
LLM Core - Machine Learning Algorithm
线性回归
概述
- 线性回归是一种预测分析技术,用于研究两个或者多个变量之间的关系
- 尝试用一条直线(二维)或者一个平面(三维)的去拟合数据点
- 这条直线或者平面,可以用来预测或者估计一个变量基于另一个变量的值
数学
- 假设有一个因变量 y 和一个自变量 x
- 线性回归会尝试找到一条直线 y=ax+b
- a 为斜率,而 b 为截距
- 以便这条直线尽可能地接近所有数据点
$$
y=ax+b
$$
sklearn
房价预测 - 房价是因变量 y,而房屋面积是自变量 x
1 | import matplotlib.pyplot as plt |
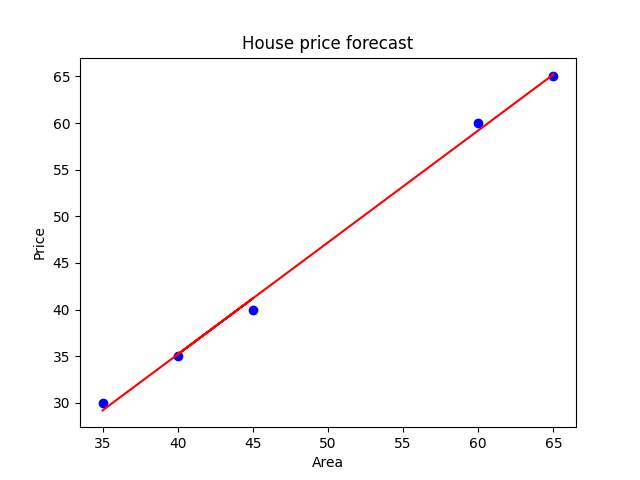
- 蓝色的点代表用于训练模型的实际数据点
- 红色的线用于展示模型拟合的结果
- 拟合 - 直线尝试穿过所有的数据点
逻辑回归
概述
- 逻辑回归主要用于处理分类问题,尤其是二分类问题
- 目的 - 预测一个事件的发生概率,并将这个概率转化为二元结果 - 0/1
数学
逻辑回归通过使用 Sigmoid 函数将线性回归模型的输出映射到 0 和 1 之间的概率值上
$$
\sigma(z)=\frac{1}{1+e^{-z}}
$$
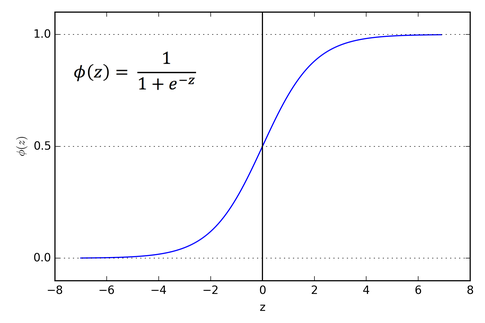
- $z$ 为线性回归模型的输出
- $z=\beta_{0}+\beta_{1}x_{1}+…+\beta_{n}x_{n}$,其中 $x_{n}$ 为特征变量,而 $\beta_{n}$ 为模型参数
- 要取得模型参数的值,需要用到似然函数 - 基于观测,通过结果反推模型参数
- 在某些特定场景下,得出了 $\sigma$,并且到了 $x_{n}$ 的值
- 可以推测出使得 $\sigma$ 取得(准确率)最大的 $\beta_{n}$ 的值
