能满足绝大部分场景)弱一致性:只要Leader提交后,就响应客户端;强一致性:等待超过半数的 Follow也提交后,才响应客户端
即便在发生
网络分区时,Raft 协议依然能保持一致性
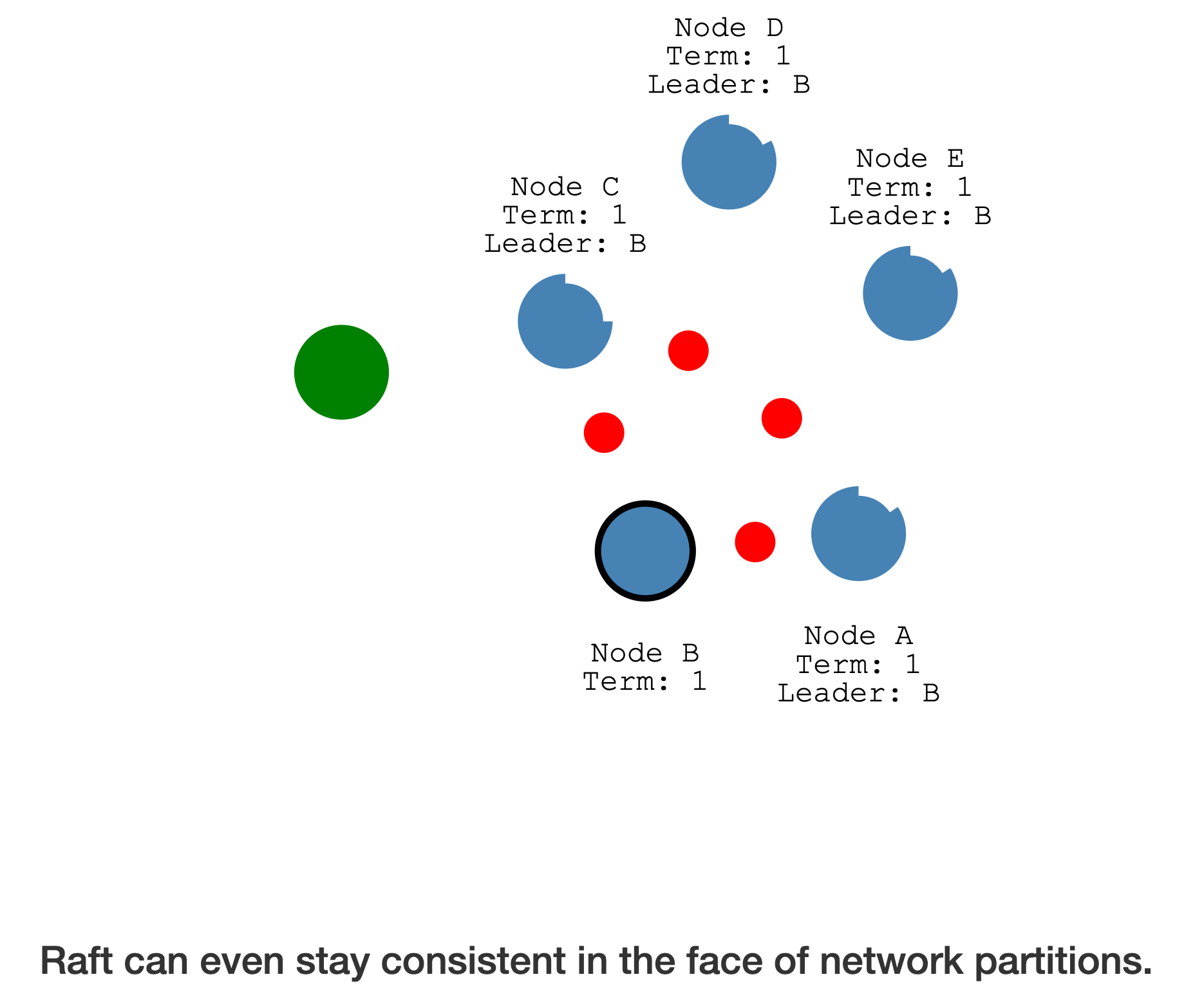
出现网络分区,原有的 Leader 在一个
少于半数的分区,另一个多于半数的分区完成了新一轮的选举(选举任期更大)
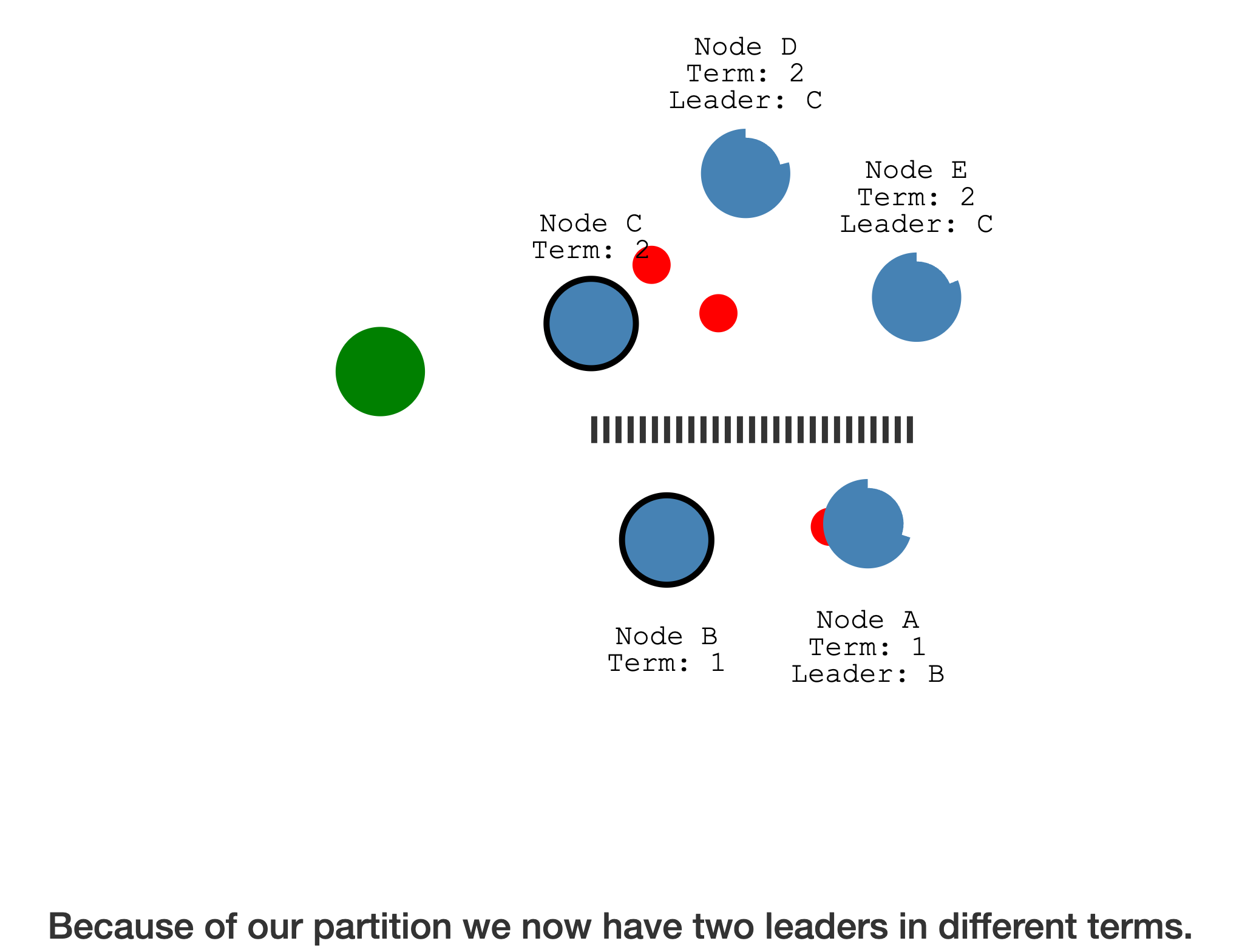
少于半数的分区,可读不可写,处于只读状态,且任期更低
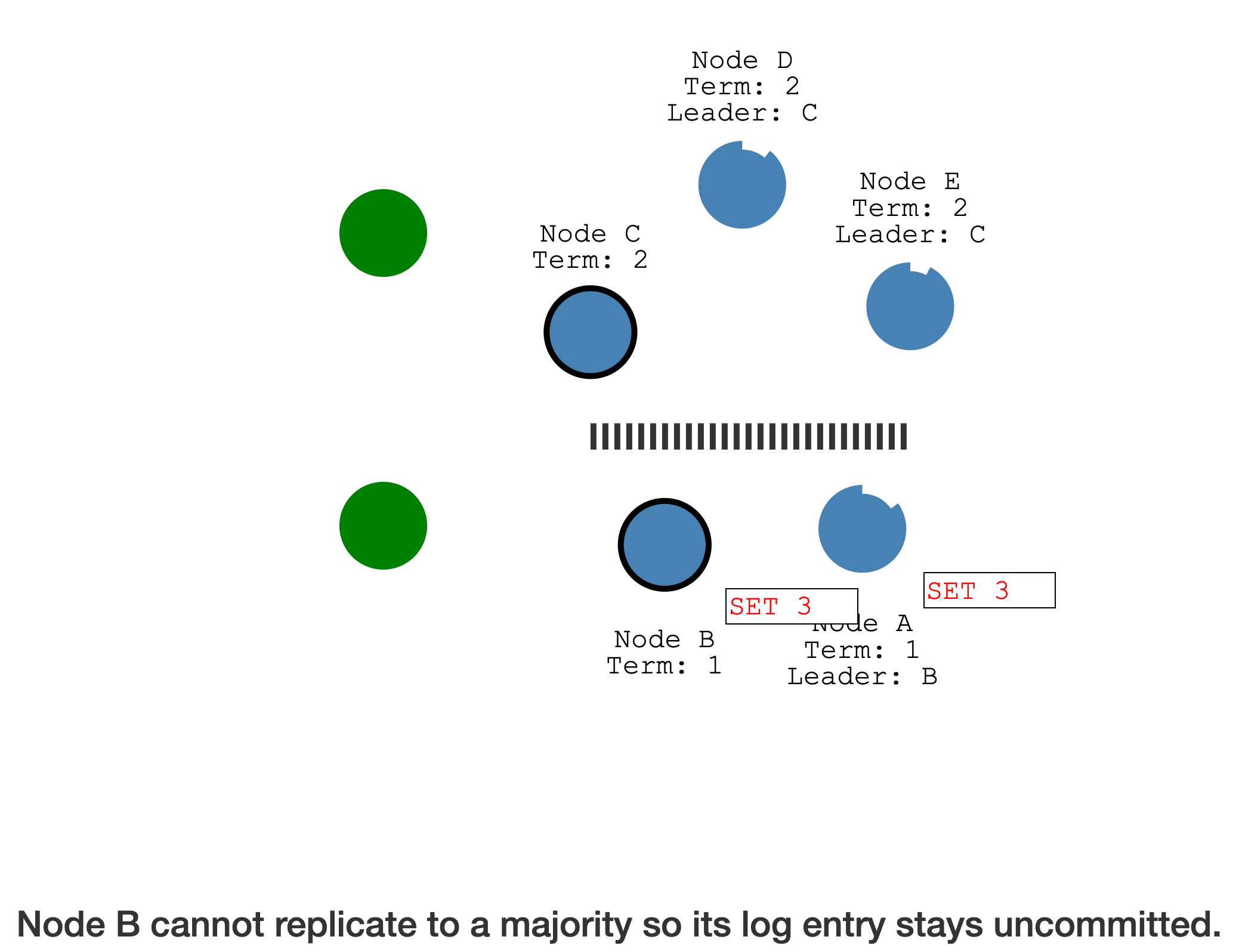
多于半数的分区,可读可写,且任期更高,优先级更高
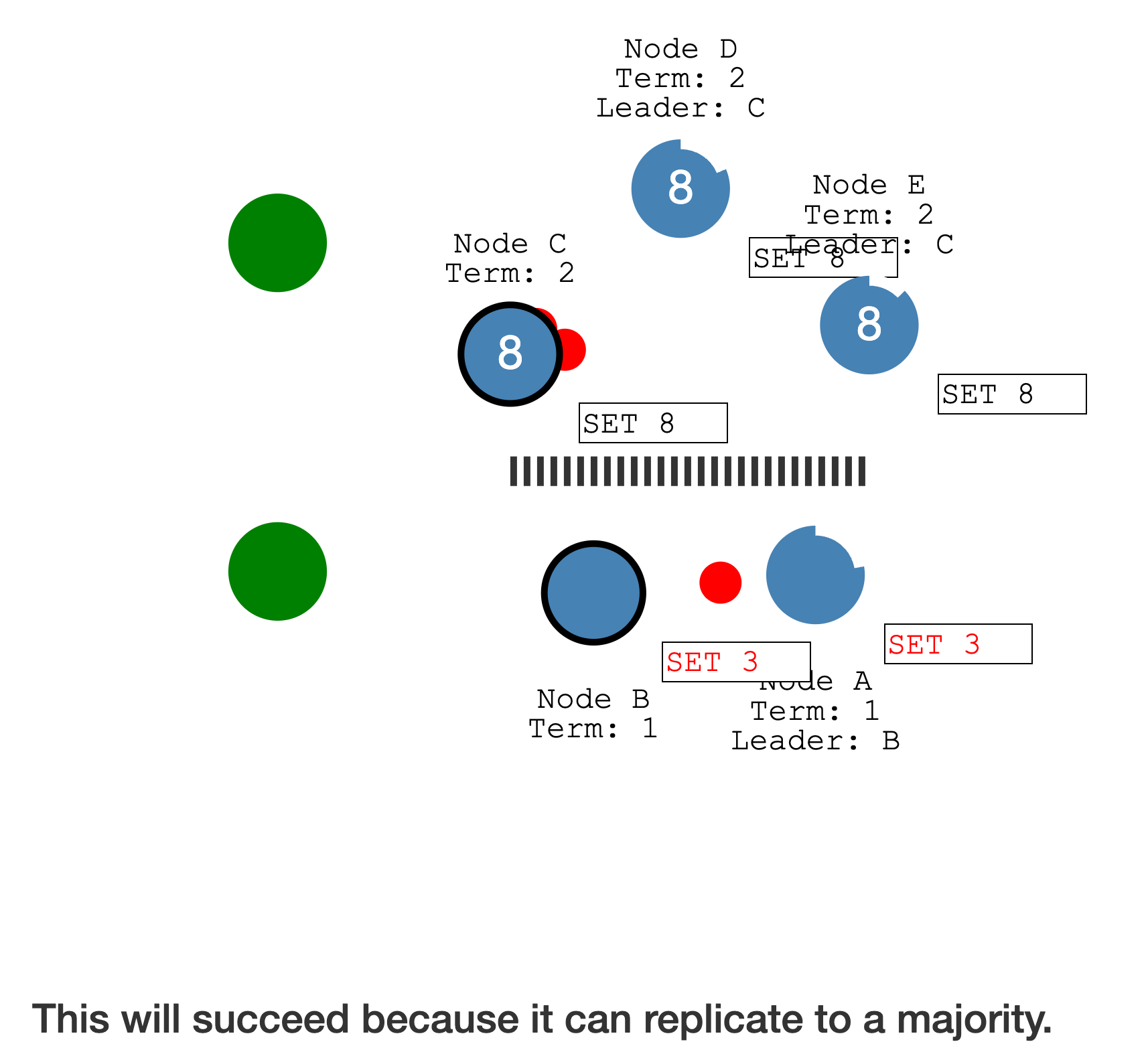
网络分区恢复后,以
高选举任期的 Leader 为准,低选举任期的 Leader降级为 Follower
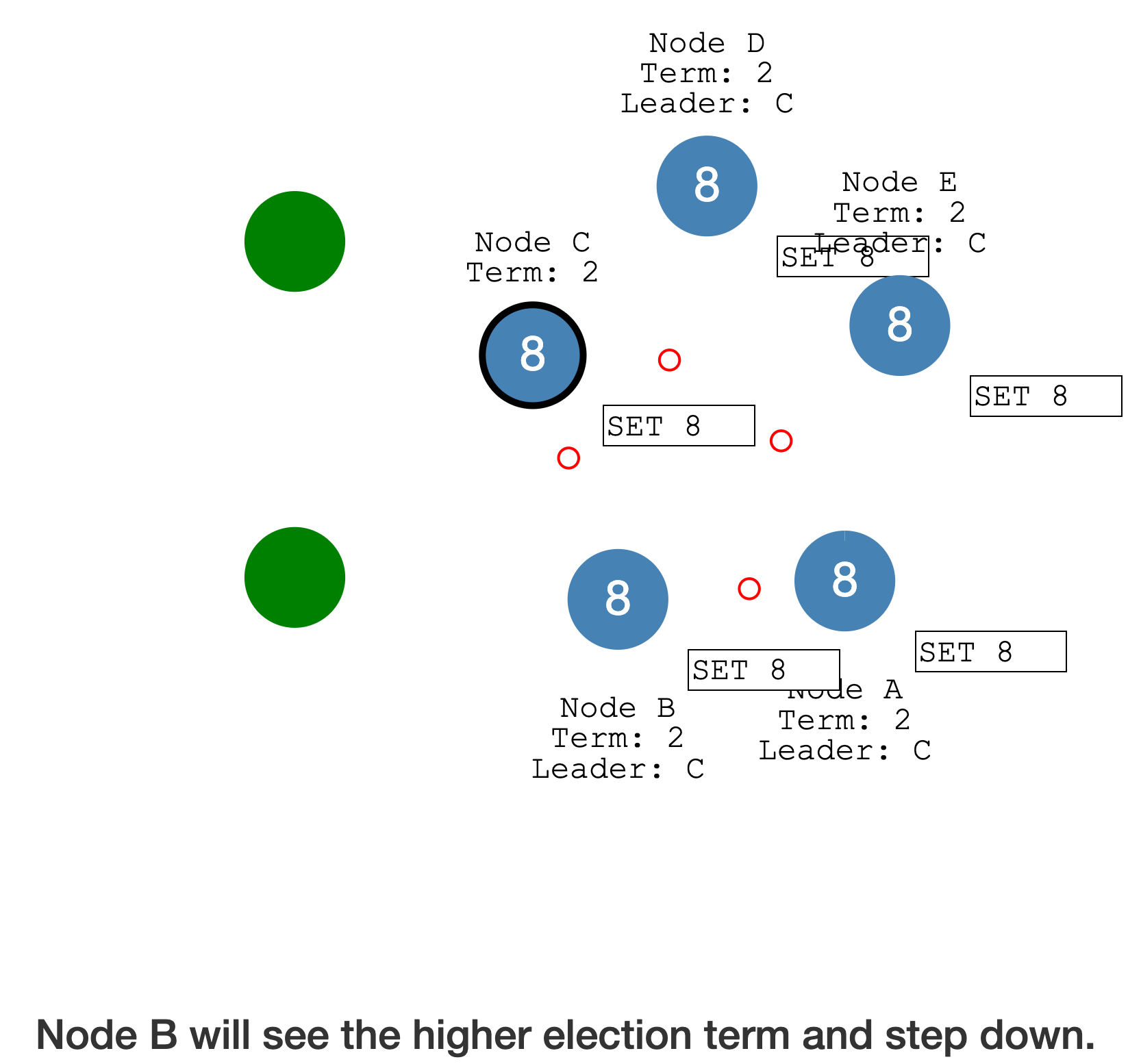
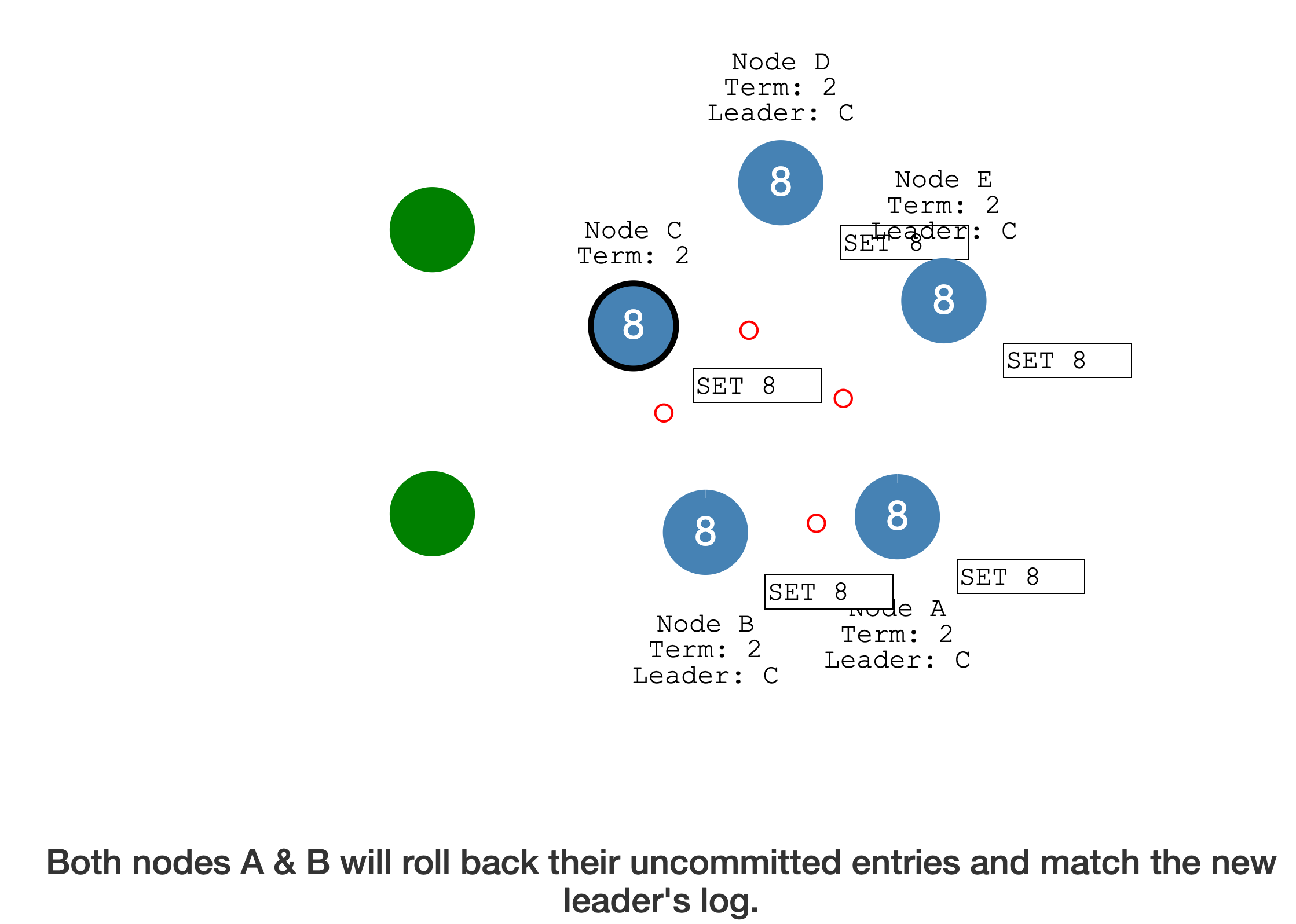
发生网络分区时
少于半数的分区,会放弃尚未提交的 Log entry,接收并提交新 Leader 的日志,最后集群恢复一致
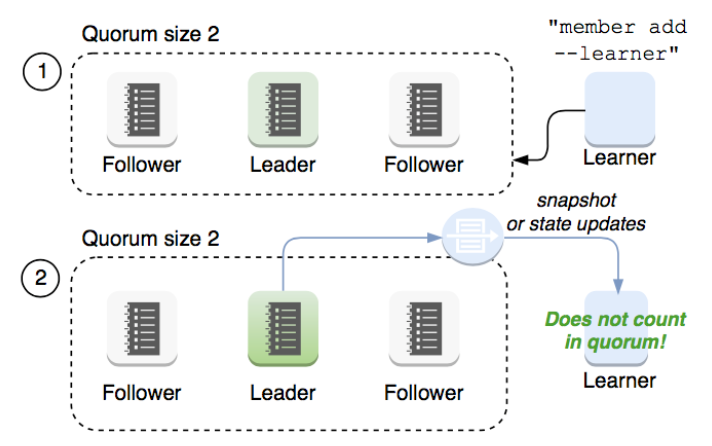
Learner
Raft
4.2.1引入 Learner:Learner只接收数据,但不参与投票,集群的Quorum(大多数) 不会发生变化
新启动的节点与 Leader 差异很大,默认以 Learner 身份启动,只有当 Learner
完成数据同步后,才有可能成为 Follower
安全性
保证每个节点都执行
相同的序列
选举安全性- 每个选举任期,只能选举出 1 个 Leader
Leader 日志完整性- 日志在某个任期被提交后,
后续任期的 Leader 都必须包含该日志 - 选举阶段:Candidate 本身的
偏移必须超过半数成员,才能赢得选举- Follower 只会投票给(
