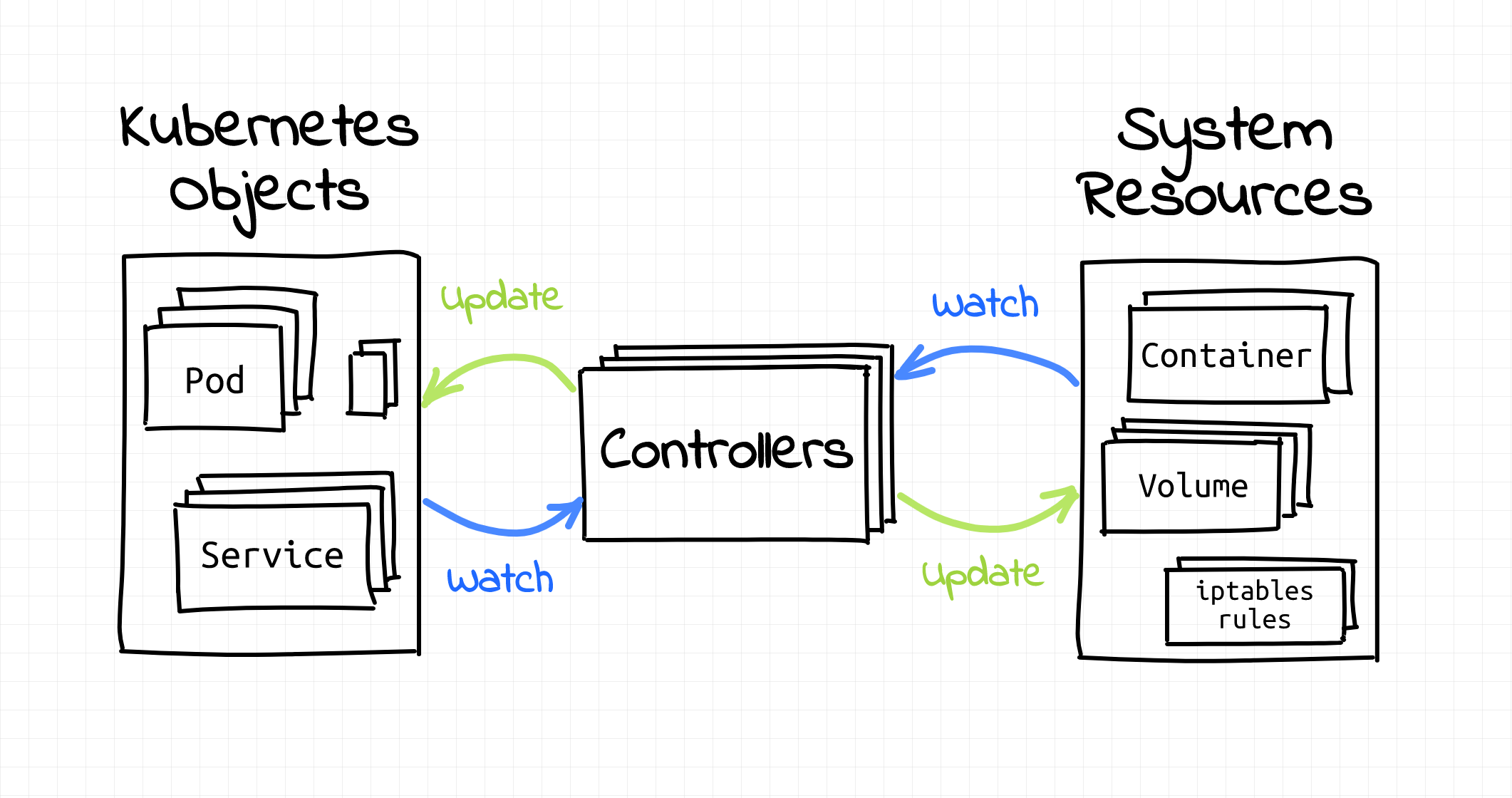
生命周期
Pending - 调度尚未成功,ContainerCreating - 完成调度
Pod 状态机
Pod Phase
Pod Phase: Pending / Running / Succeeded / Failed / Unknown
k get pod 显示的 STATUS 是由 pod.status.phase 和 pod.status.conditions 计算得出
1 2 3 $ k get po nginx NAME READY STATUS RESTARTS AGE nginx 1/1 Running 0 35s
k get po nginx -oyaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 status: conditions: - lastProbeTime: null lastTransitionTime: "2022-08-28T07:00:45Z" status: "True" type: Initialized - lastProbeTime: null lastTransitionTime: "2022-08-28T07:00:46Z" status: "True" type: Ready - lastProbeTime: null lastTransitionTime: "2022-08-28T07:00:46Z" status: "True" type: ContainersReady - lastProbeTime: null lastTransitionTime: "2022-08-28T07:00:45Z" status: "True" type: PodScheduled containerStatuses: - containerID: docker://7610adb2b5874ac1de274a2839679fd9d45d7c2f4046203b12725e6f53c1f220 image: nginx:1.25.2 imageID: docker-pullable://nginx@sha256:104c7c5c54f2685f0f46f3be607ce60da7085da3eaa5ad22d3d9f01594295e9c lastState: {} name: nginx ready: true restartCount: 0 started: true state: running: startedAt: "2022-08-28T07:00:46Z" phase: Running
Pod Status 的计算细节
Status
Phase
Conditions
Completed
Succeeded
ContainerCreating
Pending
CrashLoopBackOff
Running
container exits
CreateContainerConfigError
Pending
configmap or secret not found
ErrImagePull
Pending
back-off pulling image
Error
Error
restartPolicy: Never
Evicted
Failed
message: ‘Usage of Empty Dir volume
Init:0/1
Pending
Init containers don’t exit
Init:CrashLoopBackOff /
Pending
Init container crashed (exit with not 1)
OOMKilled
Running
Containers are OOMKilled
StartError
Running
Containers cannot be started
Unknown
Running
Node NotReady
OutOfCpu/OutOfMemory
Failed
Scheduled, but it cannot pass kubelet admit
Pod HA
避免容器进程被终止 + 避免 Pod 被驱逐
kubelet 会监控不可压缩资源(内存、磁盘等)的使用情况,会驱逐相关的 Pod
设置合理的 resources.memory.limit,防止容器进程被 OOMKill
设置合理的 emptydir.sizeLimit 并确保数据写入不超过 emptyDir 的限制,防止 Pod 被驱逐
存储
多容器之间共享存储,最简单的方案是 emptyDir
emptyDir 需要控制 size limit
无限扩张的应用会撑爆主机磁盘导致主机不可用,导致大规模集群故障
emptyDir size limit 生效后
kubelet 会定期对容器目录执行 du 操作,会产生性能影响 - 前期版本的方案
到达 size limit 后
Pod 会被驱逐,原 Pod 的日志配置等信息会消失
数据
当 Configmap 以 Volume 的形式挂载到 Pod 后,变更会有延迟(一般为 1 分钟)
除了 rootFS(不可变基础设施),容器重启后数据还在(没有调度到其它 Node)Network volume,Pod 重建后,数据不在了
控制日志写入速度,防止 OS 在配置日志滚动窗口期内将硬盘写满
存储卷类型
容器重启后
Pod 重建后
大小控制
备注
emptyDirN
hostPath - 不常用N(调度到别的 Node)
N
需要额外权限控制
Local volumeN
无备份
Network volume
rootFSN
N
N
不要写任何数据
中断
kubelet 升级
大部分情况下,不会重建 Pod
某些版本因为修改了哈希算法所以会重建 Pod
OS 升级 / Node 重启
Pod 进程会被终止数分钟(≈ 10 分钟)
跨故障域部署
修改 livenesProbe 和 readinessProbe,加速应用启动
增加 Node NotReady 的 Toleration 时间(例如 15 分钟),避免被驱逐
Node 计划下架
drain Node(优雅驱逐 Pod),Pod 进程会被终止数分钟(≈ 10 分钟)
跨故障域部署
利用 Pod distruption budget 避免 Node 被 drain 而导致 Pod 被意外删除
应用最多容忍有几个 Pod 不 Ready,避免因为 drain Node 而导致 Pod 一下子被驱逐过多
利用 pre-stop 做数据备份等操作
