Go - Map
定义
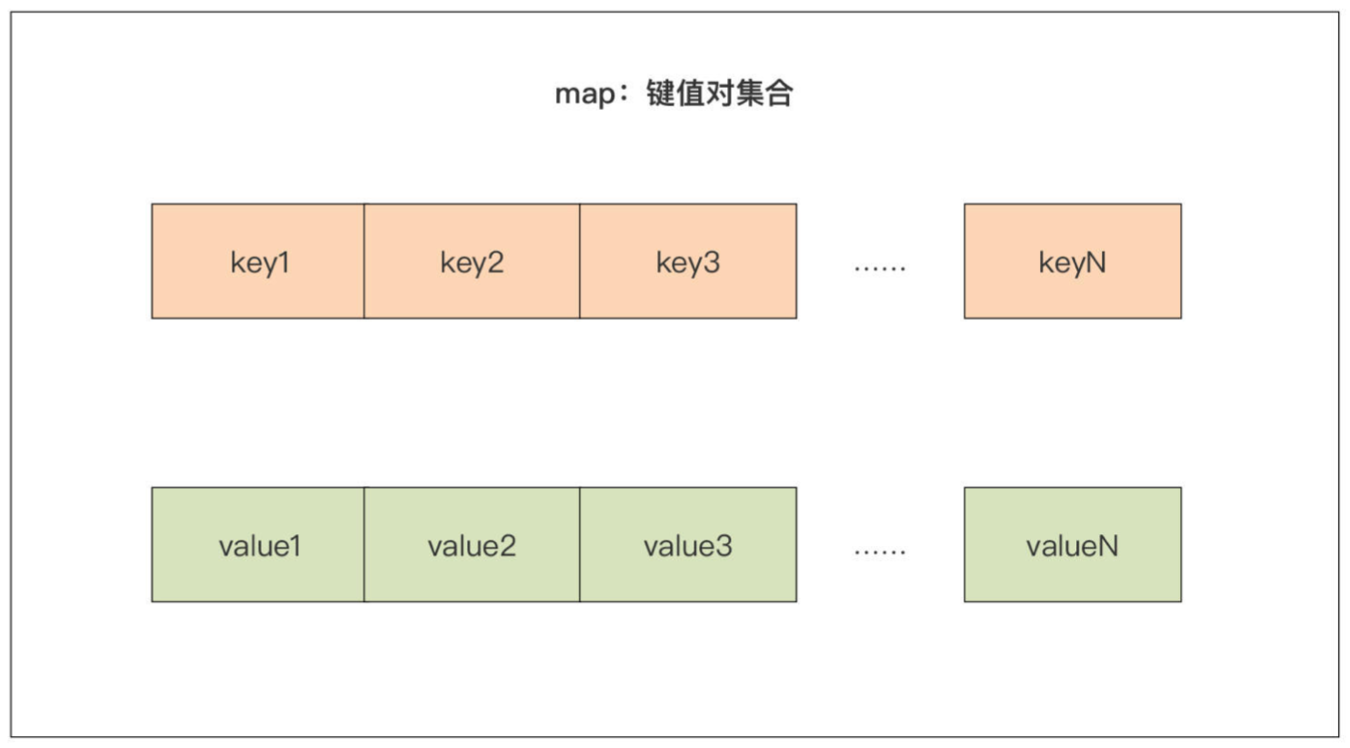
map 表示一组
无序的键值对,map 中每个Key都是唯一的
Key 和 Value 的类型不要求相同,如果 Key 类型和 Value 类型都相同,map 类型才是
等价的
1 | m1 := map[string]string{} |
对
Value类型没有限制,但对Key类型有严格限制
因为 map 类型要保证 Key 类型的唯一性,因此,Key类型必须支持==和!=两种比较操作
在 Go 中,
slice、map、func都只支持与nil比较,并不支持同类型变量比较,因此不能作为 map 类型的 Key
1 | s1 := make([]int, 1) |
1 | m1 := make(map[[]int]int) // invalid map key type []int |
声明
如果
没有显式赋值,则map和slice的默认值都为nil
1 | var arr [4]int // not nil |
slice支持零值可用,但map由于其内部实现的复杂性,不支持零值可用
1 | var sl []int // nil |
由于
map 不支持零值可用,因此必须对map类型变量进行显式初始化后才能使用
初始化
复合字面量
1 | m := map[int]string{} |
语法糖:允许省略
字面值中元素类型
因为 map 类型声明时已经指定了Key类型和Value类型,Go编译器有足够的信息进行类型推导
1 | m := map[int][]string{ |
1 | type Position struct { |