<Term,Index>)不比自己小的 Candidate,否则拒绝该投票请求
- Follower 只会投票给(
- 日志在某个任期被提交后,
实现
WAL
Write-
aheadlogging
WAL 为二进制,可以通过
etcd-dump-logs工具分析,数据结构为 LogEntry
由 4 部分组成:type、term、index、data
| Field | Desc |
|---|---|
| type | 0 - Normal1 - ConfChange:etcd 本身的配置发生变更,如有新节点加入 |
| term | 选举任期 |
| index | 变更序号,严格递增 |
| data | 二进制,为 protobuf 格式Raft 本身不关心 data,Raft 关注的只是 分布式一致性 |
Store V3
etcd 为 KV 存储,只需要处理好
Key 的索引即可
内存:kvindex -
<Key,List<Reversion>>;磁盘:boltdb -<Reversion,Key-Value>
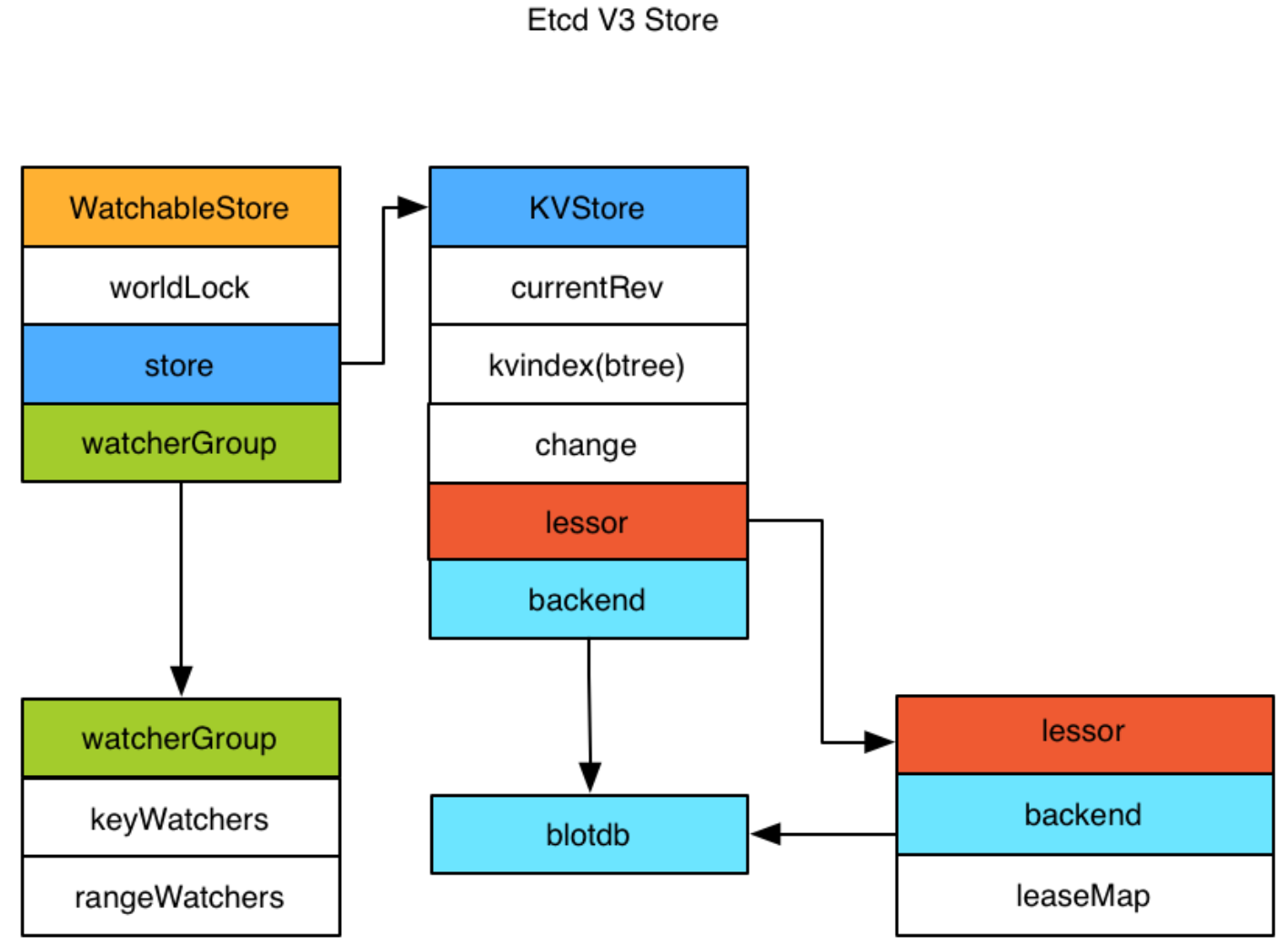
- Store 分为两部分
kvindex- 在
内存中的索引,基于B Tree,由 Google 开源,用 Go 实现
- 在
boltdb- 在
磁盘上的存储,基于B+ Tree,是backend的一种实现(backend可以对接多种存储实现) - boltdb 是一个
单机的支持事务的 KV 存储,etcd 的事务是基于 boltdb 的事务实现的- etcd 在 boltdb 中存储的
Key是reversion,Value为 etcd 自己的KV 组合- reversion 组成:
main rev(事务) +sub rev(事务内的操作)
- reversion 组成:
- etcd 会在 boltdb 中
存储每一个版本,从而实现多版本机制- etcd 支持设置
compact,用来控制某个 Key 的历史版本数量
- etcd 支持设置
- etcd 在 boltdb 中存储的
- 在
