LLM Core - NLP
基础
NLP 的研究目的是让计算机能够理解、解释和生成人类语言,一般包含 4 个步骤
| Step | Desc |
|---|---|
| 文本预处理 | 将原始文本转换成机器容易理解的格式 分词(单词或短语)、去除停用词、词干提取、词性标注等 |
| 特征提取 | 从处理过的文本中提取特征,以便用于机器学习模型 将文本转换成数值形式 - 向量化 - 词袋模型 or 词嵌入 |
| 模型训练 | 使用提取到的特征和相应的机器学习算法来训练模型 分类器、回归模型、聚类算法等 |
| 评估与应用 | 评估模型的性能,并在实际应用中使用模型来解释、生成或翻译文本 |
应用场景 - 搜索引擎 / 语音转换 / 文本翻译 / 系统问答
ML vs NLP
| Scope | Desc |
|---|---|
| ML | 让计算机通过查看大量的例子来学习如何完成任务 |
| NLP | 教会计算机理解和使用人类语言 |
| ML + NLP | 用机器学习的技术来让计算机学习如何处理和理解语言 |
文本预处理
将原始文本转换成易于机器理解和处理的格式
文本清洗
去除噪音(对分析无关紧要的部分)及标准化文本
1 | import re |
输出
1 | Hello World Heres a link |
分词
将文本分解成词汇、句子等
1 | from nltk.tokenize import word_tokenize |
输出
1 | ['Natural', 'language', 'processing', '(', 'NLP', ')', 'is', 'a', 'field', 'of', 'computer', 'science', '.'] |
去除停用词
停用词 - 文本中频繁出现但对分析意义不大的词,如 is 和 and 等
去除停用词 - 提高处理效率和分析效果 + 使得数据集变小
1 | import nltk |
词干提取
- 去除单词的词缀(前缀 or 后缀),以便于找到单词的词干或根形式
- 该过程是启发式的,可能返回的不是真实的单词,而是单词的一个截断形式
- running / runs / runner -> run
- 可以减少词形变化的影响,使相关的单词能够在分析时被归纳为相同的形式
- 简化文本数据 + 提高文本任务的处理性能
1 | import nltk |
输出
1 | 原始文本: |
词形还原
- 将单词还原到它的词典形式,即词条的基本形式或者词元形式
- 与词干提取相比,词形还原考虑了单词的词性,并尝试更加精确的转换 - 真实单词
- am / are / is -> be
- 词性还原能够将单词还原到其标准形式,有助于保持语义的准确性
- 适用于需要精确理解和分析文本意义的场合 - 语义分析
1 | from nltk.stem import WordNetLemmatizer |
输出
1 | 原始文本: |
词性标注
- 将文本中的每个单词或符号标注为相应的词性 - 名词/动词/形容词
- 可以揭示单词在句子或语言结构中的作用和意义
命名实体识别
- 识别文本中具有特定意义的实体 - 人名、地点、组织、日期、时间等
- 旨在识别出文本中的实体,并将它们归类为预定义的类别
1 | import spacy |
词性标注
1 | POS Tagging: |
命名实体识别
1 | Named Entity Recognition: |
特征提取
从原始文本中挑选出主要信息,然后用计算机能理解的方式进行表达
- 将原始文本转换成可以被机器学习模型理解和处理的数值形式
- 在文本数据中,挑选出反映文本特征的信息,将其转换成一种结构化的数值表示
- 机器学习算法通常无法直接处理原始文本数据,有助于提高模型性能
词袋模型
Bag of Words - BoW
- 忽略文本中单词的顺序,仅关注每个单词出现的次数
- 部分失真,对原文语义的理解不足
- 每个文档被转换成一个长向量
- 向量的长度 = 词汇表中的单词的数量
- 每个单词分配一个固定的索引
- 向量中的每个元素是该单词在文档中出现的次数
1 | from sklearn.feature_extraction.text import CountVectorizer |
词汇表
1 | ['analysis' 'data' 'for' 'fun' 'great' 'is' 'python' 'science' 'text' |
