
LLM - ChatGPT
Timeline

- OpenAI 在
NLP领域取得了突破性进展 - ChatGPT 背后包含了一系列的资源整合 - 技术、资源、大厂背书、国际巨头的通力合作 - 工程 + 产品
NLP
Transformer
基于 Transformer 架构的
语言模型大体可分为两类
- 以
BERT为代表的掩码语言模型 -Masked Language Model- MLM - 以
GPT为代表的自回归语言模型 -Autoregressive Language Mode- ALM
OpenAI
- 创造造福全人类的安全通用人工智能 -
Artificial general intelligence- AGI - 创立之初就摒弃了传统 AI
模型标注式的训练方式- 可用来标注的数据总是
有限的,而且很难做得非常通用
- 可用来标注的数据总是
Autoregressive
基于
自回归的无监督训练
- BERT 由 Google 发布,非常权威,GPT 早期压力巨大 -
GPT-2引入了zero-shot - 按照人类语言的习惯,语言本身是有
先后顺序的,下文依赖上文- 自回归语言模型代表了标准的语言模型 -
利用上文信息预测下文 - 比传统 AI 预测
更加复杂,但上限更高,有望通向AGI
- 自回归语言模型代表了标准的语言模型 -
- 在 GPT-1 和 GPT-2 的探索中没有取得压倒性的效果
- 但验证了
标准语言模型在zero-shot等当面的潜在能力
- 但验证了
无监督自回归的训练方式,使 GPT 模型可以接受大量文本数据- GPT-3 的参数规模为
1750 亿,使用了大约45 TB的文本数据,一次训练费用为460 万美元
- GPT-3 的参数规模为
- GPT-3 还不具备直接和人类对话的能力,而
ChatGPT所使用的模型为GPT-3.5
Alignment
与人类意识对齐
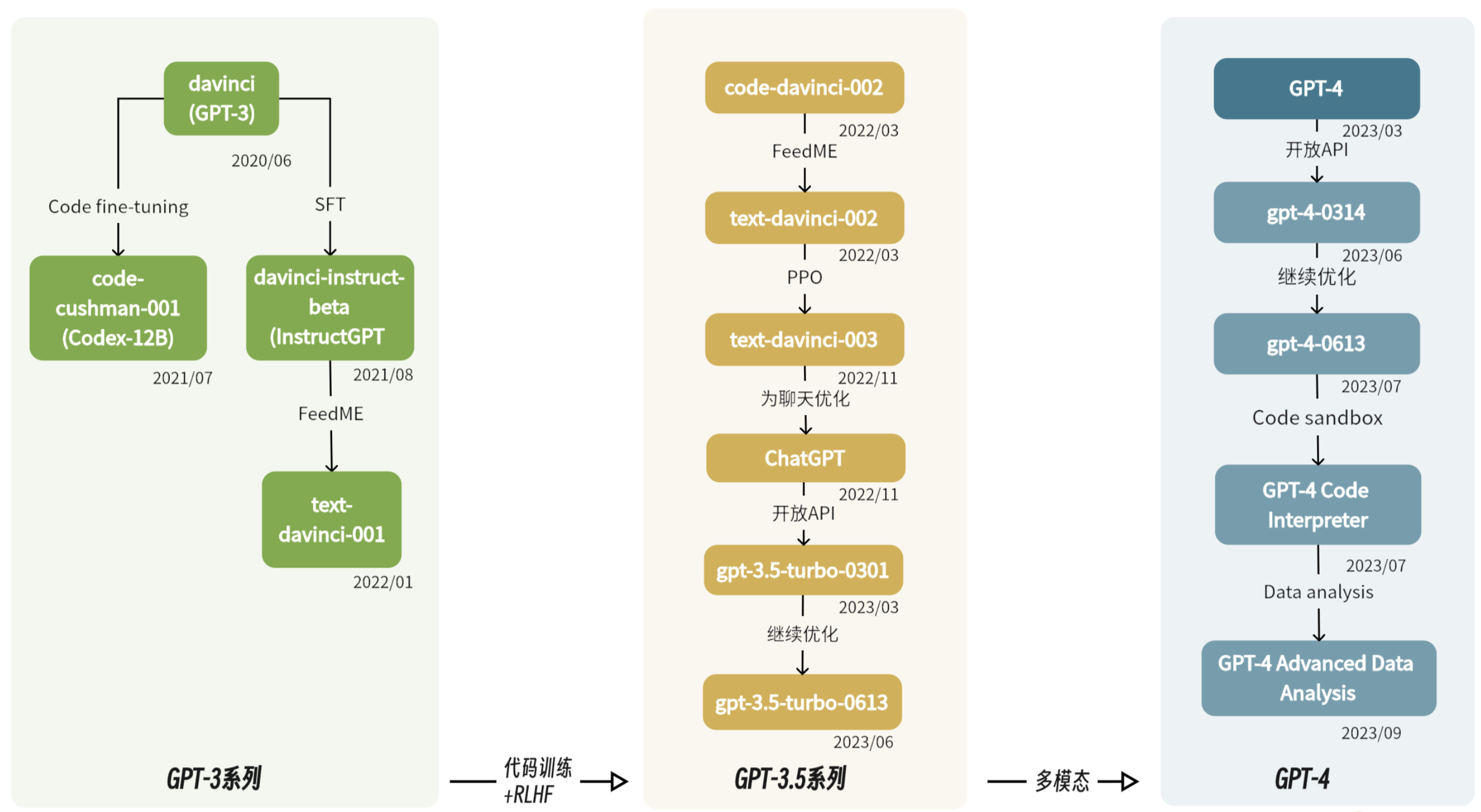
- GPT-3 和 GPT-3.5 是不同的系列
GPT-3经过充分训练,但依然不是一个适合与人类进行对话的模型- 从 GPT-3 到 GPT-3.5 再到 InstructGPT 和 ChatGPT,