- 内存中的 kvindex 保存的是
Key和Reversion的映射关系,用于加速查询 WatchableStore:支持监听机制;lessor:支持TTL
写入
etcd 对 Raft 协议的实现
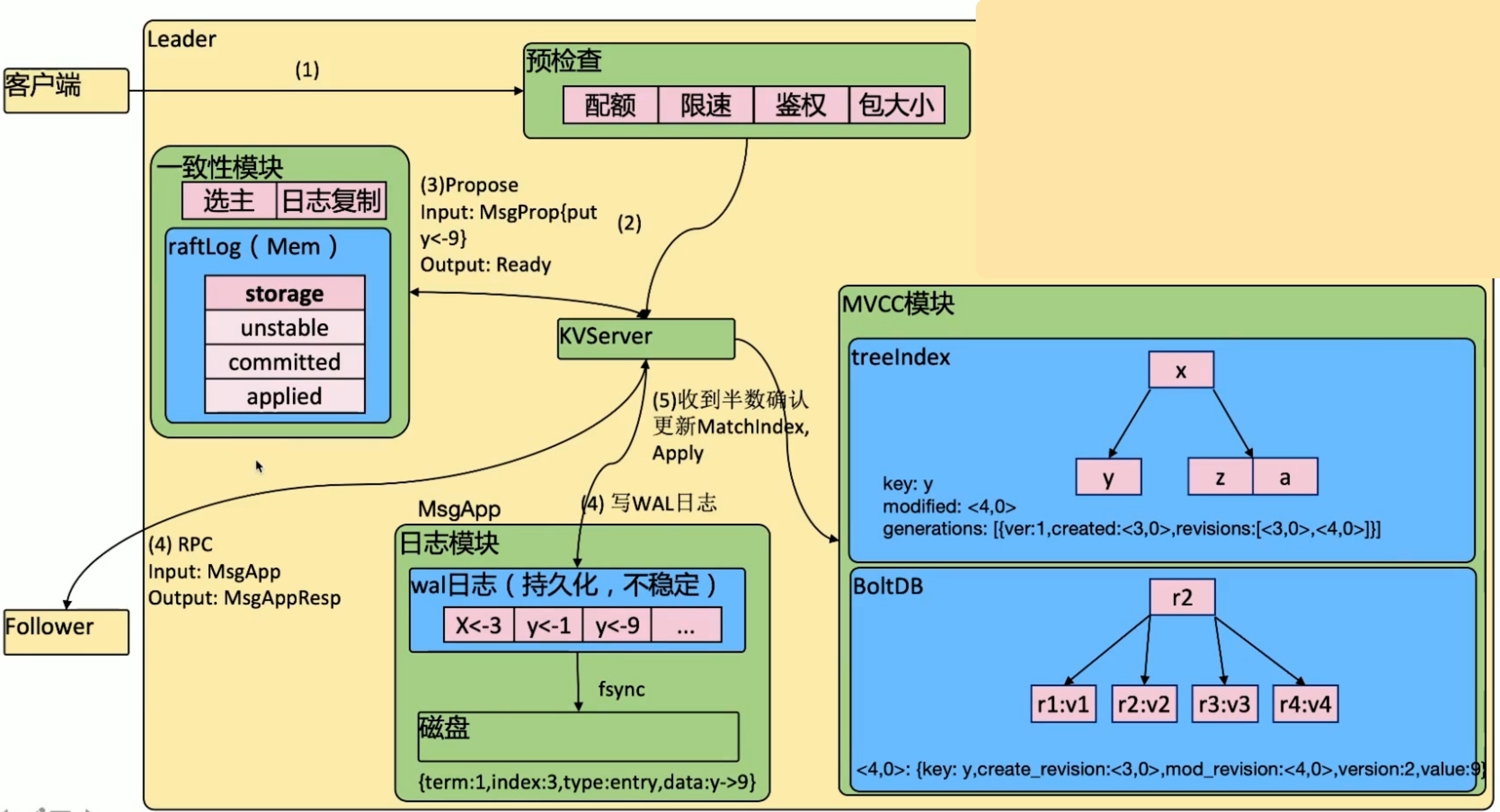
- 第 3 步,一致性模块接收到
Propose请求后,会放入内存中 raftLog 的unstable区域 - 第 4 步,
同时发生:WAL+RPC- WAL 需要通过周期性的
fsync持久化到磁盘上 - WAL 无法通过 ectdctl 读取,只能通过
etcd-dump-logs工具获取 - Follower 接收到请求后,执行的操作也是类似的:
raftLog+WAL
- WAL 需要通过周期性的
- 第 5 步,收到超过半数的成员确认
- 从 raftLog 中的
unstable区域,移动到committed区域 - 将
WAL提交到状态机(MVCC模块) - MVCC - 最终的状态机
- etcd 是
多读少写- TreeIndex + BoltDB - 加快读
- Leader + Follower - 支持读
TreeIndex-内存 B tree- Key 为用户写入的
Key,Value 为Reversion modified:<4,0>- 事务 ID 为 4,事务中的第 1 个操作,为当前的 Reversiongenerations- 历史变更记录
- Key 为用户写入的
BoltDB-磁盘 B+Tree- Key 为
Reversion,Value 为Key-Value
- Key 为
- etcd 是
- 从 raftLog 中的
- 在 Leader 提交到 MVCC 成功后,会更新
MatchIndex- 该 MatchIndex 会在
下一次心跳传播到 Follower ,Follower 也会将 WAL 提交到 MVCC - 集群达成了
分布式共识,时间上差了一个心跳
- 该 MatchIndex 会在
数据一致性(多数确认),
MatchIndex
revision 为
