Kubernetes - Service Discovery
基本概念
发展历程
数据包
负载均衡的核心原理 -
修改包头数据
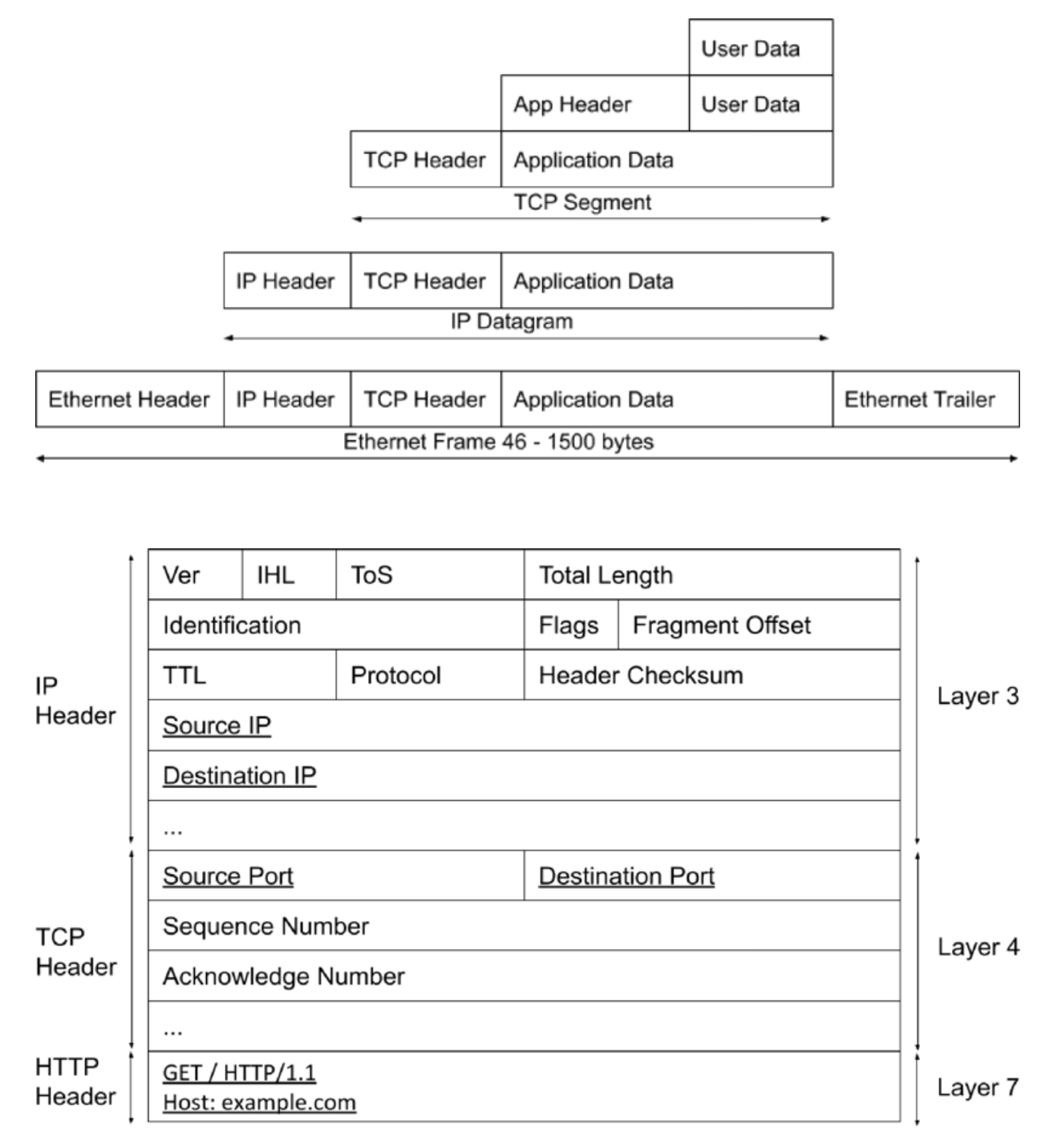
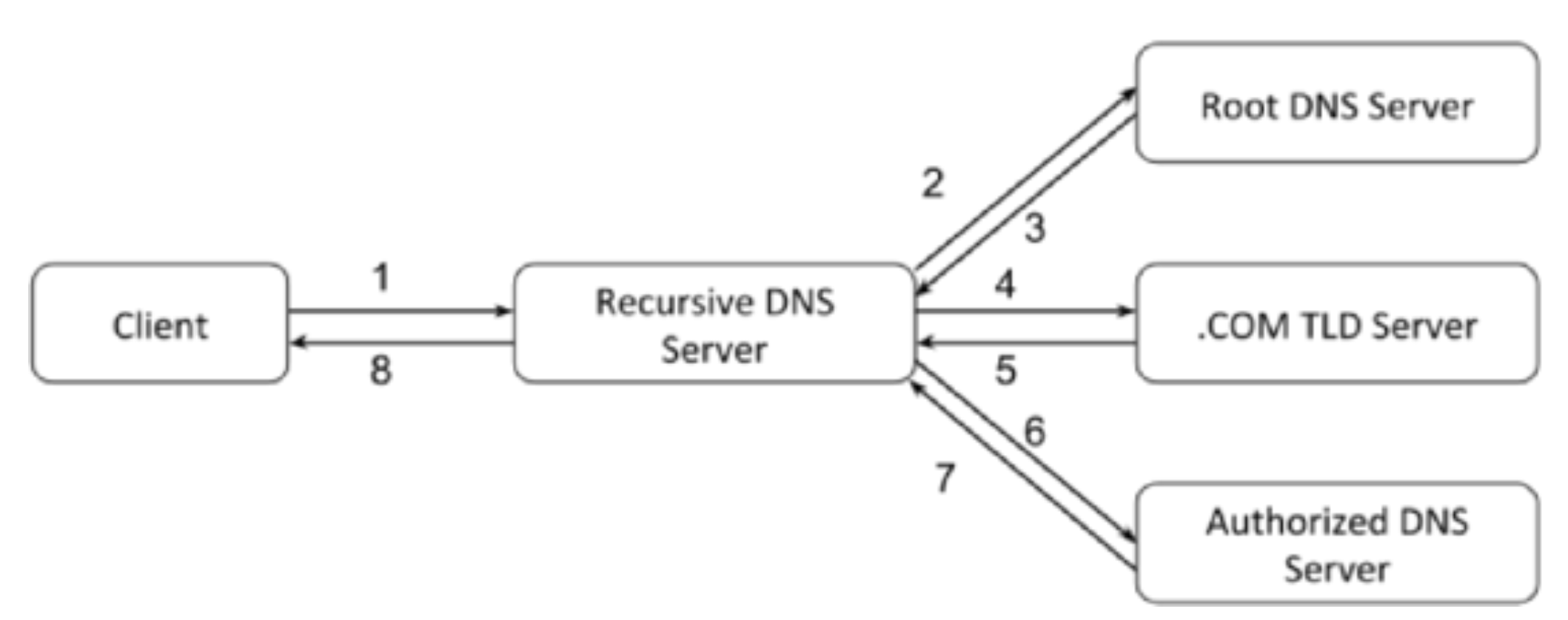
通过浏览器访问某网站的过程(
组包在应用层,传包在内核层)
- 在浏览器输入网站的网址
- 浏览器本质上是一个 HTTP 客户端,组装成 HTTP 包
- 做 DNS 解析(递归)
- 封装 TCP 包(源端口 + 目标端口)
- 封装 IP 包(源 IP + 目标 IP -
来自于 DNS)
负载均衡
面向连接的负载均衡不一定能保证平均,如 grpc 是基于 http/2,会复用 TCP 连接,L4 的负载均衡就无法实现平均
方案
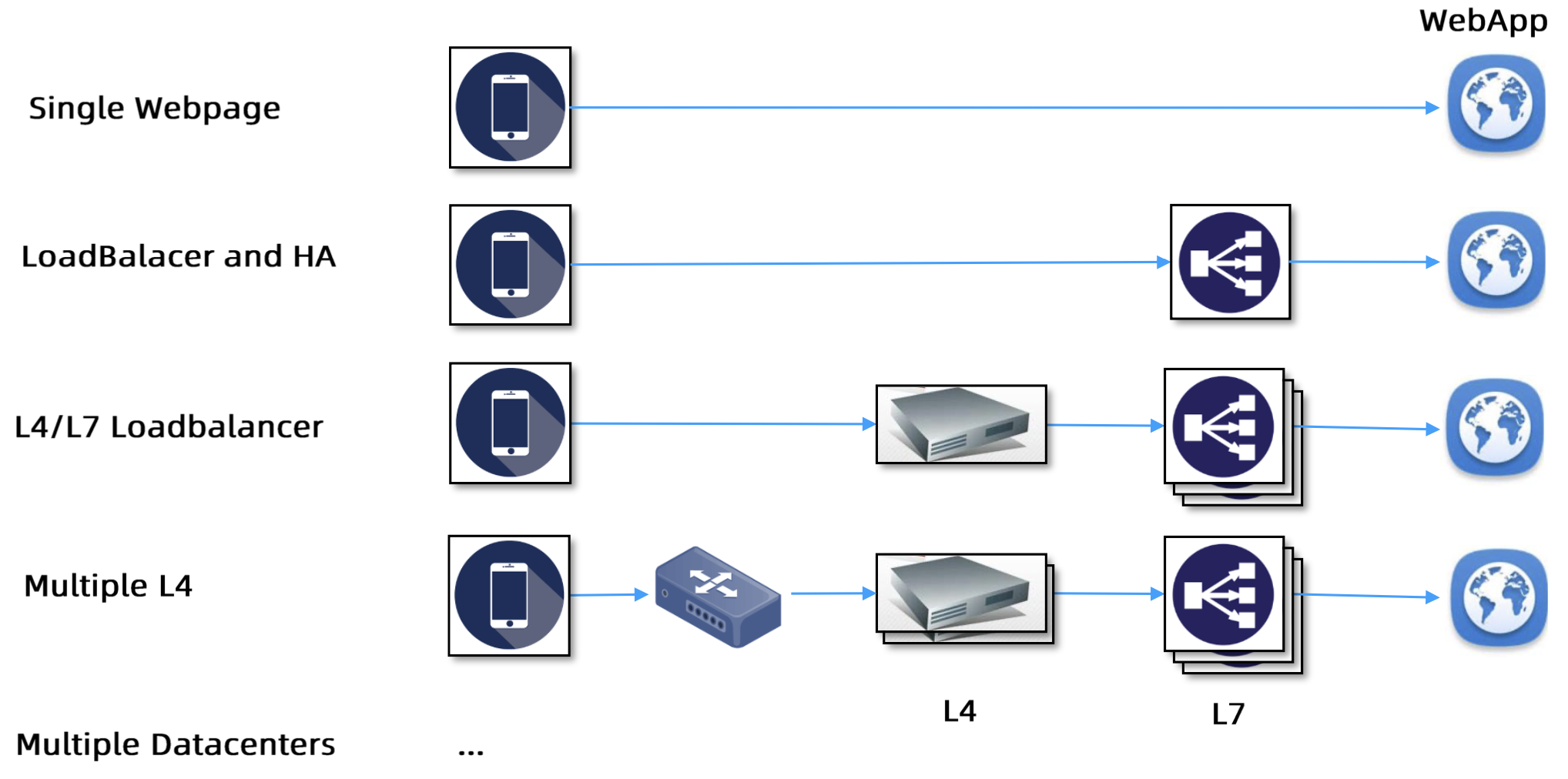
集中式
F5(HLB) / Nginx(SLB) - 接入集群外部流量
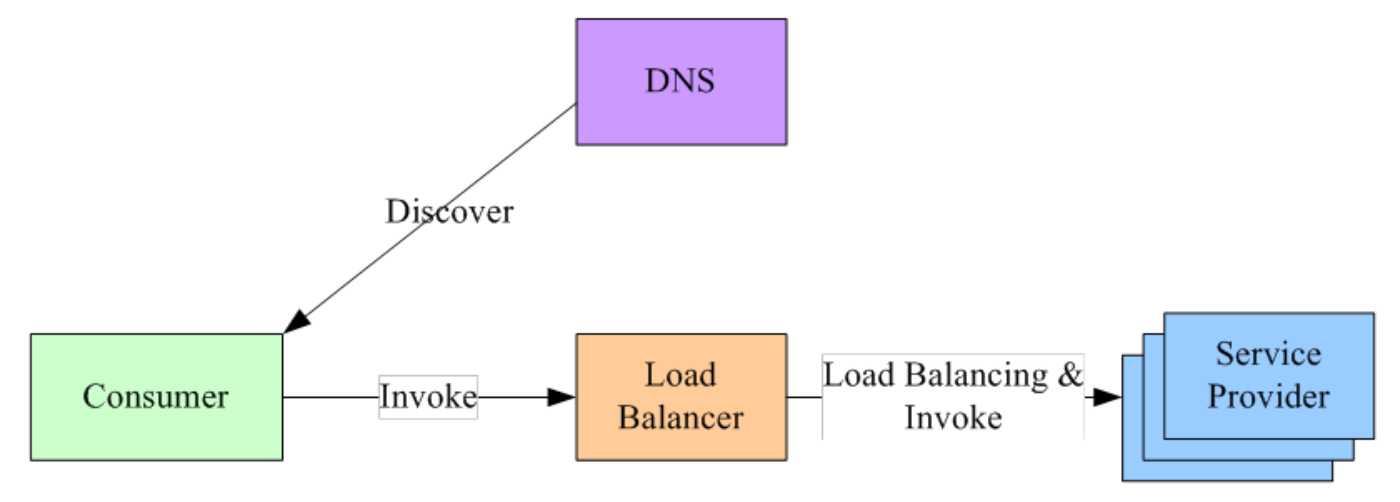
- 在服务消费者和服务提供者之间有一个
独立的 LB LB上有所有服务的地址映射表,通常由运维配置注册- 当服务消费者调用某个目标服务时,向 LB 发起请求,由 LB 以某种策略做
负载均衡后将请求转发到目标服务 - LB 一般具备
健康检查的能力,能自动摘除不健康的服务实例 - 服务消费者通过
DNS发现 LB,运维人员配置一个指向该 LB 的 DNS 域名 - 优缺点
- 优点
- 方案简单,在 LB 上容易实现
集中式的访问控制,为业界主流
- 方案简单,在 LB 上容易实现
- 缺点
单点问题,LB 容易成为性能瓶颈- 服务调用
增加 1 跳的性能开销
- 优点
进程内
集群内部 - 微服务流量治理
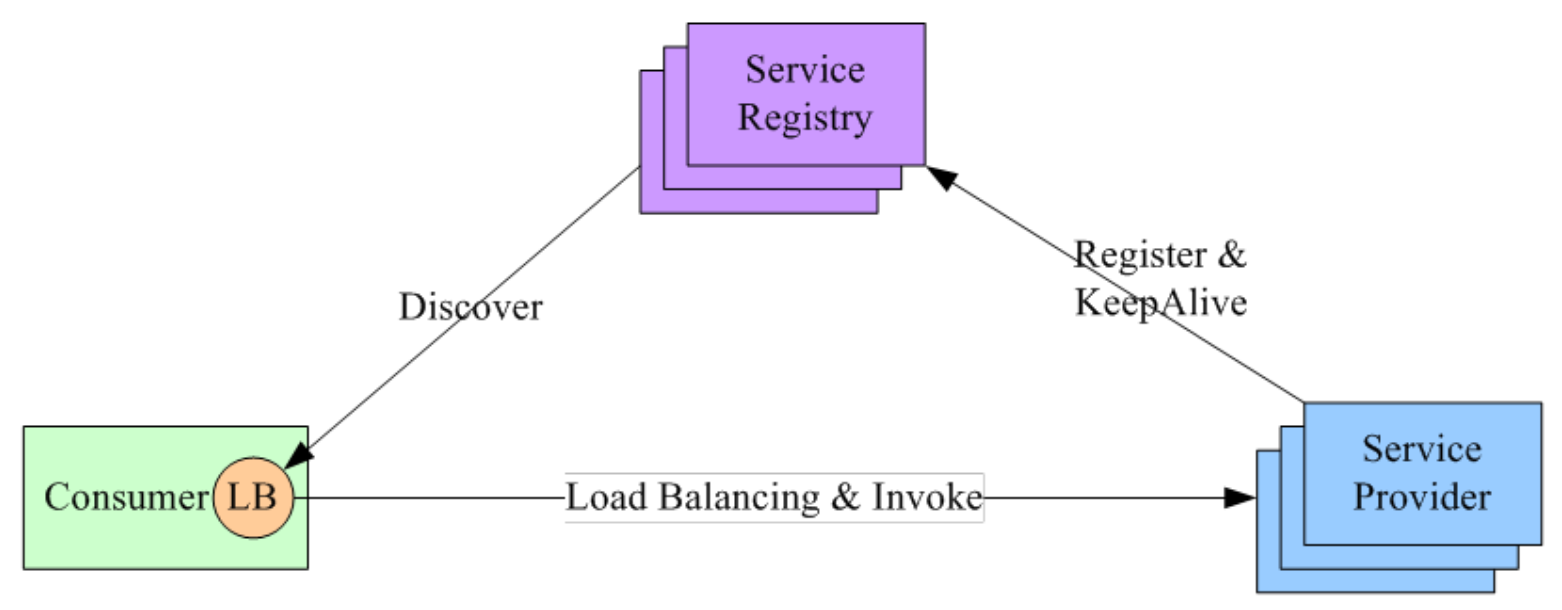
- 将 LB 的功能以
库的形式集成到服务消费者进程里面,也称为客户端负载均衡 Service Registry配合支持服务注册和服务发现- 服务提供者启动时,首先将服务地址注册到 Service Registry,并定时上报心跳保活
- 服务消费者要访问某个服务时
- 通过
内置的 LB 组件向 Service Registry 查询(同时缓存并定时刷新)目标服务的地址列表 - 然后以某种负载均衡策略选择一个目标服务地址,最后向目标服务发起请求
- 通过
- 对 Service Registry 的
HA要求很高,常用为 zookeeper、consul、etcd 等 - 优缺点
- 优点
- 性能较好 - LB 和服务发现能力被
分散到每一个服务消费者的进程内部,同时直接进行服务调用,没有额外开销
- 性能较好 - LB 和服务发现能力被
- 缺点
- 可能需要维护多种语言的客户端
- 内嵌到服务消费者,客户端升级成本较大
- 优点
Sidecar
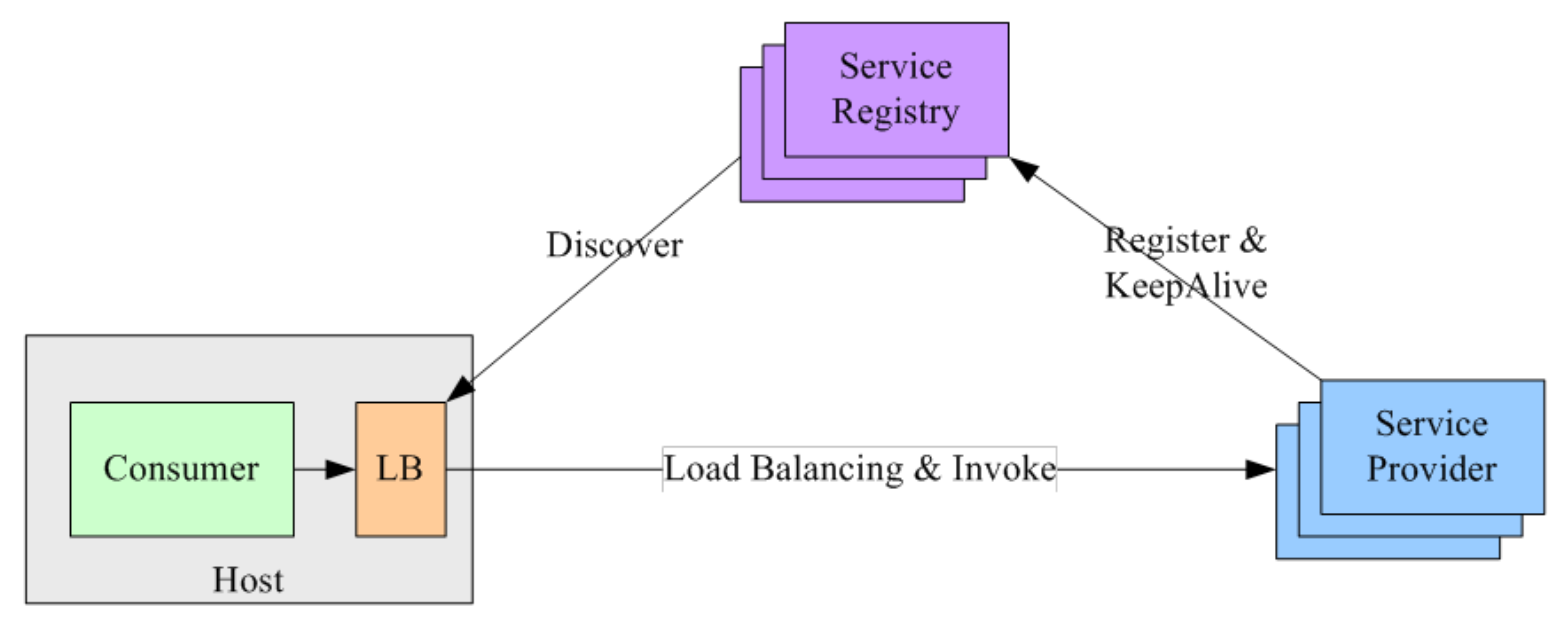
- 将 LB 和服务发现功能从服务消费者进程剥离,变成主机上的一个
独立进程- 服务消费者要访问目标服务时,需要通过
同一主机上独立的 LB 进程做服务发现和负载均衡
- 服务消费者要访问目标服务时,需要通过
- LB 独立进程可以进一步与服务消费者进行解耦,以
独立集群的形式提供高可用的负载均衡服务 - 优缺点
- 优点
- 无单点问题,只会影响
同一主机上的服务消费者 - 服务消费者和 LB 之间是
进程间调用,性能好 - 不需要为不同的语言开发不同的库,LB 可
单独升级
- 无单点问题,只会影响
- 缺点
- 部署复杂,问题排查不方便
- 优点
作用
- 解决并发压力,提高应用
处理性能,增加吞吐量,加强网络处理能力 - 提供
Failover,实现HA - 实现
横向扩展,增强应用的弹性能力 安全防护,可以在 LB 上做一些过滤等处理
DNS
最早的负载均衡技术,在 DNS 服务器,配置多个
A 记录,这些 A 记录对应的服务器构成集群
优点
- 使用简单,负载均衡交给 DNS 服务器
加速访问,可以实现基于地址的域名解析
缺点
TTL- 进程有可能一直使用第一个 A 记录,直到该 A 记录失效
可用性差- DNS 解析为
多级解析,修改 DNS 后,解析时间较长,解析过程中,用户访问网站将失败
- DNS 解析为
扩展性低- 控制权在
域名商
- 控制权在
维护性差- 不能反映服务器的当前运行状态,支持算法少,不能区分服务器的差异
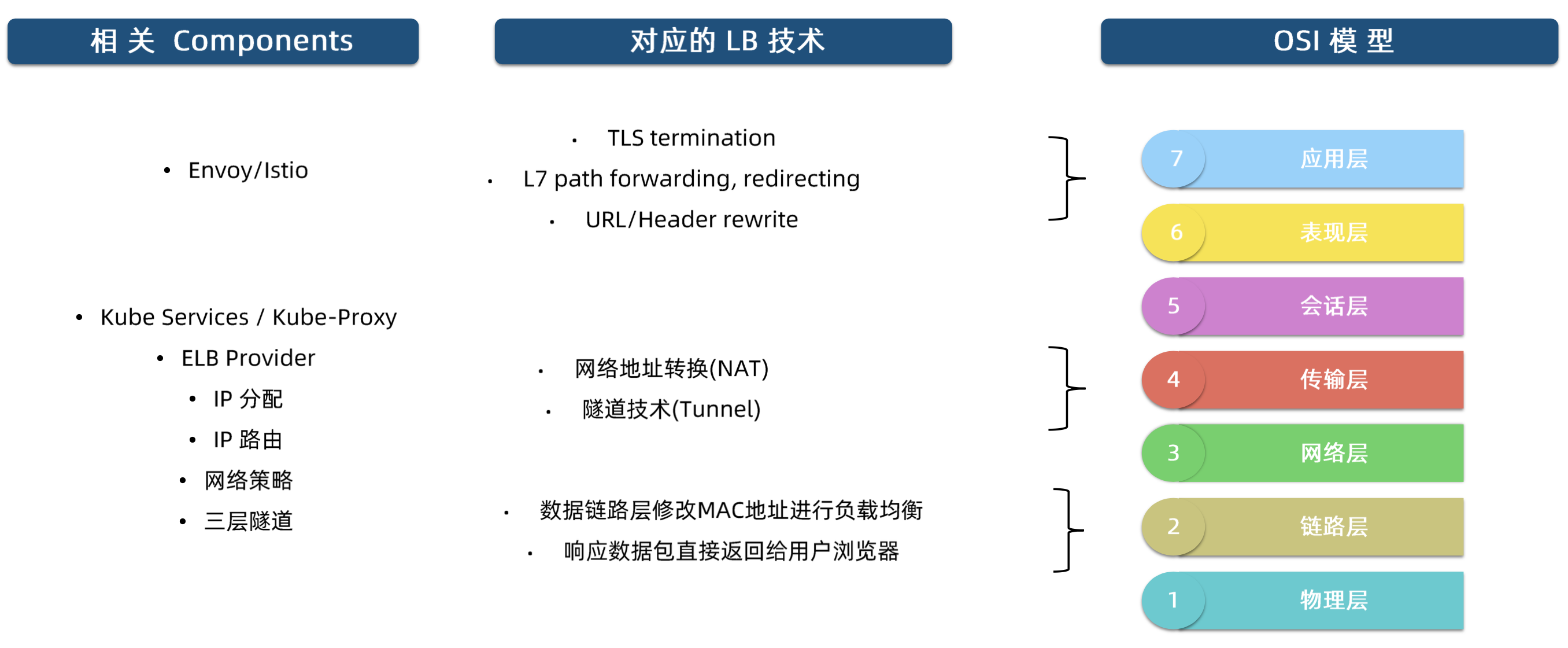
相关技术
现阶段,重点关注
NAT和Tunnel即可
网络层 - NAT
不修改 TCP 连接,通过修改数据包的源地址(SNAT)或目标地址(DNAT)来控制数据包的转发行为
