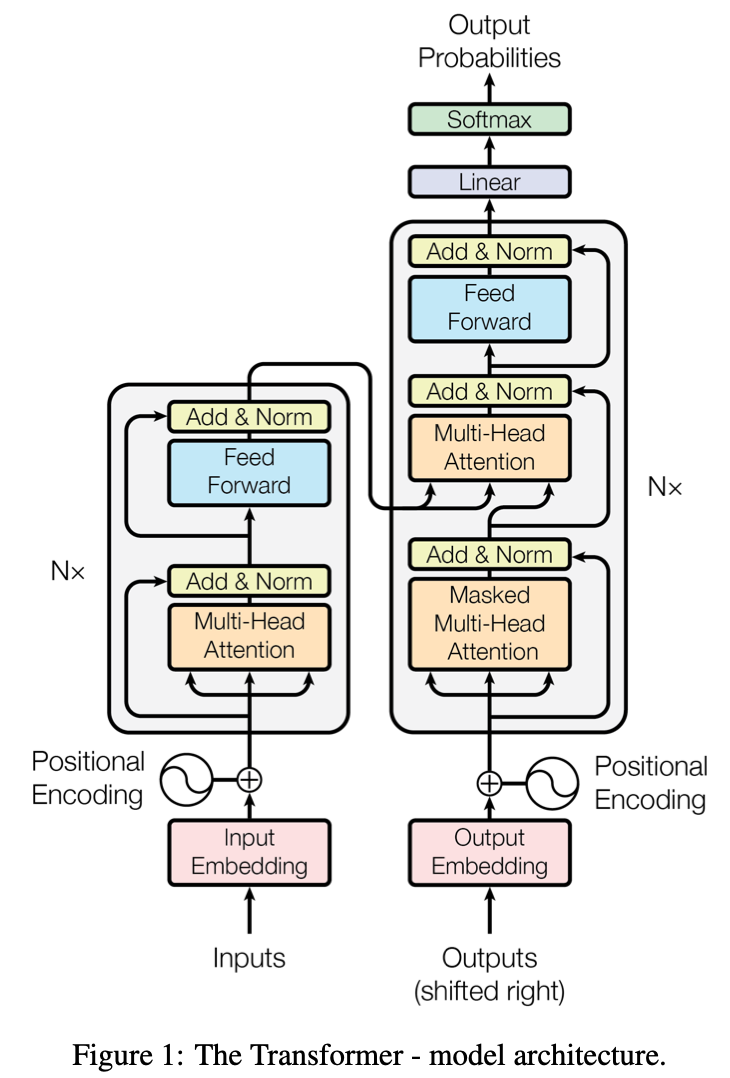
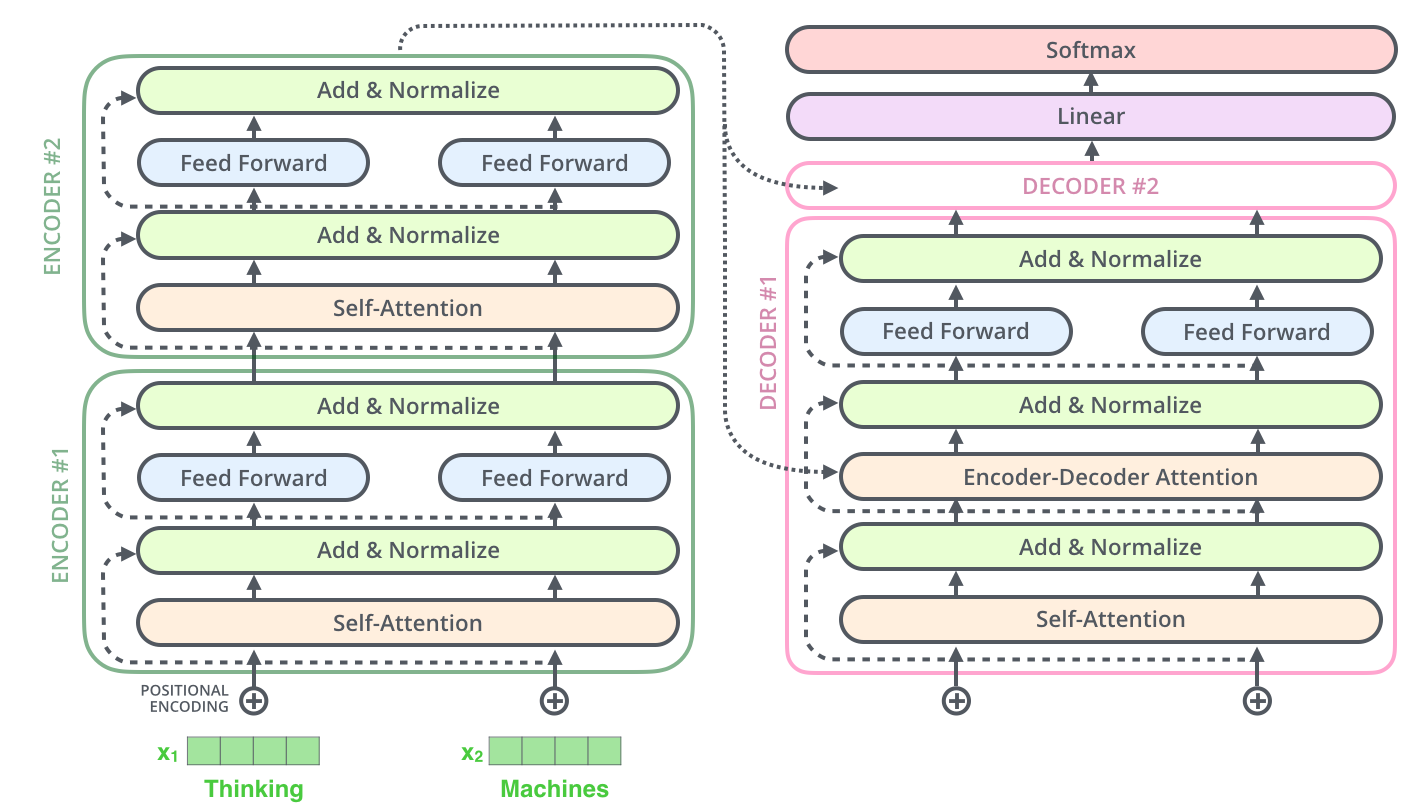
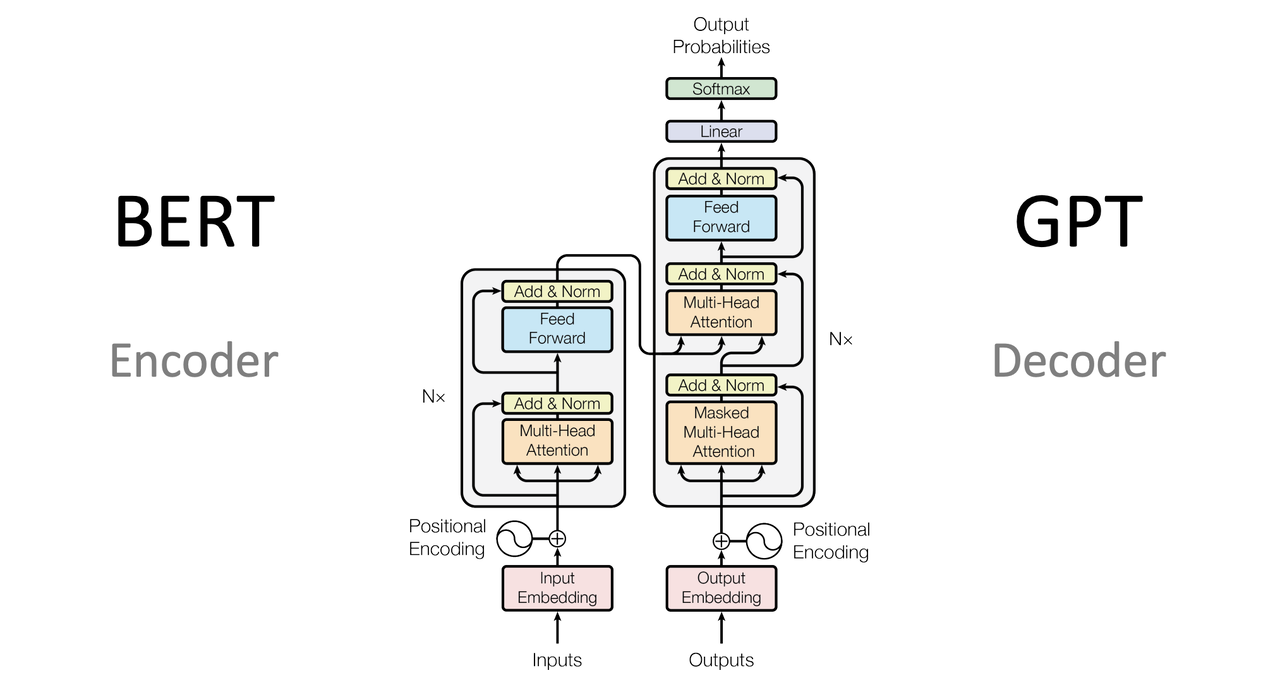
模型架构
已经演化出很多 Transformer 变体,用来适应不同的任务和性能需求
架构名称
特点
主要应用
与原始 Transformer 的关系
原始 Transformer
编码器-解码器结构
机器翻译、文本摘要
基础模型
Decoder-only 只包含解码器
文本生成
去除了编码器部分
Encoder-only
只包含编码器
文本分类、信息提取
去除了解码器部分
Transformer-XL
加入循环机制
长文本处理
扩展了处理长序列的能力
Sparse Transformer
引入稀疏注意力机制
长序列处理
优化了注意力计算效率
Universal Transformer
递归的编码器结构
各种序列处理
引入递归机制,多次使用相同的参数
Conformer
结合 CNN 和 Transformer 优势
音频处理、语音识别
引入卷积层处理局部特征
Vision Transformer
应用于视觉领域
图像分类、视觉任务
将图像块处理为序列的 Transformer 编码器
Switch Transformer 使用稀疏性路由机制
大规模模型训练
提高了模型的可扩展性和效率
Performer
使用随机特征映射技术近似注意力机制
处理非常长的序列
降低计算负担,提高处理效率
GPT 系列模型,使用的是 Decoder-only 架构,Google 的 Bert 模型使用的是 Encoder-only 架构
GPT 是语言模型,根据给定的文本预测 下一个单词,而解码器 就是用来生成输出序列 的
Decoder-only 模型采用自回归 方式进行训练
在生成一个新词时,都会利用之前所有已生成的词 作为上下文
自回归的特定使得 GPT 能够在生成文本时保持内容的连贯性 和逻辑性
与编码器-解码器结构相比,Decoder-only 架构简化 了模型设计,专注于解码器的能力
GPT vs Bert
GPT 是 Decoder-only 架构,采用单向注意力机制 ,在生成文本时,只考虑前面的上下文
Bert 是 Encoder-only 架构,采用双向注意力机制 ,可以同时考虑上文和下文的信息
Bert 可以被应用在更广泛的 NLP 任务 中,如文本分类、情感分析、命名实体识别等
构建模型 模型设计
比较复杂
先设计模型大概的结构,如层数、多头注意力头数、隐藏层层数、预估词汇表大小
根据这些参数,可以大概计算出模型的参数量
然后根据 Scaling Law ,计算出大概需要的计算量 ,进而评估训练成本
Scaling Law
Scaling Law - 随着模型大小 、数据集大小 和用于训练的计算浮点数 的增加,模型的性能 会提高
为了获得最佳性能 ,这三个因素必须同时放大
当不受其它两个因素的制约时,模型性能 与每个单独的因素 都有幂律关系
计算公式 - $C ≈ 6ND$ - 仅针对 Decoder-only 架构
浮点计算量(FLOPS) $C$、模型参数 $N$、训练的 Token 数 $D$
FLOPS - floating-point operations per second
参数规模
总参数量 = 嵌入层参数量 + 位置编码参数量 + 解码器层参数量 + 线性输出层参数量
嵌入层参数量
Input Embedding - vocab_size × embed_size
vocab_size 是指词汇表的大小
预训练数据集处理后会转换成词汇表,vocab_size 即该词汇表的大小
embed_size 是指词嵌入向量的维度数,即每个词的特征数
位置编码参数量
Positional encoding - embed_size