make
为 map 类型变量指定键值对的
初始容量,但无法进行具体的键值对赋值
当 map 中的键值对数量超过初始容量后,
Go Runtime会对 map 进行自动扩容
1 | //m1 := make(map[string]int) |
基本操作
插入
对于一个
非 nil的 map 类型变量,可以插入符合定义的任意新键值对
Go 会保证插入总是成功的,Go Runtime会负责 map 变量内部的内存管理
1 | m := make(map[int]string) |
如果 key 已经存在,则
覆盖
1 | m := map[int]string{ |
数量
通过
len函数,获取当前变量已经存储的键值对数量
1 | m := map[int]string{ |
map 不支持
cap函数
索引
查找 map 中
不存在的 key,会返回对应的类型零值
1 | m := make(map[string]int) |
comma ok
1 | m := make(map[string]int) |
删除
delete函数是从 map 中删除数据的唯一方法(即便 map 不存在,也不会panic)
1 | m := map[string]int{ |
遍历
只有
一种遍历方式:for range
1 | func main() { |
遍历 map,key 是
无序的
1 | func iteration(m map[int]int) { |
传递开销
与
slice一样,map也是引用类型,实际传递的并非整个 map 的数据拷贝,因此传递开销是固定,并且是很小的
当 map 被传递到