丢失原始客户端的 IP 地址,上游服务器只能感知到负载均衡器,而无法感知到原始客户端
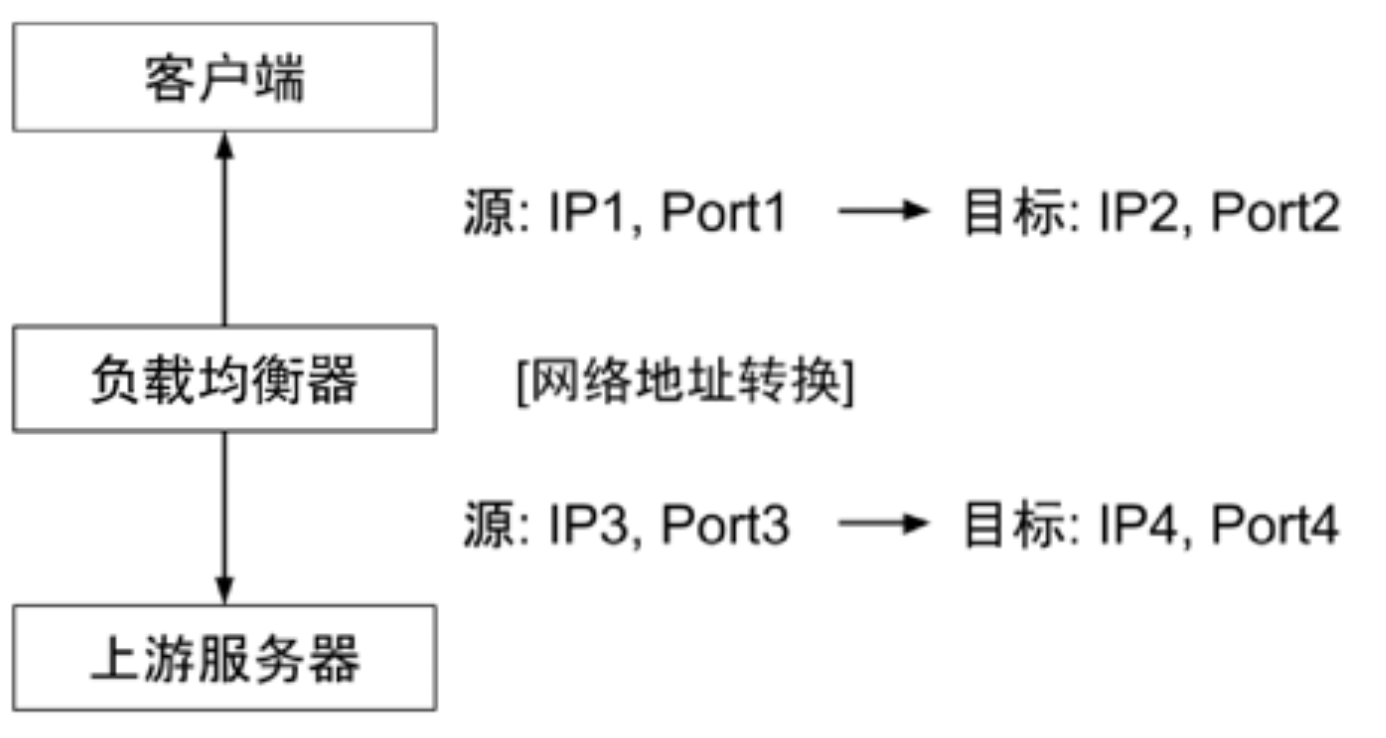
- 客户端访问负载均衡器的 VIP,即
IP2:PORT2 - 负载均衡器不会修改 TCP 连接
- 而是修改数据包包头的源地址和目标地址为负载均衡器自身的 IP 端口(即
IP3:PORT3)和上游服务器的 IP 端口
- 而是修改数据包包头的源地址和目标地址为负载均衡器自身的 IP 端口(即
- 上游服务器处理完后,再将数据包返回给负载均衡器
- 负载均衡器会记录
Connection Table,会找到 3-4 对应的连接是 1-2,最终将数据返回给原始客户端
传输层
让上游服务器能够感知到原始客户端,基于传输层的负载均衡,
将相关信息写入新建 TCP 连接的数据包
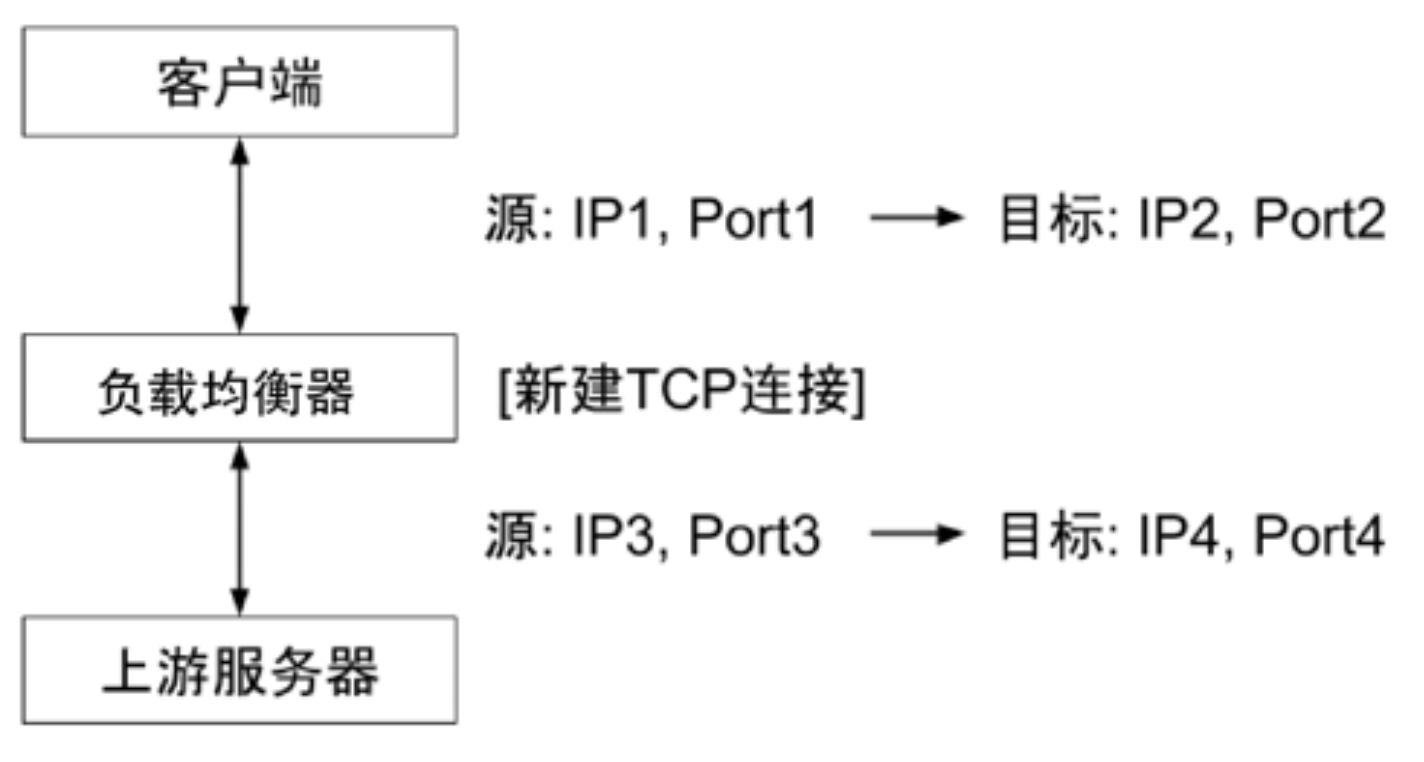
- 负载均衡器真实监听端口
IP2:PORT2 - 实现方式
- 利用
空闲的 TCP Options记录原始的客户端信息 - 需要Linux Kernel支持Tcp Proxy Protocol也预留了空间,在 TCP 数据包的前段
- 利用
链路层
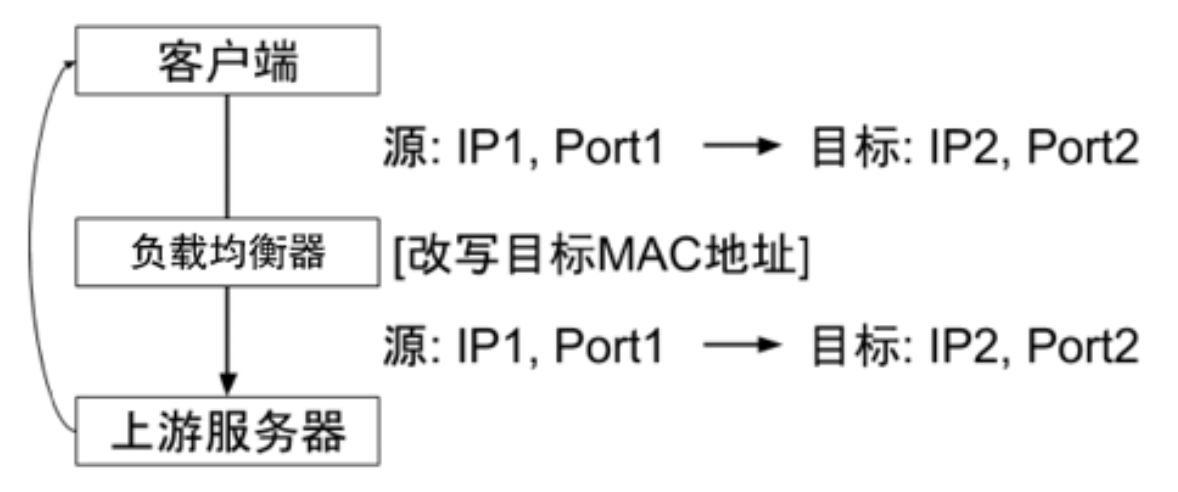
数据分发时,
不修改 IP 地址,而是修改目标 Mac 地址上游服务器 VIP和负载均衡器 VIP要保持一致- 不修改数据包的源地址和目标地址,进行数据分发
实际处理服务器 IP 和数据请求目的 IP 一致
回包不再需要经过负载均衡器进行
地址转换,可将响应数据包直接返回给用户浏览器避免负载均衡服务器网卡带宽成为瓶颈,也称为
直接路由模式
只改 Mac 地址,源地址和目标地址没有改变,可以直接回包
- 进包 - 负载均衡,修改 Mac 地址
- 出包 - 直接路由回包
优缺点
- 优点
- 性能很好
- 缺点
- 客户端、负载均衡器、上游服务器都必须在
同一个子网,且配置很复杂,不常用
- 客户端、负载均衡器、上游服务器都必须在
- 优点
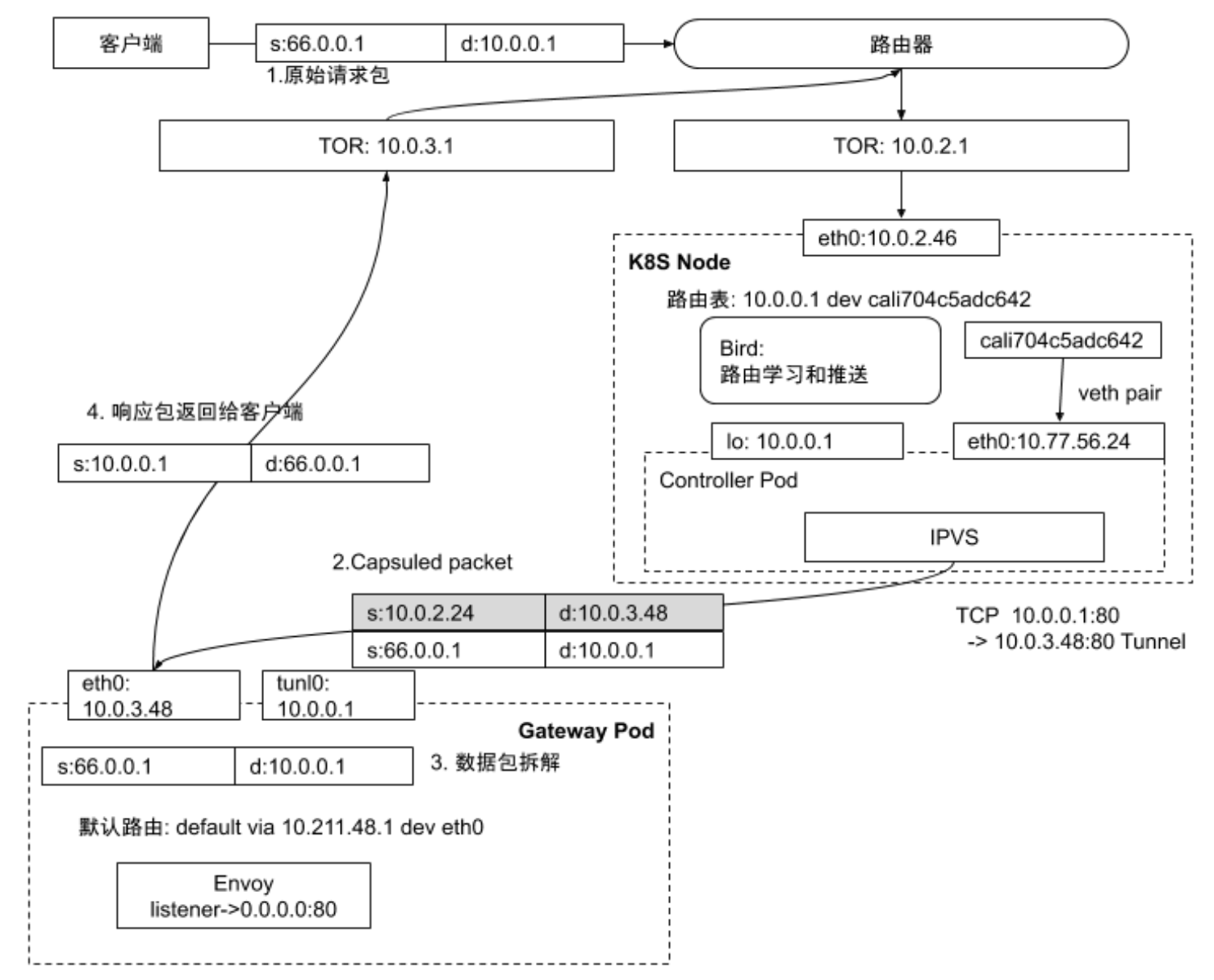
隧道 - Tunnel
链路与链路层负载均衡类似,
负载均衡器负责封包,上游服务器解包后,直接回包给客户端,性能也很好
- 负载均衡中常用的隧道技术是
IP in IP Tunneling- 保持原始数据包的 IP 头不变,在 IP 头外层增加额外的 IP 头后转发到上游服务器
- 上游服务器接收到 IP 数据包后,解开外层 IP 包头后,剩下的是原始数据包
- 上游服务器处理完数据请求后,响应包通过网关直接返回给客户端
Service
Service
用于描述负载均衡
1 | apiVersion: v1 |
- Selector
- Kubernetes 允许将
Pod对象通过Label进行标记 - 通过 Service Selector 定义基于
Pod Label的过滤规则,来选择 Service 的Upstream
- Kubernetes 允许将
- Ports
- 定义
协议和端口
- 定义
Service 实际上是要配置负载均衡,监听一个
VIP:PORT,然后做NAT
Upstream 的 Port 即targetPort,Upstream 的 IP 即 Selector 匹配到的Pod IP
Endpoint
Endpoint 是
中间对象,用于处理多对多(Service对Pod)的关系
kube-proxy 会监听
Service对象和Endpoint对象,调用本机的接口去配置本机的负载均衡
kube-proxy 的配置在所有Node上要一致
1 | apiVersion: v1 |
- 当 Service 的 Selector 不为空时
Kubernetes Endpoint Controller会监听Service的创建事件,创建与 Service同名的 Endpoint 对象
- Selector 能够选取的所有
Pod IP都会被配置到Address属性中- 如果 Selector
查询不到匹配的 Pod,则 Address 列表为空 - 默认情况下,如果对应的 Pod 为
Not Ready状态,对应的 Pod IP 只会出现在 subsets 的notReadyAddresses- 意味着对应的 Pod 还未准备好提供服务,不能作为
流量转发的目标
- 意味着对应的 Pod 还未准备好提供服务,不能作为
- 如果设置了
PublishNotReadyAddress为 true,则无论 Pod 是否就绪都会被加入addresses(接收流量)
- 如果 Selector
Deployment
1 | apiVersion: apps/v1 |