- 使用这个 $\beta_{n}$ 的值作为模型参数,从而进行概率推导
sklearn
基于学习时间,预测学生是否会通过考试,分为两类:通过为 1,未通过为 0
1 | from sklearn.linear_model import LogisticRegression |
决策树
概述
- 决策树主要用于分类和回归任务
- 从数据中学习决策规则来预测目标变量的值
- 场景 - 猜谜游戏 - 客户分类 / 信用评分 / 医疗诊断
- 每次只能问 1 个问题,对方只能回答是或否
- 目标 - 用最少的问题才出答案 - 高效决策
sklearn
根据天气情况、温度和风速来决定进行什么活动
1 | from sklearn.tree import DecisionTreeClassifier, plot_tree |
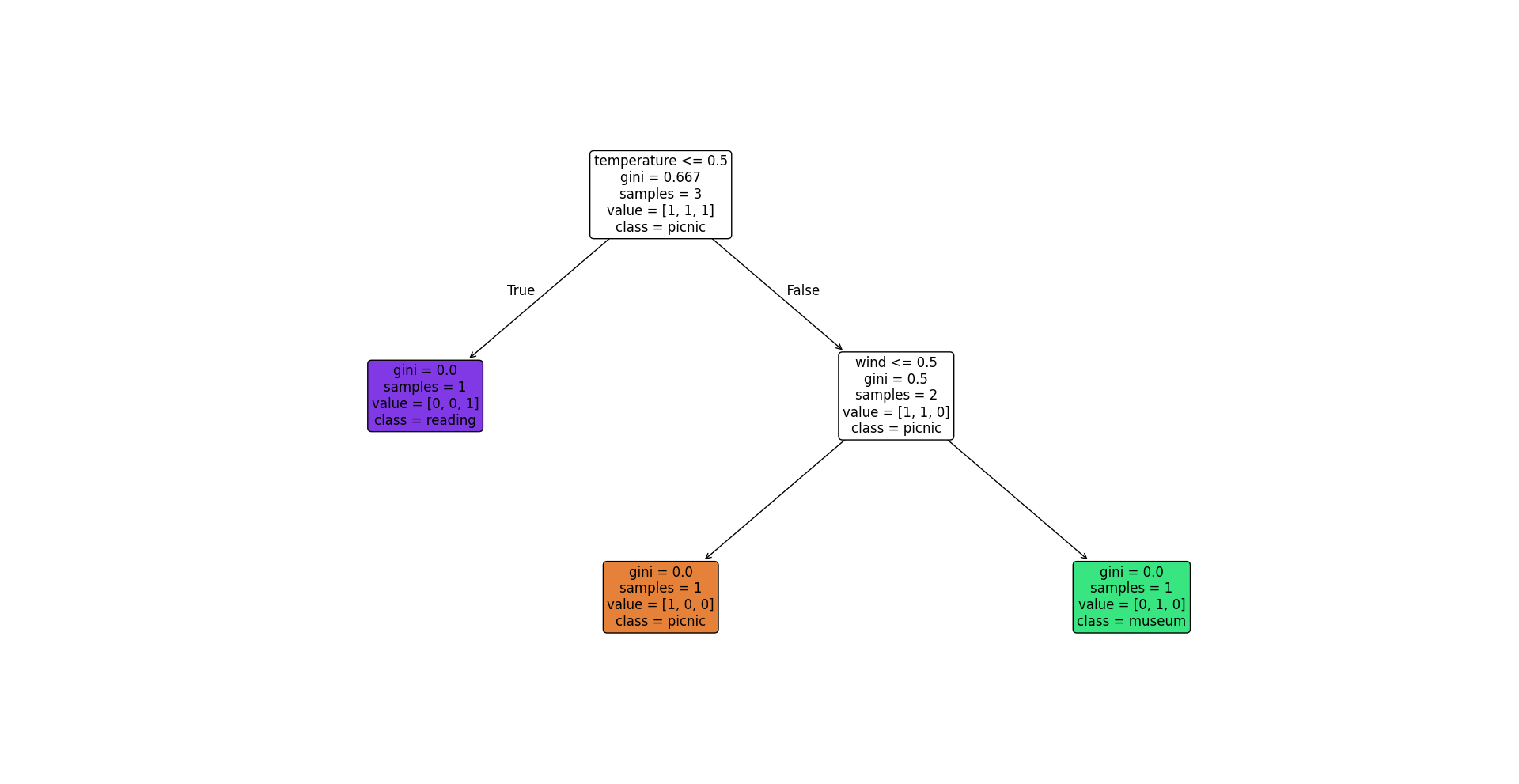
指标
- gini 指数 - 纯度
- 衡量节点纯度的指标,用于分类问题
- 一个节点的 gini 指数越低,表示这个节点包含的样本越倾向于同一个类别
- 0 表示所有样本都属于同一类别,即完全纯净
- samples - 样本总数
- 表示到达这个节点的样本数量
- 提供了关于树的分支如何基于数据集进行分割的直观理解
- 可以用于帮助评估决策树各个部分的数据覆盖范围
- value - 样本分布
- 表示这个节点每个类别的样本数量
- 该数组提供了分类分布的具体信息
- 有助于了解每个决策节点处数据是如何被分割的
- class - 主要类别/预测类别
- 代表在当前节点样本中占多数的类别
- 如果一个节点是叶子节点,那么该类别就是这个节点的预测类别
- 如果一个节点是非叶子节点,那么该类别就是这个节点的主要类别
作用
- 可以理解决策树是如何根据特征分割数据
- 还可以评估树的深度、每个节点的决策质量、模型是否可能出现过拟合
- 过拟合 - 某些叶子节点上只有很少的样本