参数规模并没有太大变化,主要是经历了各种技术的微调- 适配
人类场景 - RLHF - Reinforcement Learning From Human Feedback
- 适配
Emergent Ability
突现能力- 大语言模型展现出来的特有的强大能力 - 复杂推理 + 思维链 - NLP 领域所追求
1 | 问题:小明每天早饭吃2个馒头,他一个月会吃掉多少包馒头? |
- 语言和数学混在一起,在早期
GPT-3模型上进行类型的推理,准确率低于40% - 后来在
code-davinci-002上进行推理,准确率能达到80%code-davinci-002在模型规模上并没有扩大,而是基于代码进行训练的- 这些突现能力是大模型经过
大量代码训练后展现出来的能力 代码训练和思维链及复杂推理有很强的相关性 - 暂无确定证据
小结
- 模型
并非越大越好- GPT-3 的参数规模为 1750 亿
- 微软与英伟达联合开发的 Megatron-Turing 模型拥有超过 5000 个参数
- 但在性能方面却不是最好的,因为模型未经过充分训练
RLHF并不是最早用在 GPT 上,而且在恰当的时机用到了 ChatGPT 上- 只有 codex 使用了大量代码进行训练
自回归语言模型 + 充分无监督训练 + 大量代码训练 + 有监督指令微调+RLHF
超大规模预训练
超过 40T 的文本数据,
大模型训练首先需要高质量的数据集
数据集
GPT-3
基础模型 GPT-3 具有
1750亿个参数,训练数据集大约500B个 Token
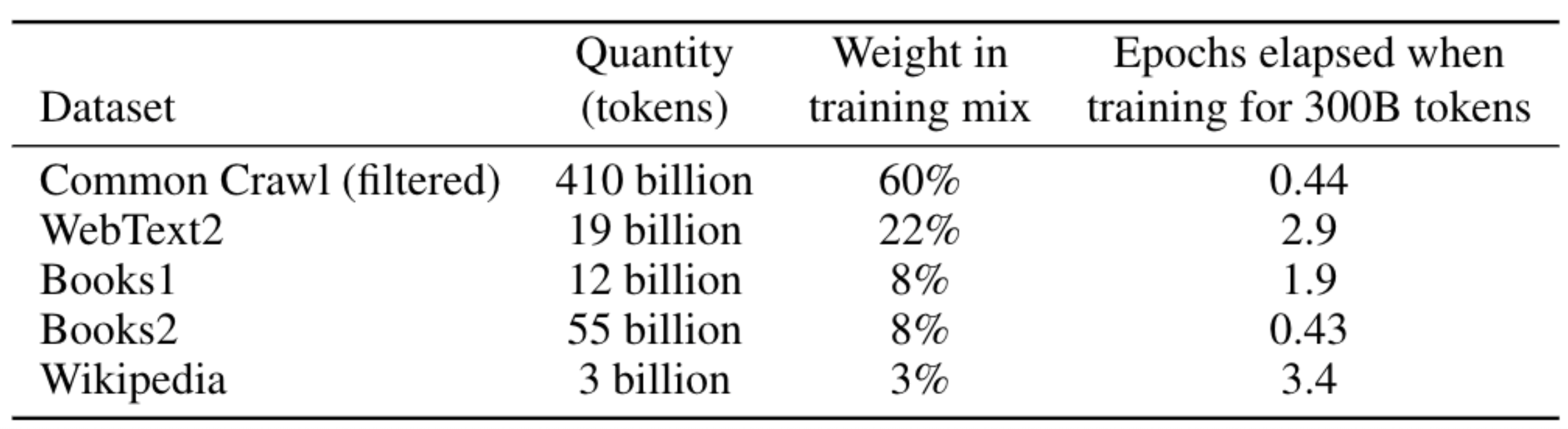
原始大约 45T 的纯文本数据,经过
过滤后,大概是 750G 的高质量文本数据
ChatGPT
- ChatGPT 属于 GPT-3.5 系列
- 大概率上,ChatGPT 的参数规模要
小于GPT-3,其训练数据基于大量对话型数据进行指令微调- 典型数据集 - Persona-Chat 的数据集、康奈尔电影对话语料库、Ubuntu 对话语料库、DailyDialog
- 互联网上大量