1 | $ k apply -f nginx-deploy.yaml |
Service
1 | apiVersion: v1 |
1 | $ k apply -f service.yaml |
1 | apiVersion: v1 |
1 | apiVersion: v1 |
1 | $ k scale deployment nginx-deployment --replicas=2 |
1 | apiVersion: v1 |
使得某个 Pod 变成 Ready
1 | $ k exec -it nginx-deployment-7b89c988df-tmpl8 -- touch /tmp/healthy |
1 | apiVersion: v1 |
1 | $ curl -sI 10.100.49.21:80 |
将 Service 的 PublishNotReadyAddress 设置为 true
1 | $ k get po -owide |
1 | apiVersion: v1 |
1 | apiVersion: v1 |
EndpointSlice
1 | apiVersion: discovery.k8s.io/v1beta1 |
- 当某个 Service 对应的
Backend Pod 较多时,Endpoint 对象会因为保存的地址信息过多而变得庞大 - Pod 状态的变更会引起 Endpoint 的变更,而
Endpoint 的变更会被推送到所有的 Node,占用大量的网络带宽 - EndpointSlice 对 Pod 较多的 Endpoint 进行
切片,切片大小可自定义
No Selector
创建了 Service 但不定义 Selector
- Kubernetes Endpoint Controller
不会为该 Service自动创建Endpoint - 可以
手动创建 Endpoint 对象(需要与 Service同名),并设置任意 IP 地址到Address - 可以为
集群外的一组 Endpoint 创建服务
1 | apiVersion: v1 |
1 | $ k apply -f service-without-selector.yaml |
指向集群外站点
1 | $ nslookup blog.zhongmingmao.top |
1 | apiVersion: v1 |
1 | $ k apply -f service-without-selector-ep.yaml |
对应关系
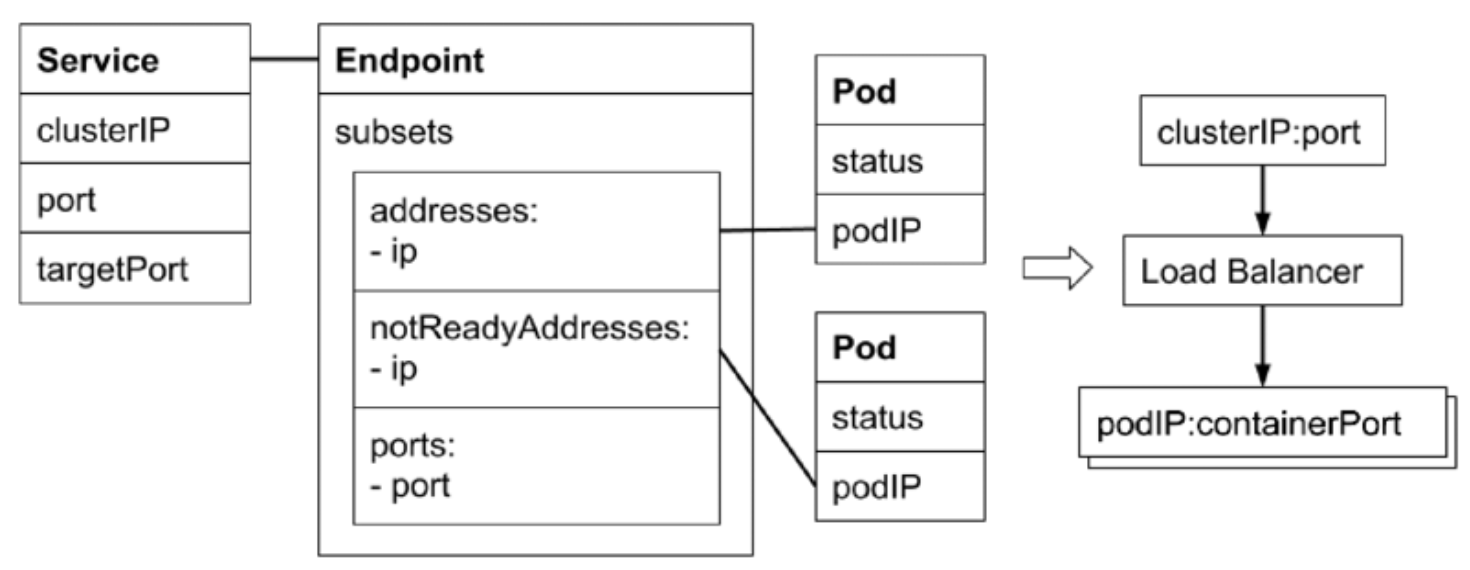
分类
包含关系:
ClusterIP->NodePort->LoadBalancer
ClusterIP
- Service 的默认类型,服务被发布到
仅集群内部可见的VIP上 - 在
API Server启动时,需要通过service-cluster-ip-range参数来配置VIP 地址段API Server中有用于分配 IP 地址和端口的组件,当该组件捕获 Service 对象并创建事件时- 会从配置的
VIP 地址段中取一个有效的 IP 地址,分配给该 Service 对象
- 通过 API Server 创建 Service 时,ClusterIP 本身为空
1 | $ sudo cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep 'service-cluster-ip-range' |
NodePort
- 在
API Server启动时,需要通过node-port-range参数配置 NodePort 的范围(默认值为30000 ~ 32767)- API Server 组件会
捕获 Service 对象并创建事件时 - 会从配置好的 NodePort 范围取一个有效端口,分配被该 Service
- API Server 组件会
- 每个
Node上的kube-proxy会尝试在Service分配的NodePort上建立监听器接收请求- 并转发给 Service 对应的
Backend Pod
- 并转发给 Service 对应的
LoadBalancer
IDC一般会采购一些负载均衡器,作为外网请求进入 IDC 的统一流量入口- 需要配置外部的 LB,一般由
云厂商提供
- 需要配置外部的 LB,一般由
- 针对不同的基础架构云平台,
Kubernetes Cloud Manager提供支持不同供应商 API 的Service Controller
Headless Service
不配置
VIP,不需要负载均衡的能力
- 将
ClusterIP显式定义为None - Kubernetes 不会为 Headless Service 分配
