
LLM - API
背景
- LLM 是没有 Web API 的,需要进行一次封装
- 将 LLM 的核心接口封装成 Web API 来为用户提供服务 - 必经之路
接口封装
FastAPI
接口封装
Uvicorn + FastAPI
- Uvicorn 类似于 Tomcat,但比 Tomcat 轻量很多,作为 Web 服务器
- 允许异步处理 HTTP 请求,非常适合处理并发请求
- 基于 uvloop 和 httptools,具备非常高的性能
- FastAPI 类似于 SpringBoot,同样比 SpringBoot 轻量很多,作为 API 框架
- 结合 Uvicorn 和 FastAPI
- 可以构建一个高性能的、易于扩展的异步 Web 应用程序
- Uvicorn 作为服务器运行 FastAPI 应用,可以提供优异的并发处理能力
安装依赖
1 | $ pip install fastapi |
代码分层
1 | import uvicorn |
1 | $ curl -s 127.0.0.1:8888 | jq |
模型定义
在 Python 中使用 Pydantic 模型来定义数据结构
Pydantic - 数据验证 + 数据管理 - 类似于 Java Validation
1 | import uvicorn |
- BaseModel 为了数据验证和管理而设计的
- 当继承 BaseModel 后,将自动获得数据验证、序列化和反序列化的功能
项目结构
1 | project_name/ |
路由集成
FastAPI 通过 include_router 将不同的路由集成到主应用中
1 | ├── app |
chat_schema.py
1 | from pydantic import BaseModel, Field |
chat_service.py
1 | from schemas.chat_schema import ChatMessage |
chat_controller.py
1 | from fastapi import APIRouter |
main.py
1 | import uvicorn as uvicorn |
test_chat_controller.py
1 | import json |
LLM
不同的 LLM 对应的对话接口不一样
懒加载
1 | from transformers import AutoTokenizer, AutoModelForCausalLM |
Chat
一次性输出 LLM 返回的内容
1 | from datetime import datetime |
Stream Chat
model.stream_chat()
1 | 我 |
1 | 我 |
通过 stream 变量控制是否流式输出
1 | if stream: |
stream=true
1 | data: {"text": "你", "message_id": "80b2af55c5b7440eaca6b9d510677a75"} |
stream=false
1 | data: {"text": "你好!我是人工智能助手,很高兴为您服务。请问有什么问题我可以帮您解答吗?", "message_id": "741a630ac3d64fd5b1832cc0bae6bb68"} |
接口调用
- 在工程化实践中,一般会将与 AI 相关的逻辑封装在 Python 应用中
- 上层应用一般通过其它语言实现 - Java / Go
Java
Java -> Python,基于 OkHttp 实现 Server-Sent Events

JavaScript
JavaScript -> Java,基于 EventSource 实现 Server-Sent Events
1 | <script> |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-07-06
LLM Core - Word2Vec
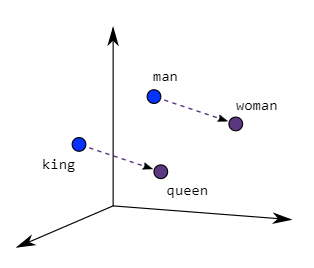
Word2Vec概述 在 NLP 中,在文本预处理后,进行特征提取,涉及到将词语转化成数值的形式,方便计算机理解 Word2Vec 的目的 - 将词语转换成向量形式,使得计算机能够理解 通过学习大量文本数据,捕捉到词语之间的上下文关系,进而生成词的高维表示 - 即词向量 架构 Word2Vec 有 2 种主要的模型 - Skip-Gram + CBOW Model Desc CBOW 根据周围的上下文词汇来预测目标词 Skip-Gram 根据目标词预测其周围的上下文词汇 优劣 Key Value 优点 揭示词与词之间的相似性 - 通过计算向量之间的距离来找到语义相近的词 缺点 无法处理多义词,每个词被赋予一个向量,不考虑上下文中的多种含义 模型架构 连续词袋 - Continuous Bag of Words, CBOW跳字模型 - Skip-Gram 连续词袋 CBOW 模型是一种通过上下文预测目标词的神经网络架构 上下文由目标词周围的一个词或多个词组成,这个数目由窗口大小决定 窗口是指上下文词语的范围 - 如果窗口为 10,那么模型将使用目标词前后各...

