
LLM PEFT - ChatGLM3-6B + LoRA
通用 LLM
千亿大模型(130B、ChatGPT)和小规模的大模型(6B、LLaMA2)都是通用 LLM
- 通用 LLM 都是通过常识进行预训练的
- 在实际使用过程中,需要 LLM 具备某一特定领域知识的能力 - 对 LLM 的能力进行增强
增强方式
| Method | Desc |
|---|---|
| 微调 | 让预先训练好的 LLM 适应特定任务或数据集的方案,成本相对低 LLM 学会训练者提供的微调数据,并具备一定的理解能力 |
| 知识库 | 使用向量数据库或者其它数据库存储数据,为 LLM 提供信息来源外挂 |
| API | 与知识库类似,为 LLM 提供信息来源外挂 |
互不冲突,可以同时使用几种方案来优化 LLM,提升内容输出能力
LoRA / QLoRA / 知识库 / API
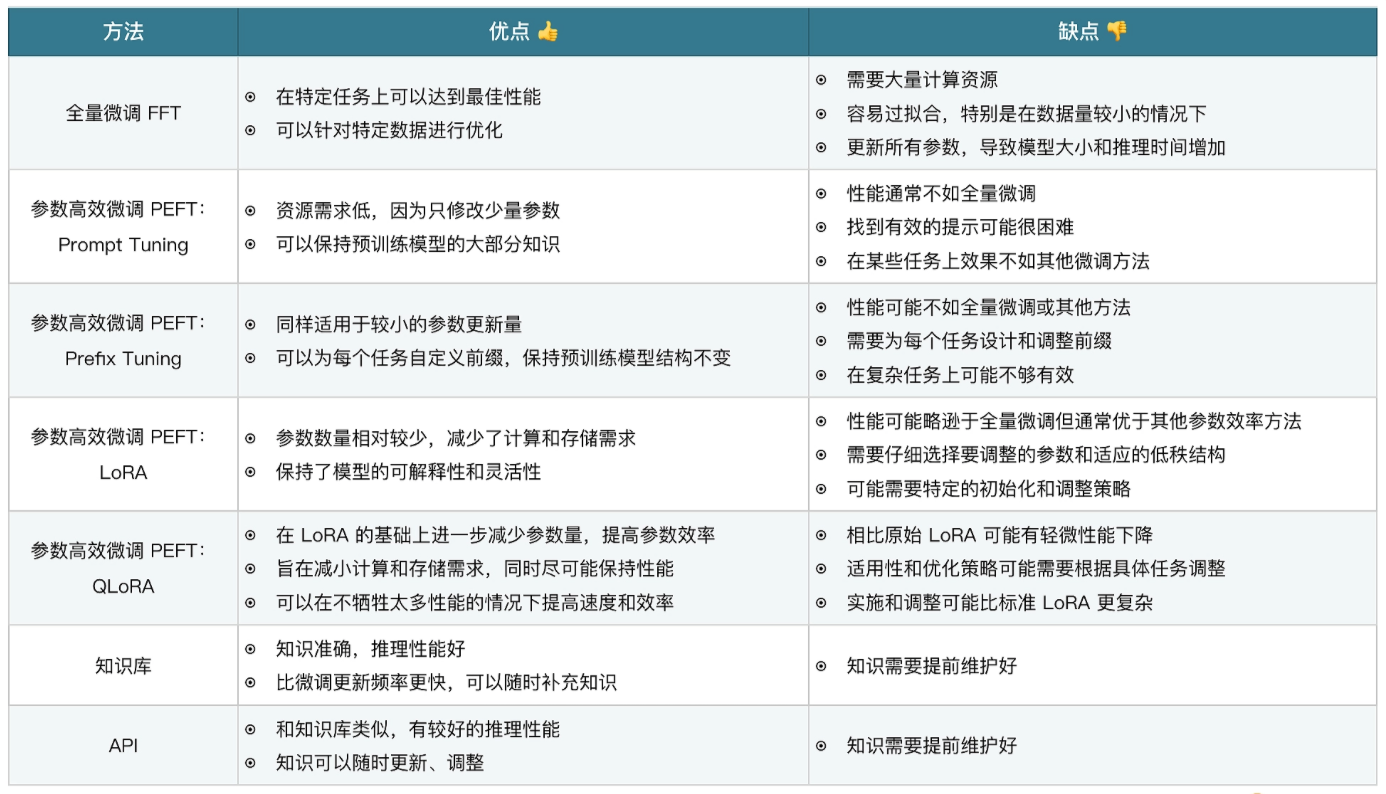
LLM Performance = 推理效果
落地过程
| Method | Pipeline |
|---|---|
| 微调 | 准备数据 -> 微调 -> 验证 -> 提供服务 |
| 知识库 | 准备数据 -> 构建向量库 -> 构建智能体 -> 提供服务 |
| API | 准备数据 -> 开发接口 -> 构建智能体 -> 提供服务 |