统一入口,包括 ClusterIP、NodePort 等
1 | apiVersion: v1 |
1 | $ k apply -f headless-svc.yaml |
访问有 ClusterIP 的 Service,DNS 解析出其
VIP(一条 A 记录),再通过ipvs或者iptables做负载均衡
而访问 Headless Service,DNS 解析出来的是Pod IP的多条 A 记录,本质上是通过DNS做负载均衡
1 | $ k exec -it nginx-deployment-7b89c988df-tmpl8 -- curl -vsI nginx-basic.default |
ExternalName Service
相当于外部服务的
cname
1 | apiVersion: v1 |
Service Topology
- Kubernetes 提供
通用标签来标记Node所处的物理位置- topology.kubernetes.io/
zone: us-west2-a - failure-domain.beta.kubernetes.io/
region: us-west - failure-domain.tess.io/
network-device: us-west05-ra053 - failure-domain.tess.io/
rack: us_west02_02-314_19_12 - kubernetes.io/
hostname: node-1
- topology.kubernetes.io/
- Service 引入
topologyKeys来控制流量- [“kubernetes.io/
hostname“]- 调用 Service 的客户端所在 Node 上如果有该 Service 的服务实例正在运行
- 则该服务实例处理请求,否则调用失败
- [“kubernetes.io/
hostname“, “topology.kubernetes.io/zone“, “topology. kubernetes.io/region“- 若同一 Node 上有对应的服务实例,则请求优先转发到该实例
- 否则,顺序查找
当前 zone以及当前 region是否有该服务实例,并将请求按顺序转发
- [“topology. kubernetes.io/
region“, “*”]- 请求会被优先转发到
当前 region的服务实例 - 如果当前 region 不存在服务实例,则请求会被转发到
任意服务实例
- 请求会被优先转发到
- [“kubernetes.io/
只在本机转发
1 | apiVersion: v1 |
优先选择本机转发
1 | apiVersion: v1 |
kube-proxy
kube-proxy 为控制面组件,运行模式为
Control-Loop
iptables专注于防火墙,而ipvs专注于负载均衡
- 每个
Node上都运行一个 kube-proxy 服务- 监听
API Server中的Service和Endpoint的变化 - 并通过
iptables等来为 Service 配置负载均衡(仅支持TCP和UDP)
- 监听
- kube-proxy 可以直接运行在
Node上,也可以通过Static Pod或者DaemonSet的方式运行 - kube-proxy 支持的实现方式
userspace最早的负载均衡方案- 在
用户空间监听一个端口,所有服务通过iptables转发到该端口,然后在其内部负载均衡到实际的 Pod - 缺点
- 效率低,有明显的
性能瓶颈 - 数据包先到
Kernel,再转到kube-proxy(通过负载均衡选择一个 Pod IP),最后又回到Kernel
- 效率低,有明显的
winuserspace- 同 userspace,仅工作在 Windows 上
iptables- 目前
推荐的方案,完全以iptables 规则的方式来实现 Service 的负载均衡 - Kernel 中的 TCP 协议栈本身可以通过
Netfilter框架对数据包(三层 / 四层)做转发 - 缺点
- 在 Service 多的时候会产生太多的 iptables 规则
非增量式更新会引入一定的延时,在大规模的情况下会有明显的性能问题
- 目前
ipvs- 为了解决
iptables模式的性能问题- 在
v1.8新增了 ipvs 模式,采用增量式更新,并保证Service 更新期间连接保持不断开
- 在
- ipvs
专注于数据包处理,但能力没有 iptables 丰富,因此很多能力需要依托于 iptables
- 为了解决
1 | $ k get ds -n kube-system -owide |
Cilium 基于
eBPF,完全绕过了TCP 协议栈(Netfilter)
Netfilter