函数或者方法内部后,后续对 map 的修改,在函数或者方法外部是可见的
1 | func f(m map[string]int) { |
内部实现
Go Runtime使用一张哈希表来实现抽象的 map 类型,实现了 map 类型操作的所有功能
对应关系
在
编译阶段,Go 编译器会将语法层面的 map 操作,重写成Runtime对应的函数调用
1 | // go |
1 | // go |
1 | // go |
1 | // go |
Runtime
实现原理
与
slice类似,map由编译器和运行时联合实现
- 编译器在编译阶段将语法层面的 map 操作,
重写为运行时对应的函数调用- 运行时则采用了高效的算法实现了 map 类型的各类操作
其实这是简化了用户的使用门槛,用户本可以像 Java 那边直接感知到各种 map 的实现
初始
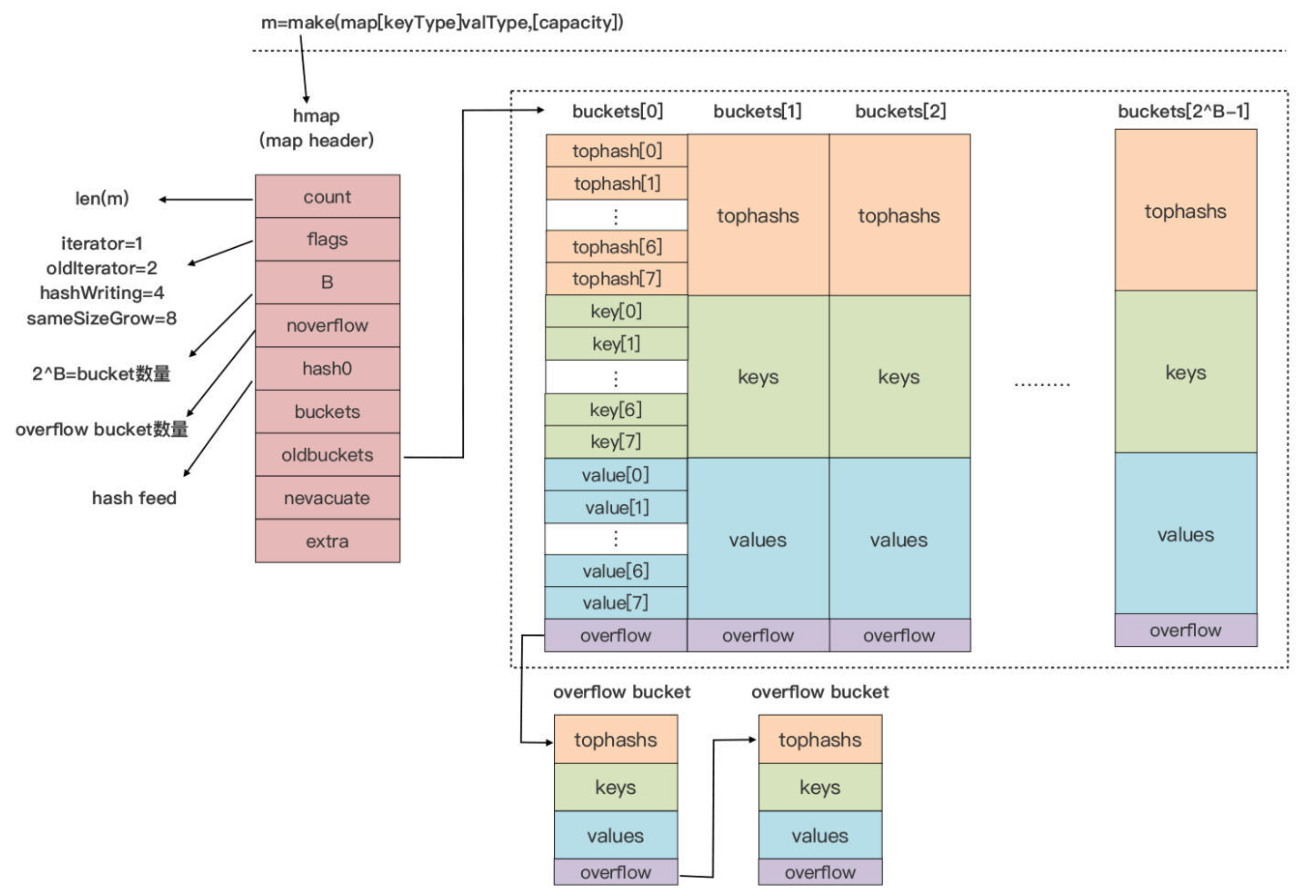
hmap
与语法层面
map类型变量对应的runtime.hmap的实例
hmap类型是map类型的头部结构,即变量传递时的描述符(实际的传递开销)
| Field | Desc |
|---|---|
| count | 当前 map 中的元素个数,使用 len 函数,返回 count 值 |
| flags | 当前 map 所处的状态标志iterator、oldlterator、hashWriting、sameSizeGrow |
| B | 2 ^ B = bucket 数量 |
| noverflow | overflow bucket 的大约数量 |
| hash0 | 哈希函数的种子 |