非结构化数据的训练 - 网站、书籍、其它文本源- ChatGPT 能够从更一般的意义上了解语言的
结构和模式,然后可以针对对话管理或者情感分析等特定应用进行微调
- ChatGPT 能够从更一般的意义上了解语言的
训练成本
- GPT-3 的单次训练成本高达 460 万美元,为了
找钱,OpenAI 从开源转为了闭源 - 早期的 OpenAI 是开源的,创办宗旨为创建
通用人工智能 - 为了引入资金,OpenAI 从开源转为闭源,设计了一种
商业模式来吸引投资人,最主要为微软
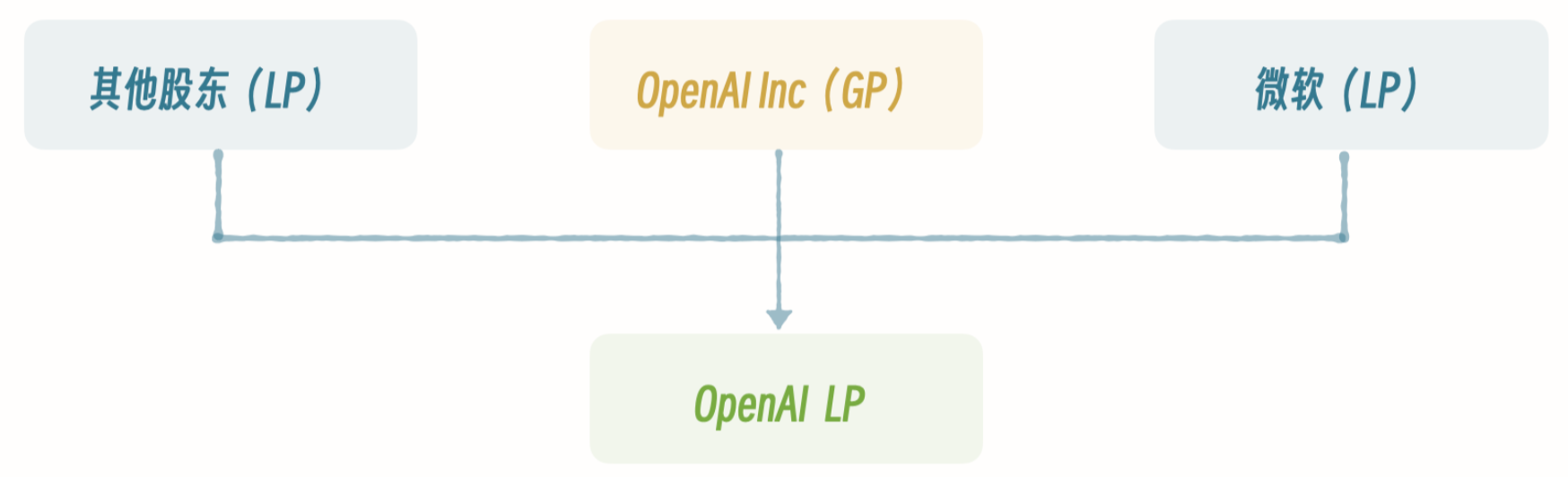
- OpenAI 的母公司为
OpenAI Inc- 为非营利性组织 - 后来成立一家子公司,
OpenAI LP,即常说的OpenAI- 为一家纯粹的商业化公司,设置了最高100倍的回报上限
产品化
- ChatGPT 在真正
产品化后愿意公开免费给普通用户使用 - 大部分的 AI 厂家只
发布模型,技术人员去Huggingface下载然后部署,但这样会将模型限制在一个非常小的范围 - ChatGPT 发布的是
普通大众用户都可以使用的产品(使用门槛非常低) - 邮箱注册 + 全天候不限时 + 网页对话
优点
- 适用场景多
- 代码编写、代码翻译、智能问答、语言识别等
- 使用效果好
- 微软小冰由
小模型组成,只能同时处理特定类型的任务,无法相互关联,此类产品无法做通用性回答 - ChatGPT 像
真人在回答,甚至有记忆和感情
- 微软小冰由
- 工程化应用
- ChatGPT 是以
大模型为内核的整套技术完成了产品化- 两个月注册用户过亿的世界级产品
- ChatGPT 是以
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-08-11
RAG - KG-RAG