2024-07-10
LLM Core - Model Structure
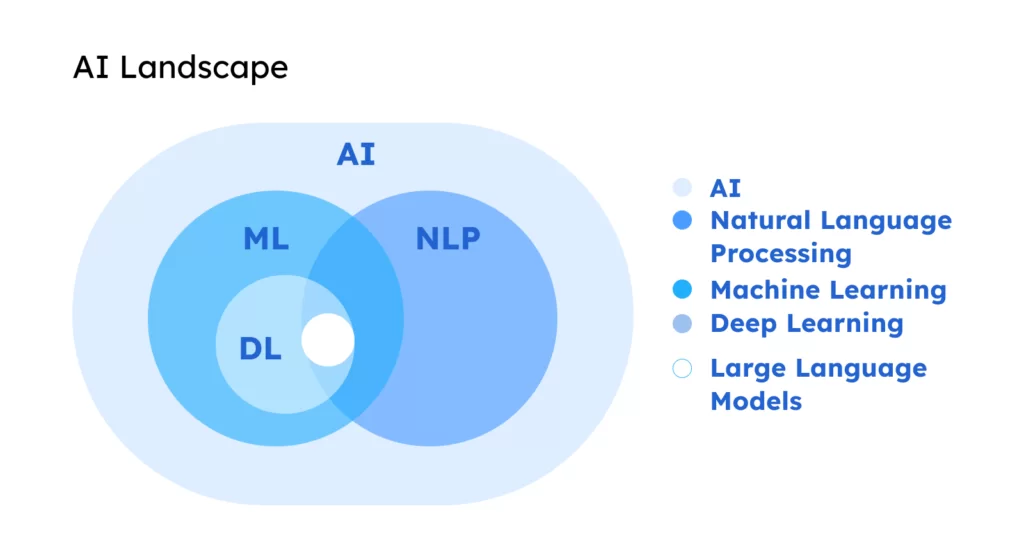
模型文件 模型文件,也叫模型权重,里面大部分空间存放的是模型参数 - 即权重(Weights)和偏置(Biases) 还有其它信息,如优化器状态和元数据等 文件格式 使用 PyTorch,后缀为 .pth 使用 TensorFlow 或者 Hugging Face Transformers,后缀为 .bin 在模型预训练后,可以保存模型,在生产环境,不建议保存模型架构 与 Python 版本和模型定义的代码紧密相关,可能存在兼容性问题 模型权重 - 推荐 1torch.save(model.state_dict(), 'model_weights.pth') 模型权重 + 模型架构 - 可能存在兼容性问题 1torch.save(model, model_path) 权重 + 偏置 权重 - 最重要的参数之一 在前向传播过程中,输入会与权重相乘,这是神经网络学习特征和模式的基本方式 权重决定了输入如何影响输出 偏置 - 调整输出 允许模型输出在没有输入或者所有输入都为 0 的时候,调整到某个基线值 $y=kx+b$ $k$ 为权重,$b$ ...
2024-07-02
LLM Core - Machine Learning Concept
机器学习 机器学习是让计算机利用数据来学习如何完成任务 机器学习允许计算机通过分析和学习数据来自我改进以及作出决策 房价预测 利用 scikit-learn 进行预测 数据集 housing_data.csv 面积 卧室数量 地理位置 售价 100 2 1 300 150 3 2 450 120 2 2 350 80 1 1 220 线性回归12345678910111213141516171819202122232425from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionimport pandas as pd# 加载数据集data = pd.read_csv("housing_data.csv") # 假设这是我们的房屋数据# 准备数据X = data[['面积', '卧室数量', '地理位置']] # 特征y = data[...