NAT - 实现 Service 的负载均衡
routing decision 之前只能 nat 而不能 filter
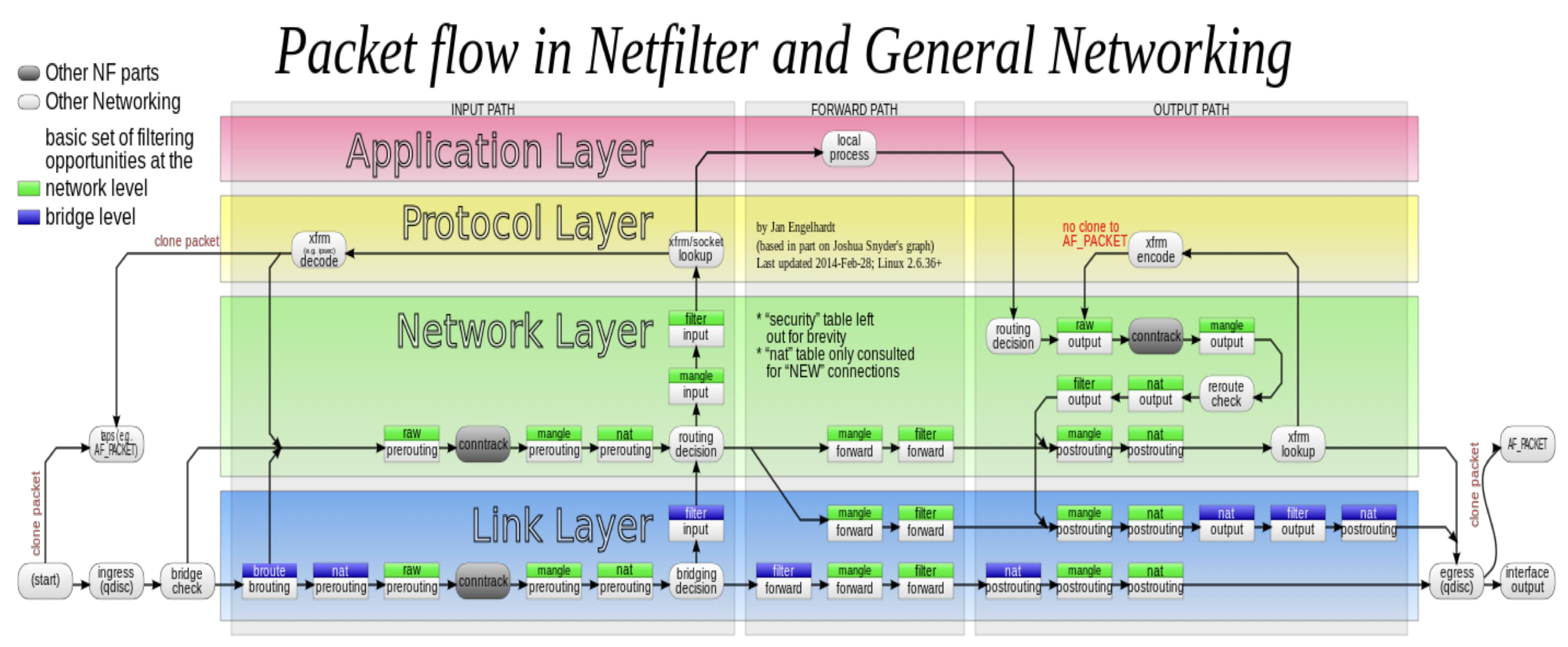
iptables
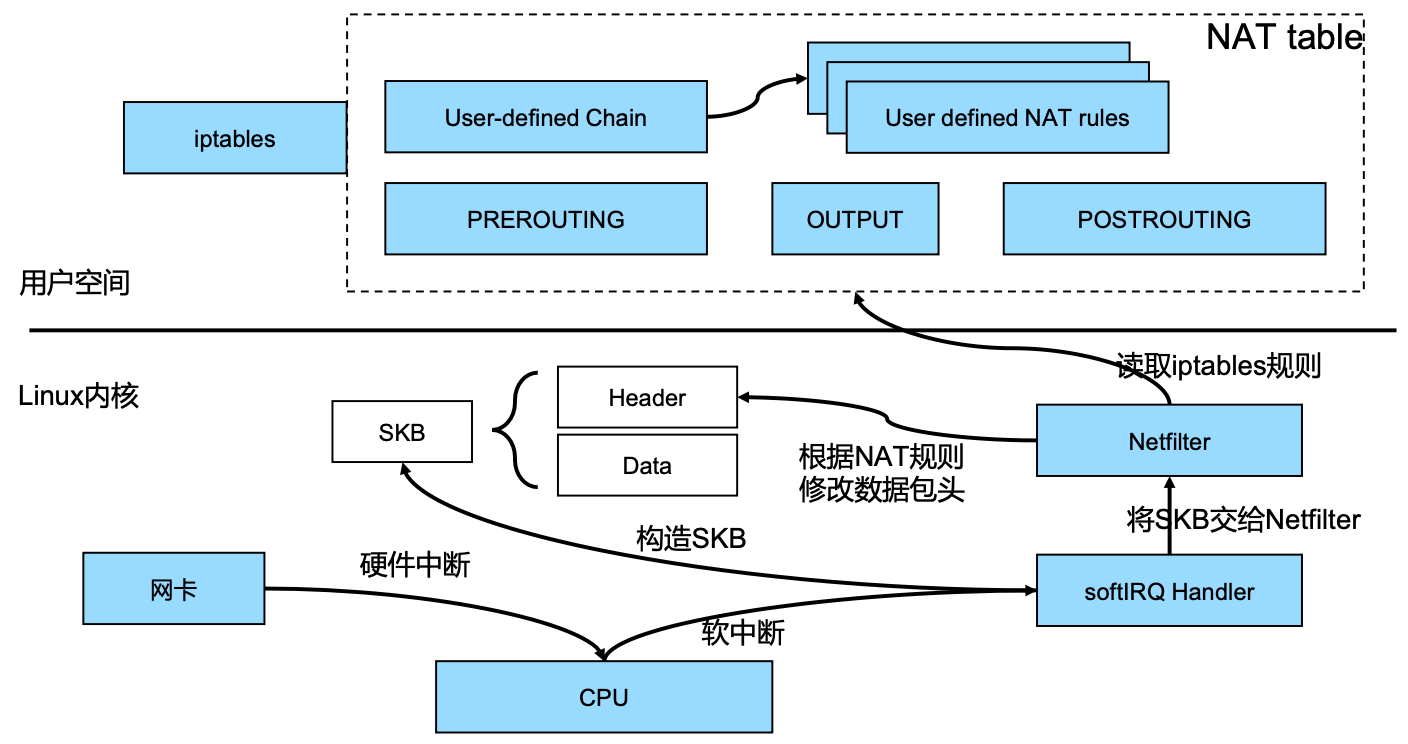
- 网卡接收到数据包后,会给 CPU 发送硬件中断,唤醒 CPU
- 但 CPU 不会直接读取和处理数据包,响应硬件中断时,无法处理其它事项,效率非常低
- 因此
CPU 会软中断 Kernel,触发 SoftIRQ Handler 去读取数据包 - SoftIRQ Handler 会在 Kernel 构造 SKB,然后再将 SKB 交给 Netfilter (TCP 协议栈)
- Netfilter 会去读取并执行 kube-proxy 在
用户空间定义的一些 iptables 规则
重点关注
nat和filter规则
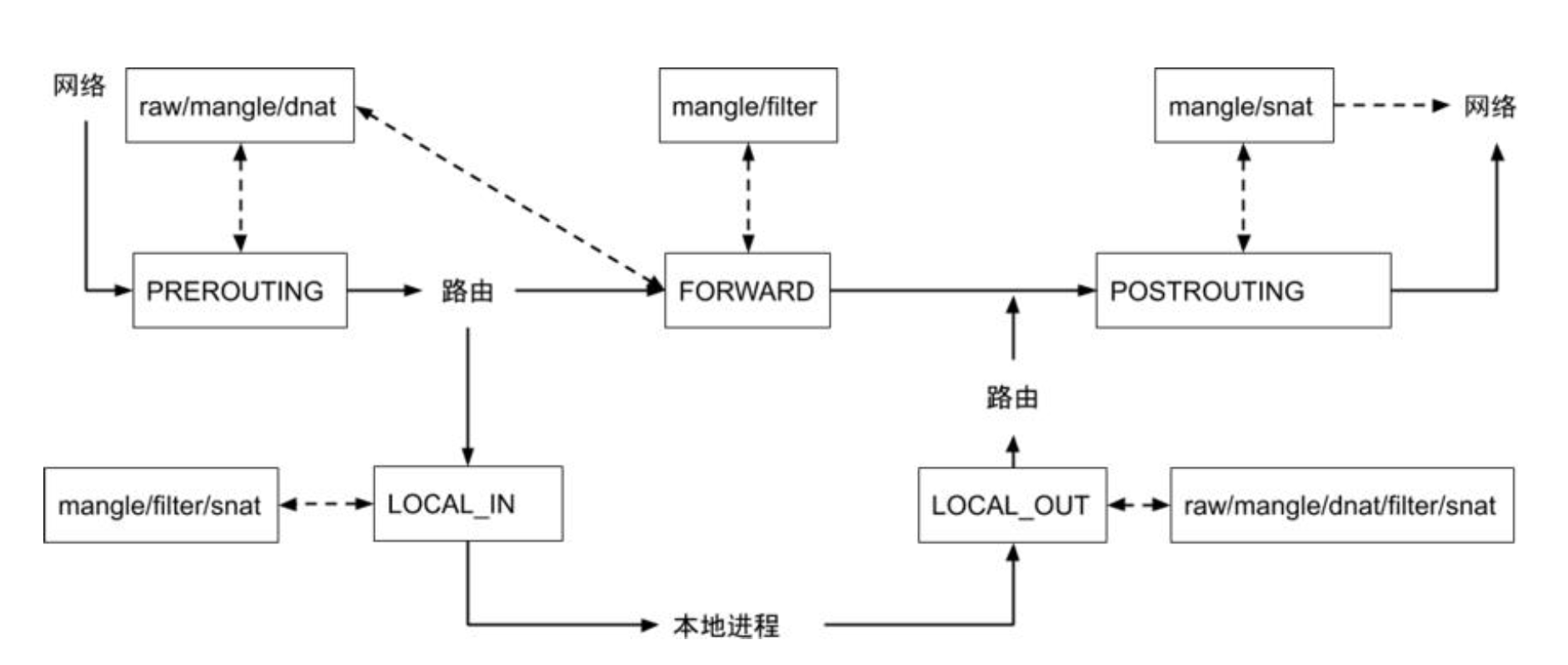
锚点 - 针对负载均衡,主要关注
PREROUTING和OUTPUT
| table / chain | PREROUTING |
INPUT | FOREORD | OUTPUT |
POSTROUTING |
|---|---|---|---|---|---|
| raw | Y | Y | |||
| mangle | Y | Y | Y | Y | Y |
dnat |
Y |
Y |
|||
filter |
Y | Y | Y | ||
snat |
Y | Y | Y |
工作原理
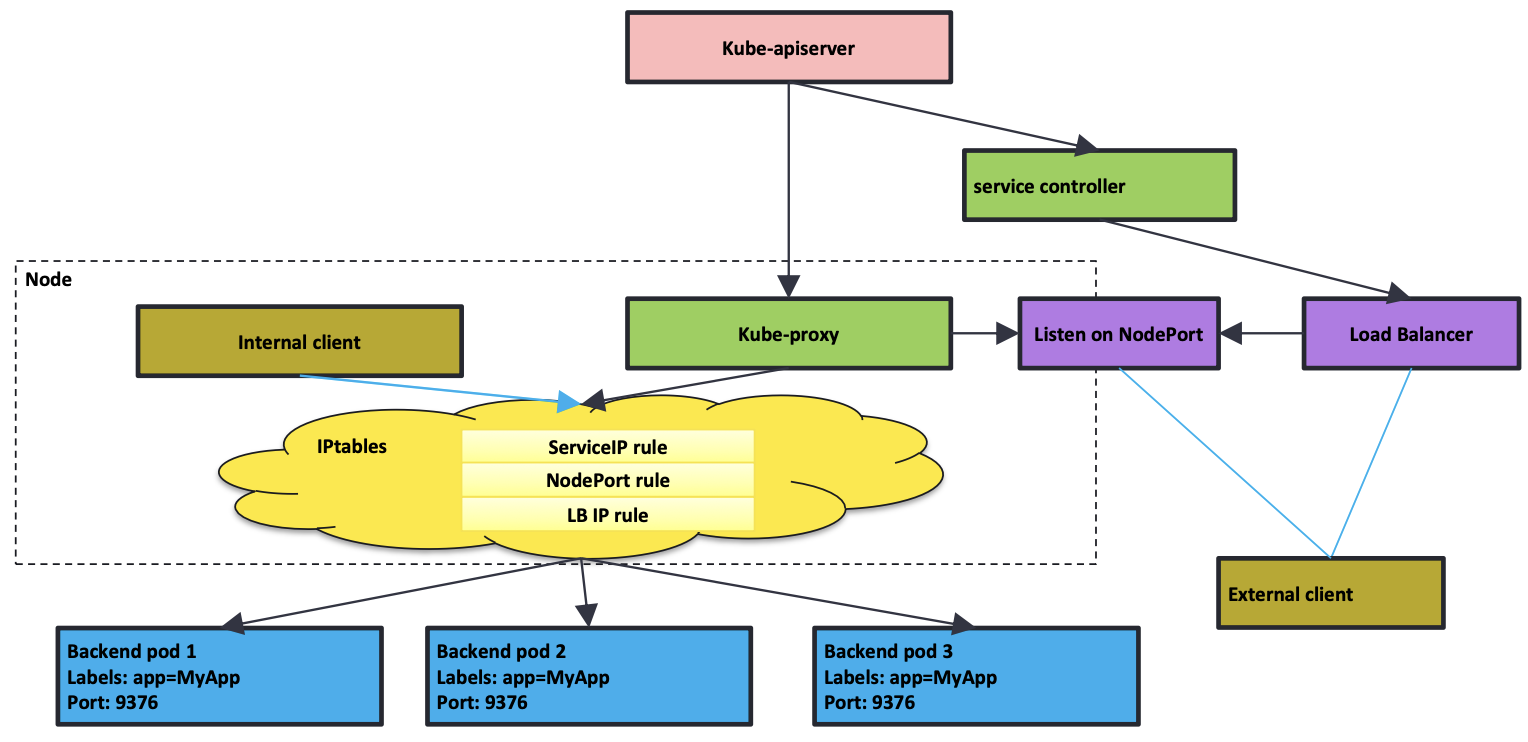
- API Server 接收请求
- 创建 Service 或者 Endpoint,对应的 Service Controller 或者 Endpoint Controller 会执行对应的动作
- kube-proxy 会通过 API Server 监听 Service 或者 Endpoint 的变化
- 如果 kube-proxy 采用 iptables 模式,会创建对应的 iptables 规则
- iptables 不会感知不同类型的 Service(ClusterIP、NodePort 等),都是
一视同仁地创建 iptables 规则
- iptables 不会感知不同类型的 Service(ClusterIP、NodePort 等),都是
- Load Balancer 一般在
集群外部,跟 Kubernetes 集群不在一个网络体系- Pod IP 一般为私有 IP,对 Load Balancer 来说不可达,此时要借助
NodePort - Node 可能会出故障,
Load Balancer 相当于 NodePort 的负载均衡- 在 Node 上打
Label,配置 Load Balancer 时得出对应的 NodeIP + NodePort
- 在 Node 上打
- 如果 Load Balancer 对 Pod 可见,可以定制 Service Controller,让 Load Balancer 直连 Pod,从而绕过 NodePort
- Pod IP 一般为私有 IP,对 Load Balancer 来说不可达,此时要借助
所有 Node 上的 kube-proxy 的行为是
完全一致的,形成分布式的负载均衡- Node 本地就能完成负载均衡
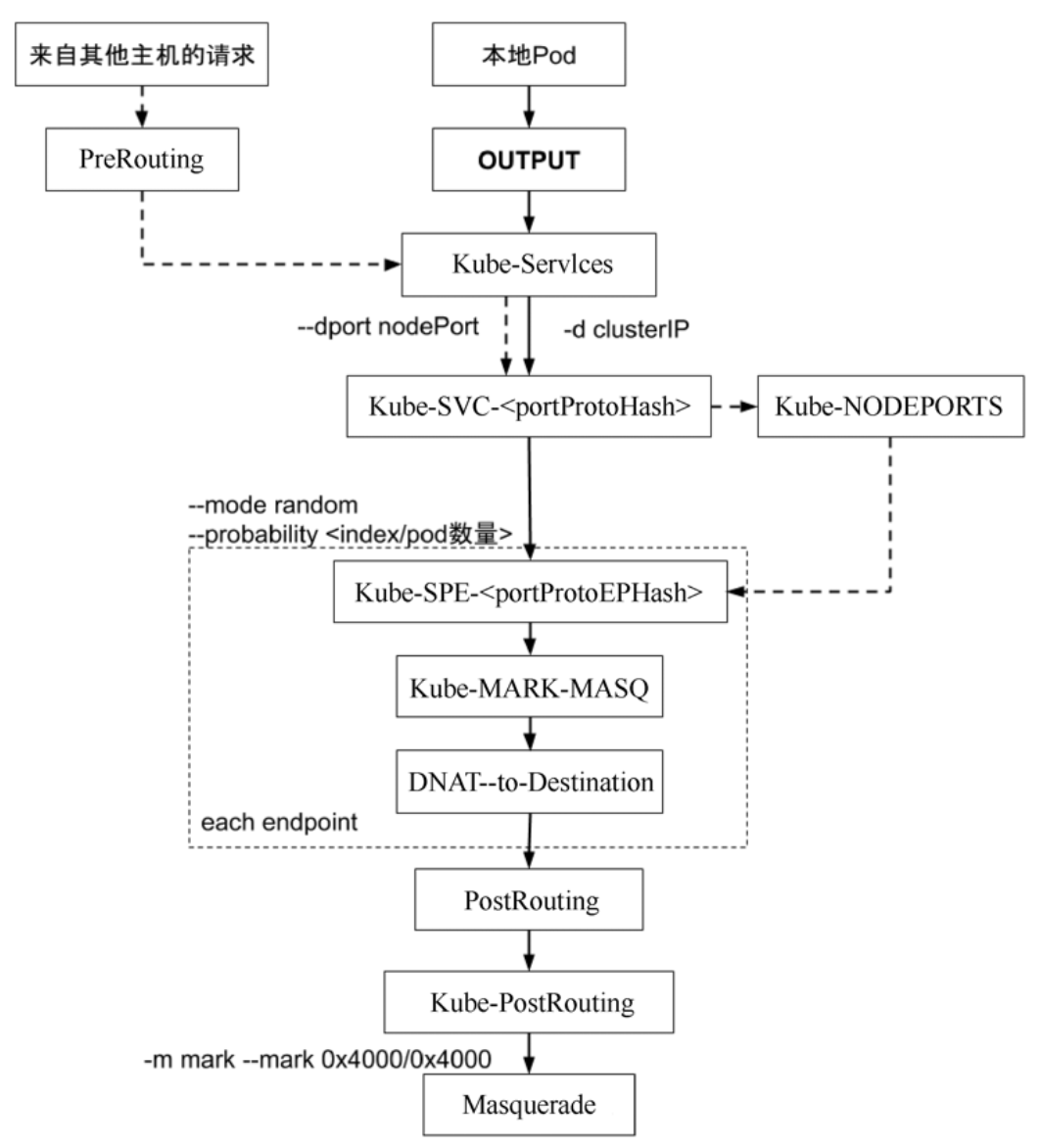
ClusterIP
1 | $ k get services -owide |
1 | apiVersion: v1 |
| VIP | Backend |
|---|---|
| 10.100.49.21:80 | 192.168.185.15:80 |
| 192.168.185.14:80 | |
| 192.168.185.13:80 |
sudo iptables-save -t nat
1 | :PREROUTING ACCEPT [454:20430] |
| Key | Desc |
|---|---|
| -A | Add |
| -j | Jump |
| -d | Destination |
| –dport | Destination Port |
| -p | Protocol |
iptables 为规则引擎,
自上而下逐条执行
随机实现平均(ipvs支持round robin)
- 第1条 33%
- 第1条不命中后,第2条 50%(总体上还是 33%)
- 第2条不命中后,第3条 100%(总体上还是 33%)
如果有 N 个 Pod,就会有 N 条类似的规则,时间复杂度为