需求分析
法律小助手用来解决日常生活中遇到的法律问题,以问答的方式进行 - 知识库 or 微调
知识库
一旦数据集不足,可以随时补充,即时生效
- 将数据集拆分成一条一条的知识,放入到向量库
- 然后通过 Agent 从向量库检索,在输入给 LLM
微调
- 法律知识有时候需要一定的逻辑能力,不是纯文本检索
- 微调 - 通过在一定量的数据集上的训练,增加 LLM 法律相关的常识及思维,从而进行推理
准备数据
原始数据
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/lawzhidao/intro.ipynb
| 字段 | 说明 |
|---|---|
| title | 问题的标题 |
| question | 问题内容(可为空) |
| reply | 回复内容 |
| is_best | 是否为页面上显示的最佳回答 |
微调数据
1 | { |
让 ChatGPT 生成转换代码
1 | 原始数据是CSV格式,包含4列:title、question、reply、is_best,需要通过Python语言处理该CSV文件,来构建大语言模型的微调数据集,目标数据集格式是JSON的,单条数据格式为:{"conversations":[{"role":"user","content":"value1"},{"role":"assistant","content":"value2"}]},需要将原始CSV文件里的title列填充到目标JSON文件里的value1处,原始CSV文件里的reply填充到目标JSON文件里的value1处,请注意:最终生成的不是JSON数组,而是每个JSON对象生成一行,出示示例代码。 |
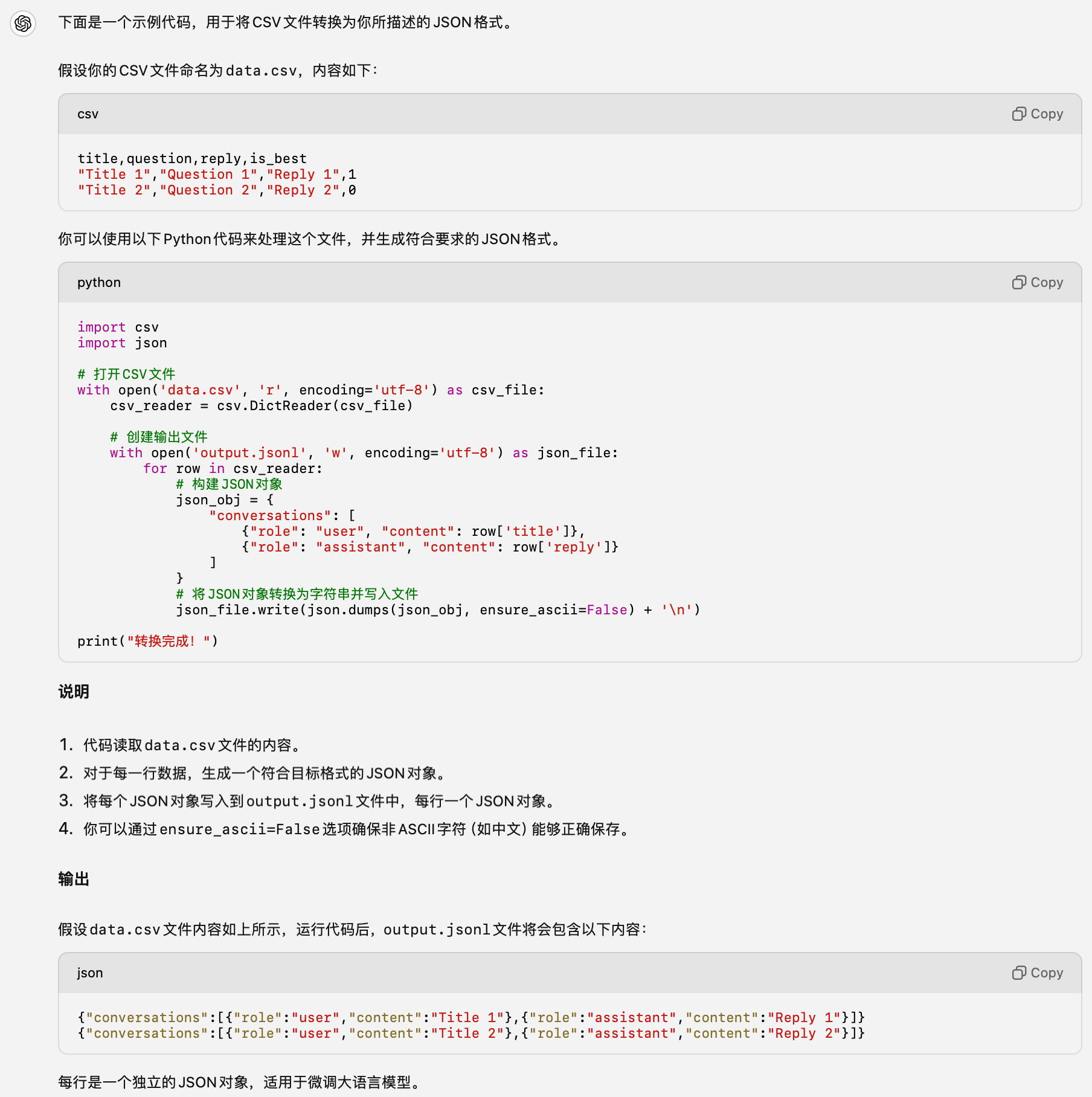
微调
依赖
1 | $ sudo apt install libopenmpi-dev |
数据
- 训练需要至少准备两个数据集,一个用来训练,一个用来验证
- train.json 与 dev.json 格式相同
- 当 LLM 在训练过程中,会自动进行测试验证,输出微调效果
1 | $ tree data/ |
配置
configs/lora.yaml
1 | data_config: |
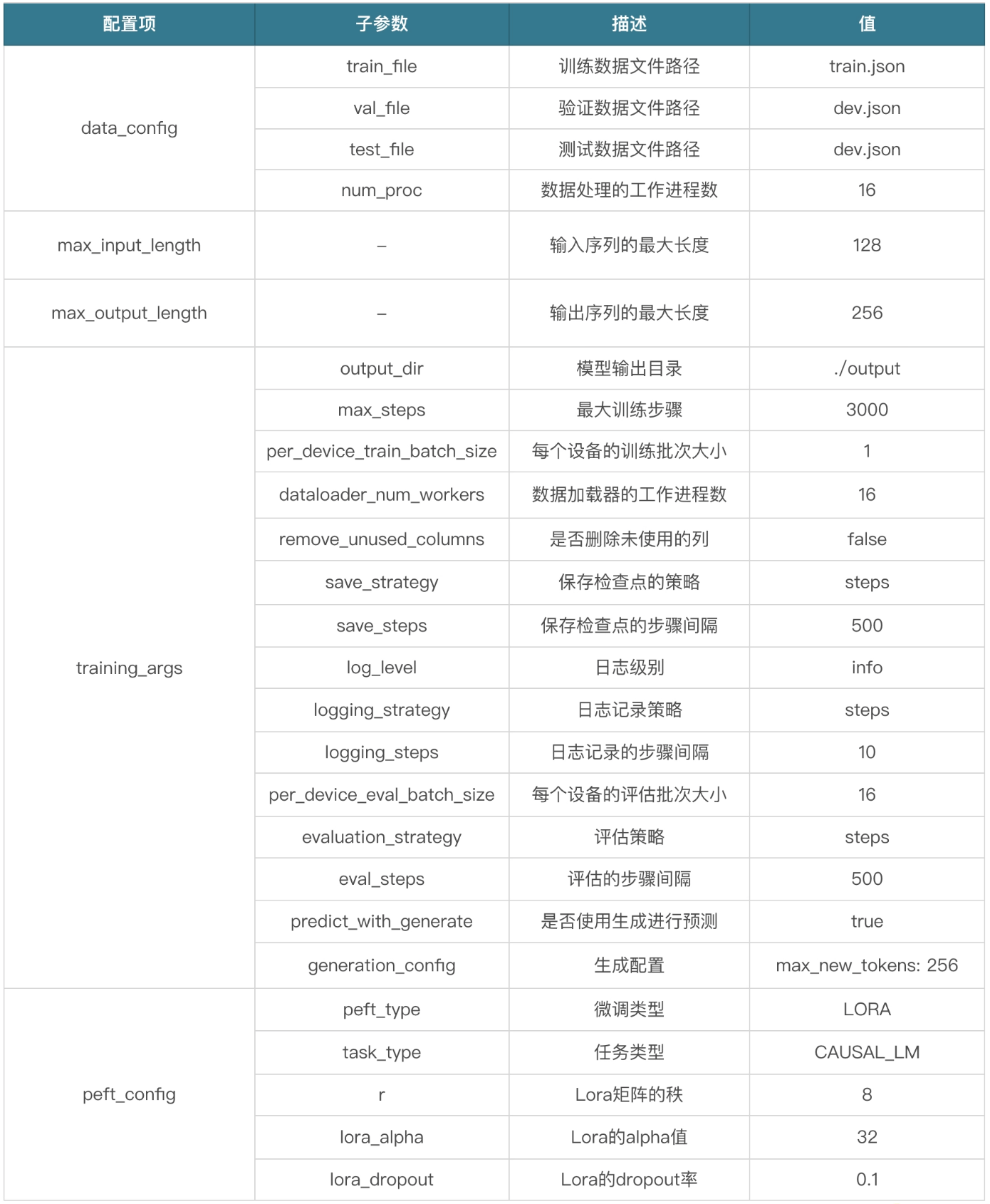
微调
| Parameter | Desc |
|---|---|
| 训练数据集所在的目录 | data |
| 模型所在目录 | ../model |
| 微调配置 | configs/lora.yaml |