1 2 3 4 $ k api-resources --api-group='policy' NAME SHORTNAMES APIVERSION NAMESPACED KIND poddisruptionbudgets pdb policy/v1 true PodDisruptionBudget podsecuritypolicies psp policy/v1beta1 false PodSecurityPolicy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apiVersion: policy/v1 kind: PodDisruptionBudget metadata: name: calico-typha namespace: calico-system spec: maxUnavailable: 1 selector: matchLabels: k8s-app: calico-typha status: currentHealthy: 1 desiredHealthy: 0 disruptionsAllowed: 1 expectedPods: 1
Node Crashed
Pod 进程会被终止超过 15 分钟
冗余
副本数
更新策略 - maxSurge + maxUnavailable
PodTemplateHash 的易变形
Pod QoS
当内存承压时,按照 BestEffort -> Burstable -> Guaranteed 的顺序依次驱逐 Pod
Level
QoS
Desc
Scene
High
Guaranteed每个容器都设置了 CPU 和 Memory 需求完全一致重要业务
Burstable至少1个容器设置了 CPU 和 Memory 需求不一致大多数场景
Low
BestEffort每个容器都没有设置了 CPU 和 Memory 需求生产尽量避免
1 2 3 4 5 6 7 8 9 10 spec: containers: resources: limits: cpu: 700m memory: 200Mi requests: cpu:700m memory: 200Mi qosClass: Guaranteed
1 2 3 4 5 6 7 8 spec: containers: resources: limits: memory: 200Mi requests: memory: 100Mi qosClass: Burstable
1 2 3 4 spec: containers: resources: {} qosClass: BestEffort
Concept
Key points
priorityClass关注调度(抢占低优 Pod)
qosClass关注驱逐(资源承压时的质量保证)
Toleration + Eviction
节点临时不可达
网络分区
kubelet、containerd 不工作
节点重启超过 15 分钟
增加 tolerationSeconds 以避免被驱逐
NotReady Node
1 2 3 4 5 6 7 8 9 10 11 12 13 taints: - effect: NoSchedule key: node.kubernetes.io/unreachable timeAdded: "2020-07-09T11:25:10Z" - effect: NoExecute key: node.kubernetes.io/unreachable timeAdded: "2020-07-09T11:25:21Z" - effect: NoSchedule key: node.kubernetes.io/not-ready timeAdded: "2020-07-09T11:24:28Z" - effect: NoExecute key: node.kubernetes.io/not-ready timeAdded: "2020-07-09T11:24:32Z"
增加 tolerationSeconds
1 2 3 4 5 6 7 8 9 tolerations: - effect: NoExecute key: node.kubernetes.io/not-ready operator: Exists tolerationSeconds: 900 - effect: NoExecute key: node.kubernetes.io/unreachable operator: Exists tolerationSeconds: 900
Probe
探针类型 - startupProbe 通过后,livenessProbe 和 readinessProbe 才会介入
Probe
Desc
startupProbe在初始化阶段(Ready 之前)进行的健康检查延迟探测
livenessProbe探活,当检查失败时,意味着应用进程已经无法正常提供服务kubelet 会终止该容器进程并按照 restartPolicy 决定是否重启
readinessProbe就绪状态检查,当检查失败时,意味着应用进程正在运行,但不能提供服务NotReady,不接受流量
探测方法
Method
Type
ExecAction在容器内部运行指定命令,当返回码为 0 时,探测成功
TCPSocketAction由 kubelet 发起,通过 TCP 协议检查容器 IP 和 Port,当端口可达时,探测成功
HTTPGetAction由 kubelet 发起,对 Pod 进行 GET 请求,当返回码为 200 ~ 400,探测成功
探针属性 - livenesProbe.successThreshold 必须为 1
Params
Default
Min
initialDelaySeconds0
0
period Seconds
10
1
timeoutSeconds1
1
successThreshold
1
1
failureThreshold
3
1
1 2 3 4 5 6 7 8 9 livenesProbe: httpGet: s path: /healthz port: 8080 httpHeaders: - name: X-Custom-Header value: Awesome initialDelaySeconds: 15 timeoutSeconds: 1
