
LLM Core - Model Structure
模型文件
- 模型文件,也叫模型权重,里面大部分空间存放的是模型参数 - 即权重(Weights)和偏置(Biases)
- 还有其它信息,如优化器状态和元数据等
- 文件格式
- 使用 PyTorch,后缀为
.pth - 使用 TensorFlow 或者 Hugging Face Transformers,后缀为
.bin
- 使用 PyTorch,后缀为
- 在模型预训练后,可以保存模型,在生产环境,不建议保存模型架构
- 与 Python 版本和模型定义的代码紧密相关,可能存在兼容性问题
模型权重 - 推荐
1 | torch.save(model.state_dict(), 'model_weights.pth') |
模型权重 + 模型架构 - 可能存在兼容性问题
1 | torch.save(model, model_path) |
权重 + 偏置
- 权重 - 最重要的参数之一
- 在前向传播过程中,输入会与权重相乘,这是神经网络学习特征和模式的基本方式
- 权重决定了输入如何影响输出
- 偏置 - 调整输出
- 允许模型输出在没有输入或者所有输入都为 0 的时候,调整到某个基线值
- $y=kx+b$
- $k$ 为权重,$b$ 为偏置
- 在神经网络中,权重 $k$ 决定了每个输入特征对于输出的重要性和影响力
- 偏置 $b$ 是个常数项,提供除了输入特征之外的额外输入
- 允许模型输出可以在没有任何输入或者所有输入都为 0 的时候,调整到某个基线或阈值