1 | $ python3 finetune_hf.py data ../model/ configs/lora.yaml |
trainable params 为 1.9M,整个参数量为 6B,训练比为 3%
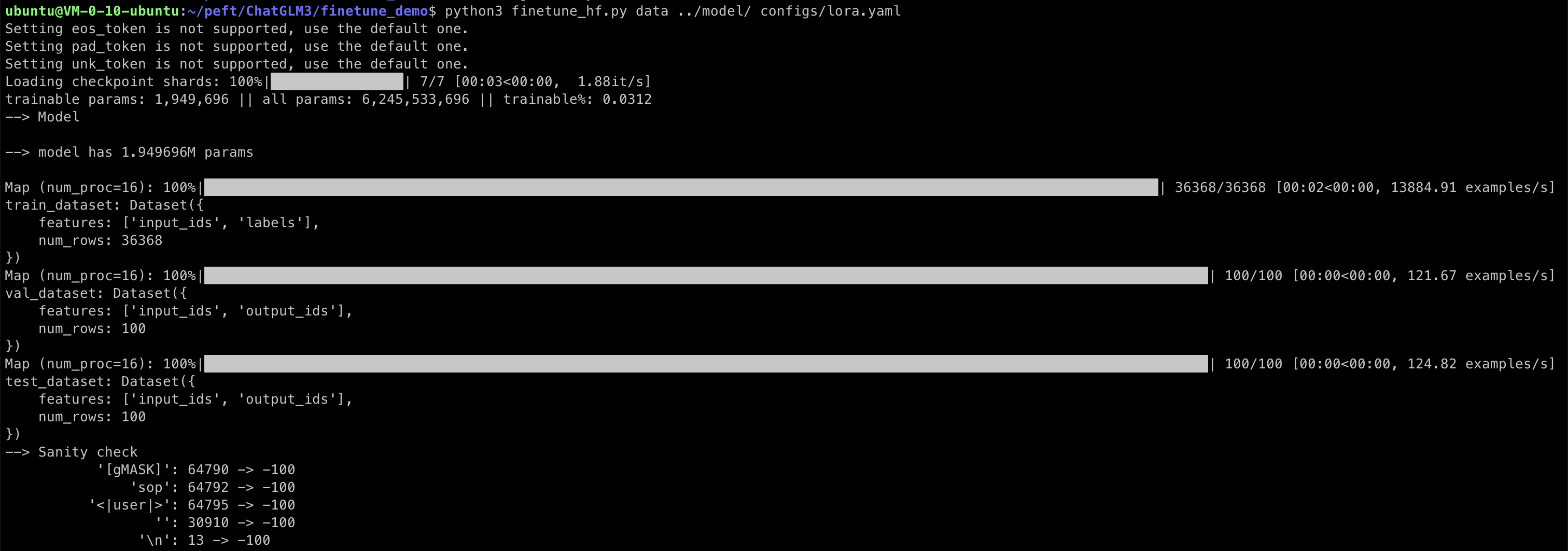
- trainable params 指的是在模型训练过程中可以被优化或更新的参数数量
- 在深度学习模型中,这些参数通常是网络的权重和偏置
- 它们是可训练的
- 因为在训练过程中,通过反向传播算法,这些参数会根据损失函数的梯度不断更新
- 以减少模型输出与真实标签之间的差异
- 通过调整 lora.yaml 中的 peft_config 的 r 参数来改变可训练参数的数量
- r 越大,trainable params 就越大
- r - LoRA 矩阵的秩
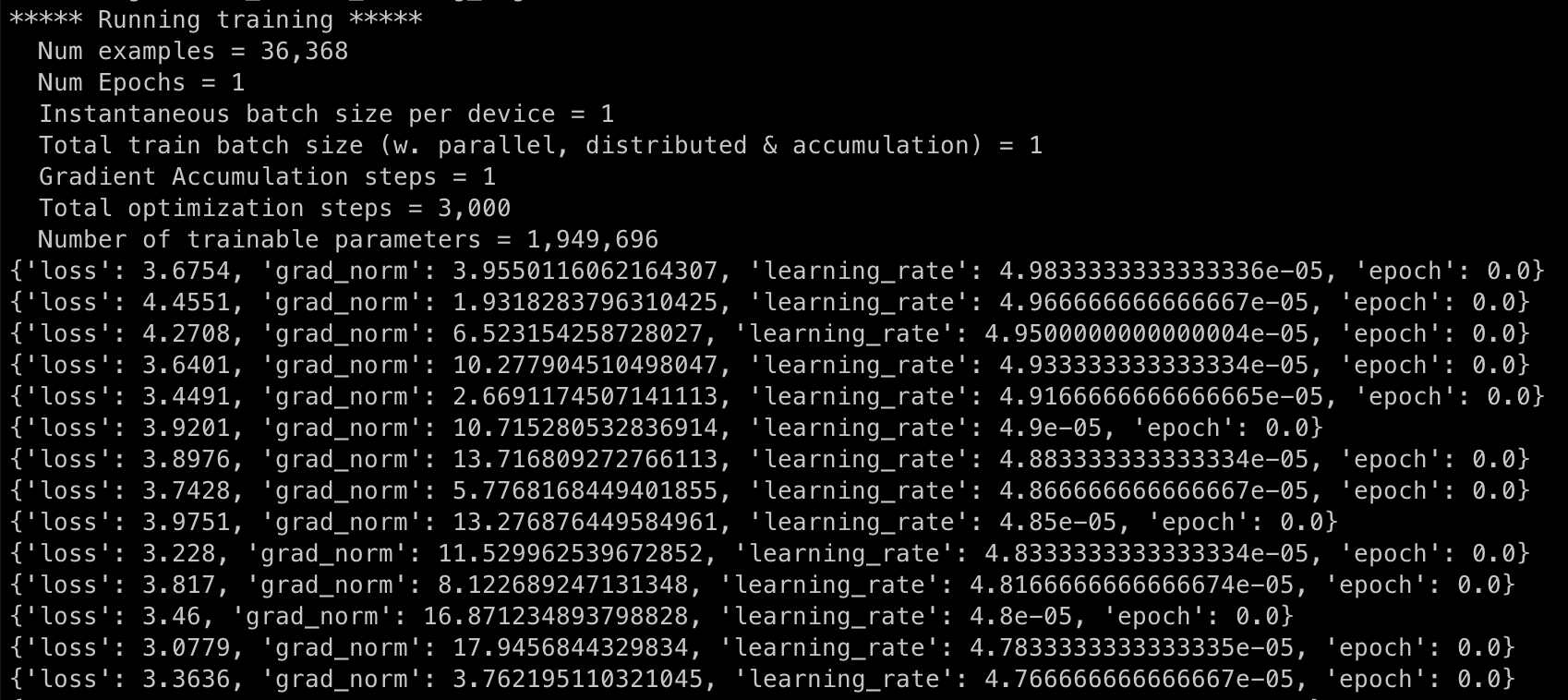

loss
- 损失函数衡量模型预测的输出与实际数据之间的差异
- 在训练过程中,目标是最小化该损失值,从而提高模型的准确性
grad_norm
梯度范数 - 参数更新幅度
- 在训练深度学习模型时,通过反向传播算法计算参数的梯度,以便更新这些参数
- 梯度范数是这些梯度向量的大小或者长度,提供了关于参数更新幅度的信息
- 如果梯度范数非常大,可能表示模型在训练过程中遇到了梯度爆炸问题