30 秒后开始探测,5 秒为周期,35 秒就绪,40 秒删除文件,连续 3 次探测失败,55 秒恢复未就绪,但不会终止 Pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: v1 kind: Pod metadata: name: initial-delay spec: containers: - name: initial-delay image: centos args: - /bin/sh - -c - touch /tmp/healthy; sleep 40 ; rm -rf /tmp/healthy; sleep 600 readinessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 30 periodSeconds: 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 $ k describe po initial-delay Name: initial-delay Namespace: default Priority: 0 Node: mac-k8s/192.168.191.153 Start Time: Tue, 29 Aug 2022 08:25:42 +0800 Labels: <none> Annotations: cni.projectcalico.org/containerID: 65b75a148cab67864c4ef204299083bcd73ad3028037142f6be2810e42d3157f cni.projectcalico.org/podIP: 192.168.185.10/32 cni.projectcalico.org/podIPs: 192.168.185.10/32 Status: Running IP: 192.168.185.10 IPs: IP: 192.168.185.10 Containers: initial-delay: Container ID: docker://c9246e77914de66df7d961a08e9594c60990c8bfc7b91b18a5323fcaedc7a388 Image: centos Image ID: docker-pullable://centos@sha256:a27fd8080b517143cbbbab9dfb7c8571c40d67d534bbdee55bd6c473f432b177 Port: <none> Host Port: <none> Args: /bin/sh -c touch /tmp/healthy; sleep 40; rm -rf /tmp/healthy; sleep 600 State: Running Started: Tue, 29 Aug 2022 08:25:44 +0800 Ready: False Restart Count: 0 Readiness: exec [cat /tmp/healthy] delay=30s timeout=1s period=5s #success=1 #failure=3 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-ppn52 (ro) Conditions: Type Status Initialized True Ready False ContainersReady False PodScheduled True Volumes: kube-api-access-ppn52: Type: Projected (a volume that contains injected data from multiple sources) TokenExpirationSeconds: 3607 ConfigMapName: kube-root-ca.crt ConfigMapOptional: <nil> DownwardAPI: true QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 3m51s default-scheduler Successfully assigned default/initial-delay to mac-k8s Normal Pulling 3m50s kubelet Pulling image "centos" Normal Pulled 3m49s kubelet Successfully pulled image "centos" in 1.331745551s Normal Created 3m49s kubelet Created container initial-delay Normal Started 3m49s kubelet Started container initial-delay Warning Unhealthy 96s (x21 over 3m6s) kubelet Readiness probe failed: cat: /tmp/healthy: No such file or directory
1 2 3 4 5 6 7 8 9 $ k get po -w NAME READY STATUS RESTARTS AGE initial-delay 0/1 Pending 0 0s initial-delay 0/1 Pending 0 0s initial-delay 0/1 ContainerCreating 0 0s initial-delay 0/1 ContainerCreating 0 1s initial-delay 0/1 Running 0 2s initial-delay 1/1 Running 0 35s initial-delay 0/1 Running 0 55s
3 秒就是 Ready,默认为存活,10 秒后开始探活,周期为 5 秒,45 秒会探活失败(累计 3 次),原地重启 PodSIGKILL - Exit Code 137