向量表示
1 | [[1 0 0 1 0 1 0 0 1 0] |
词嵌入
Word Embeddings
- 基于词嵌入产生的检索是真是意义的相似
- 将词汇映射到实际向量空间中,同时可以捕获语义关系
1 | from gensim.models import Word2Vec |
通过 gensim 库训练出来一个 Word2Vec 模型,设置 100 维向量 - 单词
1 | [['the', 'cat', 'sat', 'on', 'the', 'mat', '.'], ['dogs', 'and', 'cats', 'are', 'enemies', '.'], ['the', 'dog', 'chased', 'the', 'cat', '.']] |
解释
| 方式 | 描述 |
|---|---|
| 数学 | 单词用 100 维向量来表示,是在 100 维空间的表示方式 |
| 语义 | 单词有 100 个属性 |
模型训练
- 丢给计算机包含了大量例子(包含正确答案)的数据集
- 计算机通过数据集尝试学习,一开始会犯很多错误
- 随着不断地尝试和学习,开始识别数据中的模式和规律
- 会用一些计算机没见过的新例子来检测计算机学到了多少
- 在训练过程中,不断调整计算机学习的方式,即算法参数
- 最后,当计算机能够准确快速地解决问题时,说明模型已经训练好了
评估与应用
- 当模型训练好后,需要进行测试与评估
- 评估的目的 - 衡量模型的性能和准确性 - 确保它能够可靠地完成既定任务
- 实现方式 - 将模型的预测结果与实际结果进行比较
- 性能指标(取决于任务的性质) - 准确率、精确率、召回率、F1 分数等
- 如果模型经过评估满足标准,则可以放到实际应用去解决问题
- 在模型部署后,依然需要持续监控其性能
- 确保随着时间的推移和数据变化,模型依然有效
- 必要时,模型需要基于新数据或反馈进行重新训练和更新
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-06-29
LLM PEFT - ChatGLM3-6B + LoRA
通用 LLM 千亿大模型(130B、ChatGPT)和小规模的大模型(6B、LLaMA2)都是通用 LLM 通用 LLM 都是通过常识进行预训练的 在实际使用过程中,需要 LLM 具备某一特定领域知识的能力 - 对 LLM 的能力进行增强 增强方式 Method Desc 微调 让预先训练好的 LLM 适应特定任务或数据集的方案,成本相对低LLM 学会训练者提供的微调数据,并具备一定的理解能力 知识库 使用向量数据库或者其它数据库存储数据,为 LLM 提供信息来源外挂 API 与知识库类似,为 LLM 提供信息来源外挂 互不冲突,可以同时使用几种方案来优化 LLM,提升内容输出能力 LoRA / QLoRA / 知识库 / API LLM Performance = 推理效果 落地过程 Method Pipeline 微调 准备数据 -> 微调 -> 验证 -> 提供服务 知识库 准备数据 -> 构建向量库 -> 构建智能体 -> 提供服务 API 准备数据 -&g...

2024-07-10
LLM Core - Model Structure
模型文件 模型文件,也叫模型权重,里面大部分空间存放的是模型参数 - 即权重(Weights)和偏置(Biases) 还有其它信息,如优化器状态和元数据等 文件格式 使用 PyTorch,后缀为 .pth 使用 TensorFlow 或者 Hugging Face Transformers,后缀为 .bin 在模型预训练后,可以保存模型,在生产环境,不建议保存模型架构 与 Python 版本和模型定义的代码紧密相关,可能存在兼容性问题 模型权重 - 推荐 1torch.save(model.state_dict(), 'model_weights.pth') 模型权重 + 模型架构 - 可能存在兼容性问题 1torch.save(model, model_path) 权重 + 偏置 权重 - 最重要的参数之一 在前向传播过程中,输入会与权重相乘,这是神经网络学习特征和模式的基本方式 权重决定了输入如何影响输出 偏置 - 调整输出 允许模型输出在没有输入或者所有输入都为 0 的时候,调整到某个基线值 $y=kx+b$ $k$ 为权重,$b$ ...