- 如果梯度范数太小,可能表示梯度消失问题
learning_rate
学习率 - 控制参数更新幅度的超参数
- 在优化算法中,学习率决定了在反向传播期间参数更新的步长大小
- 学习率太高,会导致训练过程不稳定
- 学习率太低,会导致训练进展缓慢或者陷入局部最小值
epoch
- epoch - 训练算法在整个训练数据集上的一次完整遍历
- 通常需要多个 epochs 来训练模型,以确保模型能够充分学习数据集中的模式
- 每个 epoch 后,通常会评估模型在验证集上的表现,以监控和调整训练过程

验证
加载
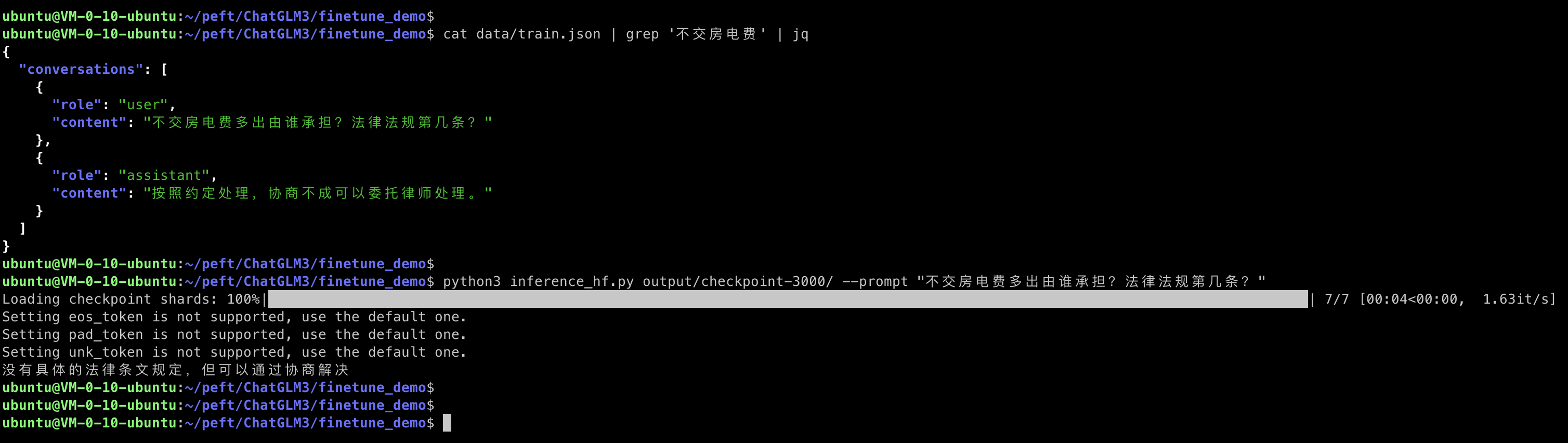
output/checkpoint-3000 - 新生成的权重
模型启动时,会将原模型和新权重全部加载,然后进行推理
1 | $ python3 inference_hf.py output/checkpoint-3000/ --prompt "xxxxxxxxxxxx" |

微调前

微调后
微调数据集中有对应内容,微调效果明显
服务
微调完成后,即验证后得知整体效果满足一定的百分比,可以对外服务
通过 API 组件将模型的输入输出封装成接口对外提供服务
- 模型的推理性能 - 效果
- 模型的推理吞吐量
- 服务的限流,适当保护 LLM 集群