- 在复杂的神经网络中,每个神经元都有权重和偏置
- 从前一层接收多个输入信号,对这些输入信号加权求和后加上偏置
- 然后通过一个非线性激活函数(tanh or ReLU)来生成输出信号 - 传递到下一层
- 每一层的权重和偏置都是模型需要学习的参数,根据训练数据进行调整,以最小化模型的预测误差
模型可视化
Netron - 整体结构
6 层 Transformer Decoder-only 架构
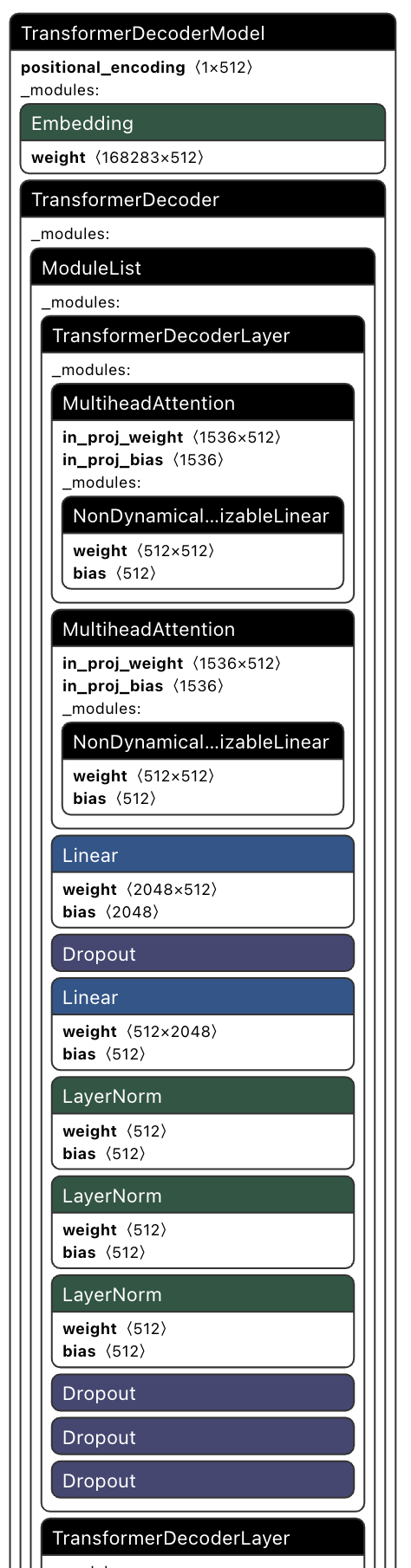
Embedding
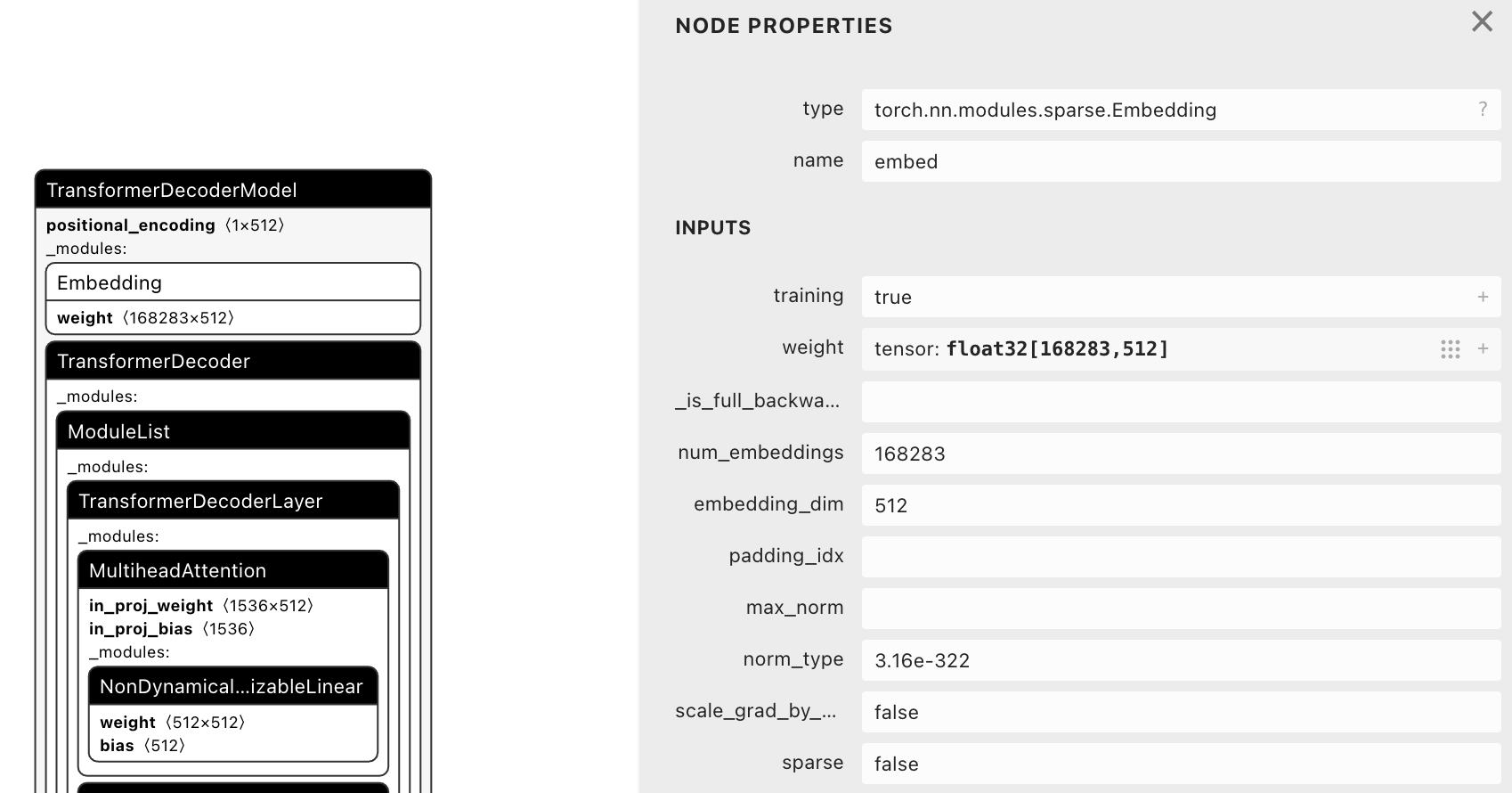
weight(168283×512)- 代表 168283×512 的矩阵,每一行对应一个特定的词向量
- 对于词汇表中一个词或者标记,该矩阵提供了一个 512 维的嵌入向量
tensor: float32[168283,512]- 表明这是一个 FP32 精度的变量,168283 表明训练时使用了 168283 个词汇
TransformerDecoderLayer
具体的实现类 - torch.nn.modules.transformer.TransformerDecoderLayer
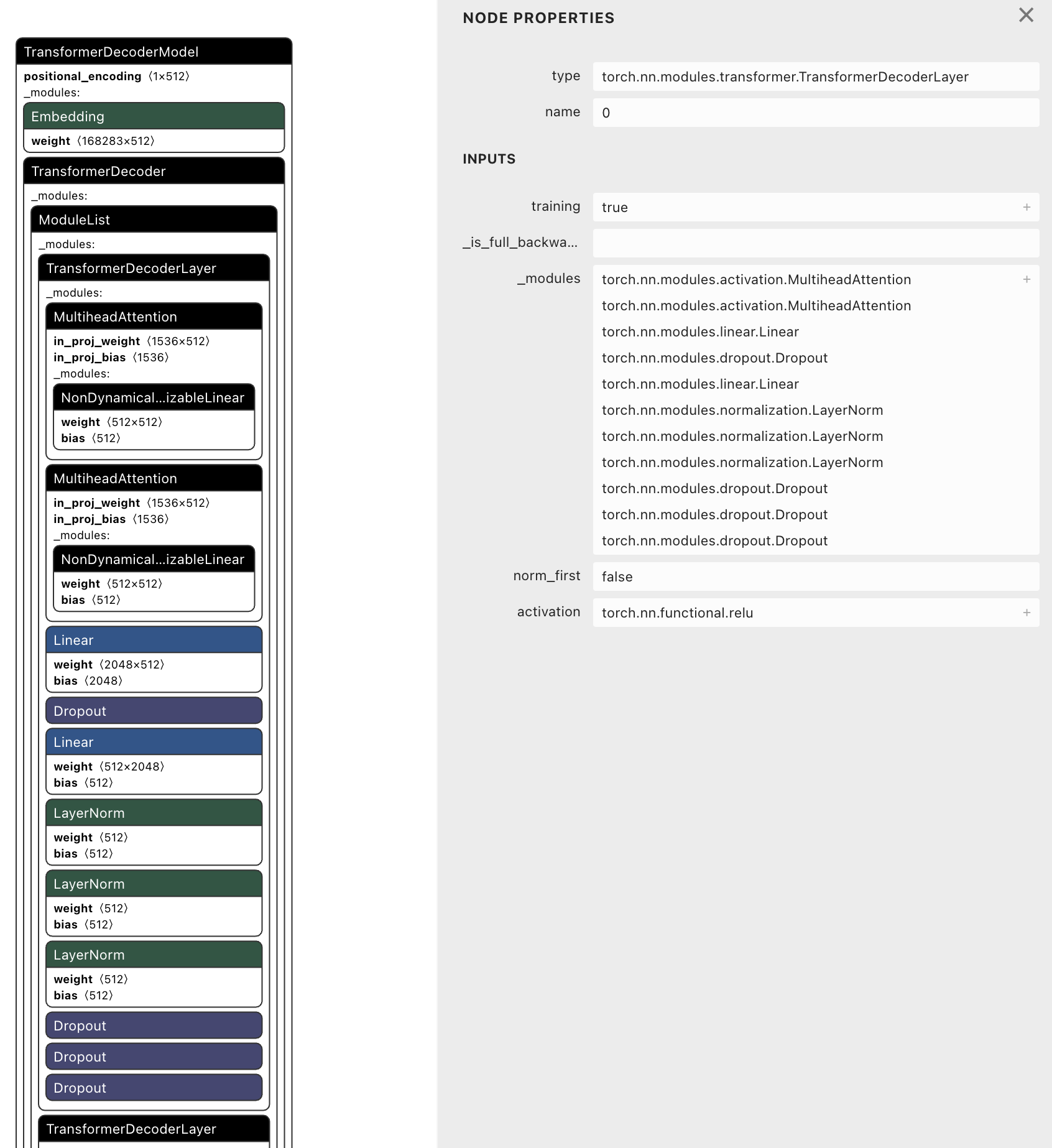
包含组件
1 | torch.nn.modules.activation.MultiheadAttention |
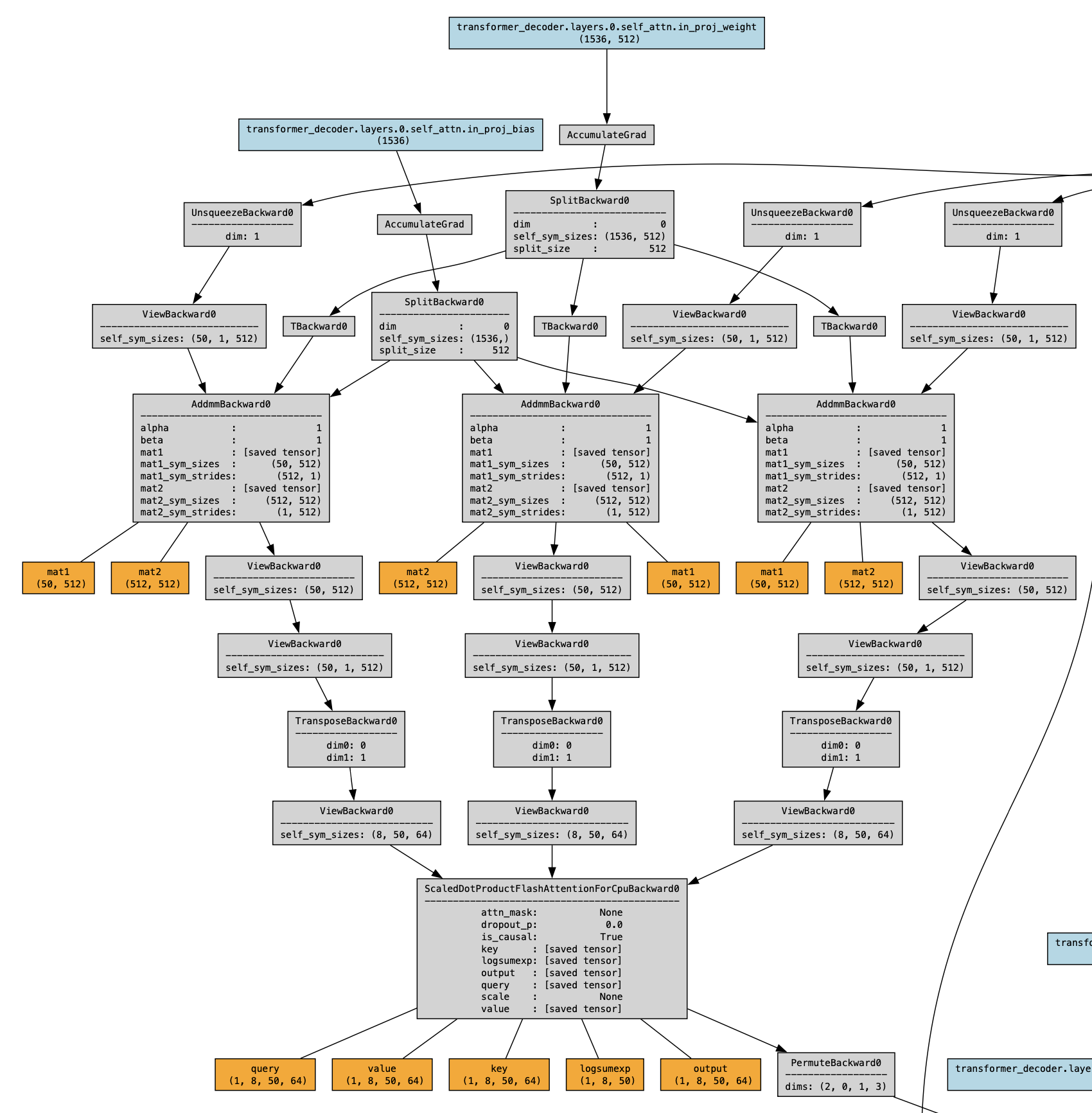