- 指标是调整模型参数来优化模型性能的重要依据
- 树的最大深度
- 进行节点分割的最少样本数
随机森林
概述
- 随机森林属于集成学习家族
- 随机森林可以通过构建多个决策树来进行预测
- 基本思想 - 集体智慧 - 多个模型集合起来可以作出更好的判断
- 随机森林的关键 - 随机性
| 随机性 | 描述 |
|---|---|
| 样本随机性 | 每棵树训练的数据通过从原始数据中进行随机抽样得到 - 自助采样 |
| 特征随机性 | 在分裂决策树节点时,从所有特征中随机选取一部分特征 然后只在这些随机选取的特征中寻找最优分裂特征 |
随机森林的随机性,使得模型具有很高的准确性,同时能防止模型过拟合
过拟合 - 因为训练数据或者模型参数导致模型缺乏泛化能力
- 泛化能力 ≈ 通用能力
- 训练模型的目的是希望模型解决通用问题
- 场景 - 训练一个模型,用来识别一个照片中有没有狗
- 训练完成后,只能识别直尾巴的狗,因为有一个参数是描述尾巴是直的还是弯的
- 该参数的存在使得模型额外识别了狗的另一个(不重要的)特征,失去了泛化能力 - 过拟合
决策树
决策树会出现过拟合 - 不通用,缺少泛化能力
- 如果一个决策条件中有一个非常不通用的条件,分类后的分支节点只有一个样本
- 说明该决策没有通用性(缺少泛化能力),那么这个决策树模型存在过拟合的问题
工作原理
随机森林可以解决决策树过拟合的问题
- 训练 - 随机
- 从原始数据集中随机抽样选取多个子集
- 每个子集训练一个决策树
- 决策 - 独立 + 投票
- 每棵树独立进行预测
- 最终预测结果是所有的树预测结果的投票或者平均
sklearn
1 | import matplotlib.pyplot as plt |
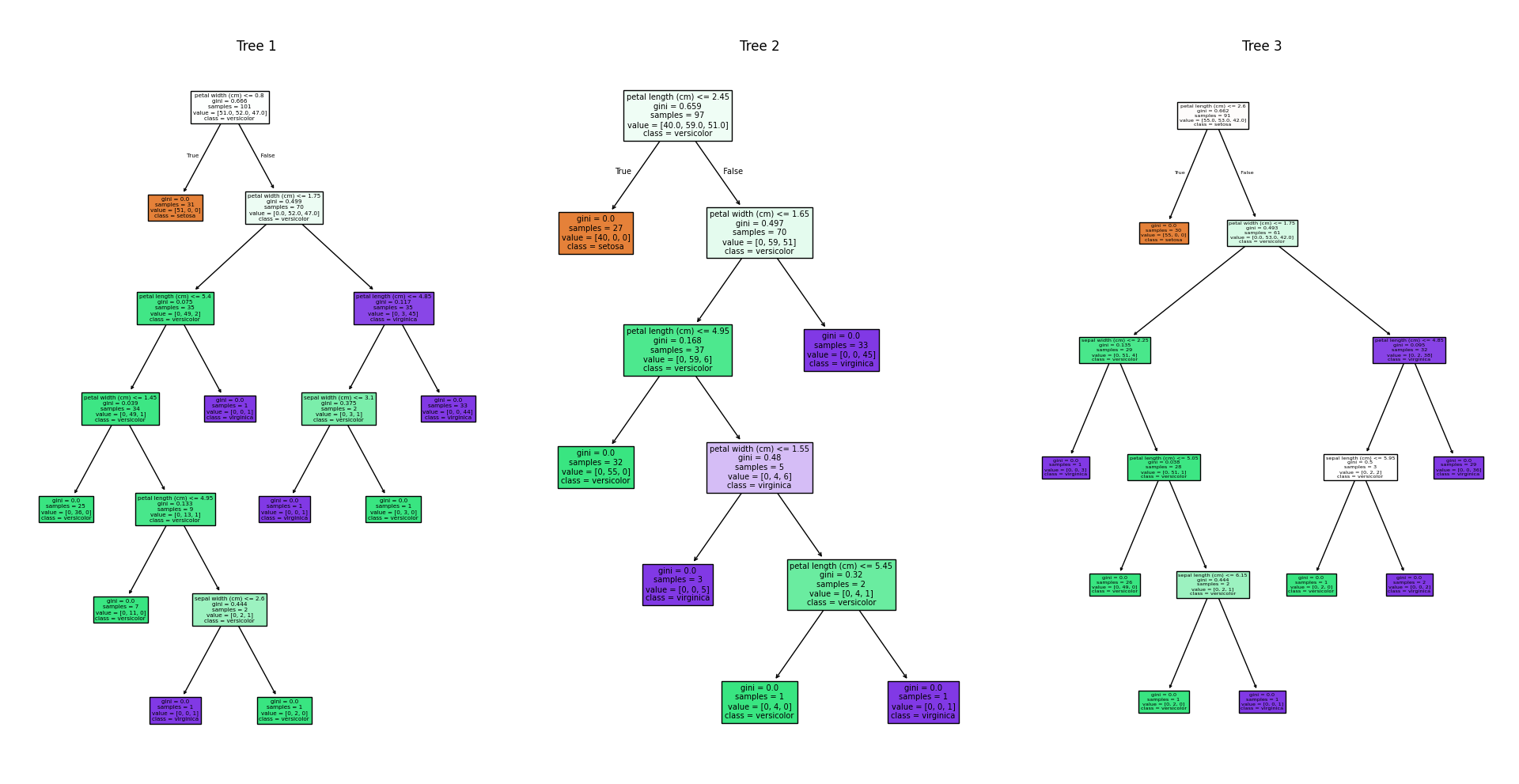
决策步骤
| 步骤 | 操作 |
|---|---|
| 独立预测 | 对于每个输入样本,随机森林中的每棵树都会独立作出预测 |