- 当 LLM 服务不可用时,服务降级,开关控制
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-06-27
LLM - LangChain + RAG
局限 大模型的核心能力 - 意图理解 + 文本生成 局限 描述 数据的及时性 大部分 AI 大模型都是预训练的,如果要问一些最新的消息,大模型是不知道的 复杂任务处理 AI 大模型在问答方面表现出色,但不总是能够处理复杂任务AI 大模型主要是基于文本的交互(多模态除外) 代码生成与下载 根据需求描述生成对应的代码,并提供下载链接 - 暂时不支持 与企业应用场景的集成 读取关系型数据库里面的数据,并根据提示进行任务处理 - 暂时不支持 在实际应用过程中,输入数据和输出数据,不仅仅是纯文本 AI Agent - 需要解析用户的输入输出 AI Agent AI Agent 是以 LLM 为核心控制器的一套代理系统 控制端处于核心地位,承担记忆、思考以及决策等基础工作 感知模块负责接收和处理来自于外部环境的多样化信息 - 文字、声音、图片、位置等 行动模块通过生成文本、API 调用、使用工具等方式来执行任务以及改变环境 LangChain - 开源 + 提供一整套围绕 LLM 的 Agent 工具 AI Agent 很有可能在未来一段时间内成为 AI 发展的一...