torchviz - 具体节点
1 | x = torch.randint(10000, (50,)) # 假设一个序列长度为10的输入 |
整个网络结构的顺序图
训练
- 模型的训练过程就是不断调整权重的过程
- 调整权重的依据就是根据损失函数计算损失,通过反向传播不断调整权重使得损失最小
- 达到理想损失值后,把权重记录下来保存
推理
- 数据到达节点(神经元)后,先从输入层到隐藏层,再从隐藏层到输出层
- 每一层都执行 $y_1=k_1x_1+b_1$,然后应用非线性的激活函数,比如 $x_2=ReLU(y_1)$,最后将 $x_2$ 继续传递下一层
- 下一层的权重 $k_2$ 和偏置 $b_2$ 是已知的,继续计算得到 $y_2$
- 基本都是张量相乘,而不是简单的整数小数相乘
机器学习框架(PyTorch)可以根据描述文件,将模型重构出来,进行训练和推理
模型容量
存储大小
755M
总参数量
vocab_size × embed_size + embed_size + (4 × embed_size × embed_size + 2 × (embed_size × hidden_dim)) × 层数 + vocab_size × embed_size
vocab_size × 512 + 512 + (4 × 512 × 512 + 2 × (512 × 2048)) × 6 + vocab_size × 512
vocab_size = 168283