| 投票计数 | 收集到所有树对每个样本的预测结果,并对这些结果进行计数 |
| 决定决策 | 对于每个样本,被预测次数最多的类别将成为随机深林的最终预测结果 |
在实际应用中,可以构造更多的决策树来进行预测,使得模型更准确更稳定
支持向量机
Support Vector Machine - SVM
概述
寻找不同类别间的很粗且清晰的界线,该界线由距离最近的几个点(支持向量)决定
优势
- 在分类决策时,不仅仅依赖数据的分布
- 并且具有很好的泛化能力,能够应对未见过的新数据
核心思想
- 支持向量机是一种强大的分类算法,在数据科学和机器学习领域广泛应用
- 核心思想
- 找到一个最优的决策边界 - 即超平面
- 超平面能够以最大的间隔将不同类别的数据分开
超平面
在二维空间中,边界为一条线
在三维空间中,边界为一个平面
在高维空间中,边界为超平面
边界的目的 - 尽可能准确地分隔开不同类别的数据点
最大间隔
- SVM 寻找的是能够以最大间隔分开数据的边界
- 间隔 - 是不同类别中的数据点到这个边界的最小距离
- SVM 试图使得该最小距离尽可能大
- 目的 - 更能抵抗数据中的小变动,提高模型的泛化能力
支持向量
- 支持向量 - 决定最优超平面位置的几个关键数据点
- 这些关键数据点不同类别中是最靠近决策边界的数据点
- 最大间隔的边界就是通过这些关键数据点来确定的
核技巧
升维 -> 线性可分
当数据不是线性可分时 - 即无法通过一条直线或者一个平面来分隔
SVM 可以利用核技巧将数据映射到一个更高维的空间 - 数据可能会线性可分
核技巧使得 SVM 在处理非线性数据时非常强大
sklearn
1 | from sklearn import datasets |
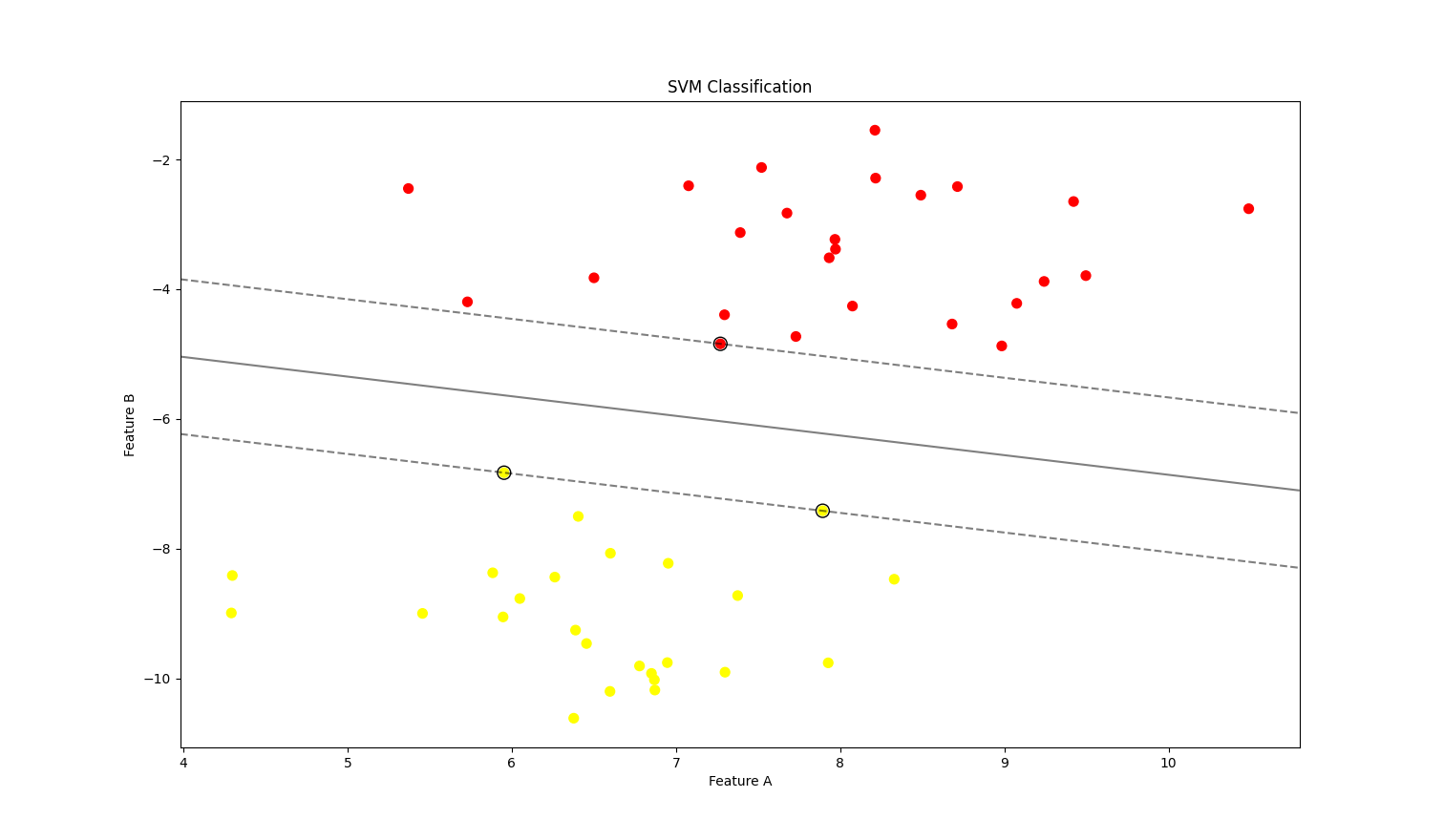
- 使用线性核的 SVM 模型来分类模拟生成的数据点 - 橙色和黄色代表不同的类别