探活 ≈ 探死,livenessProbe 不会重建 Pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: v1 kind: Pod metadata: name: liveness spec: containers: - name: liveness image: centos args: - /bin/sh - -c - touch /tmp/healthy; sleep 30 ; rm -rf /tmp/healthy; sleep 600 livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 10 periodSeconds: 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 $ k describe po liveness Name: liveness Namespace: default Priority: 0 Node: mac-k8s/192.168.191.153 Start Time: Tue, 29 Aug 2022 08:38:02 +0800 Labels: <none> Annotations: cni.projectcalico.org/containerID: d1d42cce5270ebc8c5f92277d69ada4a6d640c43b0da7a1a8380897f290a9a19 cni.projectcalico.org/podIP: 192.168.185.11/32 cni.projectcalico.org/podIPs: 192.168.185.11/32 Status: Running IP: 192.168.185.11 IPs: IP: 192.168.185.11 Containers: liveness: Container ID: docker://c22a7dc92cd082ea82dbf7f3f2604458080ea3a059dcff5307b308a393f3ce26 Image: centos Image ID: docker-pullable://centos@sha256:a27fd8080b517143cbbbab9dfb7c8571c40d67d534bbdee55bd6c473f432b177 Port: <none> Host Port: <none> Args: /bin/sh -c touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600 State: Running Started: Tue, 29 Aug 2022 08:39:19 +0800 Last State: Terminated Reason: Error Exit Code: 137 Started: Tue, 29 Aug 2022 08:38:04 +0800 Finished: Tue, 29 Aug 2022 08:39:17 +0800 Ready: True Restart Count: 1 Liveness: exec [cat /tmp/healthy] delay=10s timeout=1s period=5s #success=1 #failure=3 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-8ms2w (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: kube-api-access-8ms2w: Type: Projected (a volume that contains injected data from multiple sources) TokenExpirationSeconds: 3607 ConfigMapName: kube-root-ca.crt ConfigMapOptional: <nil> DownwardAPI: true QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 87s default-scheduler Successfully assigned default/liveness to mac-k8s Normal Pulled 85s kubelet Successfully pulled image "centos" in 1.649042848s Warning Unhealthy 42s (x3 over 52s) kubelet Liveness probe failed: cat: /tmp/healthy: No such file or directory Normal Killing 42s kubelet Container liveness failed liveness probe, will be restarted Normal Pulling 12s (x2 over 87s) kubelet Pulling image "centos" Normal Created 10s (x2 over 85s) kubelet Created container liveness Normal Started 10s (x2 over 85s) kubelet Started container liveness Normal Pulled 10s kubelet Successfully pulled image "centos" in 1.933447781s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ k get po -w NAME READY STATUS RESTARTS AGE liveness 0/1 Pending 0 0s liveness 0/1 Pending 0 0s liveness 0/1 ContainerCreating 0 0s liveness 0/1 ContainerCreating 0 0s liveness 1/1 Running 0 3s liveness 1/1 Running 1 (2s ago) 77s liveness 1/1 Running 2 (3s ago) 2m33s liveness 1/1 Running 3 (4s ago) 3m49s liveness 1/1 Running 4 (3s ago) 5m3s liveness 1/1 Running 5 (2s ago) 6m17s liveness 0/1 CrashLoopBackOff 5 (0s ago) 7m30s liveness 1/1 Running 6 (85s ago) 8m55s liveness 0/1 CrashLoopBackOff 6 (0s ago) 10m liveness 1/1 Running 7 (2m51s ago) 12m
ReadinessGates - 在自带的 Pod Conditions 之外引入自定义的就绪条件
新引入的 ReadinessGates 的 Condition 为 True 后(由 Controller 修改)
