Go - Primitive Type
数值
整型
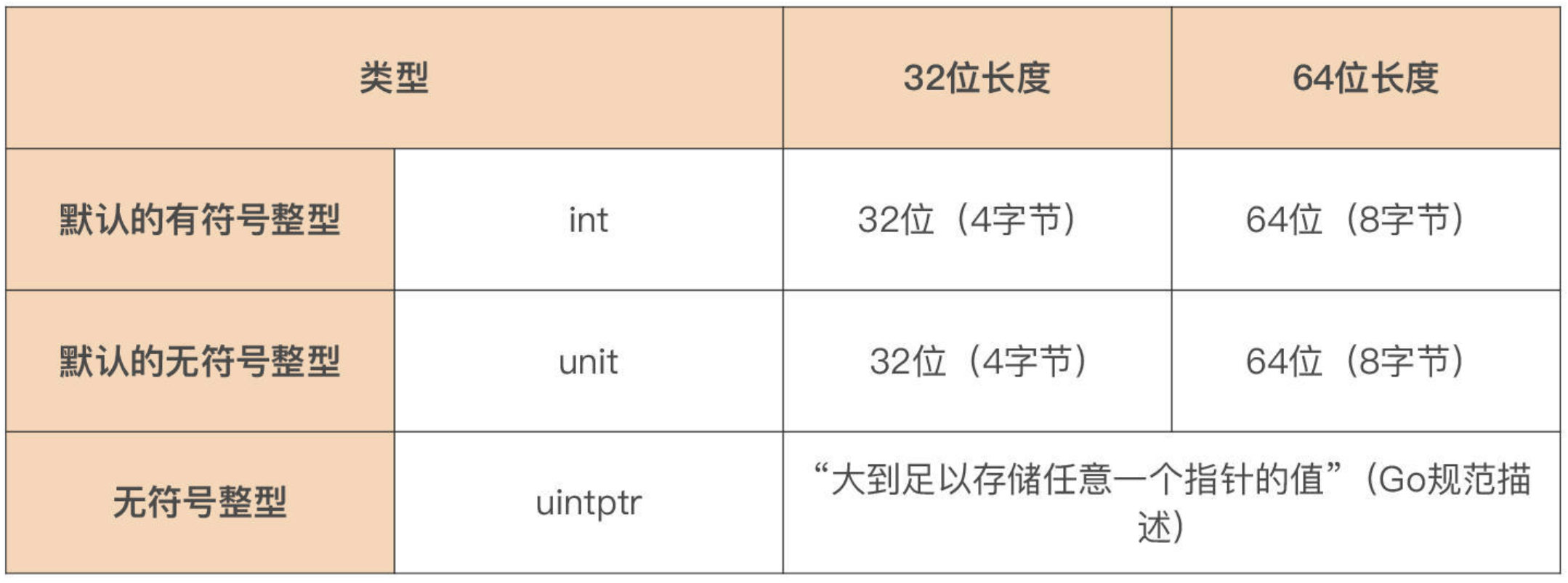
平台无关整型
在任何
CPU 架构和任何操作系统下面,长度都是固定不变的
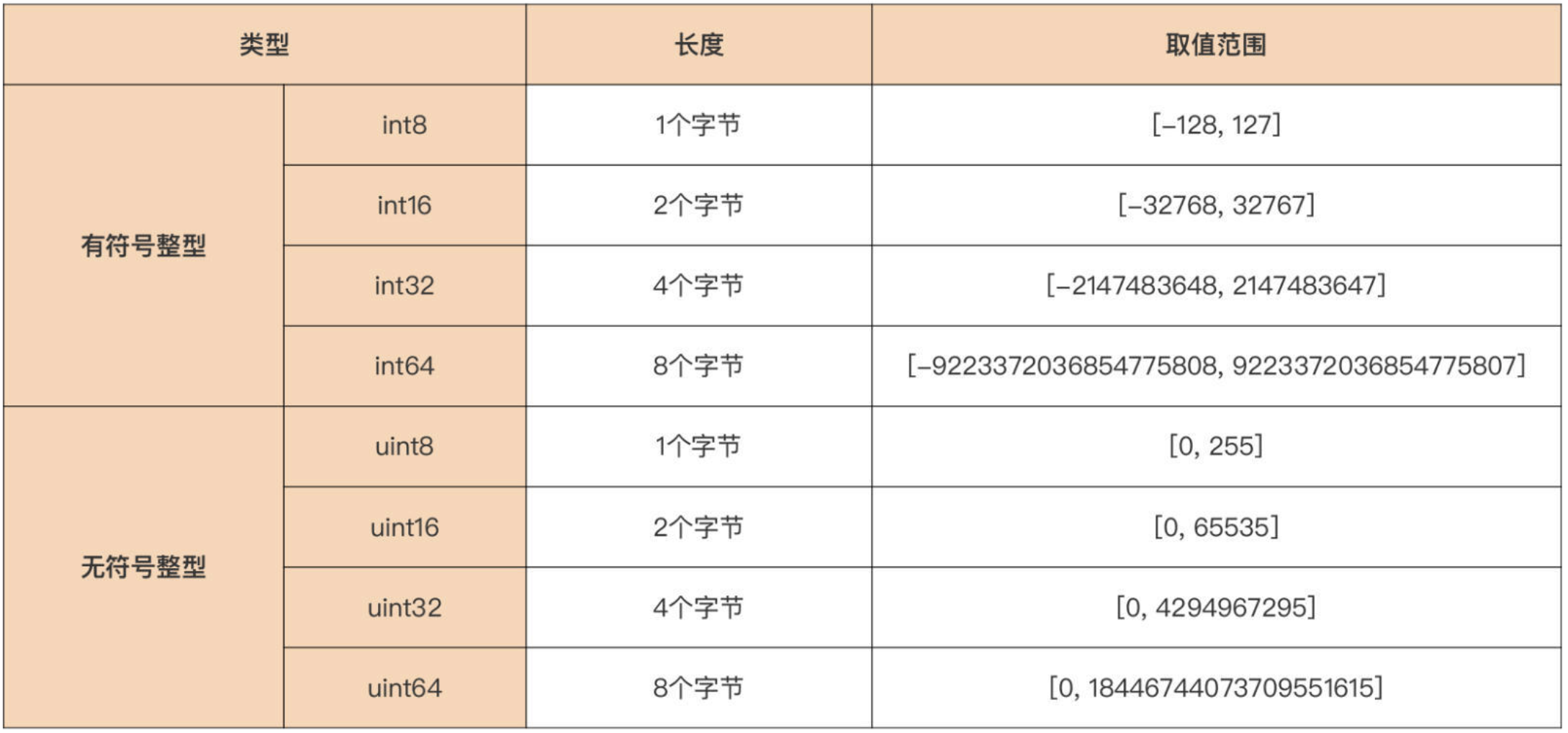
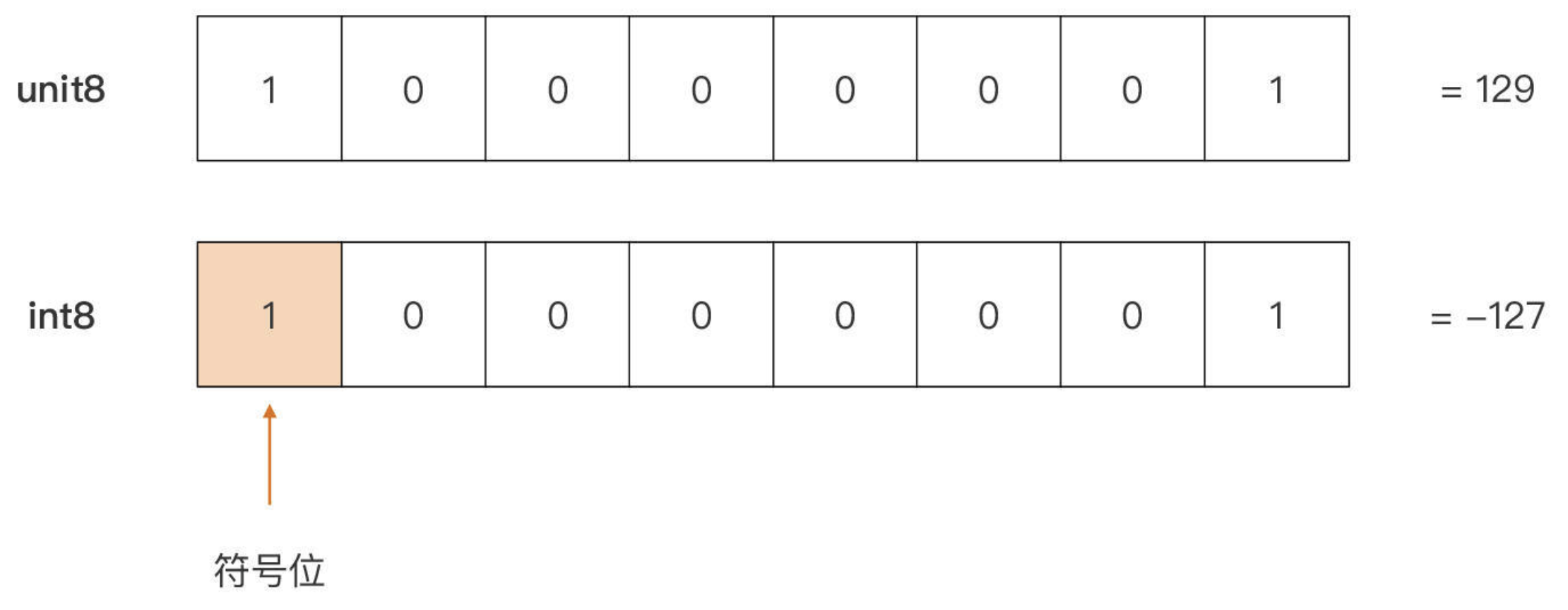
有符号整型 vs 无符号整型
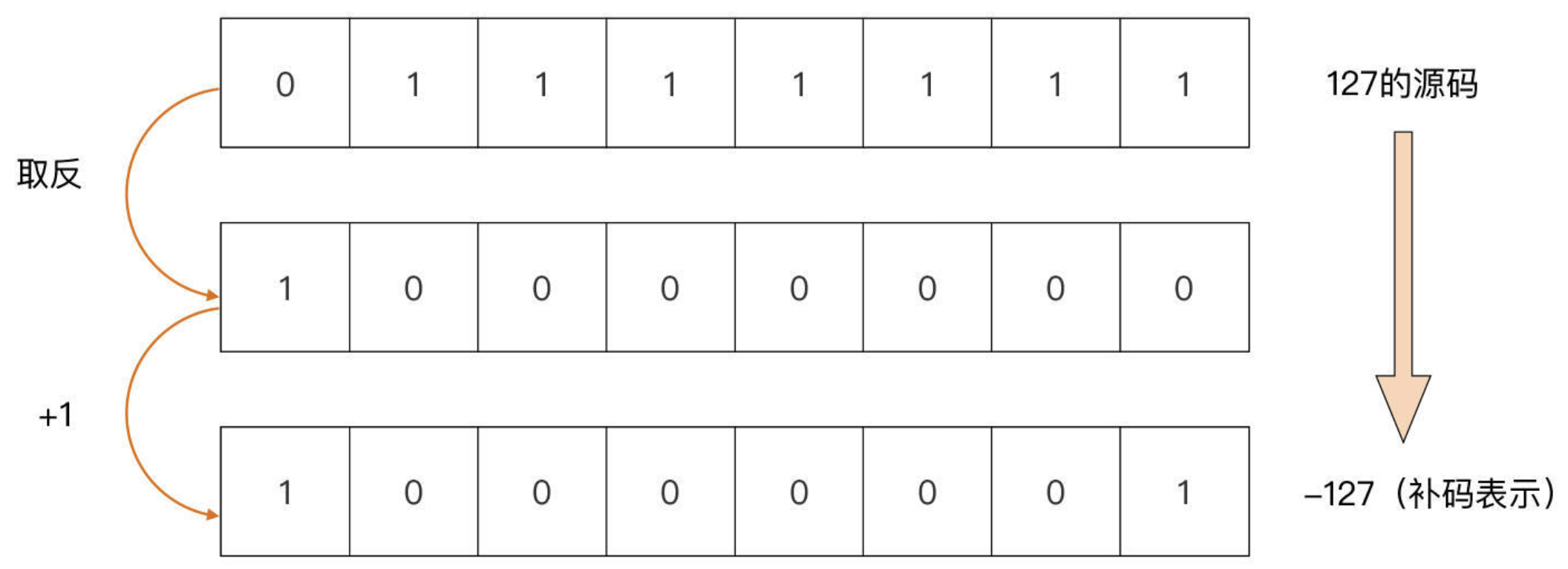
Go 采用
补码作为整型的比特位编码方法:原码逐位取反后加 1
平台相关整型
长度会根据运行平台的改变而改变,在编写移植性要求的代码时,不要依赖下述类型的长度
1 | a, b := int(5), uint(6) |
溢出
1 | var s int8 = 127 |
字面值
1 | a := 53 // 十进制 |
为了增强字面值的可读性,Go 1.13 支持数字分隔符
_
只在 go.mod 中的 go version 为 Go 1.13 后的版本才会生效,否则编译器会报错
underscores in numeric literals requires go1.13 or later
1 | a := 5_3_7 // 十进制 537 |
格式化
1 | var a int8 = 59 |
浮点型
二进制
IEEE 754是 IEEE 制定的二进制浮点数算术标准,是最广泛使用的浮点数运算标准,被许多 CPU 和浮点数运算器采用- IEEE 754 标准规定了四种表示浮点数值的方式
单精度(32 bit)、双精度(64 bit)、扩展单精度(43 bit 以上)、扩展双精度(79 bit 以上)
- Go 提供了
float32和float64两种浮点类型,分别对应IEEE 754的单精度和双精度 - Go 没有提供 float 类型,Go 提供的浮点数类型都是