- 黑色实线 - 决策边界 - 即 SVM 找到的最优超平面 - 用于将两类数据分开
- 虚线 - 决策边界的边缘 - 最大间隔的边界 - 这些边缘之间的区域就是模型的间隔
- 黑色圆圈 - 支持向量 - 不同类别中离决策边界最近的几个点 - 用于确定决策边界
核函数 - 升维 - 线性可分
- 上述例子可以通过直线完成分类 - 线性可分 - 无需升维
- 如果数据无法通过直线进行分类,则需要进行升维
- 在三维空间,通过一个平面进行分类
- SVM 可以选择不同的核函数来处理更复杂的数据集
神经网络
概述
- 现在大部分的主流 LLM 都是基于深度神经网络
- 设计思路
- 模仿大脑,由许多小的、处理信息的单位组成 - 神经元
- 各个神经元之间彼此连接,每个神经元可以向其它神经元发送和接收信号
- 神经网络能够执行各种复杂的计算任务 - 图像识别 / 语音识别 / 自然语言处理等
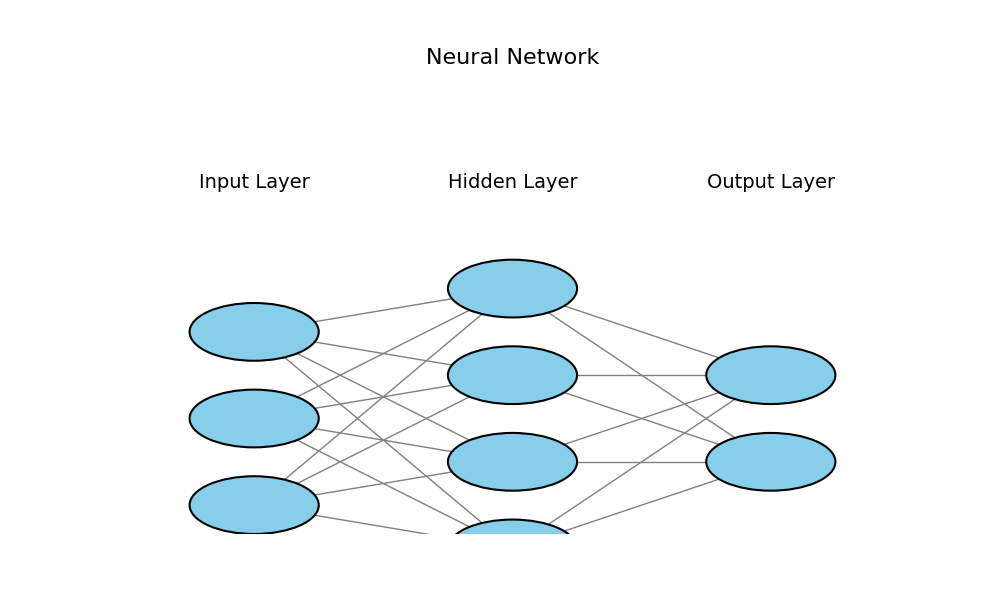
结构
输入层 + 隐藏层(多层) + 输出层
| Layer | Desc |
|---|---|
| 输入层 | 接收原始数据输入 - 图片的像素值 / 一段文本的编码 |
| 隐藏层 | 处理输入数据,可以有一个或多个隐藏层 隐藏层的神经元会对输入数据进行加权和,应用激活函数 可以捕捉输入数据中的复杂模式和关系 |
| 输出层 | 根据隐藏层的处理结果,输出一个值或者一组值 - 最终预测结果 |
优势
非线性 -> 处理复杂任务
- 神经网络是非线性的,可以理解非常复杂的逻辑关系
- 在深层神经网络中,不同的层可以学习到不同的特征
- 较低的层可能学习简单的特征
- 较高的层可以学习到更复杂的概念
- 从简单到复杂的学习过程使得神经网络非常适合处理复杂的数据结构
组件
| Component | Desc |
|---|---|
| 激活函数 | 赋予不同的特性 |