全局变量
1 | $ /tmp/etcd-download-test/etcdctl --endpoints=localhost:12379 put k v1 |
resourceVersion即 etcd 中的mod_revision乐观锁:多个Controller修改同一个 API 对象
1 | $ k get po -n kube-system etcd-mac-k8s -oyaml | grep resourceVersion |
Watch
- Watcher 分类
KeyWatcher:监听固定的 KeyRangeWatcher:监听范围的 Key
- WatcherGroup 分类
synced:Watcher 数据已经完成同步unsynced:Watcher 数据同步中
- etcd 发起请求,携带了
revision参数- revision 参数
>etcd 当前的 revision- 将该 Watcher 放置于
synced的 WatcherGroup
- 将该 Watcher 放置于
- revision 参数
<etcd 当前的 revision- 将该 Watcher 放置于
unsynced的 WatcherGroup - 在 etcd 后端启动一个
goroutine从BoltDB读取数据- 完成同步后,将 Watcher 迁移到
synced的 WatcherGroup,并将数据发给客户端
- 完成同步后,将 Watcher 迁移到
- 将该 Watcher 放置于
- revision 参数
灾备
etcdctl
snapshot save+ etcdctlsnapshot restore
容量
- 单个对象不超过
1.5M - 默认容量
2G,不超过8G- 因为内存有限制- 直接访问磁盘上的
BoltDB是非常低效的, 将BoltDB通过mmap的方式直接映射到内存 TreeIndex本身也要占用内存
- 直接访问磁盘上的
设置 ectd 存储大小:
--quota-backend-bytes