Knowledge Graph 知识图谱也称为语义网络,表示现实世界实体的网络,并说明它们之间的关系 信息通常存储在图形数据库中,并以图形结构直观呈现 知识图谱由三部分组成 - 节点 + 边 + 标签 Why 降噪 + 提召 + 提准 传统 RAG 中的 Chunking 方式会召回一些噪音的 Chunk 引入 KG,可以通过实体层级特征来增强相关性 传统 RAG 中的 Chunk 之间是彼此孤立的,缺乏关联,在跨文档回答任务上表现不太好 引入 KG,增强 Chunk 之间的关联,并提升召回的相关性 假设已有 KG 数据存在,可以将 KG 作为一路召回信息源,补充上下文信息 Chunk 之间形成的 KG,可以提供 Graph 视角的 Embedding,来补充召回特征 构建一个高质量、灵活更新、计算简单的大规模图谱的代价很高 - RAG 会很慢 https://hub.baai.ac.cn/view/30017 https://hub.baai.ac.cn/view/33147 https://hub.baai.ac.cn/view/33390 https://hub.baa...
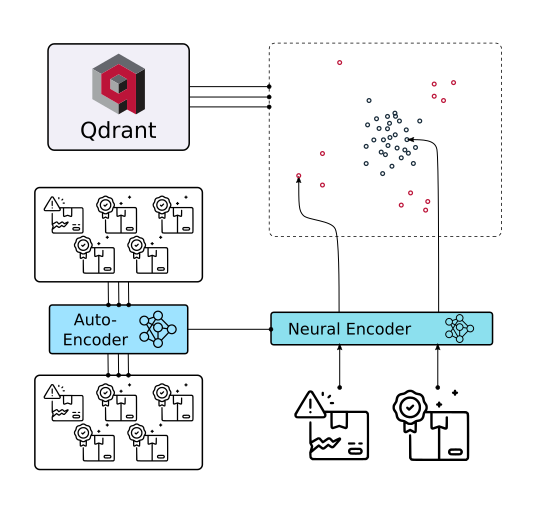
2024-09-09
RAG - Qdrant
Features Getting StartedIntroduction Vector databases are a relatively new way for interacting with abstract data representations derived from opaque machine learning models such as deep learning architectures. These representations are often called vectors or embeddings and they are a compressed version of the data used to train a machine learning model to accomplish a task like sentiment analysis, speech recognition, object detection, and many others. What is Qdrant? Qdrant “is a vector similarity s...