平台无关的 float32和float64的默认值都是0.0,但占用的内存大小是不一样的,可以表示的浮点数的范围和精度也是不一样的- 日常开发中,使用
float64的情况更多,也是 Go浮点常量或者字面量的默认类型
- 日常开发中,使用
1 | func main() { |
float32 可能会因为
精度不足,导致输出结果与预期不符合
1 | func main() { |
字面值
十进制
1 | func main() { |
科学计数法(十进制,
e/E代表幂运算的底数为10)
1 | func main() { |
科学计数法(十六进制,
p/P代表幂运算的底数为2)整数和小数部分均采用十六进制,而指数部分依然采用十进制
1 | func main() { |
格式化
%f输出浮点数最直观的原值形式
1 | func main() { |
输出为科学计数法(
%e对应十进制的科学计数法,%x对应十六进制的科学计数法)
1 | func main() { |
复数类型
Go 原生支持复数类型,主要用于专业领域,如矢量计算
- Go 提供 complex64 和 complex128 两种复数类型
complex64的实部和虚部都是float32类型complex128的实部和虚部都是float64类型
- 默认的复数类型为 complex128
通过
复数字面量直接初始化一个复数类型变量
1 | func main() { |
通过
complex函数,创建complex128类型变量
1 | func main() { |
通过
real函数和imag函数,获取复数的实部和虚部,返回一个浮点类型
1 | func main() { |
由于复数类型的实部和虚部都是
浮点数,因此可以直接采用浮点型的格式化输出方式
1 | func main() { |
自定义
类型定义
通过
type关键字基于原生数值类型来声明一个新类型
1 | type MyInt int32 |
- MyInt 类型的