1 | $ /tmp/etcd-download-test/etcd --listen-client-urls 'http://localhost:12379' \ |
写满 ectd:
etcdserver: mvcc: database space exceeded
1 | $ while [ 1 ]; do dd if=/dev/urandom bs=1024 count=1024 | ETCDCTL_API=3 /tmp/etcd-download-test/etcdctl --endpoints http://localhost:12379 put key || break; done |
可读不可写
1 | $ /tmp/etcd-download-test/etcdctl --endpoints http://localhost:12379 get k |
告警:
NOSPACE
1 | $ tmp/etcd-download-test/etcdctl --endpoints http://localhost:12379 alarm list |
清理碎片,依然无法解决
1 | $ /tmp/etcd-download-test/etcdctl --endpoints http://localhost:12379 defrag |
压缩历史版本数量
1 | $ /tmp/etcd-download-test/etcdctl --endpoints http://localhost:12379 get key -wjson | jq '.header.revision' |
etcd 启动参数,自动压缩,保存一小时的历史:
--auto-compaction-retention=1
高可用
集群 + 备份(容灾)
实践
cfssl
1 | $ sudo apt install golang-cfssl |
tls certs
1 | $ mkdir -p $GOPATH/github.com/etcd-io |
1 | $ git clone https://github.com/etcd-io/etcd.git |
req-csr.json -