解码器层参数量
(自注意力机制参数量 + 前馈网络参数量) × 层数
自注意力层
自注意力机制参数量 = 4 × embed_size × embed_size
组件
参数量
查询矩阵 - Q
embed_size × embed_size
键矩阵 - K
embed_size × embed_size
值矩阵 -V
embed_size × embed_size
输出线性变换
embed_size × embed_size
前馈网络层
2 × (embed_size × hidden_dim) - hidden_dim 指的是隐藏层层数
线性输出层参数量
vocab_size × embed_size
总参数量
vocab_size × embed_size + embed_size + (4 × embed_size × embed_size + 2 × (embed_size × hidden_dim)) × 层数 + vocab_size × embed_size
vocab_size 取决于训练文本大小以及分词方式
定义模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import torchfrom torch import nnclass TransformerDecoderModel (nn.Module): def __init__ (self, vocab_size, embed_size, num_heads, hidden_dim, num_layers ): super (TransformerDecoderModel, self ).__init__() self .embed = nn.Embedding(vocab_size, embed_size) self .positional_encoding = nn.Parameter(torch.randn(embed_size).unsqueeze(0 )) decoder_layer = nn.TransformerDecoderLayer(d_model=embed_size, nhead=num_heads, dim_feedforward=hidden_dim) self .transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=num_layers) self .fc = nn.Linear(embed_size, vocab_size) def forward (self, src ): src = self .embed(src) + self .positional_encoding src_mask = self .generate_square_subsequent_mask(src.size(0 )) output = self .transformer_decoder(src, src, src_mask) output = self .fc(output) return output def generate_square_subsequent_mask (self, sz ): mask = (torch.triu(torch.ones(sz, sz)) == 1 ).transpose(0 , 1 ) mask = mask.float ().masked_fill(mask == 0 , float ('-inf' )).masked_fill(mask == 1 , float (0.0 )) return mask
Method
Desc
__init__类似于 Java 的构造函数,用来初始化属性
forward前向传播的具体实现
generate_square_subsequent_mask用来生成掩码矩阵
训练数据 文本格式