2024-07-08
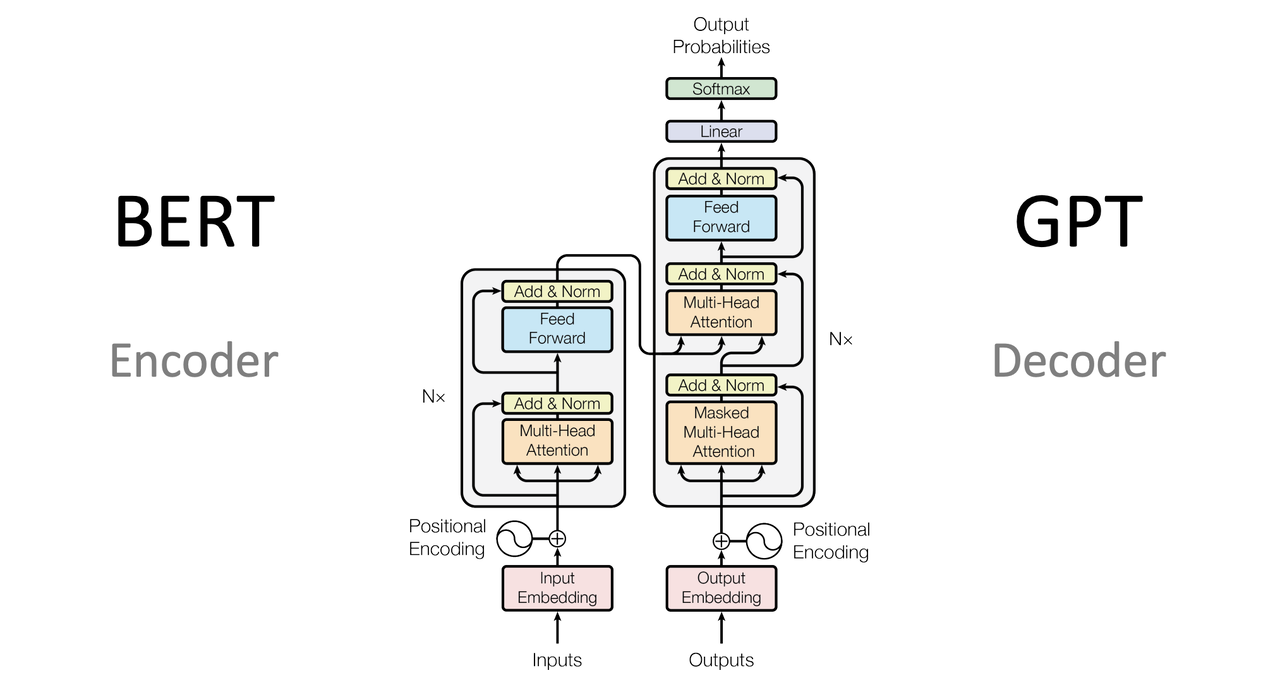
LLM Core - Transformer
背景 不论是 GRU 还是 LSTM 都面临梯度消失和梯度爆炸的问题 RNN 必须按照顺序处理序列中的每个元素,无法并发处理 RNN 还有长依赖问题,虽然可以处理长序列,但实战效果不佳 Attention Is All You Need - http://arxiv.org/pdf/1706.03762 简单介绍 Transformer 是一种基于自注意力机制的深度学习模型,诞生于 2017 年 目前大部分的语言模型(如 GPT 系列、BERT系列)都基于 Transformer 架构 Transformer 摒弃了之前序列处理任务中广泛使用的 RNN 转而使用自注意力层来直接计算序列内各元素之间的关系,从而有效捕获长距离依赖 Transformer 明显提高了处理速度 Transformer 由于其并行计算的特性,大幅度提升了模型在处理长序列数据时的效率 Transformer 由编码器和解码器组成 每个部分均由多层重复的模块构成,其中包括自注意力层和前馈神经网络 优势 Transformer 通过其独特的架构设计,在效率、效果和灵活性方面提供了显著优势使其成为处理复杂序列数据任...