Certificate Signing Requests
1 | { |
certs
1 | $ export infra0=127.0.0.1 |
start etcd
1 | nohup /tmp/etcd-download-test/etcd --name infra0 \ |
1 | $ sh start-all.sh |
1 | $ /tmp/etcd-download-test/etcdctl \ |
backup,
snapshot是全量的
1 | $ /tmp/etcd-download-test/etcdctl \ |
delete data + kill etcd
1 | $ rm -rf /tmp/etcd |
restore
1 | export ETCDCTL_API=3 |
1 | $ sh ./restore.sh |
restart 不需要指定
--initial-cluster,在 restore 阶段已指定
1 | nohup /tmp/etcd-download-test/etcd --name infra0 \ |
1 | $ sh ./restart.sh |
社区
etcd operator
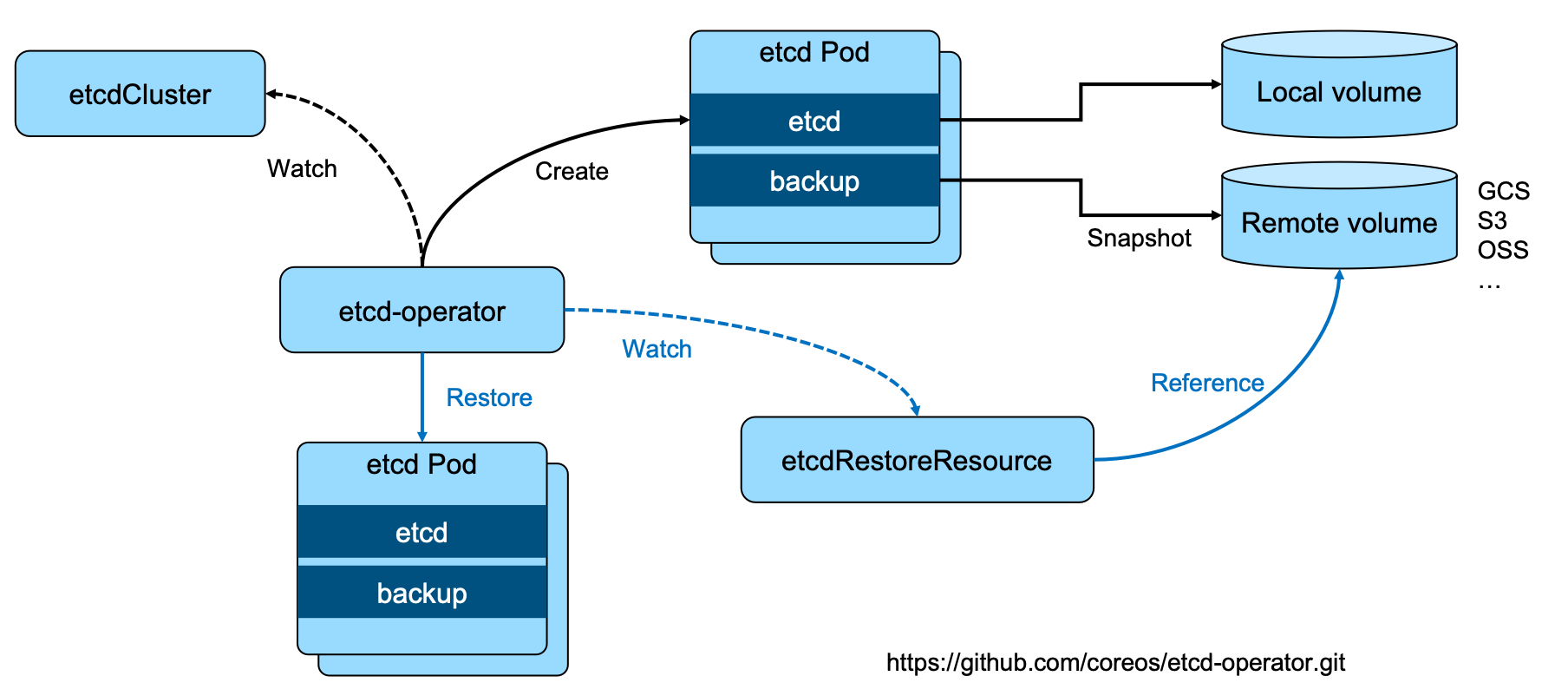
- CRD -
etcdCluster+etcdRestoreResource- etcd-operator 监听到
etcdCluster:创建etcd Pod - etcd-operator 监听到
etcdRestoreResource:恢复etcd Pod
- etcd-operator 监听到
- etcd Pod 包含两个容器:
etcd+backup- etcd 要
外挂存储
- etcd 要
1 | $ sudo cat /etc/kubernetes/manifests/etcd.yaml |
Statefulset
Helm
Kubernetes
- etcd 是 Kubernetes 的
后端存储 - 对于每一个