底层类型是 int32,其数值性质与 int32完全相同,但是完全不同的类型 - 基于 Go 的
类型安全规则,无法让 MyInt 和 int32相互赋值,否则编译器会报错
1 | func main() { |
可通过
显式转型来避免
1 | func main() { |
类型别名
通过类型别名(
Type Alias)语法来定义的新类型与原类型完全一样,可以相互替代(不需要显式转换)
1 | type MyInt = int32 |
字符串
原生支持
C 语言没有提供对字符串类型的原生支持,字符串需要通过
字符串字面值或者以\0结尾的字符类型数组来呈现
1 |
|
- 不是原生类型,
编译器不会对它进行类型校验,导致类型安全性差 - 字符串操作时需要时刻考虑结尾的
\0,防止缓存区溢出 - 以
字符数组形式定义的字符串,值是可变的,在并发场景中需要考虑同步问题 - 获取一个字符串的
长度,通常为O(n)的时间复杂度 - C 语言没有内置对
非 ASCII 字符集的支持
在 Go 中,字符串类型为
string:字符串常量、字符串变量、字符串字面值
1 | package main |
优势
string 类型的数据是
不可变的,与 Java 类似,提高了并发安全性和存储利用率
- string 类型的
值在它的生命周期内是不可变的,但 string 变量是可以再次赋值的- 开发者不用再担心字符串的
并发安全问题,字符串可以被多个 goroutine 共享
- 开发者不用再担心字符串的
- 由于字符串的不可变性,针对
同一个字符串值,Go 的编译器都只需要为其分配同一块存储
1 | func main() { |
没有结尾
\0,获取字符串长度的时间复杂度为0(1)
- 在 C 语言中,通过标准库的
strlen函数获取一个字符串的长度- 实现原理:
遍历字符串中的每个字符并计数,直到遇到\0,时间复杂度为O(N)
- 实现原理:
- Go 中没有
\0,获取字符串长度的时间复杂度为O(1)