| buckets | 指向 bucket 数组的指针 |
| oldbuckets | 在 map 扩容阶段指向前一个 bucket 数组的指针 |
| nevacuate | 在 map 扩容阶段的扩容进度计数器所有下标 小于 nevacuate 的 bucket 都已经完成了数据排空和迁移操作 |
| extra | 如果存在 overflow bucket,且 Key 和 Value 都因不包含指针而被内联的情况下,该字段将存储所有指向 overflow bucket 的指针,保证 overflow bucket 不会被 GC 掉 |
1 | // A header for a Go map. |
1 | // mapextra holds fields that are not present on all maps. |
bucket
真正
存储键值对数据的是 bucket
每个 bucket 中存储的是 Hash 值
低 bit 位数值相同的元素,默认的元素个数为BUCKETSIZE- 8 = 2^3
1 | const ( |
1 | const ( |
- 当某个 bucket 的
8个 slot 都填满了,且 map 尚未达到扩容的条件,Runtime会建立overflow bucket - 并将这个
overflow bucket挂在上面 bucket 末尾的overflow 指针上 - 这样多个 bucket 就形成了一个
链表,直到下一次 map扩容
tophash
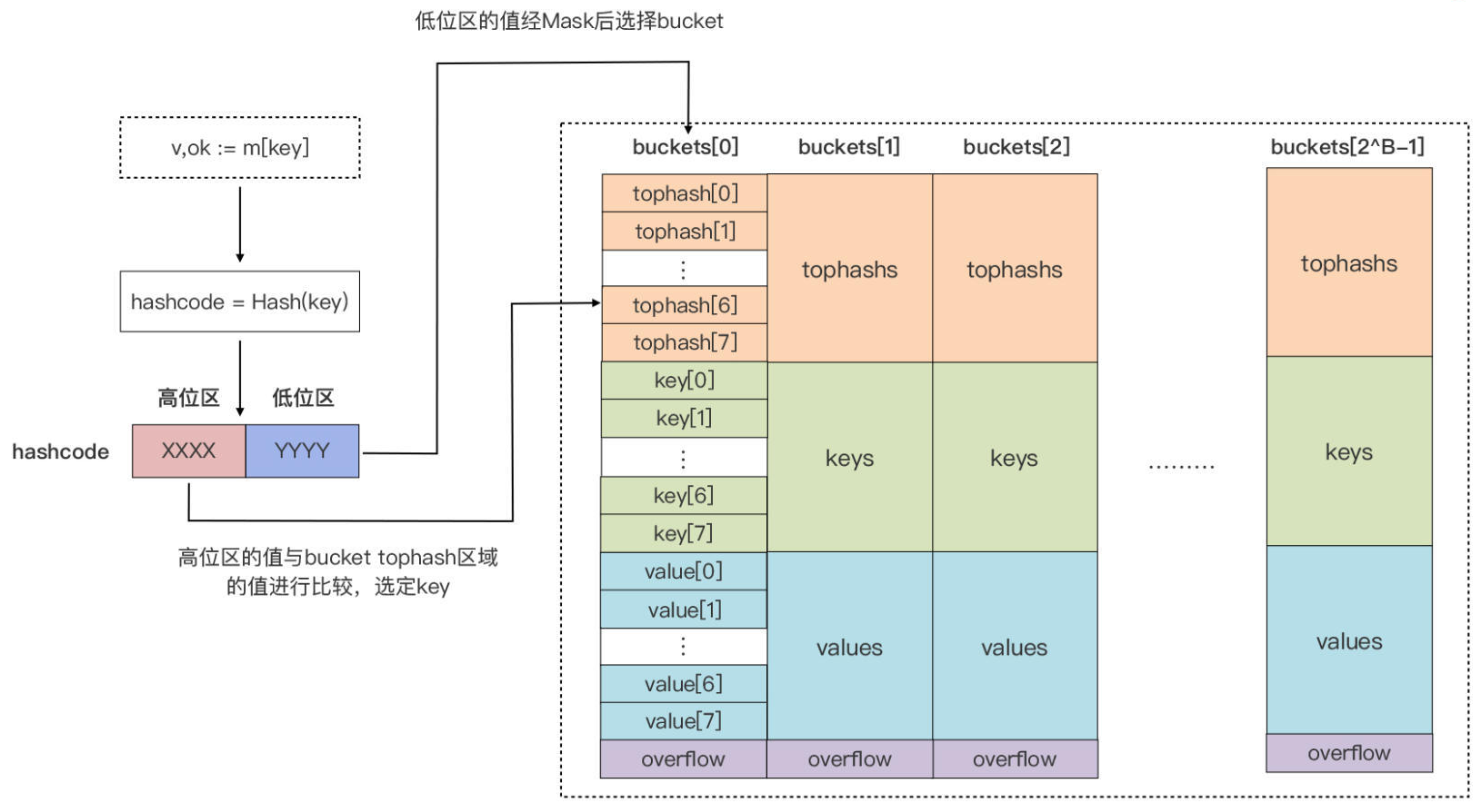