API 对象,都有对应的storage.go负责对象的存储操作 - API Server 在启动脚本中指定 etcd 集群
1 | $ sudo cat /etc/kubernetes/manifests/kube-apiserver.yaml |
API 对象在 etcd 中的存储路径
1 | $ ps -ef | grep etcd |
架构
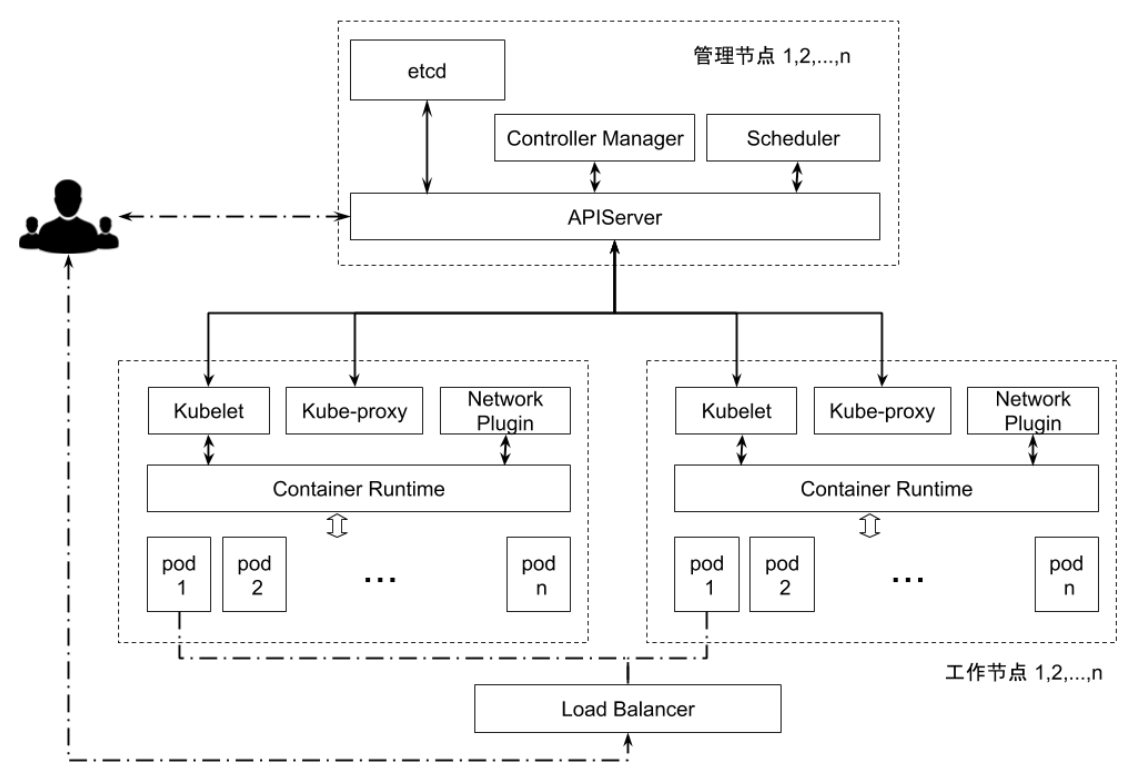
API Server 通过
--etcd-servers-overrides指定辅助 etcd 集群,增强主 etcd 集群的稳定性
1 | /usr/local/bin/kube-apiserver \ |
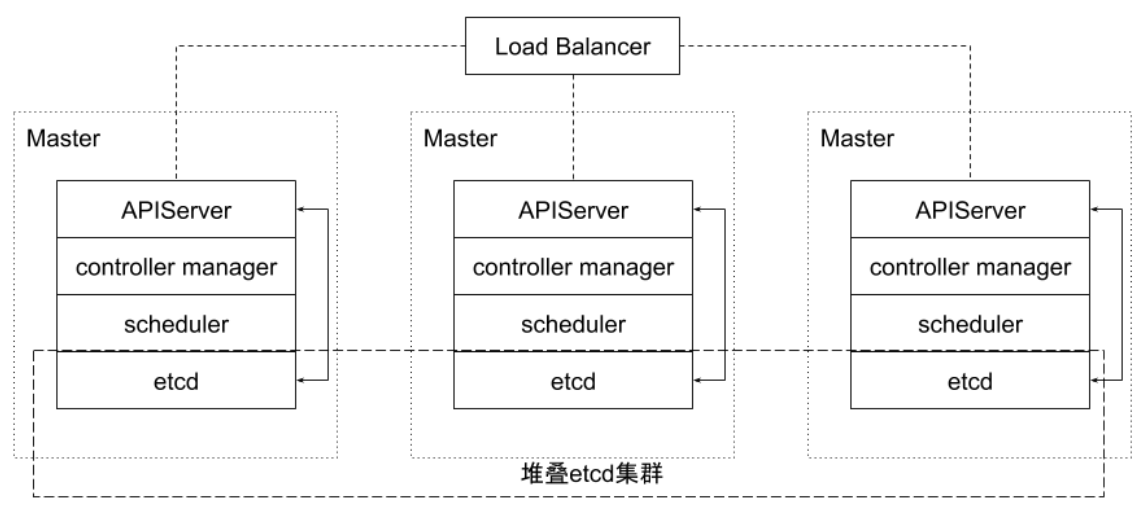
堆叠式 etcd 集群:至少3个节点
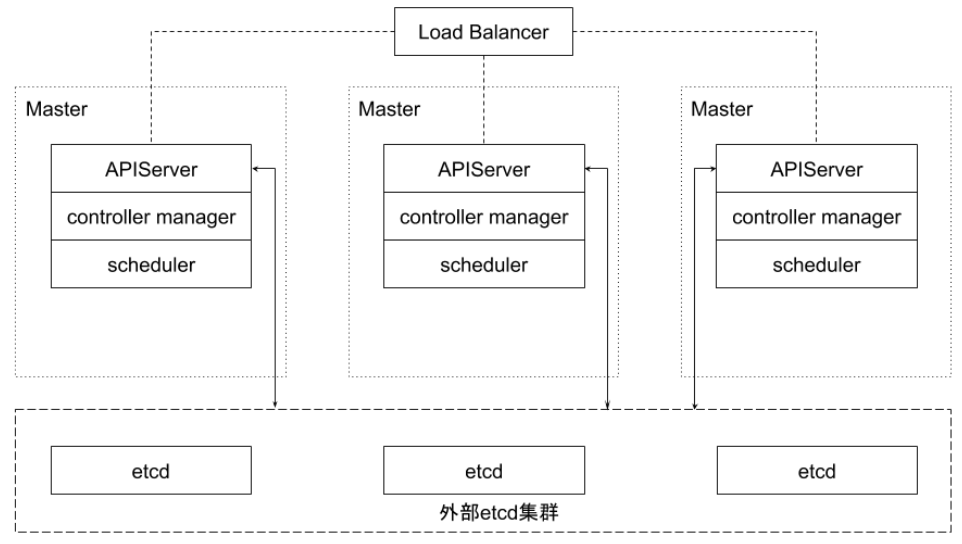
外部 etcd 集群:至少
6个节点
经验
高可用
5个 peer,一般不需要弹性扩容,但多 peer 不一定能提升读性能- API Server 配置了所有的 etcd peers,但只有在当前连接的 etcd member
异常时,才会切换
- API Server 配置了所有的 etcd peers,但只有在当前连接的 etcd member
- 高效通信
- API Server 和 etcd 部署在同一个节点 -
堆叠 - API Server 和 etcd 之间的通信是基于
gRPC,而gRPC是基于HTTP/2- HTTP/2 中的
Stream是共享 TCP Connection,并没有解决 TCP队头阻塞的问题
- HTTP/2 中的
- API Server 和 etcd 部署在同一个节点 -
存储
- 最佳实践:
Local SSD+Local volume
安全
- peer 之间的通信是
加密的 - Kubernetes 的
Secret对象,是对数据加密后再存入 etcd
事件分离
--etcd-servers-overrides
网络延迟
- etcd 集群尽量