168283 × 512 + 512 + (4 × 512 × 512 + 2 × (512 × 2048)) × 6 + 168283 × 512 = 191,196,672 = 1.9 亿
- 模型的精度为 float32,即每个参数需要 4 字节的存储空间
- 纯参数方面大约需要 729M 的空间(191,196,672×4/1024/1024),占比 96.5%,剩余 26M 的空间可能存放的是模型结构、元数据等
Embedding 层
Embedding 层在整个模型中的作用非常大,占比 40%
- 权重是
tensor: float32[168283,512] - 在 Embedding 层参数量为 168283×512 = 86,160,896,存储≈ 328M
- 参数占比 = 86,160,896 / 191,196,672 ≈ 0.45
- 存储占比 = 328 / 755 ≈ 0.43
模型参数

- 具有 50 个参数的矩阵,每个参数表示词向量在特定维度上的权重或特征
- 每一行表示某个词在 10 个不同的特征维度上的数值表示
- 假设 Embedding 层是可训练的
- 在模型训练的过程中,会根据损失计算,反向传播后更新某个参数
- 使得模型可以更好地表示某个词,来达到训练的目的
- 在最终的推理过程中,词向量会被传播下去,作为下一层神经网络的输入,参与到后续的计算过程中
小结
类比 - 通过 Java 字节码文件反推 Java 编码过程
- 模型里存放的是各个层的权重和偏置,类似于 $y=kx+b$ 里面的 $k$ 和 $b$
- 机器学习框架(PyTorch)可以识别模型文件,并且把模型结构重构出来进行训练和推理