2024-06-26
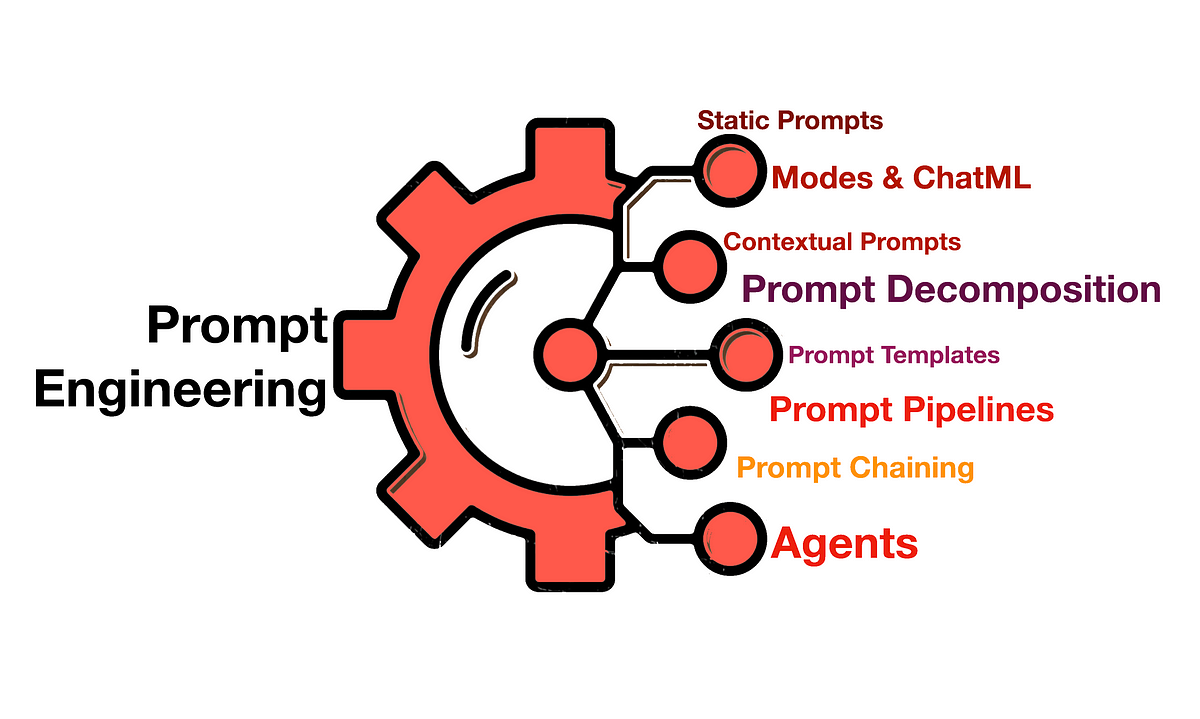
LLM - Prompt
Prompt 是否充分使用好 AI 大模型,提示是关键 OpenAI question / answer prompt / completion - 给 LLM 一个提示,让 LLM 进行补全 LLM 训练原理 GPT 系列模型基于 Transformer 架构的解码器机制,使用自回归无监督方式进行预训练 训练过程 - 大量的文本输入,不断进行记忆 相比于监督学习,训练效率更低,但训练过程简单,可以喂大量的文本语料,上限比较高 completion 根据训练过的记忆,一个字一个字地计算概率,取概率最大的那个字进行输出 因此有人吐槽 LLM 输出很慢 - 逐字计算并输出 Prompt Engineering 需求描述越详细越准确,LLM 输出的内容就越符合要求 Prompt Engineering 是一门专门研究与 LLM 交互的新型学科 通过不断地开发和优化,帮助用户更好地了解 LLM 的能力和局限性 探讨如何设计出最佳提示,用于指导 LLM 帮助我们高效完成某项任务 不仅仅是设计和研发提示,还包含了与 LLM 交互的各种技能和技术 在实现与 LLM 交互、...