1 |
|
通过
反引号实现所见即所得(Raw String),降低构造多行字符串的心智负担
1 | func main() { |
支持非 ASCII 字符
- Go 源文件默认采用
Unicode 字符集 - Go 字符串中的每个字符都是一个 Unicode 字符,并且以
UTF-8编码格式存储在内存当中
内部组成
字节视角
字符串值是一个可空的字节序列,字节序列中的字节个数称为该字符串的长度
1 | func main() { |
字符视角
字符串是由一个
可空的字符序列构成的
1 | func main() { |
- Go 采用
Unicode 字符集,每个字符都是一个Unicode 字符 Unicode 码点:在 Unicode 字符集中的每个字符,都被分配了统一且唯一的字符编号- 一个 Unicode 码点唯一对应一个字符
rune
rune表示一个Unicode 码点,本质上是int32类型的类型别名(Type alias),与 int32完全等价
1 | // rune is an alias for int32 and is equivalent to int32 in all ways. It is |
- 一个
rune 实例就是一个Unicode 字符;一个Go 字符串也可被视为rune 实例的集合 - 可以通过
字符字面值来初始化一个rune 变量
字符字面值 - 单引号
1 | func main() { |
字符字面量 - 使用 Unicode 专用的转义字符
\u或者\U作为前缀,来表示一个 Unicode 字符
\u后接2个十六进制数,\U后接4个十六进制数
1 | func main() { |
rune 本质上是一个
整型数,可以用整型值来直接作为字符字面值给 rune 变量赋值
1 | func main() { |
字面值
1 | func main() { |
UTF-8
UTF-8 编码解决的是 Unicode 码点值在计算机如何