O(N)首包慢- 未建立 TCP 连接,首包需要逐条匹配,匹配成功后,会在raw表中记录(Kernel Connection Checking)
不支持增量更新
一旦Service或者Endpoint发生变化,需要重新生成整个 iptables 表- 触发CPU Soft Lock,影响应用
1 | -A KUBE-SVC-WWRFY3PZ7W3FGMQW ! -s 192.168.0.0/16 -d 10.100.49.21/32 -p tcp -m comment --comment "default/nginx-basic:http cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ |
DNAT
1 | :KUBE-SEP-C6OXGZ6X74U4SWF2 - [0:0] |
NodePort
将 ClusterIP 修改为 NodePort
1 | apiVersion: v1 |
监听端口 31195
1 | apiVersion: v1 |
1 | $ ss -lt |
与前面 ClusterIP 的 KUBE-SVC-WWRFY3PZ7W3FGMQW 能
串联起来,复用ClusterIP 的负载均衡能力
1 | :KUBE-NODEPORTS - [0:0] |
VIP
在
iptables模式下,VIP 不会绑定任何设备(ping 不通,ICMP 包),只会存在于 iptables 规则中
1 | $ ping -c 1 10.100.49.21 |
IPVS
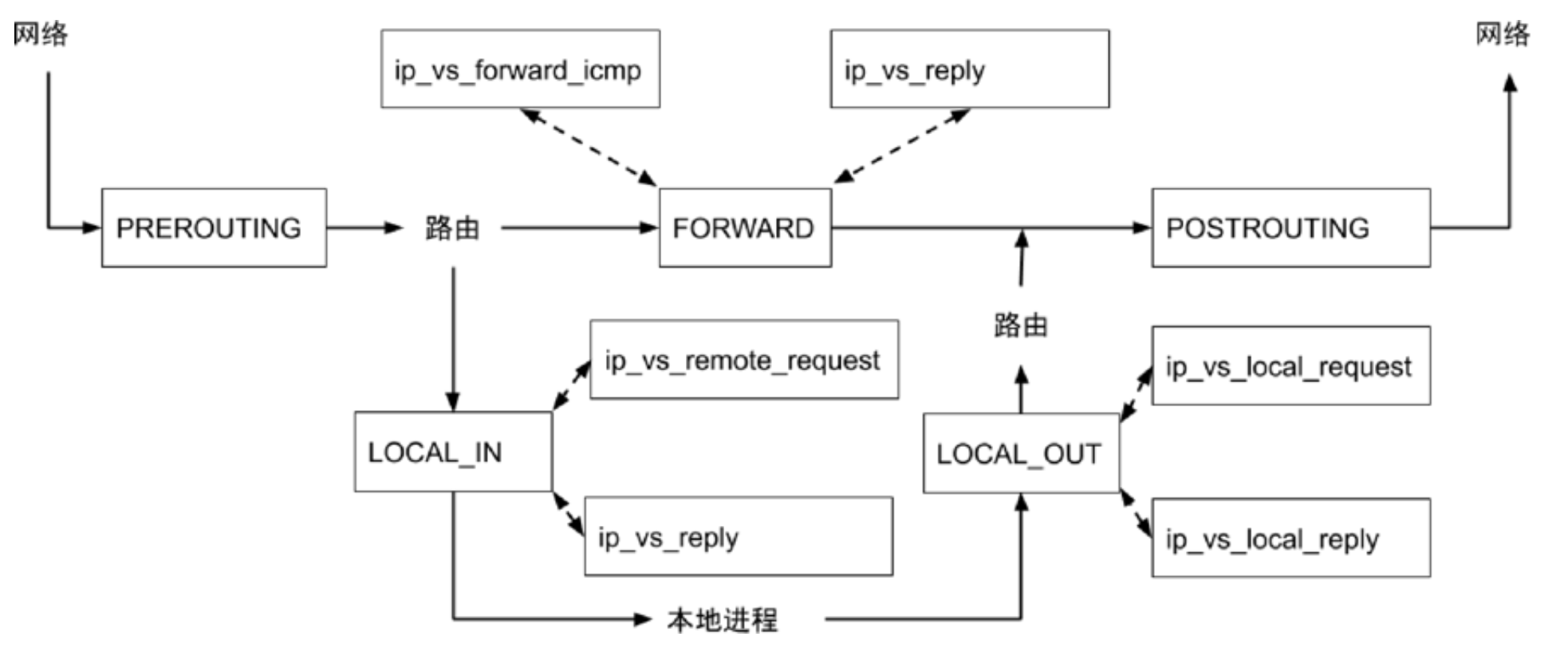
- ipvs 和 iptables 都是 Netfilter 插件,但只支持
LOCAL_IN/LOCAL_OUT/FORWARD - 不支持
PREROUTING的dnat- 在 ipvs 模式下,会在
Node上启动一个虚拟网卡kube-ipvs0,并绑定所有的 ClusterIP - 当接收到数据包时(请求
VIP),Kernel 能识别是否为本机 IP,进而转发到LOCAL_IN(再做后续的DNAT)
- 在 ipvs 模式下,会在
切换
将 kube-proxy 的 mode 修改为 ipvs
1 | $ k edit cm -n kube-system kube-proxy |
重建 kube-proxy
1 | $ k delete po -n kube-system kube-proxy-vz9p8 |
刷新 iptables 规则,减少了很多在 iptables 模式下产生的 iptables 规则
1 | $ sudo iptables -F -t nat |
查看 ipvs 规则(rr =
round robin)
1 | $ sudo ipvsadm -L -n |
查看
kube-ipvs0虚拟网卡
1 | $ ip a |
测试 Service
1 | $ k get service -owide |
在 ipvs 模式下,由于 ClusterIP 会绑定在
kube-ipvs0的虚拟网卡下,所以能 ping 通
1 | $ ping -c 1 10.100.49.21 |
iptables
结合
ipset(减少 iptables 规则),通过一条 iptables 规则实现IP 伪装(snat)
1 | $ ipset -L |
避免了原本在 iptables 模式下产生很多 iptables 规则的情况
1 | $ iptables-save -t nat |
DNS
Kubernetes 提供了内置的域名服务,Service 会自动获得域名
无论 Service 重建多少次,只要 Service 名称不变,对应的域名也不会发生改变
DNS 主要与
Service配合,而 Service 工作在四层
CoreDNS
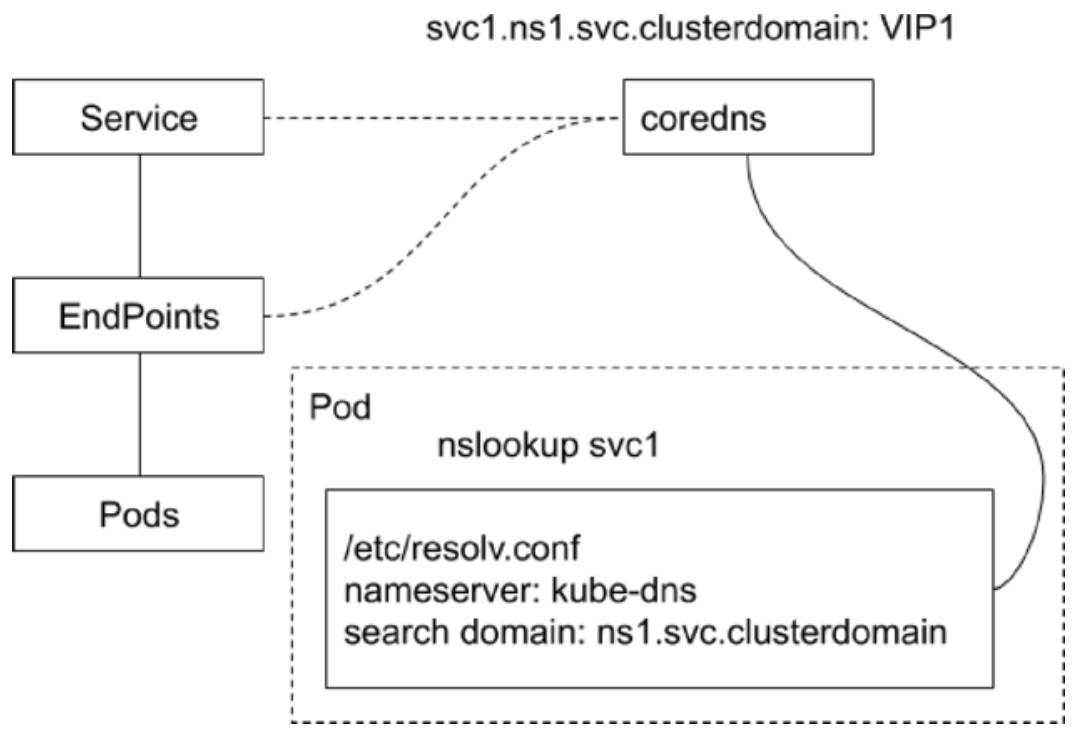
- CoreDNS 包含一个
内存态DNS,并且本身也是一个控制器 - 工作原理
- 控制器监听
Service和Endpoint的变化并配置DNS - 客户端 Pod 在进行域名解析时,会从 CoreDNS 中查询 Service 对应的地址记录
- 控制器监听
- 递归查询
- 查询 CoreDNS 本身的 A 记录,如果不存在,则转发到 CoreDNS 的上游 DNS 服务器(配置来自于
Node)
- 查询 CoreDNS 本身的 A 记录,如果不存在,则转发到 CoreDNS 的上游 DNS 服务器(配置来自于
kube-proxy采用DaemonSet部署,CoreDNS采用Deployment部署
1 | $ k get deployments.apps -n kube-system -owide |
1 | $ k get po |