2024-07-04
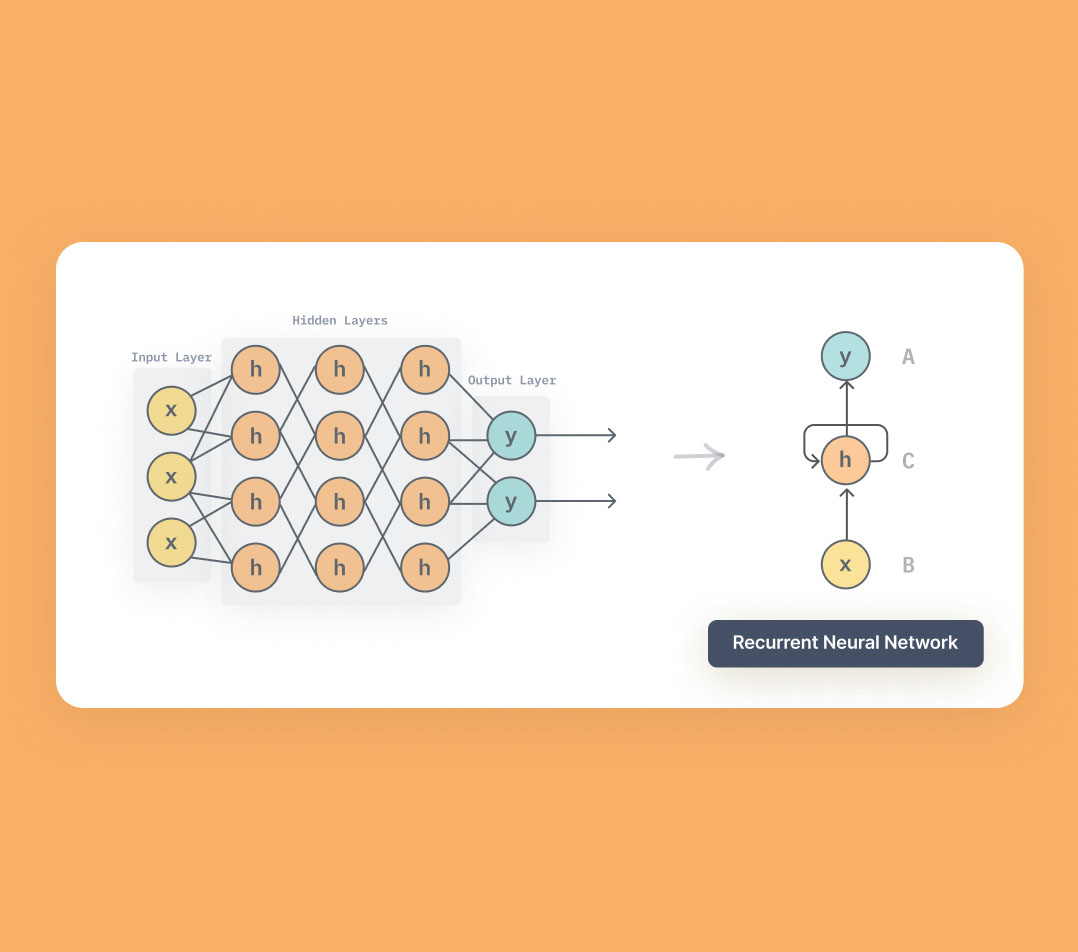
LLM Core - RNN
背景 RNN 主要用来处理序列数据,目前大部分 LLM 都是基于 Transformer 通过学习 RNN,有助于理解 Transformer 有助于理解神经网络如何处理序列中的依赖关系、记忆过去的信息,并在此基础上生成预测 有助于理解关键问题 - 梯度消失 / 梯度爆炸 RNN Recurrent neural network - 循环神经网络 RNN 是一类用于处理序列数据的神经网络,RNN 能够处理序列长度变化的数据 - 文本 / 语音 RNN 的特点是在模型中引入了循环,使得网络能够保持某种状态,表现出更好的性能 左边 $x$ 为输入层,$o$ 为输出层,中间的 $s$ 为隐藏层,在 $s$ 层进行一个循环 $W$ 右边(展开循环) 与时间 $t$ 相关的状态变化 神经网络在处理数据时,能看到前后时刻的状态,即上下文 RNN 因为隐藏层有时序状态,那么在推理的时候,可以借助上下文,从而理解语义更加准确 优劣优势 RNN 具有记忆能力,通过隐藏层的循环结构来捕捉序列的长期依赖关系 特别适用于文本生成、语音识别等领域 局限 存在梯度消失和梯度爆炸的...