| 前向传播 | 逐层处理输入数据,通过各种操作和激活函数的作用 逐渐提取并组合数据的特征,最终得到输出结果 |
| 训练过程 | 通过反向传播算法来调整网络参数 使得网络的输出尽可能接近真实标签,达到最佳预测效果 |
| 反向传播 | 通过计算模型输出与真实标签之间的差距(损失函数) 并利用链式法则逆向传播这个误差,调整每一层的参数,使得网络的输出更接近真实标签 |
| 梯度下降 | 是一种优化算法,通过不断沿着梯度的反方向调整参数 逐步降低损失函数,使得网络的预测效果逐渐提升,达到最优的训练效果 |
| 损失函数 | 衡量模型输出与真实标签之间差距,即模型的预测效果 损失函数越小表示模型的预测越接近真实标签 |
sklearn
1 | import matplotlib.pyplot as plt |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-07-02
LLM Core - Machine Learning Concept
机器学习 机器学习是让计算机利用数据来学习如何完成任务 机器学习允许计算机通过分析和学习数据来自我改进以及作出决策 房价预测 利用 scikit-learn 进行预测 数据集 housing_data.csv 面积 卧室数量 地理位置 售价 100 2 1 300 150 3 2 450 120 2 2 350 80 1 1 220 线性回归12345678910111213141516171819202122232425from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionimport pandas as pd# 加载数据集data = pd.read_csv("housing_data.csv") # 假设这是我们的房屋数据# 准备数据X = data[['面积', '卧室数量', '地理位置']] # 特征y = data[...