2024-07-09
LLM Core - Decoder Only
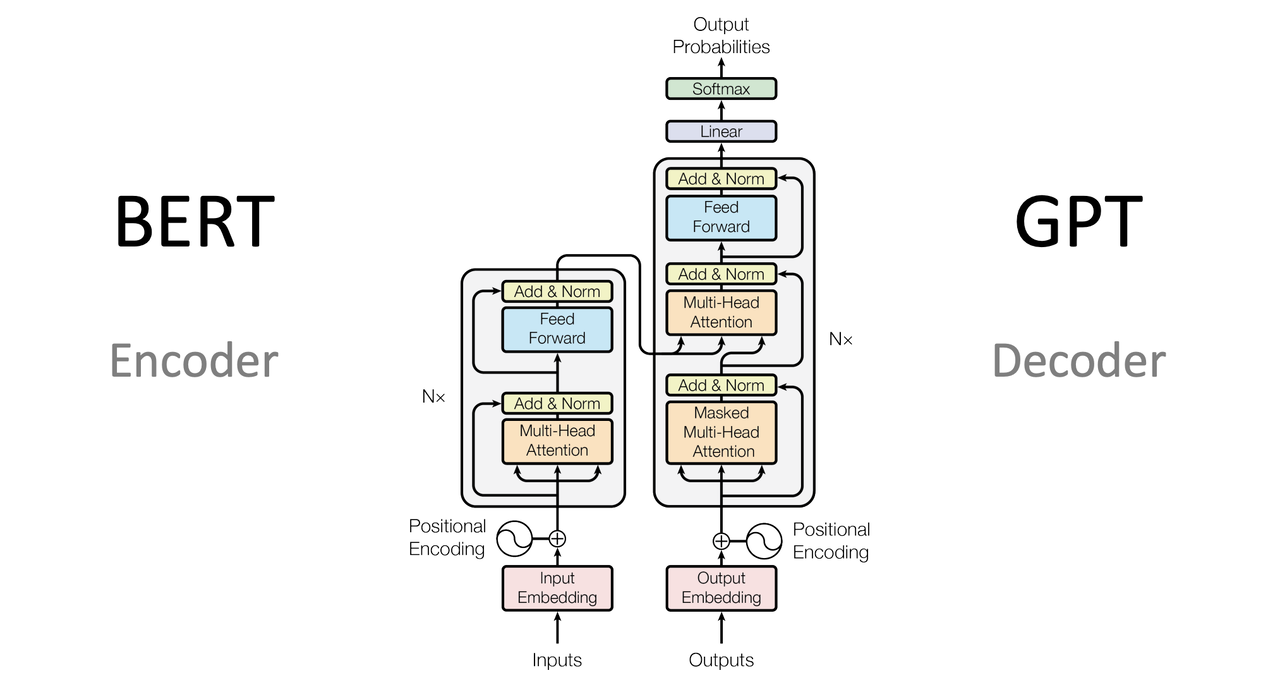
模型架构 已经演化出很多 Transformer 变体,用来适应不同的任务和性能需求 架构名称 特点 主要应用 与原始 Transformer 的关系 原始 Transformer 编码器-解码器结构 机器翻译、文本摘要 基础模型 Decoder-only 只包含解码器 文本生成 去除了编码器部分 Encoder-only 只包含编码器 文本分类、信息提取 去除了解码器部分 Transformer-XL 加入循环机制 长文本处理 扩展了处理长序列的能力 Sparse Transformer 引入稀疏注意力机制 长序列处理 优化了注意力计算效率 Universal Transformer 递归的编码器结构 各种序列处理 引入递归机制,多次使用相同的参数 Conformer 结合 CNN 和 Transformer 优势 音频处理、语音识别 引入卷积层处理局部特征 Vision Transformer 应用于视觉领域 图像分类、视觉任务 将图像块处理为序列的 Transformer 编码器 Switch Transformer 使用稀疏性路由机制 大规模模型训练...
2024-07-08
LLM Core - Transformer
背景 不论是 GRU 还是 LSTM 都面临梯度消失和梯度爆炸的问题 RNN 必须按照顺序处理序列中的每个元素,无法并发处理 RNN 还有长依赖问题,虽然可以处理长序列,但实战效果不佳 Attention Is All You Need - http://arxiv.org/pdf/1706.03762 简单介绍 Transformer 是一种基于自注意力机制的深度学习模型,诞生于 2017 年 目前大部分的语言模型(如 GPT 系列、BERT系列)都基于 Transformer 架构 Transformer 摒弃了之前序列处理任务中广泛使用的 RNN 转而使用自注意力层来直接计算序列内各元素之间的关系,从而有效捕获长距离依赖 Transformer 明显提高了处理速度 Transformer 由于其并行计算的特性,大幅度提升了模型在处理长序列数据时的效率 Transformer 由编码器和解码器组成 每个部分均由多层重复的模块构成,其中包括自注意力层和前馈神经网络 优势 Transformer 通过其独特的架构设计,在效率、效果和灵活性方面提供了显著优势使其成为处理复杂序列数据任...