同 Region 部署
日志大小 -
创建 Snapshot+移除 WAL
- etcd
周期性创建 Snapshot保存系统的当前状态,并移除 WAL - 指定
--snapshot-count(默认10,000),即到一定的修改次数,etcd 会创建 Snapshot
合理的储存配额(8G)
没有存储配额,etcd 可以利用整个磁盘,性能在大存储空间时严重下降,且耗完磁盘空间后,分险不可预测存储配额太小,容易超出配额,使得集群处于维护模式(只接收读和删除请求)
自动压缩历史版本
- 压缩历史版本:
丢弃某个 Key在给定版本之前的所有信息 - etcd 支持
自动压缩,单位为小时:--auto-compaction
定期消除碎片
压缩历史版本:离散地抹除 etcd 存储空间中的数据,将会出现碎片- 碎片:无法被利用,但依然占用存储空间
备份与恢复
- snapshot
save+ snapshotrestore - 对 etcd 的影响
- 做 snapshot save 时,会
锁住当前数据 并发的写操作需要开辟新空间进行增量写,磁盘会增长
- 做 snapshot save 时,会
增量备份
- wal - 记录数据变化的过程,提交前,都需要写入到 wal
- snap - 生成 snap 后,wal 会被
删除 - 完整恢复 -
restore snap + replay wal

Heatbeat Interval + Election Timeout
- 所有节点的配置都应该一致
ResourceVersion
单个对象的 ResourceVersion:对象最后修改的 ResourceVersionList 对象的 ResourceVersion:生成 List Response 时的 ResourceVersion
List 行为
无 ResourceVersion,需要Most Recent数据,请求会击穿 API Server 缓存,直接到 etcd- API Server 通过 Label 过滤查询对象时,实际的
过滤动作在API Server,需要向 etcd 发起全量查询