- 向 map 插入数据或者从 map 按 key 查询数据
Runtime都会使用哈希函数对 key 做哈希运算,并得到一个hashcode
hashcode的低位区用于选定bucket,而hashcode的高位区用于在某个 bucket 中确定 key 的位置- 每个 bucket 的 tophash 用来
快速定位 key 的位置,避免逐个key 比较(代价很大) -以空间换时间
key
- 存储这个 bucket 承载的所有 key 数据
Runtime在分配 bucket 时需要知道key size
当
声明一个 map 类型变量Runtime会为这个变量对应的特定 map 类型,生成一个runtime.maptype实例(已存在则复用)
该runtime.maptype实例包含了该 map 类型中所有元数据
1 | type maptype struct { |
Runtime通过runtime.maptype实例确定Key 的类型和大小
runtime.maptype使得所有 map 类型都共享一套 runtime map 的操作函数
value
- 存储 key 对应的 value
- 与 key 一样,该区域的创建也借助了
runtime.maptype中的信息
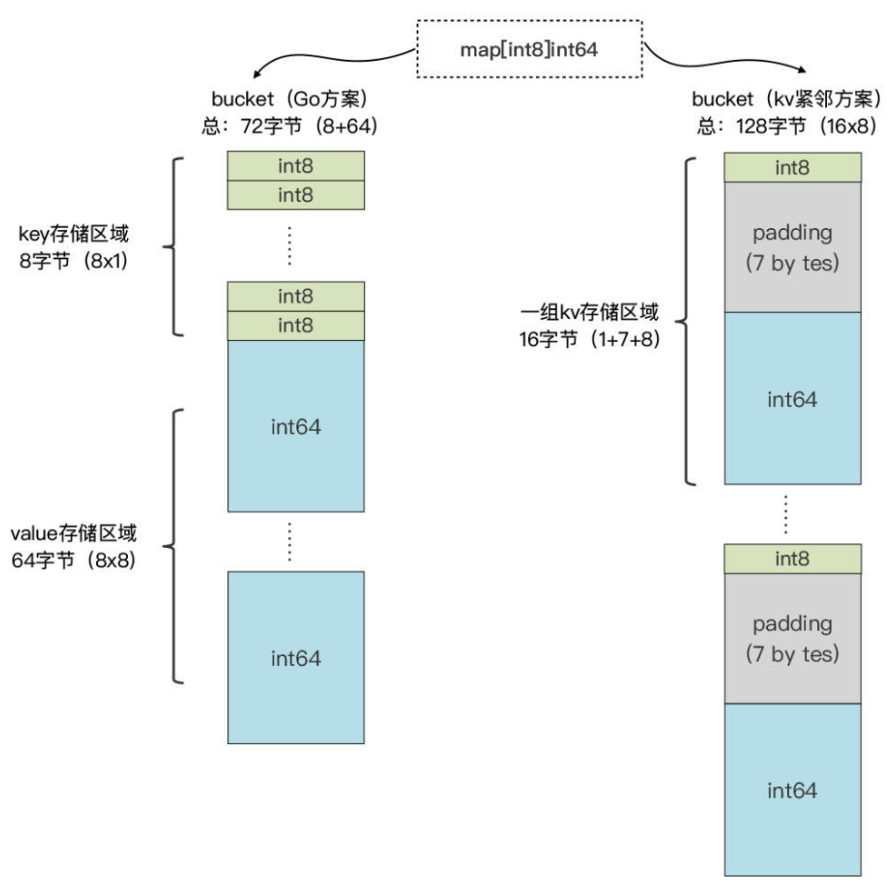
Runtime 将 Key 和 Value
分开存储,而不是采用kv-kv的紧邻方式存储
- 增加了
算法复杂性 - 减少因
内存对齐带来的内存浪费
Go Runtime 的内存利用率很高
如果 Key 或者 Value 的数据长度超过了
128,那么Runtime不会在 bucket 中直接存储数据,而是存储数据的指针