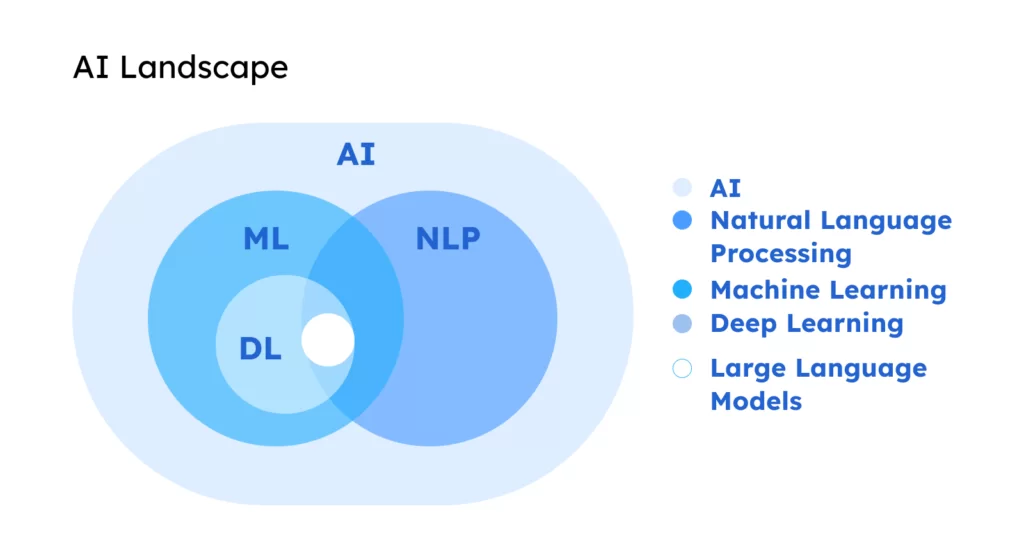
2024-07-02
LLM Core - Machine Learning Concept
机器学习 机器学习是让计算机利用数据来学习如何完成任务 机器学习允许计算机通过分析和学习数据来自我改进以及作出决策 房价预测 利用 scikit-learn 进行预测 数据集 housing_data.csv 面积 卧室数量 地理位置 售价 100 2 1 300 150 3 2 450 120 2 2 350 80 1 1 220 线性回归12345678910111213141516171819202122232425from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionimport pandas as pd# 加载数据集data = pd.read_csv("housing_data.csv") # 假设这是我们的房屋数据# 准备数据X = data[['面积', '卧室数量', '地理位置']] # 特征y = data[...
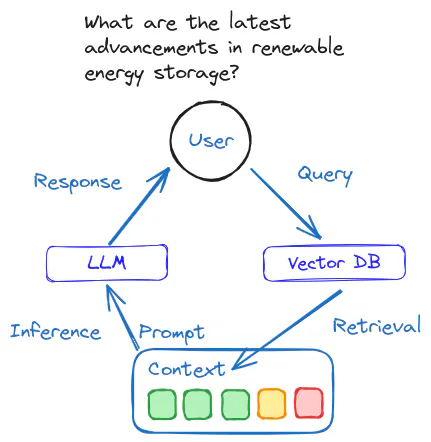
2024-08-01
RAG - AI 2.0
AI 技术 做 AI 产品的工程研发需充分掌握 AI 技术 AI 产品从 MVP 到 PMF 的演进过程中会面临非常多的挑战 MVP - Minimum Viable Product - 最小可用产品 PMF - Product-Market Fit - 产品市场契合 要实现 AI 产品的 PMF 首先需要充分了解 AI 技术,明确技术边界,找到合适 AI 技术的应用场景 其次,需要深刻理解业务,用户需求决定产品方向,AI 技术是为业务服务的工具 在验证阶段,优先使用最佳 AI 模型以确保产品满足市场需求,确认后再逐步降低模型成本 坚持业务优先、价值至上的原则,避免纯 AI 科研化,脱离实际场景做 AI 技术选型 RAG LLM 局限 - 幻觉 + 知识实效性 + 领域知识不足 + 数据安全问题 由 OpenAI ChatGPT 引领的 AI 2.0 LLM 时代,见证了 LLM 在知识、逻辑、推理能力上的突破 Scaling Law、压缩产生智能、边际成本为零为理想中的 AGI 尽管 LLM 功能强大,但仍存在幻觉、知识实效性、领域知识不足以及数据安全问题的局限性 - RAG 文档问...