存储和表示的问题
UTF-32编码:固定使用4 Bytes表示每个 Unicode 码点,编解码比较简单- 缺点
- 使用 4 Bytes
存储和传输一个整型数的时候,需要考虑不同平台的字节序问题(大端、小端) - 与采用
1 Bytes编码的ASCII字符集无法兼容 - 所有 Unicode 码点都是用 4 Bytes 编码,
空间利用率很差
- 使用 4 Bytes
- Go 之父 Rob Pike 发明了 UTF-8 编码方案
- UTF-8 使用
变长度字节,对 Unicode 字符的码点进行编码 - 编码采用的
字节数量与 Unicode 字符对应的码点大小有关- 码点
小的字符使用的字节数量少,码点大的字符使用字节数量多
- 码点
- UTF -8 编码使用
1 ~ 4 Bytes- 前
128个与 ASCII 字符重合的码点(U+0000 ~ U+007F)使用1 Byets表示 - 带变音符号的拉丁文、希腊文、阿拉伯文等使用
2 Bytes表示 东亚文字使用3 Bytes表示- 极少使用的语言字符使用
4 Bytes表示
- 前
- UTF-8 使用
- UTF-8 优势
兼容ASCII 字符的内存表示,无需任何改变- UTF-8 的
编码单元为1 Bytes(即一次编解码一个 Bytes),因此无需像 UTF-32 那样需要考虑字节序问题 - 相对于 UTF-32,UTF-8 的
空间利用率也很高
- UTF-8 编码方案已经成为
Unicode 字符编码方案的事实标准
1 | // rune -> []byte |
1 | // []byte -> rune |
内部表示
string 类型是一个描述符,本身并
不真正存储字符串数据,而仅是由一个指向底层存储的指针和字符串的长度字段组成
由于有 Len 字段,因此获取字符串长度的时间复杂度为O(1)
1 | // StringHeader is the runtime representation of a string. |