2024-07-04
LLM Core - RNN
背景 RNN 主要用来处理序列数据,目前大部分 LLM 都是基于 Transformer 通过学习 RNN,有助于理解 Transformer 有助于理解神经网络如何处理序列中的依赖关系、记忆过去的信息,并在此基础上生成预测 有助于理解关键问题 - 梯度消失 / 梯度爆炸 RNN Recurrent neural network - 循环神经网络 RNN 是一类用于处理序列数据的神经网络,RNN 能够处理序列长度变化的数据 - 文本 / 语音 RNN 的特点是在模型中引入了循环,使得网络能够保持某种状态,表现出更好的性能 左边 $x$ 为输入层,$o$ 为输出层,中间的 $s$ 为隐藏层,在 $s$ 层进行一个循环 $W$ 右边(展开循环) 与时间 $t$ 相关的状态变化 神经网络在处理数据时,能看到前后时刻的状态,即上下文 RNN 因为隐藏层有时序状态,那么在推理的时候,可以借助上下文,从而理解语义更加准确 优劣优势 RNN 具有记忆能力,通过隐藏层的循环结构来捕捉序列的长期依赖关系 特别适用于文本生成、语音识别等领域 局限 存在梯度消失和梯度爆炸的...

2024-06-28
LLM Deploy - ChatGLM3-6B
LLM 选择核心玩家 厂家很多,但没多少真正在研究技术 - 成本 - 不少厂商是基于 LLaMA 套壳 ChatGLM-6B ChatGLM-6B 和 LLaMA2 是比较热门的开源项目,国产 LLM 是首选 企业布局 LLM 选择 MaaS 服务,调用大厂 LLM API,但会面临数据安全问题 选择开源 LLM,自己微调、部署、为上层应用提供服务 企业一般会选择私有化部署 + 公有云 MaaS 的混合架构 在国产厂商中,从技术角度来看,智谱 AI 是国内 LLM 研发水平最高的厂商 6B 的参数规模为 62 亿,单张 3090 显卡就可以进行微调和推理 企业预算充足(百万以上,GPU 费用 + 商业授权) 可以尝试 GLM-130B,千亿参数规模,推理能力更强 GLM-130B 轻量化后,可以在 3090 × 4 上进行推理 训练 GLM-130B 大概需要 96 台 A100(320G),历时两个多月 计算资源 适合 CPU 计算的 LLM 不多 有些 LLM 可以在 CPU 上进行推理,但需要使用低精度轻量化的 LLM 但在低精度下,LLM 会失真,效果较差 要真正体验并应...
2024-07-08
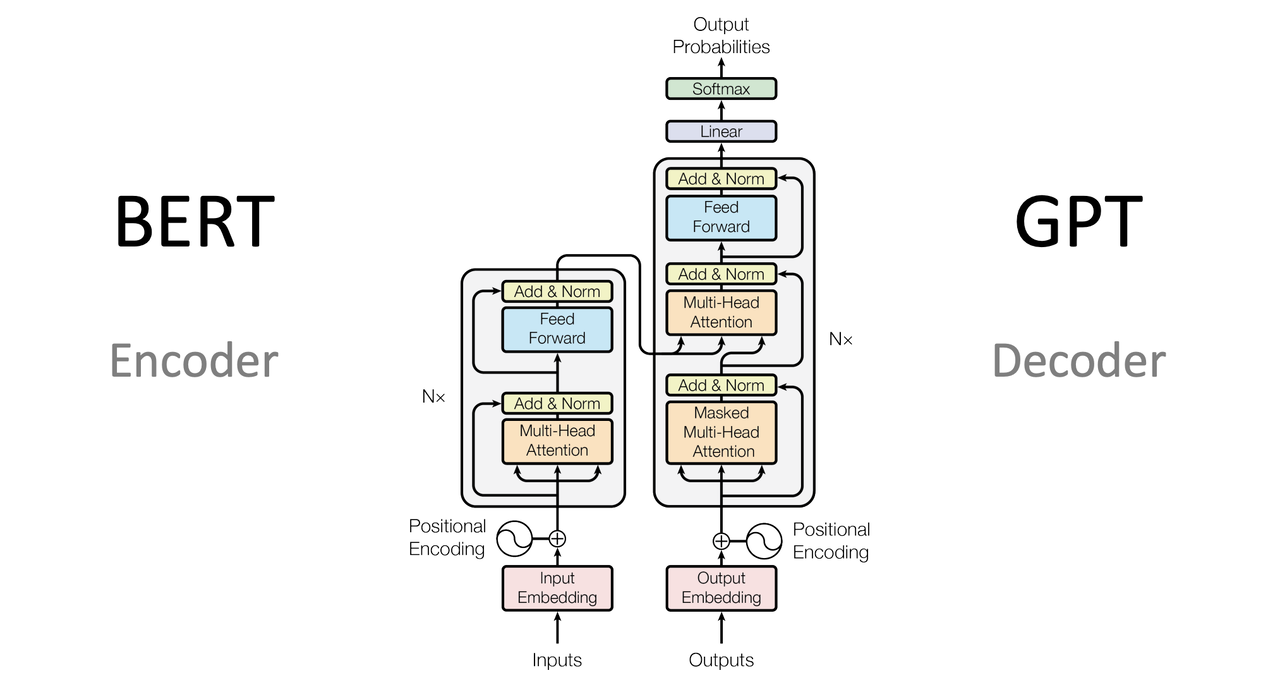
LLM Core - Transformer
背景 不论是 GRU 还是 LSTM 都面临梯度消失和梯度爆炸的问题 RNN 必须按照顺序处理序列中的每个元素,无法并发处理 RNN 还有长依赖问题,虽然可以处理长序列,但实战效果不佳 Attention Is All You Need - http://arxiv.org/pdf/1706.03762 简单介绍 Transformer 是一种基于自注意力机制的深度学习模型,诞生于 2017 年 目前大部分的语言模型(如 