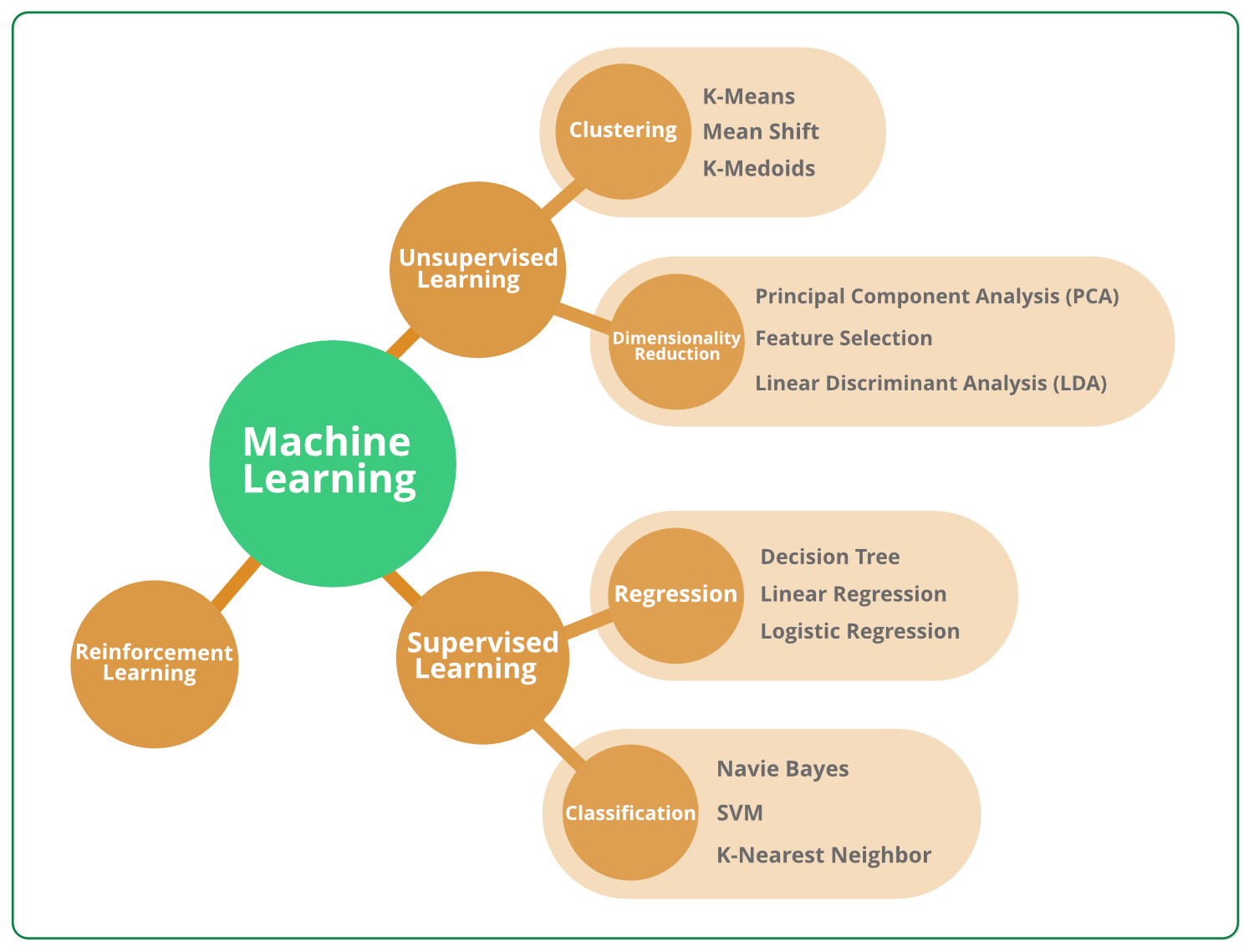
2024-07-03
LLM Core - Machine Learning Algorithm
线性回归概述 线性回归是一种预测分析技术,用于研究两个或者多个变量之间的关系 尝试用一条直线(二维)或者一个平面(三维)的去拟合数据点 这条直线或者平面,可以用来预测或者估计一个变量基于另一个变量的值 数学 假设有一个因变量 y 和一个自变量 x 线性回归会尝试找到一条直线 y=ax+b a 为斜率,而 b 为截距 以便这条直线尽可能地接近所有数据点 $$y=ax+b$$ sklearn 房价预测 - 房价是因变量 y,而房屋面积是自变量 x 12345678910111213141516171819202122232425import matplotlib.pyplot as pltimport numpy as npfrom sklearn.linear_model import LinearRegression# 定义数据X = np.array([35, 45, 40, 60, 65]).reshape(-1, 1) # 面积y = np.array([30, 40, 35, 60, 65]) # 价格# 创建并拟合模型model = LinearRegre...