- 模型训练过程 - 不断前向传播、损失计算、反向传播、参数更新的过程
- 模型推理过程 - 根据训练好的参数,进行前向传播的过程
- 模型可视化工具 - Netron + torchviz
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
2024-06-27
LLM - LangChain + RAG
局限 大模型的核心能力 - 意图理解 + 文本生成 局限 描述 数据的及时性 大部分 AI 大模型都是预训练的,如果要问一些最新的消息,大模型是不知道的 复杂任务处理 AI 大模型在问答方面表现出色,但不总是能够处理复杂任务AI 大模型主要是基于文本的交互(多模态除外) 代码生成与下载 根据需求描述生成对应的代码,并提供下载链接 - 暂时不支持 与企业应用场景的集成 读取关系型数据库里面的数据,并根据提示进行任务处理 - 暂时不支持 在实际应用过程中,输入数据和输出数据,不仅仅是纯文本 AI Agent - 需要解析用户的输入输出 AI Agent AI Agent 是以 LLM 为核心控制器的一套代理系统 控制端处于核心地位,承担记忆、思考以及决策等基础工作 感知模块负责接收和处理来自于外部环境的多样化信息 - 文字、声音、图片、位置等 行动模块通过生成文本、API 调用、使用工具等方式来执行任务以及改变环境 LangChain - 开源 + 提供一整套围绕 LLM 的 Agent 工具 AI Agent 很有可能在未来一段时间内成为 AI 发展的一...