ndots:5- 如果提供的域名少于 5 个.,则会认为是短名,尝试从search domain中依次匹配
1 | $ k exec -it centos -- bash |
CoreDNS 会使用 Node 上的
/etc/resolv.conf文件
1 | $ cat /etc/resolv.conf |
DNS Record
依赖
ClusterIP来做服务调用,相对稳定
- Common Service
- ClusterIP、NodePort、LoadBalancer 类型的 Service 都拥有
API Server分配的ClusterIP - CoreDNS 会为其创建
FQDN格式的A 记录和PTR 记录,并为端口创建SRV 记录- FQDN -
fullyqualified domain name,即${svcname}.${ns}.svc.${clusterdomain}
- FQDN -
- ClusterIP、NodePort、LoadBalancer 类型的 Service 都拥有
- Headless Service
- 显式指定 ClusterIP 为
None,所以 API Server不会为其分配 ClusterIP- 但还是会
创建同名的 Endpoint,只有 Selector 为空才不会自动创建 Endpoint
- 但还是会
- CoreDNS 需为此类 Service 创建
多条 A 记录,目标为每个就绪的 Pod IP- 如果某个 Pod
不 Ready,CoreDNS 会把对应的 A 记录移除
- 如果某个 Pod
- 每个 Pod 会拥有一个
FQDN的A 记录指向 Pod IP${podname}.${svcname}.${ns}.svc.${clusterdomain}
- Pod 的属性
hostname和subdomain组成${podname}${hostname}.${subdomain}.${svcname}.${ns}.svc.${clusterdomain}- 如 StatefulSet
- 客户端通过 CoreDNS 拿到的就是 Pod IP,对 Pod IP 请求不再需要经过
ipvs或者iptables
- 显式指定 ClusterIP 为
- ExternalName Service
- 此类 Service 用来引用一个
已经存在的域名 - CoreDNS 会为该 Service 创建一个
CName 记录指向该目标域名
- 此类 Service 用来引用一个
| Type | DNS | Key | Value | Count |
|---|---|---|---|---|
| Common | a | ${svcname}.${ns}.svc.${clusterdomain} |
ClusterIP | 1 |
| Headless | a | ${podname}.${svcname}.${ns}.svc.${clusterdomain}${hostname}.${subdomain}.${svcname}.${ns}.svc.${clusterdomain} |
Ready PodIP | N |
| ExternalName | cname | Alias | Existed Domain | 1 |
Resolution
- Pod 默认的
DNSPolicy为ClusterFirst(即CoreDNS)- 如果使用
Default,则采用Node上的/etc/resolv.conf
- 如果使用
- Pod 启动后的
/etc/resolv.conf会被改写,所有的地址解析优先发送到CoreDNS - 当 Pod 启动时,
同一 Namespace的所有Service都会以环境变量的形式设置到容器内
1 | $ k get svc -owide |
自定义
DNSPolicy
1 | spec: |
生产落地
- Service 在
集群内通过CoreDNS寻址,在集群外通过企业 DNS寻址,Service 在集群内外有统一标识 - Service 需要发布到企业 DNS
- 在企业 DNS,同样创建
A/PTR/SRV记录(通常解析地址为LoadBalancer VIP) Headless Service- 在
Pod IP可全局路由的前提下,按需创建 DNS 记录- 否则对企业 DNS 是很大的冲击(DNS 不是专门用于
负载均衡)
- 否则对企业 DNS 是很大的冲击(DNS 不是专门用于
- CoreDNS 支持
横向扩展,而一般的企业 DNS 不具备这个扩展能力
- 在
- 在企业 DNS,同样创建
Ingress
负载均衡
Kubernetes 中的负载均衡技术
| L4 Service | L7 Ingress |
|---|---|