ReadinessGates 不就绪,不会接收流量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 apiVersion: v1 kind: Pod metadata: labels: app: readiness-gate name: readiness-gate spec: readinessGates: - conditionType: "www.example.com/feature-1" containers: - name: readiness-gate image: nginx:1.25.2 --- apiVersion: v1 kind: Service metadata: name: readiness-gate spec: ports: - port: 80 protocol: TCP targetPort: 80 selector: app: readiness-gate
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 $ k apply -f readiness-gate.yaml pod/readiness-gate created service/readiness-gate created $ k get po -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES readiness-gate 1/1 Running 0 16s 192.168.185.12 mac-k8s <none> 0/1 $ k get svc -owide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 22h <none> readiness-gate ClusterIP 10.100.49.21 <none> 80/TCP 38s app=readiness-gate $ k describe svc readiness-gate Name: readiness-gate Namespace: default Labels: <none> Annotations: <none> Selector: app=readiness-gate Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.100.49.21 IPs: 10.100.49.21 Port: <unset> 80/TCP TargetPort: 80/TCP Endpoints: Session Affinity: None Events: <none> $ curl -sI 192.168.185.12 HTTP/1.1 200 OK Server: nginx/1.25.2 Date: Tue, 29 Aug 2023 04:56:25 GMT Content-Type: text/html Content-Length: 615 Last-Modified: Tue, 15 Aug 2023 17:03:04 GMT Connection: keep-alive ETag: "64dbafc8-267" Accept-Ranges: bytes $ curl -v 10.100.49.21 * Trying 10.100.49.21:80... * connect to 10.100.49.21 port 80 failed: Connection refused * Failed to connect to 10.100.49.21 port 80 after 1001 ms: Connection refused * Closing connection 0 curl: (7) Failed to connect to 10.100.49.21 port 80 after 1001 ms: Connection refused
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 $ k describe po readiness-gate Name: readiness-gate Namespace: default Priority: 0 Node: mac-k8s/192.168.191.153 Start Time: Tue, 29 Aug 2022 12:52:01 +0800 Labels: app=readiness-gate Annotations: cni.projectcalico.org/containerID: f7e1476b14d527d84dd05d97d99e95e4321f4e16c67c491a231a828d39742400 cni.projectcalico.org/podIP: 192.168.185.12/32 cni.projectcalico.org/podIPs: 192.168.185.12/32 Status: Running IP: 192.168.185.12 IPs: IP: 192.168.185.12 Containers: readiness-gate: Container ID: docker://d715bf00071ee8dd886f64944c798d3abddb847bebca120565d9e1ac79c458bf Image: nginx:1.25.2 Image ID: docker-pullable://nginx@sha256:104c7c5c54f2685f0f46f3be607ce60da7085da3eaa5ad22d3d9f01594295e9c Port: <none> Host Port: <none> State: Running Started: Tue, 29 Aug 2022 12:52:02 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-wd97x (ro) Readiness Gates: Type Status www.example.com/feature-1 <none> Conditions: Type Status Initialized True Ready False ContainersReady True PodScheduled True Volumes: kube-api-access-wd97x: Type: Projected (a volume that contains