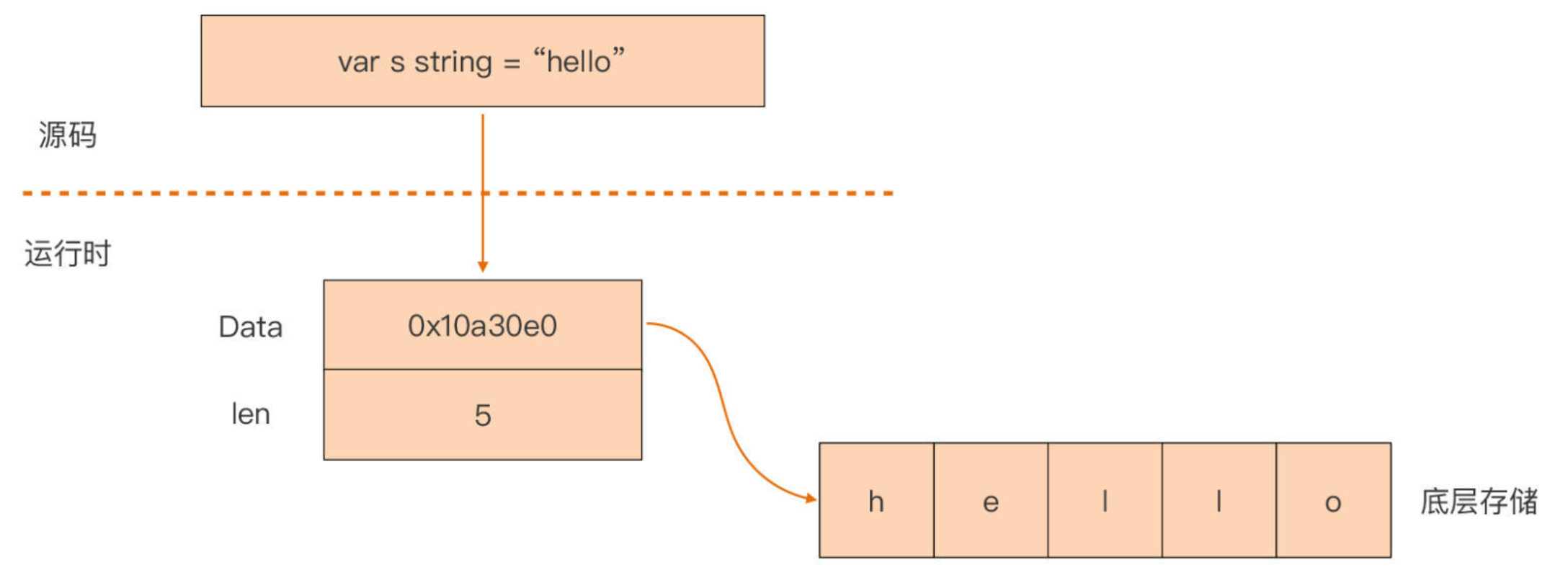
- Go
编译器将源码中的 string 类型映射为运行时的一个二元组(Data + Len) - 真实的
字符串值数据存储在一个被 Data 指向的底层数组中
利用
unsafe.Pointer的通用指针转型能力,按照内存布局,顺藤摸瓜,输出底层数组的内容
1 | func dumpBytesArray(bytes []byte) { |
即便直接将 string 类型变量作为
函数参数,其传递的开销也是恒定的,不会随着字符串大小的变化而变化
常见操作
下标
字符串的下标操作本质上等价于
底层数组的下标操作,获取的是字符串特定下标上的字节,而不是字符
1 | func main() { |
迭代
for为字节视角;而for range为字符视角
1 | func main() { |
字符串 Unicode 字符的
码点值,以及该字符在字符串对应底层数组中的偏移量
相当于将
s[0,3]的字节数组解码成一个rune
1 | func main() { |
长度
1 | func main() { |
连接
追求
性能更优的话,应该使用strings.Builder,strings.Join,fmt.Sprintf等函数
1 | func main() { |
比较
采用
字典序的比较策略,分别从每个字符串的起始处,开始逐个字节对比两个字符串,直到遇到第一个不相同的元素
如果两个字符串长度不同,长度较小的字符串会用空元素补齐,空元素比非空元素小
1 | func main() { |
转换
Go 支持字符串与
字节切片,字符串和rune 切片的双向显式转换
1 | func main() { |
有一定
开销,根源在于 string 的不可变性,运行时要为转换后的类型分配新内存
string 有两个维度上的表示,
[]rune(字符) 和[]byte(字节)