2024-06-30
LLM RAG - ChatGLM3-6B + LangChain + Faiss
RAG 使用知识库,用来增强 LLM 信息检索的能力 知识准确 先把知识进行向量化,存储到向量数据库中 使用的时候通过向量检索从向量数据库中将知识检索出来,确保知识的准确性 更新频率快 当发现知识库里面的知识不全时,可以随时补充 不需要像微调一样,重新跑微调任务、验证结果、重新部署等 应用场景 ChatOps 知识库模式适用于相对固定的场景做推理 如企业内部使用的员工小助手,不需要太多的逻辑推理 使用知识库模式检索精度高,且可以随时更新 LLM 基础能力 + Agent 进行堆叠,可以产生智能化的效果 LangChain-Chatchat组成模块 模块 作用 支持列表 大语言模型 智能体核心引擎 ChatGLM / Qwen / Baichuan / LLaMa Embedding 模型 文本向量化 m3e-* / bge-* 分词器 按照规则将句子分成短句或者单词 LangChain Text Splitter 向量数据库 向量化数据存储 Faiss / Milvus Agent Tools 调用第三方...

2024-06-28
LLM Deploy - ChatGLM3-6B
LLM 选择核心玩家 厂家很多,但没多少真正在研究技术 - 成本 - 不少厂商是基于 LLaMA 套壳 ChatGLM-6B ChatGLM-6B 和 LLaMA2 是比较热门的开源项目,国产 LLM 是首选 企业布局 LLM 选择 MaaS 服务,调用大厂 LLM API,但会面临数据安全问题 选择开源 LLM,自己微调、部署、为上层应用提供服务 企业一般会选择私有化部署 + 公有云 MaaS 的混合架构 在国产厂商中,从技术角度来看,智谱 AI 是国内 LLM 研发水平最高的厂商 6B 的参数规模为 62 亿,单张 3090 显卡就可以进行微调和推理 企业预算充足(百万以上,GPU 费用 + 商业授权) 可以尝试 GLM-130B,千亿参数规模,推理能力更强 GLM-130B 轻量化后,可以在 3090 × 4 上进行推理 训练 GLM-130B 大概需要 96 台 A100(320G),历时两个多月 计算资源 适合 CPU 计算的 LLM 不多 有些 LLM 可以在 CPU 上进行推理,但需要使用低精度轻量化的 LLM 但在低精度下,LLM 会失真,效果较差 要真正体验并应...
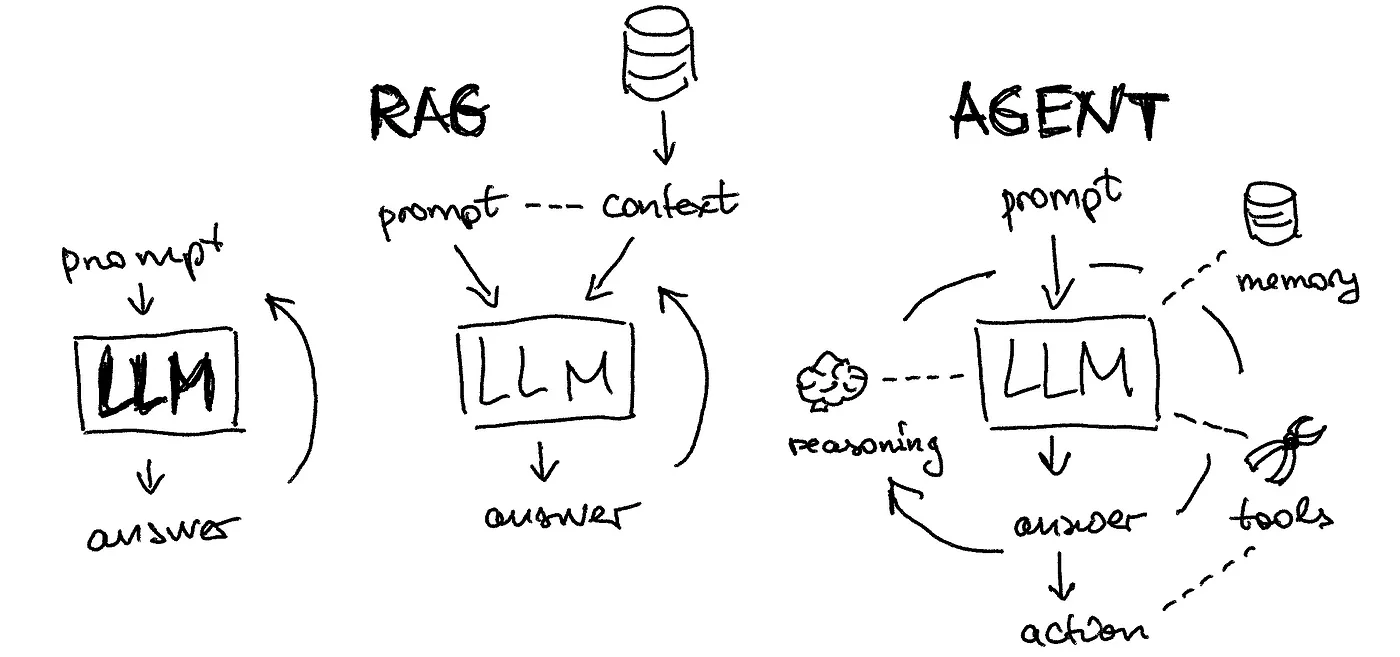
2024-08-04
RAG - LangChain
Practice LangChain RAG https://github.com/langchain-ai/rag-from-scratch RAG 如何随着长期 LLM 而改变 Is RAG Really Dead? https://www.youtube.com/watch?v=SsHUNfhF32s 自适应 RAG 根据复杂程度动态地将查询路由到不同的 RAG 方法 - Command-R @ LangGraph Adaptive