injected data from multiple sources) TokenExpirationSeconds: 3607 ConfigMapName: kube-root-ca.crt ConfigMapOptional: <nil> DownwardAPI: true QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m12s default-scheduler Successfully assigned default/readiness-gate to mac-k8s Normal Pulled 2m12s kubelet Container image "nginx:1.25.2" already present on machine Normal Created 2m12s kubelet Created container readiness-gate Normal Started 2m11s kubelet Started container readiness-gate
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 apiVersion: v1 kind: Pod metadata: annotations: cni.projectcalico.org/containerID: f7e1476b14d527d84dd05d97d99e95e4321f4e16c67c491a231a828d39742400 cni.projectcalico.org/podIP: 192.168 .185 .12 /32 cni.projectcalico.org/podIPs: 192.168 .185 .12 /32 kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"app":"readiness-gate"},"name":"readiness-gate","namespace":"default"},"spec":{"containers":[{"image":"nginx:1.25.2","name":"readiness-gate"}],"readinessGates":[{"conditionType":"www.example.com/feature-1"}]}} creationTimestamp: "2022-08-29T04:52:01Z" labels: app: readiness-gate name: readiness-gate namespace: default resourceVersion: "9147" uid: 7cdf038f-80c5-4c15-9507-f20d41b6c0ea spec: containers: - image: nginx:1.25.2 imagePullPolicy: IfNotPresent name: readiness-gate resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /var/run/secrets/kubernetes.io/serviceaccount name: kube-api-access-wd97x readOnly: true dnsPolicy: ClusterFirst enableServiceLinks: true nodeName: mac-k8s preemptionPolicy: PreemptLowerPriority priority: 0 readinessGates: - conditionType: www.example.com/feature-1 restartPolicy: Always schedulerName: default-scheduler securityContext: {} serviceAccount: default serviceAccountName: default terminationGracePeriodSeconds: 30 tolerations: - effect: NoExecute key: node.kubernetes.io/not-ready operator: Exists tolerationSeconds: 300 - effect: NoExecute key: node.kubernetes.io/unreachable operator: Exists tolerationSeconds: 300 volumes: - name: kube-api-access-wd97x projected: defaultMode: 420 sources: - serviceAccountToken: expirationSeconds: 3607 path: token - configMap: items: - key: ca.crt path: ca.crt name: kube-root-ca.crt - downwardAPI: items: - fieldRef: apiVersion: v1 fieldPath: metadata.namespace path: namespace status: conditions: - lastProbeTime: null lastTransitionTime: "2022-08-29T04:52:01Z" status: "True" type: Initialized - lastProbeTime: null lastTransitionTime: "2022-08-29T04:52:01Z" message: corresponding condition of pod readiness gate "www.example.com/feature-1" does not exist. reason: ReadinessGatesNotReady status: "False" type: Ready - lastProbeTime: null lastTransitionTime: "2022-08-29T04:52:02Z" status: "True" type: ContainersReady - lastProbeTime: null lastTransitionTime: "2022-08-29T04:52:01Z" status: "True" type: PodScheduled