2024-06-27
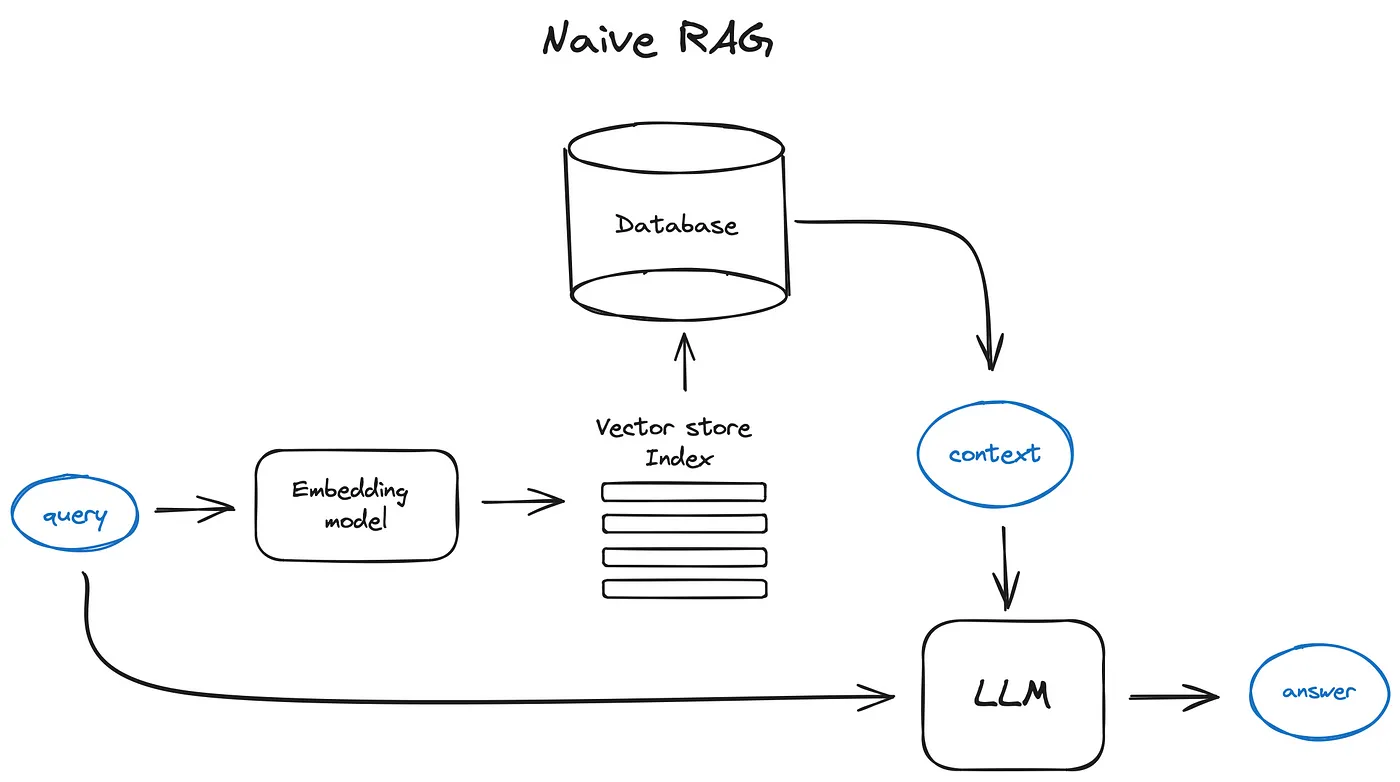
LLM - LangChain + RAG
局限 大模型的核心能力 - 意图理解 + 文本生成 局限 描述 数据的及时性 大部分 AI 大模型都是预训练的,如果要问一些最新的消息,大模型是不知道的 复杂任务处理 AI 大模型在问答方面表现出色,但不总是能够处理复杂任务AI 大模型主要是基于文本的交互(多模态除外) 代码生成与下载 根据需求描述生成对应的代码,并提供下载链接 - 暂时不支持 与企业应用场景的集成 读取关系型数据库里面的数据,并根据提示进行任务处理 - 暂时不支持 在实际应用过程中,输入数据和输出数据,不仅仅是纯文本 AI Agent - 需要解析用户的输入输出 AI Agent AI Agent 是以 LLM 为核心控制器的一套代理系统 控制端处于核心地位,承担记忆、思考以及决策等基础工作 感知模块负责接收和处理来自于外部环境的多样化信息 - 文字、声音、图片、位置等 行动模块通过生成文本、API 调用、使用工具等方式来执行任务以及改变环境 LangChain - 开源 + 提供一整套围绕 LLM 的 Agent 工具 AI Agent 很有可能在未来一段时间内成为 AI 发展的一...