GPT 系列、BERT系列)都基于 Transformer 架构 Transformer 摒弃了之前序列处理任务中广泛使用的 RNN 转而使用自注意力层来直接计算序列内各元素之间的关系,从而有效捕获长距离依赖 Transformer 明显提高了处理速度 Transformer 由于其并行计算的特性,大幅度提升了模型在处理长序列数据时的效率 Transformer 由编码器和解码器组成 每个部分均由多层重复的模块构成,其中包括自注意力层和前馈神经网络 优势 Transformer 通过其独特的架构设计,在效率、效果和灵活性方面提供了显著优势使其成为处理复杂序列数据任...

2024-07-10
LLM Core - Model Structure
模型文件 模型文件,也叫模型权重,里面大部分空间存放的是模型参数 - 即权重(Weights)和偏置(Biases) 还有其它信息,如优化器状态和元数据等 文件格式 使用 PyTorch,后缀为 .pth 使用 TensorFlow 或者 Hugging Face Transformers,后缀为 .bin 在模型预训练后,可以保存模型,在生产环境,不建议保存模型架构 与 Python 版本和模型定义的代码紧密相关,可能存在兼容性问题 模型权重 - 推荐 1torch.save(model.state_dict(), 'model_weights.pth') 模型权重 + 模型架构 - 可能存在兼容性问题 1torch.save(model, model_path) 权重 + 偏置 权重 - 最重要的参数之一 在前向传播过程中,输入会与权重相乘,这是神经网络学习特征和模式的基本方式 权重决定了输入如何影响输出 偏置 - 调整输出 允许模型输出在没有输入或者所有输入都为 0 的时候,调整到某个基线值 $y=kx+b$ $k$ 为权重,$b$ ...
2024-07-09
LLM Core - Decoder Only
模型架构 已经演化出很多 Transformer 变体,用来适应不同的任务和性能需求 架构名称 特点 主要应用 与原始 Transformer 的关系 原始 Transformer 编码器-解码器结构 机器翻译、文本摘要 基础模型 Decoder-only 只包含解码器 文本生成 去除了编码器部分 Encoder-only 只包含编码器 文本分类、信息提取 去除了解码器部分 Transformer-XL 加入循环机制 长文本处理 扩展了处理长序列的能力 Sparse Transformer 引入稀疏注意力机制 长序列处理 优化了注意力计算效率 Universal Transformer 递归的编码器结构 各种序列处理 引入递归机制,多次使用相同的参数 Conformer 结合 CNN 和 Transformer 优势 音频处理、语音识别 引入卷积层处理局部特征 Vision Transformer 应用于视觉领域 图像分类、视觉任务 将图像块处理为序列的 Transformer 编码器 Switch Transformer 使用稀疏性路由机制 大规模模型训练...