2024-06-26
LLM - Prompt
Prompt 是否充分使用好 AI 大模型,提示是关键 OpenAI question / answer prompt / completion - 给 LLM 一个提示,让 LLM 进行补全 LLM 训练原理 GPT 系列模型基于 Transformer 架构的解码器机制,使用自回归无监督方式进行预训练 训练过程 - 大量的文本输入,不断进行记忆 相比于监督学习,训练效率更低,但训练过程简单,可以喂大量的文本语料,上限比较高 completion 根据训练过的记忆,一个字一个字地计算概率,取概率最大的那个字进行输出 因此有人吐槽 LLM 输出很慢 - 逐字计算并输出 Prompt Engineering 需求描述越详细越准确,LLM 输出的内容就越符合要求 Prompt Engineering 是一门专门研究与 LLM 交互的新型学科 通过不断地开发和优化,帮助用户更好地了解 LLM 的能力和局限性 探讨如何设计出最佳提示,用于指导 LLM 帮助我们高效完成某项任务 不仅仅是设计和研发提示,还包含了与 LLM 交互的各种技能和技术 在实现与 LLM 交互、...
2024-07-02
LLM Core - Machine Learning Concept
机器学习 机器学习是让计算机利用数据来学习如何完成任务 机器学习允许计算机通过分析和学习数据来自我改进以及作出决策 房价预测 利用 scikit-learn 进行预测 数据集 housing_data.csv 面积 卧室数量 地理位置 售价 100 2 1 300 150 3 2 450 120 2 2 350 80 1 1 220 线性回归12345678910111213141516171819202122232425from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionimport pandas as pd# 加载数据集data = pd.read_csv("housing_data.csv") # 假设这是我们的房屋数据# 准备数据X = data[['面积', '卧室数量', '地理位置']] # 特征y = data[...

2024-06-28
LLM Deploy - ChatGLM3-6B
LLM 选择核心玩家 厂家很多,但没多少真正在研究技术 - 成本 - 不少厂商是基于 LLaMA 套壳 ChatGLM-6B ChatGLM-6B 和 LLaMA2 是比较热门的开源项目,国产 LLM 是首选 企业布局 LLM 选择 MaaS 服务,调用大厂 LLM API,但会面临数据安全问题 选择开源 LLM,自己微调、部署、为上层应用提供服务 企业一般会选择私有化部署 + 公有云 MaaS 的混合架构 在国产厂商中,从技术角度来看,智谱 AI 是国内 LLM 研发水平最高的厂商 6B 的参数规模为 62 亿,单张 3090 