基于 iptables / ipvs 的分布式四层负载均衡技术(五元组) |
基于七层应用层,提供更多功能 |
多种 Load Balancer Provider 提供与企业现有 ELB(比较贵) 整合 |
TLS termination 反向代理处理 TLS,业务开发只关注 HTTP 即可 |
kube-proxy 基于 iptables rules 为 Kubernetes 形成全局统一的分布式负载均衡器 |
L7 path forwarding |
kube-proxy 是一种 mesh,内部客户端无论通过 ClusterIP、NodePort、LB VIP 都经过 kube-proxy 跳转到 pod |
URL/http header rewrite |
属于 Kubernetes Core |
与采用 7 层软件紧密相关 |
每个应用独占 ELB,浪费资源 |
多个应用共享 ELB,节省资源 |
为每个 Service 动态创建 DNS 记录,频繁的 DNS 更新 |
多个应用共享一个 Domain,采用静态 DNS 配置 |
支持 TCP 和 UDP,如果需要启动 HTTPS 服务,需要管理证书 |
TLS termination 发生在 Ingress 层,可集中管理证书 |
| 更复杂,更多的网络 hop |
Ingress 是
反向代理+控制器
监听 Ingress Spec,生成对应的反向代理规则,应用到 Ingress 的反向代理,Ingress 会执行 TLS termination
Ingress 工作在七层,但前面还有一个
四层的Ingress Service
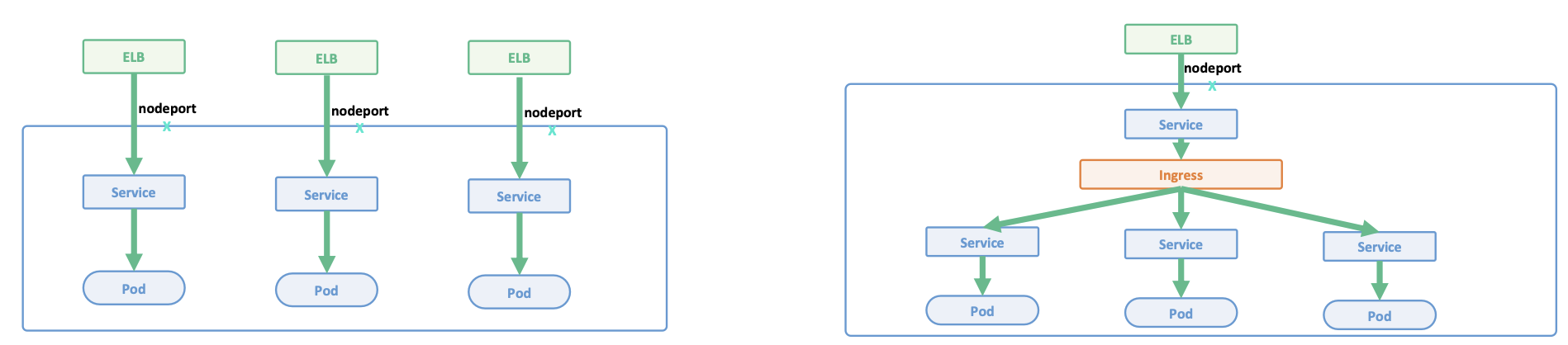
基本概念
- Ingress
- Ingress 是一层
反向代理 - 根据
hostname和path将流量转发到不同的服务,使得同一个负载均衡器用于多个后端应用 Ingress Spec是转发规则的集合
- Ingress 是一层
- Ingress Controller
负载均衡配置边缘路由配置DNS配置
逻辑结构
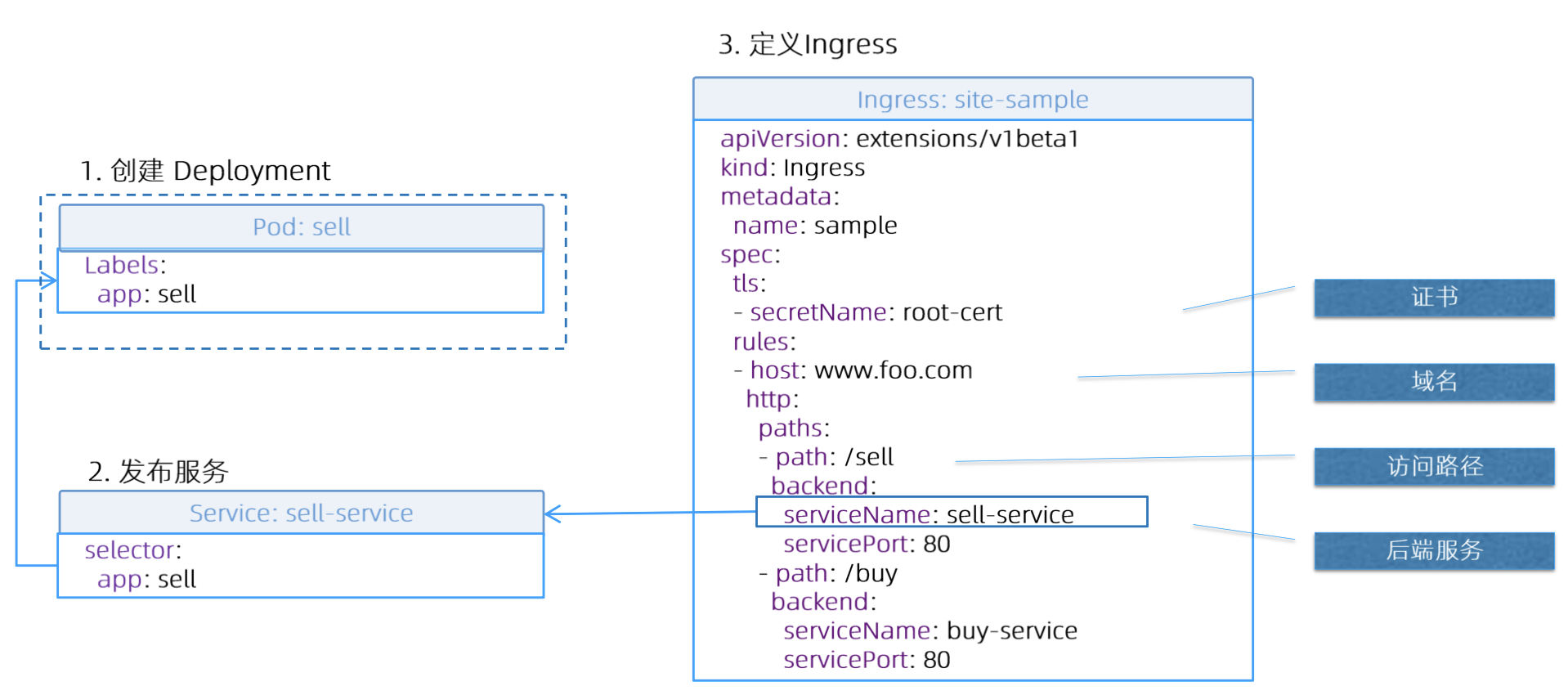
TLS
CN = Common Name,如果为
*,表示不做域名校验
1 | $ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=z.com/O=z" -addext "subjectAltName = DNS:z.com" |
Ingress
kubernetes.io/ingress.class指定IngressClass,再通过 IngressClass 关联Ingress Controller
Ingress Controller 应遵循统一规范,
只解析需要解析的 Ingress
1 | apiVersion: networking.k8s.io/v1 |
1 | $ k get ingressclasses.networking.k8s.io -A |
1 | apiVersion: networking.k8s.io/v1 |
1 | $ k apply -f z-ingress.yaml |
1 | apiVersion: networking.k8s.io/v1 |
直接访问 Ingress Controller 的 Pod IP(会被 ipvs 拦截)
1 | $ curl -H "Host: z.com" https://192.168.185.21 -v -k |
通过
Ingress Service来访问 - https 的 NodePort 端口为 31590
1 | $ k get service -n ingress-nginx -owide |
缺陷
Ingress 已毕业,但很难满足所有业务场景
导致很多 Ingress Controller 采用非标准化的方式来实现一些高级功能,主要是借助Annotation
七层的流量治理是一个很大的范畴,很难通过一个 Ingress Spec 去完整定义 -
Service API/(Envoy + Istio)
- TLS 配置受限(如无法配置 cypher, dhkey, TLSVersion)
- 无法实现基于
Header来配置规则 - 无法实现
Rewriting- Header rewriting
- URI rewriting
实战案例
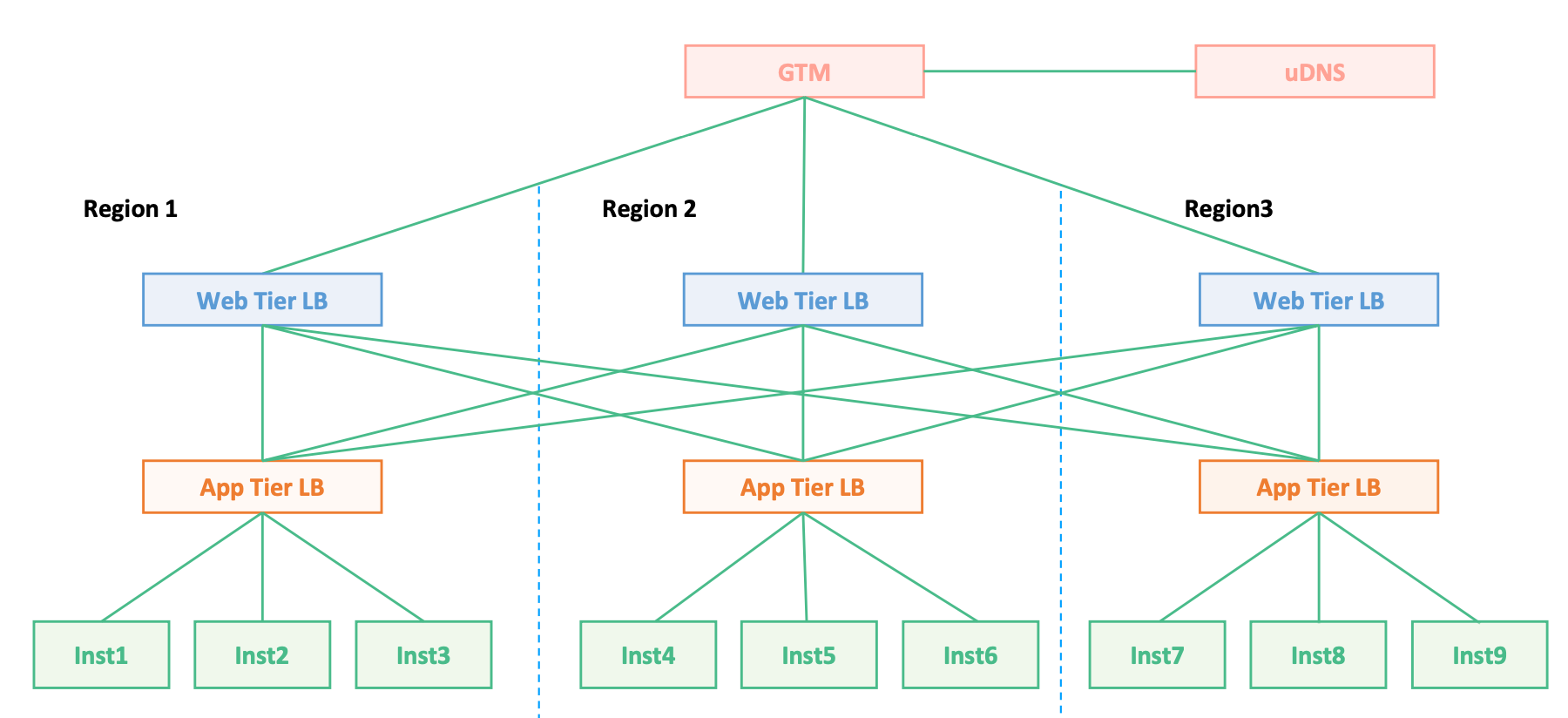
L4
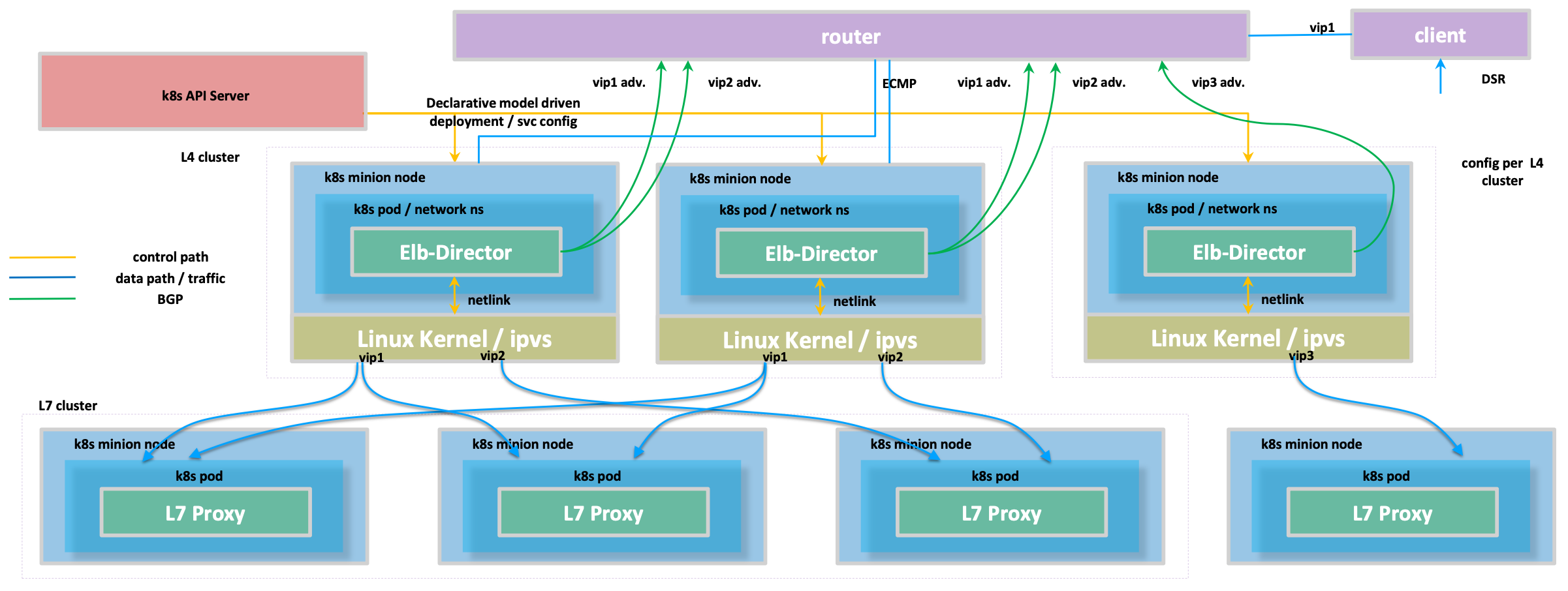
L7 - IP in IP Tunneling
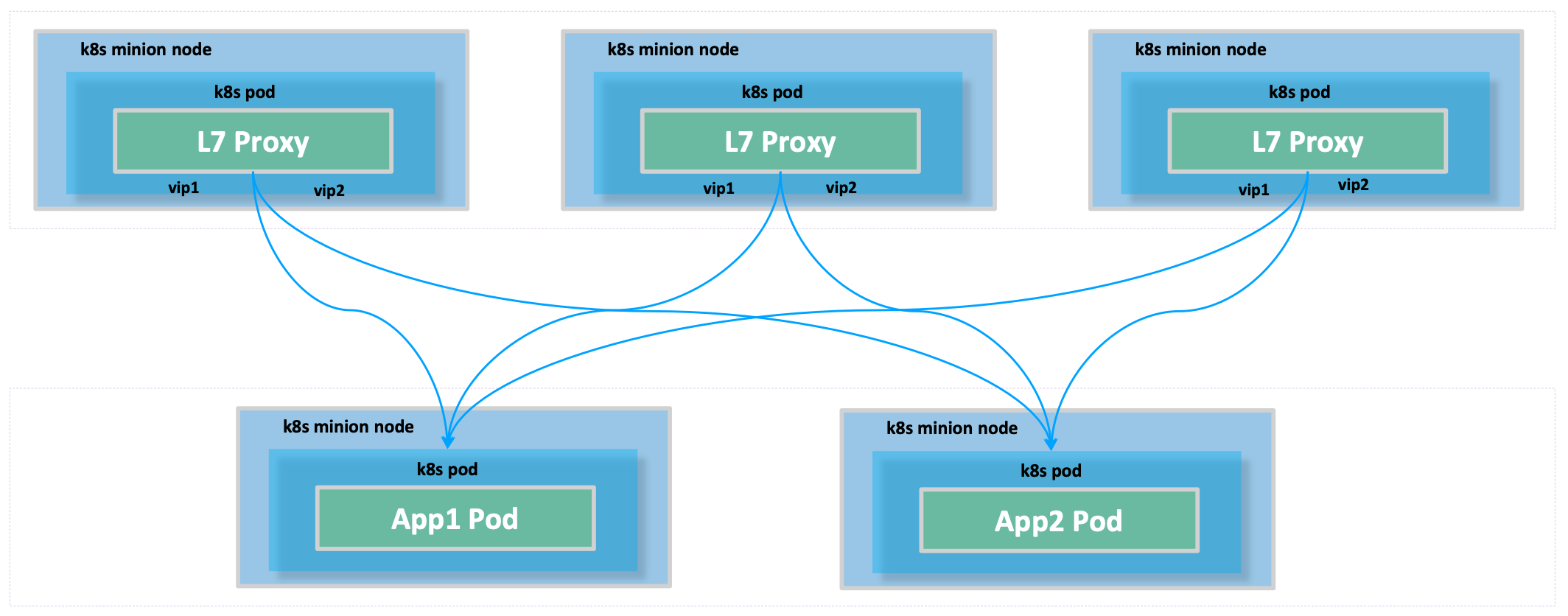
数据流