RAG https://www.youtube.com/watch?v=04ighIjMcAI Code https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_adaptive_rag_cohere.ipynb Paper https://arxiv.org/abs/2403.14403 Adaptive RAG 在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索 在 LangGraph 中实现 Mistral 7B + Ol...
2024-06-26
LLM - Prompt
Prompt 是否充分使用好 AI 大模型,提示是关键 OpenAI question / answer prompt / completion - 给 LLM 一个提示,让 LLM 进行补全 LLM 训练原理 GPT 系列模型基于 Transformer 架构的解码器机制,使用自回归无监督方式进行预训练 训练过程 - 大量的文本输入,不断进行记忆 相比于监督学习,训练效率更低,但训练过程简单,可以喂大量的文本语料,上限比较高 completion 根据训练过的记忆,一个字一个字地计算概率,取概率最大的那个字进行输出 因此有人吐槽 LLM 输出很慢 - 逐字计算并输出 Prompt Engineering 需求描述越详细越准确,LLM 输出的内容就越符合要求 Prompt Engineering 是一门专门研究与 LLM 交互的新型学科 通过不断地开发和优化,帮助用户更好地了解 LLM 的能力和局限性 探讨如何设计出最佳提示,用于指导 LLM 帮助我们高效完成某项任务 不仅仅是设计和研发提示,还包含了与 LLM 交互的各种技能和技术 在实现与 LLM 交互、...
2024-08-14
RAG - LLM + Prompt Engineering
RAG 生成流程 经过 RAG 索引流程(外部知识的解析和向量化)和 RAG 检索流程(语义相似性的匹配及混合检索),进入到 RAG 生成流程 在 RAG 生成流程中,需要组合指令,即携带查询问题及检索到的相关信息输入的 LLM,由 LLM 理解并生成最终的回复 RAG 的本质是通过 LLM 提供外部知识来增强其理解和回答领域问题的能力 LLM 在 RAG 系统中起到了大脑的作用 在面对复杂且多样化的 RAG 任务时,LLM 的性能直接决定了系统的整体效果 提示词工程是生成流程中的另一个关键环节 通过有效的指令的设计和组合,可以帮助 LLM 更好地理解输入内容,从而生成更加精确和相关的回答 精心设计的问题提示词,往往能提升生成效果 LLM发展 RAG 目前更关注通用大模型 原理 Google 于 2017 年发布论文 Attention Is All You Need,引入了 Transformer 模型 Transformer 模型是深度学习领域的一个突破性架构,LLM 的成功得益于对 Transformer 模型的应用 与传统的 RNN(循环神经网络) 相比,Transform...