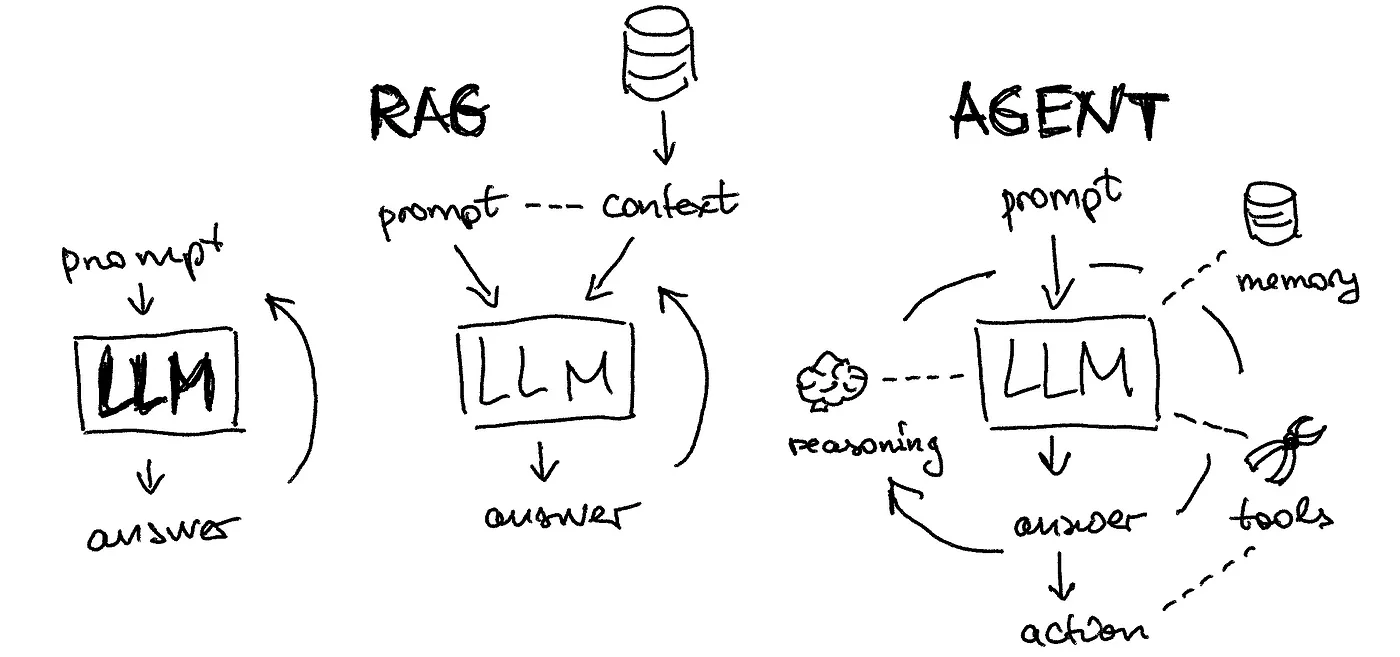
2024-08-04
RAG - LangChain
Practice LangChain RAG https://github.com/langchain-ai/rag-from-scratch RAG 如何随着长期 LLM 而改变 Is RAG Really Dead? https://www.youtube.com/watch?v=SsHUNfhF32s 自适应 RAG 根据复杂程度动态地将查询路由到不同的 RAG 方法 - Command-R @ LangGraph Adaptive RAG https://www.youtube.com/watch?v=04ighIjMcAI Code https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_adaptive_rag_cohere.ipynb Paper https://arxiv.org/abs/2403.14403 Adaptive RAG 在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索 在 LangGraph 中实现 Mistral 7B + Ol...
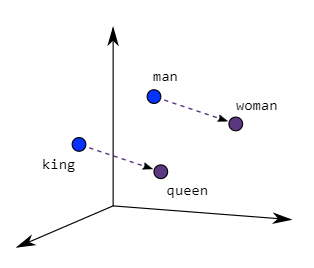
2024-07-06
LLM Core - Word2Vec
Word2Vec概述 在 NLP 中,在文本预处理后,进行特征提取,涉及到将词语转化成数值的形式,方便计算机理解 Word2Vec 的目的 - 将词语转换成向量形式,使得计算机能够理解 通过学习大量文本数据,捕捉到词语之间的上下文关系,进而生成词的高维表示 - 即词向量 架构 Word2Vec 有 2 种主要的模型 - Skip-Gram + CBOW Model Desc CBOW 根据周围的上下文词汇来预测目标词 Skip-Gram 根据目标词预测其周围的上下文词汇 优劣 Key Value 优点 揭示词与词之间的相似性 - 通过计算向量之间的距离来找到语义相近的词 缺点 无法处理多义词,每个词被赋予一个向量,不考虑上下文中的多种含义 模型架构 连续词袋 - Continuous Bag of Words, CBOW跳字模型 - Skip-Gram 连续词袋 CBOW 模型是一种通过上下文预测目标词的神经网络架构 上下文由目标词周围的一个词或多个词组成,这个数目由窗口大小决定 窗口是指上下文词语的范围 - 如果窗口为 10,那么模型将使用目标词前后各...