显卡就可以进行微调和推理 企业预算充足(百万以上,GPU 费用 + 商业授权) 可以尝试 GLM-130B,千亿参数规模,推理能力更强 GLM-130B 轻量化后,可以在 3090 × 4 上进行推理 训练 GLM-130B 大概需要 96 台 A100(320G),历时两个多月 计算资源 适合 CPU 计算的 LLM 不多 有些 LLM 可以在 CPU 上进行推理,但需要使用低精度轻量化的 LLM 但在低精度下,LLM 会失真,效果较差 要真正体验并应...
2024-07-04
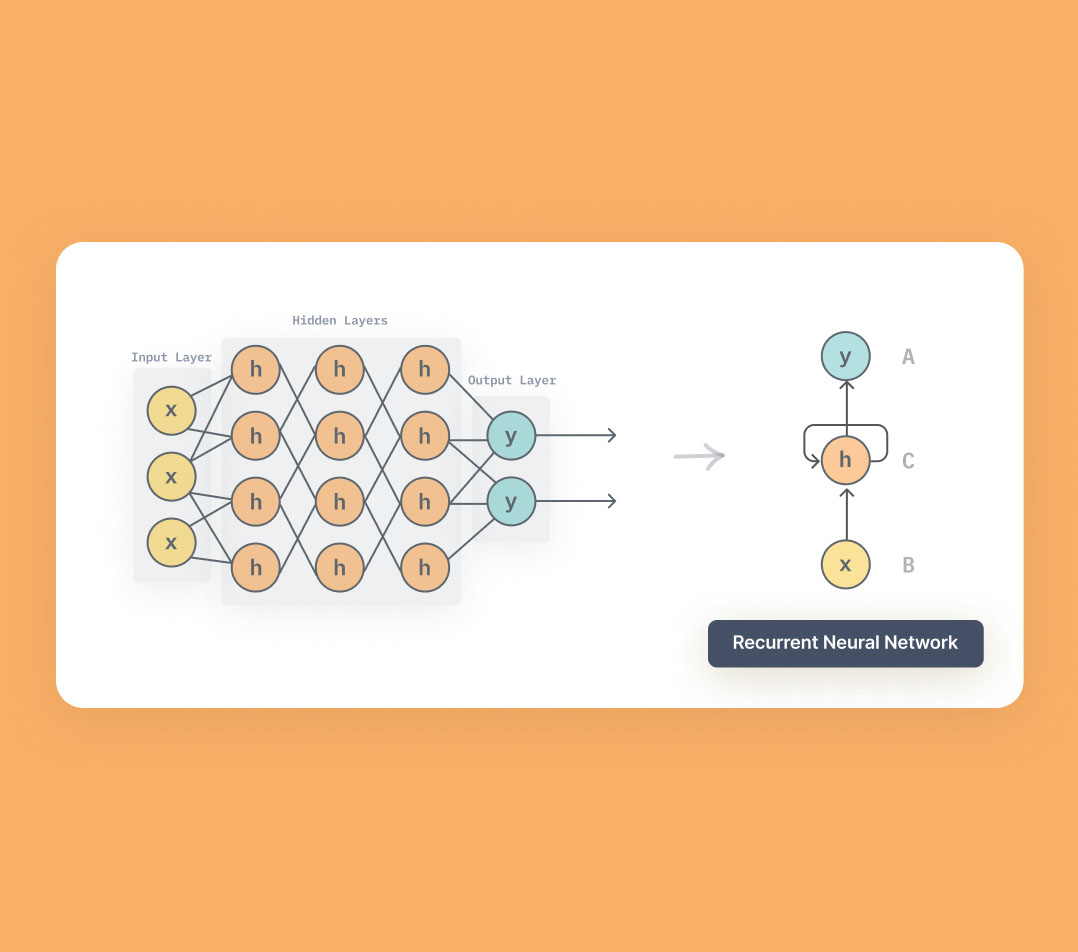
LLM Core - RNN
背景 RNN 主要用来处理序列数据,目前大部分 LLM 都是基于 Transformer 通过学习 RNN,有助于理解 Transformer 有助于理解神经网络如何处理序列中的依赖关系、记忆过去的信息,并在此基础上生成预测 有助于理解关键问题 - 梯度消失 / 梯度爆炸 RNN Recurrent neural network - 循环神经网络 RNN 是一类用于处理序列数据的神经网络,RNN 能够处理序列长度变化的数据 - 文本 / 语音 RNN 的特点是在模型中引入了循环,使得网络能够保持某种状态,表现出更好的性能 左边 $x$ 为输入层,$o$ 为输出层,中间的 $s$ 为隐藏层,在 $s$ 层进行一个循环 $W$ 右边(展开循环) 与时间 $t$ 相关的状态变化 神经网络在处理数据时,能看到前后时刻的状态,即上下文 RNN 因为隐藏层有时序状态,那么在推理的时候,可以借助上下文,从而理解语义更加准确 优劣优势 RNN 具有记忆能力,通过隐藏层的循环结构来捕捉序列的长期依赖关系 特别适用于文本生成、语音识别等领域 局限 存在梯度消失和梯度爆炸的...
2024-07-05
LLM Core - NLP
基础 NLP 的研究目的是让计算机能够理解、解释和生成人类语言,一般包含 4 个步骤 Step Desc 文本预处理 将原始文本转换成机器容易理解的格式分词(单词或短语)、去除停用词、词干提取、词性标注等 特征提取 从处理过的文本中提取特征,以便用于机器学习模型将文本转换成数值形式 - 向量化 - 词袋模型 or 词嵌入 模型训练 使用提取到的特征和相应的机器学习算法来训练模型分类器、回归模型、聚类算法等 评估与应用 评估模型的性能,并在实际应用中使用模型来解释、生成或翻译文本 应用场景 - 搜索引擎 / 语音转换 / 文本翻译 / 系统问答 ML vs NLP Scope Desc ML 让计算机通过查看大量的例子来学习如何完成任务 NLP 教会计算机理解和使用人类语言 ML + NLP 用机器学习的技术来让计算机学习如何处理和理解语言 文本预处理 将原始文本转换成易于机器理解和处理的格式 文本清洗 去除噪音(对分析无关紧要的部分)及标准化文本 123456789101112131415161718impor...