containerStatuses: - containerID: docker://d715bf00071ee8dd886f64944c798d3abddb847bebca120565d9e1ac79c458bf image: nginx:1.25.2 imageID: docker-pullable://nginx@sha256:104c7c5c54f2685f0f46f3be607ce60da7085da3eaa5ad22d3d9f01594295e9c lastState: {} name: readiness-gate ready: true restartCount: 0 started: true state: running: startedAt: "2022-08-29T04:52:02Z" hostIP: 192.168 .191 .153 phase: Running podIP: 192.168 .185 .12 podIPs: - ip: 192.168 .185 .12 qosClass: BestEffort startTime: "2022-08-29T04:52:01Z"
Hook post-start
post-start 结束之前,不会被标记为 Running 状态
无法保证 post-start 脚本和 Entrypoint 哪个先执行
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: v1 kind: Pod metadata: name: poststart spec: containers: - name: lifecycle-demo-container image: nginx:1.25.2 lifecycle: postStart: exec: command: ["/bin/sh" , "-c" , "echo Hello from the postStart handler > /usr/share/message" ]
1 2 3 4 5 $ k apply -f poststart.yaml pod/poststart created $ k exec poststart -- cat /usr/share/message Hello from the postStart handler
pre-stop
只有当 Pod 被终止时,Kubernetes 才会执行 pre-stop 脚本,而当 Pod 完成或者容器退出时,pre-stop 脚本不会被执行
kubelet 会先发送 SIGTERM 信号,然后过一会才会发送 SIGKILL 信号(前提是容器进程还存活)
pre-stop + SIGTERM = terminationGracePeriodSeconds = 40 + 20 = 60
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 spec: containers: - name: app livenessProbe: httpGet: path: /health port: 8080 scheme: HTTP initialDelaySeconds: 120 timeoutSeconds: 5 periodSeconds: 10 successThreshold: 1 failureThreshold: 10 readinessProbe: httpGet: path: /health port: 8080 scheme: HTTP initialDelaySeconds: 60 timeoutSeconds: 5 periodSeconds: 10 successThreshold: 1 failureThreshold: 10 lifecycle: preStop: exec: command: - /bin/sh - '-c' - /home/xxx/shell/sleep_40s.sh terminationMessagePath: /dev/termination-log terminationMessagePolicy: File imagePullPolicy: Always restartPolicy: Always terminationGracePeriodSeconds: 60
bash和sh 会忽略 SIGTERM 信号 - 因此 SIGTERM 会永远超时
1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: Pod metadata: name: no -sigterm spec: terminationGracePeriodSeconds: 60 containers: - name: no -sigterm image: centos command: ["/bin/sh" ] args: ["-c" , "while true; do echo hello; sleep 10;done" ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $ k apply -f no-sigterm.yaml pod/no-sigterm created $ k delete po no-sigterm pod "no-sigterm" deleted $ k get po -w NAME READY STATUS RESTARTS AGE no-sigterm 0/1 Pending 0 0s no-sigterm 0/1 Pending 0 0s no-sigterm 0/1 ContainerCreating 0 0s no-sigterm 0/1 ContainerCreating 0 0s no-sigterm 1/1 Running 0 3s no-sigterm 1/1 Terminating 0 10s no-sigterm 1/1 Terminating 0 70s no-sigterm 0/1 Terminating 0 71s no-sigterm 0/1 Terminating 0 71s no-sigterm 0/1 Terminating 0 71s
terminationGracePeriodSeconds
最佳实践
如果想快速终止 Pod
可以在 pre-stop 或者 SIGTERM 中主动退出进程
优雅初始化(子进程)
正确处理系统信号量,将信号量转发给子进程
在主进程退出之前,需要等待并确保所有子进程退出
监控并清理孤儿子进程