采用自回归训练,不需要使用像翻译模型那样的语料对,直接使用自然语言文本,格式如下
1 2 3 4 5 6 { "id" : "13" , "url" : "https://zh.wikipedia.org/wiki?curid=13" , "title" : "数学" , "text" : "数学\n\n数学是利用符号语言研究数量、结构、变化以及空间等概念的一门学科,..." }
文本预处理
只需要保留 text 字段,先进行文本预处理
循环遍历子目录,然后分别读取每个文件里的文本
从 JSON 格式的数据中抽取 text 字段对应的数据,保存成 sentence.txt 文件 - 1.2GB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import jsonimport osclass PrepareData (): @staticmethod def prepare (): root_dir = 'wiki_zh' ds = [] for dir_path, dir_names, file_names in os.walk(root_dir): for file_name in file_names: file_path = os.path.join(dir_path, file_name) if "." in file_path: continue with open (file_path, 'r' ) as file: for line in file: try : text = json.loads(line)["text" ] ds.append(text) if len (ds) % 100000 == 0 : print ("size: " , len (ds)) except json.JSONDecodeError: print ("格式不正确" ) print (len (ds)) with open ('sentence.txt' , 'w' ) as file: for i in ds: file.write(i + '\n' ) return ds data_set = PrepareData.prepare()
训练模型
训练模型 - 非常复杂 + 最消耗资源
数据处理
将 sentence.txt 的内容逐行读入,使用 jieba 进行分词,转换成词汇表保存到本地
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from torch.utils.data import Datasetimport torchimport jiebaimport jsonclass TextDataset (Dataset ): def __init__ (self, filepath ): words = [] with open (filepath, 'r' ) as file: for line in file: words.extend(list (jieba.cut(line.strip()))) self .vocab = list (set (words)) self .vocab_size = len (self .vocab) print ("vocab_size" , self .vocab_size) self .word_to_int = {word: i for i, word in enumerate (self .vocab)} self .int_to_word = {i: word for i, word in enumerate (self .vocab)} with open ('word_to_int.json' , 'w' ) as f: json.dump(self .word_to_int, f, ensure_ascii=False , indent=4 ) with open ('int_to_word.json' , 'w' ) as f: json.dump(self .int_to_word, f, ensure_ascii=False , indent=4 ) self .data = [self .word_to_int[word] for word in words] def __len__ (self ): return len (self .data) - 1 def __getitem__ (self, idx ): idx = max (50 , idx) input_seq = torch.tensor(self .data[max (0 , idx - 50 ):idx], dtype=torch.long) target = torch.tensor(self .data[idx], dtype=torch.long) return input_seq, target
加载数据集,并处理成 DataLoader
1 2 3 batch_size = 32 dataset = TextDataset('sentence.txt' ) dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True , drop_last=True )
初始化模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 model = TransformerDecoderModel(vocab_size=dataset.vocab_size, embed_size=512 , num_heads=8 , hidden_dim=2048 , num_layers=6 ) device = torch.device("cuda" if torch.cuda.is_available() else "cpu" ) print ('使用设备:' , device)model.to(device) learning_rate = 1e-3 optimizer = optim.Adam(model.parameters(), lr=learning_rate) criterion = nn.CrossEntropyLoss()
总参数量
vocab_size × 512 + 512 + (4 × 512 × 512 + 2 × (512 × 2048)) × 6 + vocab_size × 512
假设 vocab_size = 100000(几 MB 的训练数据,词汇量就能达到 100000)- 1.2 亿参数
GPT-3 的训练数据大约 570GB,Transformer 层数为 96,按上述计算会超过 1750 亿参数
开始训练
训练过程太过于消耗资源,为了快速出模型,截取其中一部分训练数据,大约 10M
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 model.train() num_epochs = 1 for epoch in range (num_epochs): for i, (inputs, targets) in enumerate (dataloader): try : inputs = inputs.t().to(device) targets = targets.to(device) optimizer.zero_grad() outputs = model(inputs) outputs = outputs[-1 ] loss = criterion(outputs, targets) loss.backward() optimizer.step() if i % 100 == 0 : print ( f'Time [{datetime.now()} ], Epoch [{epoch + 1 } /{num_epochs} ], Step [{i + 1 } /{len (dataloader)} ], Loss: {loss.item()} ' ) except RuntimeError as e: print (e) continue model_path = "decoder-only.model" torch.save(model, model_path) print ('模型已保存到' , model_path)
模型测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import torchimport jsonimport jiebadef load_model (model_path ): model = torch.load(model_path, map_location=torch.device('cpu' )) model.eval () return model def load_vocab (json_file ): """从JSON文件中加载词汇表。""" with open (json_file, 'r' ) as f: vocab = json.load(f) return vocab def predict (model, initial_seq, max_len=50 ): int_to_word = load_vocab('int_to_word.json' ) model.eval () with torch.no_grad(): generated = initial_seq for _ in range (max_len): input_tensor = torch.tensor([generated], dtype=torch.long) output = model(input_tensor) predicted_idx = torch.argmax(output[:, -1 ], dim=-1 ).item() generated.append(predicted_idx) if predicted_idx == len (int_to_word) - 1 : break return [int_to_word[str (idx)] for idx in generated] def generate (model, input_sentence, max_len=50 ): input_words = list (jieba.cut(input_sentence.strip())) word_to_int = load_vocab('word_to_int.json' ) input_seq = [word_to_int.get(word, len (word_to_int) - 1 ) for word in input_words] generated_text = predict(model, input_seq, max_len) return "" .join(generated_text) def main (): prompt = "hello" model = load_model('decoder-only.model' ) completion = generate(model, prompt) print ("生成文本:" , completion) if __name__ == '__main__' : main()
因训练有限,效果惨不忍睹,预料之中
小结
模型构建本身不复杂 ,构建过程就是整个深度神经网络 的构建过程 难点 在于预训练过程 - 吃训练资源 + 考虑训练效果 如何调整参数 让训练效果更好是难点
GPT-3 在不同参数规模下的设置