1 | const ( |
扩容
当
count > LoadFactor * 2 ^ B或者overflow bucket过多时,Runtime会对 map 进行自动扩容
6.5 / 8 =
0.8125
1 | const ( |
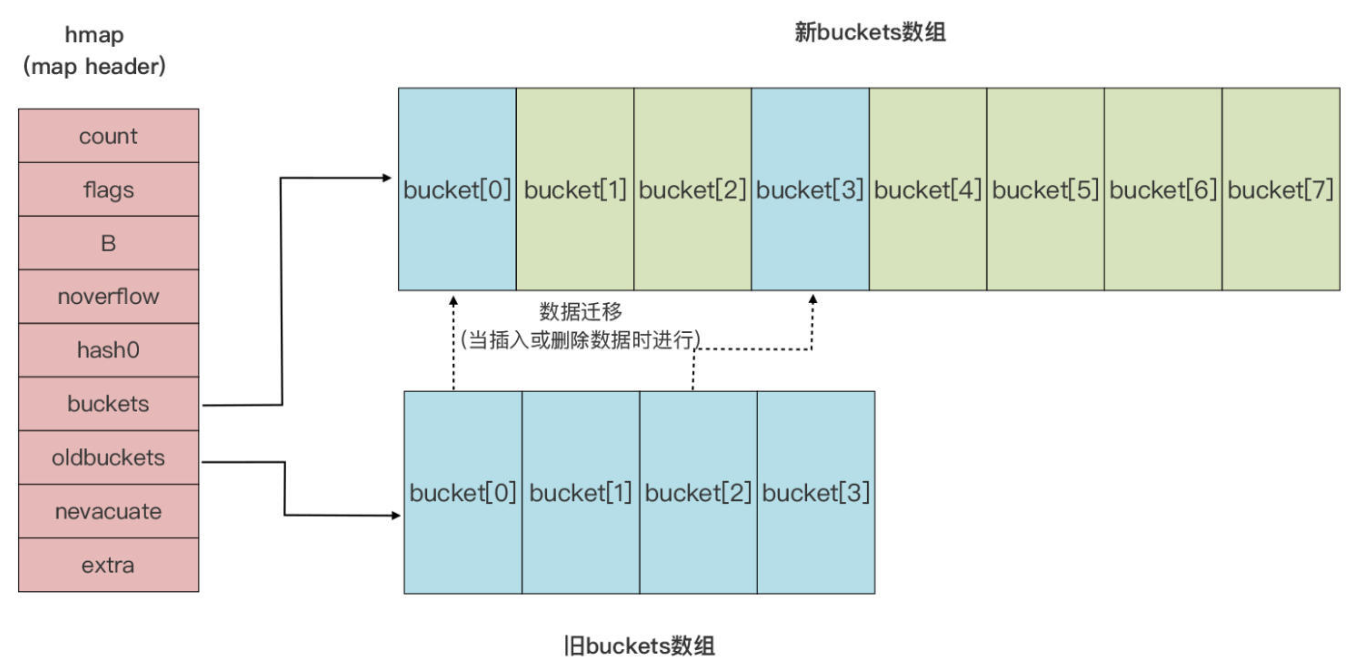
由于
overflow bucket过多导致的扩容 -分配不均
- Runtime 会新建一个与现有规模
一样的 bucket 数组 - 然后在
assign和delete时做排空和迁移
由于当前数据量超过
LoadFactor指定水位而导致的扩容 -容量不足
- Runtime 会新建一个
两倍于现有规模的 bucket 数组 - 但真正的排空和迁移工作,也是在
assign和delete时逐步进行 - 原 bucket 数组会挂在
hmap的oldbuckets指针下- 直到原 bucket 数组中所有的数据都迁移到新数组,原 bucket 数组才会被释放
map 可以自动扩容,
value 的位置可能会发生变化,因此不允许获取map value的地址,编译阶段就会报错
1 | m := make(map[string]int) |
并发
- 充当 map 描述符的 hmap 实例本身是
有状态的(hmap.flags),而且对状态的读写是没有并发保护 - 即 map 实例并
不是并发安全的,也不支持并发读写
并发读写
1 | func read(m map[int]int) { |
只是并发读
1 | func read(m map[int]int) { |